
华为云码道智能体聊天记录查询与导出完整指南
本文详细介绍了华为云码道智能体聊天记录的查询与导出方法。主要内容包括: 聊天记录存储位置:SQLite数据库文件位于用户目录下,包含会话信息、消息记录等数据,同时配套相关日志文件。 数据库结构分析:核心表包括session(会话信息)、message(消息记录)、part(内容分段)等,详细说明了各表的重要字段。 查询实战: 查看会话列表 统计会话消息数量 预览消息内容 导出方案:提供Python
前言
在使用华为云码道(CodeArts)智能体进行开发过程中,我们经常需要查看历史聊天记录,回顾问题解决方案或者分析交互过程。本文将详细介绍如何查询和导出码道智能体的聊天记录,帮助你更好地管理和利用这些宝贵的对话数据。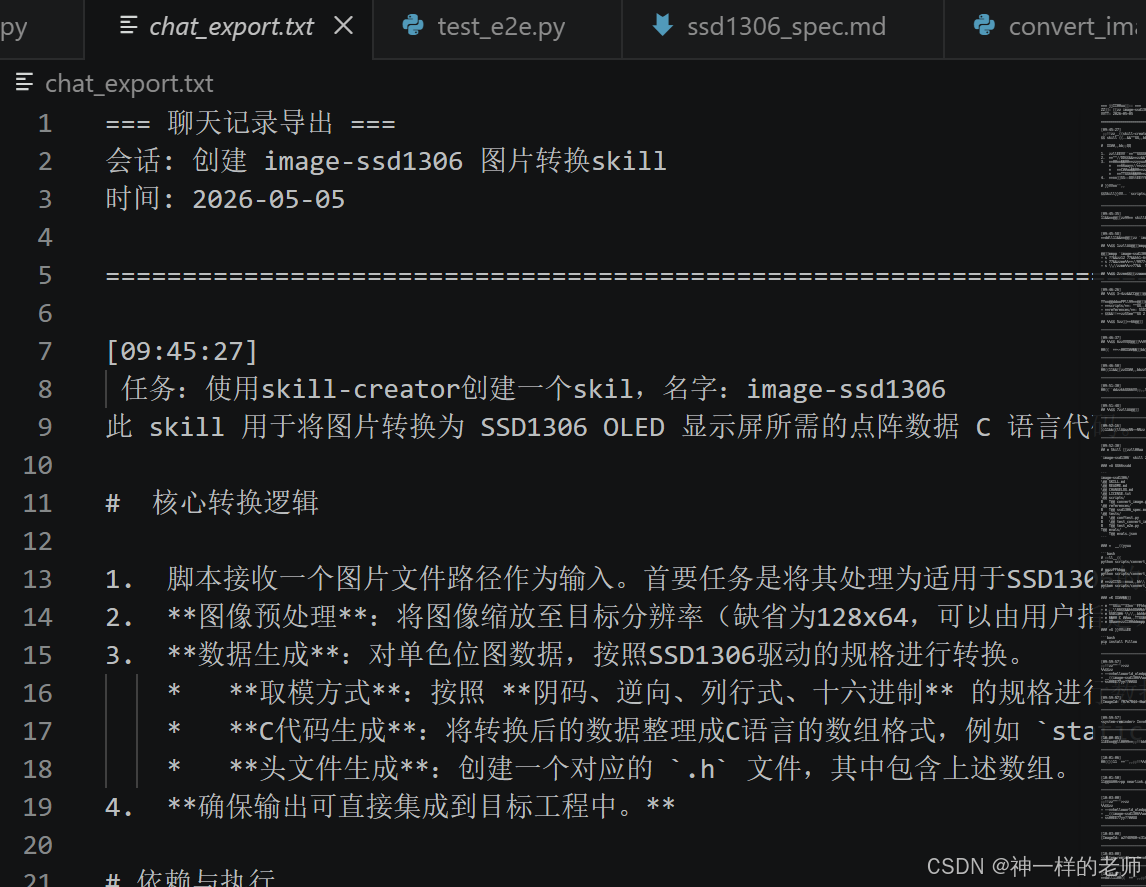
一、聊天记录存储位置
1.1 主要数据库文件
码道智能体的聊天记录存储在 SQLite 数据库中:
位置:C:\Users\<用户名>\.codeartsdoer\vscode-data\opencode.db
数据库特点:
- 格式:SQLite 3.x 数据库
- 编码:UTF-8
- 包含内容:会话信息、消息记录、用户交互数据等
- 文件大小:随着使用会逐渐增长(通常几MB到几十MB)
1.2 相关日志文件
除了数据库,还有相关的日志文件:
日志目录:C:\Users\<用户名>\.codeartsdoer\vscode-data\log\
包含以下日志:
kernel-codeartsdoer-incognito-*.log- 智能体运行日志agent-kernel-sdk-*.log- SDK 交互日志kernel_error_*.log- 错误日志kernel_output_*.log- 输出日志
二、数据库结构分析
2.1 核心数据表
码道智能体数据库包含以下核心表:
-- 查看所有表
SELECT name FROM sqlite_master WHERE type='table';
主要表说明:
| 表名 | 说明 |
|---|---|
session |
会话信息(标题、时间、项目目录等) |
message |
消息记录(用户输入、助手回复) |
part |
消息内容分段(文本、图片等具体内容) |
project |
项目信息 |
todo |
待办事项 |
permission |
权限管理 |
2.2 表结构详解
session 表(会话表)
-- 查看表结构
PRAGMA table_info(session);
重要字段:
id- 会话唯一标识title- 会话标题directory- 工作目录time_created- 创建时间(毫秒时间戳)time_updated- 更新时间(毫秒时间戳)
message 表(消息表)
-- 查看表结构
PRAGMA table_info(message);
重要字段:
id- 消息唯一标识session_id- 所属会话ID(外键)time_created- 创建时间data- 消息元数据(JSON格式)
part 表(内容分段表)
-- 查看表结构
PRAGMA table_info(part);
重要字段:
id- 分段唯一标识message_id- 所属消息ID(外键)session_id- 所属会话IDdata- 具体内容(JSON格式)
三、查询聊天记录实战
3.1 环境准备
首先确保你的环境中有 Python 和 sqlite3 模块:
import sqlite3
import json
from datetime import datetime
3.2 查看所有会话列表
import sqlite3
from datetime import datetime
# 连接数据库
conn = sqlite3.connect('C:/Users/<用户名>/.codeartsdoer/vscode-data/opencode.db')
cursor = conn.cursor()
# 查询最近的会话
cursor.execute('''
SELECT id, title, directory, time_created, time_updated
FROM session
ORDER BY time_updated DESC
LIMIT 10
''')
sessions = cursor.fetchall()
for sid, title, directory, created, updated in sessions:
created_str = datetime.fromtimestamp(created/1000).strftime('%Y-%m-%d %H:%M:%S')
updated_str = datetime.fromtimestamp(updated/1000).strftime('%Y-%m-%d %H:%M:%S')
print(f'会话: {title}')
print(f'ID: {sid}')
print(f'目录: {directory}')
print(f'创建时间: {created_str}')
print(f'更新时间: {updated_str}')
print('-' * 80)
conn.close()
输出示例:
会话: 创建 image-ssd1306 图片转换skill
ID: ses_20a303bbcffeyXNYNuajLSj4Je
目录: D:/fbb_ws63/src
创建时间: 2026-05-05 09:45:27
更新时间: 2026-05-05 10:51:39
--------------------------------------------------------------------------------
3.3 查询单个会话的消息统计
import sqlite3
conn = sqlite3.connect('C:/Users/<用户名>/.codeartsdoer/vscode-data/opencode.db')
cursor = conn.cursor()
# 指定会话ID
session_id = 'ses_20a303bbcffeyXNYNuajLSj4Je'
# 查询消息总数
cursor.execute('''
SELECT COUNT(*)
FROM message
WHERE session_id = ?
''', (session_id,))
total_messages = cursor.fetchone()[0]
# 查询用户消息数
cursor.execute('''
SELECT COUNT(*)
FROM message
WHERE session_id = ? AND json_extract(data, '$.role') = 'user'
''', (session_id,))
user_messages = cursor.fetchone()[0]
# 查询助手消息数
cursor.execute('''
SELECT COUNT(*)
FROM message
WHERE session_id = ? AND json_extract(data, '$.role') = 'assistant'
''', (session_id,))
assistant_messages = cursor.fetchone()[0]
print(f'消息总数: {total_messages}')
print(f'用户消息: {user_messages}')
print(f'助手消息: {assistant_messages}')
conn.close()
3.4 查看消息内容概览
import sqlite3
import json
from datetime import datetime
conn = sqlite3.connect('C:/Users/<用户名>/.codeartsdoer/vscode-data/opencode.db')
cursor = conn.cursor()
session_id = 'ses_20a303bbcffeyXNYNuajLSj4Je'
# 查询part表中的内容
cursor.execute('''
SELECT p.message_id, p.time_created, p.data
FROM part p
JOIN message m ON p.message_id = m.id
WHERE m.session_id = ?
ORDER BY p.time_created ASC
LIMIT 20
''', (session_id,))
parts = cursor.fetchall()
print('=== 聊天记录预览 ===\n')
for i, (msg_id, timestamp, data) in enumerate(parts, 1):
time_str = datetime.fromtimestamp(timestamp/1000).strftime('%H:%M:%S')
try:
part_data = json.loads(data)
part_type = part_data.get('type', 'unknown')
if part_type == 'text':
text = part_data.get('text', '')
# 只显示前150字符作为预览
preview = text[:150].replace('\n', ' ')
if len(text) > 150:
print(f'{i}. [{time_str}] {preview}...')
else:
print(f'{i}. [{time_str}] {preview}')
else:
print(f'{i}. [{time_str}] [{part_type}]')
except Exception as e:
print(f'{i}. [{time_str}] 解析错误: {e}')
conn.close()
四、导出聊天记录完整方案
4.1 导出为文本文件
import sqlite3
import json
from datetime import datetime
def export_chat_to_txt(db_path, session_id, output_file):
"""
导出聊天记录到文本文件
Args:
db_path: 数据库路径
session_id: 会话ID
output_file: 输出文件路径
"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 获取会话信息
cursor.execute('''
SELECT title, time_created
FROM session
WHERE id = ?
''', (session_id,))
session_info = cursor.fetchone()
if not session_info:
print('会话不存在')
return
title, created = session_info
created_str = datetime.fromtimestamp(created/1000).strftime('%Y-%m-%d')
# 查询所有内容
cursor.execute('''
SELECT p.time_created, p.data
FROM part p
JOIN message m ON p.message_id = m.id
WHERE m.session_id = ?
ORDER BY p.time_created ASC
''', (session_id,))
parts = cursor.fetchall()
# 写入文件
with open(output_file, 'w', encoding='utf-8') as f:
f.write('=== 聊天记录导出 ===\n')
f.write(f'会话: {title}\n')
f.write(f'时间: {created_str}\n')
f.write(f'消息数: {len(parts)}\n\n')
f.write('=' * 80 + '\n\n')
for timestamp, data in parts:
time_str = datetime.fromtimestamp(timestamp/1000).strftime('%H:%M:%S')
try:
part_data = json.loads(data)
part_type = part_data.get('type', 'unknown')
if part_type == 'text':
text = part_data.get('text', '')
f.write(f'[{time_str}]\n')
f.write(text)
f.write('\n\n' + '-' * 80 + '\n\n')
except Exception as e:
pass
f.write('\n=== 导出完成 ===\n')
conn.close()
print(f'导出成功: {output_file}')
print(f'共导出 {len(parts)} 条消息')
# 使用示例
db_path = 'C:/Users/<用户名>/.codeartsdoer/vscode-data/opencode.db'
session_id = 'ses_20a303bbcffeyXNYNuajLSj4Je'
output_file = 'D:/chat_export.txt'
export_chat_to_txt(db_path, session_id, output_file)
4.2 导出为 Markdown 格式
import sqlite3
import json
from datetime import datetime
def export_chat_to_markdown(db_path, session_id, output_file):
"""
导出聊天记录为 Markdown 格式
Args:
db_path: 数据库路径
session_id: 会话ID
output_file: 输出文件路径
"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 获取会话信息
cursor.execute('''
SELECT title, time_created
FROM session
WHERE id = ?
''', (session_id,))
session_info = cursor.fetchone()
title, created = session_info
created_str = datetime.fromtimestamp(created/1000).strftime('%Y-%m-%d %H:%M:%S')
# 查询消息和角色
cursor.execute('''
SELECT m.id, m.time_created, m.data
FROM message m
WHERE m.session_id = ?
ORDER BY m.time_created ASC
''', (session_id,))
messages = cursor.fetchall()
# 写入 Markdown
with open(output_file, 'w', encoding='utf-8') as f:
f.write(f'# {title}\n\n')
f.write(f'**会话时间**: {created_str}\n\n')
f.write(f'**消息总数**: {len(messages)}\n\n')
f.write('---\n\n')
for msg_id, msg_timestamp, msg_data in messages:
try:
msg_obj = json.loads(msg_data)
role = msg_obj.get('role', 'unknown')
role_cn = '👤 用户' if role == 'user' else '🤖 助手'
time_str = datetime.fromtimestamp(msg_timestamp/1000).strftime('%H:%M:%S')
# 查询该消息的所有part
cursor.execute('''
SELECT data FROM part
WHERE message_id = ?
ORDER BY time_created ASC
''', (msg_id,))
parts = cursor.fetchall()
for part_data, in parts:
try:
part_obj = json.loads(part_data)
part_type = part_obj.get('type', 'unknown')
if part_type == 'text':
text = part_obj.get('text', '')
f.write(f'### {role_cn} [{time_str}]\n\n')
f.write(f'{text}\n\n')
f.write('---\n\n')
except:
pass
except:
pass
conn.close()
print(f'Markdown 导出成功: {output_file}')
# 使用示例
export_chat_to_markdown(db_path, session_id, 'D:/chat_export.md')
4.3 导出为 JSON 格式
import sqlite3
import json
from datetime import datetime
def export_chat_to_json(db_path, session_id, output_file):
"""
导出聊天记录为 JSON 格式(结构化数据)
Args:
db_path: 数据库路径
session_id: 会话ID
output_file: 输出文件路径
"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 获取会话信息
cursor.execute('''
SELECT title, directory, time_created, time_updated
FROM session
WHERE id = ?
''', (session_id,))
session_info = cursor.fetchone()
title, directory, created, updated = session_info
# 构建导出数据结构
export_data = {
'session': {
'id': session_id,
'title': title,
'directory': directory,
'time_created': datetime.fromtimestamp(created/1000).isoformat(),
'time_updated': datetime.fromtimestamp(updated/1000).isoformat()
},
'messages': []
}
# 查询所有消息
cursor.execute('''
SELECT id, time_created, data
FROM message
WHERE session_id = ?
ORDER BY time_created ASC
''', (session_id,))
messages = cursor.fetchall()
for msg_id, msg_timestamp, msg_data in messages:
try:
msg_obj = json.loads(msg_data)
role = msg_obj.get('role', 'unknown')
# 查询该消息的所有part
cursor.execute('''
SELECT time_created, data
FROM part
WHERE message_id = ?
ORDER BY time_created ASC
''', (msg_id,))
parts = cursor.fetchall()
content_parts = []
for part_timestamp, part_data in parts:
try:
part_obj = json.loads(part_data)
part_type = part_obj.get('type', 'unknown')
if part_type == 'text':
content_parts.append({
'type': 'text',
'text': part_obj.get('text', ''),
'time': datetime.fromtimestamp(part_timestamp/1000).isoformat()
})
except:
pass
export_data['messages'].append({
'id': msg_id,
'role': role,
'time': datetime.fromtimestamp(msg_timestamp/1000).isoformat(),
'parts': content_parts
})
except:
pass
# 写入 JSON 文件
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(export_data, f, ensure_ascii=False, indent=2)
conn.close()
print(f'JSON 导出成功: {output_file}')
# 使用示例
export_chat_to_json(db_path, session_id, 'D:/chat_export.json')
五、高级查询技巧
5.1 搜索包含特定关键词的会话
import sqlite3
def search_sessions_by_keyword(db_path, keyword):
"""
搜索标题中包含关键词的会话
"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute('''
SELECT id, title, time_updated
FROM session
WHERE title LIKE ?
ORDER BY time_updated DESC
''', (f'%{keyword}%',))
sessions = cursor.fetchall()
print(f'找到 {len(sessions)} 个包含 "{keyword}" 的会话:\n')
for sid, title, updated in sessions:
time_str = datetime.fromtimestamp(updated/1000).strftime('%Y-%m-%d %H:%M')
print(f'- [{time_str}] {title}')
print(f' ID: {sid}\n')
conn.close()
# 使用示例
search_sessions_by_keyword(db_path, 'OLED')
5.2 统计各项目的会话数量
import sqlite3
from collections import Counter
def count_sessions_by_project(db_path):
"""
统计各项目目录的会话数量
"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute('''
SELECT directory, COUNT(*) as count
FROM session
GROUP BY directory
ORDER BY count DESC
''')
results = cursor.fetchall()
print('=== 项目会话统计 ===\n')
for directory, count in results:
print(f'{directory}: {count} 个会话')
conn.close()
# 使用示例
count_sessions_by_project(db_path)
5.3 批量导出所有会话
import sqlite3
import os
def export_all_sessions(db_path, output_dir):
"""
批量导出所有会话到指定目录
"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 获取所有会话
cursor.execute('SELECT id, title FROM session ORDER BY time_updated DESC')
sessions = cursor.fetchall()
print(f'准备导出 {len(sessions)} 个会话...\n')
for i, (session_id, title) in enumerate(sessions, 1):
# 生成安全的文件名
safe_title = title.replace('/', '_').replace('\\', '_').replace(':', '_')
output_file = os.path.join(output_dir, f'{i:03d}_{safe_title}.txt')
# 导出单个会话
try:
export_chat_to_txt(db_path, session_id, output_file)
except Exception as e:
print(f'导出失败 [{title}]: {e}')
conn.close()
print(f'\n批量导出完成!输出目录: {output_dir}')
# 使用示例
export_all_sessions(db_path, 'D:/chat_exports')
六、注意事项与最佳实践
6.1 数据库安全
⚠️ 重要提示:
-
备份原始数据库:在操作前先备份数据库文件
cp opencode.db opencode.db.backup -
只读操作:查询脚本应该只进行 SELECT 操作,不要执行 UPDATE、DELETE 等修改操作
-
连接管理:使用完毕后务必关闭数据库连接
conn.close()
6.2 性能优化
处理大量数据时:
- 使用 LIMIT 限制查询结果数量
- 使用索引加速查询(session_id、time_created 等字段已有索引)
- 分批处理大量导出任务
示例:
# 分批查询
batch_size = 100
offset = 0
while True:
cursor.execute('''
SELECT * FROM message
WHERE session_id = ?
ORDER BY time_created
LIMIT ? OFFSET ?
''', (session_id, batch_size, offset))
batch = cursor.fetchall()
if not batch:
break
# 处理这一批数据
process_batch(batch)
offset += batch_size
6.3 编码问题
确保正确处理中文编码:
# 打开文件时指定编码
with open(output_file, 'w', encoding='utf-8') as f:
f.write(content)
# JSON 处理时保留中文
json.dump(data, f, ensure_ascii=False, indent=2)
6.4 时间戳转换
数据库中的时间是毫秒时间戳,需要除以 1000:
# 正确的转换方式
from datetime import datetime
timestamp_ms = 1777946397184 # 毫秒时间戳
timestamp_s = timestamp_ms / 1000 # 转换为秒
dt = datetime.fromtimestamp(timestamp_s)
time_str = dt.strftime('%Y-%m-%d %H:%M:%S')
七、完整工具脚本
将以上功能整合为一个完整的命令行工具:
#!/usr/bin/env python3
"""
华为云码道智能体聊天记录导出工具
"""
import sqlite3
import json
import os
from datetime import datetime
import argparse
class ChatExporter:
def __init__(self, db_path):
self.db_path = db_path
self.conn = None
def connect(self):
"""连接数据库"""
self.conn = sqlite3.connect(self.db_path)
def close(self):
"""关闭连接"""
if self.conn:
self.conn.close()
def list_sessions(self, limit=20):
"""列出最近的会话"""
cursor = self.conn.cursor()
cursor.execute('''
SELECT id, title, directory, time_updated
FROM session
ORDER BY time_updated DESC
LIMIT ?
''', (limit,))
sessions = cursor.fetchall()
print(f'\n=== 最近 {len(sessions)} 个会话 ===\n')
for i, (sid, title, directory, updated) in enumerate(sessions, 1):
time_str = datetime.fromtimestamp(updated/1000).strftime('%Y-%m-%d %H:%M')
print(f'{i}. {title}')
print(f' 时间: {time_str}')
print(f' ID: {sid}')
print(f' 目录: {directory}\n')
return sessions
def export_session(self, session_id, output_file, format='txt'):
"""导出单个会话"""
if format == 'txt':
self._export_txt(session_id, output_file)
elif format == 'md':
self._export_markdown(session_id, output_file)
elif format == 'json':
self._export_json(session_id, output_file)
def _export_txt(self, session_id, output_file):
"""导出为文本格式"""
cursor = self.conn.cursor()
# 获取会话信息
cursor.execute('SELECT title FROM session WHERE id=?', (session_id,))
title = cursor.fetchone()[0]
# 查询内容
cursor.execute('''
SELECT p.time_created, p.data
FROM part p
JOIN message m ON p.message_id = m.id
WHERE m.session_id = ?
ORDER BY p.time_created ASC
''', (session_id,))
parts = cursor.fetchall()
with open(output_file, 'w', encoding='utf-8') as f:
f.write(f'=== {title} ===\n\n')
for timestamp, data in parts:
time_str = datetime.fromtimestamp(timestamp/1000).strftime('%H:%M:%S')
try:
part_obj = json.loads(data)
if part_obj.get('type') == 'text':
f.write(f'[{time_str}]\n')
f.write(part_obj.get('text', ''))
f.write('\n\n' + '-' * 80 + '\n\n')
except:
pass
print(f'导出成功: {output_file}')
# 其他导出方法类似...
def _export_markdown(self, session_id, output_file):
"""导出为 Markdown 格式"""
# 实现略...
pass
def _export_json(self, session_id, output_file):
"""导出为 JSON 格式"""
# 实现略...
pass
def main():
parser = argparse.ArgumentParser(description='码道智能体聊天记录导出工具')
parser.add_argument('--db', default='C:/Users/<用户名>/.codeartsdoer/vscode-data/opencode.db',
help='数据库路径')
parser.add_argument('--list', action='store_true', help='列出最近会话')
parser.add_argument('--export', help='导出指定会话ID')
parser.add_argument('--output', help='输出文件路径')
parser.add_argument('--format', choices=['txt', 'md', 'json'], default='txt',
help='导出格式')
args = parser.parse_args()
exporter = ChatExporter(args.db)
exporter.connect()
try:
if args.list:
exporter.list_sessions()
elif args.export and args.output:
exporter.export_session(args.export, args.output, args.format)
else:
parser.print_help()
finally:
exporter.close()
if __name__ == '__main__':
main()
使用示例:
# 列出最近会话
python chat_exporter.py --list
# 导出指定会话
python chat_exporter.py --export ses_20a303bbcffeyXNYNuajLSj4Je --output chat.txt
# 导出为 Markdown
python chat_exporter.py --export ses_20a303bbcffeyXNYNuajLSj4Je --output chat.md --format md
八、总结
本文详细介绍了华为云码道智能体聊天记录的存储结构和查询导出方法:
- 存储位置:聊天记录存储在 SQLite 数据库
opencode.db中 - 数据结构:通过 session、message、part 三张表组织数据
- 查询方法:提供了多种查询方式,包括会话列表、消息统计、内容预览
- 导出方案:支持文本、Markdown、JSON 三种导出格式
- 高级功能:搜索、统计、批量导出等实用功能
- 最佳实践:数据安全、性能优化、编码处理等注意事项
通过这些方法,你可以方便地管理和利用码道智能体的聊天记录,为开发工作提供参考和回顾。
参考资料
- SQLite 官方文档:https://www.sqlite.org/docs.html
- Python sqlite3 模块:https://docs.python.org/3/library/sqlite3.html
- 华为云码道官方文档:https://support.huaweicloud.com/productdesc-codearts/

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)