
91.59% 执行准确率!NL2SQL 多智能体框架(值得收藏)
基于论文级研究成果构建的 NL2SQL 企业级解决方案,已在但问智能大模型应用开发班落地实施。用 6 个专业化 Agent 的"流水线分工 + 分类法引导纠错",在 Spider 基准测试上达到 91.59% 执行准确率,成本还可降低 30%。
一、NL2SQL痛点
自然语言转 SQL(NL2SQL/Text-to-SQL)被称为"数据分析的最后一公里"。但现实中,大量企业的 NL2SQL 项目卡在 40%~60% 的准确率上,迟迟无法落地生产:

核心矛盾:95%~99% 的生成查询在语法上是正确的,但逻辑上错了——AI 不知道"为什么错",只知道"报错了"。
二、但问智能 NL2SQL
但问智能自研基于 Multi-agentic Text-to-SQL with Guided Error Correction 研究论文的企业级 NL2SQL 多智能体框架,核心能力是将用户的自然语言业务问题转化为精确、可执行的 SQL 查询语句。
🏆 核心指标
┌─────────────────────────────────────────┐
│ Spider 基准测试执行准确率: 91.59% │
│ 混合部署成本降低: ~30% │
│ 纠错成功率: >85% │
│ 最大纠错尝试: 3 次 │
│ 温度参数: 0 (确定性) │
└─────────────────────────────────────────┘
🎯 形式化定义
整个 NL2SQL 流程被严格形式化为:
Y = LLM(Q, S, C, P, T | θ)
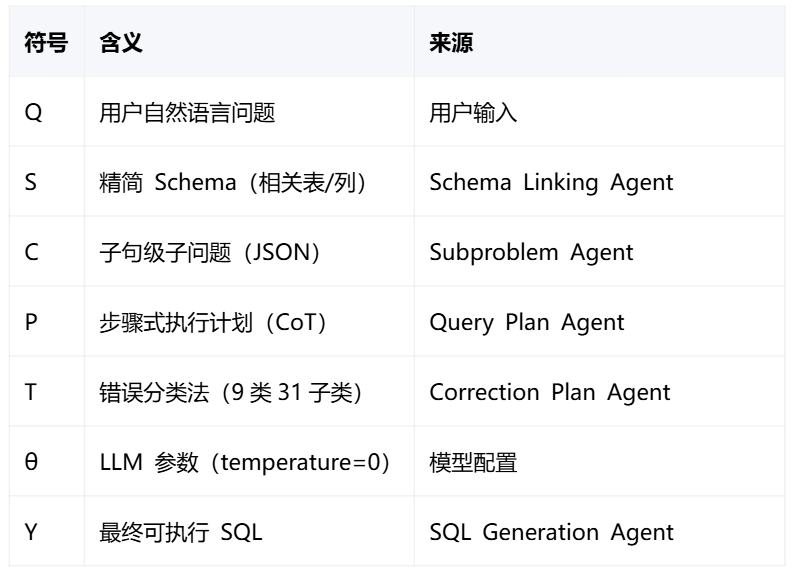
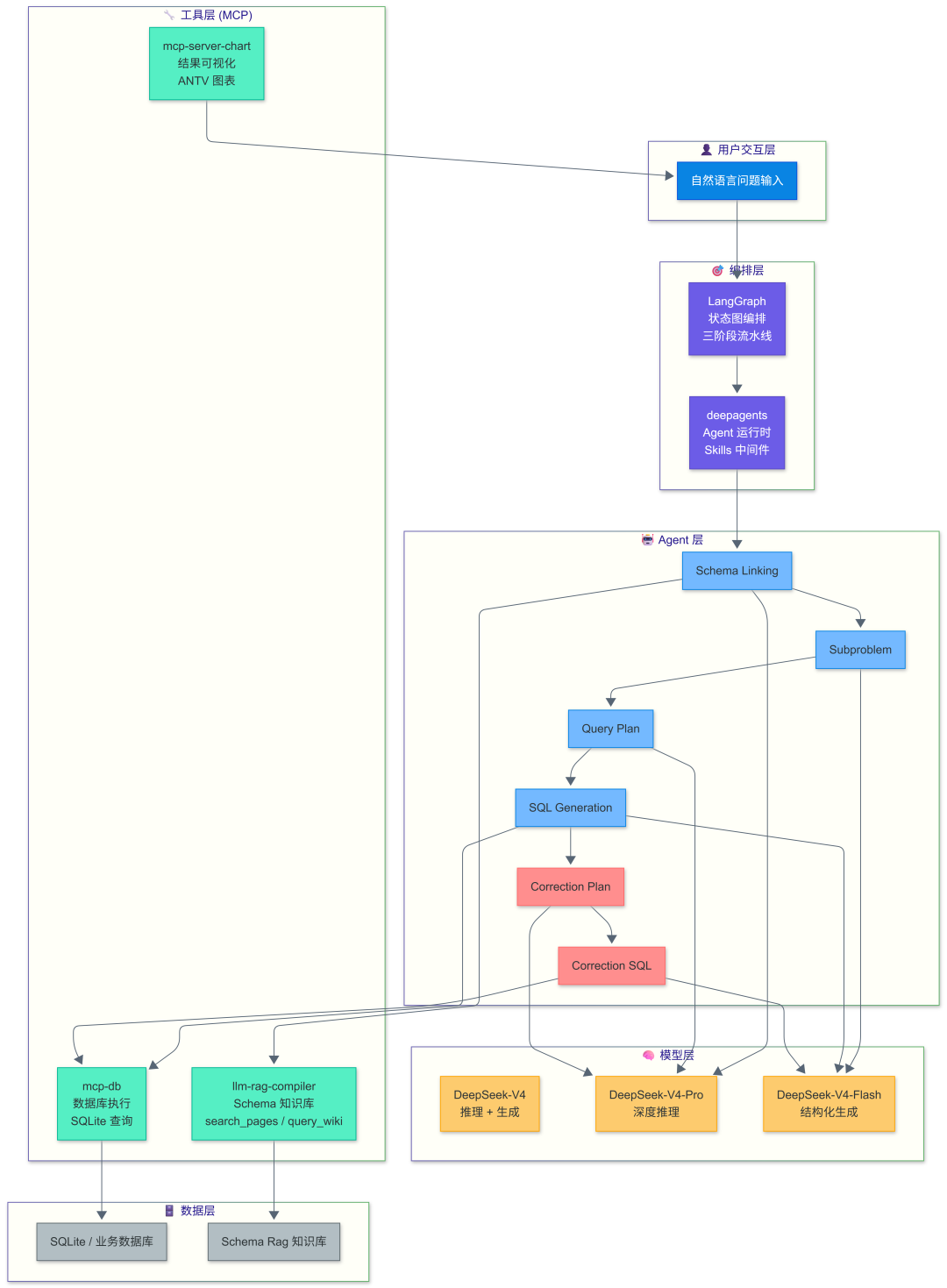
三、核心架构:三阶段流水线
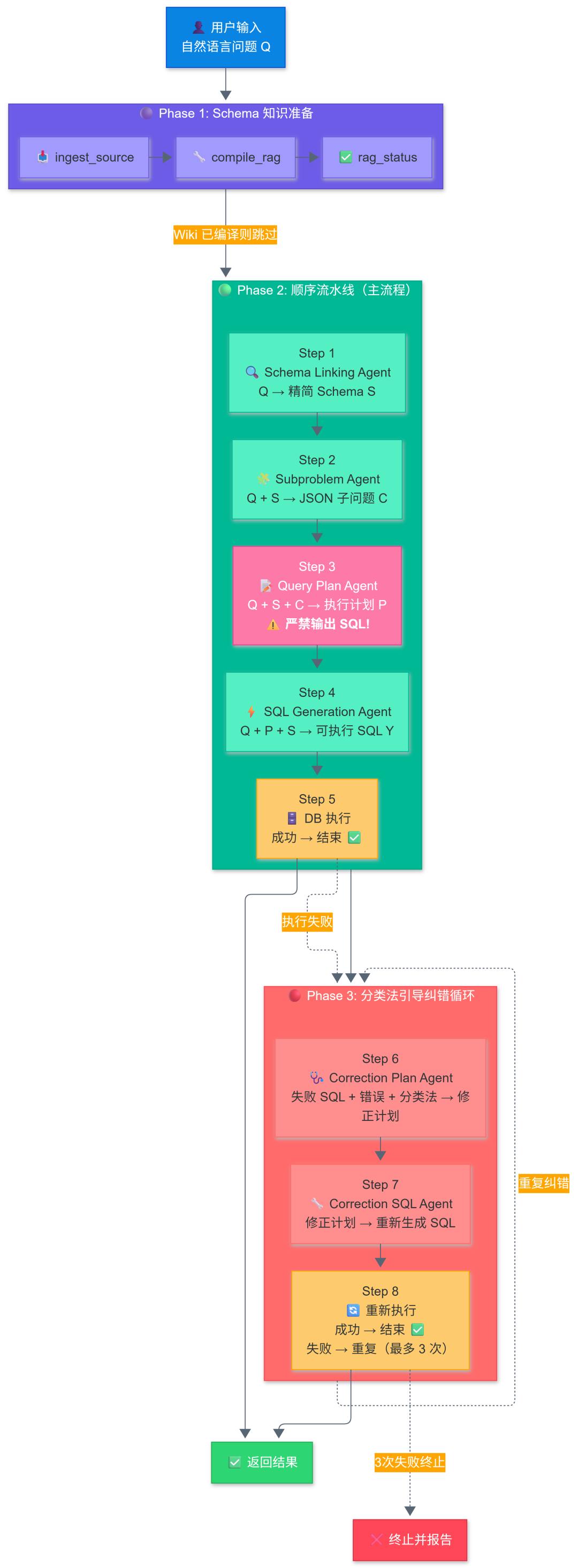
设计精髓:
● Phase 1 是预流水线,确保数据库 Schema 知识库通过 RAG MCP 工具链就绪
● Phase 2 是严格的 5 步顺序流水线,不可跳过、不可重排
● Phase 3 是条件触发的纠错循环,仅在执行失败时启动
四、六大智能体:专业化分工,各显神通
🔍 Schema Linking Agent — “导航员”
通过 RAG MCP 工具链(search_pages → query_rag→ read_page)从问题中提取相关表、列、主键、外键和 JOIN 路径。只保留直接相关的 Schema 元素,避免无关信息干扰下游 Agent。
🧩 Subproblem Agent — “拆解师”
将复杂问题拆解为结构化 JSON,覆盖 9 种 SQL 子句类型:WHERE、GROUP BY、HAVING、JOIN、DISTINCT、ORDER BY、LIMIT、EXCEPT、UNION。每个子问题用自然语言描述,而非 SQL 语法。
📝 Query Plan Agent — “总设计师”
这是整个系统最关键的中间推理步骤。基于 CoT 生成步骤式执行计划,但 严禁输出任何 SQL 代码。消融实验证明:跳过此步骤准确率下降约 5%,在此步骤生成 SQL 会导致过早承诺特定构造、增加幻觉。
⚡ SQL Generation Agent — “翻译官”
整个流水线中唯一生成 SQL 的 Agent。严格依照 Query Plan 的步骤顺序,将 procedural plan 翻译为可执行 SQL,并进行后处理(去除尾部分号、自然语言片段、规范化空白)。
🩺 Correction Plan Agent — “诊断专家”
当 SQL 执行失败时,不盲目重试,而是基于 9 大类 31 小类错误分类法 进行结构化诊断,输出包含根因分析、修复策略、SQL 修改点的 CoT 修正计划。
🔧 Correction SQL Agent — “修复工程师”
按照修正计划重新生成 SQL,不携带任何历史 scratchpad,从零开始避免上下文漂移。
五、最大创新:31 维错误分类法引导纠错
传统 NL2SQL 系统的纠错机制是"执行报错 → 把错误信息塞给 LLM → 让 LLM 猜怎么修"。这种方式的失败率高达 70% 以上,因为:
95%~99% 的失败查询语法是正确的,问题出在逻辑错误——原始执行 trace 提供的指导非常有限。
本系统的解决方案是:结构化错误分类法 + CoT 推理引导

纠错流程示例
失败 SQL: SELECT name, AVG(salary) FROM employees WHERE dept_id > 5
❌ 传统方式: "SQL 执行返回了错误结果,请修复"
→ LLM 猜来猜去,越修越错
✅ 分类法引导方式:
诊断:
- aggregation.agg_no_groupby ← AVG() 没写 GROUP BY
- filter.condition_type_mismatch ← dept_id 是外键不该和数字比
- schema_link.incorrect_foreign_key ← 应该用 departments 表 join
修正计划:
1. Add JOIN with departments table via dept_id FK
2. Add GROUP BY d.dept_name
3. Add d.dept_name to SELECT
4. Replace WHERE with proper HAVING if needed
修正后 SQL:
SELECT d.dept_name, AVG(e.salary)
FROM employees e JOIN departments d ON e.dept_id = d.id
GROUP BY d.dept_name
六、九大黄金设计原则(经过消融实验验证)
这些原则不是"拍脑袋"想出来的,每一项都有消融实验的失败数据支撑:

七、混合模型策略:性能与成本的黄金平衡点
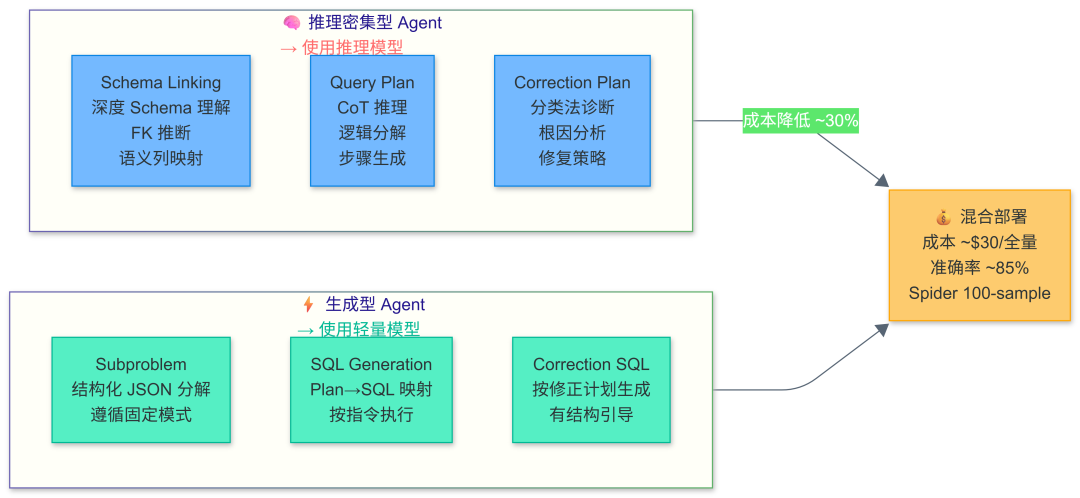
关键洞察:Schema Linking、Query Plan、Correction Plan 需要深度推理能力,必须使用推理模型;Subproblem、SQL Generation、Correction SQL 是结构化映射任务,轻量模型完全胜任。
八、技术栈全景
九、实战效果:从" average salary" 看完整流水线
以经典问题 “Find the average salary of employees in departments with more than 10 people” 为例:
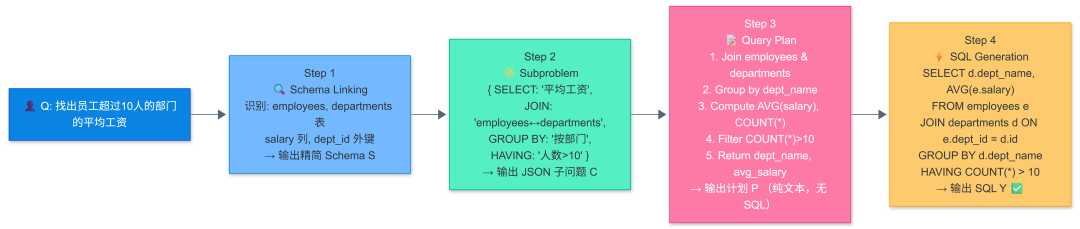
首次生成即成功 → 跳过 Phase 3 纠错循环,直接返回结果。
十、但问智能 NL2SQL 核心优势
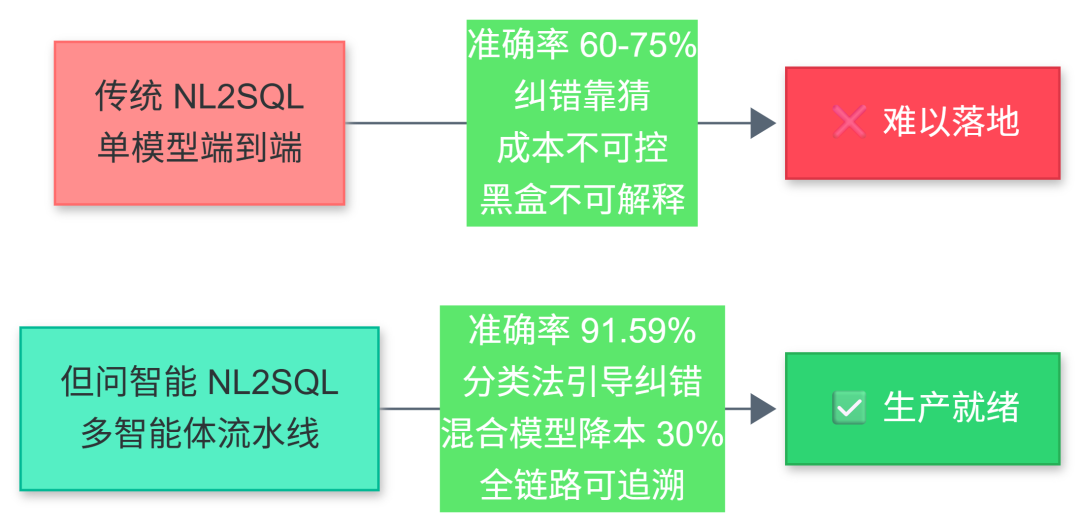
五大核心优势

项目定位:企业级 NL2SQL 生产框架,让自然语言到 SQL 的转换从"Demo 可用"走向"生产可靠"。
📞 支持与反馈
维护团队: 北京慧测·杭州但问智能技术团队

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)