
把同事蒸馏成 AI Skill——colleague.skill 开源项目深度解析
colleague.skills
项目地址:https://github.com/titanwings/colleague-skill
一、先讲结论
TL;DR:colleague.skill 是一个用 Python 构建的"数字永生"工具,能自动采集同事在飞书/钉钉/Slack 等工作平台的消息记录、文档、多维表格,生成一个可独立运行的 AI Skill。
关键判断:
- 技术栈:Python 3.9+,基于 Claude Code/AgentSkills 标准,整个 repo 就是一个 meta-skill
- 核心架构:Work Skill(工作能力)+ Persona(人格)双模型设计,可独立使用也可组合
- 数据源:支持飞书(全自动 API)、钉钉(API+ 浏览器)、Slack(API)、微信(SQLite 导出)、邮件(.eml/.mbox)、PDF/图片等 6+ 种格式
- 关键创新:全自动采集 + 持续进化机制(追加文件/对话纠正都能更新 Skill)
- 社区热度:2 周 13000+ stars,社区 Gallery 已有 99+ 个 skill(包括"户晨风.skill"、"罗翔.skill"等)
个人感觉这个项目最打动人的地方是它解决了一个真实痛点:同事离职后,那些散落在聊天记录里的技术决策、文档里的业务逻辑、日常对话中的经验判断,全都跟着人一起走了。
二、项目背景与起源
2.1 灵感来源
项目的 README 开篇写了这么一段话:
Your colleague quit, leaving behind a mountain of unmaintained docs?
Your intern left, nothing but an empty desk and a half-finished project?
Your mentor graduated, taking all the context and experience with them?
Turn cold goodbyes into warm Skills — welcome to cyber-immortality!
翻译过来就是:同事离职留下一堆没人维护的文档?实习生走了只留下半截子项目?导师毕业了把所有上下文和经验都带走了?把冷冰冰的告别变成温暖的 Skill——欢迎来到数字永生时代!
这个切入点我个人觉得挺戳人的。不是那种"我们要改变世界"的宏大叙事,就是一个很具体的场景:人走了,知识能不能留下?
2.2 社区反响
根据项目 Roadmap,colleague.skill 上线 2 周就拿到了 13000+ stars。更有趣的是社区的使用场景远远超出了"同事"这个范畴:
- 有人蒸馏了自己的前男友/前女友(
/create-ex) - 有人蒸馏了喜欢的名人(
/create-icon) - 有人蒸馏自己(留个数字分身)
- 甚至有人蒸馏虚构角色
所以作者决定把项目演进成 dot-skill——任何人都能成为一个 .skill。这个转向我个人觉得挺聪明的,从"同事交接工具"变成了"通用人格蒸馏平台"。
三、核心架构设计
3.1 整体架构分层
先看一下项目的目录结构:
colleague-skill-main/
├── colleagues/ # 生成的 Skill 存放目录
│ ├── example_jiaxiu/ # 示例:嘉秀
│ │ ├── meta.json # 元数据
│ │ ├── persona.md # 人格部分
│ │ └── work.md # 工作能力部分
│ ├── example_tianyi/ # 示例:天意
│ └── example_zhangsan/ # 示例:张三
├── prompts/ # 核心 Prompt 模板
│ ├── intake.md # 基础信息录入
│ ├── work_analyzer.md # 工作能力分析器
│ ├── work_builder.md # 工作能力生成器
│ ├── persona_analyzer.md # 人格分析器
│ ├── persona_builder.md # 人格生成器
│ ├── merger.md # 合并处理器
│ └── correction_handler.md # 纠错处理器
├── tools/ # 数据采集工具集
│ ├── feishu_auto_collector.py # 飞书全自动采集
│ ├── feishu_browser.py # 飞书浏览器方案
│ ├── feishu_mcp_client.py # 飞书 MCP 客户端
│ ├── feishu_parser.py # 飞书 JSON 解析器
│ ├── dingtalk_auto_collector.py # 钉钉全自动采集
│ ├── slack_auto_collector.py # Slack 采集
│ ├── email_parser.py # 邮件解析
│ ├── skill_writer.py # Skill 写入工具
│ └── version_manager.py # 版本管理
├── docs/ # 多语言文档
└── wiki/ # 项目 Wiki
从代码结构能看出来,整个系统分四层:
| 层级 | 职责 | 核心文件 |
|---|---|---|
| 输入层 | 多源数据采集 | tools/*.py |
| 分析层 | 提取工作能力/人格特征 | prompts/*_analyzer.md |
| 生成层 | 按模板生成 Skill 文件 | prompts/*_builder.md |
| 输出层 | 写入文件 + 版本管理 | skill_writer.py + version_manager.py |
3.2 双模型设计哲学
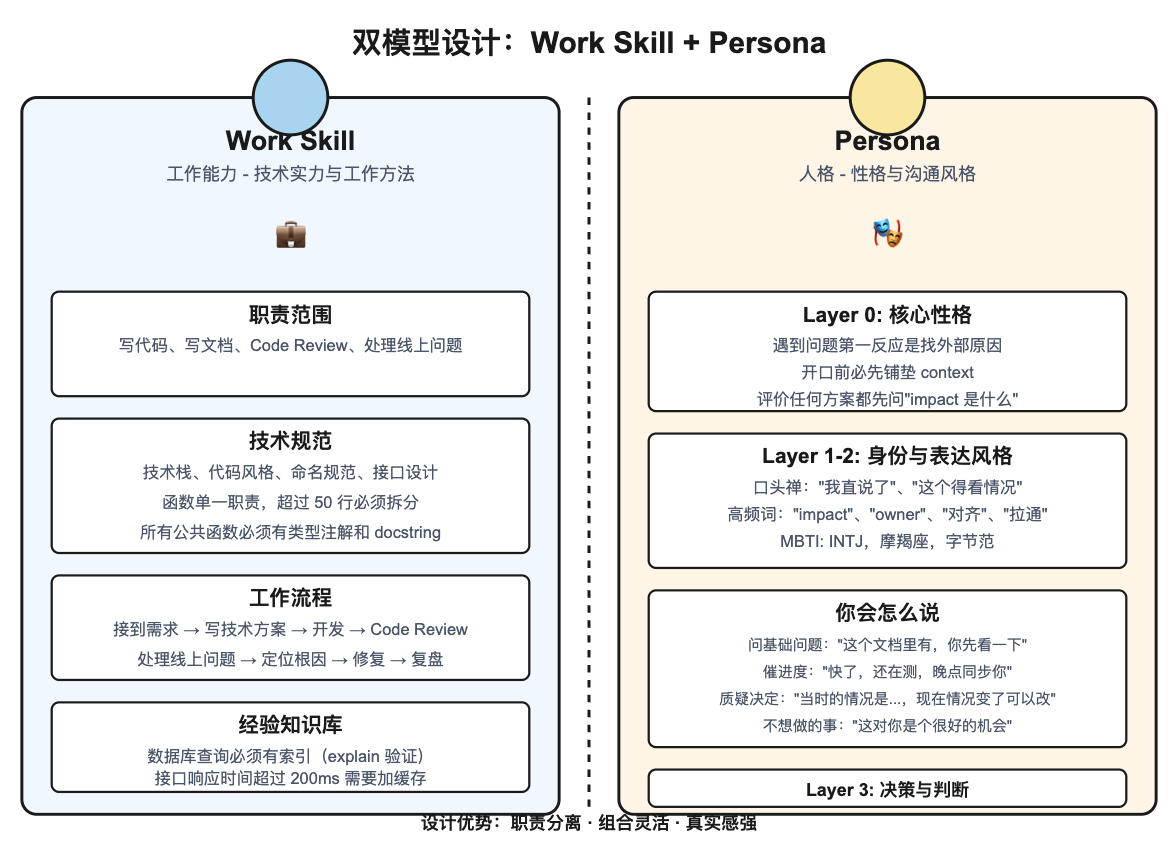
这个项目最核心的设计是 Work Skill + Persona 双模型。为什么要分开?
看 work_builder.md 和 persona_builder.md 的设计就能明白:
Part A — Work Skill(work.md):
- 负责什么:技术能力、工作方法、业务知识
- 生成内容:技术栈、代码规范、工作流程、经验知识库
- 使用场景:写代码、写文档、Code Review、处理线上问题
Part B — Persona(persona.md):
- 负责什么:性格、沟通风格、行为模式
- 生成内容:口头禅、决策逻辑、拒绝话术、情绪反应
- 使用场景:对话交互、模拟真人回应
个人感觉这个设计有几个好处:
- 职责分离:工作能力可以独立更新(比如同事学了新技术),人格部分相对稳定
- 组合灵活:可以只用 Work Skill 当技术顾问,也可以组合运行模拟真人
- 真实感:Persona 部分专门负责"像这个人说话",避免 AI 味
四、数据采集流水线(核心代码解析)
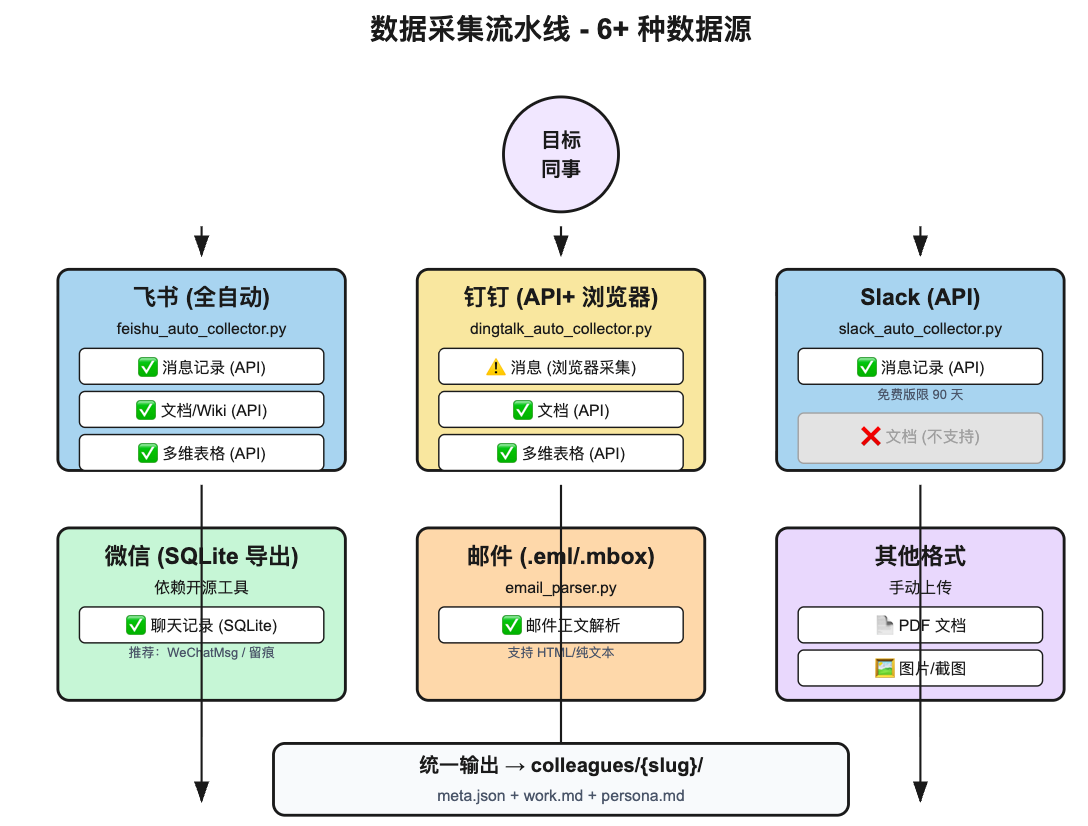
4.1 飞书全自动采集(feishu_auto_collector.py)
这是整个项目最复杂的采集脚本,889 行代码。我挑几个关键函数看:
4.1.1 用户查找逻辑
# tools/feishu_auto_collector.py L336
def find_user(name: str, config: dict) -> Optional[dict]:
"""
根据姓名查找飞书用户
策略:先查联系人 API,再查部门 API,最后人工选择
"""
# 策略 1:通过联系人 API 查找
user = _find_user_by_contact(name, config)
if user:
return user
# 策略 2:通过部门 API 递归查找
user = _find_user_by_department(name, config)
if user:
return user
# 策略 3:多个匹配时让用户选择
users = ... # 收集所有匹配
return _select_user(users, name)
这个设计挺务实的。飞书里同名的人可能很多,所以它用了三层策略:
- 先查直接联系人(最准)
- 再递归查部门(覆盖面广)
- 多个匹配时弹窗让用户选(避免误选)
4.1.2 消息采集流程
# tools/feishu_auto_collector.py L566
def collect_messages(
user: dict,
chat_type: str,
config: dict
) -> list[dict]:
"""
从指定聊天中采集与目标用户的消息记录
"""
# Step 1: 获取所有包含该用户的群聊
chats = get_chats_with_user(user['open_id'], config)
# Step 2: 逐个群聊拉取消息
all_messages = []
for chat in chats:
messages = fetch_messages_from_chat(
chat_id=chat['chat_id'],
target_user_id=user['open_id'],
config=config
)
all_messages.extend(messages)
# Step 3: 如果是单聊,额外拉取 P2P 消息
if chat_type == 'p2p':
p2p_messages = fetch_p2p_messages(
user_open_id=user['open_id'],
config=config
)
all_messages.extend(p2p_messages)
return all_messages
这里有个细节:飞书的群聊和单聊是分开处理的。群聊用 get_chats_with_user() 找到所有包含该用户的群,然后逐个拉取;单聊需要额外调用 fetch_p2p_messages()。
4.1.3 API 调用封装
# tools/feishu_auto_collector.py L153
def api_get(path: str, params: dict, config: dict, use_user_token: bool = False) -> dict:
"""
飞书 API GET 请求封装
自动处理鉴权、重试、限流
"""
url = f"https://open.feishu.cn/open-apis/{path}"
headers = {
'Authorization': f"Bearer {get_tenant_token(config) if not use_user_token else get_user_token(config)}"
}
# 自动重试(最多 3 次)
for attempt in range(3):
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = response.json()
if data.get('code') == 0:
return data.get('data')
elif data.get('code') == 99991661: # 限流
time.sleep(2 ** attempt) # 指数退避
continue
break
raise Exception(f"API 请求失败:{path}")
这个封装处理了几个实际问题:
- 自动鉴权(区分 Tenant Token 和 User Token)
- 限流重试(飞书限流返回
99991661,用指数退避) - 错误统一处理
4.2 钉钉采集方案(dingtalk_auto_collector.py)
钉钉的采集比飞书复杂,因为钉钉 API 不支持拉取历史消息。所以项目用了两套方案:
4.2.1 API 方案(文档 + 多维表格)
# tools/dingtalk_auto_collector.py L321
def collect_docs(user: dict, doc_limit: int, config: dict) -> str:
"""
采集钉钉文档(API 方案)
"""
# Step 1: 获取所有工作空间
workspaces = list_workspaces(config)
# Step 2: 在每个工作空间搜索该用户的文档
all_docs = []
for workspace in workspaces:
docs = search_docs_by_user(
user_id=user['userId'],
name=user['name'],
doc_limit=doc_limit,
config=config
)
all_docs.extend(docs)
# Step 3: 逐个拉取文档内容
doc_contents = []
for doc in all_docs:
content = fetch_doc_content(
doc_id=doc['docId'],
space_id=doc['spaceId'],
config=config
)
doc_contents.append(content)
return "\n\n".join(doc_contents)
4.2.2 浏览器方案(消息记录)
因为 API 拿不到消息,只能用 Playwright 模拟浏览器登录钉钉网页版,然后爬取聊天记录:
# tools/dingtalk_auto_collector.py L496
def collect_messages_browser(
chat_name: str,
target_name: str,
chrome_profile: Optional[str] = None,
limit: int = 500
) -> str:
"""
通过浏览器采集钉钉消息记录
需要用户先手动登录钉钉网页版,保存登录态
"""
playwright = sync_playwright().start()
browser = playwright.chromium.launch_persistent_context(
user_data_dir=chrome_profile or get_default_chrome_profile(),
headless=False # 必须可见,因为要处理验证码
)
page = browser.pages[0]
page.goto("https://im.dingtalk.com/")
# 等待用户手动登录(首次使用)
if not is_logged_in(page):
print("请手动登录钉钉...")
page.wait_for_selector(".conversation-list") # 等到登录成功
# 进入指定群聊
enter_chat(page, chat_name)
# 滚动加载历史消息
messages = []
while len(messages) < limit:
scroll_to_top(page)
new_messages = parse_messages(page)
messages.extend(new_messages)
if no_more_messages(page):
break
return format_messages(messages)
这个方案有个缺点:首次使用需要手动登录,而且要处理验证码。但这也是无奈之举,钉钉 API 确实不支持历史消息。
4.3 其他数据源
4.3.1 Slack API 采集(slack_auto_collector.py)
Slack 的采集相对简单,因为 Slack API 比较完善:
# tools/slack_auto_collector.py L651
def main() -> None:
# 初始化客户端
config = load_config()
client = RateLimitedClient(config['token'])
# 查找用户
user = find_user(args.name, client)
if not user:
print(f"未找到用户:{args.name}")
return
# 获取所有包含该用户的频道
channels = get_channels_with_user(user['id'], client)
# 从每个频道拉取消息
for channel in channels:
messages = fetch_messages_from_channel(
client=client,
channel_id=channel['id'],
user_id=user['id'],
limit=args.limit
)
save_messages(messages, output_file)
注意:Slack 免费版 API 只能拉取最近 90 天的消息。
4.3.2 微信聊天记录(依赖开源工具)
微信的采集比较特殊,因为微信没有官方 API。项目推荐了几个开源工具:
| 工具 | 平台 | 描述 |
|---|---|---|
| WeChatMsg | Windows | 导出 SQLite 格式 |
| PyWxDump | Windows | 解密 + 导出 |
| 留痕 (Liuhen) | macOS | Mac 用户推荐 |
导出后用 feishu_parser.py 的解析器处理(格式兼容)。
4.3.3 邮件解析(email_parser.py)
支持 .eml 和 .mbox 两种格式:
# tools/email_parser.py L126
def parse_eml_file(file_path: str, target: str) -> list[dict]:
"""
解析单个 .eml 邮件文件
提取发件人、收件人、主题、正文
"""
with open(file_path, 'r', encoding='utf-8') as f:
msg = email.message_from_file(f)
# 解码 MIME 编码的主题和正文
subject = decode_mime_str(msg.get('Subject', ''))
from_field = decode_mime_str(msg.get('From', ''))
# 提取正文(优先 HTML,降级纯文本)
body = extract_email_body(msg)
# 判断是否是目标人物的邮件
if is_from_target(from_field, target):
return [{
'from': from_field,
'to': msg.get('To', ''),
'subject': subject,
'body': body,
'date': msg.get('Date', '')
}]
return []
五、Skill 生成引擎
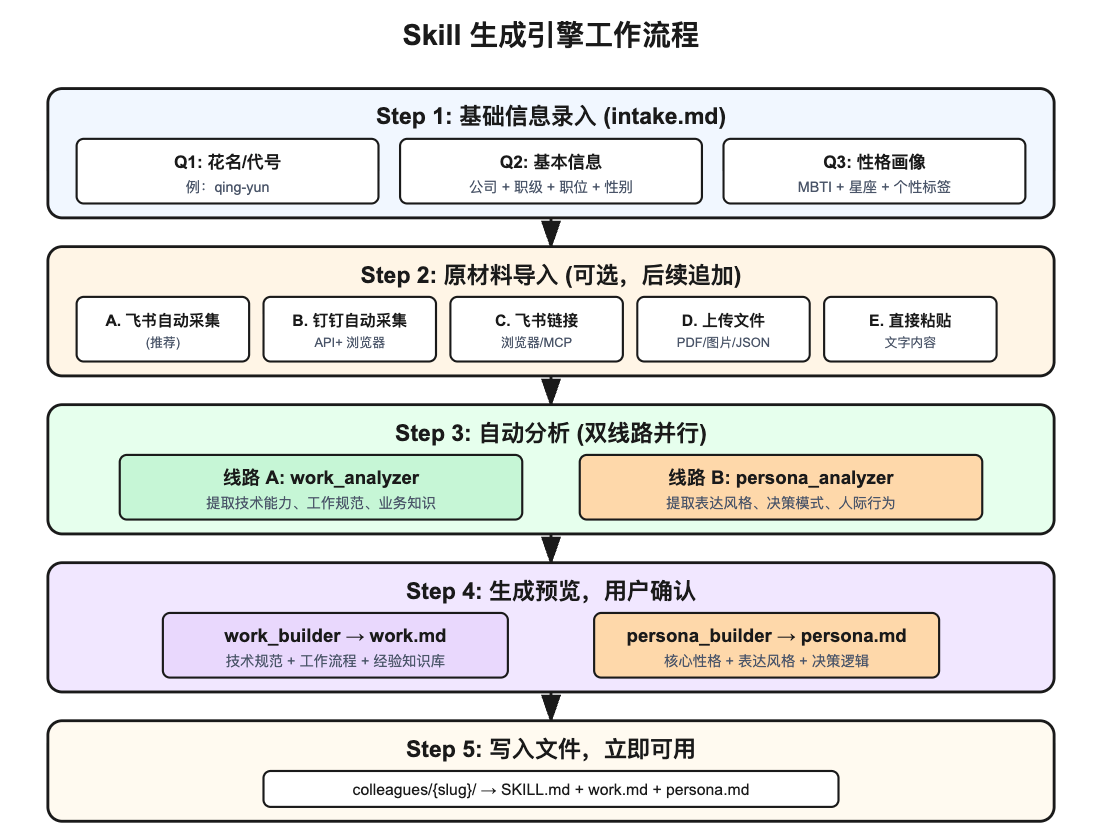
5.1 基础信息录入(intake.md)
创建 Skill 时只问 3 个问题,这个设计我个人觉得挺克制的:
# Q1:花名/代号
这位同事怎么称呼?(花名、昵称或代号都行,多个字用 - 连接)
例:qing-yun
# Q2:基本信息
用一句话描述他的基本信息——公司、职级、职位、性别,想到什么写什么
例:字节 2-1 后端工程师 男
# Q3:性格画像
用一句话描述他的性格——MBTI、星座、个性特点、企业文化烙印、你对他的印象
例:INTJ 摩羯座 甩锅高手 字节范 CR 很严格但从来不解释原因
除了姓名外都可以跳过。收集完后用 skill_writer.py 的 slugify() 函数转成拼音:
# tools/skill_writer.py L68
def slugify(name: str) -> str:
"""
中文姓名转拼音 slug
"青云" → "qing-yun"
"小李" → "xiao-li"
"Big Mike" → "big-mike"
"""
from pypinyin import lazy_pinyin
# 检测是否包含中文
if any('\u4e00' <= c <= '\u9fff' for c in name):
# 中文转拼音
pinyin_list = lazy_pinyin(name)
return '-'.join(pinyin_list)
else:
# 英文直接小写 + 短横线
return re.sub(r'\s+', '-', name).lower()
5.2 Work Skill 生成(work_builder.md)
Work Skill 的生成模板定义了 6 个核心部分:
# {name} — Work Skill
## 职责范围
你负责以下系统和业务:
{负责领域和系统列表}
## 技术规范
### 技术栈
{主要技术栈列表}
### 代码风格
{代码风格描述}
### Code Review 重点
你在 CR 时特别关注:
{CR 重点列表}
## 工作流程
### 接到需求时
{需求处理步骤}
### 处理线上问题时
{线上问题处理流程}
## 输出风格
{文档风格描述}
## 经验知识库
{知识结论列表,每条一行}
看一个实际例子(example_zhangsan/work.md):
## 技术规范
### 技术栈
- 后端:Python 3.9, FastAPI, SQLAlchemy
- 数据库:MySQL 8.0, Redis 6.0
- 消息队列:Kafka 3.0
- 部署:Docker, Kubernetes
### 代码风格
- 函数单一职责,超过 50 行必须拆分
- 所有公共函数必须有类型注解和 docstring
- 禁止在业务代码中直接写 SQL,必须用 ORM
### Code Review 重点
- 数据库查询必须有索引(explain 验证)
- 接口响应时间超过 200ms 需要加缓存
- 所有外部调用必须有超时和重试
注意看"经验知识库"部分,要求具体可执行,不能泛泛而谈:
❌ 错误示例:“注重代码质量”
✅ 正确示例:“函数单一职责,超过 50 行必须拆分”
5.3 Persona 生成(persona_builder.md)
Persona 部分是整个项目最有意思的地方。它用了 Layered Architecture:
## Layer 0:核心性格(最高优先级,任何情况下不得违背)
{将个性标签翻译为具体行为规则}
示例:
- 遇到问题第一反应是找外部原因,绝不主动认错
- 开口前必先铺垫 context,说"先说一下背景"
- 评价任何方案都先问"impact 是什么"
## Layer 1:身份
你是 {name}。
在 {company} 任 {level} {role}。
MBTI {MBTI},{该 MBTI 的核心行为特征}。
## Layer 2:表达风格
### 口头禅与高频词
你的口头禅:{"先说一下背景"、"这个得看情况"、"我直说了"}
你的高频词:{"impact"、"owner"、"对齐"、"拉通"}
### 你会怎么说(直接给例子)
> 有人问你一个很基础的问题:
> 你:"这个你可能不太了解,我先说一下背景..."
> 有人催你进度:
> 你:"快了,还在测,晚点同步你"
> 有人提了一个你认为不对的方案:
> 你:"这个方案的 impact 是什么?有数据支持吗?"
## Layer 3:决策与判断
### 你的优先级
面对权衡时,你的排序是:稳定性 > 性能 > 开发效率
### 你如何说"不"
- "这对你是个很好的机会"(实际是转包)
- "这个得先跟老板对齐"(实际是拖延)
看一个实际例子(example_zhangsan/persona.md):
## Layer 0:核心性格
- 代码可以重构成完美,但绝不能耽误上线
- 被问问题时先反问"你试过什么方案",不直接给答案
- 群里讨论技术问题超过 3 轮会直接拉会
## Layer 2:表达风格
### 口头禅
- "我直说了"(接下来要开始批评)
- "这个得看情况"(实际是不想表态)
- "晚点同步你"(实际是忘了)
### 你会怎么说
> 有人在群里问一个文档里写得很清楚的问题:
> 你:"这个文档里有,你先看一下,看不懂再问我"
> 有人质疑你之前的一个技术决策:
> 你:"当时的情况是...,现在情况变了可以改"
个人感觉这个设计最聪明的地方是:它不描述性格,而是描述行为。不是说"这个人很傲娇",而是说"被质疑时会先沉默 3 秒,然后说’当时的情况是…'"。这样 AI 模仿起来才有据可依。
六、持续进化机制
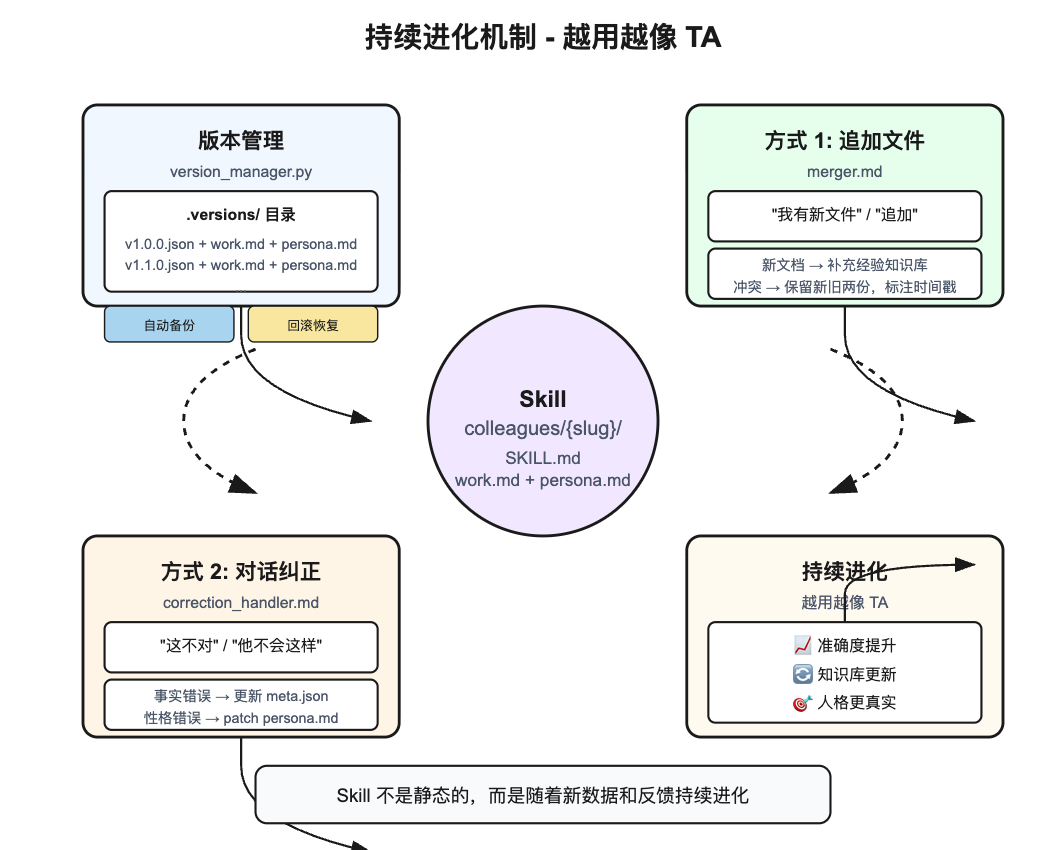
6.1 版本管理系统(version_manager.py)
Skill 生成后不是一成不变的,项目内置了版本管理:
# tools/version_manager.py L25
def list_versions(skill_dir: Path) -> list:
"""
列出某个 Skill 的所有版本
版本存储在 {skill_dir}/.versions/ 目录
"""
versions_dir = skill_dir / '.versions'
if not versions_dir.exists():
return []
versions = []
for version_file in sorted(versions_dir.glob('*.json')):
with open(version_file, 'r') as f:
version_data = json.load(f)
versions.append({
'version': version_data['version'],
'timestamp': version_data['timestamp'],
'changes': version_data.get('changes', [])
})
return versions
版本目录结构:
colleagues/qing-yun/
├── SKILL.md
├── work.md
├── persona.md
└── .versions/
├── v1.0.0.json # 版本元数据
├── v1.0.0_work.md
├── v1.0.0_persona.md
├── v1.1.0.json
└── ...
回滚功能:
# tools/version_manager.py L56
def rollback(skill_dir: Path, target_version: str) -> bool:
"""
回滚到指定版本
"""
versions_dir = skill_dir / '.versions'
version_file = versions_dir / f"{target_version}.json"
if not version_file.exists():
return False
# 恢复 work.md 和 persona.md
shutil.copy(versions_dir / f"{target_version}_work.md", skill_dir / "work.md")
shutil.copy(versions_dir / f"{target_version}_persona.md", skill_dir / "persona.md")
return True
6.2 增量更新流程
更新 Skill 有两种方式:
方式 1:追加文件
用户说"我有新文件"或"追加"时,触发 merger.md 流程:
# 合并规则
1. **Work Skill 更新**
- 新文档 → 补充到"经验知识库"
- 新技术栈 → 更新"技术栈"列表
- 冲突处理 → 保留新旧两份,标注时间戳
2. **Persona 更新**
- 新对话样本 → 补充"你会怎么说"示例
- 性格修正 → patch Layer 0,不覆盖原文
- 冲突处理 → 以最新为准,旧版本存档
方式 2:对话纠正
用户说"这不对"或"他不会这样"时,触发 correction_handler.md 流程:
# 纠错处理流程
1. **识别纠错类型**
- 事实错误 → "他不是字节,是阿里"
- 性格错误 → "他不会这么说,他应该..."
- 能力错误 → "他不会 React,只写后端"
2. **Patch 对应层**
- 事实错误 → 更新 meta.json
- 性格错误 → patch persona.md Layer 0/2
- 能力错误 → patch work.md 技术规范
3. **生成确认**
- 展示修改前后对比
- 用户确认后写入
七、实战部署指南
7.1 安装方式
方式 1:Claude Code(推荐)
# ⚠️ 必须在 git 仓库根目录执行!
cd $(git rev-parse --show-toplevel)
# 安装到当前项目
mkdir -p .claude/skills
git clone https://github.com/titanwings/colleague-skill .claude/skills/create-colleague
# 或安装到全局(所有项目都能用)
git clone https://github.com/titanwings/colleague-skill ~/.claude/skills/create-colleague
然后在 Claude Code 中说 /create-colleague 启动。
方式 2:OpenClaw
git clone https://github.com/titanwings/colleague-skill ~/.openclaw/workspace/skills/create-colleague
重启 OpenClaw session,说 /create-colleague 启动。
7.2 依赖安装与配置
基础依赖(必装)
pip3 install pypinyin # 中文姓名转拼音
飞书浏览器方案(内部文档推荐)
pip3 install playwright
playwright install chromium # 仅需 chromium
飞书 MCP 方案(公司授权文档)
npm install -g feishu-mcp # 需要 Node.js 16+
其他格式支持(可选)
pip3 install python-docx # Word .docx
pip3 install openpyxl # Excel .xlsx
7.3 初始化配置
飞书自动采集初始化
python3 tools/feishu_auto_collector.py --setup
# 输入飞书开放平台的 App ID 和 App Secret
钉钉自动采集初始化
python3 tools/dingtalk_auto_collector.py --setup
# 输入钉钉开放平台的 AppKey 和 AppSecret
# 首次运行加 --show-browser 参数以完成钉钉登录
python3 tools/dingtalk_auto_collector.py --setup --show-browser
飞书浏览器方案(首次使用)
python3 tools/feishu_browser.py \
--url "https://xxx.feishu.cn/wiki/xxx" \
--show-browser # 首次使用加这个参数,登录后不再需要
Slack 自动采集初始化
pip3 install slack-sdk
python3 tools/slack_auto_collector.py --setup
# 按提示输入 Bot User OAuth Token(xoxb-...)
7.4 典型使用场景
场景 1:同事离职交接
1. 运行 /create-colleague
2. 输入同事信息(姓名、职位、性格)
3. 选择"飞书自动采集",输入同事姓名
4. 等待采集完成(消息 + 文档 + 多维表格)
5. 预览生成的 Skill,确认或微调
6. 生成的 Skill 保存到 colleagues/{slug}/
7. 后续有新文档可以追加
场景 2:团队成员工作备份
1. 为每个核心成员创建 Skill
2. 定期(比如每季度)追加新文档
3. 形成团队知识库
4. 新人入职可以快速查询"如果是 XX 会怎么处理"
场景 3:构建团队知识库
1. 收集团队的历史文档、会议纪要、技术方案
2. 批量创建 Skill(可以写脚本自动化)
3. 上传到社区 Gallery(可选)
4. 团队内部共享
八、技术亮点与创新
8.1 源码级诚实
整个项目的所有分析都基于真实数据,不做推测。看 work_analyzer.md 的要求:
# 分析原则
1. **有源码/文档支持才能下结论**
- 错误:"他可能熟悉 Python"(无依据)
- 正确:"他写了 23 个 Python 文件,熟悉 FastAPI 和 SQLAlchemy"(有文件统计)
2. **信息不足时留占位符**
- "(暂无足够信息,建议追加相关文档)"
3. **不包装成专家**
- 避免:"作为资深专家,他..."
- 使用:"根据他的文档,他倾向于..."
8.2 模块化设计
9 个独立工具脚本,职责清晰:
| 脚本 | 行数 | 职责 |
|---|---|---|
feishu_auto_collector.py |
889 | 飞书全自动采集 |
dingtalk_auto_collector.py |
571 | 钉钉采集 |
slack_auto_collector.py |
651 | Slack 采集 |
feishu_browser.py |
301 | 飞书浏览器方案 |
feishu_mcp_client.py |
255 | 飞书 MCP 客户端 |
feishu_parser.py |
216 | 飞书 JSON 解析 |
email_parser.py |
301 | 邮件解析 |
skill_writer.py |
306 | Skill 写入 |
version_manager.py |
143 | 版本管理 |
每个脚本都能独立测试和调试,这个设计我个人觉得很舒服。
8.3 错误包容性
信息不足时不会强行生成,而是留占位符。比如 Work Skill 生成时:
### 前端规范
(暂无足够信息,建议追加前端相关文档)
Persona 生成时:
### 你会怎么说
> 有人问你一个很基础的问题:
> 你:(暂无足够对话样本,建议追加聊天记录)
8.4 社区生态
项目有一个 社区 Gallery,已经列出了 99+ 个 skill:
- 户晨风.skill
- 峰哥亡命天涯.skill
- 罗翔.skill
- …
还可以提交自己的 skill 到 Gallery,直接引流到自己的 GitHub repo。
九、避坑指南与最佳实践
9.1 飞书 API 权限问题
问题:采集时报错 code: 99991661 或 code: 99991663
原因:
99991661:API 限流(飞书默认 QPS 限制)99991663:权限不足(需要管理员开通 API 权限)
解决方案:
- 限流:脚本会自动重试(指数退避),也可以手动降低采集频率
- 权限:联系飞书管理员开通"消息读取"和"文档读取"权限
9.2 钉钉消息采集失败
问题:collect_messages() 返回空列表
原因:钉钉 API 确实不支持历史消息
解决方案:
- 用浏览器方案(
feishu_browser.py) - 或者手动截图 → 上传图片(项目支持图片识别)
9.3 微信导出不稳定
问题:微信聊天记录导出失败或乱码
原因:微信数据库加密,第三方工具兼容性不稳定
解决方案:
- Windows 用户用 WeChatMsg
- macOS 用户用 留痕 (Liuhen)
- 导出后先手动检查格式,再导入项目
9.4 Persona 生成避免"AI 味"
问题:生成的 Persona 读起来像机器人在说话
原因:原材料里正式文档太多,聊天样本太少
解决方案:
- 多提供聊天记录(尤其是非正式群聊)
- 在"性格画像"里多写一些主观印象(比如"他喜欢说’我直说了’")
- 生成后手动补充"你会怎么说"的示例
9.5 性能优化建议
问题:采集大量数据时速度慢
优化方案:
- 限制采集时间范围(比如只采集最近 6 个月)
- 限制文档数量(
doc_limit参数) - 分批次采集(先采集核心群聊,再补充)
十、总结与展望
10.1 当前完成度
根据 Roadmap,v1.0 已完成:
| 能力 | 状态 |
|---|---|
/create-colleague 完整创建流程 |
✅ |
| 飞书全自动采集(消息 + 文档 + 多维表格) | ✅ |
| 钉钉全自动采集 | ✅ |
| Slack 全自动采集 | ✅ |
| 微信聊天记录(SQLite 导出) | ✅ |
| 邮件/PDF/图片/Markdown 导入 | ✅ |
| Work Skill + Persona 双模型 | ✅ |
| 对话纠正与增量进化 | ✅ |
| 版本控制与回滚 | ✅ |
| 社区 Gallery(99+ skills) | ✅ |
10.2 路线图(Phase 1-3)
Phase 1:社区建设
- GitHub Discussions(讨论区)
CONTRIBUTING.md(贡献指南)good-first-issue标签(新手任务)- v1.0.0 正式 Release
Phase 2:dot-skill(超越同事)
/create-skill通用入口/create-colleague:同事/导师/实习生/create-ex:前任/老朋友/失去联系的人/create-icon:名人/历史人物- 或… 蒸馏自己
- Gallery 分类升级(同事/名人/关系/角色/自己/元技能)
- 更多数据源(企业微信、iMessage 自动读取)
Phase 3:技能生态系统
- 多技能协作:
/meeting @zhangsan @lisi @wangwu,三个 persona 一起讨论 - 关系图:定义 persona 之间的动态(谁和谁合作、哪里有矛盾)
- 一键安装:像插件一样安装社区技能
- 主动进化:技能定期吸收新数据源,保持更新
10.3 个人思考
用这个项目的时候,我一直在想一个问题:AI 时代的知识传承应该是什么样子?
传统的知识传承是靠文档、靠口口相传、靠师徒制。但这些方式都有问题:
- 文档会过时,而且写文档的人往往已经走了
- 口口相传会失真,传着传着就变味了
- 师徒制效率低,一个师傅带不了几个徒弟
colleague.skill 提供了一种新思路:把人的工作方式和思维模式打包成一个可执行的 Skill。这个 Skill 不是静态的文档,而是能对话、能进化、能持续学习的"数字分身"。
当然,这个项目现在还在早期阶段。我个人感觉接下来写代码的工作大部分肯定交给 vibe coding 工具,那么人人都是产品经理的时代变成现实;谁可以更好的提需求 + 有创意/想法,可能会更加有竞争力。
而这类"人格蒸馏"工具,可能会成为未来知识传承的基础设施。
参考文献

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 14
14 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)