
【AI应用开发】-Agent 思考时间那么长,怎么优化前端的用户体验?
摘要:本文探讨如何优化AI Agent长响应时间的前端用户体验。核心策略是通过透明化和可视化手段减轻用户等待焦虑,包括两种实现方案:1)Stream流式输出技术,让AI逐字显示响应内容;2)透明化思考过程,展示AI的"内心活动"。文章提供Python代码示例演示FastAPI实现流式输出的方法,并强调注意事项如缓冲区管理、错误处理等。这些优化让用户感知等待时间缩短,提升交互体验
Agent 思考时间那么长,怎么优化前端的用户体验?

文章目录
前言:让等待变成一种享受
既然不能让模型变快,就让用户觉得没那么慢。 —— 这句话简直是产品经理的至理名言,也是我们技术人必须面对的现实。
想象一下,你打开一个 AI 助手,输入了一个复杂的问题,然后…然后就盯着屏幕发呆。5 秒过去了,10 秒过去了,30 秒过去了…你开始怀疑:这玩意是不是卡死了?是不是我的网络挂了?还是这个 AI 正在偷偷嘲笑我的问题太蠢?
这种等待焦虑,简直比等外卖小哥打电话还让人抓狂!今天咱们就来聊聊,当你的 Agent 思考时间比思考人生还长的时候,怎么通过前端优化,让用户感觉"哎呀,好像也没那么慢嘛"!

一、核心策略:透明化 + 可视化
在深入技术细节之前,我们先来理解一下为什么长时间等待会让用户体验变得这么糟糕:
- 不可见的焦虑:用户看不到 AI 在做什么,就会怀疑是否在正常工作
- 缺乏反馈:没有进度提示,用户感觉自己的请求被"扔进了黑洞"
- 认知失调:现代互联网的"即时响应"习惯,让几秒钟的等待都觉得漫长
所以,我们的核心策略就是:把 Agent 的思考过程透明化,让用户看到 AI 正在"忙碌"。就像你在餐厅点菜,如果厨师让你看到后厨正在热火朝天地准备,你就不会觉得等待时间漫长。

二、实现方案一:Stream 流式输出
2.1 专业解释
Stream 流式输出(Streaming Output)是一种数据传输方式,服务器在生成内容的同时,将已生成的内容实时推送到客户端,而不是等待所有内容生成完毕后再一次性返回。在 LLM 应用中,这通常通过 **SSE(Server-Sent Events)**技术实现。
SSE 是一种基于 HTTP 的服务器推送技术,允许服务器向客户端单向发送事件流。与 WebSocket 不同,SSE 是单向通信(服务器 → 客户端),更适合这种"服务器持续生成内容并推送到客户端"的场景。
2.2 大白话解读
想象一下你在看直播:
- 传统方式:主播录完整个视频,你才能开始看(这叫"非流式")
- 流式输出:主播一边直播,你一边观看,内容实时到达
在我们的 Agent 场景中,就是 LLM 每生成一个字,前端就立刻显示一个字,而不是等 LLM 把整个回复都写完了再一次性显示出来。这样用户就能看到内容在"生长",感觉自己好像在参与创造过程!
2.3 生活案例
这就像你和朋友聊天:
- 传统方式:你朋友想好了整个回复,然后一口气说完(但你可能觉得他好半天不说话,是不是不想理你)
- 流式输出:你朋友边想边说,虽然语速慢点,但你能感受到他在认真思考并回应你
或者更形象的比喻:就像打字机效果,你看旧电影里那种打字机,字是一个一个蹦出来的,虽然总时间可能一样长,但那种"正在输入"的感觉,让你不会觉得机器卡死了。
2.4 Python 代码实现
下面是一个使用 FastAPI 和 SSE 实现流式输出的完整示例:
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import asyncio
import json
app = FastAPI()
async def generate_llm_response(prompt: str):
"""
模拟LLM流式生成响应
在实际应用中,这里会调用真实的LLM API(如OpenAI、Claude等)
"""
# 模拟的响应内容
response_text = f"针对您的问题'{prompt}',我需要思考一下...\n"
response_text += "首先,让我分析一下问题的核心...\n"
response_text += "然后,我会从多个角度进行考虑...\n"
response_text += "最后,给您一个综合性的建议。\n"
# 模拟逐字生成(实际中这里是真正的LLM流式输出)
for char in response_text:
yield char
await asyncio.sleep(0.05) # 模拟生成每个字的时间间隔
@app.post("/chat")
async def chat_endpoint(prompt: str):
"""
流式聊天接口
"""
async def event_stream():
try:
async for chunk in generate_llm_response(prompt):
# 将每个字符作为SSE事件发送
data = {
"type": "content",
"content": chunk,
"finished": False
}
yield f"data: {json.dumps(data)}\n\n"
# 发送完成信号
finish_data = {
"type": "finish",
"content": "",
"finished": True
}
yield f"data: {json.dumps(finish_data)}\n\n"
except Exception as e:
# 错误处理
error_data = {
"type": "error",
"content": str(e),
"finished": True
}
yield f"data: {json.dumps(error_data)}\n\n"
return StreamingResponse(
event_stream(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"X-Accel-Buffering": "no" # 禁用Nginx缓冲
}
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
前端 JavaScript 代码示例:
async function streamChat(prompt) {
const response = await fetch('/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ prompt })
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
let fullContent = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
const lines = chunk.split('\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6));
if (data.type === 'content') {
// 实时显示内容
fullContent += data.content;
updateChatDisplay(fullContent);
} else if (data.type === 'finish') {
console.log('流式输出完成');
} else if (data.type === 'error') {
console.error('错误:', data.content);
}
}
}
}
}
function updateChatDisplay(content) {
// 更新聊天界面显示
const chatContainer = document.getElementById('chat-container');
chatContainer.innerHTML = content;
}
2.5 注意事项
⚠️ 重要提醒:
- 缓冲区问题:很多服务器(如 Nginx)默认会缓冲输出,需要配置禁用缓冲
- 连接超时:长时间连接可能被防火墙或负载均衡器断开,需要设置合理的超时时间
- 错误处理:流式连接中断时,需要有优雅的降级处理机制
- 性能考虑:频繁的小数据包传输会增加服务器负载,需要权衡
三、实现方案二:透明化思考过程
3.1 专业解释
透明化思考(Transparent Reasoning)是指在 Agent 执行复杂任务时,将内部的处理步骤、工具调用状态、中间结果等信息实时展示给用户。这通常通过在界面上显示"思考气泡"(Thinking Bubbles)或"状态指示器"(Status Indicators)来实现。
这种设计模式遵循了**认知心理学中的"等待感知优化"**原理:当用户能够感知到系统的处理进度时,主观等待时间会显著缩短。这也是为什么电梯里要装镜子(分散注意力)、下载软件要显示进度条的原因。
3.2 大白话解读
简单来说,就是让用户看到 AI 在"干什么",而不是让他对着空白屏幕发呆。
比如你问 Agent:“帮我分析一下 2024 年特斯拉的财报”
- 不透明:屏幕一片空白,你等了 30 秒,AI 突然给出一个完整答案
- 透明化:屏幕上依次弹出小气泡:
- “正在检索特斯拉 2024 年 Q3 财报…”
- “正在对比去年同期数据…”
- “正在计算增长率…”
- “正在生成分析报告…”
这样你就知道 AI 没偷懒,它真的在努力工作!
3.3 生活案例
这就像你在银行办理业务:
- 不透明:你坐在大厅里等,完全不知道柜台里在干嘛,只能干着急
- 透明化:屏幕显示"正在为您办理业务:身份验证 → 风险评估 → 账户查询 → 资金划转",你看着进度条,心里就有底了
或者像手机安装应用时的进度条:“正在解压资源包 → 正在配置系统 → 正在优化性能”,虽然总时间可能差不多,但你感觉快多了!

3.4 Python 代码实现
下面是一个实现透明化思考的完整示例:
from fastapi import FastAPI, WebSocket
from fastapi.responses import HTMLResponse
import asyncio
import json
from datetime import datetime
app = FastAPI()
class AgentTool:
"""
模拟Agent的工具调用
"""
@staticmethod
async def search_financial_report(company: str, year: str, quarter: str):
"""搜索财报数据"""
await asyncio.sleep(2) # 模拟耗时操作
return {
"company": company,
"year": year,
"quarter": quarter,
"revenue": "245亿美元",
"growth": "+15%"
}
@staticmethod
async def compare_with_last_year(data: dict):
"""与去年同期对比"""
await asyncio.sleep(1.5)
return {
"last_year_revenue": "213亿美元",
"growth_comparison": "增长15%"
}
@staticmethod
async def generate_analysis(data: dict):
"""生成分析报告"""
await asyncio.sleep(3)
return "特斯拉2024年Q3表现强劲,营收同比增长15%..."
async def execute_agent_task(websocket: WebSocket, prompt: str):
"""
执行Agent任务并实时反馈状态
"""
await websocket.send_json({
"type": "status",
"message": "正在分析您的问题...",
"timestamp": datetime.now().isoformat()
})
# 步骤1:检索财报数据
await websocket.send_json({
"type": "thinking",
"message": f"🔍 正在检索特斯拉2024年Q3财报...",
"timestamp": datetime.now().isoformat()
})
financial_data = await AgentTool.search_financial_report(
"特斯拉", "2024", "Q3"
)
# 步骤2:对比数据
await websocket.send_json({
"type": "thinking",
"message": "📊 正在对比去年同期数据...",
"timestamp": datetime.now().isoformat()
})
comparison_result = await AgentTool.compare_with_last_year(financial_data)
# 步骤3:生成分析
await websocket.send_json({
"type": "thinking",
"message": "✍️ 正在生成分析报告...",
"timestamp": datetime.now().isoformat()
})
final_answer = await AgentTool.generate_analysis({
"financial_data": financial_data,
"comparison": comparison_result
})
# 返回最终结果
await websocket.send_json({
"type": "result",
"message": final_answer,
"timestamp": datetime.now().isoformat()
})
@app.get("/")
async def get_chat_page():
"""返回聊天页面"""
html_content = """
<!DOCTYPE html>
<html>
<head>
<title>Agent透明化思考示例</title>
<style>
.thinking-bubble {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
color: white;
padding: 10px 15px;
border-radius: 20px;
margin: 5px 0;
max-width: 80%;
animation: fadeIn 0.5s;
font-size: 14px;
}
@keyframes fadeIn {
from { opacity: 0; transform: translateY(10px); }
to { opacity: 1; transform: translateY(0); }
}
.status-message {
color: #888;
font-style: italic;
margin: 5px 0;
}
.final-result {
background: #f0f0f0;
padding: 15px;
border-radius: 10px;
margin: 10px 0;
border-left: 4px solid #667eea;
}
</style>
</head>
<body>
<h2>Agent透明化思考示例</h2>
<input type="text" id="prompt" placeholder="输入问题(如:分析特斯拉财报)"
style="width: 300px; padding: 8px;">
<button onclick="sendQuestion()" style="padding: 8px 15px;">提问</button>
<div id="messages" style="margin-top: 20px; border: 1px solid #ddd;
padding: 15px; min-height: 200px; border-radius: 10px;">
</div>
<script>
let ws = null;
function sendQuestion() {
const prompt = document.getElementById('prompt').value;
if (!prompt) return;
const messagesDiv = document.getElementById('messages');
messagesDiv.innerHTML = ''; // 清空之前的内容
// 建立WebSocket连接
ws = new WebSocket(`ws://${window.location.host}/ws/agent?prompt=${encodeURIComponent(prompt)}`);
ws.onmessage = function(event) {
const data = JSON.parse(event.data);
const messagesDiv = document.getElementById('messages');
if (data.type === 'status') {
// 显示状态消息
messagesDiv.innerHTML +=
`<div class="status-message">ℹ️ ${data.message}</div>`;
} else if (data.type === 'thinking') {
// 显示思考气泡
messagesDiv.innerHTML +=
`<div class="thinking-bubble">${data.message}</div>`;
// 自动滚动到底部
messagesDiv.scrollTop = messagesDiv.scrollHeight;
} else if (data.type === 'result') {
// 显示最终结果
messagesDiv.innerHTML +=
`<div class="final-result"><strong>📝 分析结果:</strong><br>${data.message}</div>`;
}
messagesDiv.scrollTop = messagesDiv.scrollHeight;
};
ws.onerror = function(error) {
console.error('WebSocket错误:', error);
};
ws.onclose = function() {
console.log('WebSocket连接关闭');
};
}
</script>
</body>
</html>
"""
return HTMLResponse(content=html_content)
@app.websocket("/ws/agent")
async def websocket_agent(websocket: WebSocket, prompt: str):
"""WebSocket端点,用于实时通信"""
await websocket.accept()
try:
await execute_agent_task(websocket, prompt)
except Exception as e:
await websocket.send_json({
"type": "error",
"message": f"执行出错: {str(e)}"
})
finally:
await websocket.close()
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
3.5 思考气泡的设计原则
🎨 设计要点:
- 简洁明了:每个状态用一句话描述,不要写太长
- 视觉区分:使用不同的颜色或图标区分不同类型的状态
- 合理频率:不要更新太快(用户看不清),也不要太慢(用户觉得卡住)
- 可关闭性:提供让用户关闭思考气泡显示的选项
- 错误透明:如果某步骤失败,也要诚实地告诉用户
四、技术架构对比
下面我们来对比一下几种不同的实现方案:
| 方案 | 技术复杂度 | 用户体验 | 适用场景 | 实时性 |
|---|---|---|---|---|
| 传统 HTTP 请求 | ⭐ | ⭐ | 简单查询、快速响应 | 低 |
| SSE 流式输出 | ⭐⭐ | ⭐⭐⭐ | LLM 生成内容、长文本输出 | 高 |
| WebSocket 透明化 | ⭐⭐⭐ | ⭐⭐⭐⭐ | 复杂 Agent 任务、多步骤处理 | 极高 |
| 混合模式 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 最优用户体验场景 | 极高 |
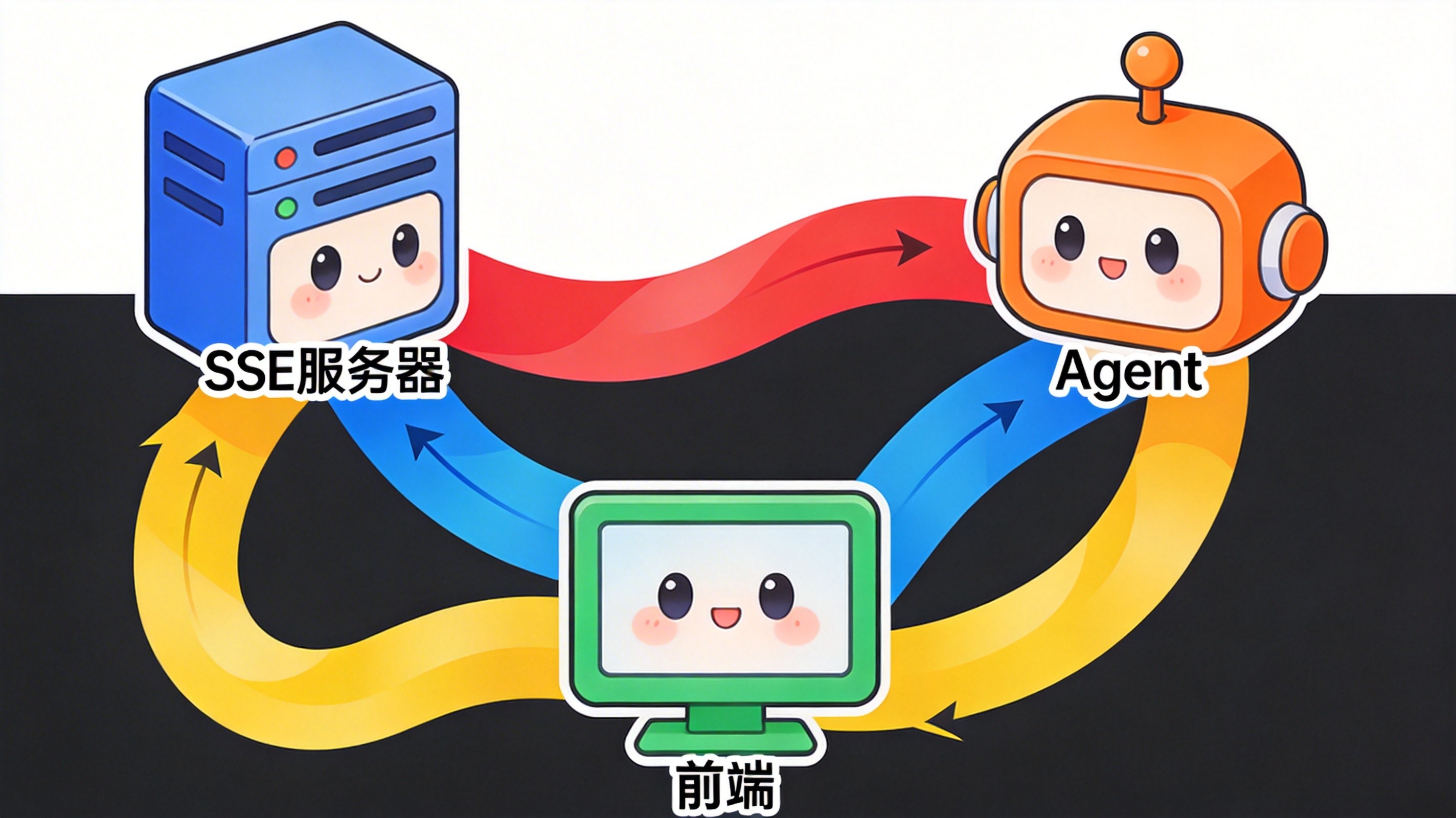
4.1 混合模式(最佳实践)
在实际项目中,我推荐使用混合模式:
- SSE 处理文本生成:用于 LLM 的流式文本输出
- WebSocket 处理状态更新:用于显示 Agent 的工具调用状态
- 心跳检测:确保连接稳定性
- 降级方案:当 WebSocket 不可用时,降级到 HTTP 轮询
# 混合模式的架构示例
class HybridAgentServer:
"""
混合模式Agent服务器
结合了SSE和WebSocket的优势
"""
def __init__(self):
self.active_connections = {}
async def handle_streaming_response(self, prompt: str):
"""处理流式响应(SSE)"""
async for chunk in self.llm_generate(prompt):
yield chunk
async def handle_status_updates(self, websocket: WebSocket, task_id: str):
"""处理状态更新(WebSocket)"""
while True:
status = await self.get_task_status(task_id)
await websocket.send_json(status)
await asyncio.sleep(0.5) # 每0.5秒更新一次状态
五、性能优化技巧
5.1 减少不必要的渲染
// ❌ 错误做法:每次更新都重新渲染整个列表
function updateChatList(newMessage) {
const chatList = document.getElementById('chat-list');
chatList.innerHTML = ''; // 清空整个列表
allMessages.forEach(msg => {
chatList.innerHTML += createMessageHTML(msg);
});
}
// ✅ 正确做法:只追加新消息
function appendNewMessage(newMessage) {
const chatList = document.getElementById('chat-list');
const messageElement = createMessageElement(newMessage);
chatList.appendChild(messageElement);
}
5.2 使用虚拟滚动
当消息很多时,使用虚拟滚动可以显著提升性能:
import { FixedSizeList as List } from 'react-window';
const MessageList = ({ messages }) => (
<List
height={600}
itemCount={messages.length}
itemSize={100}
width="100%"
>
{({ index, style }) => (
<div style={style}>
{messages[index].content}
</div>
)}
</List>
);
5.3 节流和防抖
// 节流:限制函数执行频率
function throttle(func, limit) {
let inThrottle;
return function(...args) {
if (!inThrottle) {
func.apply(this, args);
inThrottle = true;
setTimeout(() => inThrottle = false, limit);
}
};
}
// 使用示例:限制滚动事件的触发频率
window.addEventListener('scroll', throttle(() => {
checkIfNeedLoadMore();
}, 200));
六、常见问题与解决方案
Q1: SSE 连接断开怎么办?
解决方案: 实现自动重连机制
class SSEManager {
constructor(url) {
this.url = url;
this.eventSource = null;
this.reconnectAttempts = 0;
this.maxReconnectAttempts = 5;
}
connect() {
this.eventSource = new EventSource(this.url);
this.eventSource.onopen = () => {
console.log('SSE连接成功');
this.reconnectAttempts = 0;
};
this.eventSource.onerror = () => {
console.error('SSE连接错误');
this.eventSource.close();
if (this.reconnectAttempts < this.maxReconnectAttempts) {
setTimeout(() => {
this.reconnectAttempts++;
this.connect();
}, 1000 * Math.pow(2, this.reconnectAttempts)); // 指数退避
}
};
}
}
Q2: 如何处理长时间任务的超时问题?
解决方案: 使用心跳机制和任务队列
import asyncio
class LongRunningTask:
def __init__(self, task_id, timeout=300):
self.task_id = task_id
self.timeout = timeout
self.last_heartbeat = asyncio.get_event_loop().time()
async def check_timeout(self):
"""检查任务是否超时"""
current_time = asyncio.get_event_loop().time()
if current_time - self.last_heartbeat > self.timeout:
raise TimeoutError("任务执行超时")
async def send_heartbeat(self):
"""发送心跳"""
self.last_heartbeat = asyncio.get_event_loop().time()
Q3: 如何优化移动端的性能?
解决方案:
- 减少 DOM 操作频率
- 使用 CSS 动画替代 JavaScript 动画
- 实现懒加载
- 压缩和优化图片资源
七、总结
通过本文的学习,我们掌握了两种核心的前端优化策略:
- Stream 流式输出:让用户实时看到 AI 生成的内容,消除"空白等待"的焦虑
- 透明化思考:展示 Agent 的处理步骤,让用户感知到系统正在工作
关键要点回顾:
- ✅ 可见性缓解等待焦虑:让用户看到 Agent 真的在干活,而不是卡死
- ✅ 技术选型:简单场景用 SSE,复杂场景用 WebSocket,最佳实践是混合模式
- ✅ 性能优化:减少不必要的渲染,使用虚拟滚动,实现节流防抖
- ✅ 错误处理:实现自动重连、超时检测、降级方案
💡 最后的思考:
前端优化不仅仅是技术问题,更是用户体验的心理学问题。当我们无法改变模型的速度时,我们就改变用户对速度的感知。这就像生活中的很多事情一样:有时候问题本身无法解决,但我们可以改变面对问题的方式。
🚀 现在就开始实践吧!
选择一个你正在开发的 Agent 应用,尝试添加流式输出和透明化思考功能,看看用户的反馈如何。相信我,这小小的改动,会带来大大的惊喜!
📝 互动与讨论
💬 你在实际项目中遇到过哪些前端优化的挑战?
- 你的 Agent 响应时间最长是多少?你是怎么优化的?
- 除了流式输出和透明化思考,你还用过哪些用户体验优化技巧?
- 在移动端实现这些功能时,遇到了什么坑?
欢迎在评论区分享你的经验和想法,让我们一起探讨如何打造更好的 AI 应用体验!
📄 转载声明
本文为原创技术文章,欢迎转载,但请注明!
- 转载请保留文章完整性,不得删改核心内容
🔗 参考链接
- Server-Sent Events (SSE) - MDN Web Docs
- FastAPI 官方文档 - WebSockets
- WebSocket API - MDN Web Docs
- React Window - 虚拟滚动库
- 前端性能优化最佳实践
记得点赞关注,获取更多 Agent 开发干货! 🌟

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)