
数仓 + Claude Code Skill 的方式实现统计分析 Agent 化
本文提出了一种基于自然语言处理的统计分析Agent化方案,通过Claude Code Skill实现评测项目指标的自动化查询。
·
一、背景与目标
1.1 背景
当前评测项目的统计需求(产能、质量等指标)如果以传统方式实现,每新增一个指标都需要后端写接口、前端写页面、联调上线,周期长、灵活性差。
1.2 目标
通过 数仓 + Claude Code Skill 的方式实现统计分析 Agent 化:
- 用户在 Claude Code 中用自然语言描述统计需求
- Skill 理解需求,自动生成 SQL 查询数仓
- 查询结果直接在终端中展示
- 新增/变更指标零开发成本,只需调整 Skill 或数仓 ETL
1.3 核心理念
传统方式:需求 → 后端开发 → 前端开发 → 联调 → 上线
Agent方式:需求(自然语言)→ Claude Skill 生成 SQL → 查询数仓 → 终端展示结果
二、整体架构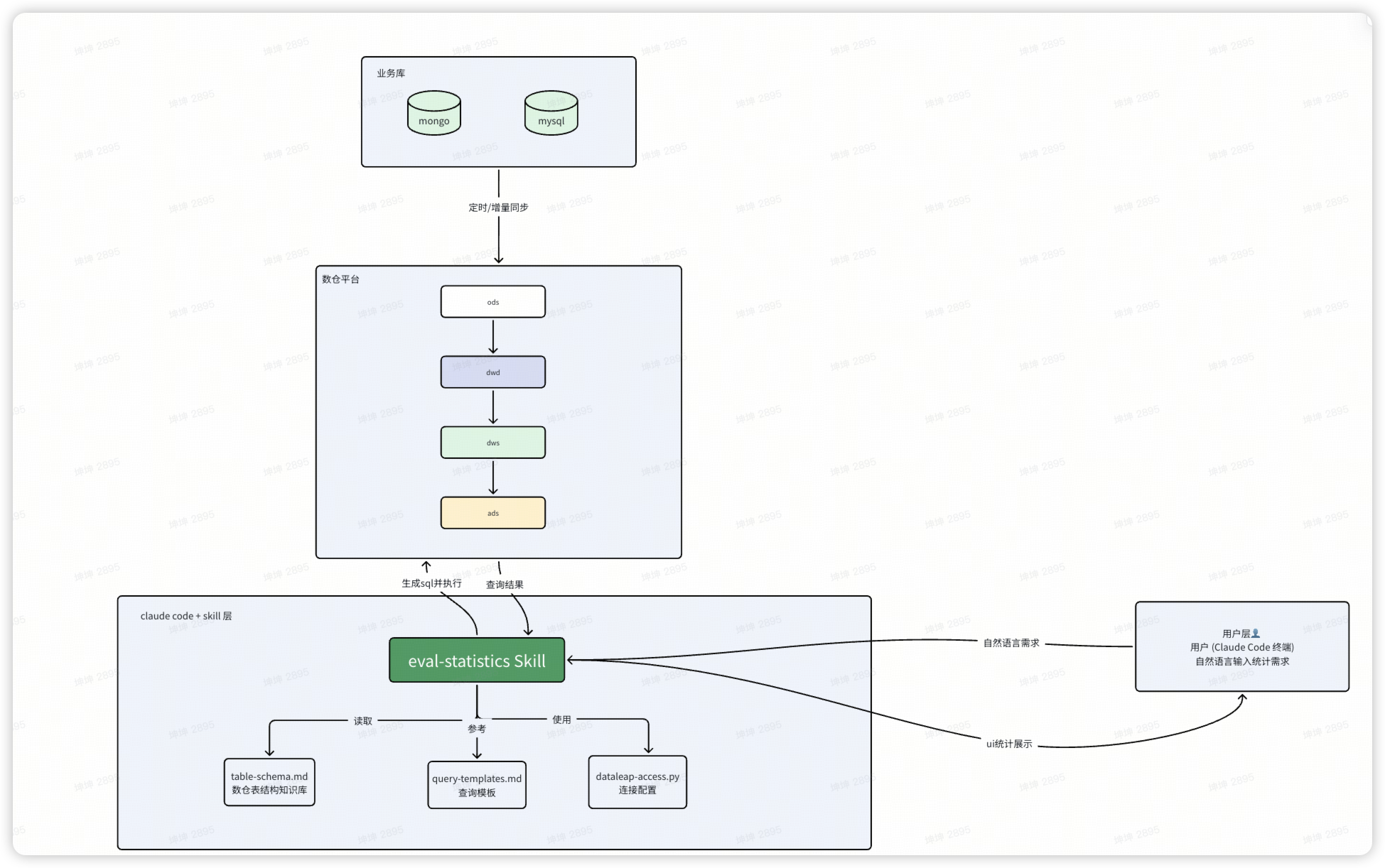
三 、执行流程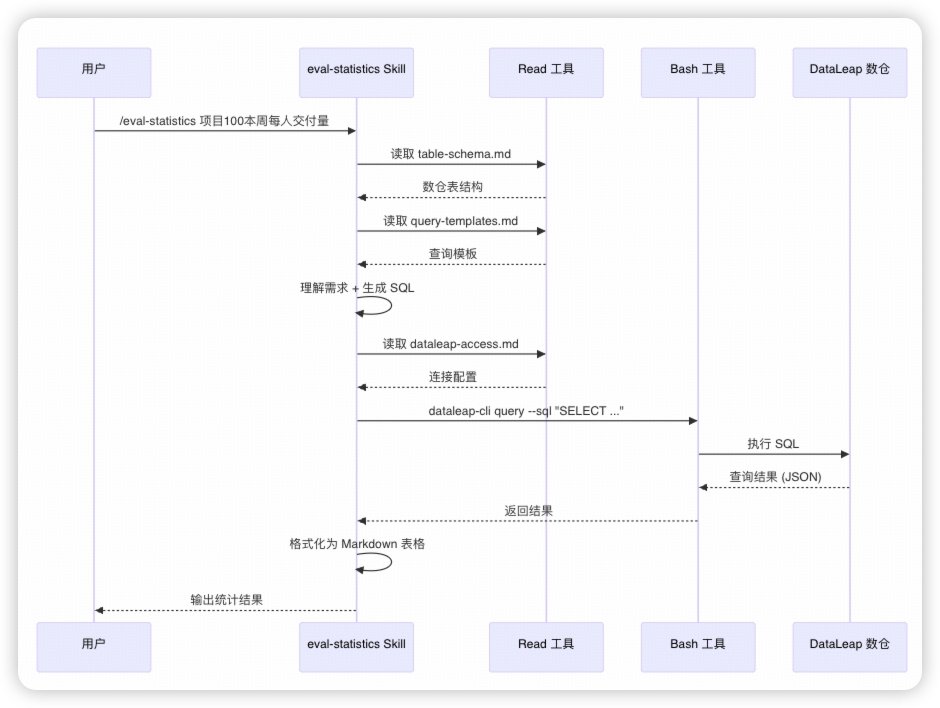
四、Skill 设计(简单举例)
4.1 Skill 的定位
Skill 是 Claude Code 中的一个指令(/eval-statistics),用户通过自然语言描述统计需求,Skill 自动完成:
用户: /eval-statistics 查看项目100本周每个人的交付量
↓
Skill: 读取表结构 → 生成 SQL → 执行查询 → 格式化输出
↓
终端输出:
| 评测员 | 数据交付量 | 实际提交次数 |
|--------|-----------|------------|
| 张三 | 120 | 150 |
| 李四 | 98 | 110 |
4.2 Skill 目录结构
.claude/skills/eval-statistics/
├── SKILL.md # Skill 入口:执行流程定义
├── table-schema.md # 数仓表结构(Skill 的知识库)
├── query-templates.md # 常见查询模板与示例
└── dataleap-access.md # DataLeap 连接配置与 CLI 用法
4.3 SKILL.md(入口文件)
---
disable-model-invocation: false
---
# eval-statistics: 评测项目统计分析
当用户需要查询评测项目的统计数据(产能、质量等)时使用。
## 执行流程
### 第一步:理解用户需求
从用户的自然语言中提取:
- **项目 ID**:必须,哪个评测项目
- **时间范围**:可选,默认近 7 天
- **指标类型**:数据交付量 / 实际提交次数 / 人员交付量 / 自定义
- **人员筛选**:可选,默认全部人员
如果信息不完整,使用 AskUserQuestion 询问缺失参数。
### 第二步:生成 SQL
1. 读取 `table-schema.md` 了解可用的数仓表和字段
2. 参考 `query-templates.md` 中的查询模板
3. 根据用户需求组合生成 SQL
### 第三步:执行查询
读取 `dataleap-access.md` 获取连接信息,使用 Bash 工具执行:
方式一:DataLeap CLI
bash: dataleap-cli query --sql "SELECT ..." --format json
方式二:DataLeap REST API
bash: curl -X POST https://dataleap.xxx.com/api/v1/query \
-H "Authorization: Bearer $DATALEAP_TOKEN" \
-d '{"sql": "SELECT ..."}'
### 第四步:格式化输出
将查询结果以 Markdown 表格形式展示给用户:
- 单值指标(如交付量总数)→ 直接输出数字
- 列表数据(如人员交付量)→ Markdown 表格
- 趋势数据(如每日交付量)→ 按日期排列的表格
4.4 table-schema.md(知识库)
# 数仓表结构
以下是可用于统计查询的数仓表。生成 SQL 时必须参考此文件。
## DWS 层(推荐优先使用,已聚合)
### dws_eval_daily_delivery(项目每日交付汇总)
- 用途:统计数据交付量
- 分区:dt (日期)
| 字段 | 类型 | 说明 |
|------|------|------|
| project_id | BIGINT | 项目 ID |
| label_user | STRING | 评测员邮箱 |
| delivery_count | INT | 当日交付量 |
| dt | STRING | 日期分区 (yyyy-MM-dd) |
### dws_eval_user_submit_daily(用户每日提交汇总)
- 用途:统计实际提交次数
- 分区:dt (日期)
| 字段 | 类型 | 说明 |
|------|------|------|
| project_id | BIGINT | 项目 ID |
| user_email | STRING | 操作人邮箱 |
| submit_count | INT | 当日提交次数 |
| dt | STRING | 日期分区 (yyyy-MM-dd) |
## DWD 层(明细数据,需要时使用)
### dwd_eval_submit_detail(提交明细)
| 字段 | 类型 | 说明 |
|------|------|------|
| project_id | BIGINT | 项目 ID |
| task_id | BIGINT | 任务 ID |
| user_email | STRING | 操作人邮箱 |
| node_type | INT | 节点:1=评测, 3=修改 |
| operate_type | INT | 操作:1=提交, 5=修改后提交 |
| submit_time | TIMESTAMP | 提交时间 |
| dt | STRING | 日期分区 |
### dwd_eval_delivery_detail(交付明细)
| 字段 | 类型 | 说明 |
|------|------|------|
| project_id | BIGINT | 项目 ID |
| task_id | BIGINT | 任务 ID |
| label_user | STRING | 评测员邮箱 |
| finish_time | TIMESTAMP | 完成时间 |
| dt | STRING | 日期分区 |
## 业务含义说明
- 数据交付量:任务最终完成(status=3)的数量,按 finish_time 归属日期
- 实际提交次数:评测/修改节点的所有提交记录,含被驳回后重新提交
- 一个任务被驳回后重新提交,交付量 +0(还没完成),提交次数 +1
4.5 query-templates.md(查询模板)
# 常见查询模板
## 1. 数据交付量(项目汇总)
SELECT SUM(delivery_count) AS total_delivery
FROM dws_eval_daily_delivery
WHERE project_id = {project_id}
AND dt BETWEEN '{start_date}' AND '{end_date}';
## 2. 实际提交次数(项目汇总)
SELECT SUM(submit_count) AS total_submit
FROM dws_eval_user_submit_daily
WHERE project_id = {project_id}
AND dt BETWEEN '{start_date}' AND '{end_date}';
## 3. 人员交付量(按人员聚合)
SELECT
COALESCE(d.label_user, s.user_email) AS user_email,
COALESCE(SUM(d.delivery_count), 0) AS delivery_count,
COALESCE(SUM(s.submit_count), 0) AS submit_count
FROM dws_eval_daily_delivery d
FULL OUTER JOIN dws_eval_user_submit_daily s
ON d.project_id = s.project_id
AND d.label_user = s.user_email
AND d.dt = s.dt
WHERE COALESCE(d.project_id, s.project_id) = {project_id}
AND COALESCE(d.dt, s.dt) BETWEEN '{start_date}' AND '{end_date}'
GROUP BY COALESCE(d.label_user, s.user_email)
HAVING delivery_count > 0 OR submit_count > 0
ORDER BY delivery_count DESC;
## 4. 每日交付趋势
SELECT dt, SUM(delivery_count) AS daily_delivery
FROM dws_eval_daily_delivery
WHERE project_id = {project_id}
AND dt BETWEEN '{start_date}' AND '{end_date}'
GROUP BY dt
ORDER BY dt;
## 5. 某人的提交明细(需要下钻时用 DWD 层)
SELECT task_id, node_type, operate_type, submit_time
FROM dwd_eval_submit_detail
WHERE project_id = {project_id}
AND user_email = '{user_email}'
AND dt BETWEEN '{start_date}' AND '{end_date}'
ORDER BY submit_time DESC;
五、使用场景示例
场景 1:查看项目整体产能
用户: /eval-statistics 项目100 本月的数据交付量和提交次数
Claude 输出:
项目 100 (2026-02-01 ~ 2026-02-26) 评测产能:
| 指标 | 数值 |
|-------------|-------|
| 数据交付量 | 2,525 |
| 实际提交次数 | 3,000 |
场景 2:查看人员交付量
用户: /eval-statistics 项目100 每个人的交付量
Claude 输出:
项目 100 人员交付量 (2026-02-20 ~ 2026-02-26):
| 评测员 | 数据交付量 | 实际提交次数 |
|--------------------|-----------|------------|
| zhangsan@xx.com | 120 | 150 |
| lisi@xx.com | 98 | 110 |
| wangwu@xx.com | 85 | 95 |
场景 3:自由提问(Skill 动态生成 SQL)
用户: /eval-statistics 项目100 上周哪天交付量最高?
Claude:
读取 table-schema.md → 生成 SQL:
SELECT dt, SUM(delivery_count) AS daily_delivery
FROM dws_eval_daily_delivery
WHERE project_id = 100 AND dt BETWEEN '2026-02-17' AND '2026-02-23'
GROUP BY dt ORDER BY daily_delivery DESC LIMIT 1
执行查询 → 输出:
上周交付量最高的是 2026-02-19(周四),共交付 186 条数据。
场景 4:下钻到个人明细
用户: /eval-statistics 张三在项目100上周的提交明细
Claude:
生成 SQL 查 DWD 明细层 → 输出:
zhangsan@xx.com 项目100 提交明细 (2026-02-17 ~ 2026-02-23):
| 任务ID | 节点 | 操作 | 提交时间 |
|--------|--------|-----------|---------------------|
| 1001 | 评测 | 提交 | 2026-02-17 14:30:00 |
| 1001 | 修改 | 修改后提交 | 2026-02-18 10:15:00 |
| 1005 | 评测 | 提交 | 2026-02-19 09:22:00 |
六、方案优势
| 维度 | 传统方式 | 数仓 + Skill 方式 |
|---|---|---|
| 新增指标 | 后端 + 前端 + 联调上线 | 改 Skill 模板或 ETL,零代码 |
| 使用方式 | 登录平台、点击页面 | 终端自然语言提问 |
| 灵活性 | 固定指标、固定图表 | 任意维度、任意组合、支持下钻 |
| 查询性能 | 查业务库,影响线上 | 查数仓,完全隔离 |
| 数据口径 | 各接口各自实现 | ETL 统一加工,口径一致 |
| 历史数据 | 业务库可能清理 | 数仓保留全量 |
| 开发成本 | 每个需求都要开发 | 一次搭建,持续复用 |

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)