
重新定义AI Agent的记忆:超越向量数据库与长上下文
AI Agent的记忆不应简化为向量数据库或长上下文窗口,而应视为其持续学习、演化和保持一致性的核心机制。记忆分为基础记忆(存储历史交互)和高级记忆(从经验中学习改进),需区分Agent Memory(认知状态)、LLM Memory(序列处理)、RAG(静态知识)和Context Engineering(当前交互优化)。设计记忆系统需明确需求层次,结合短期/长期存储,区分静态知识与动态经验,并关
重新定义AI Agent的记忆:超越向量数据库与长上下文
在构建AI Agent(智能体)的工程实践中,“记忆”是一个高频词汇,却也是最容易被简化的概念之一。很多开发者会下意识地将记忆等同于“向量数据库+相似度检索”,或是“更长的上下文窗口(KV cache)”。似乎只要模型能够“看到”过去的信息,系统就具备了记忆能力。然而,这种理解忽略了记忆在智能体系统中的本质作用——它不仅仅是信息的存储,更是智能体持续学习、演化、保持身份一致性的核心机制。
本文将通过剖析“上下文工程”的完整图景,厘清Agent Memory、LLM Memory、RAG、Context Engineering这几个关键概念的本质区别,并探讨如何为AI Agent设计真正意义上的记忆系统。
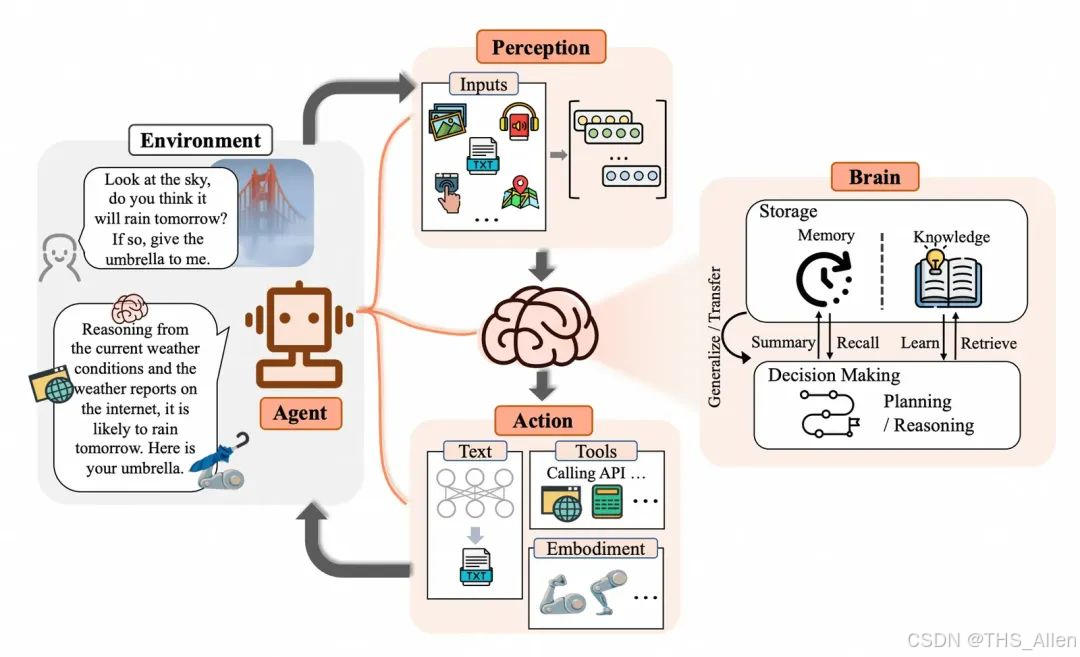
一、 上下文工程:模型所“看见”的一切
在讨论记忆之前,我们需要先理解模型究竟是如何感知世界的。模型在生成回复时,所依据的并非仅仅是我们输入的prompt,而是一个综合的“上下文”(Context)。这个上下文由三类信息共同构成:
| 上下文类型 | 核心内容 | 关键技术/概念 |
|---|---|---|
| 指令上下文 (Instructions) | 告诉模型“如何做”的信息 | 系统提示词、用户指令、少样本示例、工具描述、格式约束 |
| 知识上下文 (Knowledge) | 提供给模型的事实性、参考性信息 | RAG(检索增强生成)、领域知识、记忆、知识库、实时数据 |
| 工具上下文 (Tools) | 模型与外部世界交互的过程与结果 | 函数调用结果、工具执行状态、多步骤工具链、执行历史 |
这个框架清晰地表明,记忆(Memory)是“知识上下文”中的一个子集,它特指那些动态变化的、关于用户偏好、历史交互和会话记录的信息。而整个上下文工程的职责,就是将这些不同来源的信息有机地组织起来,形成模型在当前时刻能够有效利用的输入。
二、 记忆的层次:从“存储”到“认知”
文档将记忆分为两个层次:
-
基础记忆:回忆之前的交互
这是最直观的记忆形式,让Agent能够在多轮对话中引用之前提到过的信息,例如用户的名字、偏好或之前讨论过的话题。它的作用是保证对话的连贯性,通常可以通过短期缓存或简单的键值存储实现。 -
高级记忆:从经验中学习与改进
这是Agent记忆的高级形态。它不仅要求Agent“记住”,更要求它能够根据积累的经验调整自身的行为模式。例如,一个客服Agent在多次被用户纠正后,学会使用更简洁的语言;一个编程助手通过观察你的代码风格,在后续任务中自动适配。这种记忆涉及到知识的沉淀、抽象和行为演化,需要更复杂的机制支持。
三、 核心概念辨析:走出“向量数据库”的误区
文档中最具价值的部分,是对四个极易混淆的概念进行了深入辨析。这有助于我们跳出工具视角,从问题本质去理解记忆。
1. Agent Memory:智能体的持续认知状态
定义:Agent Memory关注的是智能体持续维持的认知状态。它不仅“存”,更要能更新、整合、纠错、抽象,并在跨任务中保持一致性。
独特性:
- 它维护的是一个持久的状态,把事实与经验整合在一起。
- 它关心的是“智能体知道什么、经历过什么,以及这些东西如何随时间变化”。
- 它包含将反复交互沉淀成知识、从成功/失败中抽象程序性知识、跨任务保持身份一致性等高级能力。
本质:这是构建一个拥有“自我”的长期存在体的基础。它超越了单纯的存储,进入了认知和学习的范畴。
2. LLM Memory:模型内部的长序列处理
定义:LLM Memory是真正意义上的模型内部记忆机制。它关注的是模型在一次或有限次推理过程中,如何更有效地保留和利用序列信息。
核心问题:
- 如何避免早期token的信息衰减(如Transformer的注意力机制问题)?
- 如何在计算与显存受限的前提下保持对长距离依赖的建模能力?
本质:这类工作的研究对象是模型内部的状态与动态。它并不假设模型是一个长期存在、需要跨任务保持身份与目标的自主体。即便不引入agentic行为,这些方法也完全成立——模型依然可以在单次问答、长文档理解或摘要等任务中受益。
3. RAG:静态知识访问
定义:RAG强调从外部知识库检索静态信息以提升回答的事实性。
本质:
- RAG可以是Agent Memory的一部分实现,例如将长期记忆向量化后检索。
- 但如果系统没有长期一致性、没有演化机制、没有跨任务的“自我”,那么它本质上只是一个“知识访问模块”,而非完整记忆系统。
- 它处理的是相对固定的知识(如百科、文档),而非动态演化的经验。
4. Context Engineering:当下推理的外部脚手架
定义:Context Engineering的目标是:在上下文窗口受限时,如何组织提示、压缩信息、构建工具输出格式等——它优化的是“此刻模型看到什么”。
本质:
- 它是外部的、用于优化当前交互的技巧,例如如何写系统提示词、如何格式化工具调用结果。
- 而Agent Memory是内部的基底,支持学习与自主性。
- 前者优化当下的接口,后者维持持续的认知状态。
一个形象的比喻可以帮助理解:
想象一个智能助手为你规划旅行。
- Context Engineering就像你递给它一张写得密密麻麻的便签,上面有你的目的地、天数、预算和偏好。它优化了这一次交互的信息呈现。
- RAG就像它即时查阅最新的航班数据库和酒店评论网站,获取的是公开的、静态的事实知识。
- LLM Memory就像它处理你便签上所有文字时,能牢牢记住第一行写的预算限制,不会在最后推荐超豪华酒店。这是它一次推理过程中的内部能力。
- Agent Memory则像是这个助手记住了你是它的老用户。它知道你喜欢靠窗座位、讨厌早起、上次抱怨过推荐的餐厅太油腻。下次你再找它,它不用你重复,就会基于这些积累的动态认知,主动调整推荐策略。这才是真正的“智能体记忆”。
四、 记忆的存在形式:从时间维度到功能角色
在简单场景下,我们可以按时间维度将记忆分为:
- 短期记忆:当前对话的缓存,通常以原始消息列表形式存在。
- 长期记忆:跨会话持久化的信息,例如用户画像、偏好、重要事实,通常存储在向量数据库中,通过相似度检索召回。
但在更复杂的场景,例如多智能体协作中,我们需要从功能角色的维度去划分记忆:
- 共享记忆:多个Agent可以访问的公共知识库或团队协作历史。例如,一个团队中所有Agent都能看到的项目进度信息。
- 私有记忆:单个Agent独有的、关于自身任务和状态的记录。例如,每个Agent的执行日志、内部状态。
- 全局记忆:协调者(orchestrator)持有的、关于整个系统目标和进度的最高层级记忆。
这种从“时间”到“角色”的思维转变,是设计复杂、健壮的多智能体系统时的关键。
五、 工程实践启示:如何设计真正的Agent记忆系统
基于以上辨析,我们可以提炼出设计Agent记忆系统时应遵循的原则:
-
明确需求层次:首先要区分你需要的是基础记忆(连贯对话)还是高级记忆(学习演化)。前者可以用简单的缓存或向量检索实现,后者则需要更复杂的机制,如经验回放、知识蒸馏、元学习等。
-
选择合适的工具组合:
- 对于短期记忆,可以使用Redis等内存数据库存储最近N条对话。
- 对于长期记忆,向量数据库(如Chroma、Milvus)是合适的,但需结合语义检索和时效性策略。
- 对于程序性知识(如从成功/失败中抽象出的规则),可能需要用符号存储或微调模型来沉淀。
- 对于多智能体共享记忆,需要设计同步协议和权限控制。
-
区分静态知识与动态经验:RAG适合处理静态知识(如公司知识库),而Agent Memory适合处理动态演化的用户交互经验。两者可以共存,但应分开管理。
-
保持认知状态的一致性:当Agent经历多轮交互甚至跨任务时,需要一种机制来维持其“自我”的一致性。这可能涉及到对记忆的定期总结、抽象和压缩,以及身份标识的持久化。
-
关注记忆的演化与纠错:真正的记忆不是一成不变的。系统应该能够根据新信息修正旧记忆,或者从失败中学习。例如,当用户明确纠正偏好时,Agent应该更新记忆,而非坚持错误。
六、 结语:记忆,通往真正智能体的必经之路
当我们把目光从“向量数据库”和“长上下文”这些具体技术实现上移开,重新审视Agent Memory的本质时,会发现它其实是通往真正自主智能体的核心基石。一个没有真正记忆的Agent,只能对当下的输入做出反应,无法积累经验、无法适应个性化、无法在长期交互中成长。
未来的AI系统将不再是一个个孤立的对话模型,而是拥有持续认知状态的数字生命体。它们将能够记住你的习惯、理解你的成长、与你建立长期的关系。而这一切,都始于我们对“记忆”这一概念的深刻理解和正确实践。
正如文档所言:“Agent Memory关心的是智能体知道什么、经历过什么,以及这些东西如何随时间变化。” 这不仅仅是一个技术问题,更是对人机关系未来的探索。让我们从厘清概念开始,迈向那个更智能、更人性化的未来。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)