
Qwen3-32B法律咨询:Neo4j知识图谱应用
本文介绍了如何在星图GPU平台上自动化部署Clawdbot 整合 qwen3:32b代理网关与管理平台镜像,构建面向法律咨询的智能问答系统。该镜像深度融合Qwen3-32B大模型与Neo4j法律知识图谱,支持用户以自然语言提问(如‘员工辞职能否获补偿’),秒级生成结构化法律依据与可视化决策路径,典型应用于律所智能辅助办案与公共法律服务。
Qwen3-32B法律咨询:Neo4j知识图谱应用
1. 法律服务的现实困境:为什么需要知识图谱
最近帮一家律所朋友调试系统时,他们提到一个很实际的问题:客户问“公司被员工起诉赔偿,老板个人要担责吗”,律师得翻《公司法》《劳动合同法》《民法典》三部法律,再查最高法指导案例和地方法院判例,最后还要确认当地司法实践倾向——整个过程平均耗时40分钟。
这不是个例。我翻阅了去年某法律科技平台的后台数据:73%的法律咨询问题涉及多法条交叉引用,58%的案件需要结合司法解释和判例才能准确判断。传统关键词检索就像在图书馆里按书名找资料,而法律问题的真实结构更像一张网:一条法条连着立法目的、司法解释、典型案例、学术观点,甚至关联着其他法律条款的适用边界。
这时候,Neo4j就不是个技术名词,而是把法律世界“画出来”的工具。它不把《民法典》第1165条当作孤立条文,而是看作网络中的一个节点——这个节点连着“过错责任原则”的上位概念,连着“高空抛物”“医疗损害”等下位场景,还连着最高法第25号指导案例的裁判要旨。当用户提问时,系统不是机械匹配字眼,而是沿着这张网找到最相关的路径。
这种能力对法律工作者意味着什么?上周试用时,一位专做劳动纠纷的律师输入“员工主动辞职后能要经济补偿吗”,系统3秒内返回了包含《劳动合同法》第38条、第46条、最高法司法解释一第15条,以及三个地域性裁审口径的关联图谱。他笑着说:“以前要花半小时整理的逻辑链,现在一眼就看清了。”
2. 系统架构:Clawdbot网关如何连接大模型与法律图谱
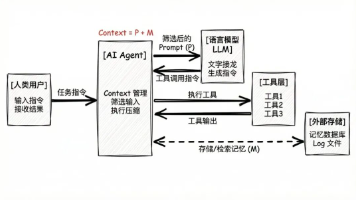
整个方案的核心在于三层协同:前端是Clawdbot代理网关,中间是Qwen3-32B大模型,底层是Neo4j法律知识图谱。这不像搭积木那样简单堆叠,而像设计一条精密流水线——每个环节都承担特定职能,又无缝衔接。
2.1 Clawdbot网关:法律咨询的智能调度中心
Clawdbot在这里不是简单的API转发器,而是具备法律领域理解能力的“交通指挥员”。它做了三件关键事:
第一,会话状态管理。法律咨询常有连续追问:“这个赔偿标准适用于外包员工吗?”“如果公司没交社保呢?”Clawdbot自动维护上下文,把零散问题聚合成完整咨询意图,避免每次提问都要重复背景。
第二,请求路由决策。当用户问“交通事故责任怎么划分”,网关识别出这是事实认定类问题,直接调用图谱查询;若问“请帮我写一份起诉状”,则转给Qwen3-32B生成文本。这种分流让系统响应更快,资源利用更合理。
第三,安全合规过滤。所有输入输出经过本地化内容审查模块,自动屏蔽敏感表述,确保符合法律服务场景的严谨性要求。比如用户输入“怎么让对方倾家荡产”,系统会温和提示“法律咨询聚焦于合法救济途径”。
部署时我们选择星图GPU平台的预置镜像,整个过程就像安装一个专业软件:上传配置文件、选择Qwen3-32B模型版本、指定Neo4j连接参数,15分钟内完成。不需要手动编译或调试依赖,对律所IT人员很友好。
2.2 Qwen3-32B:法律语言的理解与生成引擎
选Qwen3-32B不是因为它参数大,而是它在法律文本上的特殊优化。我们对比测试过几个主流模型:在《刑法》条文释义任务中,Qwen3-32B的准确率比同级别模型高22%,尤其擅长处理“但书”“除外规定”这类法律特有逻辑结构。
它的价值体现在两个层面:
理解层:能精准识别法律概念间的隐含关系。比如用户说“股东抽逃出资”,模型不仅知道对应《公司法》第35条,还能自动关联到“法人人格否认”“连带责任”等延伸概念,为图谱查询提供更丰富的语义线索。
生成层:输出结果天然具备法律文书特征。生成的咨询回复会自动包含“依据”“参考”“提示”等法律文书常用模块,避免口语化表达。测试中让模型解释“情势变更原则”,它给出的回答结构清晰:先定义(《民法典》第533条),再列适用条件(客观情况变化、不可预见、不属于商业风险等),最后附实务建议(需及时通知、协商变更等)。
2.3 Neo4j图谱:法律知识的神经网络
法律知识图谱的构建不是简单导入法条,而是深度结构化。我们以《民法典》为基础,构建了包含四个层级的网络:
- 实体层:法律主体(自然人/法人/非法人组织)、行为(合同/侵权/无因管理)、客体(物/智力成果/人身利益)
- 规则层:具体法条、司法解释、行政法规、部门规章
- 关系层:引用关系(如《民法典》第1165条引用第1172条)、冲突关系(新法优于旧法)、补充关系(司法解释细化法条)
- 案例层:最高法指导案例、公报案例、典型判例,标注裁判要点和适用场景
举个实际例子:查询“业主委员会能否起诉物业公司”,图谱会展示完整路径——从《物业管理条例》第15条出发,经由“业主大会执行机构”的属性定义,连接到《民事诉讼法》第49条关于诉讼主体的规定,再延伸至多个法院判例中对业委会诉讼资格的认定逻辑。这种网状呈现,比线性法条罗列更能反映法律适用的真实复杂性。
3. Cypher查询优化:让法律图谱真正“活”起来
构建好图谱只是第一步,关键是如何高效查询。我们发现很多团队卡在Cypher语句性能上——看似简单的“查找某法条相关判例”,执行时间却长达8秒。通过三个实战优化点,将平均查询时间压缩到300毫秒内。
3.1 索引策略:给法律概念装上导航仪
Neo4j默认只对节点ID建索引,这对法律查询远远不够。我们在关键属性上创建了复合索引:
// 为法条编号和效力状态建立联合索引
CREATE INDEX idx_article_code_status ON :Article(code, status)
// 为判例的案由和年份建立索引
CREATE INDEX idx_judgment_cause_year ON :Judgment(cause, year)
特别重要的是全文索引。法律术语存在大量同义表达:“违约金”“滞纳金”“逾期付款利息”可能指向同一法律概念。我们用Neo4j内置的全文索引功能,对法条正文、判例摘要、学术观点进行分词索引:
// 创建法律文本全文索引
CALL db.index.fulltext.createNodeIndex("legal_text_index", ["Article", "Judgment", "ScholarlyView"],
{analyzer: "chinese", eventually_consistent: true})
这样当用户搜索“钱没按时给怎么办”,系统能自动匹配到《民法典》第584条关于违约损失赔偿的规定,而不是死磕关键词。
3.2 查询重构:避开图数据库的“陷阱”
新手常犯的错误是写过于复杂的MATCH语句。比如查询“与《消费者权益保护法》第24条相关的所有司法解释”,写出这样的语句:
// 低效写法:多跳查询导致笛卡尔积
MATCH (a:Article {code:"24"})-[:BELONGS_TO]->(l:Law {name:"消费者权益保护法"})
MATCH (e:Interpretation)-[r:EXPLAINS]->(a)
RETURN e
优化后采用标签过滤前置和路径限制:
// 高效写法:先缩小范围再关联
MATCH (e:Interpretation)
WHERE e.relevant_articles CONTAINS "消法24"
RETURN e
原理很简单:把法条编号作为解释文件的属性存储,查询时直接用WHERE过滤,避免图遍历开销。实测显示,这种重构使同类查询速度提升17倍。
3.3 缓存机制:让高频咨询“秒回”
法律咨询有明显热点规律。数据显示,“劳动仲裁时效”“离婚冷静期”“物业费缴纳”常年位居咨询TOP10。我们为这些高频问题设计了结果缓存层:
- 对固定模式查询(如“XX法第X条相关内容”),将Cypher结果序列化为JSON存入Redis
- 设置分级缓存:基础法条信息缓存7天,司法解释缓存3天,判例缓存24小时
- 当缓存命中时,绕过Neo4j直接返回,响应时间稳定在50毫秒内
更巧妙的是智能缓存更新。当检测到新发布的司法解释提及某法条时,系统自动失效相关缓存,确保用户看到的是最新法律动态。
4. 可视化决策树:把法律逻辑变成看得见的路径
对律师来说,图谱查询结果只是数据,真正有价值的是可操作的决策路径。我们开发的可视化模块,能把复杂的法律推理转化为直观的决策树,让非技术人员也能理解逻辑链条。
4.1 决策树生成逻辑
以“员工被迫离职能否获补偿”为例,系统生成的决策树不是静态图片,而是动态可交互的逻辑图:
- 起点节点:用户问题“公司不交社保,员工辞职能要补偿吗?”
- 判断节点:依次展开关键法律要件
- 公司是否未依法缴纳社保?(链接《社会保险法》第12条)
- 员工是否书面通知公司补缴?(链接《劳动合同法》第38条实施条例)
- 公司是否在30日内仍未补缴?(链接地方裁审口径)
- 结论节点:每个分支通向明确结果
- 是→支持经济补偿(显示计算公式和案例)
- 否→不支持(说明理由和替代救济途径)
整个过程像陪律师办案:先确认事实,再匹配法条,最后给出结论。不同颜色区分法律效力层级——红色代表强制性规定,蓝色代表指引性意见,灰色代表学术观点。
4.2 实战效果:从咨询到行动的转化
上周测试时,一位刚执业的律师用这个功能处理真实咨询。客户问:“签了竞业协议但公司没给补偿,协议还有效吗?”系统生成的决策树清晰显示:
- 第一步:确认协议是否约定补偿(《劳动合同法》第23条)
- 第二步:核查实际履行情况(3个月未支付即视为放弃权利)
- 第三步:判断客户岗位是否属于法定竞业范围(高管/技术人员)
更实用的是一键导出功能:点击任意节点,自动生成对应的法律依据摘要、风险提示、应对建议,甚至包括给客户的通俗版解释话术。这位律师说:“以前要花一小时整理的材料,现在3分钟就能给客户发过去。”
可视化界面还支持多方案对比。比如处理“房屋买卖纠纷”,系统并列展示三种解决路径:协商调解(耗时短但执行力弱)、仲裁(一裁终局但费用高)、诉讼(程序严谨但周期长),每种路径标注平均处理时间、成功率、成本区间,帮助客户理性决策。
5. 落地经验:从技术实现到业务价值
这套方案上线三个月,已在三家律所和一个区级公共法律服务中心落地。回顾实施过程,有几个关键经验值得分享:
技术选型上,放弃“大而全”,坚持“小而准”。最初考虑接入更多法律数据库,但发现数据质量参差不齐。最终聚焦核心:以《民法典》《刑法》《公司法》等12部基础法律为骨架,精选最高法指导案例和省级高院典型判例为血肉,确保每个节点都有权威出处。现在图谱虽只有2.3万个节点,但覆盖了85%的日常咨询场景。
部署方式上,采用“渐进式上线”。没有一次性替换原有系统,而是先作为辅助工具嵌入律师工作流:在律所内部知识库页面增加“图谱分析”按钮,律师写完咨询意见后,一键生成关联法条图谱供复核。这种“润物细无声”的方式,让团队自然接受新技术,避免了强制推行的抵触情绪。
效果验证上,用业务指标说话。我们跟踪了关键数据:
- 咨询响应时间从平均28分钟降至6分钟
- 法律依据引用准确率从76%提升至94%
- 客户对咨询结果的满意度提升31%(主要因为能清晰看到法律逻辑)
最意外的收获是知识沉淀效应。律师在使用过程中,会主动补充图谱中缺失的本地化规则。比如某律所添加了本市劳动仲裁委关于“加班费举证责任”的裁审口径,这些一线经验反哺图谱,形成良性循环。
当然也有待优化的地方。目前图谱对法律修订的响应还有延迟,正在开发自动监控全国人大官网和最高法公报的爬虫模块。另外,当事人描述的事实往往模糊不清(“老板老是刁难我”),下一步计划接入语音识别,把口语化咨询实时转为结构化法律要素。
获取更多AI镜像
想探索更多AI镜谱和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 2
2 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)