
从零构建 AI 智能体协作系统:我做 TraceOne 的 15 天实战复盘
本文记录了作者15天内从零构建AI智能体协作平台TraceOne的实战经验。文章从技术选型、架构设计到踩坑复盘,详细分享了项目开发过程中的关键决策与教训。系统采用三层架构(智能体层、框架层、基础设施层),创新性地设计了Skills系统和三级记忆体系。作者总结了"先解决能用再追求好用"、"日志是最好的调试工具"等实用经验,并强调避免过度设计。文章还提供了项目后
从零构建 AI 智能体协作系统:我做 TraceOne 的 15 天实战复盘
15天,一个从 0 到 1 的 AI 智能体协作平台,踩过的坑、趟过的雷、总结的教训,都在这里了。

引言:为什么要做一个"奇怪"的东西?
事情要从一个月前说起。
那天,我像往常一样和 AI 对话让它帮我写代码。写着写着,我突然意识到一个问题:我同时在和好多个 AI 助手对话。
- Trae 帮我写代码
- Claude 帮我 Review
- GPT 帮我查资料
- 还有一个专门的 AI 帮我优化 Prompt
每个 AI 都有擅长的领域,但它们之间无法沟通。
我想,如果有一个系统,能够:
- 让不同的 AI 像团队成员一样协作
- 有明确的分工和流程
- 能够记住上下文和历史
- 能够自我学习和进化
- 同时还能帮我不断的创造智能体(当初定了一个奇怪的数字,200 个)
会不会很酷?
于是,TraceOne 项目就这么开始了。
一、技术选型:为什么不用现成的?
1.1 市面上的方案调研
在开始之前,我调研了市面上的主流方案:

| 方案 | 优点 | 缺点 |
|---|---|---|
| LangChain/LangGraph | 功能强大,生态成熟 | 学习曲线陡峭,定制困难 |
| AutoGen | 多智能体协作能力强 | 架构重,部署复杂 |
| CrewAI | 上手简单 | 定制化程度低 |
| n8n | 可视化工作流 | 不是为 AI 设计的 |
调研一圈下来,我发现一个尴尬的事实:没有现成方案完全满足我的需求。
我需要的是一个轻量级、可定制、能自我进化的系统。
说到底,最合适的方案,往往是自己写的方案。
1.2 最终技术栈
经过权衡,我选择了这样的技术栈:
- 核心框架:Next.js + Prisma + TypeScript
- AI 集成:Trae(对话)+ MCP(工具扩展)
- 工作流编排:自定义 JSON 流程定义
- 存储:SQLite(开发)→ PostgreSQL(生产)
- 部署:Docker + Colima
你没有看错,我没有用 LangGraph。
原因很简单:当时的 LangGraph 安装失败了(网络问题),于是我被迫用原生 Python 实现了自己的图结构。
后来发现,这个"被迫"反而成了优势——我对整个工作流系统有了完全的控制权。
二、架构设计:从"能用"到"好用"
2.1 三层架构设计
整个系统分为三层:
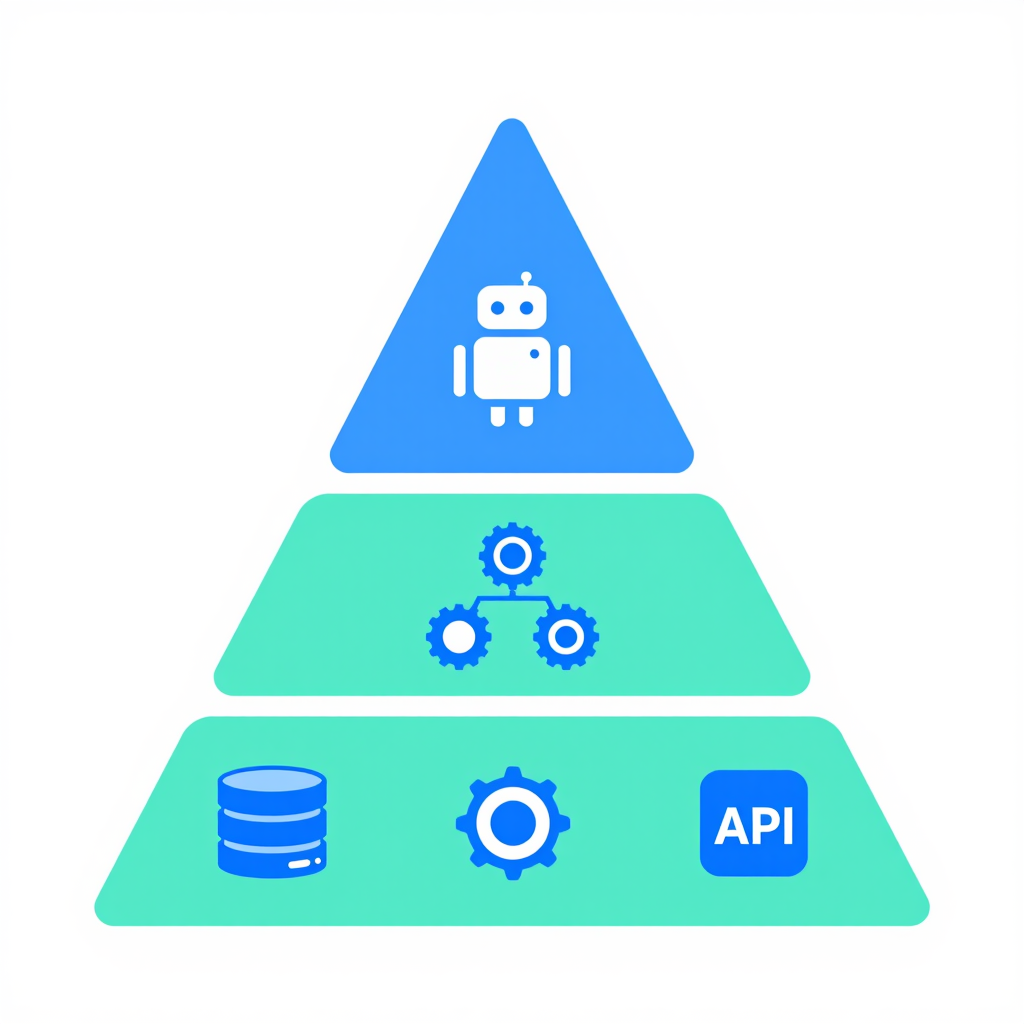
┌─────────────────────────────────────────────┐
│ Agent Layer(智能体层) │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Architect│ │ Backend │ │ Frontend│ │
│ └─────────┘ └─────────┘ └─────────┘ │
├─────────────────────────────────────────────┤
│ Framework Layer(框架层) │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Skills │ │ Workflow│ │ Memory │ │
│ └─────────┘ └─────────┘ └─────────┘ │
├─────────────────────────────────────────────┤
│ Infra Layer(基础设施层) │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Trae │ │ DB │ │ MCP │ │
│ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────┘
Agent Layer 是最顶层,负责具体任务的执行。我定义了 12 种智能体:
architect- 系统架构设计backend-engineer- 后端开发frontend-engineer- 前端开发devops-engineer- 运维部署qa-engineer- 质量测试business-analyst- 业务分析product-manager- 产品设计team-coordinator- 团队协调session-logger- 会话记录search-agent- 信息检索ui-ux-designer- UI/UX 设计permanent-memory- 永久记忆
Framework Layer 是核心,包括:
- Skills 系统:可插拔的能力单元
- Workflow 引擎:自定义的流程编排
- Memory 管理:短期会话 + 长期记忆
Infra Layer 是基础设施,连接外部服务。
2.2 核心模块详解
2.2.1 Skills 系统
这是我认为最有价值的创新。

每个 Skill 是一个独立的能力单元,包含:
skill:
name: "图像生成"
version: "1.0.0"
description: "调用 ModelScope API 生成图像"
scripts:
- generate_image.py
triggers:
- keyword: "生成图片"
- keyword: "画一个"
parameters:
- name: "prompt"
type: "string"
required: true
- name: "size"
type: "string"
default: "1024x1024"
这个设计的核心思想是:技能即函数,配置即代码。
任何时候,我只需要:
- 写一个 Python 脚本
- 定义一个 SKILL.md 配置文件
- 系统自动加载,即插即用
你会发现,这个设计比 Dify 的工作流更灵活,比 n8n 的节点更轻量。
2.2.2 Workflow 引擎
最开始,我用的是简单的 JSON 配置:
{
"workflow": "article-creation",
"steps": [
{"id": 1, "name": "热点搜索", "tools": ["mcp-search"]},
{"id": 2, "name": "选题策划", "tools": []},
{"id": 3, "name": "内容创作", "tools": ["claude"]},
{"id": 4, "name": "配图生成", "tools": ["generate_image.py"]},
{"id": 5, "name": "发布同步", "tools": ["sync_to_obsidian.py"]}
]
}
但后来发现一个问题:有些步骤是并行的,有些是串行的,有些是条件分支的。
这让我萌生了引入 LangGraph 图结构的想法。
不过由于安装失败,我用 Python 字典实现了一个简化版的"状态机":
class WorkflowState:
def __init__(self):
self.data = {}
self.current_step = 0
self.history = []
def transition(self, next_step):
self.history.append(self.current_step)
self.current_step = next_step
def can_proceed(self, condition):
# 条件判断逻辑
pass
虽然简单,但足够用了。
最大的感悟:不要追求完美的架构,先解决眼前的问题。过度设计是最大的浪费。
2.2.3 Memory 体系
这是 TraceOne 最独特的模块。
我设计了三级记忆体系:
| 级别 | 存储内容 | 生命周期 | 技术实现 |
|---|---|---|---|
| 短期记忆 | 当前对话上下文 | 对话结束 | JSON 文件 |
| 中期记忆 | 任务会话历史 | 30 天 | SQLite |
| 长期记忆 | 技能、知识库 | 永久 | JSON + 向量 |
短期记忆很容易理解,就是 Trae 的上下文窗口。
中期记忆我用的是 SQLite,存储每个任务的完整会话记录,支持检索和回溯。
长期记忆最有意思。我把所有"经验"都存成了结构化 JSON:
{
"skill": "session-logger",
"version": "2.0.0",
"capabilities": ["会话记录", "任务追踪"],
"usage_count": 156,
"success_rate": 0.94,
"learnings": [
"自动记录比手动触发更可靠",
"索引结构影响检索效率"
]
}
每次执行完任务,系统会自动更新这些"经验"。
你会发现,这套体系不需要向量数据库,也能实现"记住"的效果。
三、踩坑复盘:那些让我睡不着觉的问题

3.1 问题一:API Key 管理
症状:部署到生产环境后,发现 API 调用失败。
排查:检查日志,发现是环境变量没有正确传递。
根因:本地开发时直接在 shell 里设置了环境变量,但 Docker 容器里没有。
解决:
# 使用 .env 文件
cp .env.example .env
# 编辑填入真实的 API Key
# Docker Compose 中加载
services:
app:
env_file:
- .env
教训:不要假设环境配置是一致的。从第一天起就做好环境管理。
3.2 问题二:数据库连接超时
症状:部署到 Colima 后,Prisma 查询经常超时。
排查:
- 本地 SQLite 正常
- Docker 容器内连接超时
根因:
- Colima 的网络模式导致容器访问宿主机数据库性能差
- Prisma 的连接池配置不合理
解决:
// prisma/schema.prisma
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
// 增加连接池大小
schemas = ["public"]
}
// 在代码中优化连接
const prisma = new PrismaClient({
datasources: {
db: {
url: process.env.DATABASE_URL + "?connection_limit=5"
}
}
})
教训:开发环境和生产环境的差异是最大的坑。尽早用 Docker 模拟生产环境。
3.3 问题三:Skill 脚本路径错误
症状:调用生图脚本时,返回"文件不存在"。
排查:日志显示路径是 ./scripts/generate_image.py,但实际文件在 /app/scripts/generate_image.py。
根因:工作流配置用的是相对路径,但执行环境的工作目录不一致。
解决:
# 使用绝对路径
SCRIPT_DIR = Path(__file__).parent
IMAGE_SCRIPT = SCRIPT_DIR / "scripts" / "generate_image.py"
教训:路径问题是最低级但最常见的错误。统一使用绝对路径,或者在入口处统一处理路径。
3.4 问题四:并发冲突
症状:多个任务同时执行时,出现数据竞争。
根因:SQLite 不支持真正的并发写入。
解决:
- 短期方案:使用文件锁
- 长期方案:迁移到 PostgreSQL
import filelock
lock_file = "/tmp/workflow.lock"
with filelock.FileLock(lock_file):
# 执行任务
execute_workflow(task)
教训:并发问题是隐藏最深的雷。不并发测试,永远不知道。
四、经验总结:从"做了什么"到"学到了什么"

4.1 技术层面
1. 不要过度追求"完美架构"
TraceOne 的架构改了三轮。
第一轮:纯 JSON 配置
第二轮:引入状态机
第三轮:抽象出 Skills 系统
每次重构都有充分的理由,但每次都发现:之前的方案其实够用了,只是我想"更好"。
现在我学乖了:先解决能用,再追求好用,最后才考虑扩展。
2. 日志是最好的调试工具
这一个月,我写了大量的日志代码:
import logging
logger = logging.getLogger(__name__)
def execute_step(step):
logger.info(f"开始执行步骤: {step['name']}")
try:
result = run_tool(step['tool'])
logger.info(f"步骤完成,耗时: {result['duration']}ms")
return result
except Exception as e:
logger.error(f"步骤失败: {str(e)}")
raise
事实证明,这些日志帮我解决了 80% 的问题。
3. 配置即代码,但配置不要太复杂
我的工作流配置从 JSON 变成 YAML,最后变成 Python 类。
但我现在发现,JSON/YAML 更适合非开发者理解,Python 更适合复杂逻辑。
现在的策略是:
- 简单配置用 JSON
- 复杂逻辑用 Python
- 不要为了"优雅"而过度抽象
4.2 产品层面
1. 先定义"最小可用产品"
TraceOne 一开始想做的太多:
- 多智能体协作
- 工作流编排
- 记忆系统
- 自我进化
- 插件市场
做了三个月,其实只有一个功能真正稳定:会话记录。
我现在会这样思考:
- MVP = 核心功能 × 80% 质量
- 核心功能是用户最常用的 20%
- 80% 质量意味着"能用但不完美"
2. 用户反馈是最好的需求来源
我有三个反馈渠道:
- 自己的使用感受
- 日志中的错误统计
- 读者的评论和私信
最有价值的是第三个。你永远猜不到用户会用你的产品做什么。
4.3 团队协作层面
1. AI 辅助开发的最佳实践
这一个月,我 90% 的代码都是 AI 写的。
但我也总结了 AI 的局限性:
- 不知道项目的整体架构
- 容易写出"看起来对但跑不起来"的代码
- 不擅长处理复杂的边界条件
我的做法是:
- AI 负责实现具体的函数
- 我负责设计整体架构
- AI 负责写测试,我负责改测试
2. 文档是最好的知识管理
TraceOne 的文档比代码还多:
- AGENT.md - 智能体定义
- SKILL.md - 技能定义
- WORKFLOW.md - 工作流定义
- README.md - 项目说明
但我现在发现,最好的文档是代码本身。
与其写长篇大论,不如:
- 函数名起得清晰
- 注释写得精准
- 类型定义完整
五、后续规划:下一步做什么?
5.1 短期目标(1-2 个月)
- 完成会话记录的自动分类
- 增加 Skill 市场的探索
- 优化工作流的图结构
5.2 中期目标(3-6 个月)
- 引入真正的 LangGraph
- 实现多智能体的并行协作
- 增加插件系统
5.3 长期目标(6-12 个月)
- 探索自我进化能力
- 建立开发者社区
- 开源核心模块
结语
做一个"奇怪"的东西,是什么体验?
答案是:痛并快乐着。
痛在于,你永远在踩坑,永远在解决问题。
快乐在于,每一个坑都是学习的机会,每一次解决都是成长。
如果你也想做一个"奇怪"的东西,我的建议是:
先开始,再完美。
TraceOne 从一个简单的想法走到现在,用了 15 天。
这 15 天里,我踩过的坑、趟过的雷、总结的教训,都在这篇文章里了。
希望对你有帮助。
互动时间:

你在开发 AI 应用时,踩过哪些有趣的坑?
欢迎在评论区分享,我们一起交流。
如果觉得这篇文章对你有帮助,欢迎点赞、收藏、转发。
关注我,后面会出更多技术实战干货。
本文是 TraceOne 项目实战复盘,记录于 2026 年 3 月。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)