
从OpenClaw到实现如何实现个人Agent:基于LangChain 和 LangGraph 的 Agent 设计
本文带你了解,如何通过LangChain、LangGraph、tools、MCP、Agent Skills、ReAct、SubAgent这些关键能力,做出一个能路由、会规划、可调用工具、带记忆、还能完成执行闭环的AI Agent。
先说结论。
项目灵感来源于OpenClaw,这套东西和 OpenClaw 有一点像,也有一点不一样。
像的地方在于,大家都不满足于“做一个会聊天的模型壳子”,而是想把 Agent 真正接到工具、状态和执行链路上。不一样的地方在于,OpenClaw 更偏本地运行时和通用 Agent 能力,这个项目更偏中心化后端、多平台接入、多用户共享数据,以及提醒、记账、技能这些更具体的业务闭环。
所以这篇文章不是去复述 OpenClaw,而是想讲一件更具体的事:我怎么在它这类 Agent 项目的启发下,把一句自然语言,尽量稳定地变成一个系统动作。
比如这句话:
如果明天武汉下雨,早上 8 点提醒我带伞。
这事看起来像聊天,实际上不是。
它至少要经过下面几步:
- 识别这不是普通问答
- 判断这不是单节点就能做完的事
- 先查天气
- 再判断“下雨”这个条件成不成立
- 条件成立才创建提醒
- 到点以后把提醒推到用户绑定的多个端
- 记录每个端到底发没发成功
这类需求,已经不是“模型回一句话”能解决的了。
所以我把项目拆成了一条比较清楚的 Agent 链路:
统一输入 -> 路由 -> 复杂任务规划 / 普通 ReAct -> 工具调用 -> 状态落库 -> 调度执行 -> 多端投递
这篇文章围绕 Agent 内核来讲:路由、规划、工具、记忆和执行。
一、先看 Agent 总图
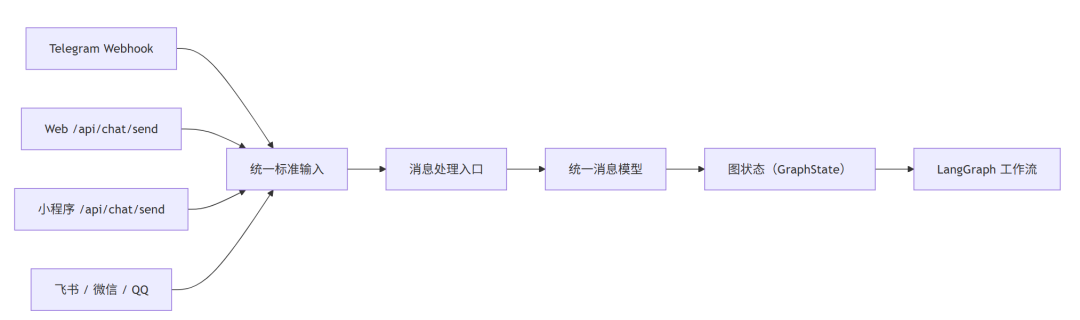
先上一张图,讲最外层的链路。
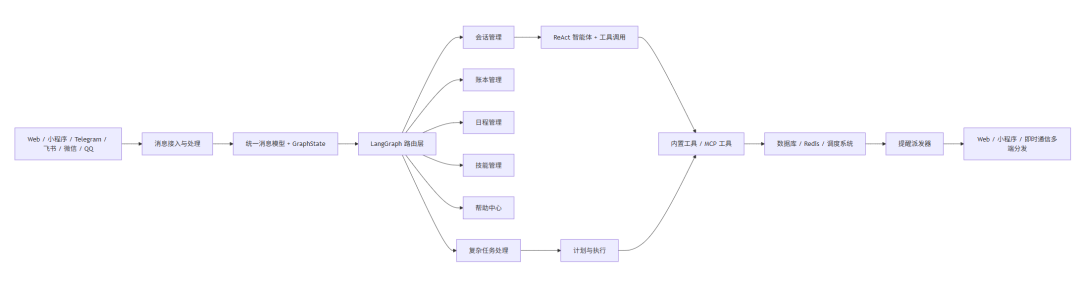
如果一句话概括这张图,就是:
多端只是入口,真正的 Agent 在后端。
web端、telegram、小程序,这些都只是把消息送进来。后面的统一消息模型、路由、规划、执行、调度,才是这套系统的核心。
二、多端不是重点,重点是后面只有一个 Agent
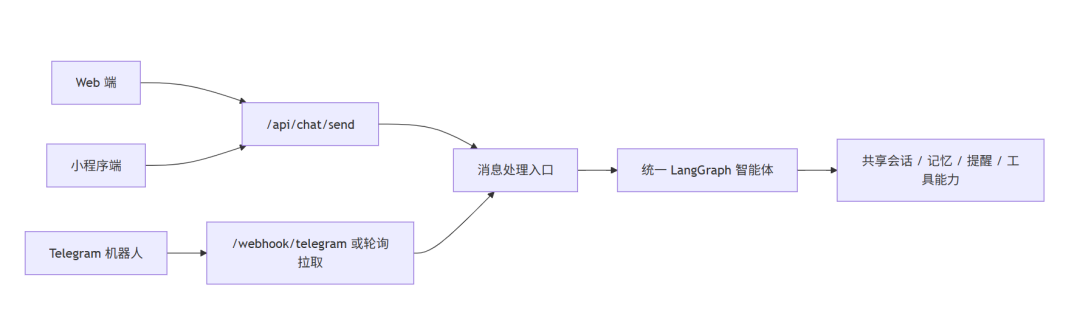
对我来说,多端真正有价值的地方,不是 UI 数量,而是这些入口共享同一套后端能力:
- 同一个用户体系
- 同一个会话体系
- 同一个 LangGraph 工作流
- 同一套长期记忆
- 同一套提醒与投递系统
这里放一张更清楚的图:
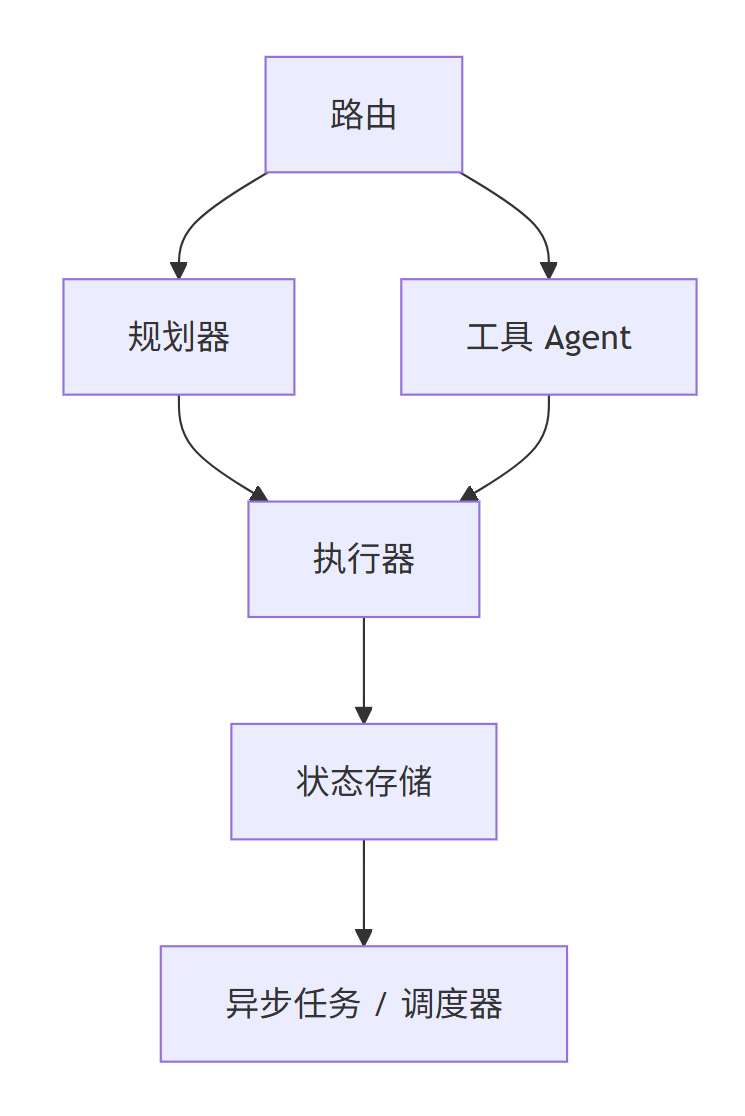
三、这套 Agent 我是怎么拆解的
我后来越来越确定一件事:
Agent 不能只看“有没有调用工具”,要看你有没有把决策层、执行层、状态层拆开。
我在这个项目里,基本按下面这张图拆:
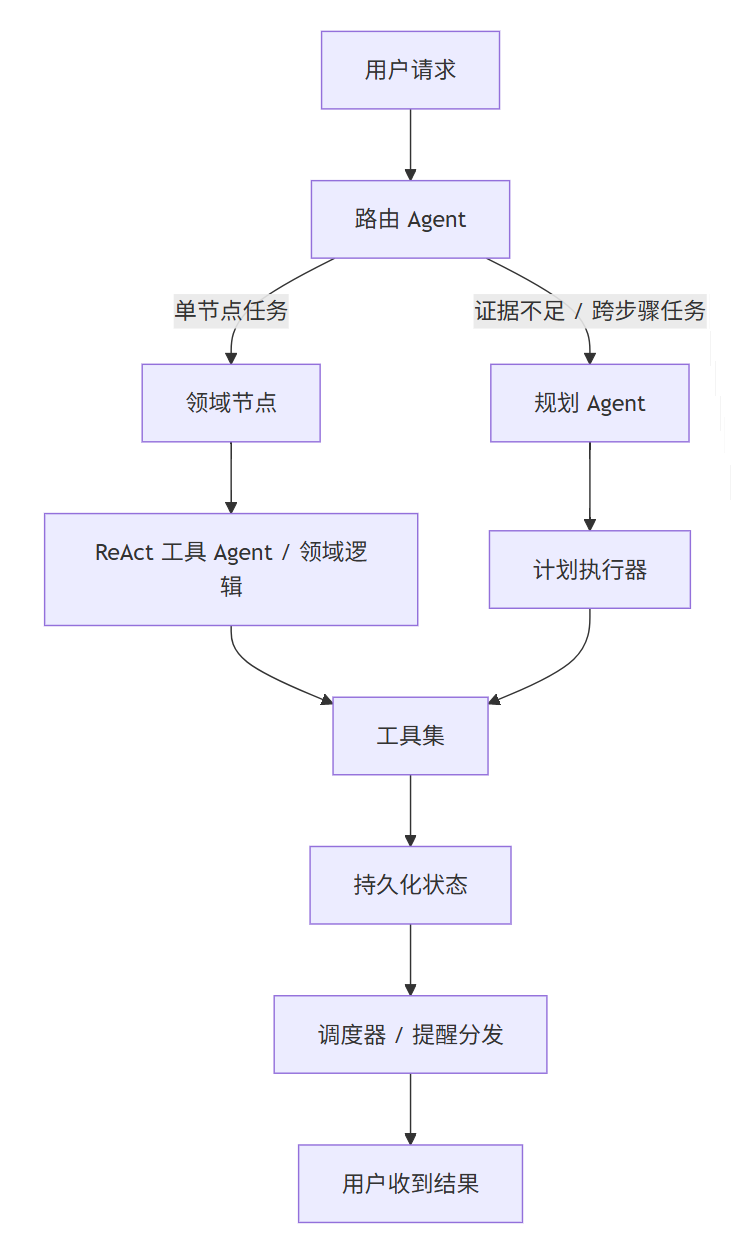
这里面其实有 4 类 Agent / Agent-like 组件:
- 路由Agent 只负责判断去哪,不负责做完全部事情。
- 规划Agent 只在复杂任务里出现,负责把目标拆成步骤。
- ReAct工具Agent 主要在普通实时查询里使用,负责自主选择工具。
- 计划执行器这个不一定是 LLM,但它负责把计划变成真正的系统动作。
- 路由Agent 可以专心分类
- 规划Agent 可以专心拆步骤
- ReAct工具Agent 可以专心查信息
- 计划执行器执行层可以专心保证动作真的落地
如果这些全塞给一个总 Agent,理论上也能跑,但可控性会越来越差。
四、统一输入不是工程细节,而是 Agent 的前置条件
这个项目支持 Web、微信小程序、Telegram、飞书、微信、QQ。
但后端主流程并不关心消息来源。进来以后先统一。
主入口在backend/app/services/message_handler.py,核心动作大概是这样:
async def handle_message(platform: str, normalized: dict[str, Any], session: AsyncSession) -> dict[str, Any]:
if await is_duplicate(platform, normalized.get("message_id")):
return {"ok": True, "dedup": True}
user, _ = await get_or_create_user(session, platform, normalized["platform_id"])
conversation = await ensure_active_conversation(session, user)
message = UnifiedMessage(
platform=platform,
user_uuid=user.uuid,
content=normalized.get("content") or "",
image_urls=normalized.get("image_urls") or [],
raw_data=normalized.get("raw_data", {}),
message_id=normalized.get("message_id"),
event_ts=normalized.get("event_ts"),
)
graph = await get_graph()
result = await graph.ainvoke(state, config=graph_config)
这段代码做的事很简单,但对 Agent 很关键:
- 去重,挡住 webhook 重投
- 找用户
- 找当前会话
- 组装统一消息结构
- 进入 LangGraph
为什么这一步值得单独讲?
因为一旦不统一,后面的 Router、Planner、Tool Agent 都得知道“这条消息是从哪来的”,Agent 主链路就会被平台差异污染。
我宁愿让平台适配都堆在入口层,也不要把平台差异泄漏到 Agent 主链路里。
再看一张图会更清楚:
五、LangGraph 工作流不是花架子,它解决的是“谁来处理这件事”
Agent 最容易写崩的地方,不是工具,而是路由。
因为一旦路由不准,后面全白搭。
工作流定义在backend/app/graph/workflow.py:
def _build_graph(checkpointer):
graph = StateGraph(GraphState)
graph.add_node("router", router_node)
graph.add_node("onboarding", onboarding_node)
graph.add_node("complex_task", complex_task_node)
graph.add_node("ledger_manager", ledger_manager_node)
graph.add_node("schedule_manager", schedule_manager_node)
graph.add_node("chat_manager", chat_manager_node)
graph.add_node("skill_manager", skill_manager_node)
graph.add_node("help_center", help_center_node)
graph.set_entry_point("router")
graph.add_conditional_edges("router", route_intent, {...})
return graph.compile(checkpointer=checkpointer)
这段代码本身不复杂,但它表达了一个很实用的思想:
先把问题送到一个专职路由,再决定接下来谁来干。
如果只是个简单聊天项目,可能一个 prompt 就够了。
但一旦系统里同时有:
- 聊天
- 工具调用
- 记账
- 日程
- 技能管理
- 复杂条件任务
那就很难再靠单一 agent 稳定覆盖所有情况。
所以我用 LangGraph,不是因为它“听起来高级”,而是因为它很适合把系统拆成多个职责明确的节点。
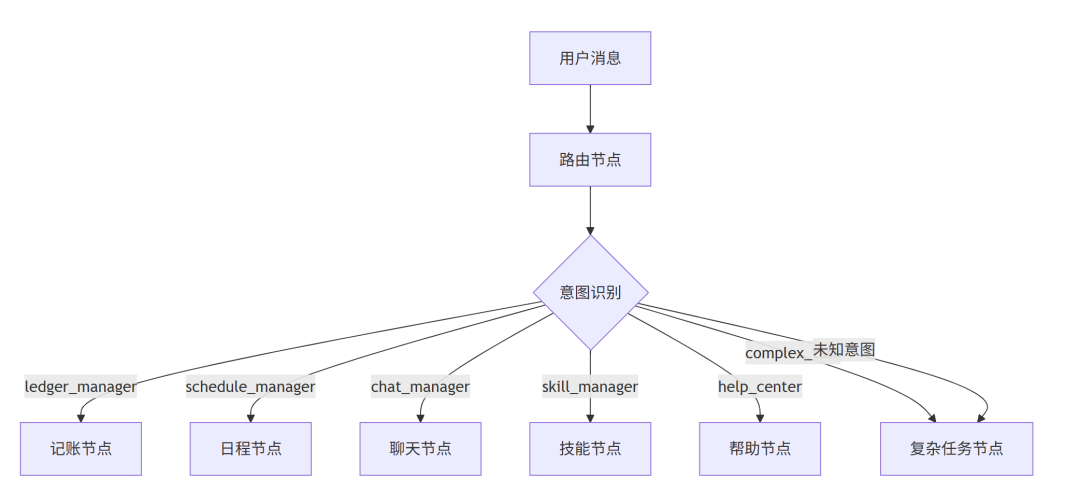
六、Router 这一层,没做关键词匹配
backend/app/graph/nodes/router.py里,Router 是一次结构化分类,不是扫关键词。
它输出的 schema 很简单:
class RouterIntentExtraction(BaseModel):
route_intent: str = Field(default="unknown")
confidence: float = Field(default=0.0, ge=0.0, le=1.0)
reason: str = Field(default="")
然后模型只能从几个合法值里选:
VALID_INTENTS = {
"complex_task",
"skill_manager",
"ledger_manager",
"schedule_manager",
"chat_manager",
"help_center",
"unknown",
}
兜底逻辑:
def route_intent(state: GraphState) -> str:
if state.get("user_setup_stage", 0) < 3:
return "onboarding"
routed = str(state.get("intent") or "").strip().lower()
if routed in {
"complex_task",
"skill_manager",
"ledger_manager",
"schedule_manager",
"chat_manager",
"help_center",
}:
return routed
return "complex_task"
也就是说,证据不足时,不会把它直接丢回普通聊天,而是送去complex_task再判一次。
这背后的考虑其实很实际:
- 真正简单的问题,Router 一次就能判准
- 真正复杂的问题,Router 不一定一次判准
- 但复杂问题最怕的不是“多判一步”,而是“太早掉回普通聊天”
换句话说,这里的策略不是“第一次必须判准”,而是“第一次至少别把复杂事判死”。
七、真正像 Agent 的部分,在 complex_task
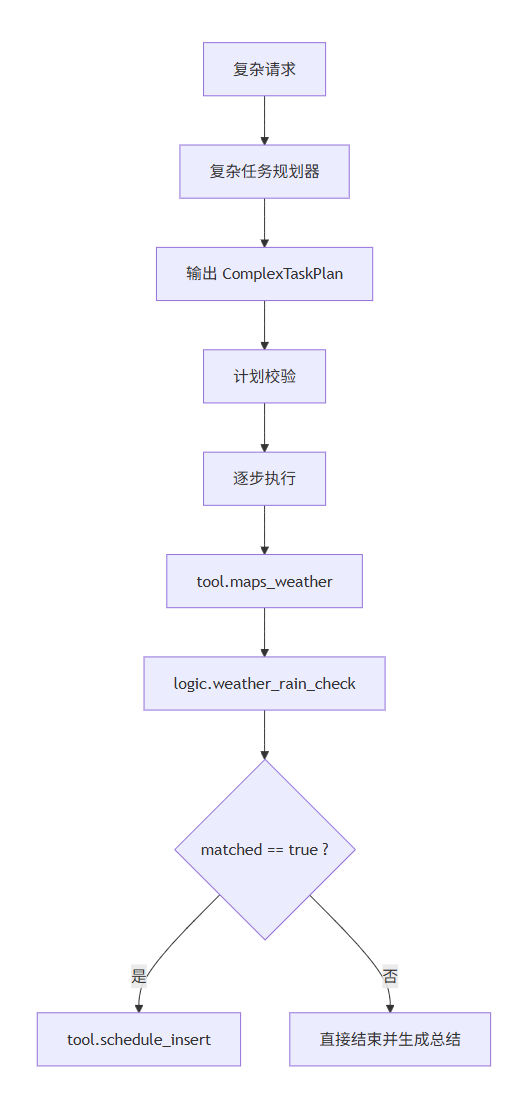
最能体现 Agent 的地方,不是 ReAct,而是backend/app/graph/nodes/complex_task.py。
因为这里不是让模型“想办法把事做了”,而是先让它把任务拆成一个结构化计划。
计划数据结构长这样:
class PlanStep(BaseModel):
step_id: str = Field(min_length=1, max_length=64)
action: str = Field(min_length=1, max_length=120)
args: dict[str, Any] = Field(default_factory=dict)
depends_on: list[str] = Field(default_factory=list)
timeout_ms: int = Field(default=20000, ge=1000, le=120000)
class ComplexTaskPlan(BaseModel):
goal: str = Field(default="")
steps: list[PlanStep] = Field(default_factory=list, min_length=1, max_length=20)
这个设计我很喜欢,因为它逼着模型做两件事:
- 先把步骤写清楚
- 再按步骤执行
这和“一个 agent 自己边想边调工具”是两种风格。
前者更像任务编排,后者更像自由探索。
- 为什么我会给 plan 加
depends_on
因为很多任务不是一步接一步平铺的,而是“后一步必须等前一步结果出来”。
比如天气条件提醒,至少会出现这种依赖:
- 先拿天气
- 再判断是否下雨
- 再决定建不建提醒
如果没有depends_on,模型很容易把这些步骤说得很像一回事,但执行时其实顺序是乱的。
- 为什么我会允许占位符引用
执行前会先解析参数里的占位符:
def _resolve_value(value: Any, step_outputs: dict[str, Any]) -> Any:
if isinstance(value, str):
match = PLACEHOLDER_PATTERN.match(value.strip())
if not match:
return value
ref_step = str(match.group(1) or "").strip()
ref_path = str(match.group(2) or "").strip()
ref_value = step_outputs.get(ref_step)
if ref_path:
return _deep_get(ref_value, ref_path)
return ref_value
这段逻辑看着小,但非常有用。
它让模型能写出这种参数:
$weather_step.output
$step2.matched
这样后续步骤就不是“拍脑袋传参”,而是显式引用前一步输出。
- 为什么要做 plan 校验
计划生成以后,还会检查一遍:
def _validate_plan(plan: ComplexTaskPlan) -> tuple[bool, str]:
step_map: dict[str, PlanStep] = {}
for step in plan.steps:
if step.step_id in step_map:
return False, f"duplicate step_id: {step.step_id}"
step_map[step.step_id] = step
for step in plan.steps:
if step.step_id in set(step.depends_on):
return False, f"self dependency: {step.step_id}"
for dep in step.depends_on:
if dep not in step_map:
return False, f"unknown dependency: {dep}"
这事很像在给 LLM 做“编译前检查”。
不指望模型每次都产出完美计划,所以宁愿多一道结构校验,也不要直接信它。
- 为什么还加了 grounded arg 校验
比如天气查询时,要求maps_weather.city这种参数必须能在当前用户消息或上下文里找到证据。
if tool_name_l == "maps_weather":
city = str(args_for_tool.get("city") or args_for_tool.get("adcode") or "").strip()
if not city:
raise RuntimeError("missing_required_arg: maps_weather.city")
if not _arg_is_grounded_in_state(city, base_state):
raise RuntimeError("ungrounded_arg: maps_weather.city")
这么做的原因很简单:
模型太爱“脑补一个看起来合理的参数”了。
如果不拦,今天它能给你脑补一个城市,明天就能给你脑补一个提醒时间。
在真实系统里,这种错比“回答不够聪明”严重得多。
- 这条链路的执行图
八、普通查询不走 planner,而是用了一个受约束的 ReAct 子代理
复杂任务不是全部。
像“纽约现在几点”“帮我看看今天天气”“列一下我的长期记忆”这种事,更适合一个工具增强的对话代理。
这部分放在backend/app/graph/nodes/chat_manager.py。
核心逻辑分两段。
先分类:
class ChatClassificationExtraction(BaseModel):
kind: str = Field(default="unknown")
tool_required: bool = Field(default=False)
weather_location: str = Field(default="")
confidence: float = Field(default=0.0)
再决定要不要起 ReAct:
should_try_tools = tool_required or (kind in {"time", "external", "weather", "tooling"})
if should_try_tools:
tool_answer, _tool_count = await _run_tool_agent(
user=user,
platform=platform,
conversation_id=conversation_id,
content=content,
context_text=context_text,
skills=skills,
runtime_tools=runtime_tools,
)
真正的 ReAct 子代理是这么起的:
agent = create_react_agent(
model=get_llm(node_name=LLM_NODE_TOOL_AGENT),
tools=_build_chat_tools(
user_id=user.id,
platform=platform,
conversation_id=conversation_id,
),
name=f"chat_tool_agent_{user.id}_{conversation_id or 0}",
)
为什么没把它做成“无限自由调用工具”?
因为线上系统没法接受一个 agent 漫无目的地试工具。
所以这里我给了它几个边界:
- 明确的工具目录
- 场景提示词
- 调用次数限制
- 最终 grounded answer
我比较喜欢chat_manager里这段“二次落地”的逻辑:
if text and tool_outputs:
text = await _ground_answer_with_tool_outputs(
user=user,
content=content,
context_text=context_text,
skills=skills,
tool_outputs=tool_outputs,
draft_answer=text,
)
也就是说,工具查完以后,不是直接把 agent 最后那段话原样给用户,而是再过一层“基于工具证据重写回答”。
这个设计能明显降低幻觉。
不是把幻觉彻底消灭,而是把它压到一个更可控的范围。
九、工具不是越多越好,关键是要有治理
这项目里工具层的代码,没写成“一个巨大的工具列表”。
工具注册在backend/app/services/tool_registry.py:
def list_builtin_tool_metas() -> list[ToolMeta]:
return [
{"name": "now_time", "source": "builtin", "description": "...", "enabled": True},
{"name": "fetch_url", "source": "builtin", "description": "...", "enabled": True},
{"name": "memory_list", "source": "builtin", "description": "...", "enabled": True},
{"name": "schedule_insert", "source": "builtin", "description": "...", "enabled": True},
{"name": "schedule_list", "source": "builtin", "description": "...", "enabled": True},
]
然后运行时工具会从 MCP 拉:
async def _list_runtime_tool_metas_uncached() -> list[ToolMeta]:
rows = list_builtin_tool_metas()
...
for url in _candidate_mcp_urls():
tools = await get_mcp_fetch_client(url=url).list_tools()
...
rows.append(
{
"name": name,
"source": "mcp",
"description": desc,
"enabled": bool(enabled_map.get(make_tool_key("mcp", name), True)),
}
)
这里故意加了几层控制:
- allowlist
- enable / disable 开关
- 运行时缓存
- 不同节点看见不同工具集
这看起来没那么“智能”,但特别实用。
因为工具系统上线后,最头疼的通常不是“不会调”,而是:
- 不该暴露的工具暴露了
- 某个工具坏了,没法临时摘掉
- 某个节点能看见太多工具,选择开始乱飘
这类问题,不靠更强的模型解决,靠的是更老实的边界约束。
我觉得 Agent 落地时,一个常见误区就是把“模型很聪明”当成“系统可以少做约束”。
实际正好相反。系统越复杂,约束越重要。
十、Skill 这层单独做,不把它变成 Prompt 收藏夹
很多项目一说“技能”,最后其实只是几段 prompt 模板。
这当然能用,但我觉得不太够。
如果 skill 真的是 Agent 的扩展能力,那它至少应该有这几样东西:
- 独立的数据模型
- 版本
- 发布状态
- 管理入口
- 在普通聊天里的加载机制
我在这个项目里,skill 基本就是按这个思路做的。
先看模型,backend/app/models/skill.py里不是一张表糊到底,而是拆成了技能本体和版本表:
class Skill(SQLModel, table=True):
user_id: int = Field(foreign_key="users.id", index=True)
slug: str = Field(index=True)
name: str = Field()
description: str = Field(default="")
status: str = Field(default=SkillStatus.DRAFT, index=True)
active_version: int = Field(default=1)
class SkillVersion(SQLModel, table=True):
skill_id: int = Field(foreign_key="skills.id", index=True)
version: int = Field(index=True)
content_md: str = Field()
这套结构很简单,但足够有用。
它至少解决了几个实际问题:
- 技能可以先保存草稿,不用一上来就发布
- 技能可以不断迭代版本,不用覆盖旧内容
- 聊天主链路里只加载
PUBLISHED的版本,避免半成品混进去
再看 skill 内容本身,我也没把它当成一句 prompt。
backend/app/services/skills.py
里会校验技能文档结构:
def _validate_skill_content(content: str) -> tuple[bool, list[str]]:
errors: list[str] = []
name, description = _parse_frontmatter(content)
if not name:
errors.append("frontmatter 缺少 name")
if not description:
errors.append("frontmatter 缺少 description")
for section in ("# Trigger", "# Workflow", "# Constraints", "# Output Contract"):
if section not in content:
errors.append(f"缺少章节: {section}")
return (len(errors) == 0), errors
也就是说,一个 skill 至少要说明:
- 什么时候触发
- 怎么做
- 不能做什么
- 最后输出长什么样
这和“我存一段写作风格 prompt”完全不是一回事。
- skill_manager 是单独一个节点
技能管理没有塞进聊天节点里糊过去,而是单独有一个skill_manager_node。
工作流里是明确挂进去的:
graph.add_node("skill_manager", skill_manager_node)
它负责的事情包括:
- 列出技能
- 查看技能
- 创建 / 更新草稿
- 发布
- 停用
- 删除
比如列出技能时,内置技能和用户技能会一起返回:
if action in {"list"}:
rows = await list_skills_with_source(session, user.id)
...
lines = ["技能列表(含内置与用户):"]
这个设计我觉得挺重要的。
因为一旦 skill 只是“后台配置项”,它很难成为 Agent 的一等能力;只有它进入主工作流,成为一个明确节点,技能这件事才算真正接进系统里。
- skill 和 tool 不是一回事
我在文章前面讲了很多 tool,但 skill 和 tool 的定位其实不一样。
我的理解是:
tool是可执行能力,偏动作,比如查天气、建提醒、查会话skill是行为模板,偏策略,比如写作风格、翻译规范、特定输出格式
换句话说,tool 更像“手”,skill 更像“做事的方法”。
所以在chat_manager里,我特地把 skill 当成文档加载进来,而不是让模型把 skill 当成工具调用:
skills = await load_skills(
session=session,
user_id=user.id,
query=content,
)
load_skills()的逻辑也比较直接:先收集内置 skill 和已发布的用户 skill,再按当前 query 做相关性排序,最后只取前几个最相关的:
async def load_skills(
session: AsyncSession,
user_id: int,
query: str | None = None,
top_k: int = 4,
) -> str:
docs.extend(_load_static_skill_docs())
...
stmt = select(Skill).where(
Skill.user_id == user_id,
Skill.status == SkillStatus.PUBLISHED,
)
...
if q:
docs = sorted(docs, key=lambda d: _score_skill(d, q), reverse=True)
这样它不会把一堆无关 skill 全塞进上下文里。
系统只会把当前请求最相关的几个 skill 文档喂给模型,尽量把 skill 这层做成“有选择地增强”,而不是“上下文污染源”。
- 为什么我觉得 skill 这层值得单独写
因为很多人写 Agent 时,会把“能力扩展”只理解成接更多工具。
但实际做下来你会发现,除了工具,还有一类非常常见的扩展需求:
- 某个用户想让写作输出更固定
- 某个场景需要稳定遵循一套 workflow
- 某个团队想给 Agent 注入领域规则,但不想改主 prompt
这类需求,用 tool 解决不合适,用全局 prompt 解决也很脏。
单独拉出 skill 层,反而更干净。
所以我现在更愿意把这个项目里的能力分成三层:
- Router / Planner:决定怎么走
- Tool:决定能做什么动作
- Skill:决定用什么方式做
如果后面你想把 Agent 做成一个能被用户长期调教的系统,skill 这层基本绕不过去。
十一、记忆不是全量“上下文”
记忆 ≠ 把历史消息拼长一点
它短期能跑,但一旦会话变长,成本、噪声、冲突都会上来。
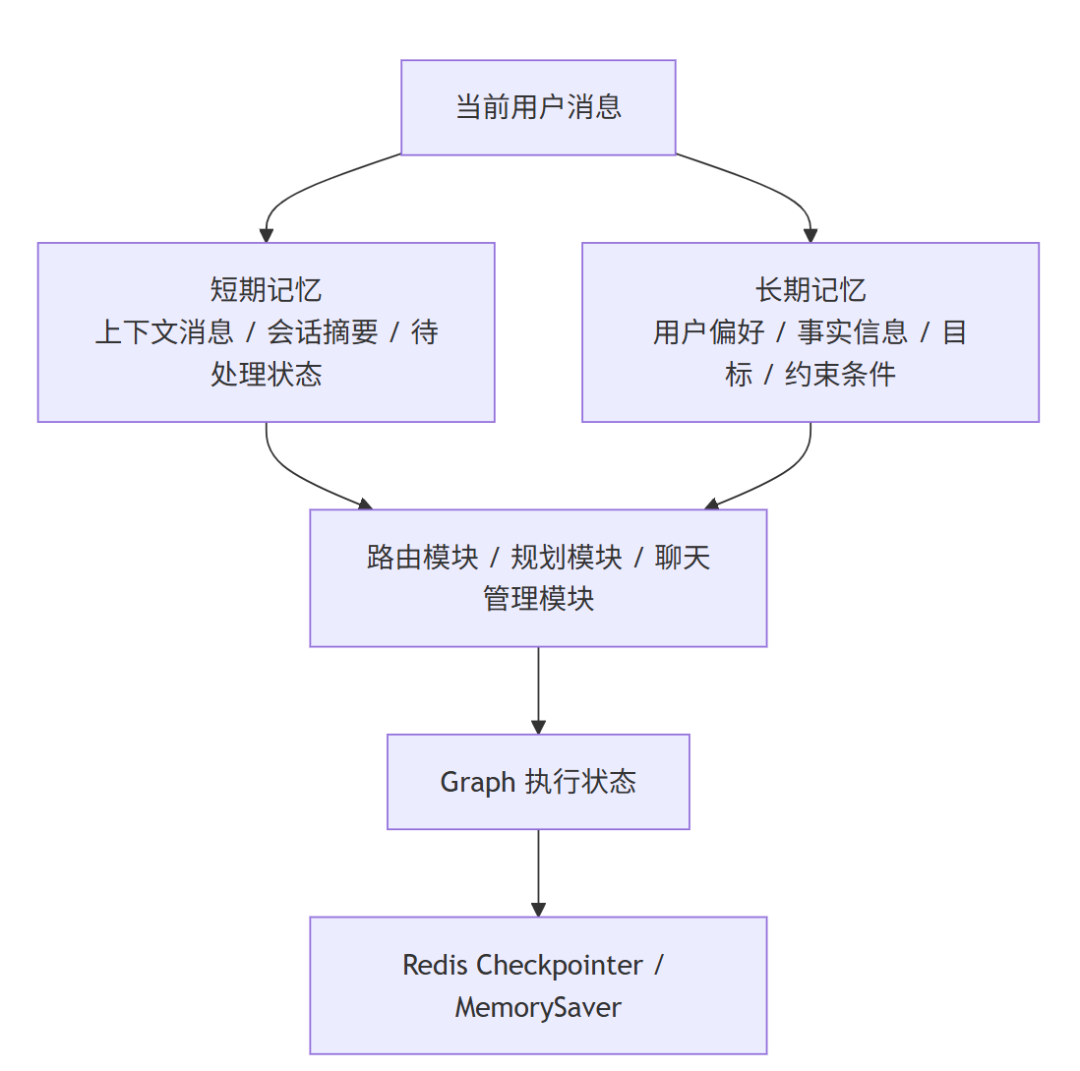
所以我这里其实拆了三层:
- 短期记忆:当前会话里最近发生了什么
- 长期记忆:跨会话仍然有效的用户信息
- 状态持久化:这轮 Agent 执行到哪一步了,能不能在中断后继续
我觉得这三层拆开以后,Agent 才算真的有“记忆”和“状态”,而不是只是在 prompt 里塞更多字。
- 短期记忆负责“把这轮对话接上”
短期记忆主要挂在GraphState和extra里。
状态定义其实很轻:
class GraphState(TypedDict, total=False):
user_id: int
conversation_id: int
user_setup_stage: int
message: UnifiedMessage
responses: List[str]
intent: str
extra: dict[str, Any]
真正有意思的是extra里塞的内容。
在渲染上下文时,会把这些东西整理出来:
def render_conversation_context(
state: GraphState,
max_messages: int = 16,
*,
include_summary: bool = True,
include_assistant_messages: bool = True,
include_long_term_memories: bool = True,
) -> str:
extra = state.get("extra") or {}
summary = _normalize_text(extra.get("conversation_summary") or "", 300)
raw_messages = extra.get("context_messages") or []
raw_memories = extra.get("long_term_memories") or []
也就是说,短期记忆这层里至少包含:
- 最近几轮对话
- 当前会话摘要
- 当前节点正在处理的临时状态
- 像
pending ledger、pending complex task这种未完成上下文
这层记忆的作用不是“永久记住你是谁”,而是让 Agent 不会在下一轮突然断片。
比如你前一轮说“明天早上 8 点提醒我”,下一轮只补一句“在武汉”,系统还能知道你是在补天气条件任务,不是在开一个全新话题。
- 长期记忆负责“跨会话还能记住你”
短期记忆解决的是会话连续性,长期记忆解决的是跨会话复用。
所以在backend/app/services/memory.py里,我做的是抽取式长期记忆,而不是把历史消息整段搬过去。
先定义允许的记忆类型:
VALID_MEMORY_TYPES = {"profile", "preference", "fact", "goal", "project", "constraint"}
然后会经历几步:
- 从消息里提候选记忆
- 规范化 key
- 做 refine
- 做语义去重 / 合并
- 注入回后续对话
长期记忆和短期记忆的分工,我现在基本是这么理解的:
- 短期记忆回答“你刚刚在说什么”
- 长期记忆回答“你平时是谁、偏好什么、长期要做什么”
如果只做短期记忆,系统会话内还算连贯,但跨会话就很快失忆。
如果只做长期记忆,不做短期上下文,系统又会变成“记得你是谁,但接不上你刚刚那句话”。
所以这两层其实不是替代关系,而是配合关系。
我比较看重的是这段身份信息排除逻辑:
IDENTITY_MEMORY_KEYS = {
"preferred_name",
"nickname",
"ai_name",
"ai_emoji",
"assistant_name",
}
def _is_reserved_identity_memory_type(memory_type: str) -> bool:
return (memory_type or "").strip().lower() == "profile"
为什么要这么做?
因为“你以后叫我小王”“你的名字叫小派”这类设定,最好不要和普通 fact / preference 混在一起。
身份档案应该有更明确的单一真相来源。
否则后面很容易出现这种问题:
- profile 里一个名字
- memory 里又有一个名字
- 对话上下文里还残留一个旧名字
这种冲突很烦,而且不靠更大模型解决。
它本质上是数据层设计问题。
- 还有一层经常被忽略:执行状态持久化
光有短期记忆和长期记忆还不够。
Agent 还有一类状态,不完全属于“记忆”,但非常关键:
执行状态
。
比如这轮图已经走到哪个节点了、上一个步骤产出了什么、服务重启后还能不能接上。
这部分在backend/app/graph/workflow.py里是靠 checkpointer 顶住的:
async def get_graph():
...
checkpointer = MemorySaver()
try:
from langgraph.checkpoint.redis import AsyncRedisSaver, RedisSaver
...
if hasattr(candidate, "__aenter__"):
checkpointer = await candidate.__aenter__()
...
except Exception as exc:
if settings.allow_memory_checkpointer_fallback:
checkpointer = MemorySaver()
else:
raise RuntimeError("Redis checkpointer unavailable") from exc
这段代码的意思其实很简单:
- 正常情况下,图状态尽量放 Redis
- Redis 不可用时,再决定要不要降级到内存
我觉得这个点特别像真正的 Agent,而不是 demo。
因为 demo 只关心“这一轮跑出来没有”,真实系统还得关心:
- 中间状态丢了怎么办
- 连接断了怎么办
- 重启之后能不能恢复
三层关系:

十二、真正的闭环,是提醒真的发出去了
“闭环”很重要。
很多系统只闭环到“模型答完了”。
但如果用户说:
10 分钟后提醒我开会
你回复一句“好的”,10 分钟后什么都没发生,那这系统其实没干成事。
- 调度器怎么接住这件事
提醒真正执行这部分,在backend/app/services/scheduler_tasks.py:
async def send_reminder_job(schedule_id: int) -> None:
async with AsyncSessionLocal() as session:
schedule = await session.get(Schedule, schedule_id)
if not schedule or schedule.status != "PENDING":
return
user = await session.get(User, schedule.user_id)
if not user:
return
ok, success_count, total_count = await dispatch_reminder(
session=session,
sender=sender,
user=user,
schedule=schedule,
)
schedule.status = "EXECUTED" if ok else "FAILED"
await session.commit()
这个函数很像在说:
“前面的推理我不管了,现在只看这条提醒到时间了没有,以及它最后到底发没发出去。”
- 重启恢复为什么是必须的
我还专门做了启动恢复:
async def restore_pending_reminder_jobs() -> None:
scheduler = get_scheduler()
...
result = await session.execute(
select(Schedule).where(Schedule.status == "PENDING")
)
pending = list(result.scalars().all())
for row in pending:
run_at = row.trigger_time
if run_at <= now:
run_at = now
scheduler.add_job(row.job_id, run_at, send_reminder_job, row.id)
原因很简单。
你不能因为服务重启一次,就把用户待提醒的任务全弄丢。
这类功能一旦上线,用户默认就把它当“基础设施”看,而不是“AI 玩具”。
- 多端投递不是一条 send 就完了
真正的 fanout 在backend/app/services/reminder_dispatcher.py:
async def dispatch_reminder(
*,
session: AsyncSession,
sender: UnifiedSender,
user: User,
schedule: Schedule,
) -> tuple[bool, int, int]:
text = f"提醒:{schedule.content}"
targets = await _load_targets(session, user)
...
for target in targets:
row = await _upsert_delivery_row(session, schedule=schedule, target=target)
ok, err, attempts = await _send_target_with_retry(sender, user, schedule, target, text)
重试逻辑也很直白:
async def _send_target_with_retry(...):
delays = (0, 1, 3)
for idx, delay in enumerate(delays, start=1):
if delay > 0:
await asyncio.sleep(delay)
ok, err = await _send_target_once(...)
if ok:
return True, "", idx
return False, last_error, len(delays)
这里我特别想强调一点:
一个 Agent,要能回答“失败在哪里”这个问题。
所以我给每个目标端单独建了投递记录。
这意味着系统最后能知道:
- 发给了哪些平台
- 哪个平台失败了
- 失败了几次
- 错误是什么
- 有多少目标端成功
这才叫闭环。
不然你只能知道“模型当时说自己会提醒”,但不知道后面到底发生了什么。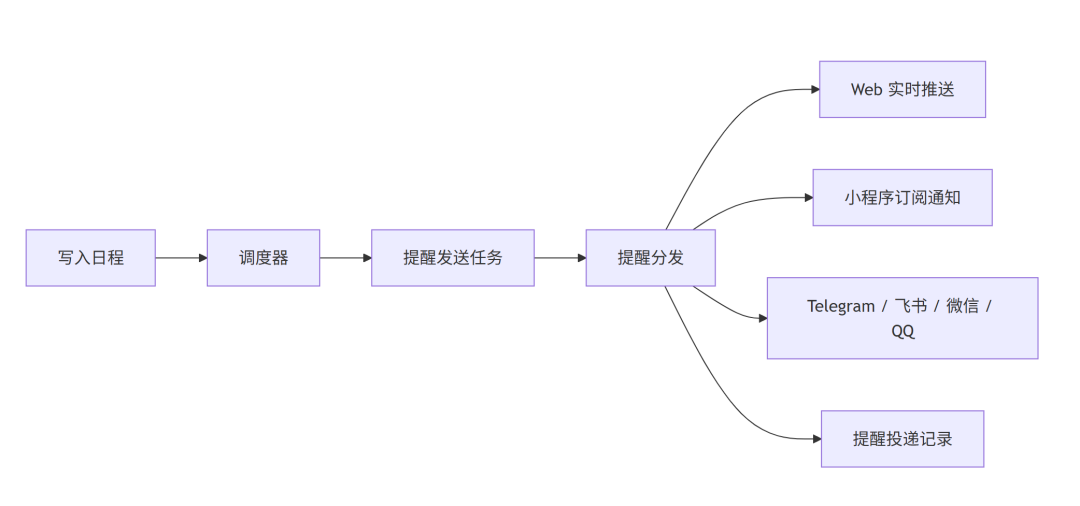
十三、这套系统为什么比“一个大 Agent”更稳
做到后面,我对 Agent 的一个判断越来越明确:
不是把一切都塞给一个超级 agent,系统就更高级。
很多时候正相反。
真正能上线、能维护、能排查的 Agent,往往都长得更像下面这样:
它更像一个带 LLM 的工作流系统,而不是一个“什么都交给模型自己决定”的黑盒。
我不是反对大一统 Agent。
只是从任务角度看,一旦你要处理:
- 多平台输入
- 多类任务
- 外部工具
- 长期记忆
- 异步执行
- 状态恢复
那分层和边界就会比“模型自主性”重要得多。
十四、如果你也在做 Agent,我建议先看这 5 个指标
我现在看一个 Agent 系统,会先问下面几个问题:
- 路由准不准
请求有没有进对节点?
- 规划稳不稳
复杂任务 plan 能不能执行,不是只能看看。
- 工具乱不乱
工具有没有边界、有没有治理、有没有调用记录。
- 记忆脏不脏
记忆有没有去重、有没有冲突、有没有单一真相来源。
- 闭环真不真
系统动作最后到底有没有发生,失败时能不能查到原因。
这 5 个问题,比“接了几个模型”“用了多少 prompt”更能说明一个 Agent 到底成熟到什么程度。
十五、最后一句
最大的感受是:
Agent 真正难的,从来不是让模型说得像人,而是让系统真的把事办了。
这也是我这篇文章最想讲的东西。
不是“我接了 LangChain 和 LangGraph”,而是:
我怎么把一句话,拆成可执行步骤;怎么把步骤接到工具;怎么把工具结果写进系统状态;怎么让未来动作继续发生;怎么在失败时还能知道失败在哪。
这些事都做对了,才能实现真正的 Agent。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)