MiniMax M3正式发布,体验实感,是夯爆了还是拉完了
刚刚M3发布了,一早上的体验,聊聊。
今天早上起来,我照例打开了 CC Switch。
这个动作我这几天大概做了二十次了。打开,点获取模型列表,看看minimax有没有更新,然后咔咔开始干活。
今天点完之后,列表里突然多了一行:
minimax-m3。
我盯着这行字看了几秒钟,好好好,终于发布了。
不是激动,不是兴奋,是一种很轻很安静的好奇。像是你住的小区楼下开了半年的围挡,今天早上你下楼买咖啡,发现围挡拆了,里面亮着灯,门口摆着一棵还没长开的圣诞树。
你知道它会开,但不知道它是什么。
M3 这个名字,得先解释一下。MiniMax 这家公司,过去几个月我一直在用它的 M2系列 写代码、改文档、做翻译。
M2 系列谈不上惊艳,但也算是个能用的老朋友。跑分不算顶尖,性能不算好,比起目前国产其他家的模型来说,甚至称得上拉完了,但是好歹速度快,便宜,支持一些简单的任务没问题。
而M3 的官方口径是「质变」。
arXiv 上的论文,X 上,VentureBeat 的报道,给了一堆数字,9.7 倍 prefill 加速,15.6 倍 decode 加速。我先记着这些数字,不急着信。
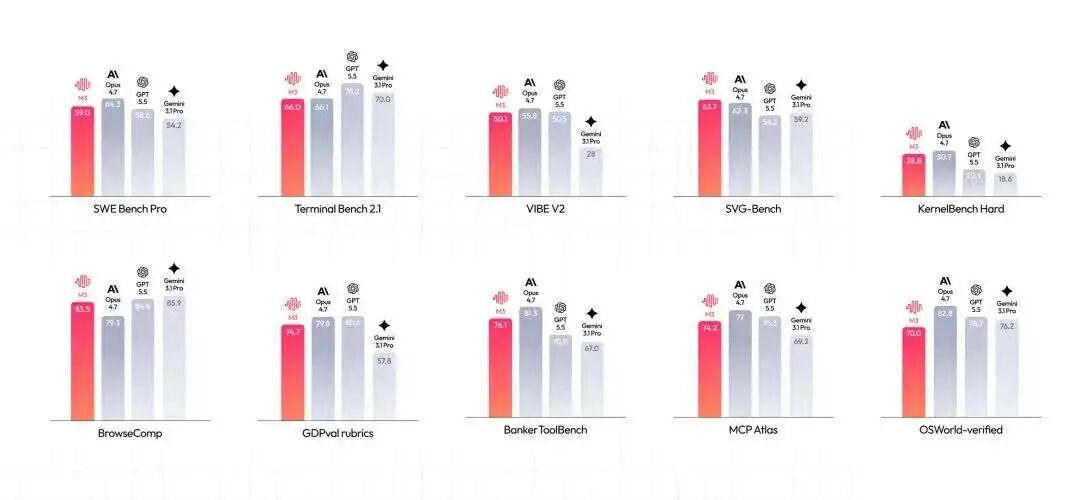
是骡子是马,我先遛一遛,等后面有空了分享一下深度体验结果。
本文没有收到广告费,放心食用,minimax团队要是看到,愿意给我投广就好了
思考的好像更深一点了
M3 给我最大的体感冲击,不是速度,是思考的深度。
M2.7 给我答案的时候,更像是「想到哪说到哪」,直接甩结果。M3 不一样,它思考的更久一点,更深一点,出错的概率要小很多

还有一点我得说。M3 思考的时候,会主动考虑「如果不是这个原因呢?」。它会列出 2 到 3 个可能的备选假设,再说明为什么排除某个、留下哪个。
这种「主动考虑反例」的习惯,在 benchmark 上看不出来,但在工程场景里救命。
M3 给我的体感是「它没在装,它真的在想」。
Agent 任务执行好像更好一点了
再讲深一档,M3 的 agent 任务执行,是真的不一样。
我让 M3 写这篇稿子的时候,给它的不是一段写好的素材,而是一句很糙的 prompt,「主题是 M3 上线了,聊聊我的第一体验,特别是比较DeepSeek V4来说」。
它接收到这个 prompt 之后,没有急着动笔。它自己识别出这个任务需要「先调研、再写」,于是先调起搜索类的 skills 去查 M3 的相关报道和 DeepSeek V4 的对比,再调起写作类的 skills 按特定风格成稿。
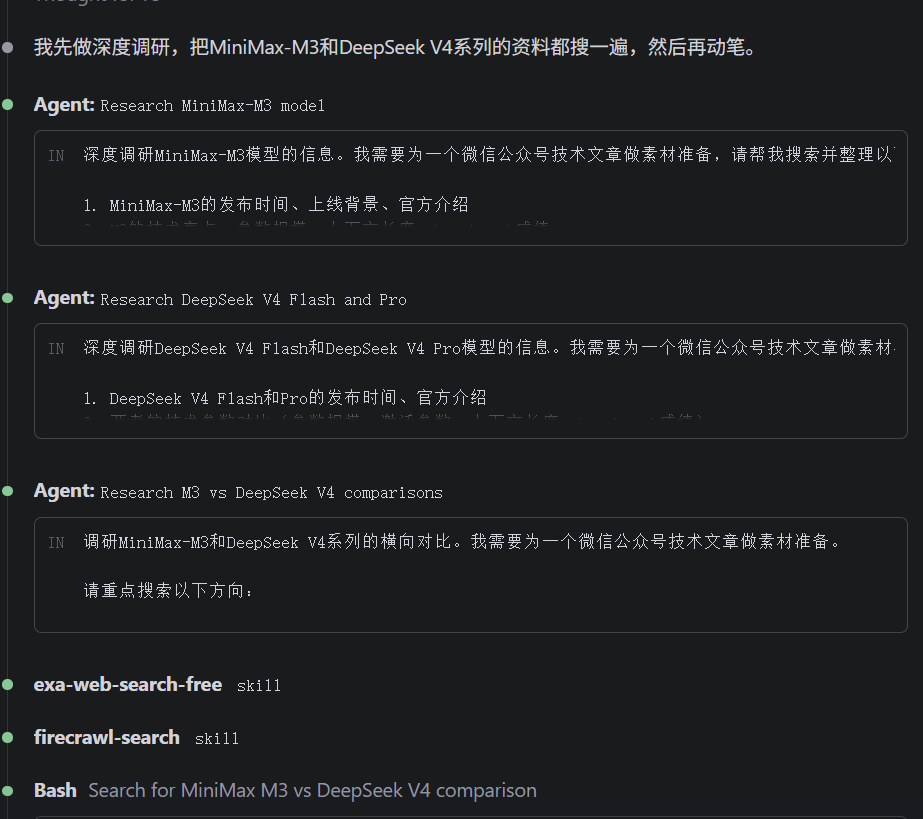
这种「主动拆解任务 + 积极调用工具」的能力,是 M3 真正让我觉得「升级」的地方。
M2.7 在这个场景下会怎么做呢?它会自己列一堆要写的点,然后直接开写。中间很少调工具,写出来的东西 80% 是基于它自己「以为」的,不是基于真实信息。
M3 的调用是「更主动的」。它会判断这个任务需要哪些能力,自己去调用对应的 skills。
比如我让它研究 M3 的技术细节,它会自己调起搜索技能、文档分析技能、对比分析技能,还主动创建了团队Agent,最后再决定怎么组织语言。
M3 给我的感觉,是它修好了 M2.7 的鬼打墙。
价格战还没开打,但已经闻到了火药味
把价格摆出来比一比。
V4 Flash,输入 0.14 美元每百万 token,输出 0.28。这个价格已经维持快一个月了,相当于「这是 DeepSeek 的地板价」。
V4 Pro,输入 0.435 美元每百万 token,输出 0.87。这是 5 月 22 日从限时促销转的永久价。
M3 的价格还没公布。但根据财讯通的判断,M3 会比 V4 更便宜。
也就是说,最有可能出现的情况是,M3 拿着 0.10 美元每百万 token 以下的输入价,去跟 V4 Flash 抢市场。
DeepSeek 这次 V4 发布的定价策略,明显是冲着 Anthropic 和 OpenAI 去的。一个 49B 激活的 MoE 模型,输出 0.87 美元每百万 token,是要把 Sonnet 4.5 的 15 美元和 Opus 4.7 的 25 美元按在地上摩擦。
但 V4 Flash 的 0.14/0.28 是冲着「自家人」来的。Flash 走量,Pro 走质。
M3 进来之后,定位就尴尬了。如果 M3 比 V4 Flash 便宜,那 V4 Flash 的市场就要被吃掉一部分。如果 M3 比 V4 Pro 便宜,那 V4 Pro 的「性价比之王」地位也要动摇。
不管哪种,国产模型这个赛道,2026 年下半年会非常好看。
算法驱动 vs 工程驱动,我选后者
讲到这,要说回到架构选择上。
V4 的 CSA+HCA 路线,说到底就是「算法驱动」。它赌的是通过极致的架构创新,让推理成本在长上下文场景下指数级下降。
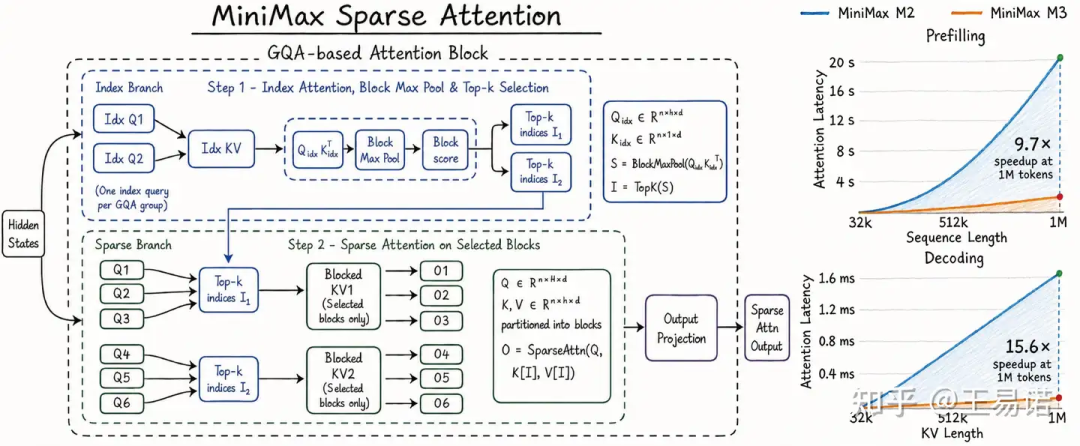
M3 的 MSA 路线,说到底就是「工程驱动」。它赌的是通过小幅度的架构修改,在现有推理框架上拿到大幅度的速度提升。
两种路线,都不是错的。
但我个人更看好 M3。
原因是,CSA+HCA 这种「先压缩再选」的方案有一个隐性的代价。压缩本身会损失信息。在某些关键场景下,比如代码 review、法律合同审查,压缩掉的 KV 可能恰好是用户最关心的那部分。
M3 的「不压缩直接选」,信息损失为零。代价是它的内存占用比 V4 大,但这个差距在硬件不断降价的趋势下,会越来越不重要。
还有一个更现实的考虑。CSA+HCA 需要专门的推理框架,V4 现在在 vLLM 和 SGLang 上的支持是有的,但属于「刚上线,还在调优」的状态。M3 的 MSA 几乎不需要改 vLLM 和 SGLang,官方说「无改动即可复用」。
在开源生态里,工程友好性比算法先进性更重要。
国产模型除了拼跑分、拼价格、拼上下文长度之外,还可以拼别的东西。
比如,像不像一个活人、对工程友不友好、指令遵循能力如何、技能调用是否积极。
这种东西,很难量化。
但很难量化的事情,往往是最重要的。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 8
8 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)