使用 ControlFlow 构建 3 个有趣的 AI 应用
AI 行业正快速迈向利用大型语言模型(LLMs)构建解决方案并最大化 AI 模型潜力的方向。企业正在寻求能将 AI 无缝集成到现有代码库中的工具,从而避免雇佣专业人员和获取资源所带来的高额成本。这正是 ControlFlow 的用武之地。借助 ControlFlow,你只需几行代码就能开发复杂的 AI 应用。在本教程中,我们将探索 ControlFlow,并用它来构建三个有趣的 AI 应用。这些项
【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。

前言
AI 行业正快速迈向利用大型语言模型(LLMs)构建解决方案并最大化 AI 模型潜力的方向。企业正在寻求能将 AI 无缝集成到现有代码库中的工具,从而避免雇佣专业人员和获取资源所带来的高额成本。这正是 ControlFlow 的用武之地。借助 ControlFlow,你只需几行代码就能开发复杂的 AI 应用。
在本教程中,我们将探索 ControlFlow,并用它来构建三个有趣的 AI 应用。这些项目涵盖从简单的文本分类器到由多个智能体、任务和流程组成的复杂 AI。
什么是 ControlFlow?
ControlFlow 是一个 Python 框架,为定义 LLM 工作流提供结构化方法。它包含三个构建 AI 应用的核心组件:
- Tasks(任务):AI 工作流的基本构建块。它们定义了需要一个或多个智能体完成的、离散且明确定义的目标。
- Agents(智能体):驱动 AI 工作流的智能自主实体。你可以为其指定模型、提供自定义指令,并添加各种工具来构建智能体。
- Flows(流程):用于按指定顺序运行多个 AI 工作流。它们提供了一种结构化方式来管理任务、智能体、工具和共享上下文。
通过使用 ControlFlow,你可以将 AI 能力无缝集成到 Python 应用中,更好地掌控 AI 工作流,并生成结构化输出而不仅仅是文本。它让你轻松构建复杂工作流,并且极为易用。ControlFlow 的最大优势在于,你能够在每个任务中观察 AI 模型的决策过程。
简而言之,ControlFlow 的两大核心用途是:编排 LLM 工作流,以及帮助生成结构化输出,从而让你对 AI 拥有更高的掌控力。
ControlFlow 的安装与配置
在终端输入以下命令安装 ControlFlow,依赖会自动安装:
$ pip install controlflow
生成 OpenAI API key,并将其设置为环境变量:
$ export OPENAI_API_KEY="your-api-key"
在使用 ControlFlow 前,确保其已正确安装。输入以下命令即可查看所有与 ControlFlow 相关的 Python 包版本:
$ controlflow version
输出示例:
ControlFlow version: 0.9.4
Prefect version: 3.0.2
LangChain Core version: 0.2.40
Python version: 3.10.12
Platform: Linux-6.1.85+-x86_64-with-glibc2.35
Path: /usr/local/lib/python3.10
创建智能体并运行任务
在 ControlFlow 中,创建一个智能体并运行任务非常简单。以下示例中,我们创建了一个“恐怖故事讲述者”智能体,通过提供自定义指令来设定其行为。
随后,我们用它运行一个简单任务,给出提示,最终生成一篇短故事。
import controlflow as cf
teller = cf.Agent(name="Horror Storyteller",
model="openai/gpt-4o",
instructions="You are an older man telling horror stories to kids.")
story = cf.run("Write a short story.", agents=[teller])
生成结果如下:

如果在 Colab 中运行以下代码时遇到 RuntimeError 或运行问题,请重新执行一次代码单元。
1. 推文分类
推文分类器是学生常见的小型项目,通常需要花费数月时间才能构建出一个合格的文本分类器。借助 ControlFlow,我们只需几行代码即可实现一个推文分类器。
步骤:
1.创建一个包含 4 条短推文的列表。
2.使用 GPT-4-mini 模型,并通过自定义指令设置智能体。
import controlflow as cf
tweets = [
"Negativity spreads too easily here. #sigh",
"Sometimes venting is necessary. #HateTherapy",
"Love fills the air today! 💖 #Blessed",
"Thankful for all my Twitter friends! 🌟"
]
# 创建一个专门的分类智能体
classifier = cf.Agent(
name="Tweet Classifier",
model="openai/gpt-4o-mini",
instructions="You are an expert at quickly classifying tweets.",
)
3.创建一个任务,用于将推文分类为 “hate” 或 “love”,并指定提示语、结果类型、智能体和上下文。我们将推文列表作为上下文输入。
4.运行任务并显示结果。
from typing import Literal
# 设置 ControlFlow 任务来分类推文
classifications = cf.run(
'Classify the tweets',
result_type=list[Literal['hate', 'love']],
agents=[classifier],
context=dict(tweets=tweets),
)
print(classifications)
ControlFlow 任务会将推文分类,并生成一个标签列表。
中文翻译:
1. "Negativity spreads too easily here. #sigh"
消极情绪在这里传播得太容易了。#叹气
2. "Sometimes venting is necessary. #HateTherapy"
有时候发泄是必要的。#仇恨疗法
3. "Love fills the air today! 💖 #Blessed"
今天空气中充满了爱!💖 #感恩
4. "Thankful for all my Twitter friends! 🌟"
感谢我所有的朋友们!🌟

我们可以通过颜色编码展示分类结果(红色表示 hate,绿色表示 love)。
# ANSI 颜色代码
GREEN = '\033[92m'
RED = '\033[91m'
RESET = '\033[0m'
# 打印推文及分类结果,分类结果带颜色
for twt, cls in zip(tweets, classifications):
if cls == 'hate':
print(f"Tweet: {twt} | Classification: {RED}{cls.upper()}{RESET}\n")
else:
print(f"Tweet: {twt} | Classification: {GREEN}{cls.upper()}{RESET}\n")
最终输出中,两条推文被标记为 “hate”,另外两条被标记为 “love”。结果相当准确,并且以结构化的形式输出,方便集成到现有应用中。

2. 图书推荐器
在本项目中,我们将使用 Pydantic 模型 定义图书推荐应用的数据模型。该模型确保每条推荐结果都包含书名、作者、出版年份和类别,并且字段类型正确。
recommend_books 函数会使用这个 Pydantic 模型来定义返回结果类型,并根据指定的类别和数量生成推荐书籍列表。
import controlflow as cf
from pydantic import BaseModel, Field
class BookRecommendation(BaseModel):
title: str = Field(description='The title of the recommended book')
author: str = Field(description='The author of the book')
year_published: int = Field(description='The year the book was published')
genre: str = Field(description='The genre of the book')
def recommend_books(genre: str, count: int) -> list[BookRecommendation]:
return cf.run(
f"Recommend {count} books in the {genre} genre with their details",
result_type=list[BookRecommendation],
context={"genre": genre, "count": count}
)
现在我们生成 5 本科幻类书籍:
recommended_books = recommend_books(genre="Science Fiction", count=5)
print(recommended_books)
智能体首先以文本形式生成推荐书籍,然后将其转换为 JSON 格式,最后映射为 Pydantic 模型类型,保证所有数据字段类型正确。
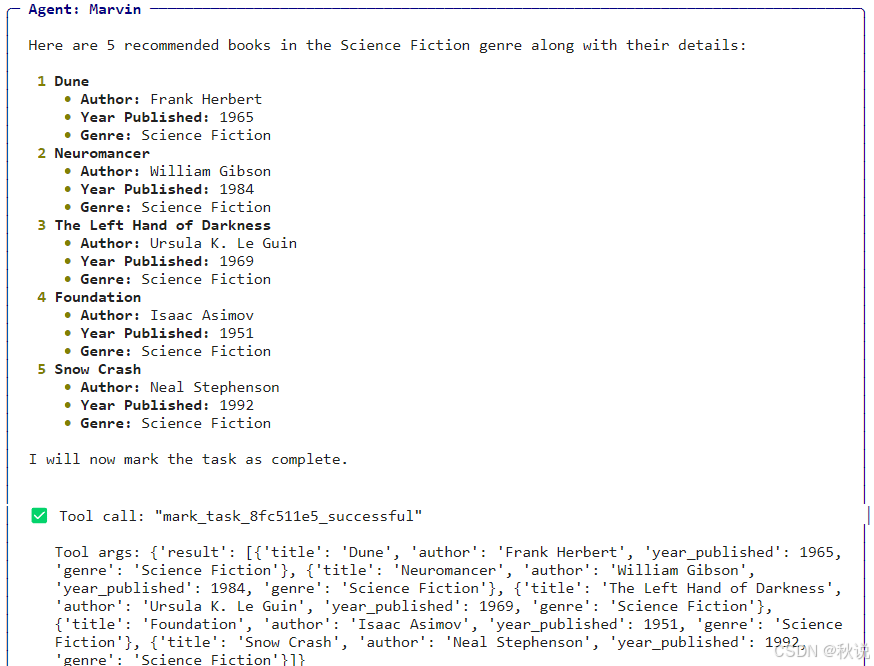
[
BookRecommendation(title='Dune', author='Frank Herbert', year_published=1965, genre='Science Fiction'),
BookRecommendation(
title='Neuromancer',
author='William Gibson',
year_published=1984,
genre='Science Fiction'
),
BookRecommendation(
title='The Left Hand of Darkness',
author='Ursula K. Le Guin',
year_published=1969,
genre='Science Fiction'
),
BookRecommendation(title='Foundation', author='Isaac Asimov', year_published=1951, genre='Science Fiction'),
BookRecommendation(
title='Snow Crash',
author='Neal Stephenson',
year_published=1992,
genre='Science Fiction'
)
]
若要将输出转换为 JSON 格式,只需调用 .model_dump_json(indent=2):
for book in recommended_books:
print(book.model_dump_json(indent=2))
输出结果为 JSON,可轻松集成到 Web 应用或任意代码库:
{
"title": "Dune",
"author": "Frank Herbert",
"year_published": 1965,
"genre": "Science Fiction"
}
{
"title": "Neuromancer",
"author": "William Gibson",
"year_published": 1984,
"genre": "Science Fiction"
}
{
"title": "The Left Hand of Darkness",
"author": "Ursula K. Le Guin",
"year_published": 1969,
"genre": "Science Fiction"
}
{
"title": "Foundation",
"author": "Isaac Asimov",
"year_published": 1951,
"genre": "Science Fiction"
}
{
"title": "Snow Crash",
"author": "Neal Stephenson",
"year_published": 1992,
"genre": "Science Fiction"
}
3. 旅行规划助手
在这个项目中,我们将连接两个任务:
- 第一个任务根据用户偏好生成旅行目的地;
- 第二个任务基于该目的地创建详细的行程安排。
要实现这一项目,我们将使用多个智能体、多个任务,并通过flow将它们组合起来。
我们将定义两个模型类:
- TravelPreferences(旅行偏好):用于用户输入。
- TravelItinerary(旅行行程):用于输出结构。
同时,我们会创建一个 flow 函数,其中包含两个任务:
- 根据用户偏好推荐目的地;
- 根据推荐目的地生成“n”天的行程计划。
import controlflow as cf
from pydantic import BaseModel
from typing import List
# 创建专门的智能体
destination_recommender = cf.Agent(name="DestinationRecommender", model="openai/gpt-4o-mini")
itinerary_planner = cf.Agent(name="ItineraryPlanner", model="openai/gpt-4o")
# 定义数据模型
class TravelPreferences(BaseModel):
preferred_activities: List[str]
budget: str # 例如: "low", "medium", "high"
travel_duration: int # 天数
preferred_region: str # 例如: "Asia", "Europe", "South America"
class TravelItinerary(BaseModel):
destination: str
daily_schedule: List[str]
@cf.flow
def create_travel_itinerary(preferences: TravelPreferences) -> TravelItinerary:
# 推荐目的地
destination = cf.run(
"Suggest a travel destination based on user preference.",
agents=[destination_recommender],
result_type=str,
context={
"preferred_activities": preferences.preferred_activities,
"budget": preferences.budget,
"travel_duration": preferences.travel_duration,
"preferred_region": preferences.preferred_region
}
)
# 基于目的地制定每日行程
daily_schedule = cf.run(
"Create a daily schedule for the trip at the chosen destination",
agents=[itinerary_planner],
result_type=List[str],
context={
"destination": destination,
"travel_duration": preferences.travel_duration,
"preferred_activities": preferences.preferred_activities
}
)
return TravelItinerary(destination=destination, daily_schedule=daily_schedule)
熟悉 ControlFlow 工作流编码后,你会发现仅用几行代码就能轻松创建新的应用和项目。
我们现在定义用户偏好(活动、预算、时长、地区),并基于这些偏好运行 flow:
preferences = TravelPreferences(
preferred_activities=["beach", "local cuisine"],
budget="medium",
travel_duration=7,
preferred_region="Europe"
)
# 生成个性化旅行行程
itinerary = create_travel_itinerary(preferences)
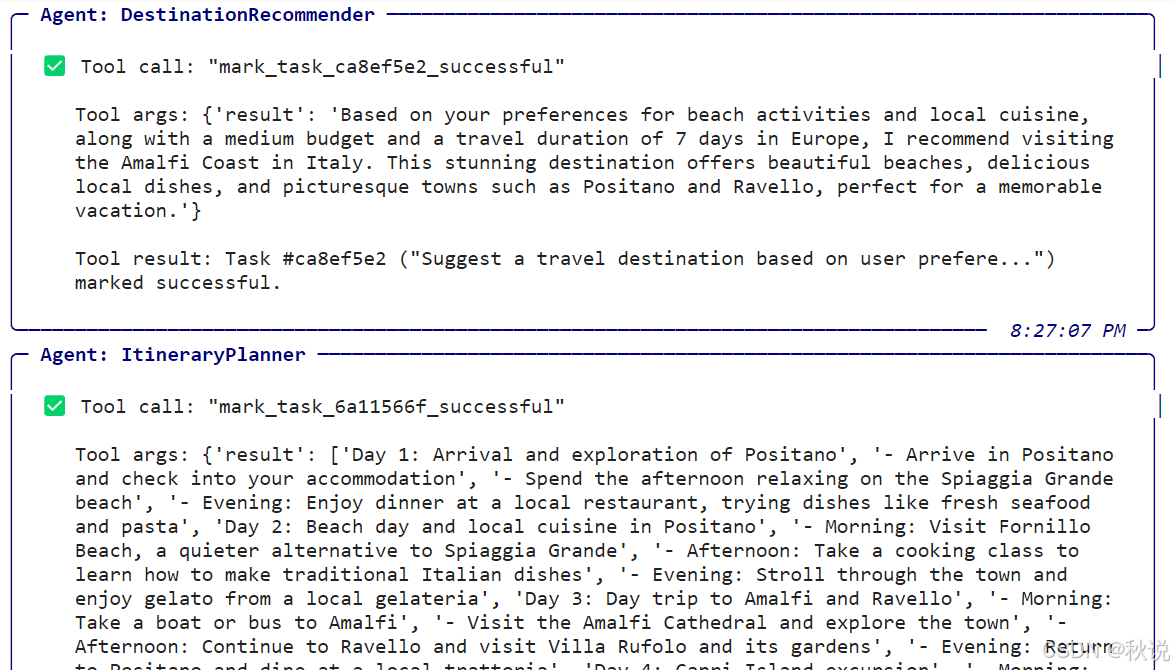
打印推荐结果与行程:
print("Recommended Destination:")
print(f"- {itinerary.destination}")
print("\n\nDaily Schedule:")
for schedule in itinerary.daily_schedule:
print(f"{schedule}")
输出结果如下:
推荐目的地:
基于你对海滩活动和当地美食的偏好,以及中等预算和在欧洲旅行 7 天的设定,我推荐你前往 意大利阿马尔菲海岸。这里拥有迷人的海滩、美味的当地菜肴,以及如波西塔诺和拉韦洛等风景如画的小镇,非常适合一次难忘的假期。
每日行程:
第 1 天:抵达与波西塔诺探索
抵达波西塔诺并办理入住
下午在 Spiaggia Grande 海滩放松
晚上在当地餐厅享用晚餐,尝试新鲜海鲜和意大利面
第 2 天:波西塔诺的海滩与美食
上午:前往 Fornillo Beach(更安静的海滩)
下午:参加烹饪课程,学习制作传统意大利菜
晚上:漫步小镇,品尝当地冰淇淋店的意式冰淇淋
第 3 天:阿马尔菲与拉韦洛一日游
上午:乘船或巴士前往阿马尔菲
参观阿马尔菲大教堂并探索小镇
下午:继续前往拉韦洛,参观鲁弗洛别墅及其花园
晚上:返回波西塔诺,在当地小餐馆用餐
第 4 天:卡普里岛游览
上午:乘渡轮前往卡普里岛
探索蓝洞,乘坐缆车登上索拉罗山
下午:游览卡普里小镇并享用午餐
晚上:返回波西塔诺,在住宿地休息
第 5 天:波西塔诺休闲日
上午:在 Arienzo 海滩放松(以清澈海水闻名)
下午:在海边咖啡馆享用悠闲午餐
晚上:乘船观看海岸日落
第 6 天:索伦托探索
上午:乘巴士或渡轮前往索伦托
参观历史中心,包括塔索广场和马里纳格兰德港口
下午:在当地餐厅用餐并品尝柠檬酒
晚上:返回波西塔诺
第 7 天:离开
上午:在波西塔诺购买纪念品
下午:前往机场或下一站目的地
我们可以很容易地将该项目转换为一个产品,并搭建一个网站,为用户提供个性化的旅行推荐。
总结
我们应当专注于构建能真正产生商业价值的 AI 解决方案,而不是仅仅追求模型精度的微小提升。要释放 AI 的全部潜力,我们需要像 ControlFlow、LangChain 这样的工具和框架,它们能帮助我们仅用几行代码就构建复杂的 AI 应用。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)