【干货收藏】Chain-of-Agents:将专家团队压缩进一个模型,AI智能体的未来
Chain-of-Agents(CoA)是一种创新的大模型范式,通过多智能体蒸馏和强化学习将多智能体协作内化到单一模型中。实验显示,该方法在Web和Code任务上表现优异,计算效率提升84.6%,在多项基准测试中达到SOTA水平。CoA不仅实现了类似多智能体系统的复杂协作能力,还保持了单体模型的高效性,为构建更强大的AI智能体提供了新思路。
Chain-of-Agents (CoA)是一种新型大模型范式,将多智能体协作"内化"到模型内部,通过多智能体蒸馏和强化学习训练的智能体基础模型(AFM)在多项任务上达到SOTA性能。相比传统方法计算效率提升84.6%,展现出强大的泛化能力。CoA代表了大语言模型智能体研究的重要方向,为构建通用、高效、强大的AI智能体提供了新路径。

- 论文:Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL
- 链接:https://arxiv.org/pdf/2508.13167
本篇论文提出的 Chain-of-Agents (CoA) 范式,旨在取两家之长,弃两家之短。它希望在一个模型内部,原生地、端到地实现复杂问题解决,其能力堪比一个多智能体系统,但其形态和效率却像一个TIR模型。这就像是把一整个专家团队的知识和协作模式,“压缩”进了一个全能型天才的大脑里。论文还详细介绍了如何通过多智能体蒸馏(Multi-Agent Distillation) 和智能体强化学习(Agentic RL) 来训练这种新型的“智能体基础模型(Agent Foundation Models, AFMs)”,并用详实的实验证明了其在多项任务上达到了新的 state-of-the-art (SOTA) 性能。
Chain-of-Agents(CoA)
设计理念:内化的协作
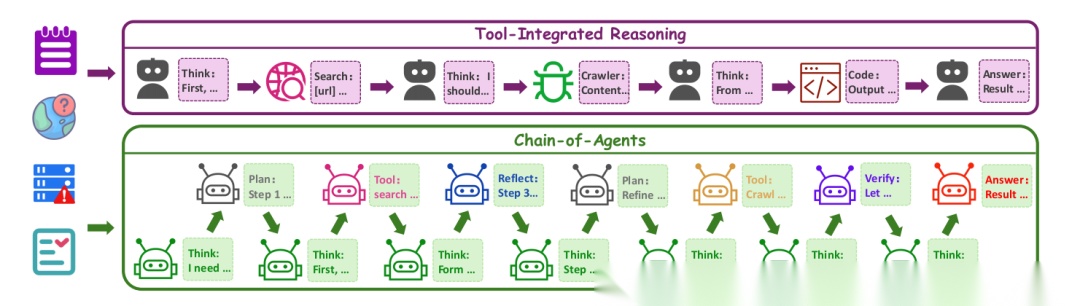
CoA的核心思想非常直观:为什么不把一个多智能体系统的协作过程,看作是模型内部的一种特殊“思维链”呢? 传统的思维链是“一步一步地想”,而CoA是“一个角色一个角色地切换着去想和做”。
在CoA范式中,给定一个复杂查询(如“总结近期AI重大突破”),模型不会固定地执行“想-搜-读”的循环。相反,它会在内部动态地激活不同的“子模块”或“角色”:
- 角色扮演智能体(Role-playing Agents):负责高层次的认知和协调。
思考智能体:总指挥,负责激活其他智能体并保持解题状态的连贯性。规划智能体:大师,负责将复杂问题分解成有结构的任务序列(如先搜索,再爬取,再分析)。反思智能体:批评家,负责检查知识的一致性,进行自我批判和修正。验证智能体:质检员,根据正式标准验证推理过程的完整性。
- 工具智能体(Tool Agents):负责执行具体的领域任务。
搜索智能体:搜索引擎高手,负责生成和优化搜索查询。爬取智能体:网络爬虫,负责从网页中并行提取和解析内容。代码生成智能体:程序员,负责在安全沙箱中生成和执行代码。
运作机制:动态编排
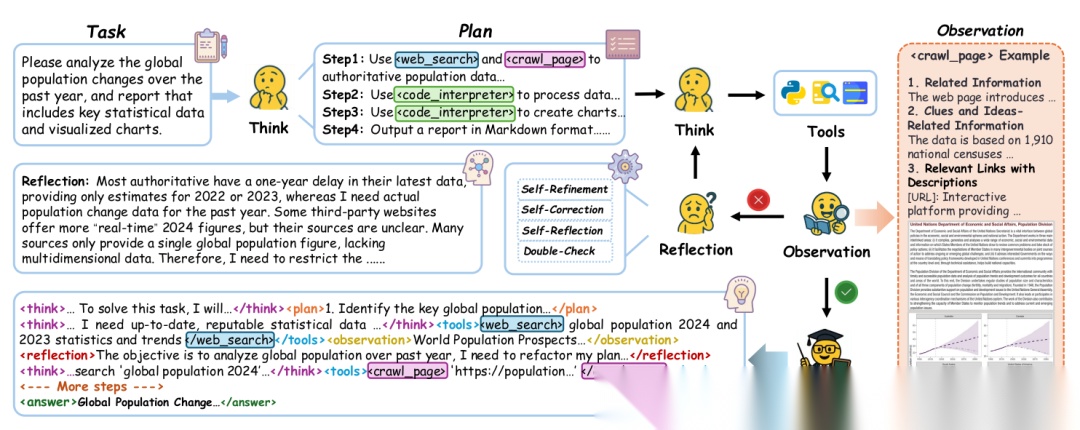
CoA的整个工作流程可以用一个状态转移方程来抽象地描述:
- 代表在时间步 模型内部的持久推理状态。它可以理解为当前解决问题的“工作记忆”或“上下文”,包含了之前所有的思考、行动结果和观察。
- φ 代表在时间步 被激活的智能体角色(例如,φ, φ, φ)。
- θ 是模型本身(参数为θ),它根据前一状态 、前一个角色 φ 的执行结果 ,来更新当前的状态 。
- 然后,模型再基于当前状态 ,抽样决定下一个要激活的角色 φ。
这个过程完全在一次模型推理(解码)过程中完成,不同角色间的切换和协作没有额外的通信开销,实现了高效的内化协作。
优势对比:全面领先

上表清晰地对比了CoA与其它范式的优劣。CoA是唯一一个在工具集成、端到端执行、多智能体协作和数据中心优化四个维度上全部获得“✓”的方案。这意味着:
- vs. ReAct:CoA支持多智能体协作,而ReAct是单智能体。
- vs. 传统MAS:CoA是端到端可训练的,计算效率更高,避免了智能体间冗余的通信。
- vs. TIR:CoA支持真正的多智能体协作模式,而TIR仅限于ReAct模式。
如何炼成“智能体基础模型”(AFM)
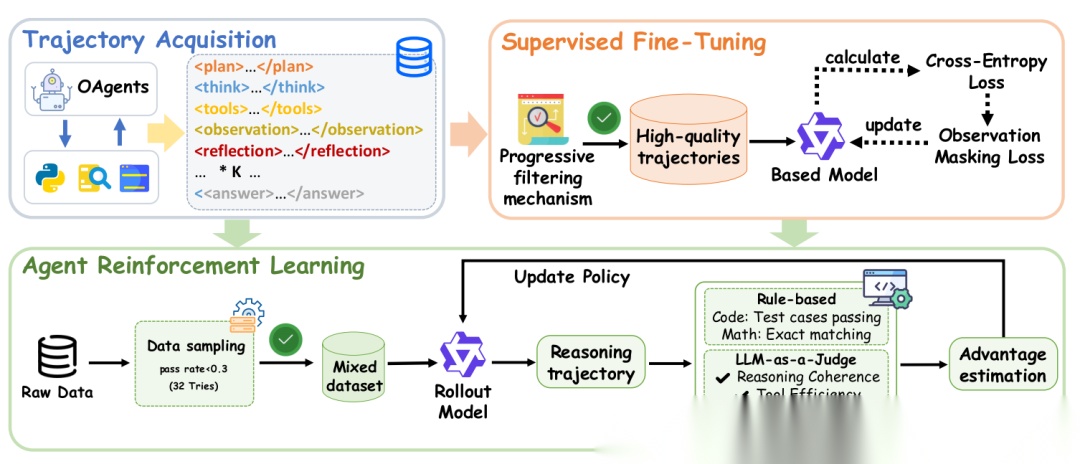
拥有一个美好的架构蓝图(CoA)只是第一步,如何让一个普通的LLM学会这种复杂的内部协作模式才是真正的挑战。论文提出了一个两阶段的训练框架。
阶段一:智能体监督微调(SFT)—— 模仿专家
目标是让模型“学会”CoA的行为模式。方法是多智能体知识蒸馏。
- 数据生成:研究者利用当时最先进的开源多智能体系统(如OAgents[82])作为“教师”,让它们去解决大量的复杂任务(如“在GAIA基准上的问题”)。然后,全程记录下这些“教师团队”的解决轨迹:哪个智能体在什么时候被激活、它看到了什么、它做了什么、输出了什么。
- 轨迹转换:将这些原始的、分布在多个智能体上的协作轨迹,转换成一条单一的、序列化的“CoA轨迹”。这条轨迹看起来就像是一个模型自己产生的、交替出现思考、工具调用和观察的复杂推理链。
- 渐进式质量过滤:生成的轨迹质量不一,需要严格筛选。
- 复杂度过滤:过滤掉交互次数太少(<5次)的简单任务。
- 质量过滤:用LLM或代码执行等方式验证答案是否正确,去除“脏数据”。
- 反思 enrichment:优先选择那些包含自我反思、自我修正步骤的高质量轨迹。
- 错误修正轨迹上采样:特别青睐那些一开始出错但通过反复检查最终做对的轨迹,这能教会模型纠错能力。
经过过滤后,用于SFT的数据集包含约1.6万条高质量轨迹,其推理链长度(5-20步)远超传统基准(2-3步)。
模型的训练目标就是预测CoA轨迹中的每一个token(除了观察结果,因为那是外部环境的信息,不应让模型去学习预测噪声)。
阶段二:智能体强化学习(RL)—— 精益求精
SFT阶段让模型“学会”了行为,RL阶段则要让它“做得更好”。其核心是奖励函数,用来告诉模型什么样的行为是好的。
- 数据采样:从开源数据集中筛选出那些真正需要工具才能解决的、有挑战性的查询。
- Web Agent:先用一个强大的LLM(Qwen-72B)尝试直接回答问题,如果正确率超过30%,说明这个问题可能不需要工具或已被模型记忆,则被过滤掉。剩下的才是RL训练的“硬骨头”。
- Code Agent:用一个较小的AFM模型尝试多次解决问题,如果一个题目每次都能被轻松解决,说明它不够难,也会被丢弃。
- 奖励函数设计:
- Web Agent奖励 (
R_web) :结果导向。直接使用LLM-as-a-Judge(让另一个LLM当裁判)来判断最终答案是否正确。正确则奖励为1,否则为0。这种设计简单直接,避免了复杂的奖励塑造可能带来的问题。 - Code Agent奖励 (
R_code) :结果+格式。奖励 =score_answer * score_format。score_answer由代码是否通过测试或答案是否正确决定(1或0)。score_format则检查工具调用(如代码块)的格式是否正确(1或0)。这意味着,即使代码逻辑正确,如果格式错误导致无法执行,也得不到奖励。
通过RL优化,模型在SFT“模仿”的基础上,进一步学会了如何更高效、更可靠地协调工具来解决难题。
实验验证
论文在Web和Code两大智能体任务上进行了 exhaustive 的实验,结果真不错。
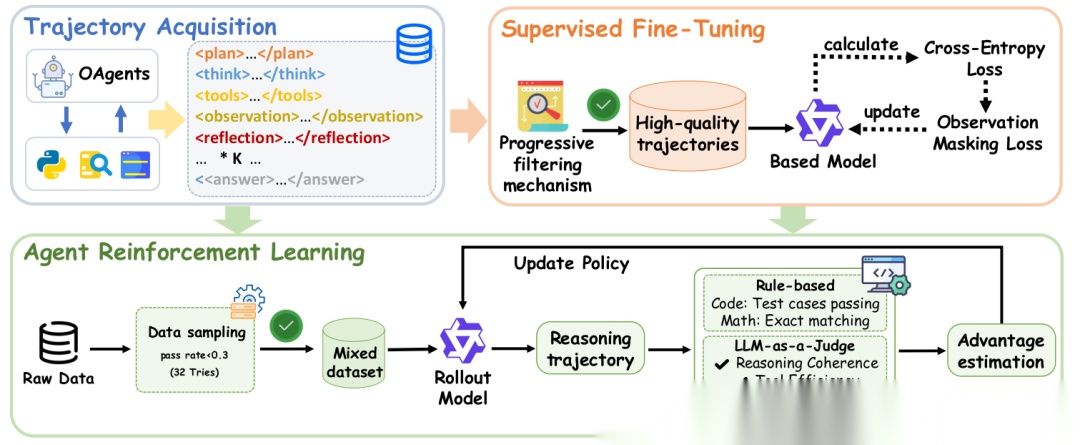
Web Agent实验
- 多跳问答(MHQA):在7个不同的数据集上,AFM模型(无论是SFT还是RL版本)在同等参数规模下,平均性能全面超越了之前的SOTA方法(如Search-R1, ZeroSearch等)。这表明多智能体蒸馏成功地将协作 intelligence 注入了模型。
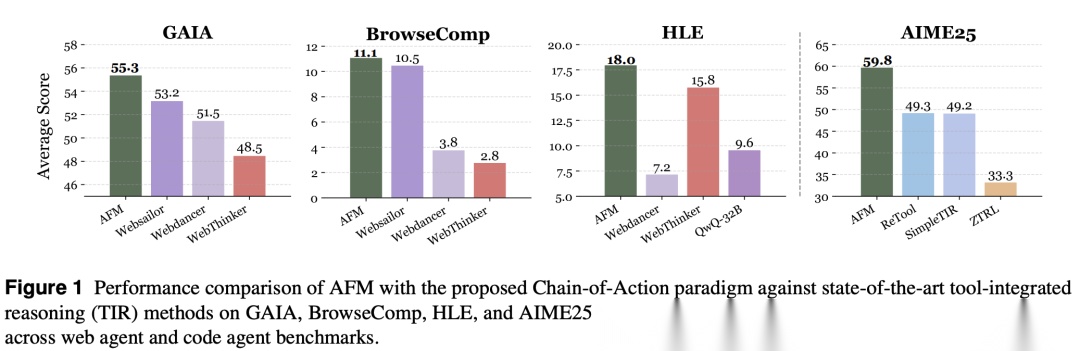
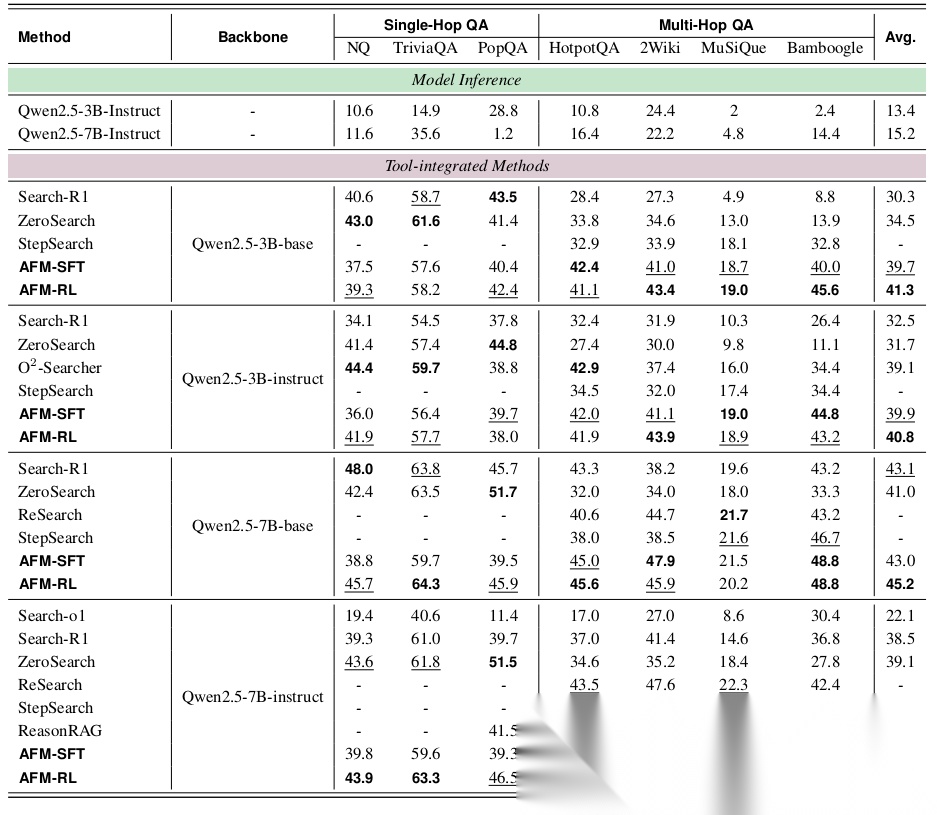
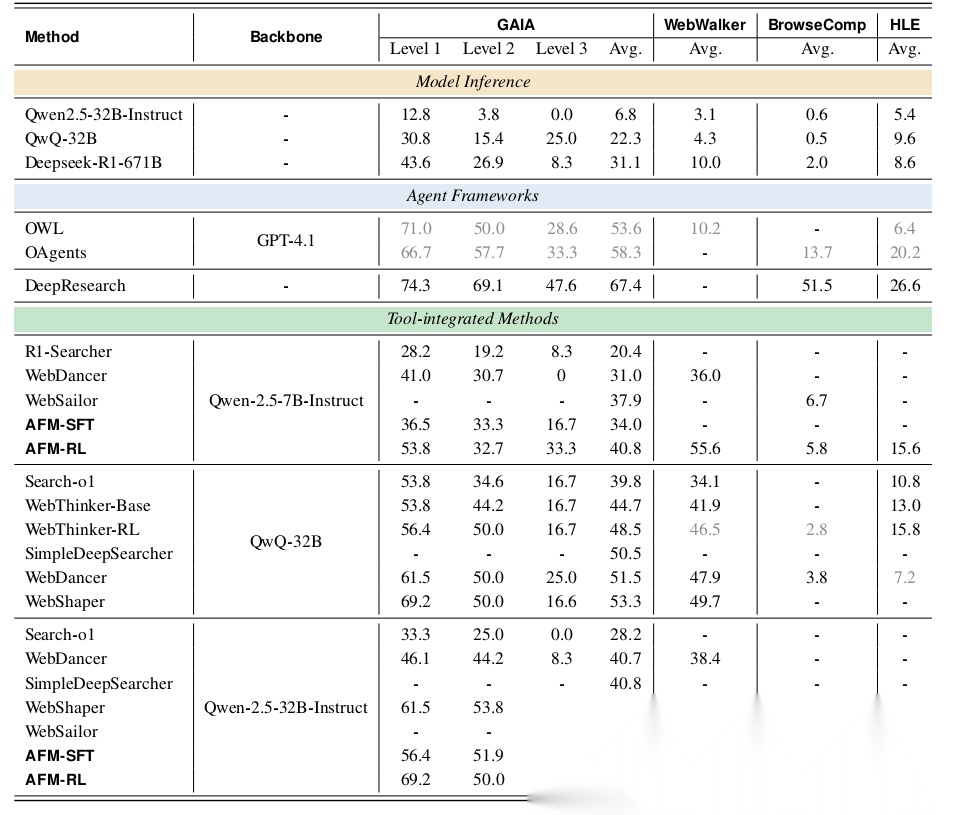
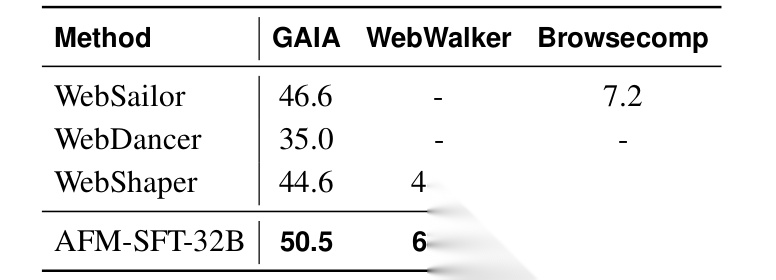
- 复杂Web任务(GAIA, BrowseComp, HLE):这是真正的“硬核”测试。AFM-32B在GAIA上达到了55.3% 的准确率,超越了所有同规模的TIR模型,甚至逼近了使用GPT-4.1作为核心的庞大Agent框架(如OWL, OAgents)的性能。在衡量前沿学术能力的HLE基准上,AFM-32B也取得了18.0% 的优异成绩,显著优于其他对比模型。
特别值得注意的是仅经过SFT的AFM模型(AFM-SFT) 就已经表现非常出色,这强有力地证明了多智能体蒸馏框架本身的有效性,而RL是在此基础上的进一步精炼。
Code Agent实验
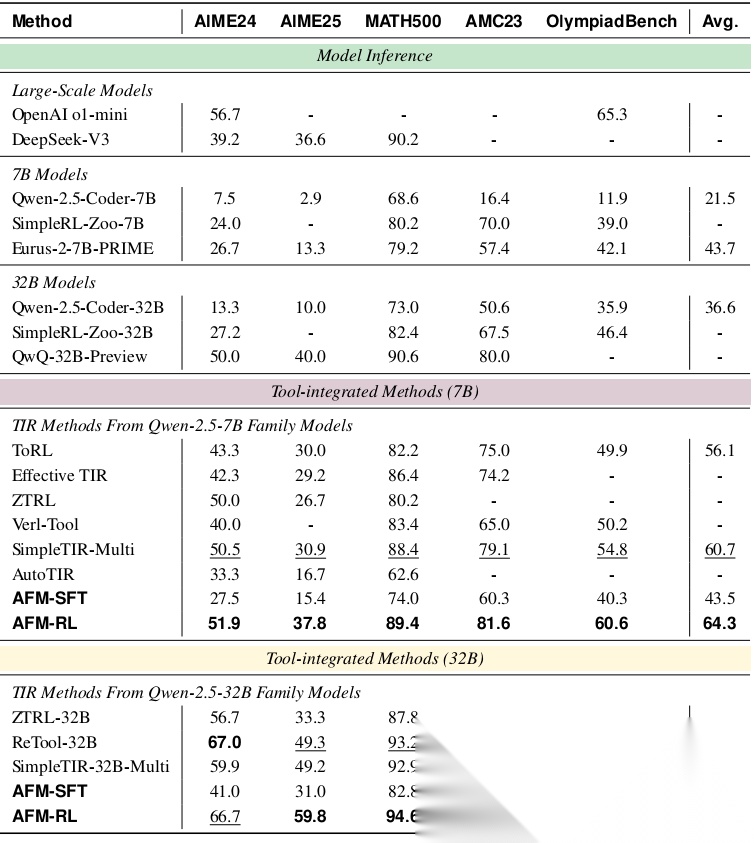
- 数学推理:在AIME、MATH500、AMC等从高中到奥林匹克难度的数学竞赛题上,AFM-7B和AFM-32B都创造了新的SOTA。例如,在最具挑战性的AIME2025上,AFM-32B达到了59.8% 的解决率,相比之前的Best方法(ReTool-32B, 49.3%)实现了10.5% 的绝对提升。
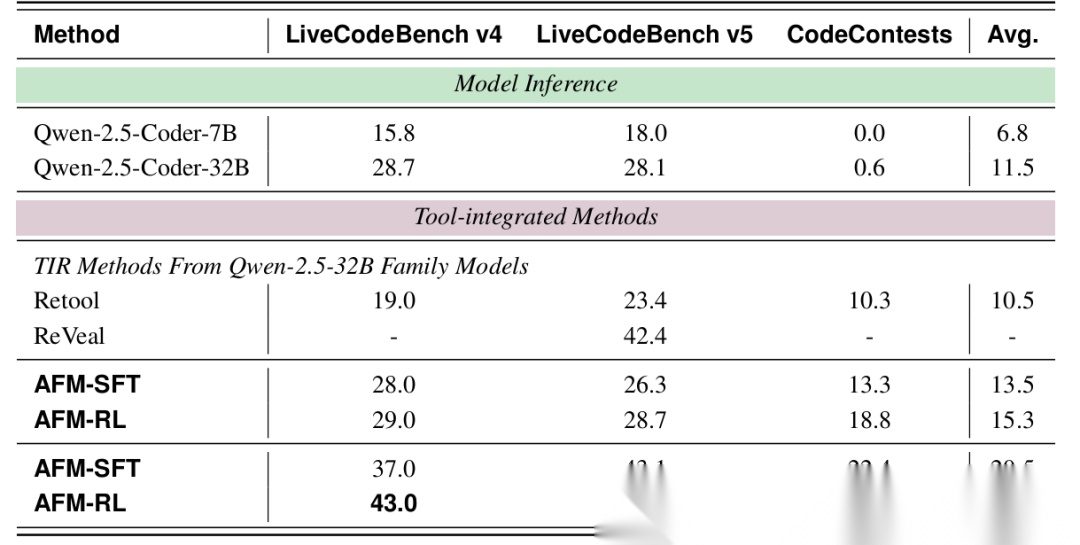
- 代码生成:在LiveCodeBench和CodeContests等编程竞赛题库上,AFM同样显著领先于仅依赖内部知识的模型和其他的TIR方法。
效率分析
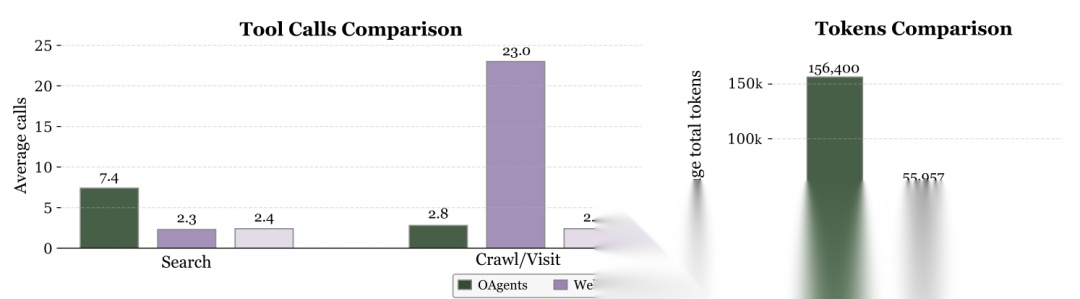
与传统多智能体系统(如OAgents)和TIR方法(如WebThinker)相比,AFM在解决相同任务时,令牌消耗降低了84.6%,并且所需的工具调用次数也更少。这得益于其端到端的内化协作,消除了智能体间大量的通信开销。效率的提升对于实际应用至关重要。
泛化性分析
一个有趣的实验是:将一个只在“代码”任务上训练过的AFM模型,突然赋予它“网页搜索”和“视觉检查”等它从未见过的工具描述,它能否正确使用?
结果是:可以! 模型能够严格遵循提示词中的格式要求,在第一次尝试中就正确协调使用了这些新工具。这证明了CoA范式强大的零样本泛化能力。反之,一个只在“网页”任务上训练的模型,在面对需要严格代码格式的工具时则表现不佳,这突显了代码训练带来的格式严谨性的优势。
测试时扩展(TTS)分析
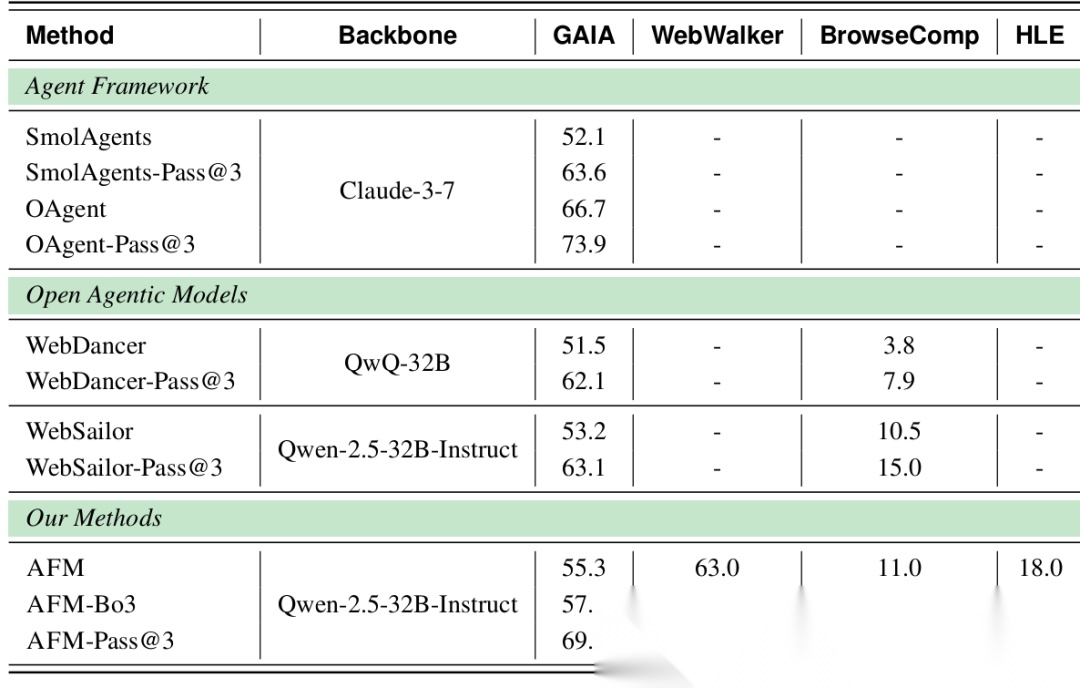
测试时扩展(Test-Time Scaling)是指通过多次采样(如多次尝试并选择最佳结果)来提升模型表现。论文发现,AFM模型(AFM-Pass@3)从TTS中获得的性能提升远大于其他模型。例如,在GAIA上,AFM-Pass@3比单次采样(AFM)的性能高出14.6个百分点,而其他模型的提升通常在10个百分点左右。这表明CoA模型具有更高的“潜力上限”,可以通过投入更多计算资源来获得更大幅度的性能提升。
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)