腾讯开源多模态 RAG:复杂文档秒变自建知识库,支持 API 调用
本文分享了`腾讯开源的知识库工具-WeKnora`,并进行了本地部署实测。
上篇,分享了 小智AI + MCP系列的第一篇:
有朋友问,能否接入知识库 RAG?
让小智可以根据企业知识库,回答客户的疑问~
当然可以,接入方式同样是 MCP,但需要 知识库 工具暴露出来检索 API。
知识库 工具有很多,尽管开源版 Coze、Dify 很强,但都没有检索 API 可供调用。
本着好东西要分享的原则,今日带来:
腾讯最近开源的 知识库 工具:WeKnora,本地部署,一手实测!
全文目录:
1. WeKnora 简介
说实在的,这名字起的,严重影响推广啊~
老规矩,简单介绍下项目亮点:
- 复杂文档:结构化提取 PDF / Word / Txt / Markdown / 图片(OCR / Caption);
- 高效检索:支持多种检索策略:关键词、向量、知识图谱;
- 简洁易用:Web界面 + 标准 API;
- 灵活扩展:从解析、嵌入、召回到生成,全流程解耦,便于灵活集成;
应该说,最吸引笔者的就是最后两个亮点,定制化程度非常高~
2. 本地部署
官方提供了 docker 部署示例,我们一步步来。
2.1 设置环境变量
首先在项目根目录下,复制得到一份环境变量:
git clone https://github.com/Tencent/WeKnora.git
cd WeKnora
# 复制示例配置文件
cp .env.example .env
支持接入本地 Ollama 模型,只需填入你的 Ollama 地址即可:
OLLAMA_BASE_URL=http://host.docker.internal:11434
关于 Ollama,可见笔者之前的教程:
https://zhuanlan.zhihu.com/p/710560829
至于 .env 中其它配置信息,如果只用到基本功能,采用默认配置即可!
2.2 修改 docker-compose 文件
官方提供的 docker-compose 提供了完备的依赖,具体功能如下:
1. app:(WeKnora-app)
后端服务,负责处理业务逻辑、API 请求等核心功能。
2. minio (WeKnora-minio)
提供文件存储服务,存储系统中的文件数据,作为文档读取服务(docreader)的存储后端
3. frontend (WeKnora-frontend)
前端界面,为用户提供可视化的操作界面
4. docreader (WeKnora-docreader)
文档读取服务,用于处理和解析各种文档格式。可集成视觉语言模型(VLM)进行文档分析
5. jaeger (Jaeger)
分布式追踪系统,用于监控和诊断微服务之间的调用链。
6. postgres (WeKnora-postgres)
数据库服务,存储系统的核心数据
7. redis (WeKnora-redis)
缓存和消息队列服务。
如果在本地已经有 redis / postgres 等服务,删掉对应服务,然后在 app 里通过环境变量传入服务地址。
其中,
extra_hosts:
- "host.docker.internal:host-gateway"
意味着把host.docker.internal在容器中映射为主机地址,保证同一份 docker-compose.yml ,可以成功跑在 Windows 和 Linux 上。
当然,也可以查看下 Docker 网桥对应的网关地址:
ip addr show docker0
# 假设输出
inet 179.10.0.1/24 brd 179.10.0.255 scope global docker0
# 那么
IP 地址: 179.10.0.1/24 (这是 Docker 容器的网关地址)
广播地址: 179.10.0.255
子网范围: 179.10.0.0 到 179.10.0.255 (可容纳 254 个容器)
2.3 启动服务
docker-compose.yml 准备好后,一键拉起:
docker compose up -d
如果用的默认端口号,启动成功后,可访问以下地址:
- Web UI:http://localhost
- 后端 API:http://localhost:8080
- 链路追踪(Jaeger):http://localhost:16686
3. Web 应用
3.1 系统配置
浏览器打开:http://localhost 进入网页配置界面
如果部署了 Ollama,这里会检查服务状态:
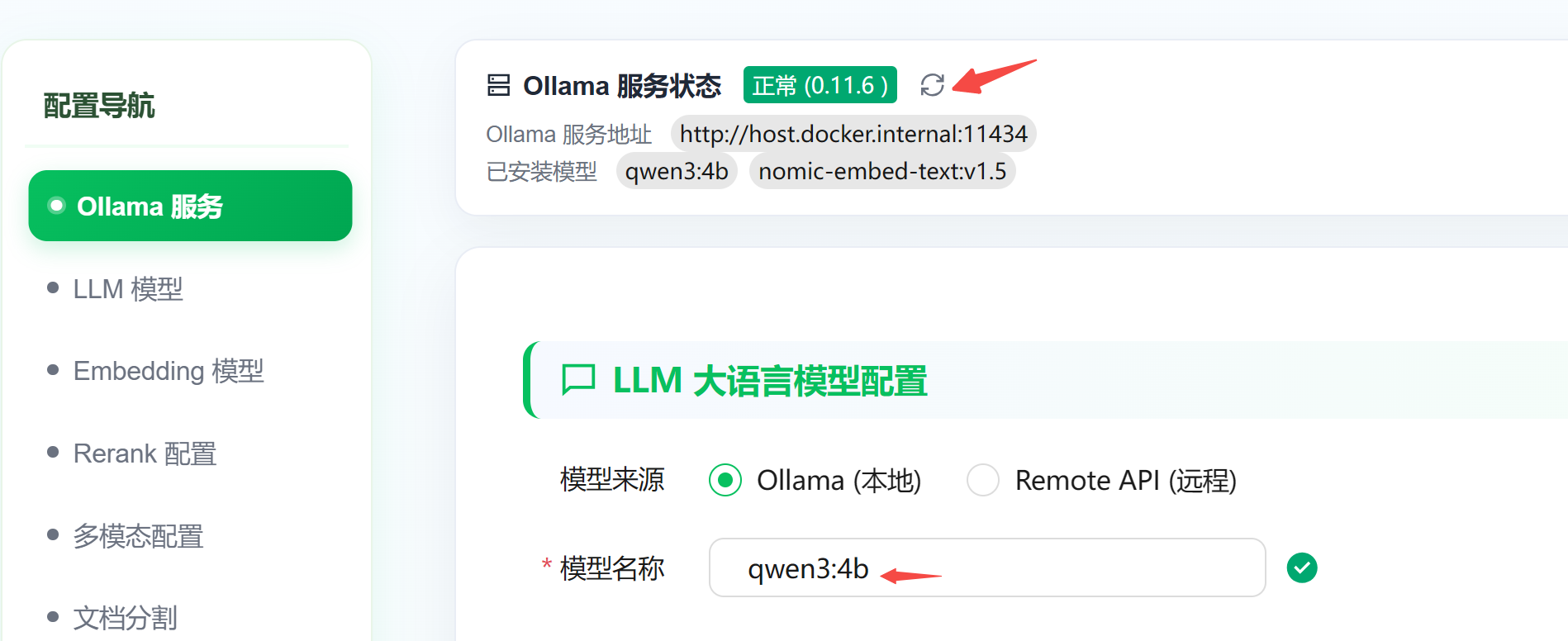
如果没有部署 Ollama,也支持 OpenAI 兼容的 API:
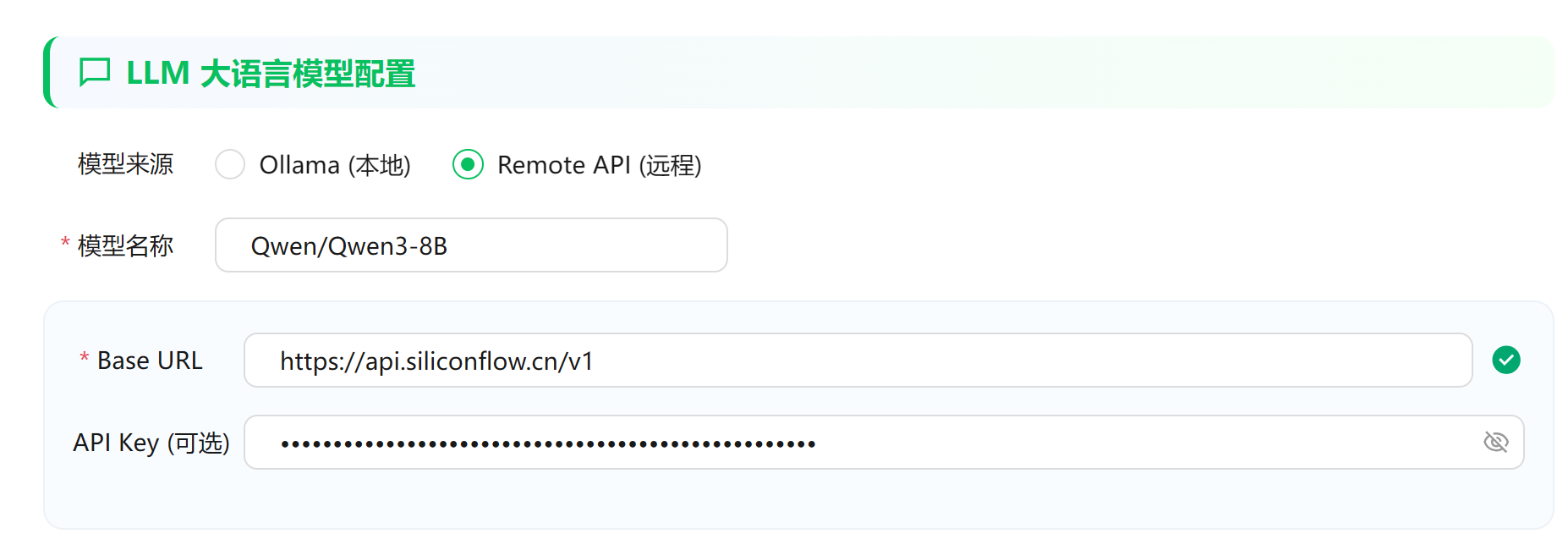
推荐大家先试试硅基流动的免费API:https://cloud.siliconflow.cn/?referrer=clxv36914000l6xncevco3u1y
3.2 知识库
配置成功后,进入主界面,左侧菜单栏简洁到只有两个 Tab:
- 知识库
- 对话
首先,上传文档,等待解析:
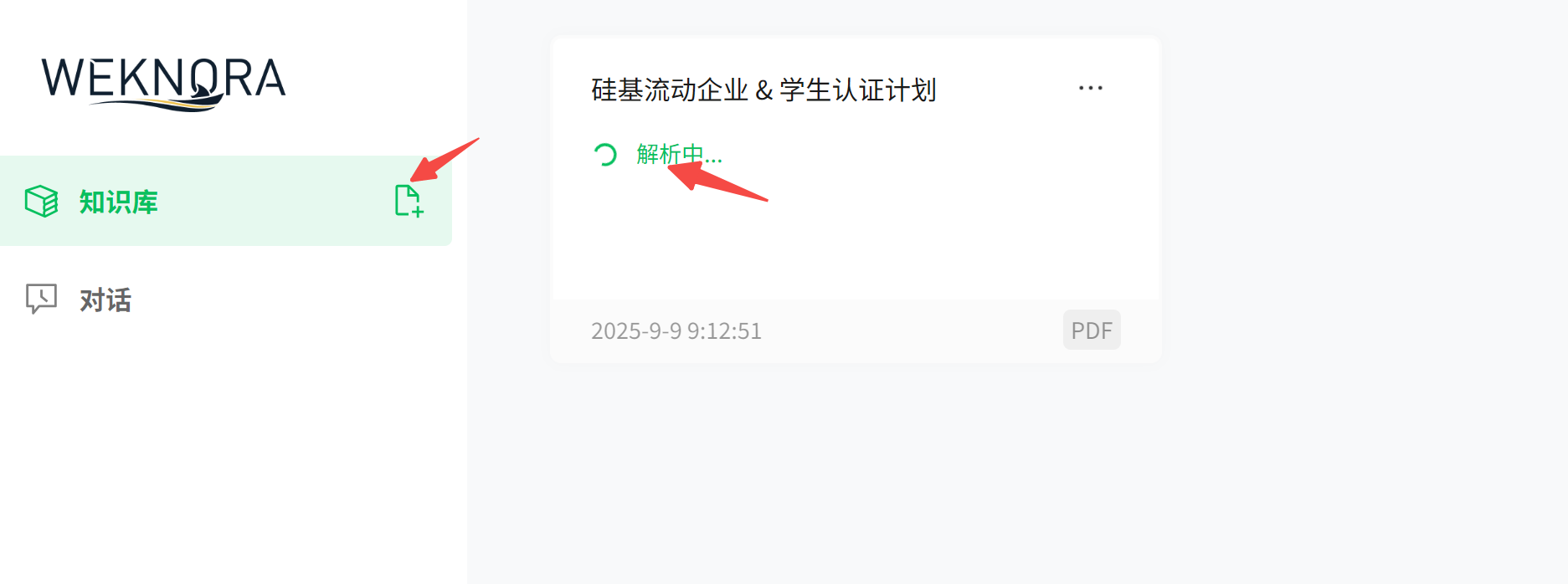
我这里测试了 PDF / Markdown 两种格式:
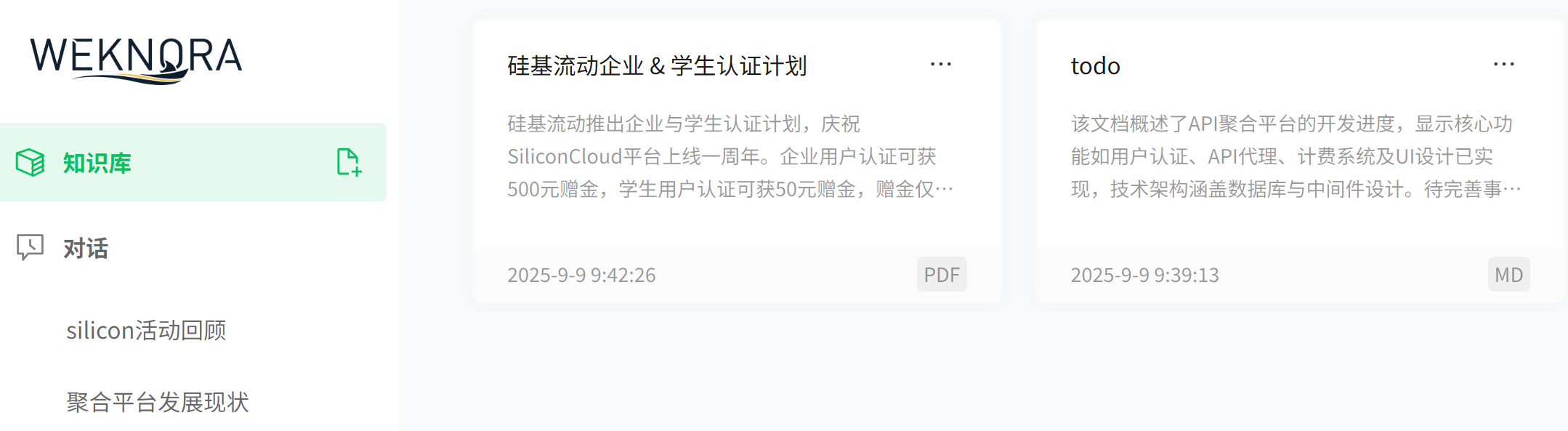
3.3 对话测试
文档解析成功后,就可以基于知识库提问:
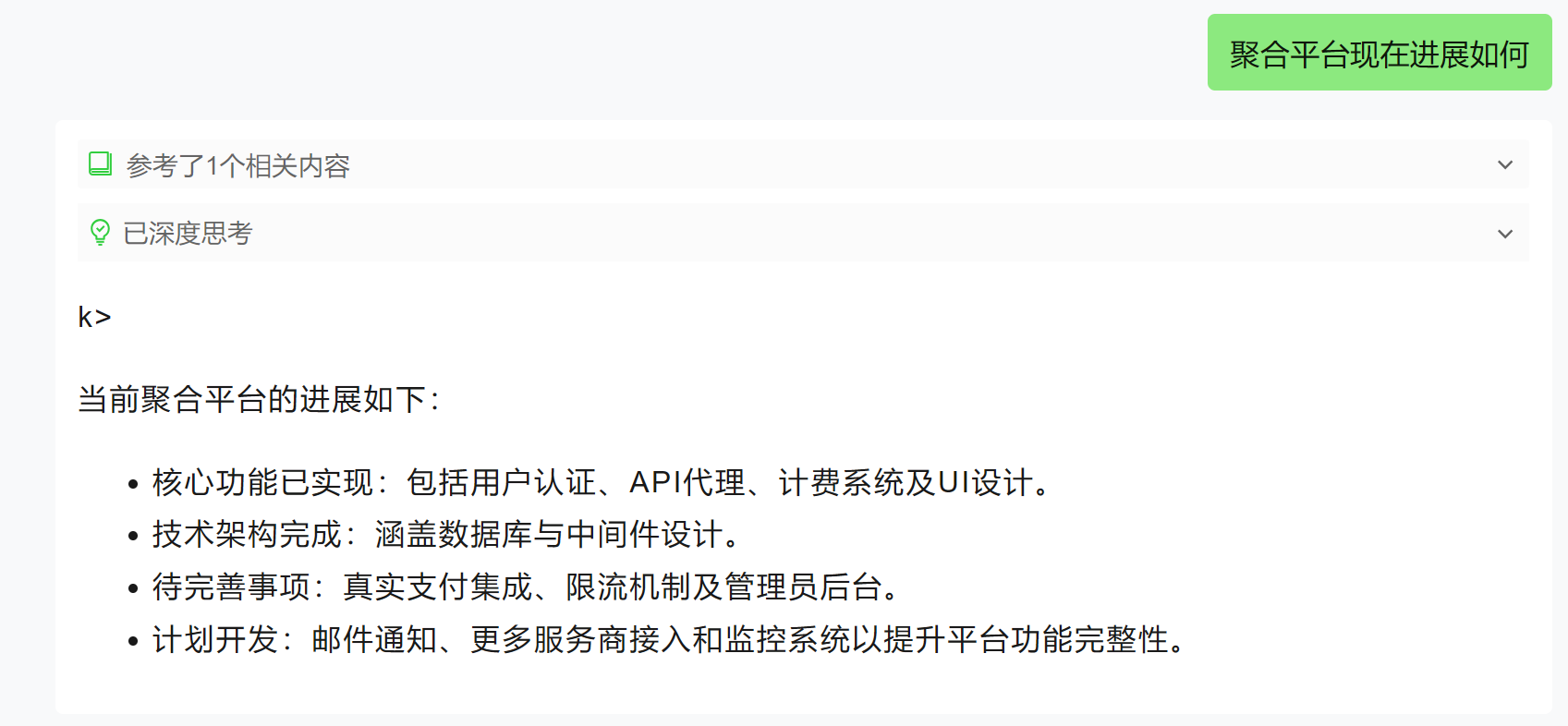
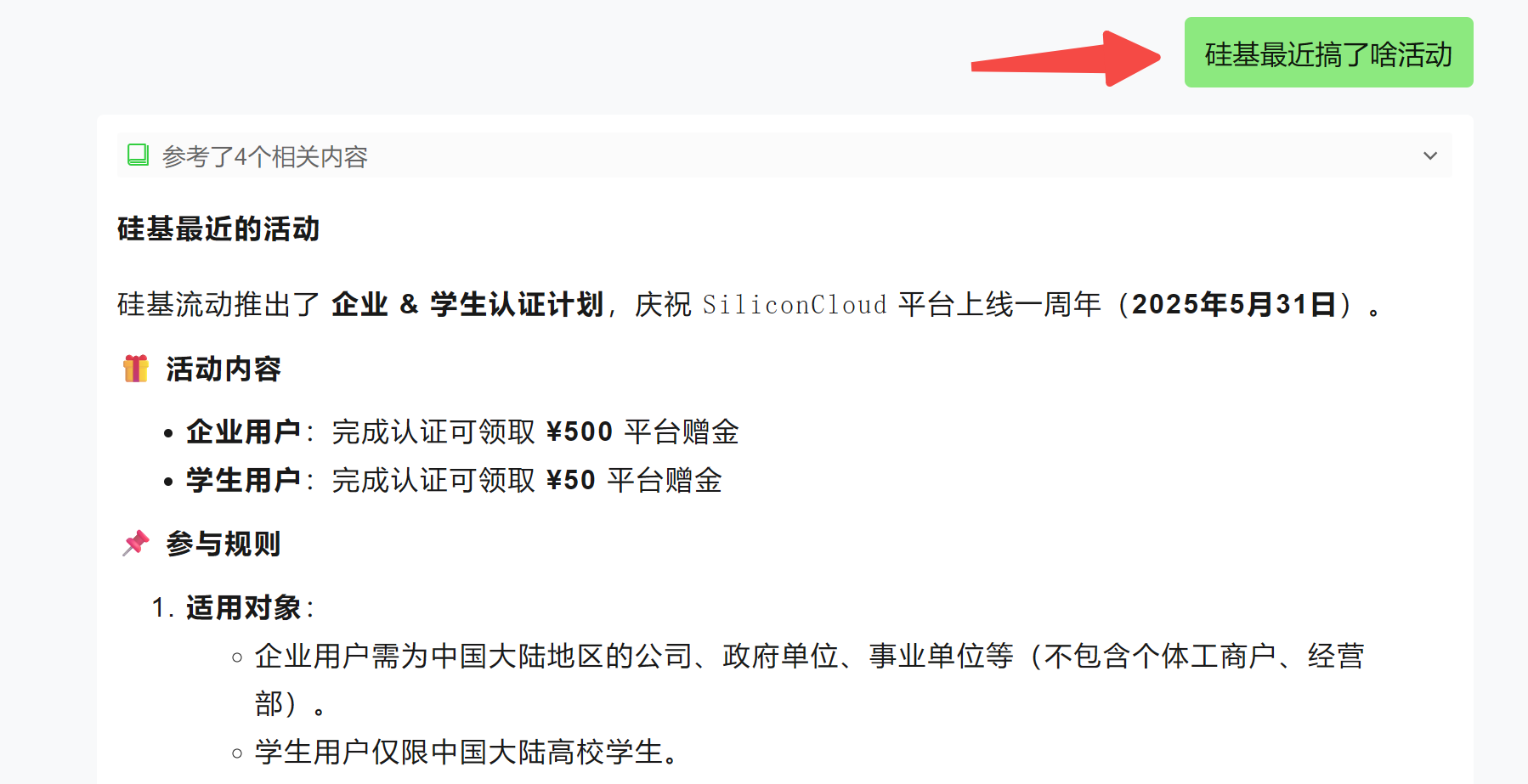
4. API 调用
API 文档:https://github.com/Tencent/WeKnora/blob/main/docs/API.md
我们测试几个核心 API,走一遍解析、嵌入、召回到生成的完整流程。
下面以 Python 为例展开:
4.1 租户管理
每个租户都可以独立创建知识库,我们刚才在前端操作的,其实就是 Default 租户身份。
所以,如果要多用户使用,就得创建租户:
base_url = 'http://localhost:8080/api/v1'
def create_tenants():
url = f'{base_url}/tenants'
data = {
"name": "test",
"description": "weknora tenants",
"business": "wechat",
"retriever_engines": {
"engines": [
{
"retriever_type": "keywords",
"retriever_engine_type": "postgres"
},
{
"retriever_type": "vector",
"retriever_engine_type": "postgres"
}
]
}
}
response = requests.post(url, json=data)
print(response.json())
返回结果:
{'data': {'id': 10002, 'name': 'test', 'description': 'weknora tenants', 'api_key': 'sk-XCLeBAgW4z7Ofq0b1uP4LxpiwJpwfq01NTwfVurcyvJcvmrA', 'status': 'active', 'retriever_engines': {'engines': [{'retriever_engine_type': 'postgres', 'retriever_type': 'keywords'}, {'retriever_engine_type': 'postgres', 'retriever_type': 'vector'}]}, 'business': 'wechat', 'storage_quota': 10737418240, 'storage_used': 0, 'created_at': '2025-09-09T10:01:58.330697479+08:00', 'updated_at': '2025-09-09T10:01:58.330697679+08:00', 'deleted_at': None}, 'success': True}
每个租户,访问API的权限通过 API-KEY 管理,为此可以通过查询租户信息,获取 API-KEY:
def get_tenants():
# url = f'{base_url}/tenants' # 查询所有用户
url = f'{base_url}/tenants/10000' # 查询指定用户
headers = {'X-API-Key': 'sk-XCLeBAgW4z7Ofq0b1uP4LxpiwJpwfq01NTwfVurcyvJcvmrA'}
response = requests.get(url, headers=headers)
print(response.json())
4.2 知识库管理
查询知识库:
注意,如果是在前端界面上传文件创建知识库的,这里的 headers 要传入 default 租户的 api-key:

def get_kb():
# url = f'{base_url}/knowledge-bases' # 查询所有知识库
url = f'{base_url}/knowledge-bases/kb-00000001' # 查询指定知识库
response = requests.get(url, headers=headers)
print(response.json())
搜索知识库:
def search_kb():
kb_id = 'kb-00000001'
url = f'{base_url}/knowledge-bases/{kb_id}/hybrid-search'
data = {
"query_text": "硅基学生活动",
"vector_threshold": 0.5,
"keyword_threshold": 0.3,
"match_count": 1
}
response = requests.get(url, json=data, headers=headers)
print(response.json())
响应中,每一条的 content 即可作为大模型的参考:

4.3 知识管理
查看知识库中有多少个文件:
def get_knowledge():
# kb_id = 'kb-00000001'
# url = f'{base_url}/knowledge-bases/{kb_id}/knowledge' # 查询知识库下所有文件
file_id = '3ee788a2-35cb-4a6d-afaf-53079ff07202'
url = f'{base_url}/knowledge/{file_id}' # 查询指定文件
response = requests.get(url, headers=headers)
print(response.json())
我这里上传了两个文件,所以有两个 id:
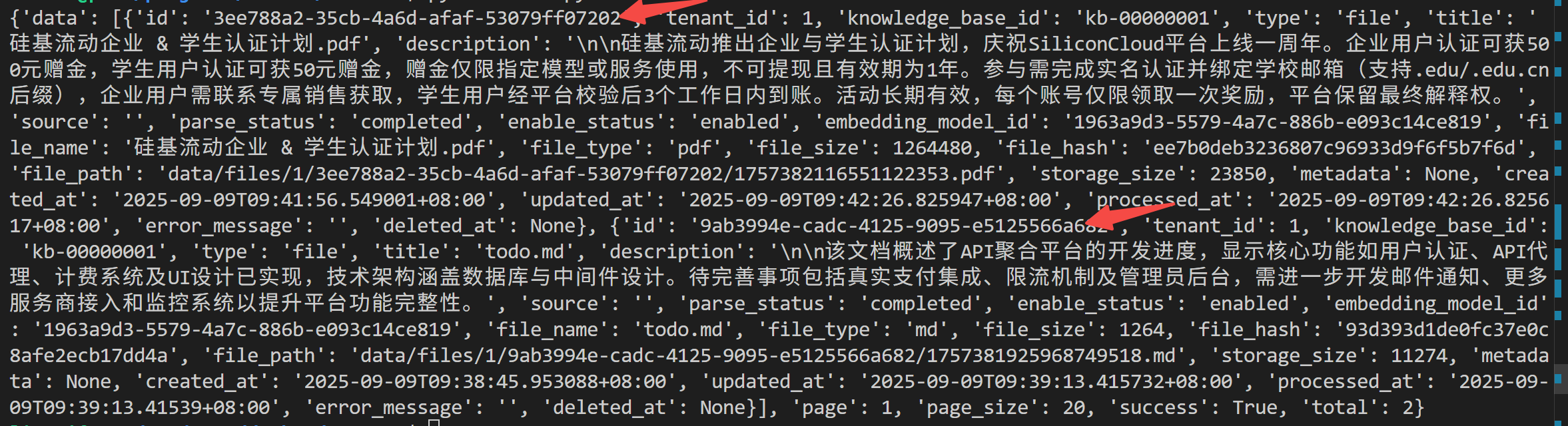
获取知识的分块列表:
def get_chunks():
file_id = '3ee788a2-35cb-4a6d-afaf-53079ff07202'
url = f'{base_url}/chunks/{file_id}?page=1&page_size=20'
response = requests.get(url, headers=headers)
print(response.json())
因为这个文档内容不多,所以只分了 4 个片段:

写在最后
本文分享了腾讯开源的知识库工具-WeKnora,并进行了本地部署实测。
如果对你有帮助,不妨点赞收藏备用。
篇幅有点长,下篇再来分享:
如何通过 MCP 的方式,把它接入 小智AI ,打造你的私人定制专家~

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)