AI应用进化论(下):Fabarta个人专属智能体的技术实现路径思考
在Fabarta企业知识引擎中我们就使用了大量的MCP,比如各类数据源的连接,外部系统的打通等等,不过也不要盲目使用MCP,Fabarta在实践上的许多经验我们在一些采访中也有提及,可以供大家参考。在这段话中,Andrej Karpathy 将 context engineering 称之为“微妙的科学与艺术”, 实际上这也是目前AI应用的主要难点之一,之前大家说要写好提示词,但现在说不够,要在正

作者:谭宇
枫清科技(Fabarta)技术合伙人
我们在上篇已经介绍了Fabarta选择从办公场景切入,通过“本地知识库+智能问答+写作”的功能设计,探索AI应用产品从“可用”到“必用”的进化路径。下篇将主要讨论Fabarta个人专属智能体的技术实践中的决策。
产品实现层面的选择
-
模型选择与模型协同
模型选择这个听起来很重要但事实上并不是特别重要。实际上如果只是在国内的模型中进行选择,这个还真不太重要,因为大家基本都是兼容OpenAI的协议,也没有提供特殊的能力比如接收PDF等。效果方面一般来说也不用去看榜单和详细的测评,只需要在开发过程中就能知道哪些模型好哪些模型不好。建议大家无需在模型选择上花太多的时间。
相比于模型选择,模型间的协同就重要一些。用得好可以提升效果和节省成本:
•比如在RAG或写作中我们会大量采用Evaluator-optimizer模式,这个时候评估与优化最好就使用不同的模型,比如优化使用常规模型,而评估则使用推理模型。
•比如在计划的时候使用推理模型,在写作的时候使用常规模型或小尺寸模型。
•文档解析的时候可以使用多种多模态模型相互配合。
类似这种组合会非常多,可以根据自己的场景不断的调整。
-
技术栈
技术栈的选择直接关乎开发效率,一般说来现在两个技术栈似乎是不可避免的,那就是JavaScript与Python,JavaScript必不可少最重要的原因当然是UI, 虽然号称有各种方式可以在不接触前端技术栈的情况下实现UI,但最终都逃不出JavaScript的范畴,类似 streamlit 的方案也许可以加快原型展示,但如果想放在产品中我建议还是不要在这些方案上浪费时间。而 Python 必不可少的原因则在于其在AI应用开发领域的成熟度,比如相同的框架,Python版本可能就比js版本要成熟,但这个情况也在发生变化。
那合理的方式是否为前端和后端技术栈分开?其实未必,就算一个人既精通JavaScript 又精通 Python 技术栈,在两个项目之间来回切换也会丧失效率。 对于类似我们3~4人的小开发团队来说,如果一门语言必须得选,那么将所有技术栈都集中到这门语言上就是一个最佳选择了,所以我们最终所有的功能都基于TypeScript来构建。
-
Agent框架
OpenAI 和 Google 都推出了自己的 Agent 框架,开源界的Agent框架更是层出不穷,我们在选择Agent框架的时候可以说走了不少弯路,从 Langgraph 到CrewAI、Agno 再到我们最终选定的Mastra,每种框架都似乎有独到之处,难以取舍,但再回过头来看实际上最终只需要做三点:
•先选定技术栈,不然范围就太广了,很难做出决定。
•再看是谁出品的这个框架,比如Mastra,它基于Vercel AI SDK,自身团队实力过硬,迭代速度也不错,那就可以放心选择。
•最后你还需要考虑UI框架的选择,这个在下面还会谈到。
虽然我个人比较喜欢Agno,但在综合权衡之下我们选择了Mastra。
-
Agent还是workflow
至于Agent还是Workflow,这个得看场景和效果决定,我们在实践中一般会先用单 Agent 来实现,再看效果来决定是否使用workflow,一般来说在国内的场景下,大部分场景最后会被workflow化,当然随着技术的演进可能会有不同。OpenAI和Google都有Agent实现相关的白皮书,值得一读。Anthropic 的两篇博客(一、二)强烈建议阅读,读完这方面应该不会再有疑问,剩下的就只是实践问题。
-
前端组件
在AI 应用的初期,界面还是相对比较简单的。基本上就是一个支持流式输出的聊天界面,但是随着模型功能与AI应用的复杂度的增加,推理过程、 Canvas/Artifact、function call、 图片/声音以及 Agent/workflow 调用细节不断的想要呈现给用户,外加这些AI应用想要展示的位置,比如是独立窗口还是浮窗等都大大的增加了前端组件的复杂度。
业界也逐步开始出现一些解决方案来降低这些复杂度,比如assistant-ui / prompt-kit / vercel Chat-SDK。其中assistant-ui 是Y combinator项目,实现比较复杂,但可扩展性很强。Prompt-kit则比较简单,自己很容易控制。 Chat-SDK则纯粹是Vercel为自家的ai sdk 提供的一个示例型项目,功能比较丰富,实现的时候可以参考。
这里有另一个关键的问题,就是需要前后端相互配合,后端用什么样的Agent框架,各类Agent框架的输出格式会不一样,当适配到一定程度前后端就深度绑定了,这个时候再换后端Agent或前端组件的工作量就太大了。当然有一种办法是前端规定一种通用的输出格式,让后端的各个Agent都来进行适配,这样大家都可以自由选择,这就是CopilotKit 提出的解决方案,称之为AG-UI,非常值得一试。
-
MCP还是工具
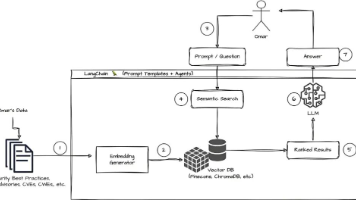
应该说MCP是一个比较实用的协议,大部分Agent框架特别是OpenAI 都给予了支持,所以在实际应用中可以按情况决定是否使用。在Fabarta企业知识引擎中我们就使用了大量的MCP,比如各类数据源的连接,外部系统的打通等等,不过也不要盲目使用MCP,Fabarta在实践上的许多经验我们在一些采访中也有提及,可以供大家参考。
具体到Fabarta个人专属智能体上,我们在实现过程中基本上都改成了工具。这个取决于我们的应用形态,作为一个桌面程序,使用MCP需要新开进程,不是一个很划算的开销。
-
Context Engineering
Context Engineering 是最近很热的词,但实际上其起源并没有神秘之处,也不是要代替提示词工程, 寥寥几语便道破本质:
context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits.
在这段话中,Andrej Karpathy 将 context engineering 称之为“微妙的科学与艺术”, 实际上这也是目前AI应用的主要难点之一,之前大家说要写好提示词,但现在说不够,要在正确的时机正确的地点正确的场合填充好正确的上下文,这实际上反应的是AI应用越来越高的复杂度。
实际上我们很早就关注到了这个问题,在Fabarta企业知识引擎里做过许多优化和尝试,与 context engineering 可以说是异曲同工:
•为企业内部的专有术语或黑话构建统一的词典,放入全局上下文,比如在大型人力密集型制造业里,“我要回家” 等同于 “我要离职”。
•为某个用户构建用户级的上下文。比如用户的性别、工作年限、公司办公地等信息,在用户问到“我的年假/产假”等信息的时候可以准确使用。
•为某次对话构建会话级上下文。比如记录用户本次要求的语气、对话风格等。以便在本次会话中统一遵循。
•为某种目的特殊构建的上下文,比如在数据分析或指标分析中记录指标的关系,在数据溯源中记录数据的血缘。
为这些上下文,我们们使用了多种技术,从最简单的缓存到复杂的图来表示与构建。
实际上现在大部分Agent也对这些概念进行了支持,只是可能有不同的叫法,以Mastra为例,它提供了:
•Runtime Context,可以动态注入依赖,是实现动态上下文的基础设施。
•Dynamic Agents & Dynamic Tool,可以运行时改变Agent的提示词或工具。
•Working Memory,提供三种能力:
○会话级上下文
○用户级上下文
○历史信息压缩与召回
在Fabarta个人专属智能体中,我们通过之前的积累和Mastra提供的能力,实现了用户、会话以及全局上下文等逻辑。 但这里也需要提醒的是,说Context Engineering是艺术在于有它固然的不确定性和复杂度,但它仍然只是AI应用中非常小的一部分,需要正确评估投入。 Andrej Karpathy 也还提到了:
On top of context engineering itself, an LLM app has to:
○break up problems just right into control flows
○pack the context windows just right
○dispatch calls to LLMs of the right kind and capability
○handle generation-verification UIUX flows
○a lot more - guardrails, security, evals, parallelism, prefetching, ...
So context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term "ChatGPT wrapper" is tired and really, really wrong.
关注全局再局部突破,切勿过早陷入到其中的一个环节。
-
数据安全
这是很多用户关注的问题,根据不同的企业需要有不同的选择。通常用户关注原始文件、问答与问答内容、生成内容的存储与使用。
我们选择不在服务端存储用户的任何问题,包括问题、问答内容、文章等,全部存储在用户本地,只将必要的信息直接送往大模型。
03
思考总结
AI应用开发是一条充满挑战与机遇的道路。
从ChatGPT发布到DeepSeek V3/R1,再到Agent生态的蓬勃发展,我们见证了AI技术前所未有的快速演进周期。然而,正如本文所述,AI应用的构建并非只是技术堆叠,而是一项涉及理念认知、产品设计、技术选型与用户体验等多维度的系统性工程。
首先,我们必须清醒地认识到,AI应用尚处于智能化的早期阶段,仍存在大量亟待解决的问题与空白:模型能力的持续演进尚未触及杀手级应用的诞生;绝大多数产品仍然是“以模型为中心”的产物,脱离用户真实工作流;AI作为助手的能力远未成型,个人数据、企业数据与公域数据之间仍缺乏融合通道。
在这种背景下,Fabarta选择了从办公场景切入,构建“个人专属办公智能体”这一产品形态,不仅是对我们过去服务大型企业经验的提炼与总结,更是对未来AI应用发展路径的主动探索与回应。我们坚信:只有将AI真正嵌入用户的日常工作流程,打通数据壁垒,做到开箱即用、端到端解决问题,才能真正让AI从“看起来很好”走向“用起来真强”。
在实现路径上,我们也做出了一系列务实而又独到的技术选择:从技术栈统一、Agent框架评估、前端组件选型,到MCP与工具之间的权衡、记忆机制设计、数据安全原则等,都是基于真实场景、有限资源和可持续演进能力的深思熟虑。这些细节虽繁杂,但它们共同构成了一个真正面向用户、可持续、具备产品力的AI应用系统。
回到最根本的问题——为什么要做AI应用?因为我们相信,AI技术只有真正落地到用户手中才具备力量。而在这条路上,没有银弹,只有不断迭代、持续验证和脚踏实地的产品主义精神。
AI 应用的未来不会自动到来,而是靠每一个“真正解决用户问题”的决策与产品一步步推动而来。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)