【工业4.0面试实录】消息队列Kafka与Spring AI RAG在智能制造中的深度应用
本文通过面试对话形式,深度剖析Kafka消息队列和Spring AI RAG技术在工业4.0智能制造场景中的应用。包含3轮技术面试实录、完整代码示例和架构设计,帮助开发者掌握企业级AI+消息队列解决方案。
【工业4.0面试实录】消息队列Kafka与Spring AI RAG在智能制造中的深度应用
📋 面试背景
某互联网大厂正在招聘Java开发工程师,专注于工业4.0智能制造领域。岗位要求熟练掌握消息队列技术和AI应用开发,能够设计高并发、高可用的分布式系统。面试官是资深技术专家,应聘者"小润龙"是一位有一定基础但经验尚浅的程序员。
🎭 面试实录
第一轮:基础概念考查
面试官: 小润龙你好,首先请你简单介绍一下在工业4.0场景下,消息队列的主要作用是什么?
小润龙: 呃...消息队列就像工厂里的传送带吧?可以把数据从一个地方传到另一个地方,实现异步处理。在工业4.0中,可以用来传输设备数据、处理订单什么的。
面试官: 这个比喻不错。那么具体来说,Kafka和RabbitMQ在工业场景中有什么区别?
小润龙: Kafka吞吐量大,适合处理海量设备数据;RabbitMQ功能丰富,适合复杂的业务逻辑。就像...Kafka是高速公路,RabbitMQ是城市道路?
面试官: 很好的比喻。那Spring AI中的RAG技术你了解吗?在智能制造中如何应用?
小润龙: RAG就是检索增强生成...呃...就像给AI装了个知识库?在工业中可以用来做设备故障诊断、工艺指导什么的。
第二轮:实际应用场景
面试官: 假设我们要为智能工厂构建一个实时质量检测系统,设备每秒产生10万条检测数据,如何设计消息队列架构?
小润龙: 这个...可以用Kafka集群?设置多个分区来并行处理,再用消费者组来消费数据。
面试官: 具体点,分区策略怎么设计?如何保证数据顺序性?
小润龙: 可以按设备ID分区?这样同一设备的数据都在同一个分区,保证顺序。但具体实现...我可能需要查下文档。
面试官: 好的。再问一个AI相关的问题:如何用Spring AI构建一个智能设备文档问答系统?
小润龙: 首先要把设备文档向量化存储,然后用RAG检索相关文档片段,最后让AI生成回答。Spring AI提供了VectorStore接口可以对接各种向量数据库。
第三轮:性能优化与架构设计
面试官: 现在系统遇到瓶颈,Kafka消费者处理速度跟不上生产者,有什么优化方案?
小润龙: 可以增加消费者实例?或者优化处理逻辑,采用批量处理...还有调整fetch参数?
面试官: 批量处理确实是个好方案。那在AI方面,如何优化RAG系统的响应速度?
小润龙: 这个...可以用缓存?或者优化向量检索算法,减少检索的文档数量?
面试官: 还有更高级的方案吗?比如使用Faiss这类优化的向量检索库?
小润龙: 啊对!Faiss可以加速向量相似度计算。还可以用GPU加速...这个我确实需要多学习。
面试结果
面试官: 小润龙,你的基础概念掌握得不错,比喻也很形象。但在实际架构设计和性能优化方面还需要加强。建议多研究一些真实的工业4.0项目案例,特别是Kafka和Spring AI的深度应用。
📚 技术知识点详解
Kafka在工业4.0中的架构设计
在智能制造场景中,Kafka的典型架构如下:
// Kafka生产者配置
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, SensorData> sensorDataProducerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
config.put(ProducerConfig.ACKS_CONFIG, "all"); // 高可靠性
config.put(ProducerConfig.RETRIES_CONFIG, 3);
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public KafkaTemplate<String, SensorData> kafkaTemplate() {
return new KafkaTemplate<>(sensorDataProducerFactory());
}
}
// 设备数据生产者
@Service
public class SensorDataProducer {
@Autowired
private KafkaTemplate<String, SensorData> kafkaTemplate;
private static final String TOPIC = "sensor-data";
public void sendSensorData(SensorData data) {
// 按设备ID分区,保证同一设备数据顺序性
kafkaTemplate.send(TOPIC, data.getDeviceId(), data)
.addCallback(
result -> log.info("消息发送成功: {}", result),
ex -> log.error("消息发送失败", ex)
);
}
}
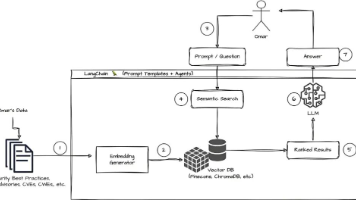
Spring AI RAG智能问答系统实现
// 配置向量存储
@Configuration
public class VectorStoreConfig {
@Bean
public VectorStore vectorStore(EmbeddingClient embeddingClient) {
// 使用内存向量存储(生产环境可用Chroma、Milvus等)
return new SimpleVectorStore(embeddingClient);
}
@Bean
public EmbeddingClient embeddingClient() {
// 使用OpenAI嵌入模型
return new OpenAiEmbeddingClient(new OpenAiApi("your-api-key"));
}
}
// 文档处理服务
@Service
public class DocumentService {
@Autowired
private VectorStore vectorStore;
@Autowired
private EmbeddingClient embeddingClient;
// 加载设备文档到向量数据库
public void loadEquipmentDocuments(List<EquipmentManual> manuals) {
List<Document> documents = manuals.stream()
.map(manual -> new Document(
manual.getContent(),
Map.of(
"equipmentType", manual.getEquipmentType(),
"model", manual.getModel(),
"version", manual.getVersion()
)
))
.collect(Collectors.toList());
vectorStore.add(documents);
}
// RAG检索增强
public String ragQuery(String question, String equipmentType) {
// 1. 检索相关文档
SearchRequest request = SearchRequest.query(question)
.withTopK(5)
.withFilterExpression("equipmentType == '" + equipmentType + "'");
List<Document> relevantDocs = vectorStore.similaritySearch(request);
// 2. 构建提示词
String context = relevantDocs.stream()
.map(Document::getText)
.collect(Collectors.joining("\n\n"));
String prompt = "基于以下设备文档内容,回答用户问题:\n\n" +
context + "\n\n问题:" + question + "\n\n回答:";
// 3. 调用AI模型生成回答
return aiClient.generate(prompt);
}
}
高并发优化策略
Kafka消费者优化:
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConcurrentKafkaListenerContainerFactory<String, SensorData>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, SensorData> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(10); // 增加并发消费者
factory.getContainerProperties().setPollTimeout(3000);
// 批量消费配置
factory.setBatchListener(true);
factory.getContainerProperties().setAckMode(AckMode.BATCH);
return factory;
}
@Bean
public ConsumerFactory<String, SensorData> consumerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ConsumerConfig.GROUP_ID_CONFIG, "sensor-data-group");
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
config.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500); // 批量拉取
config.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 52428800); // 50MB
return new DefaultKafkaConsumerFactory<>(config);
}
}
// 批量消费者
@Service
public class SensorDataBatchConsumer {
@KafkaListener(topics = "sensor-data", groupId = "sensor-data-group")
public void consumeBatch(List<SensorData> records) {
// 批量处理,提高吞吐量
records.parallelStream().forEach(this::processData);
}
private void processData(SensorData data) {
// 数据处理逻辑
}
}
💡 总结与建议
通过这次面试对话,我们可以看到在工业4.0场景中:
- 消息队列是神经系统:Kafka处理海量设备数据,RabbitMQ处理业务逻辑
- AI是大脑:Spring AI RAG提供智能决策支持
- 架构设计关键:分区策略、批量处理、向量检索优化
学习建议:
- 深入理解Kafka架构原理和调优参数
- 掌握Spring AI的VectorStore和EmbeddingClient
- 学习工业4.0实际案例和业务场景
- 实践高并发系统的性能优化技巧
技术成长路径:
- 基础:掌握Java和Spring生态
- 中级:深入学习消息队列和AI框架
- 高级:架构设计和性能优化
- 专家:业务场景深度理解和创新应用
工业4.0时代,消息队列和AI技术的结合将为智能制造带来革命性的变化,作为开发者需要不断学习新技术,适应新场景。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)