【论文精读】 PVPO: PRE-ESTIMATED VALUE-BASED POLICY OPTIMIZATION FOR AGENTIC REASONING
【论文精读】 PVPO: PRE-ESTIMATED VALUE-BASED POLICY OPTIMIZATION FOR AGENTIC REASONING
【论文精读】 PVPO: PRE-ESTIMATED VALUE-BASED POLICY OPTIMIZATION FOR AGENTIC REASONING
论文基本信息 (Paper Information)
- 文章地址
- 标题 (Title): PVPO: Pre-Estimated Value-Based Policy Optimization for Agentic Reasoning
- 中文翻译: PVPO:基于预估值驱动的策略优化,用于智能体推理
- 作者 (Authors): Wenfeng Feng, Penghong Zhao, Guochao Jiang, Chuzhan Hao, Yuewei Zhang, Hao Wang
- 机构 (Affiliation): Alibaba Cloud Computing (阿里云计算)
- 来源 (Source): arXiv preprint (arXiv:2508.21104v1) - 注:这是一个未来日期(2025年)的预印本,通常意味着尚未经同行评议。
1. 摘要 (Abstract) 翻译与分析
翻译:
无评论家(Critic-free)的强化学习方法,特别是分组策略(group policies),因其在复杂任务中的高效性而备受关注。然而,这些方法严重依赖策略内的多次采样和比较来估计优势函数(advantage),这可能导致策略陷入局部最优并增加计算成本。为了解决这些问题,我们提出了 PVPO,一种通过优势参考锚点(advantage reference anchor)和数据预采样增强的高效强化学习方法。具体来说,我们使用参考模型(reference model)进行提前 rollout(展开),并将计算出的奖励分数作为参考锚点。我们的方法有效纠正了组内比较引入的累积偏差,并显著减少了对 rollout 次数的依赖。同时,参考模型可以在数据预采样期间评估样本难度,从而能够有效选择高收益数据以提高训练效率。在两个领域的九个数据集上进行的实验表明,PVPO 实现了最先进的(SOTA)性能。我们的方法不仅在多个任务上展现了强大的泛化能力,而且在不同规模的模型上表现出可扩展的性能。
分析:
摘要清晰地指出了当前无评论家RL方法(如GRPO)的核心问题:1) 依赖组内比较导致偏差和局部最优;2) 需要大量采样导致计算成本高。
然后,它提出了PVPO的核心创新点:1) 使用参考模型预计算静态V值作为优势参考锚点;2) 利用参考模型进行数据预采样(Group Sampling) 筛选高质量数据。
最后,它总结了PVPO的主要优势:1) 高性能 (SOTA);2) 强泛化性;3) 高计算效率。
2. 引言 (Introduction) 与相关工作 (Related Work) 分析
核心问题:
- Actor-Critic方法(如PPO):需要训练一个与策略网络(Actor)规模相当的评论家网络(Critic)来估计状态值(V值),计算和内存开销大。
- 无评论家方法(如GRPO):通过组内样本的比较来估计相对优势,节省了训练Critic的开销,但引入了新问题:
- 组内偏差 (Intra-group Bias): 优势估计依赖于当前策略采样的组内均值,这个基线不稳定且随策略变化,可能导致训练不稳定和局部最优。
- 高采样成本 (High Sampling Cost): 为了获得稳定的组内估计,需要大量的rollout,计算代价高昂。
- 稀疏奖励挑战 (Sparse Reward): 在智能体推理(如多步搜索、数学推理)任务中,奖励通常非常稀疏(只有最终成功/失败),加剧了上述问题。
PVPO的解决方案思路:
受人类学习(与固定参考点比较)的启发,PVPO旨在将优势函数 A = Q − V A = Q - V A=Q−V 中的 Q Q Q (动态) 和 V V V (静态) 解耦。
- Q Q Q (动态): 仍然来自当前策略的rollout奖励,反映策略的即时性能。
- V V V (静态): 来自一个固定的参考策略(如初始模型)预计算的平均回报,作为一个稳定的、全局的参考锚点。
这种方法既避免了训练Critic的成本,又提供了比组内均值更稳定的优势估计基线。
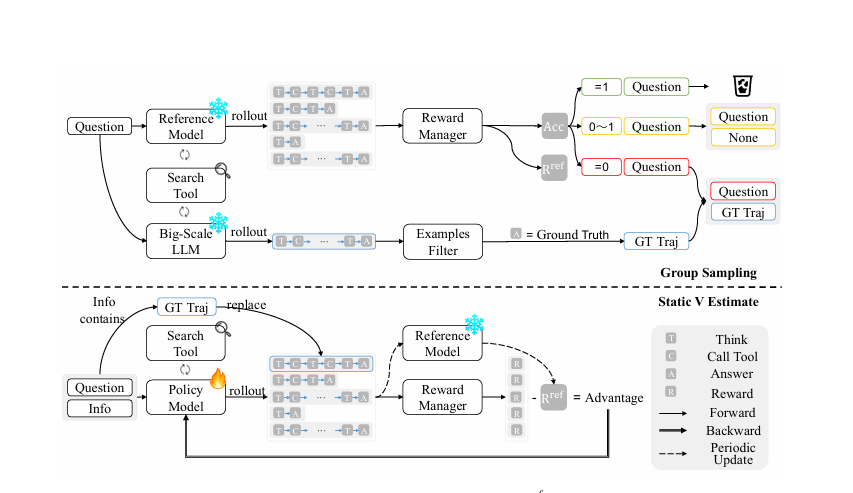
3. 方法 (Methodology) 核心内容分析
PVPO的核心包含两个部分:静态V值估计 (Static V Estimate) 和 分组采样 (Group Sampling)。
3.1 静态V值估计 (Static V Estimate)
这是PVPO最核心的创新。
-
动态V估计 (现有方法如GRPO): V ^ dyn ( s 0 ) = mean ( r ) = 1 N ∑ j = 1 N r j \hat{V}_{\text{dyn}}(s_0) = \text{mean}(\mathbf{r}) = \frac{1}{N}\sum_{j=1}^{N} r_j V^dyn(s0)=mean(r)=N1∑j=1Nrj
r_j是当前策略 π θ \pi_\theta πθ 产生的N个轨迹的奖励。- 问题: 这个基线随当前策略 π θ \pi_\theta πθ 和每次采样波动很大,尤其当N不大时。
-
静态V估计 (PVPO): V ^ sta ( s 0 ) = mean ( r ref ) = 1 M ∑ j = 1 M r j ref \hat{V}_{\text{sta}}(s_0) = \text{mean}(\mathbf{r}^{\text{ref}}) = \frac{1}{M}\sum_{j=1}^{M} r_j^{\text{ref}} V^sta(s0)=mean(rref)=M1∑j=1Mrjref
r_j^{ref}是参考策略 π ref \pi_{\text{ref}} πref (例如初始模型或之前某个检查点) 产生的M个轨迹的奖励。- 这个参考策略是固定的,只在训练过程中每隔固定步数(如500步)更新一次。
- 优势: 提供了一个稳定、低方差、全局一致的性能基线,不随当前策略的迭代而剧烈变化。
-
PVPO优势函数: A ^ PVPO ( τ i , s 0 ) = r i − mean ( r ref ) \hat{A}^{\text{PVPO}}(\tau_i, s_0) = r_i - \text{mean}(\mathbf{r}^{\text{ref}}) A^PVPO(τi,s0)=ri−mean(rref)
- 它衡量的是当前策略产生的单个轨迹的奖励与参考策略的平均表现之间的差距。
3.2 分组采样 (Group Sampling)
这是一个数据筛选机制,用于提高训练数据质量。
- 使用参考模型对训练集中的每个问题采样多次(M次),计算平均准确率(Acc)。
- 过滤规则:
- Acc = 1: 过于简单,从训练集中剔除。
- 0 < Acc < 1: 具有非零优势,保留。
- Acc = 0: 参考模型也无法解决。使用一个更大的LLM(如72B模型)来尝试生成正确答案轨迹(GT Traj)。
- 如果大模型生成成功,则将这条真实轨迹(GT Traj)及其概率分布缓存下来。
- 在训练时,对于这些难题,会用GT Traj替换掉当前策略生成的一条轨迹。
- 作用:
- 提高效率: 移除了简单和(当前)不可能完成的样本,让训练集中在“学得会”的样本上,加速收敛。
- 缓解稀疏奖励: 为难题提供了成功的示范(GT Traj),提供了学习信号,避免了在黑暗中探索。
4. 实验 (Experiments) 与结果 (Results) 分析
论文在多跳问答(Musique, 2Wiki等)和数学推理(MATH500, AIME等)两大领域共9个数据集上进行了验证,回答了5个关键问题(Q1-Q5):
-
Q1: 性能对比 (Performance)
- 结论: PVPO达到了SOTA性能。
- 证据: Table 1 显示,在7B模型上,PVPO在多个检索数据集上的平均准确率(61.0%)显著超过了GRPO(56.78%)和其他大型通用模型(如Gemini-2.5-pro的60.18%)。
-
Q2: 泛化性 (Generalization)
- 结论: PVPO具有良好的泛化能力。
- 证据: Table 2 显示,在数学推理任务上,PVPO在7B和14B模型上均一致地优于GRPO,在5个不同难度的数据集上平均准确率更高。
-
Q3: 训练效率 (Efficiency)
- 结论: PVPO显著减少了训练时间和资源消耗。
- 证据: Figure 2 显示PVPO收敛速度更快(500步达到GRPO1000步的精度)。Figure 3 显示Group Sampling过滤掉了40-60%的数据,带来了1.7-2.5倍的训练加速。
-
Q4: 训练稳定性 (Stability)
- 结论: PVPO训练更稳定。
- 证据: Figure 4 显示PVPO的优势估计方差(c)更低,平均奖励(a)更高且更平滑,同时在相似KL散度(b)下保持了更高的策略熵(d)(探索性更好)。
-
Q5: 静态V值的有效性 (Ablation)
- 结论: 静态V估计是关键有效组件。
- 证据: Figure 5 的低预算实验(N=2)表明,PVPO仅用GRPO(N=5)不到40%的计算成本,就达到了其97%的性能。这证明了静态V值提供的信号质量高、方差低,使得模型能用更少的样本进行高效更新。
5. 结论 (Conclusion) 分析
总结:
PVPO是一种高效的无评论家强化学习算法,它通过引入一个预计算的静态V值作为优势参考锚点,并结合分组采样进行数据过滤,解决了以往方法对大量采样和有偏差的组内比较的依赖。
核心贡献:
- 提出了PVPO框架: 提供了稳定、低方差的训练信号,加速收敛,显著降低计算成本。
- 引入了分组采样策略: 离线构建高质量训练批次,并利用大模型生成真实轨迹应对稀疏奖励。
- 广泛的实验验证: 在多个任务和模型规模上实现了SOTA性能和强泛化能力,证明了其在实际应用中的潜力。
意义:
这项工作在效率和性能之间取得了更好的平衡,为在资源受限环境下训练强大的AI智能体(特别是涉及推理和工具使用的场景)提供了一个非常有前景的方向。
总体评价
这是一篇写得非常清晰、扎实的论文。
- 问题定义准确: 精准地抓住了当前无评论家RL方法的核心痛点。
- 方法创新性强: 静态V估计的概念简洁而有效,参考锚点的比喻非常直观。
- 实验设计充分: 在两个不同领域的多个数据集上进行了验证,并全面地回答了关于性能、效率、泛化性、稳定性的问题,论证非常有力。
- 实用价值高: 所提出的方法直接针对计算成本这一RL应用的核心障碍,具有很高的实际应用价值。
如果该论文的结果能够被复现并经过同行评议,它很可能会成为强化学习特别是LLM对齐和智能体训练领域的一个重要工作。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)