LLM应用评估终极指南
评估大型语言模型(LLMs)的输出对于构建稳健的 LLM 应用程序的人来说至关重要,这已不是什么秘密。无论你是为了提高准确性而进行微调、在 RAG 流程中增强上下文相关性、还是在 AI 代理中提高任务完成率,选择正确的评估指标都至关重要。然而,LLM 评估仍然非常困难——尤其是在决定测量什么以及如何测量方面。LLM 评估指标(如答案正确性、语义相似性和幻觉)是根据关心的标准为评估LLM 系统输出评
前言
评估大型语言模型(LLMs)的输出对于构建稳健的 LLM 应用程序的人来说至关重要,这已不是什么秘密。无论你是为了提高准确性而进行微调、在 RAG 流程中增强上下文相关性、还是在 AI 代理中提高任务完成率,选择正确的评估指标都至关重要。然而,LLM 评估仍然非常困难——尤其是在决定测量什么以及如何测量方面。
一、什么是LLM评估指标?
LLM 评估指标(如答案正确性、语义相似性和幻觉)是根据关心的标准为评估LLM 系统输出评分的指标。它们对 LLM 评估至关重要,因为它们有助于量化不同 LLM 应用的性能,及时这个应用可能只是 LLM 本身。
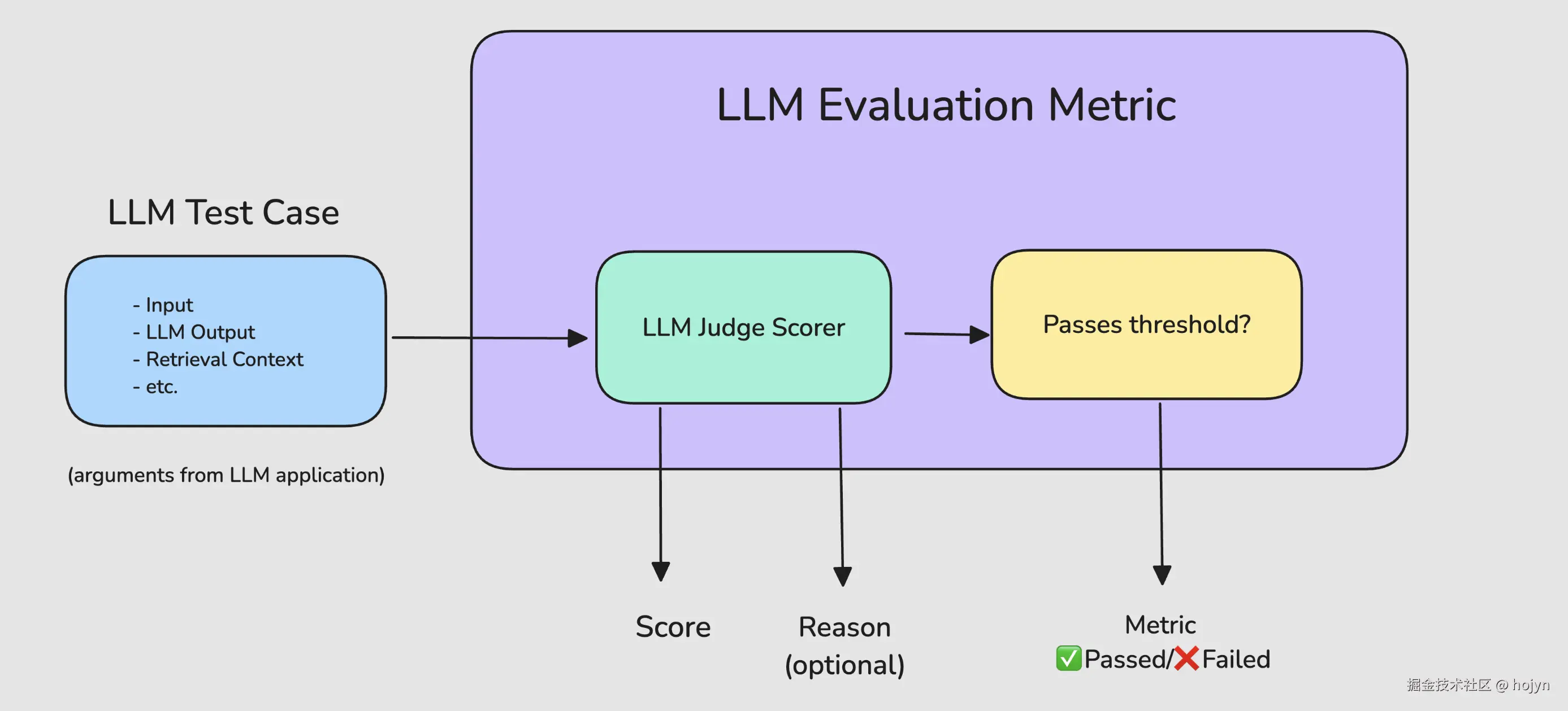
1.1 常见的评估指标
在将 LLM应用投入生产之前, 你可能需要以下最重要和最常见的指标:
- 答案相关性: 确定 LLM 输出是否能够以信息丰富且简洁的方式处理给定的输入。
- 任务完成度: 确定 LLM Agent是否能够完成其被设定的任务。
- 正确性: 根据某些基本事实,确定 LLM 输出是否事实正确。
- 幻觉: 确定 LLM 输出是否包含虚假或捏造的信息。
- 工具正确性: 确定 LLM Agent是否能够为给定任务调用正确的工具。
- 上下文相关性: 确定RAG 系统中的检索器是否能够为LLM 提取最相关的信息作为上下文。
- 责任性指标: 包括偏见和等指标,用于判断 LLM 输出是否包含(通常意义上的)有害和冒犯性内容。
- 特定任务指标: 包括摘要等指标,这些指标通常根据具体用例包含自定义标准。
1.2 自定义指标
虽然大多数指标是通用的,但在针对特定用例时,它们往往是不够的。因此,为了让你的LLM评估流程能够投入生产使用,你至少需要一个可定制化的、针对具体任务的指标。关键点在于:一个LLM评估指标应该是根据LLM应用的来设计设计并对其进行评估的。
❝
举个例子,如果你的LLM应用是用来总结新闻文章的,你就需要一个定制化的LLM评估指标,用于根据以下方面进行评分:
- 总结中是否包含了原文中的足够信息。
- 总结中是否包含任何与原文相矛盾的内容或存在幻觉(即虚构、不真实的内容)。
除此之外,如果你的LLM应用采用的是RAG架构,你可能还需要评估检索到的上下文的质量。
因此你选择的 LLM 评估指标应该同时考虑到用例和LLM系统架构:
- LLM用例:针对任务的特定指标,在不同架构实现中保持一致。
- LLM 系统架构:通用指标(例如RAG的忠实度、Agent的任务完成度)
如果你决定明天为同一个LLM用例完全更换你的LLM系统,那么你为用例所定制的指标应该保持完全不变,反之亦然。
1.3 什么是优秀的指标?
- 可定量: 在评估手头的任务时,指标应始终可以计算出一个分数。这种方法使 你能够设置一个通过评估的最低阈值,以确定 你的 LLM 应用程序是否“足够好”。同时在你后续迭代和改进时,可以实现时监控这些分数随时间的变化。
- 可靠性: 由于 LLM 的输出可能无法预测,因此你最不希望的就是 LLM 评估指标也同样不稳定。虽然可以使用 LLM评估器更准确的评估你的应用,例如 G-Eval、DAG等,但它们通常难以保障一致性,而这正是大多数 LLM-Evals 的不足之处。
- 准确性: 如果可靠的分数不能真正代表你的 LLM 应用程序的性能,那么它们就毫无意义。事实上,使一个好的 LLM 评估指标应该是可以满足人们对LLM应用能力的期望。
所以问题是:LLM 评估指标如何计算可靠且准确的分数?
二、LLM应用评估器
LLM 的输出是难以评估的,但是幸运的是,现在有许多成熟的方案可用于计算指标分数:比如利用神经网络、嵌入模型、LLM或者完全基于统计分析。
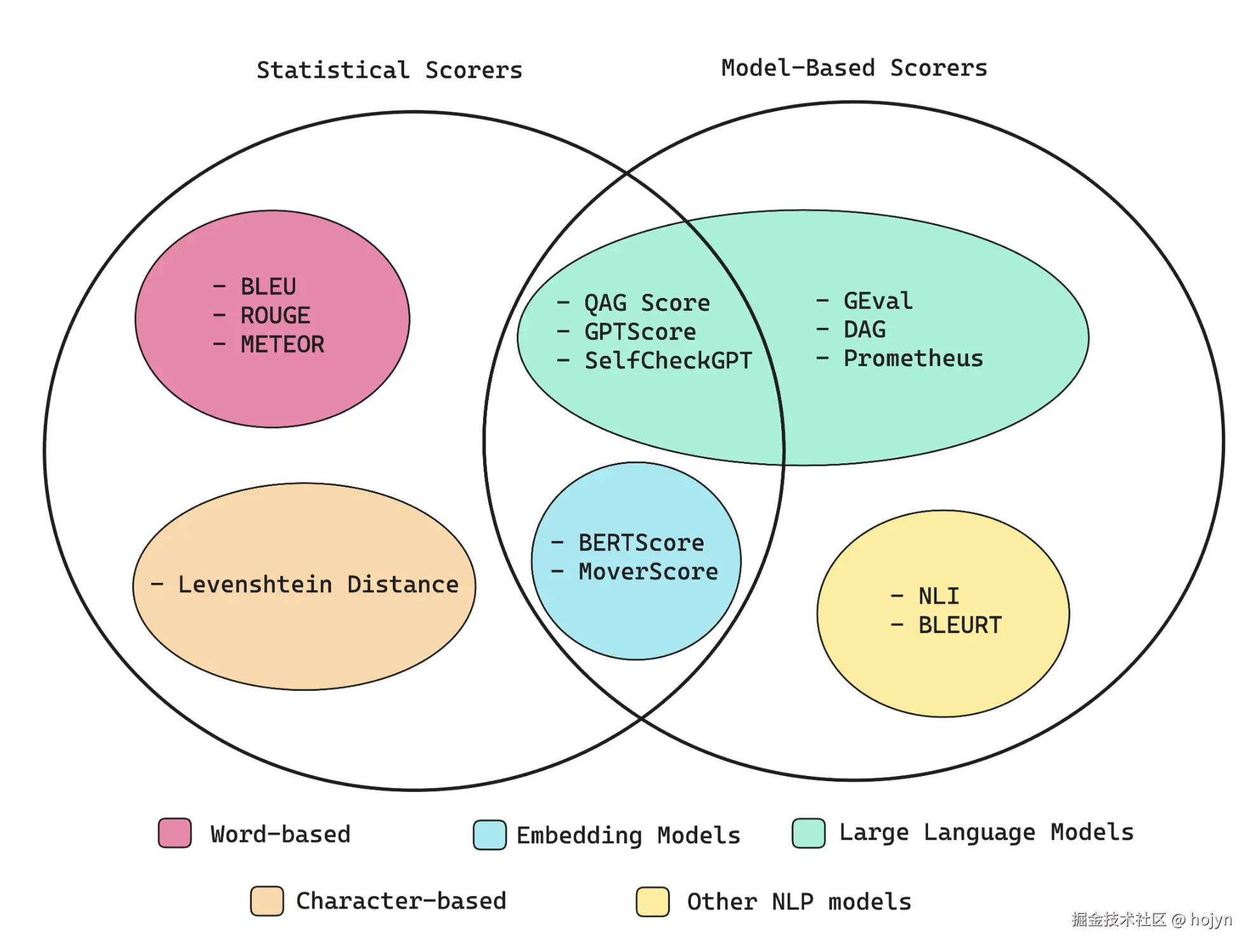
image-20250816101101005
2.1 统计评分器
统计评分方法不是必须学习的,所以如果你时间紧迫,可以直接跳到“G-Eval”部分。这是因为当需要推理时,统计方法的表现很差,作为大多数 LLM 评估标准的评分器来说,它太不准确了。
- BLEU: 评分器根据带注释的真实值(或预期输出)评估你的 LLM 应用程序的输出。它计算 LLM 输出和预期输出之间每个匹配的n 个连续的词的精确度,以计算它们的几何平均值,并在需要时进行简洁性惩罚。
- ROUGE: 用于评估来自 NLP 模型的文本摘要,并通过比较 LLM 输出和预期输出之间的n 个连续的词重叠来计算召回率。它确定参考文本中存在于 LLM 输出中的n 个连续的词的比例(0-1)。
- METEOR: 它通过评估精确率(n 个连续的词匹配)和召回率(n 个连续的词重叠)来计算分数,并针对 LLM 输出与预期输出之间的词序差异进行调整,相对而言更为全面。它还利用 WordNet 等外部语言学数据库来考虑同义词。最终分数是精确率和召回率的调和平均值,并对排序差异进行惩罚。
- Levenshtein distance: 将一个单词或文本字符串更改为另一个单词或文本字符串所需的最小单字符编辑次数(插入、删除或替换),这对于评估拼写校正或字符精确对齐至关重要的其他任务非常有用。
由于纯粹的统计评分器几乎不考虑任何语义,并且推理能力极其有限,因此它们不足以准确评估冗长而复杂的 LLM 输出结果。但是也有例外的情况,比如在评估Agent工具调用正确性指标时,可以使用完全匹配和一些条件逻辑。
2.2 基于模型的评分器
纯粹基于统计的评分器是可靠的,但不准确,因为它们难以将语义考虑在内。完全依赖 NLP 模型的评分器相对更准确,但由于其概率性质,也更加不可靠。同时其推理能力相对有限,因此基于机器学习模型的评分器表现不如基于LLM的评分器。
2.2.1 非LLM评分器
- NLI 评分器: 使用NLP 分类模型来判断 LLM 的输出在逻辑上是否与给定的参考文本一致(蕴涵)、矛盾或无关(中性)。该分数通常介于蕴涵(值为 1)和矛盾(值为 0)之间,用于衡量逻辑连贯性。
- BLEURT(基于Transformer实现的BLEU)评分器: 它使用像 BERT 这样的预训练模型来根据一些预期的输出来对 LLM 输出进行评分。
除了可能出现不一致的分数之外,现实情况中这些方法存在一些其他缺陷。例如,NLI 评分器在处理长文本时也可能难以保证准确性,而 BLEURT 则受到其训练数据的质量和代表性的限制。
2.2.2 G-Eval
G-Eval 是最近由一篇题为《NLG Evaluation using GPT-4 with Better Human Alignment》的论文开发的一个框架,它使用 LLM来评估 LLM 输出,并且是能够创建针对特定于任务的指标的最佳实践之一。
这是一个利用带有思维链(CoT)的 LLMs评估框架。该框架采用了一种表格填充模式,用户在表格中填写任务介绍和评估标准,框架会要求 LLMs 生成详细评估步骤的 CoT。然后,我们使用用户的输入以及LLM生成的评估步骤来评估LLM的输出。最终确定最终分数,输出格式为表格。
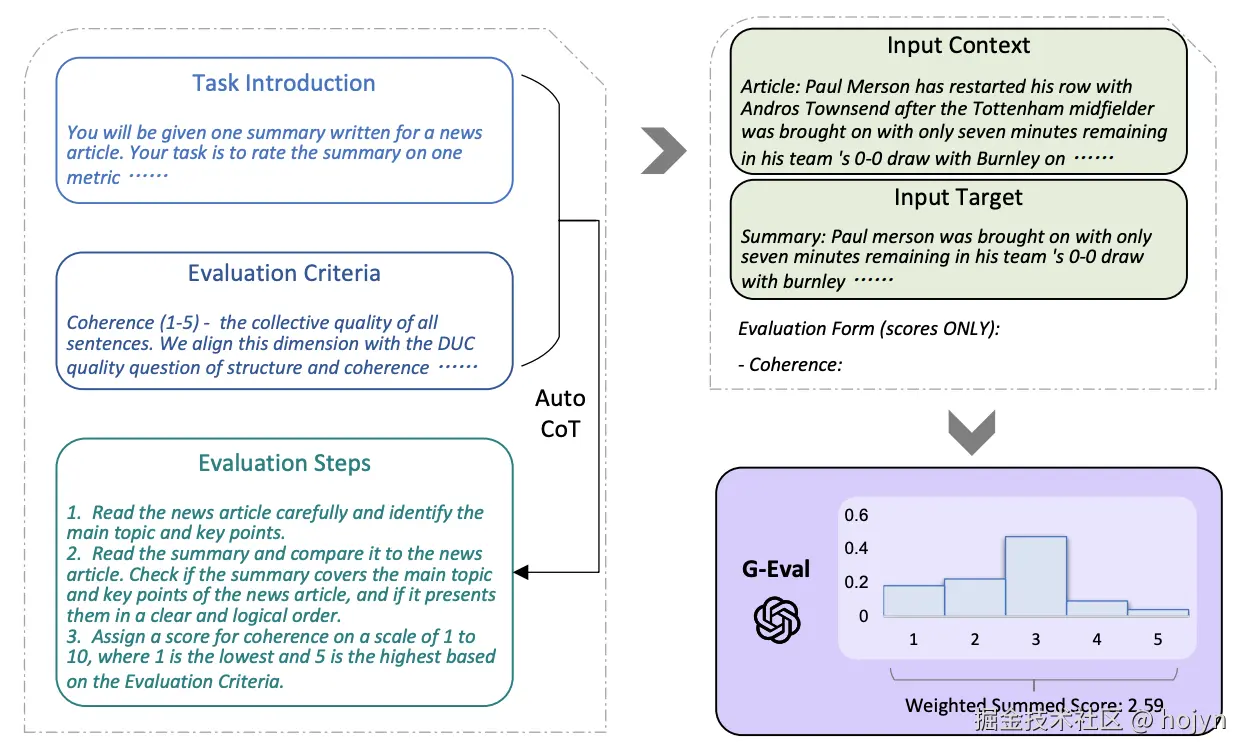
G-Eval总体框架
G-Eval包含三个主要组成部分:
-
一个包含评估任务的介绍和期望的评估标准的提示;
❝
任务介绍:你将获得一篇为新闻文章撰写的摘要。你的任务是根据一个指标对摘要进行评分。请确保你仔细阅读并理解这些说明。请在审查时保持本文档打开,并根据需要参考它。
评估标准:连贯性(1-5),表示所有句子的总体质量。我们将使用DUC会议评估摘要质量的标准,即“摘要应结构良好且组织良好。摘要不应仅仅是一堆相关信息,而应逐句构建,形成关于某个主题的连贯信息体系。”
-
一个思维链(CoT),它是由 LLM 生成的一组中间指令,描述了详细的评估步骤;
❝
1.仔细阅读新闻文章,找出主题和要点。
2.阅读摘要并将其与新闻文章进行比较。检查摘要是否涵盖了新闻文章的主要主题和要点,以及是否以清晰和合乎逻辑的顺序呈现它们。
3.根据评估标准,对连贯性进行评分,范围为 1 到 5,其中 1 为最低,5 为最高。
-
一个评分函数,它调用 LLM 并根据返回的 token 的概率计算分数。
对于评分函数,可以简单要求输出1-5的分数,但是存在以下两个问题:
- 对于某些评估任务,一个数字通常主导分数的分布,例如 1-5 分制中的 3 分。这可能导致分数的方差较低,并且与人类判断的相关性较低。
- 即使提示明确要求使用小数值,LLMs 通常也只输出整数分数。这导致评估分数中出现许多并列情况,无法捕捉到生成文本之间的细微差异。
为了解决这些问题,可以使用 LLMs 输出的 tokens 的概率来归一化分数,并将其加权求和作为最终结果。形式上,给定提示中预定义的一组分数(例如从 1 到 5),每个分数的的概率由 LLM 计算,最终分数为:
上面的方案是可选的,因为要获得输出令牌的概率, 你需要访问原始嵌入模型,但并非所有模型接口都能保证提供此功能。
G-Eval框架在基准测试的表现如下:
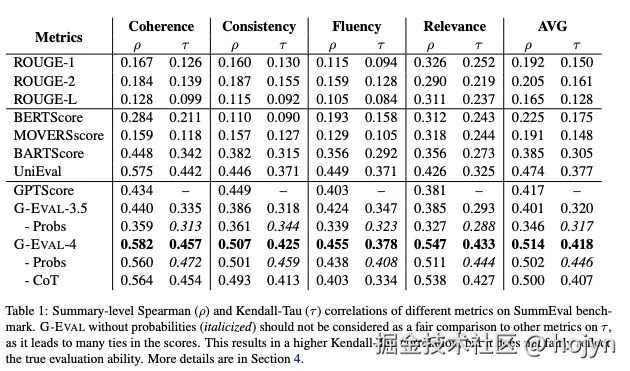
基准测试
- 是 Spearman 相关系数, 是 Kendall - Tau 相关系数,都是衡量和人工参考标准的排序相似度。
- Coherence(连贯性)、Consistency(一致性)、Fluency(流畅性)、Relevance(相关性)
G-Eval 非常优秀,因为它作为一种 LLM 评估方法,能够充分考虑 LLM 输出的完整语义,从而使其更加准确,而非 LLM 评估方法对语义的理解肯定要弱于基于LLM的评估方法。
虽然与同类方法相比,G-Eval 与人类判断的相关性更高,但它仍然可能不可靠,因为要求 LLM 给出一个分数无疑是武断的。
话虽如此,考虑到 G-Eval 的评估标准具有如此高的灵活性。它简单、易用且准确,因此目前是实现LLM评估的最流行的方案之一。
2.2.3 DAG (Deep Acyclic Graph)
G-Eval 在评估涉及主观性的情况下非常有用。但是,当你有明确的成功标准时, 你会希望使用基于决策的评分器。
❝
假如你有一个文本摘要用例,你希望在医院环境中调整患者的病史的格式。你需要保障摘要中各种标题能够按正确的顺序排列,并且只有在所有内容都满足格式要求时才给于完美的分数。
这种情况下,对于存在特定约束组合,你非常清楚地知道在不同的情况下对应的分数是多少,那么 DAG 评分器是完美的选择。
顾名思义,DAG评分器是一个基于LLM判断的决策树,其中每个节点交给LLM判断(或者规则匹配),每条边都是一个决策路径。最后,根据所采用的评估路径,返回一个固定的分数,或者使用 G-Eval作为叶节点来返回评估分数。通过将评估分解为细粒度的步骤,我们可以实现确定性。
❝
回到我们的文本摘要的例子,可以使用DAG过滤掉LLM输出不满足最低评估要求的边缘情况,这意味着如果格式不正确,可以直接输出0分。
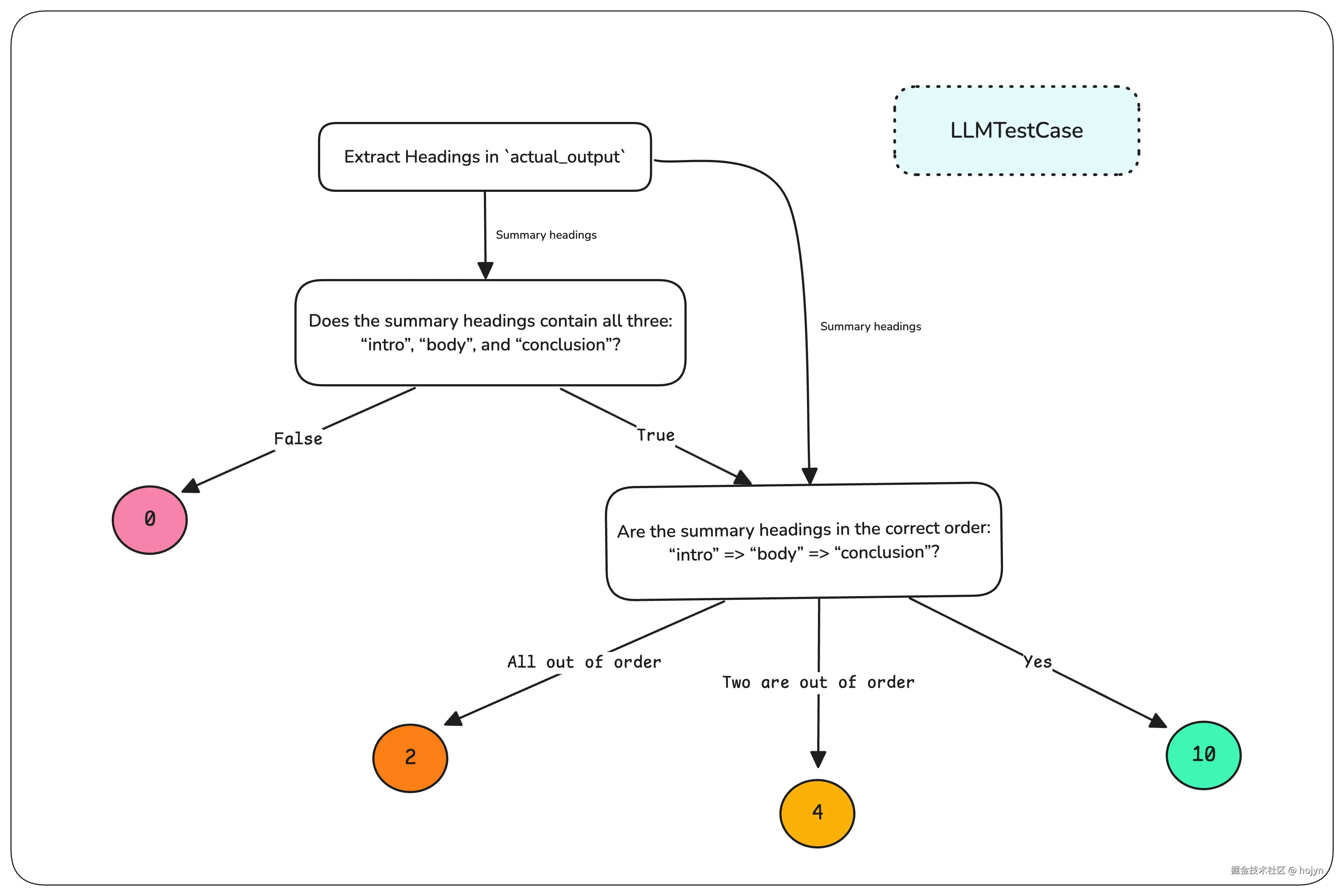
DAG是目前可用的评估器中最具自用度的度量标准,可以通过它构建许多流行指标,例如答案相关性、忠实度、甚至是G-Eval等自定义指标。
2.2.4 Prometheus-Eval
Prometheus 是一个完全开源的 LLM,当提供适当的参考资料(参考答案、评分标准)时,其评估能力可与 GPT-4 相媲美。它也与 G-Eval 类似,不局限于特定的用例。
Prometheus 是一个以 Llama-2-Chat 为基础模型的大语言模型,并在使用“Feedback Collection” 中 10 万条反馈对模型进行了微调。
❝
下面是论文中的实验结果:
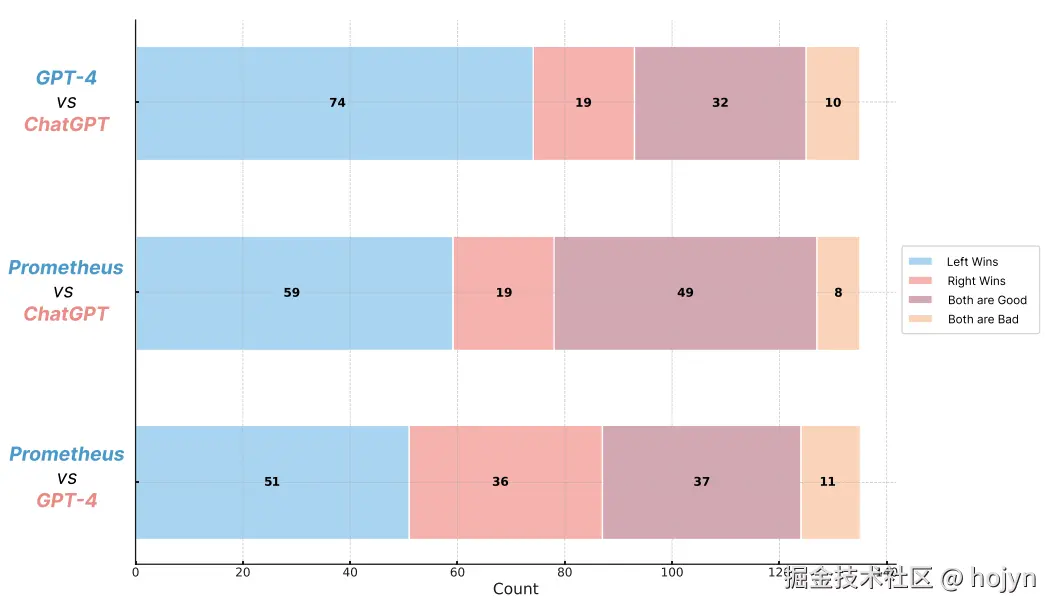
Prometheus 遵循与 G-Eval 相同的原则,两者之间存在以下几个差异:
- G-Eval 是一个使用 GPT-3.5/4 的框架,Prometheus 是一个专为评估而微调的 LLM。
- G-Eval 通过思维链(CoTs)自己生成分数标准/评估步骤,Prometheus 的分数标准则由用户提供。
- G-Eval不需要参考标准答案,Prometheus 需要参考标准答案。
Prometheus-Eval的出现是希望存在开源的LLM评估模型,而不需要在评估时依赖于通用大语言模型,如GPT、Gemini等。但是对于希望构建最佳 LLM 评估器的人来说,它并不是一个合适的选择。
2.3 统计和模型相结合的评分器
到目前为止,我们已经了解了统计方法是可靠但不准确的,以及非 LLM 模型的方法可靠性较低但准确性较高。
2.3.1 非LLM的评分器
- BERTScore评分器: 依赖于像 BERT 这样的预训练语言模型,并计算参考文本和生成文本中词语的上下文嵌入之间的余弦相似度。然后,将这些相似度聚合以产生最终得分。更高的 BERTScore 表明 LLM 输出和参考文本之间存在更大程度的语义重叠。
- MoverScore 评分器: 首先使用嵌入模型(比如像 BERT 这样的预训练语言模型),来获得参考文本和生成文本的深度语境化词嵌入,然后使用一种EMD的方法来计算:将一个 LLM 输出中的词分布转换为参考文本中的词分布所需的最小成本。
BERTScore 和 MoverScore 评分器都容易受到上下文感知和偏差的影响,因为它们依赖于来自 BERT 等预训练模型的上下文嵌入。
2.3.2 QAG评分器
QAG(问题答案生成)评分器是一种利用 LLMs 高推理能力来可靠评估 LLM 输出的评分器。它使用封闭式问题的限定答案(通常为“是”或“否”)来计算最终指标分数。这些问题可以是生成的,也可以是预设的。它之所以可靠,是因为它不使用 LLMs 直接生成分数。
❝
例如,如果 你想计算忠实度(用于衡量 LLM 输出是否为幻觉)的分数:
- 使用 LLM 提取 LLM 输出中提出的所有声明。
- 针对每个声明,询问事实依据,以确定其是否与声明一致(“是”),或者不一致(“否”)。
下面是一个具体例子:
❝
上下文: 著名民权领袖小马丁·路德·金于 1968 年 4 月 4 日在田纳西州孟菲斯市的洛林汽车旅馆遇刺身亡。当时他在孟菲斯支持罢工的环卫工人,当他站在汽车旅馆二楼的阳台上时,被一名越狱的罪犯詹姆斯·厄尔·雷枪杀。
LLM输出示例: 马丁·路德·金于 1968 年 4 月 4 日遇刺
封闭式问题: 马丁·路德·金是否于 1968 年 4 月 4 日遇刺?
QAG: 是
你可以使用QAG的这些答案,通过你选择的某种数学公式来计算得分。
❝
假如评估忠实度:
- 定义: LLM 输出中与事实真相一致的答案所占的比例
- 计算公式: 真实声明的数量除以 LLM 做出的声明总数
由于我们没有使用 LLMs 直接生成分数,而是只是利用其卓越的推理能力进行分析,因此我们获得的分数既准确又可靠。
2.3.3 GPTScore
与使用表格填充模式直接执行评估任务的 G-Eval 不同,GPTScore 使用生成目标文本的条件概率作为评估指标。
为了捕捉用户的真实需求,首先会基于以下内容建立评估协议:
- 任务说明:通常概述文本是如何生成的(例如,基于对话为人类生成回复)。
- 评估标准:记录期望的评估方面的细节(例如,回复应该容易理解)。
随后,每个评估样本将连同评估协议一起呈现。同时可以增加一些示例,这将有助于模型的学习如何评估。 最后,将使用LLM来计算基于上述评估协议生成文本的可能性。

GPTScore框架
- Evaluation Protocol(评估协议): 包含Task Specification(任务说明)、Evaluation Sample(待评估样本)、Aspect Definition(评估标准)、Demonstrated Samples(参考示例)、Template(提示词模板)
- Input(LLM的输入) :REL (相关性)用来评估摘要内容与原文主题或核心思想的相关程度,INF (信息量 )评估的是摘要中所包含的信息量
GPTScore 的核心思想是:一个高质量的生成文本,如果它能很好地遵循给定的指令和上下文,LLM就会给它一个更高的概率分数。
在我们的方法中,该指令由和组成。具体来说,假设,那么 GPTScore 被定义为以下条件概率:
- 任务描述 ()
- 评估方面定义 ()
- 待评估文本,所以表示评估文本数
- 上下文信息为(例如,源文本或参考文本)
- 代表位置的词元权重
- 表示条件概率,是不同LLM的参数
- 是定义评估协议的提示词模板,该模板通常根据具体任务而异,并通过提示词工程手动指定。
整个公式可以简单理解为: LLM结合前文内容、任务提示,去计算评估文本中每个位置token的概率,再通过加权对数概率求和。最后可以得到衡量文本与任务、上下文契合度的 GPTScore ,概率算得越高,说明文本生成的质量越好 。
论文中的测评结果如下:

- SummEval和RSumm(RealSumm)是两个专门用于文本摘要评估的基准数据集
- COU(一致性)、CON(简洁性)、FLU(流畅性)、REL(正确性)
- VAL(vanilla)指模型在
无指令、无演示的原始设定下进行评估;IST(instruction)指模型在有指令、无演示设定下进行评估 - 带有
†表示IST效果远大于VAL的结果
2.3.4 SelfCheckGPT
SelfCheckGPT 是一种独特的、基于采样的简单方法,用于对大型语言模型(LLM)的输出进行事实核查。它的核心假设是:模型编造的(即“幻觉”)内容是不可复现的;相反,如果模型确实掌握某个概念的知识,那么多次采样的回答很可能会相似,并且包含一致的事实。
SelfCheckGPT优秀的地方在于:它使得幻觉内容的检测成为一个无需参考的过程,这在实际生产环境中极其有用。
-
左侧是需要评估的LLM输出的文本:“朱塞佩·马里亚尼曾是一名意大利职业足球运动员,司职前锋。他出生于意大利米兰。死于意大利罗马。”。按句子层面评估:他出生于意大利米兰。
-
右侧是抽样的LLM再次生成的回答:
- 样例1:朱塞佩·马里亚尼曾是一名意大利画家、雕塑家和雕刻家。他于1882年出生在意大利那不勒斯,1944年死于法国巴黎
- 样例2:朱塞佩·马里亚尼曾是一名意大利小提琴家、教育家和作曲家。他于1836年6月4日出生在意大利帕维亚。
-
最终得到:{样本N}是否支持{句子}?回答:[是/否]
❝
论文中给出了基于多种方式实现的SelfCheckGPT,下面只讲基于LLM实现的方式。
LLMs 在评估文档及其摘要之间信息一致性方面非常有效,且无需任何训练样本。因此,我们查询一个LLM,以评估第句话是否得到样本(作为上下文)的支持,使用的提示词如下:
------------------------------------------------ Context: {} Sentence: {} Is the sentence supported by the context above? Answer Yes or No: ------------------------------------------------
初步调查显示,GPT-3在98%的情况下会输出Yes 或No,而其他输出结果都可以设置为N/A。将第句话与样本 进行比较时,提示的输出通过映射{Yes: 0.0, No: 1.0, N/A: 0.5}转换为分数 。然后,最终的不一致性得分计算如下:
论文中对比了传统环境评估方法,实验结果如下所示:
- GPT3、LLaMA-30B基于token概率的评估幻觉方法,核心思想是:幻觉源于模型在文本生成过程中,面对平坦概率分布所导致的高不确定性决策点。
- Sentence-level (AUC-PR):评估句子级别的准-召率,数据集非为NonFact(非事实)和Factual(事实)两类
- Passage-level (Corr.):评估段落级别(相关性),分别使用Pearson(皮尔逊相关系数)和(Spearman 斯皮尔曼等级相关系数)两种度量方法计算。
对于G-Eval和Prometheus是可以进行多种指标的评估,但是SelfCheckGPT只适用于幻觉的检测,并不适用于其他指标,比如连贯性、简洁性等。
三、选择合适的评估指标
选择哪种LLM评估指标取决于 你的LLM应用用例和架构,通常评估流程中最好不要超过5个LLM评估指标。
虽然大多数指标看起来都非常有吸引力,但事实是,当你评估一切时, 你就等于什么都没评估。
指标越多不代表越好,通常需要:
- 1到2个特定于用例的自定义指标(例如G-Eval或DAG)。
- 2到3个特定于系统的通用指标(例如RAG、Agentic或对话式)。
当然选择的指标数具体还是取决于你的系统复杂程度。
例如,如果你正在基于OpenAI模型构建一个具有工具调用能力的RAG聊天机器人,你可能需要用3个RAG指标(如忠实度、答案相关性、上下文相关性)和1个Agent指标(如工具正确性)来评估系统,再加1个使用G-Eval构建的自定义指标,用于评估品牌效应或帮助性等方面。下面这张图很好地总结了指标选择过程:
3.1 RAG指标
RAG 作为一种为 LLMs 提供额外上下文以生成定制输出的方法,非常适合构建聊天机器人。它由两个组件组成:检索器和生成器。一个典型的RAG架构如下所示:
- RAG系统接收到用户输入
- 检索器使用此输入在你的知识库(现在大多数情况下是向量数据库)中执行向量搜索。
- 成器接收检索到的上下文和用户输入作为附加上下文,以生成定制的输出。
高质量的 LLM 输出是检索器和生成器共同的产生。因此,优秀的 RAG 指标侧重于以可靠和准确的方式评估你的 RAG 检索器或生成器。
3.1.1 忠实度
忠实度用于评估 RAG 流程中的生成器(LLM)在生成内容时是否忠实于检索到的上下文信息。
❝
比如上下文说:从来没有人登上月球。
提问:第一个登上月球的国家的是什么?
忠实的回答:没有国家登上过月球。
接下来,我们该如何选择评分器来衡量忠实度指标呢?
QAG Scorer 是评估RAG 指标的最佳评分器,因为它擅长于目标明确的评估任务。对于忠实度,如果将其定义为 LLM 输出中关于检索上下文的真实声明的比例,我们可以使用 QAG 通过以下算法计算忠实度:
-
使用 LLMs 提取输出中引用的所有声明(上下文)。
-
对于每个声明,检查它是否与检索上下文中每个单独的节点一致或矛盾。
- QAG 中的封闭式问题:将可以使用类似于:“给定的声明是否与参考文本一致”,其中“参考文本”将是每个单独检索到的节点。
- 需要将答案限制为“是”、“否”。
-
忠诚度=“是”的总数除以所有声明数
这种方法利用 LLM 先进的推理能力来确保准确性,同时避免 LLM 生成的分数中出现不可靠的情况,使其成为比 G-Eval 更好的评分方法
3.1.2 答案相关性
答案相关性是一种 RAG 指标,用于评估 你的 RAG 生成器是否输出简洁的答案,可以通过确定 LLM 输出中与输入相关的句子比例来计算(即将相关句子的数量除以句子总数)。构建一个准确的答案相关性评估指标的关键在于:要将检索到的上下文纳入考量,因为额外的上下文可能会导致一个看似不相关的句子,实际上是和上下文相关的。
❝
例如用户问题:什么是光合作用?
LLM回答:植物吸收二氧化碳
评估时这个回答是和问题不相关的。但是假如上下文是:光合作用过程是:“植物从空气中吸收二氧化碳,利用光反应产生氧气。”,这个答案和上下文其实是相关的。
对于RAG的评估指标,通常都是使用QAG Scorer 。对于这个指标,封闭问题可以是:
- 请评估答案和上下文是否相关?
- 请评估答案和问题是否相关?
- 答案中是否包含与问题无关的冗余信息?
- 答案是否直接回答了问题?
- 答案是否遗漏了上下文中对回答问题至关重要的信息?
- ......
当然也可以使用GPTScore评分器来评估答案和问题以及答案和上下文的相关性。
3.1.3 上下文精确度
上下文精确度是一个 RAG 指标,用于评估你的RAG流程中检索器的质量。当我们讨论上下文指标时,我们主要关注检索上下文的相关性。较高的上下文精确度得分意味着:在检索上下文中相关的节点比不相关的节点排名更高。排序的顺序非常重要,因为 LLMs 会对检索上下文中较早出现的节点中的信息赋予更高的权重,这会影响最终输出的质量。
封闭问题参考如下:
-
在检索到的上下文的前 N 个文档中,是否包含了回答用户问题的关键信息?
- 优点: 这个问题直接、精确地评估了上下文精确度的核心概念。它将评估范围限定在“前 N 个文档”,这模拟了 LLM 关注上下文开头部分的实际行为。
- 局限性: “关键信息”的定义可能略有主观性,但对于 QAG 系统来说,可以通过比对标准答案来判断。
-
检索到的上下文是否包含了回答用户问题所需的所有信息,且没有无关的干扰信息?
- 优点: 这个问题不仅评估了相关性,还评估了完整性(所有信息)和简洁性(没有无关信息)。这能更全面地评估检索器的质量。
- 局限性: 这是一个更复杂的判断,可能需要更强大的评估模型来回答。如果无关信息太多,即使有相关信息,也可能导致得分较低。
3.1.4 上下文召回率
上下文精确度是评估检索增强生成器 (RAG) 的一个附加指标,它衡量了检索到的上下文与最终答案之间的相关性。它通过给定标注的答案,评估答案中有多少句子可以开源于上下文,上下文精确度答案中来源于检索文档的句子答案中的总句子数
精确度越高表示检索到的上下文与预期答案之间的相关性越高,表明检索器可以有效地获取相关且准确的内容,以帮助生成器生成符合上下文的响应。
因此首先需要对问题给出人工标注的答案,然后针对答案逐句评估,QAG封闭问题参考如下:
给定以下上下文和人工标注答案的其中一个句子: 上下文:[在这里插入检索到的上下文] 人工标注答案的句子:[在这里插入人工标注的预期答案] 请问这个句子中的信息是否可以从上下文推断或直接获取?请回答“是”或“否”。
3.1.5 上下文相关性
上下文相关性可能是最容易理解的指标,它仅仅是指检索上下文中与给定输入相关的句子的比例。
针对输入的每个句子与检索的上下文评估是否相关,QAG参考问题如下:
给定以下上下文和用户提问的其中一个句子: 上下文:[在这里插入检索到的上下文] 用户提问的句子:[在这里插入人工标注的预期答案] 请问检索的上下文是否可以回答这个句子的问题?请回答“是”或“否”。
3.2 Agent指标
3.2.1 工具正确性
工具正确性是一种评估你的Agent系统质量的指标,并且是一个最特殊的指标。因为它需要基于精确匹配而非基于LLM进行评估。它的计算方式是,将给定输入的Agent决定调用的工具与预期希望调用的工具进行比较。
❝
Input: 如果现在穿的鞋子不合脚怎么办?
可调用工具:网络搜索、获取当前时间
预期调用工具:网络搜索
对于这种纯规则匹配的评估方式,可以使用DAG的评分器,但是决策节点就不需要使用到LLM。
3.2.2 任务完成度
任务完成度是一个Agent指标,它使用 LLM 来评估Agent是否能够完成其给定的任务。
在启动Agent之前,针对多个Agent环节增加评估埋点,比如思考、工具执行等。评估器会从用户给的的输入推断出需要完成的任务是什么,在整个执行的过程中,会在每个埋点评估当前任务的完成度。
对于这种指标,可以使用DAG的方式编排出不同类任务完成情况的评估方式。
3.2.3 幻觉
幻觉和忠诚度比较相似,对于忠诚度主要LLM的输出是否忠实的使用检索出来的上下文,而高忠诚度其实意味着是低幻觉的。但是部分Agent应用中,模型输出时可能没有参考上下文,因此就需要单独评估Agent的结果是否存在幻觉。
评估幻觉的方法则可以SelfCheckGPT评分器,该评分器可以在零样本的情况下,抽样评估Agent输出中幻觉句子的比例。
3.2.4 责任性
责任性指标评估文本包含冒犯性、有害或不当语言的程度。
可以使用现成的预训练模型(如 Detoxify)来对责任性进行评分。然而,这种方法可能不准确,因为“评论中可能存在与咒骂、侮辱或亵渎相关的词语,无论作者的语气或意图如何(例如幽默/自嘲),都可能被归类为有害”。
在这种情况下,你可能需要考虑使用G-Eval来自定义责任性的标准。 G-Eval 是一种高度灵活的评估框架,它不局限于评估特定类型的 AI 任务,而是可以根据你自定义的标准来评估任何生成式 AI 的输出。
3.2.5 偏见
偏见指标评估文本内容中的政治、性别和社会偏见等方面。这对于自定义 LLM 参与决策过程的应用程序尤为重要。例如,在银行贷款审批中提供公正的建议,或者在招聘中,协助确定候选人是否应该入围面试。
与责任性类似,也可以使用G-Eval进行评估。
偏见是一个高度主观的问题,在不同的地理、地缘政治和社会环境中差异很大。例如,在一种文化中被认为是中性的语言或表达方式,在另一种文化中可能带有不同的含义。这也是为什么少样本评估对偏差效果不好的原因。因此也可以选择QAG用于责任性和偏见的评分器,通过增加更多的样本参考,让评分器给出更准确的答案。
3.3 特定用例指标
3.3.1 有用性
自定义的有用性指标评估 你的 LLM 应用是否能够对与之交互的用户有所帮助。当标准如此主观时,最好使用G-Eval。
3.3.2 提示词指令遵循性
提示词指令遵循性指标评估你的 LLM应用 是否能够根据你的提示词模板中规定的指令生成文本。该算法简单而有效,首先:
- 循环遍历在你的提示模板中找到的所有指令
- 根据输入和输出来确定是否遵循每个指令
这种方法之所以有效,是因为我们只向指标提供指令列表,而不是提供整个提示。这意味着你的判断 LLM 无需将整个提示作为上下文,只需在判断是否遵循指令时一次考虑一个指令,这可以有效避免幻觉。对于这种确定性的指标,可以选QAG作为评分器。
3.3.3 摘要总结得分
评估摘要总结的是否足够高,通常可以细分为下面几个点:
- 相关性:评估摘要内容与原文主题的相关程度。可以使用
QAG或者GPTScore作为评分器。 - 一致性: 评估摘要内容是否与原文事实保持一致,有没有产生“幻觉(hallucination)”。可以使用
QAG评分器。 - 流畅性: 评估摘要的语言是否通顺、语法是否正确。一个偏主观的指标,可以使用
G-Eval评分器。 - 连贯性: 评估摘要中的句子之间逻辑是否清晰、衔接是否自然。也可以使用
G-Eval评分器。
四、总结
本篇列举了大量的评分器和指标,希望你现在了解在为 LLM 评估选择指标时需要考虑的所有不同因素以及需要做出的选择。
LLM 评估指标的主要目标是量化你的 LLM应用的性能,为此我们有不同的评分器,其中一些比另一些更好。对于 LLM 评估,使用 LLMs 的评分器(G-Eval、Prometheus、SelfCheckGPT 和 QAG)由于其强大的推理能力而最为准确,但我们需要采取额外的预防措施以确保这些分数是可靠的。
归根结底,指标的选择取决于你的用例和 LLM 应用程序的实现,其中 RAG指标是评估 LLM 输出的一个很好的起点。对于更多特定于用例的指标,你可以使用 G-Eval 和少样本提示来获得最准确的结果。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)