深度学习之神经网络章节知识点
神经网络和深度学习目前提供了针对图像识别,语音识别和自然语言处理领域诸多问题的最佳解决方案。传统的编程方法中,我们告诉计算机如何去做。而神经网络不需要我们告诉计算机如何处理问题,而是通过从观测数据中学习,计算出他自己的解决方案。问题:如何训练神经网络使得它比传统的方法更好?答:深度学习是为了训练神经网络,让他(计算机)自己能够从数据中学习。神经网络使用样本自动地推断规则,通过增加训练样本...
神经网络和深度学习目前提供了针对图像识别,语音识别和自然语言处理领域诸多问题的最佳解决方案。传统的编程方法中,我们告诉计算机如何去做。而神经网络不需要我们告诉计算机如何处理问题,而是通过从观测数据中学习,计算出他自己的解决方案。
问题: 如何训练神经网络使得它比传统的方法更好?
答:深度学习是为了训练神经网络,让他(计算机)自己能够从数据中学习。神经网络使用样本自动地推断规则,通过增加训练样本的数量,该网络可以学到更多,并且更加准确。
两种重要类型的神经元:
1、感知机
感知机是一类人造神经元
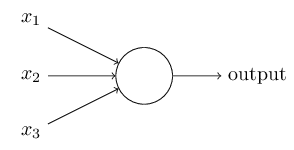
它用权重w1,w2…w1,w2…来表示各个输入对输出的重要性。神经元的输出,要么是0要么是1,由权重和
∑
j
w
j
x
j
\sum_{j} w_{j} x_{j}
∑jwjxj的值是否小于或者大于某一阈值。
output = { 0 if ∑ j w j x j ≤ threshold 1 if ∑ j w j x j > threshold =\left\{\begin{array}{ll}{0} & {\text { if } \sum_{j} w_{j} x_{j} \leq \text { threshold }} \\ {1} & {\text { if } \sum_{j} w_{j} x_{j}>\text { threshold }}\end{array}\right. ={01 if ∑jwjxj≤ threshold if ∑jwjxj> threshold
以上就是感知机的工作原理,简化一下就是:
output = { 0 if w ⋅ x + b ≤ 0 1 if w ⋅ x + b > 0 =\left\{\begin{array}{ll}{0} & {\text { if } w \cdot x+b \leq 0} \\ {1} & {\text { if } w \cdot x+b>0}\end{array}\right. ={01 if w⋅x+b≤0 if w⋅x+b>0
用向量点积的方式代替了
∑
j
w
j
x
j
\sum_{j} w_{j} x_{j}
∑jwjxj ,其中W和X分别是权重值和输入值所组成的向量, 即b=−threshold,其中b被称为感知机的偏差
把偏差b看作衡量感知机输出1的难易程度
2、Sigmoid神经元
Sigmoid神经元和感知机很相似,但是它却可以实现当对权重和偏差做微小的改变时,输出量的改变也是微小的。这将使得sigmoid神经元网络可以学习成为了可能。
和感知机一样,sigmoid函数也拥有输入向量,但是它的输入向量不再仅限于0和1,而是0到1之间的连续值。比如,0.1314可以作为sigmoid神经元的输入值。同样,sigmoid神经元对每个输入都有分配权重和一个总的偏差。但是输出也不再是0和1,而是σ(w⋅x)+b,其中σ被称为sigmoid函数,定义为:
σ ( z ) ≡ 1 1 + e − z \sigma(z) \equiv \frac{1}{1+e^{-z}} σ(z)≡1+e−z1
一个拥有输入x1,x2…x1,x2…权重w1,w2…w1,w2…偏差b的sigmoid神经元的输出为:
1 1 + exp ( − ∑ j w j x j − b ) \frac{1}{1+\exp \left(-\sum_{j} w_{j} x_{j}-b\right)} 1+exp(−∑jwjxj−b)1
为了体现和感知机的相似性,假设z=w⋅x+b是一个很大的正数,那么e−z≈0,那么σ(z)≈1。也就是说当z=w⋅x+b是一个很大的正数时,sigmoid神经元的输出就接近于1,这就像一个感知机一样。反之当z=w⋅x+b是一个很小的负数时,sigmoid的输出结果趋近于0,这和感知机的行为很相似。只有当w⋅x+b的值不大不小的时候,sigmoid的输出才和感知机不一样。
对于σ的代数式我们该如何理解?事实上,对于σ的精确表达并不重要,重要的是σ所形成的函数图形:

如果σ改为一个阶跃函数,那么sigmoid神经元就等同于感知机,如下图所示:

Sigmoid 激活函数的局限:
Sigmoid 函数的一个局限性是当
x
x
x 增大或者减小时,它的梯度变得越来越小。如果使用梯度下降或类似的方法,这就是梯度消失问题。因为随着梯度变小,参数值的变化导致网络输出的变化会很小。这将极大减慢学习速度。 这样的话使用线性整流激活函数(RELU),这个函数只有在输出为正的时候,他才允许激活。而且由于它只是一个简单的取最大值操作,使用该函数网络比具有S形激活函数的网络要快得多。这也提高了神经网络的稀疏性,因为当随机初始化时,整个网络中大约一半的神经元将被设置为0.
说明:如果神经元的输出接近1,可以认为它是"活跃的"(或者说是"激活的");如果其输出值接近于0,则为 “不活跃的”。稀疏性把神经元在大部分时间限制在不活跃的状态。这通常会得到更好的泛化性能。而Sigmoid 激活函数在分类时,若它的输出为0.9的话,便可以解释为90%的概率为正样本。
3、Softmax 函数:
Softmax函数实质上是Sigmoid函数的泛化。该函数通常应用于神经网络的最后一层,同时主要用于执行多分类任务。由于Softmax函数给出了输出属于每一类的概率,因此 Softmax 值的总和总是等于1.
到目前为止,我们所讨论的神经网络都是上一层的输出作为下一层的输入。这样的网络被称为前馈神经网
然而,有些人造神经网络中存在反馈回路是可能的。这样的模型称为递归神经网络
神经网络与黑盒子
尽管神经网络通过训练得到的模型在测试集上表现良好,但是其学习的内部细节依然不能转化为对问题的理解。权重是神经网络学习到的内容,但是权重不可能告诉我们太多的信息。特别是,神经网络的工作方式是将学习分布到不同的链接权重中。这种方式使得神经网络对损坏具有弹性。 类比生物的大脑,当大脑受到不正常的碰撞之后,还能保持正常思维。因此,删除一个节点甚至相当多的节点,都不太可能彻底破坏神经网络良好的工作能力。
神经元个数的选择:
输入层:与需要求解问题的特征维数有关
隐藏层:神经元的个数与网络的层数与求解问题的复杂度有关
输出层:与求解问题的类型有关。如果是个二分类问题,那么输出神经元的个数就是 2,且每个都是概率值;如果是一个回归问题,输出层就只有一个神经元
针对问题合理选择网络
尽管现在网络种类复杂多样,但选用哪一种网络,需要根据问题来定。假如面对的数据是线性可分,那么感知机足矣。但现实世界中的数据大多线性不可分,所以引入多层神经网络来挖掘数据特征,更好的解决实际问题。
需要说明的是,隐藏层的作用是把线性不可分的数据,通过线性变换 (预激活阶段) 和非线性变换 (激活阶段) 的操作,使得数据变为线性可分。
激活函数的作用是为了在神经网络中引入非线性的学习和处理能力。
神经网络注意点
1.隐藏层节点的激活函数将非线性引入网络中
2.为了在权重上执行梯度下降算法,激活函数需要是可微的
神经网络快速地近似任何函数:
汉阳大学 Jechang Jeong 等人开发了一种深度神经网络方法,实时去除图像中的雾气,这对于不可见的图像是很有效的,他们认为:
图像中的雾可以通过未知的复杂函数进行数学模拟,我们利用深度神经网络来近似相应的雾的数学模型
研究人员 Hornik 等发现,一个隐藏层足以模拟任何分段连续函数。他们的定理是:设 F 是 n 维空间有界子集上的连续函数,那么存在一个包含有限个隐藏单元的双层神经网络F1,它近似等于 F。也就是说,对于 F 域中所有的 x,|F(x) - F1(x) < eplison|
这个定理说明了对于任何连续函数 F 和一定的容错 eplison, 可以构建一个单隐藏层的神经网络用于计算 F。这至少在理论上说明一个隐藏层对于很多问题是足够的。
神经网络选择最佳层数的原则:
方法一:频繁的尝试和试错
方法二:如果将每个隐藏层视为一个特征检测器,层数越多,就可以学到越复杂的特征检测器。这就总结出了一个简单的法则 —— 函数越复杂,需要使用的层数就越多
神经网络中的反向传播和梯度消失:
神经网络中的传播:
前向传播利用权重参数和输入数据,从输入层到输出层,求取预测结果,并利用预测结果和真实值求解出损失函数的值。
反向传播则利用前向传播求解出来的损失函数,从输出到输入,求解网络梯度。
经过前向和反向两个操作后,完成一次迭代过程。
损失函数
机器学习算法有模型,策略和算法三个要素构成。当选择一种算法模型后,下一步需要考虑的是使用什么样的策略或准则来选择最优模型。
损失函数是机器学习用来衡量一次预测结果好坏的函数,它是一个非负实数值函数。用L(Y,f(X))来表示,常用的损失函数有四种。
-
0-1损失函数 比较的是预测值F(x)与真实值Y是否相同。0-1损失函数是一个非凸函数,在求解过程中,存在很多不足,而且它只关心预测值和真实值是否相同。没有考虑预测值和真实值之间的距离。因而只做指标,不具有优化。
-
平方损失函数 是线性回归模型最常用的最优化的目标函数。
-
对数损失函数 常用与分类模型的最优化目标函数
-
HInge损失函数 有时也称最大间隔目标函数,是SVM采用的最优化目标函数

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)