Attention的本质:从Encoder-Decoder(Seq2Seq)理解
目录1. 前言2. Encoder-Decoder(Seq2Seq)框架3. Attention原理3.1 Soft Attention介绍4. Attention机制的本质思想5. 总结1. 前言注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。所以,了...
目录
1. 前言
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。所以,了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。
2. Encoder-Decoder(Seq2Seq)框架
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下。其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。图2是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对(Source,Target),我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
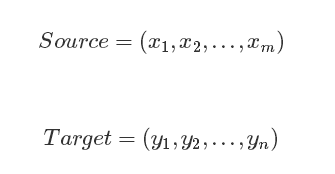
Encoder:顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C

Decoder:其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息进行解码
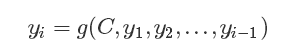
3. Attention原理
按照Encoder-Decoder的框架,我们的输出值y的表达式:
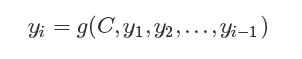
语义编码C是由句子Source的每个单词经过Encoder编码产生的,这意味着不论是生成哪个单词,y1、y2还是y3,其实句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。这样不符合人类认知事物的原理。所以我们引入Attention机制。
3.1 Soft Attention介绍
我们最普遍的一种Soft Attention的计算过程。
加上Attention的Encoder-Decoder的框架如下:
我们的图中,出现了C1,C2,C3分别对应了y1,y2,y3,这样我们的输出值的表达式也改变了:
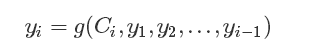
问题是我们的Ci如何计算?
我们再看一副Attention的细节图
从图中可以看出Ci是hi的加权的结果
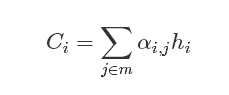
我们如何计算αi呢?这时候就用到我们的Softmax的原理,着也是Soft Attention取名的原因。

根据不同的Attention算法e(hi,sj)的实现方式也不同:
- Bahdanau Attention结构
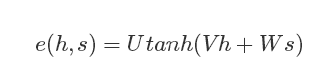
其中U、V、W是模型的参数,e(h,s)结构代表了一层全联接层。
- Luong Attention结构
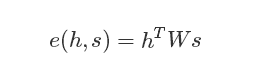
但是无论是Bahdanau Attention,还是Luong Attention,它们都属于Soft Attention的结构,都是通过Softmax来计算αi,j。
4. Attention机制的本质思想
上述内容就是经典的Soft Attention模型的基本思想,那么怎么理解Attention模型的物理含义呢?一般在自然语言处理应用里会把Attention模型看作是输出Target句子中某个单词和输入Source句子每个单词的对齐模型,即输出Target句子中某个单词Query和输入Source句子每个单词key的相关性或相似性,这是非常有道理的。
目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。
我们可以这样来看待Attention机制:将Source中的构成元素想象成是由一系列的(Key,Value)数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
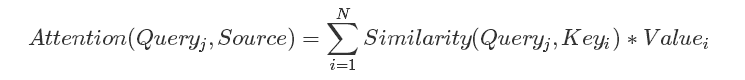
上文所举的Encoder-Decoder框架中,因为在计算Attention的过程中,Source中的Key和Value合二为一成,指向的是同一个东西,也即输入句子中每个单词对应的语义编码hi( hi即为Key和Value),所以可能不容易看出这种能够体现本质思想的结构。
从本质上理解,Attention是从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
5. 总结
Encoder-Decoder(Seq2Seq)加Attention架构由于其卓越的实际效果,目前在深度学习领域里得到了广泛的使用,了解并熟练使用这一架构对于解决实际问题会有极大帮助。
再者还有最新的Transformer结构,抛弃传统的RNN结构,完全使用Attention结构实现不同层级间的信息传递,并且还能并行处理大大提高运行速度,和准确度。
转载:https://www.cnblogs.com/huangyc/p/10409626.html#_labelTop

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)