
样本熵(Sample Entropy)
样本熵 Sample Entropy计算理解概念计算方法代码实现C语言版功能快捷键如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章计算理解图片来源:Multiscale entropy analysis of ...
计算理解
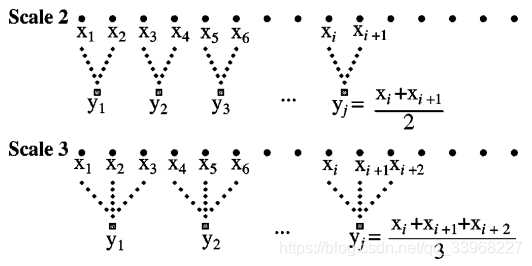
图片来源:Multiscale entropy analysis of biological signals (Fig.2)
概念
样本熵 (Sample Entropy, SampEn) 是由Richman提出的一种时间序列复杂性测度方法,可以用
S
a
m
p
E
n
(
m
,
r
,
N
)
SampEn(m,r,N)
SampEn(m,r,N)来表示,其中维数为
m
m
m及
m
+
1
m+1
m+1,
r
r
r为相似容限,
N
N
N为长度。
样本熵具有两个优势:样本熵的计算不依赖数据长度;样本熵具有更好的一致性,即参数
m
m
m和
r
r
r的变化对样本熵的影响程度是相同的。
计算方法
一般地,对于由N个数据组成的时间序列 { x ( n ) } = x ( 1 ) , x ( 2 ) , x ( N ) \{x(n)\}=x(1), x(2), x(N) {x(n)}=x(1),x(2),x(N),样本熵的计算方法如下:
- 按序号组成一组维数为 m m m的向量序列, X m ( 1 ) , . . . , X m ( N − m + 1 ) X_m(1), ..., X_m(N-m+1) Xm(1),...,Xm(N−m+1),其中 X m ( i ) = x ( i ) , x ( i + 1 ) , . . . , x ( i + m − 1 ) X_m(i)={x(i),x(i+1), ..., x(i+m-1)} Xm(i)=x(i),x(i+1),...,x(i+m−1)。从第 i i i点开始的 m m m个连续的 x x x值。
- 定义向量
X
m
(
i
)
X_m(i)
Xm(i)与
X
m
(
j
)
X_m(j)
Xm(j)之间的距离
d
[
X
m
(
i
)
,
X
m
(
j
)
]
d[X_m(i),X_m(j)]
d[Xm(i),Xm(j)]为两者对应的元素中最大差值的绝对值。即:
d [ X m ( i ) , X m ( j ) ] = max k = 0 , . . . , m − 1 ( ∣ x ( i + k ) − x ( j + k ) ∣ ) d[X_m(i),X_m(j)] = \max_{k=0,...,m-1}(|x(i+k)-x(j+k)|) d[Xm(i),Xm(j)]=k=0,...,m−1max(∣x(i+k)−x(j+k)∣) - 对于给定的
X
m
(
i
)
X_m(i)
Xm(i),统计
X
m
(
i
)
X_m(i)
Xm(i)与
X
m
(
j
)
X_m(j)
Xm(j)之间距离小于等于
r
r
r的j(
1
≤
j
≤
N
−
m
1\leq j\leq N-m
1≤j≤N−m)的数目,并记作
B
i
B_i
Bi。对于
1
≤
i
≤
N
−
m
1\leq i\leq N-m
1≤i≤N−m,定义:
B i m ( r ) = 1 N − m − 1 B i B_i^m(r)=\frac{1}{N-m-1}B_i Bim(r)=N−m−11Bi - 定义
B
i
m
(
r
)
B_i^m(r)
Bim(r)为:
B i m ( r ) = 1 N − m − 1 B i B_i^m(r)=\frac{1}{N-m-1}B_i Bim(r)=N−m−11Bi - 增加维数到
- 定义
这样,是两个序列在相似容县r下匹配m个点的概率,而是两个序列匹配m+1个点的概率。样本熵定义为:
当N为有限值时,可以用下式估计:
S
a
m
p
E
n
(
m
,
r
,
N
)
=
lim
N
→
{
−
l
n
A
m
(
r
)
B
m
(
r
)
}
SampEn(m,r,N)=\lim_{N\rightarrow} \{-ln\frac{A^m(r)}{B^m(r)}\}
SampEn(m,r,N)=N→lim{−lnBm(r)Am(r)}
代码实现
C语言版
C语言版代码
There are two major steps in the calculations performed by mse:
- Time series are coarse-grained.
- Sample entropy (SampEn) is calculated for each coarse-grained time series.

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)