神经网络总结
神经网络的总结发现现在每天看点东西都有新的认识,也有对以前知识的从新认识。之前听过张玉宏老师的一些课,今天去看了下他在云栖社区的一些深度学习系列文章,其中有介绍神经网络的发展历史,这个老师挺幽默的,理论一大堆,不管什么反正都能说出个一二三,但是感觉文章有时候太宽泛,感兴趣的可以去看下,附上老师文章的链接。一入侯门“深”似海,深度学习深几许(入门系列之一)机器学习机器学习的两层作用(1)面向过
神经网络的总结
发现现在每天看点东西都有新的认识,也有对以前知识的从新认识。
之前听过张玉宏老师的一些课,今天去看了下他在云栖社区的一些深度学习系列文章,其中有介绍神经网络的发展历史,这个老师挺幽默的,理论一大堆,不管什么反正都能说出个一二三,但是感觉文章有时候太宽泛,感兴趣的可以去看下,附上老师文章的链接。
一入侯门“深”似海,深度学习深几许(入门系列之一)
机器学习
机器学习的两层作用
(1)面向过去(对收集到的历史数据,用作训练),发现潜藏在数据之下的模式,我们称之为描述性分析(Descriptive Analysis);
(2)面向未来,基于已经构建的模型,对于新输入数据对象实施预测,我们称之为预测性分析(Predictive Analysis)。
机器学习的形式化定义
台湾大学李宏毅博士的说法,所谓机器学习,在形式上,可近似等同于在数据对象中,通过统计或推理的方法,寻找一个适用特定输入和预期输出功能函数(如图2-5所示)。习惯上,我们把输入变量写作大写的X ,而把输出变量写作大写的Y 。那么所谓的机器学习,在形式上,就是完成如下变换:Y= f(X) 。

具体说来,机器学习要想做得好,需要走好三大步:
(1) 如何找一系列函数来实现预期的功能,这是建模问题。
(2) 如何找出一组合理的评价标准,来评估函数的好坏,这是评价问题。
(3) 如何快速找到性能最佳的函数,这是优化问题(比如说,机器学习中梯度下降法干的就是这个活)。
M-P神经元模型1943年
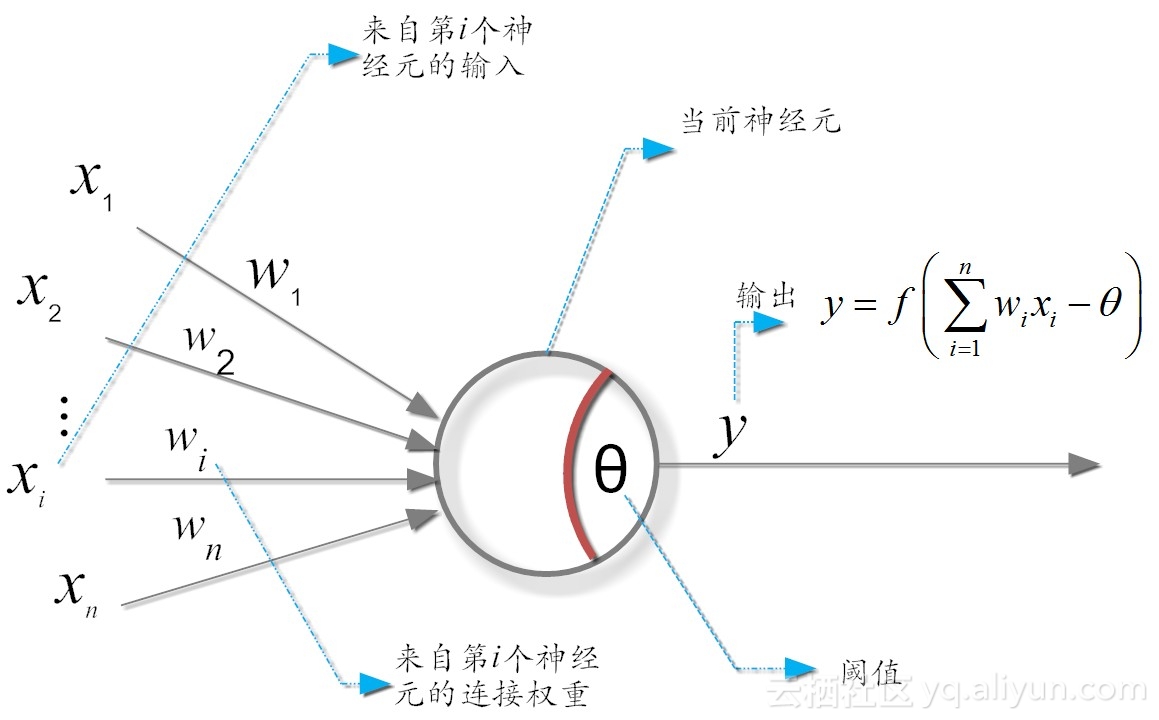
它模拟大脑神经元的工作机理,是上世纪40年代提出但一直沿用至今的“M-P神经元模型”。
在这个模型中,神经元接收来自n个其它神经元传递过来的输入信号,这些信号的表达,通常通过神经元之间连接的权重(weight)大小来表示,神经元将接收到的输入值按照某种权重叠加起来,并将当前神经元的阈值进行比较,然后通过“激活函数(activation function)”向外表达输出(这在概念上就叫感知机,是15之后才出来的概念)
所谓神经网络的学习规则,就是调整权值和阈值的规则
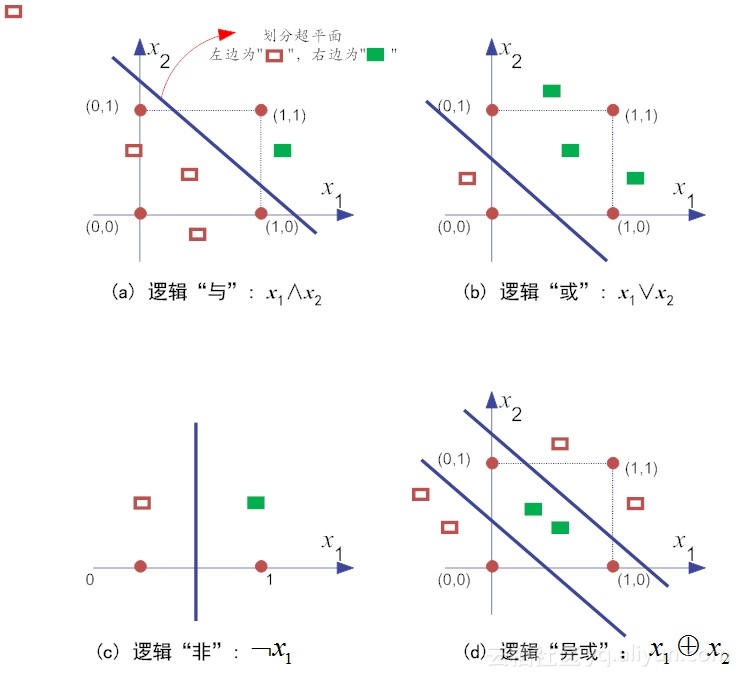
此模型可以完成“与(AND)”、“或(OR)”及“非(NOT)”状态转换,但是却不能完成“异或(XOR)”
异或(XOR),就是当且仅当输入值x1和x2不相等,则输出为1。反之,输出为0。你可以简单粗暴地把“异或”理解为:男欢女爱输出为1,搞基都是没有结果的(输出为0)!老师的理解幽默风趣,容易记住φ(>ω<*) 。
简单来说,感知机模型,就是一个由两层神经元构成的网络结构,输入层接收外界的输入,通过激活函数(阈值)变换,把信号传送至输出层,因此它也称之为“阈值逻辑单元(threshold logic unit)”,正是这种简单的逻辑单元,慢慢演进,越来越复杂,就构成了我们目前研究的热点——深度学习网络。
原子布尔函数中的“与、或、非”等问题都是线性可分的(linearly separable)的问题。对于线性不可分原子布尔函数(如“异或”操作),就不存在简单地线性超平面将其区分开来。
有问题肯定就要寻求解决的办法了!
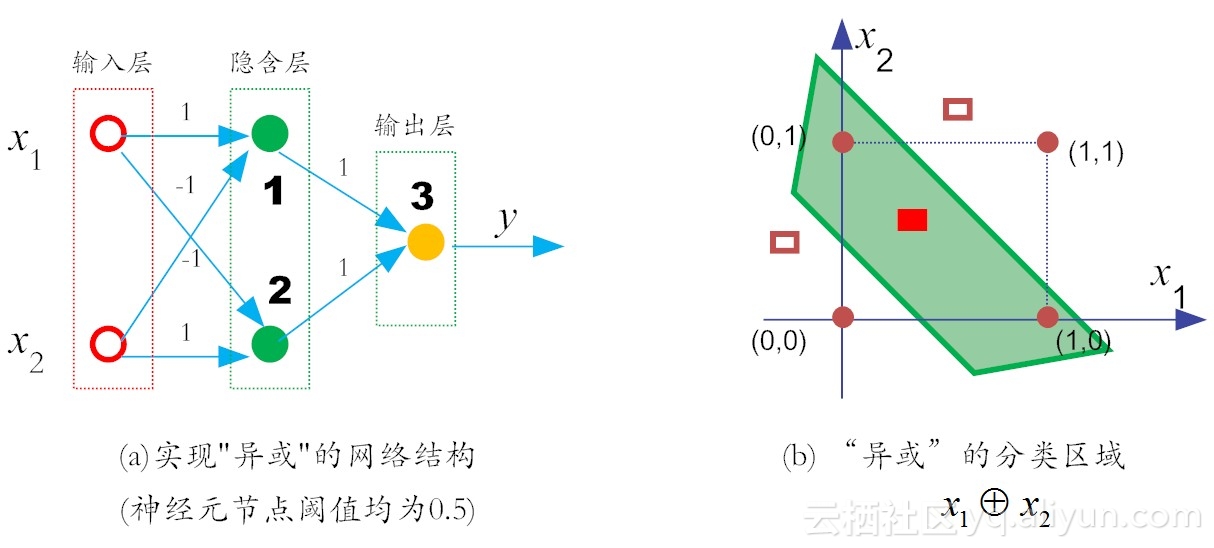
我们在输入层和输出层之间,添加一层神经元,将其称之为隐含层(hidden layer,亦有简称为“隐层”)。这样一来,隐含层和输出层中的神经元都拥有激活函数。直到1975年(此时,距离伊瓦赫年科提出多层神经网络概念已达10年之久了),感知机的“异或难题”才被理论界彻底解决。
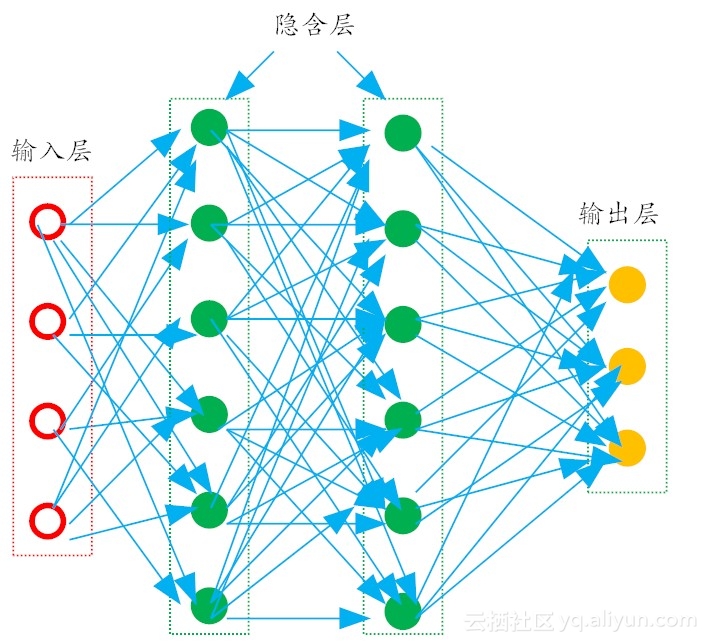
多层前馈神经网络
M-P感知机的模型就是一个神经元模型 多层感知机也就是指多层神经网络(这是笔者自己观点,有错误还请读者指出互相交流)。 在常见的多层神经网络中,每一层神经元仅仅与下一层的神经元全连接。而在同一层,神经元彼此不连接,而且跨层的神经元,彼此间也不相连。这种被简化的神经网络结构,被称之为“多层前馈神经网络(multi-layer feedforward neural networks)”。
神经网络学习的本质,其实就是利用“损失函数(loss function)”,来调节网络中的权重(weight)。
神经网络的权值,到底应该怎么调整?
第一种方法就是“误差反向传播(Error Back propagation,简称BP)”。
第二类改进方法就是当前主流的方法,也就是“深度学习”常用的“逐层初始化”(layer-wise pre-training)训练机制,不同于BP的“从后至前”的训练参数方法,“深度学习”采取的是一种从“从前至后”的逐层训练方法
BP神经网络
简单说来,就是首先随机设定初值,然后计算当前网络的输出,然后根据网络输出与预期输出之间的差值,采用迭代的算法,反方向地去改变前面各层的参数,直至网络收敛稳定。
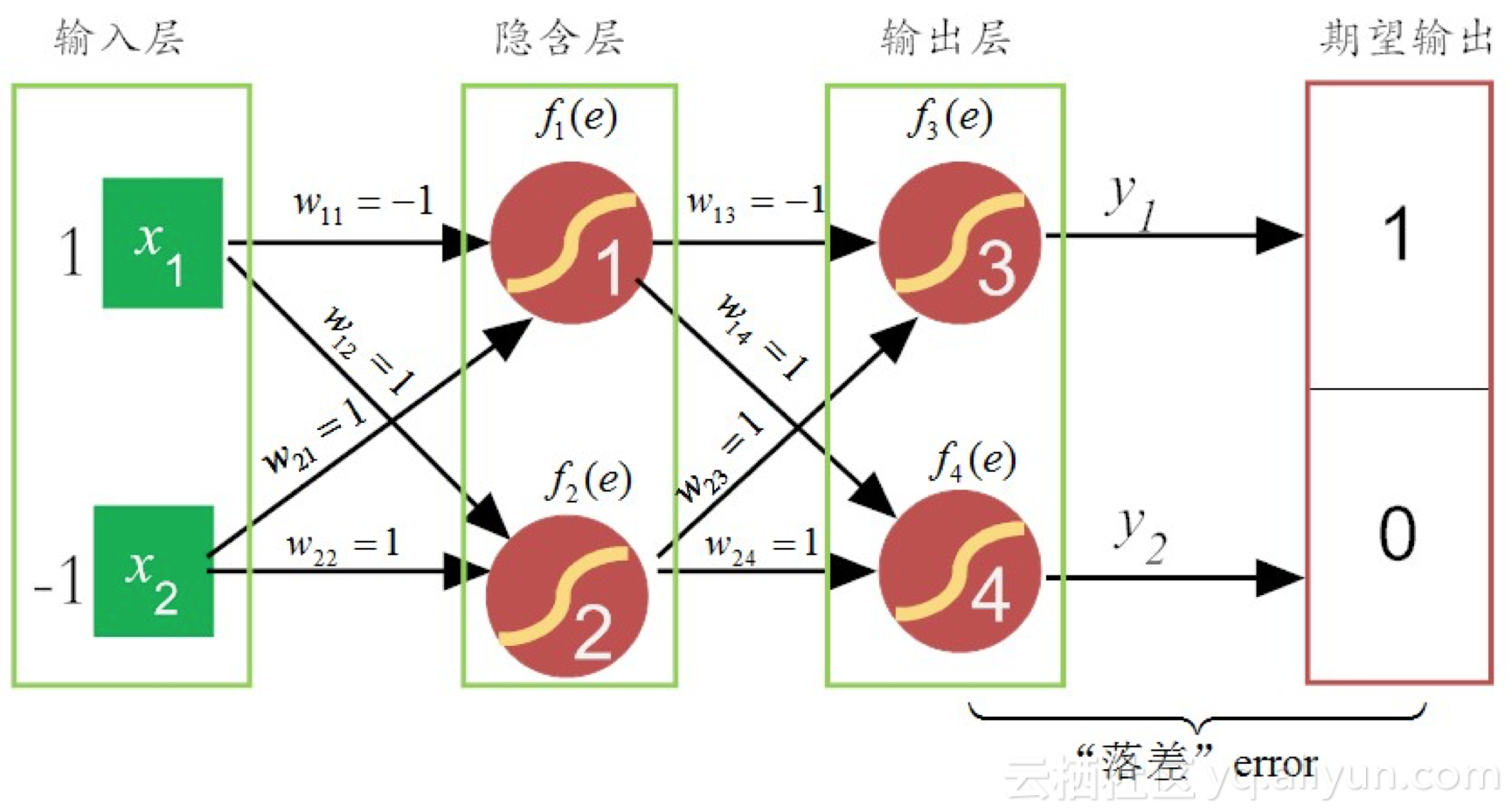
BP神经网络可以分为两步(具体内容可以去看作者原作)
(1)正向传播信号,输出分类信息;
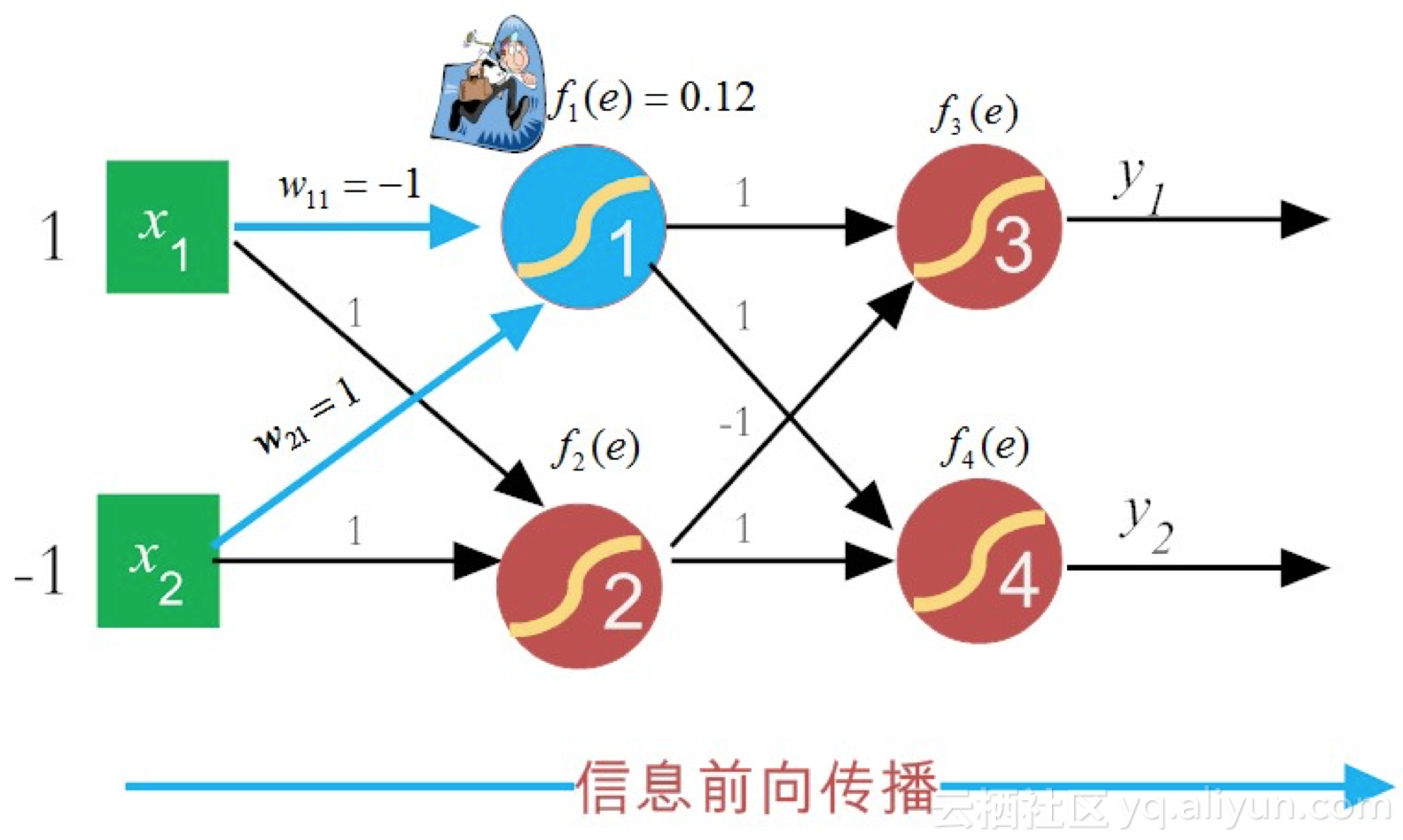
(2)反向传播误差,调整网络权值。如果没有达到预期目的,重走回头路(1)和(2)。
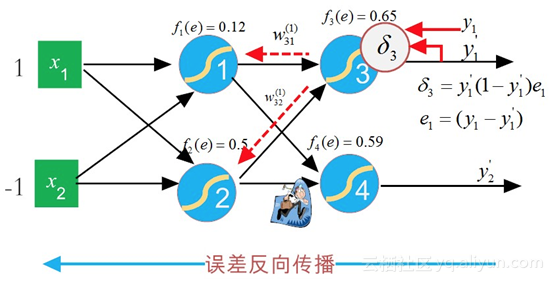
它最早是由Geoffrey Hinton 和 David Rumelhart等人1986年在《Nature》(自然)杂志上发表的论文:“Learning Representations by Back-propagating errors”中提出来的。该论文首次系统而简洁地阐述了反向传播算法在神经网络模型上的应用。
BP反向传播算法直接把纠错的运算量,降低到只和神经元数目本身成正比的程度。但是在一个层数较多网络中,当它的残差反向传播到最前面的层(即输入层),其影响已经变得非常之小,甚至出现梯度扩散(gradient-diffusion),严重影响训练精度。其根源在于对于非凸函数,梯度一旦消失,就没有指导意义,导致它可能限于局部最优。而且“梯度扩散”现象会随着网络层数增加而愈发严重,也就是说,随着梯度的逐层消减,导致它对调整网络权值的调整效益,作用越来越小,故此BP算法多用于浅层网络结构(通常小于等于3),这就限制了BP算法的数据表征能力,从而也就限制了BP的性能上限。相比于原生态的BP算法,虽然它降低了网络参数的训练量,但其网络参数的训练代价还是不小,耗时非常“可观”。
这里附一张梯度的示意图

爬坡愈平缓(相当于斜率较小),抵达山峰(函数峰值)的过程就越缓慢,而如果不考虑爬山的重力阻力(对于计算机而言不存在这样的阻力),山坡越陡峭(相当于斜率越大),顺着这样的山坡爬山,就越能快速抵达山峰(对于函数而言,就是愈加快速收敛到极值点)。
如果我们把山峰“乾坤大挪移”,把爬山峰变成找谷底(即求极小值),这时找斜率最陡峭的坡而攀爬山峰的方法,并没有本质变化,不过是方向相反而已。如果把登山过程中求某点的斜率称为“梯度(gradient)”,而找谷底的方法,就可以把它称之为“梯度递减(gradient descent)”,我们也很容易看到“梯度递减”的问题所在,那就是它很容易收敛到局部最小值。正如攀登高峰,我们会感叹“一山还比一山高”,探寻谷底时,我们也可能发现,“一谷还比一谷低”,只能是“只缘身在此山中”。
所以第二类改进方法就孕育而生了。
深度学习
深度信念网(DBN)的组成元件就是受限玻尔兹曼机 (Restricted Boltzmann Machines, RBM)。而DBN的构建其实分两步走的:(1)单独“无监督”地训练每一层RBM网络,以确保特征向量在映射到不同特征空间时,能够尽可能多地保留特征信息;(2)在DBN的最后一层,设置BP网络,用以接收RBM的输出特征向量作为它的输入特征向量,然后“有监督”地训练实体关系分类器,对网络权值实施微调(Fine-Tune)。
卷积神经网络CNN是深度学习中一大里程碑。“卷积”的概念:所谓卷积,不过是一个函数和另一个函数在某个维度上的加权“叠加”作用而已。
李德毅院士的主题报告。在报告中,李院士便提到了卷积的理解问题,非常有意思。他讲到,什么叫卷积呢?举例来说,在一根铁丝某处不停地弯曲,假设发热函数是f(t) ,散热函数是 g(t) ,此时此刻的温度就是 f(t) 跟g(t)的卷积。在一个特定环境下,发声体的声源函数是f(t) ,该环境下对声源的反射效应函数是 g(t) ,那么这个环境下的接受到声音就是 f(t) 和 g(t) 的卷积。
在不考虑输入层的情况下,一个典型的卷积神经网络通常由若干个卷积层(Convolutional Layer)、激活层(Activation Layer)、池化层(Pooling Layer)及全连接层(Fully Connected Layer)组成。
典型CNN结构
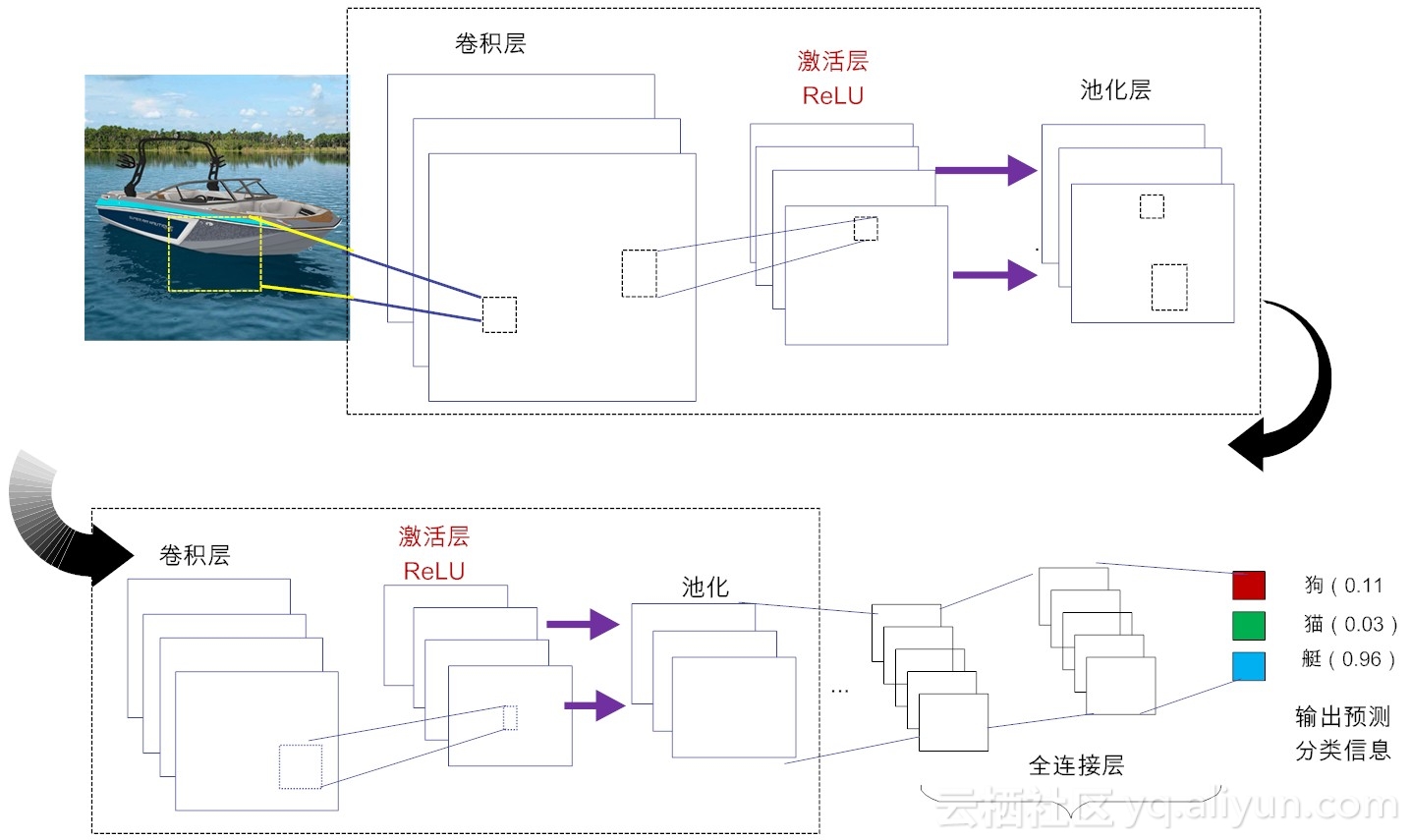
CNN拓扑结构
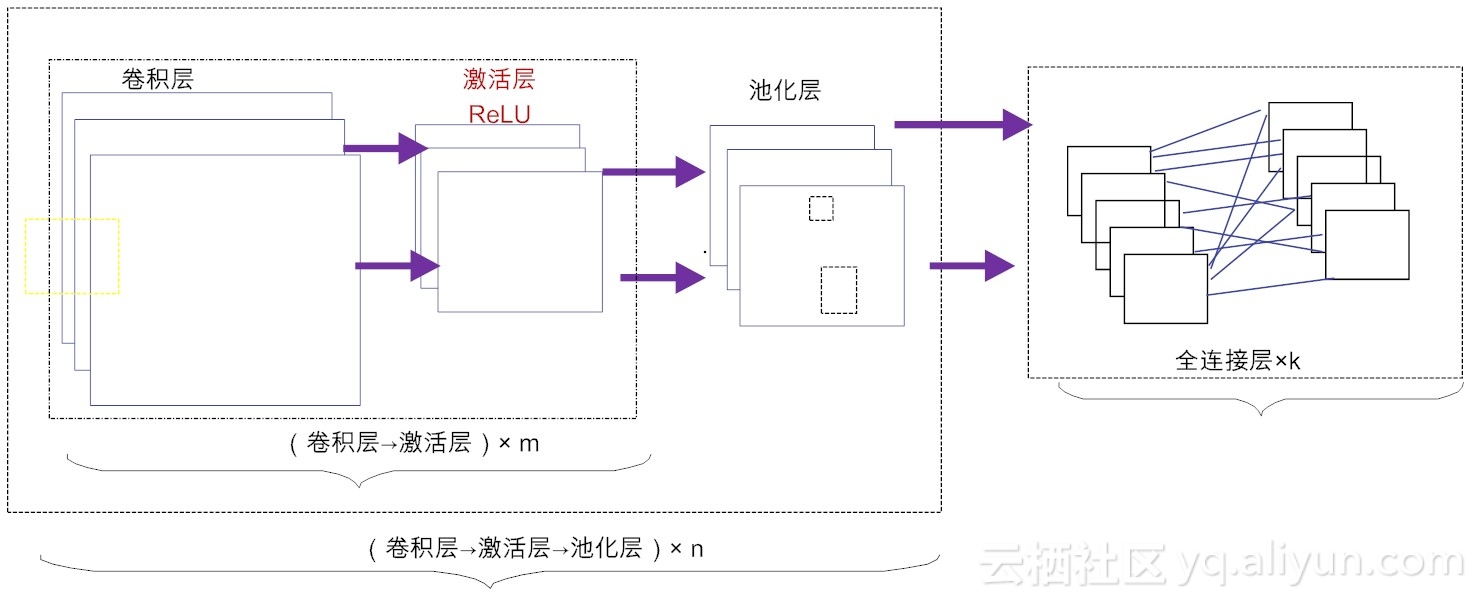
卷积层:这个是卷积神经网络的核心所在。在卷积层,通过实现“局部感知”和“权值共享”等系列的设计理念,可达到两个重要的目的:对高维输入数据实施降维处理和实现自动提取原始数据的核心特征。
激活层:其作用是将前一层的线性输出,通过非线性激活函数处理,从而可模拟任意函数,进而增强网络的表征能力。在深度学习领域,ReLU(Rectified-Linear Unit,修正线性单元)是目前使用较多的激活函数,原因是它收敛更快,且不会产生梯度消失问题。
池化层:亦称亚采样层(Subsampling Layer)。简单来说,利用局部相关性,“采样”在较少数据规模的同时保留了有用信息。巧妙的采样还具备局部线性转换不变性,从而增强卷积神经网络的泛化处理能力。
全连接层:这个网络层相当于传统的多层感知机(Multi-Layer Perceptron,简称MLP,例如我们已经讲解过的BP算法[2])。通常来说,“卷积-激活-池化”是一个基本的处理栈,通过多个前栈处理之后,待处理的数据特性已有了显著变化:一方面,输入数据的维度已下降到可用“全连接”网络来处理了;另一方面,此时全连接层的输入数据已不再是“泥沙俱下、鱼龙混杂”,而是经过反复提纯过的结果,因此最后输出的结果要可控得高。
卷积层的3个核心概念 局部连接、空间位置排列及权值共享
感兴趣的可以去拜读老师的原作
局部连接来减参,权值共享肩并肩(深度学习入门系列之十一)
感谢张玉宏老师的文章,科普作家 (张老师的目标)
如需转载请说明文章来源

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)