
数据库索引系列四:索引算法Hash与BTree的区别
我们在mysql中常用两种索引算法BTree和Hash,两种算法检索方式不一样,对查询的作用也不一样。一、BTreeBTree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量,例如:select * fr
我们在mysql中常用两种索引算法BTree和Hash,两种算法检索方式不一样,对查询的作用也不一样。
一、BTree
BTree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量,例如:
select * from user where name like 'jack%';
select * from user where name like 'jac%k%';
如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
select * from user where name like '%jack';
select * from user where name like simply_name;
二、Hash
Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
1. Hash索引仅仅能满足“=”,“IN”,“<=>”查询,不能使用范围查询。
2. 联合索引中,Hash索引不能利用部分索引键查询。
对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。
3. Hash索引无法避免数据的排序操作
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。
4. Hash索引任何时候都不能避免表扫描
Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。
5. Hash索引遇到大量Hash值相等的情况后性能并不一定会比BTree高
对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能底下。
补充:
鉴于评论区有人问hash对<,>,<=,>=等的是否支持,特意回头看了一下自己的博客,发现之前有写错的地方:hash支持<=与>=,实在是太不慎重,主要是对前人博客中<=>符号的理解错误,以为是作者偷懒,把<=,>=,的缩写写成了<=>,其实这个符号亲测于“=”一致(后来修正的时候还以为是!=,写了条sql测试了一下才又修正过来,其实在数学中这个符号叫“等价于”,代表”推理中左边可以推出右边,右边也可推出左边”的意思。P=>Q:若P则Q,P<=Q:若Q则P,P<=>Q:若P则Q且若Q则P)。接下来看一下我的测试,在库中建一张test表,建一个hash索引num1_hash:
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`num1` int(11) DEFAULT NULL,
`num2` int(11) DEFAULT NULL,
`num3` decimal(14,2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `num1_hash` (`num1`) USING HASH
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;初始化几条数据在里面:
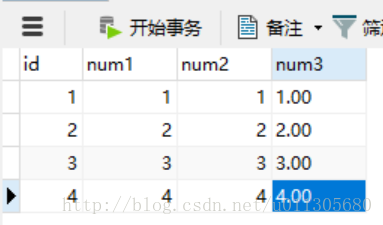
使用<=>符号查询,结果如下:
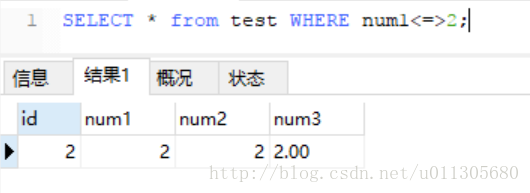
接下来再看看hash索引对<,<=,>,>=符号是否支持:

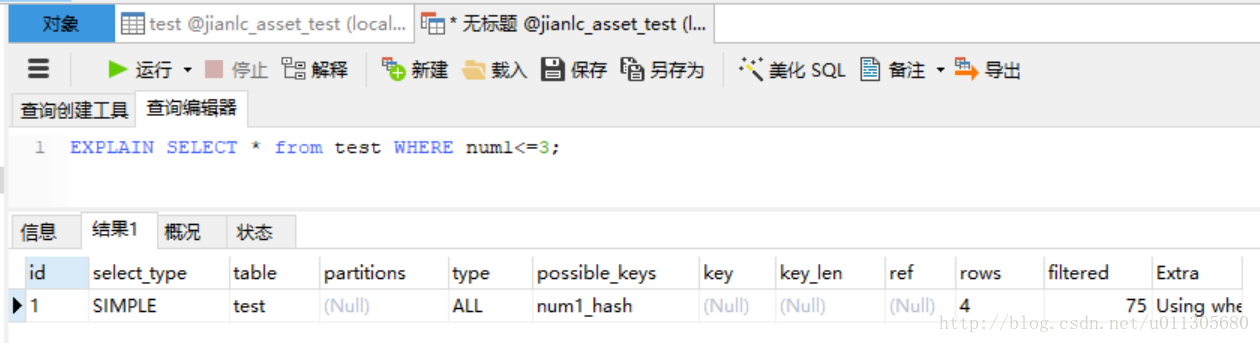


可以看出在<=2与<3是能命中索引的,在<=3与<4是全表扫描,所以<,>等符号也不是完全不能命中索引,跟btree测试结果一样,但是对查询的优化有没有用还没有研究过,后续会继续研究一下进行补充。

无需安装部署,在线快速体验 Byzer
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)