
Hadoop2.7.3的安装详细过程(伪分布式)
1.安装java2.设置ssh免密码登入3.安装Hadoop1.安装java:rpm -ivh jdk-8u101-linux-i586.rpm然后设置环境变量vi /etc/profile在最末端添加:#set java envJAVA_HOME=/usr/java/jdk1.8.0_101PATH=$JAVA_HOME/bin:$PATHCLASSPA
1.安装java
2.设置ssh免密码登入
3.安装Hadoop
1.安装java:
rpm -ivh jdk-8u101-linux-i586.rpm然后设置环境变量
vi /etc/profile
在最末端添加:
#set java env
JAVA_HOME=/usr/java/jdk1.8.0_101
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH最后,再在终端输入java -version测试一下,到此,java便安装结束了。
2.设置ssh免密码登入
ssh-keygen -t rsa
这将会产生一个公钥和私钥
ssh-copy-id -i slaver1
连续按几次enter直至结束
再来一次
ssh-copy-id -i slaver2
3.安装hadoop
tar -xzvf hadoop-2.7.3.tar.gz
cd进入解压后的文件夹
首先,先修改hadoop下面etc/hadoop里面的5个文件:
cd /usr/hadoop/hadoop-2.7.3/etc/hadoop
1.core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>2.yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<value>org.apache.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>3.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>4.hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdf/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdf/name</value>
<final>true</final>
</property>
</configuration>5.hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_101
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"6.yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_101
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"hadoop.env.sh和yarn-env.sh这里的后三行网上很多人都没有写,听说64位的机器才需要加上,但是我的是32位的,没有加上去仍然不行。。
然后把Hadoop文件夹发到其他主机上
scp -r /usr/hadoop slaver1:/usr/hadoop
scp -r /usr/hadoop slaver1:/usr/hadoop
在最后加上环境变量,所有的主机都要设置。
vi /etc/profile
#set hadoop env
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_LOG_DIR=/usr/hadoop/hadoop-2.7.3/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR最后,启动hadoop集群
./sbin/start-all.sh
在终端输入
[root@master ~]# jps
28597 NameNode
28934 ResourceManager
29800 Jps
28792 SecondaryNameNode
[root@master hadoop-2.7.3]# ./bin/hdfs dfsadmin -report
16/10/29 10:02:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Configured Capacity: 97575411712 (90.87 GB)
Present Capacity: 79984197632 (74.49 GB)
DFS Remaining: 79984140288 (74.49 GB)
DFS Used: 57344 (56 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Live datanodes (2):
Name: 192.168.183.84:50010 (slaver1)
Hostname: localhost.localdomain
Decommission Status : Normal
Configured Capacity: 49795620864 (46.38 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 8847638528 (8.24 GB)
DFS Remaining: 40947953664 (38.14 GB)
DFS Used%: 0.00%
DFS Remaining%: 82.23%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sat Oct 29 10:02:28 EDT 2016
Name: 192.168.183.51:50010 (slaver2)
Hostname: localhost.localdomain
Decommission Status : Normal
Configured Capacity: 47779790848 (44.50 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 8743575552 (8.14 GB)
DFS Remaining: 39036186624 (36.36 GB)
DFS Used%: 0.00%
DFS Remaining%: 81.70%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sat Oct 29 10:02:29 EDT 2016
进入http://192.168.183.70:50070/
可以看到
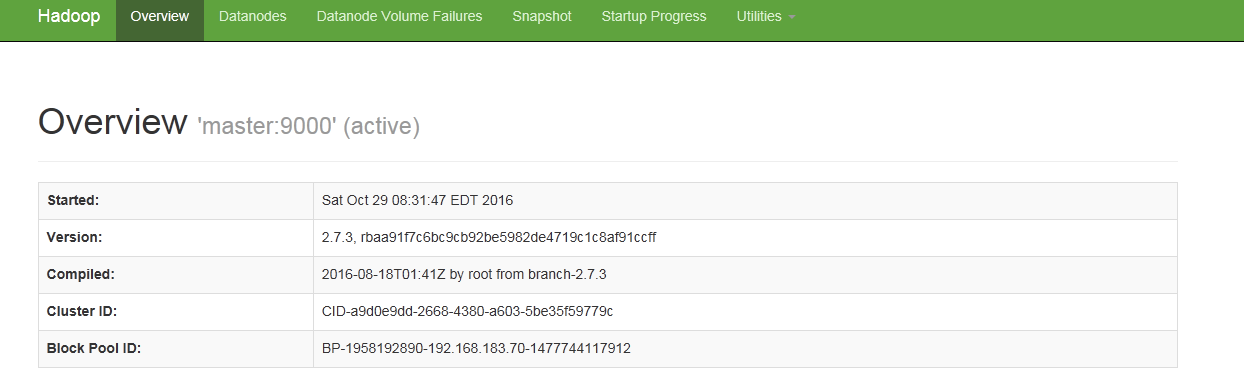
到此,Hadoop安装成功。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)