
Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)
在上一篇《Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)前期准备》一文中,我们讲解了基于HA搭建Hadoop集群环境的基础准备,并配置了SSH无密码登录,同时向大家简要的讲解了Hadoop的相关知识。那么现在我们就可以正式进行基于HA搭建Hadoop集群环境了。一、Hadoop(HA)集群的规划集群规划主机名IP
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/52728397
在上一篇《Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)前期准备》一文中,我们讲解了基于HA搭建Hadoop集群环境的基础准备,并配置了SSH无密码登录,同时向大家简要的讲解了Hadoop的相关知识。这边博文是基于上篇《Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)前期准备》一文搭建Hadoop环境的,请大家先阅读上一篇博文《Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)前期准备》,然后我们再一起搭建Hadoop集群环境。如果您已经阅读了《Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)前期准备》, 那么现在我们就可以正式进行基于HA搭建Hadoop集群环境了。
一、Hadoop(HA)集群的规划
集群规划
| 主机名 | IP | NameNode | DataNode | Yarn | ZooKeeper | JournalNode |
| liuyazhuang145 | 192.168.0.145 | 是 | 是 | 否 | 是 | 是 |
| liuyazhuang146 | 192.168.0.146 | 是 | 是 | 否 | 是 | 是 |
| liuyazhuang147 | 192.168.0.147 | 否 | 是 | 是 | 是 | 是 |
二、Hadoop(HA)集群环境搭建
注:我们搭建环境集中在liuyazhuang145主机上搭建,搭建完毕将相应的文件拷贝到liuyazhuang146和liuyazhuang147主机。
1、安装JDK
1.1下载JDK
可以到Oracle官网下载Linux版本的JDK,链接为:http://www.oracle.com/technetwork/java/javase/downloads/index.html 我下载的是jdk1.7.0_72
1.2解压JDK
在命令行输入tar -zxvf jdk-7u72-linux-x64.tar.gz 进行解压
1.3配置环境变量
在命令行输入vim /etc/profile打开profile文件,在文件末尾添加如下代码:
JAVA_HOME=/usr/local/jdk1.7.0_72
CLASS_PATH=.:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASS_PATH PATH1.4拷贝文件
在命令行输入如下命令将JDK环境和/etc/profile文件拷贝到liuyazhuang146和liuyazhuang147主机上。
scp -r /usr/local/jdk1.7.0_72 liuyazhuang146:/usr/local
scp -r /usr/local/jdk1.7.0_72 liuyazhuang147:/usr/local
scp /etc/profile liuyazhuang146:/etc/
scp /etc/profile liuyazhuang147:/etc/至此,JDK环境搭建完成。
2、搭建Zookeeper集群
2.1下载Zookeeper
在Apache官网下载Zookeeper,链接为:http://www.apache.org/dyn/closer.cgi/zookeeper/我下载的是zookeeper-3.4.9
2.2解压Zookeeper
在命令行输入tar -zxvf zookeeper-3.4.9.tar.gz对zookeeper进行解压。
2.3Zookeeper集群搭建
切换到Zookeeper的conf目录下执行以下命令
cp zoo_sample.cfg zoo.cfg # The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper-3.4.9/data
dataLogDir=/usr/local/zookeeper-3.4.9/datalog
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=liuyazhuang145:2888:3888
server.2=liuyazhuang146:2888:3888
server.3=liuyazhuang147:2888:3888mkdir data
mkdir dataLog执行命令
vim myid2.4配置Zookeeper环境变量
为操作方便,我们也将Zookeeper配置到环境变量中,加上之前配置的JDK,我们在profile的配置如下:
JAVA_HOME=/usr/local/jdk1.7.0_72
CLASS_PATH=.:$JAVA_HOME/lib
ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.9
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
export JAVA_HOME HADOOP_HOME CLASS_PATH PATH2.5拷贝文件
将Zookeeper环境和profile文件分别拷贝到liuyazhuang146和liuyazhuang147主机上。如下命令:
scp -r /usr/local/zookeeper-3.4.9 liuyazhuang146:/usr/local
scp -r /usr/local/zookeeper-3.4.9 liuyazhuang147:/usr/local
scp /ect/profile liuyazhuang146:/etc/
scp /ect/profile liuyazhuang147:/etc/2.6修改其他主机的myid文件
注:别忘了将liuyazhuang146主机上Zookeeper中myid文件内容修改为2 将liuyazhuang147主机上Zookeeper中myid文件内容修改为3
至此,Zookeeper集群环境搭建完毕。
3、Hadoop集群环境搭建
同样的,我们也是现在liuyazhuang145主机上搭建Hadoop环境,然后将环境拷贝到liuyazhuang146主机和liuyazhuang147主机上。
3.1下载Hadoop
同样的,我们也是在Apache官网下载的Hadoop,我这里下载的hadoop 2.5.2版本的。
3.2解压Hadoop
输入命令tar -zxvf hadoop-2.5.2.tar.gz解压Hadoop
3.3配置Hadoop
1) core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定hadoop数据临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.5.2/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>liuyazhuang145:2181,liuyazhuang146:2181,liuyazhuang147:2181</value>
</property>
</configuration>2) hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>liuyazhuang145:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>liuyazhuang145:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>liuyazhuang146:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>liuyazhuang146:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://liuyazhuang145:8485;liuyazhuang146:8485;liuyazhuang147:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop-2.5.2/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop-2.5.2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop-2.5.2/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration><configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration><configuration>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>liuyazhuang147</value>
</property>
</configuration>别分输入如下命令:
mkdir -p /usr/local/hadoop-2.5.2/journal
mkdir -p /usr/local/hadoop-2.5.2/hdfs/name
mkdir -p /usr/local/hadoop-2.5.2/hdfs/data5) hadoop-env.sh
找到文件的export JAVA_HOME=${JAVA_HOME} 一行,将其修改为export JAVA_HOME=/usr/local/jdk1.7.0_72
6)slaves
liuyazhuang145
liuyazhuang146
liuyazhuang147加上之前配置的JDK环境变量和Zookeeper环境变量,/etc/profile文件如下所示:
JAVA_HOME=/usr/local/jdk1.7.0_72
CLASS_PATH=.:$JAVA_HOME/lib
HADOOP_HOME=/usr/local/hadoop-2.5.2
ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.9
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$PATH
export JAVA_HOME HADOOP_HOME CLASS_PATH PATH在命令行分别输入如下命令
scp -r /usr/local/hadoop-2.5.2 liuyazhuang146:/usr/local
scp -r /usr/local/hadoop-2.5.2 liuyazhuang147:/usr/local
scp /etc/profile liuyazhuang146:/etc
scp /etc/profile liuyazhuang147:/etc至此,Hadoop集群环境搭建完毕。
三、集群的启动
1、启动Zookeeper集群
分别在liuyazhuang145、liuyazhuang146、liuyazhuang147上执行如下命令启动zookeeper集群;
zkServer.sh start 如下:
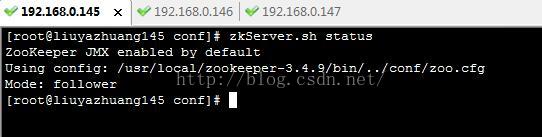
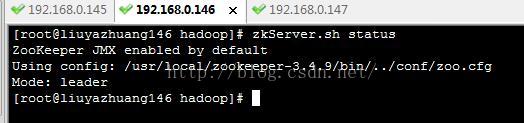
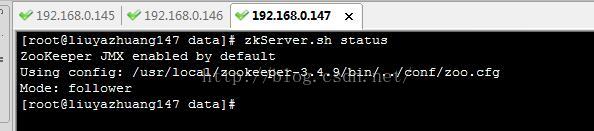
2、启动journalnode集群
在liuyazhuang145上执行如下命令完成JournalNode集群的启动
[root@liuyazhuang145 ~]# hadoop-daemons.sh start journalnode 3、格式化zkfc,在zookeeper中生成ha节点
在liuyazhaung145执行如下命令,完成格式化
hdfs zkfc –formatZK (注意,这条命令最好手动输入,直接copy执行有可能会有问题)
4、 格式化hdfs
hadoop namenode –format 5、 启动NameNode
首先在mast1上启动active节点,在liuyazhuang145上执行如下命令
[root@liuyazhuang145 ~]# hadoop-daemon.sh start namenode #把NameNode的数据同步到liuyazhuang146上
[root@liuyazhuang146 ~]# hdfs namenode -bootstrapStandby
#启动liuyazhuang146上的namenode作为standby
[root@liuyazhuang146 ~]# hadoop-daemon.sh start namenode 6、启动启动datanode
在liuyazhuang145上执行如下命令
[root@liuyazhuang145 ~]# hadoop-daemons.sh start datanode 7、 启动yarn
在作为资源管理器上的机器上启动,我这里是liuyazhuang147,执行如下命令完成yarn的启动
[root@liuyzhuang147 ~]# start-yarn.sh 8、启动ZKFC
在liuyazhaung145上执行如下命令,完成ZKFC的启动
[hadoop@liuyazhuang145 ~]# hadoop-daemons.sh start zkfc liuyazhuang145:
[root@liuyazhuang145 ~]# jps
3914 DFSZKFailoverController
3557 DataNode
4081 NameNode
2552 QuorumPeerMain
3357 JournalNode
3669 NodeManager
5716 Jps
[root@liuyazhuang145 ~]#
liuyazhuang146:
[root@liuyazhuang146 ~]# jps
3719 NameNode
3129 DataNode
6543 Jps
2460 QuorumPeerMain
3451 DFSZKFailoverController
3241 NodeManager
3025 JournalNode
[root@liuyazhuang146 ~]#
liuyazhuang147:
[root@liuyazhuang147 ~]# jps
2700 JournalNode
2838 DataNode
3569 Jps
2952 ResourceManager
3040 NodeManager
2471 QuorumPeerMain
[root@liuyazhuang147 ~]#四、测试HA的高可用性
启动后liuyazhuang145的namenode和liuyazhuang146的namenode如下所示:
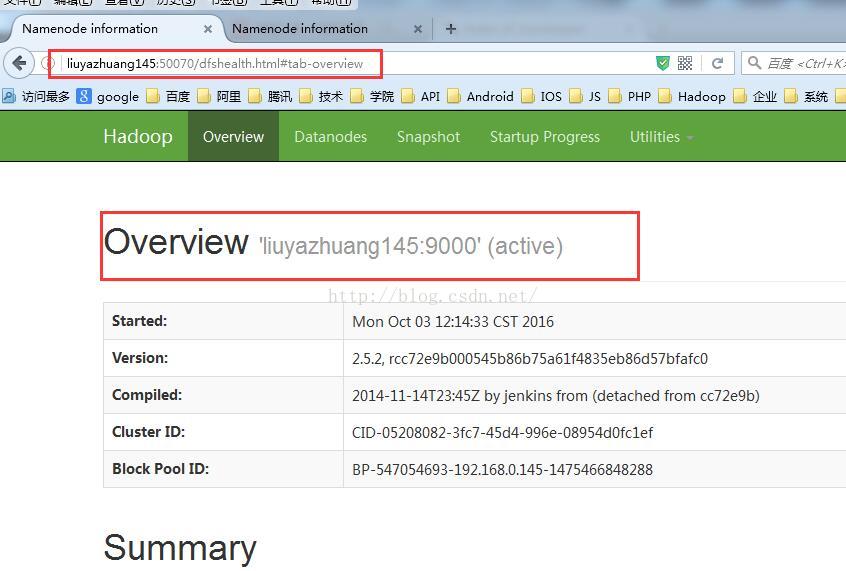
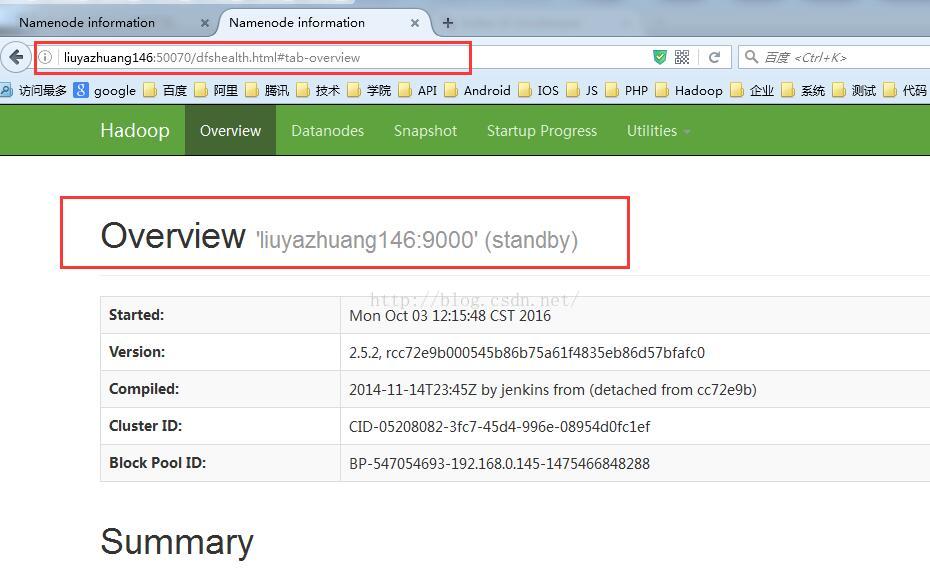
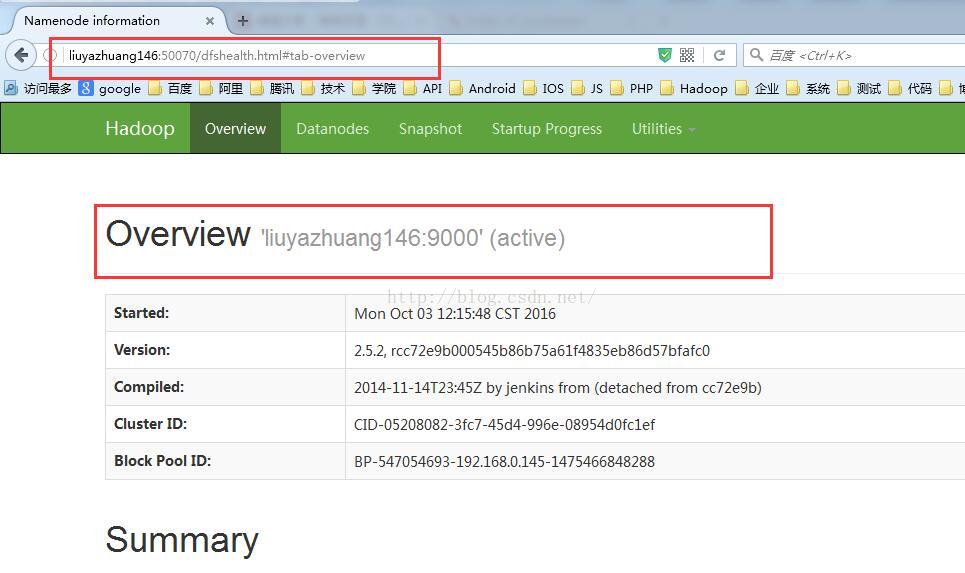
此时,我们停掉liuyazhuang145主机上的namenode
在liuyazhuang145主机上执行命令hadoop-daemon.sh stop namenode ,此时liuyazhuang146上的namenode变为active状态
此时,我们启动liuyazhuang145上的namenode,在命令行输入命令:hadoop-daemon.sh start namenode
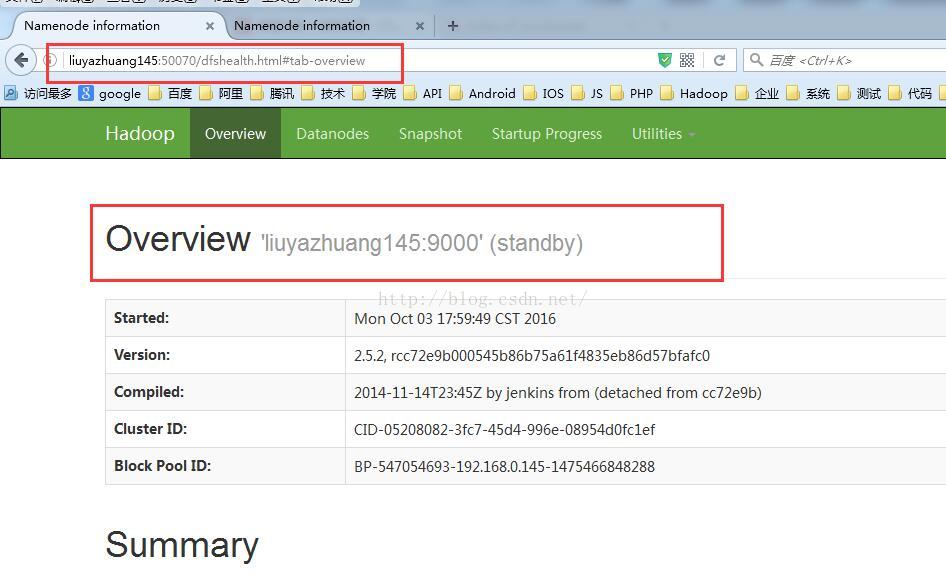
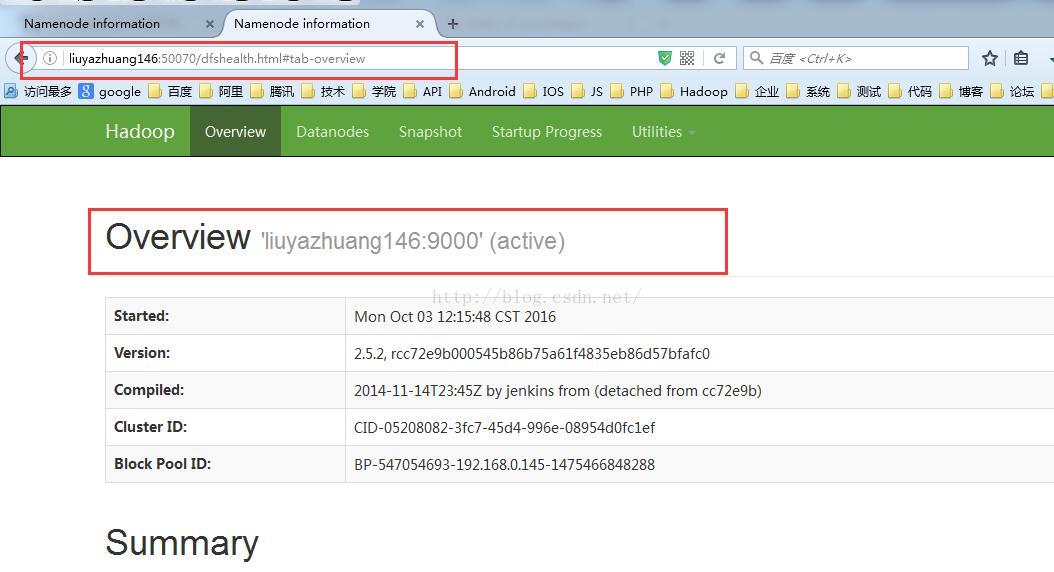
此时,我们看到liuyazhuang145上的namenode为standby状态 liuyazhuang146上的namenode为active状态
如果liuyazhuang146上的namenode挂掉,liuyazhuang145上的namenode就会变为active状态,再次重启liuyazhuang146上的namenode,liuyazhuang146上的namenode即变为standby状态,实现了namenode的高可用。
五、附录
增减DataNode需要更改的文件:
hdfs-site.xml
slaves
/etc/hosts
另外如果新加入节点,需要更新集群内所有节点的公钥,以便互相之间可以无密码访问。
至此,Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)搭建完毕。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 4
4 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)