
Hadoop与Spark整合
搭建Hadoop集群搭建Hadoop集群请参考博文《Hadoop集群搭建及wordcount测试》,在此不再赘述。安装Scala在scala官网下载合适的版本,将scala安装包拷贝到linux安装目录,执行解压缩命令进行安装:sudo tar -zxvf scala-2.11.7.tgz -C /usr/opt/spark解压缩完成后,进入etc目录,修改profile,追加以下内容e
- 搭建Hadoop集群
搭建Hadoop集群请参考博文《Hadoop集群搭建及wordcount测试》,在此不再赘述。 - 安装Scala
在scala官网下载合适的版本,将scala安装包拷贝到linux安装目录,执行解压缩命令进行安装:
sudo tar -zxvf scala-2.11.7.tgz -C /usr/opt/spark解压缩完成后,进入etc目录,修改profile,追加以下内容
export SCALA_HOME=/usr/opt/spark/scala-2.11.7
export path=$SCALA_HOME/bin:$path执行命令source /etc/profile重新编译profile文件,检查scala安装是否成功,执行scala -version,如果正确安装,会出现如下图提示

3. 安装Spark
在spark官网下载和hadoop配套的spark版本,将spark安装包拷贝到linux安装目录,执行解压缩命令
sudo tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz -C /usr/opt/spark修改/etc/profile文件,追加以下内容
export SPARK_HOME=/usr/opt/spark/spark-1.5.2-bin-hadoop2.6
export path=$SPARK_HOME/bin:$SPARK_HOME/sbin:$path最终profile文件内容如下:
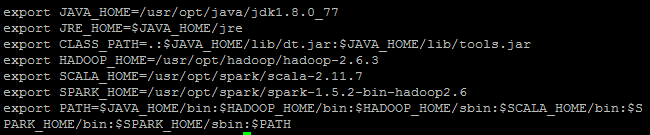
重新编译profile文件。
进入spark根目录/conf,执行命令
rm spark_env.sh.template spark_env.sh使spark配置文件生效,利用vi命令修改此配置文件,追加以下内容:
export SCALA_HOME=/usr/opt/spark/scala-2.11.7
export SPARK_WORKER_MEMORY=512m
export JAVA_HOME=/usr/opt/java/jdk1.8.0_77
export SPARK_MASTER_IP=192.168.30.128
利用上述操作,使得log4j.properties文件生效,编辑slaves文件,将所有slave机器添加到文件中,如图示

给hadoop用户赋予对spark目录的管理权限,命令如下
sudo chown -R czliuming:czliuming /usr/opt/spark利用ssh将整个spark目录拷贝到所有slave机器,命令如下:
scp -r /usr/opt/spark czliuming@ubuntu-slave:/usr/opt如果拷贝失败,请先在slave机器上建立spark目录,保证hadoop用户对此目录有管理权限的情况下,逐项将spark目录下的scala和spark安装目录拷贝到相应目录下,然后,在slave机器上修改profile环境变量。
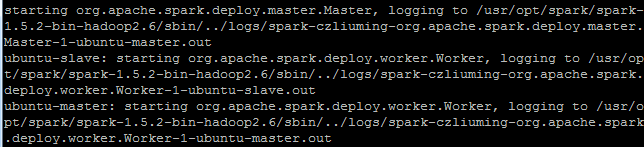
至此,spark安装完毕,进入master机器spark安装目录,执行以下命令启动spark集群:
sbin/start-all.sh启动日志如下图所示:
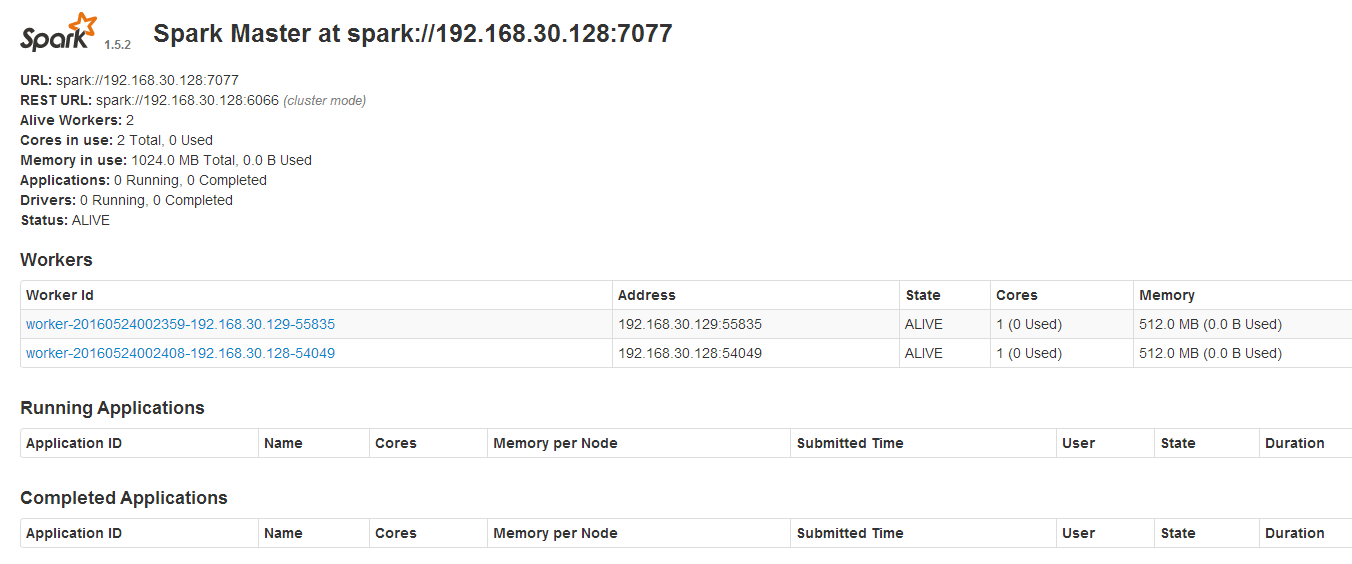
打开浏览器,输入 http://192.168.30.128:8080查看spark集群运行情况,如下图所示:
4.Hadoop与Spark整合
所有服务器修改spark-env.sh文件,追加hadoop的配置文件路径,内容如下:
export HADOOP-CONF-DIR=/usr/opt/hadoop/hadoop-2.6.3/etc/hadoop进入hadoop安装目录,启动hadoop集群,命令如下
sbin/start-all.sh进入spark安装目录,启动spark集群,启动成功后,向hadoop yarn提交任务,命令如下:
spark-submit --master yarn-cluster --class org.apache.spark.examples.SparkLR --name SparkLR /usr/opt/spark/spark-1.5.2-bin-hadoop2.6/lib/spark-examples-1.5.2-hadoop2.6.0.jar
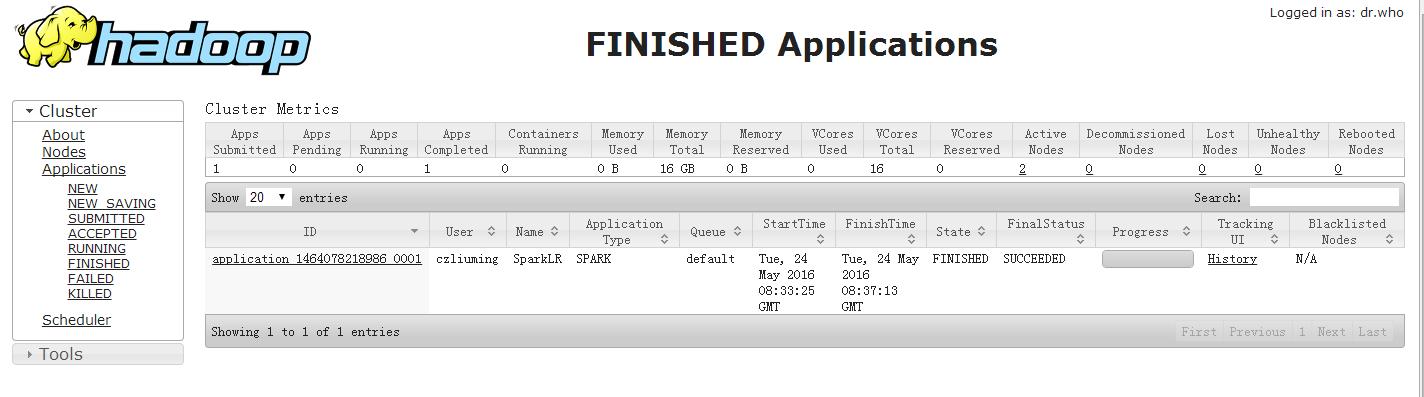
执行成功后进入hadoop WebUI查看任务执行情况,如下图所示:
下面给出spark-submit常用参数,转自其他博客。

更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)