Spark学习笔记8-搭建spark的HA(用zookeeper实现spark的高可用)
0.说明我配置的是一个standby节点。如果电脑多建议配置2个standby。1.下载zookeeper下载网址:zookeeper.apache.org我下载的是3.4.6版:用tar命令解压到/usr/local/spark里面:2.配置zookeeper的bin目录在~/.bashrc里面,配置zookeeper的bin目录:3.修改zookeeper配置文件在zoo
0.说明
我配置的是一个standby节点。如果电脑多建议配置2个standby。
1.下载zookeeper
下载网址:
zookeeper.apache.org
我下载的是3.4.6版: 
用tar命令解压到/usr/local/spark里面:
2.配置zookeeper的bin目录
在~/.bashrc里面,配置zookeeper的bin目录:
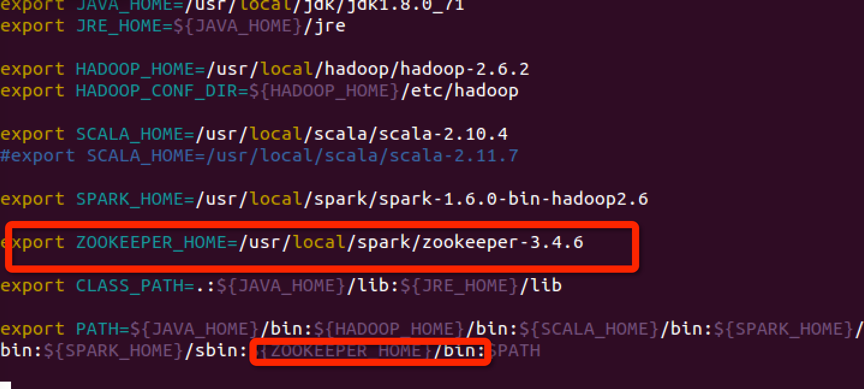
3.修改zookeeper配置文件
在zookeeper目录下添加data,logs文件夹。用来放日志和数据: 


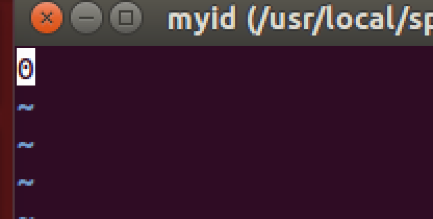
进入data文件夹,添加名为myid的文件。修改里面参数
在master上修改myid,id号为0: 
再在Worker1上修改myid,id号为1: 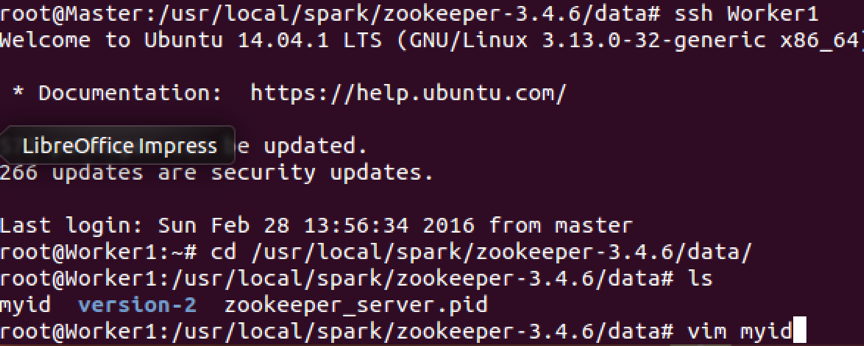
进入里面到conf文件夹,复制zoo_sample.cfg文件,命明为zoo.cfg。 
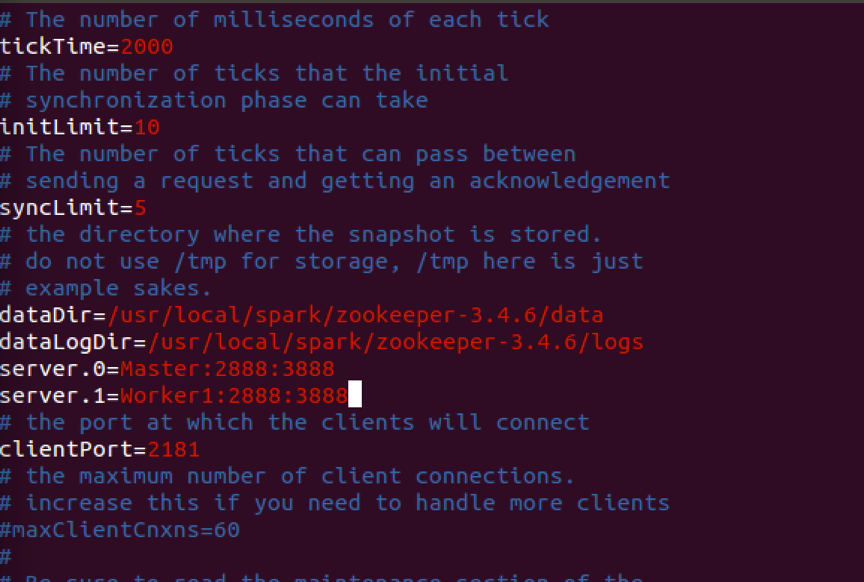
并用vim编译器修改zoo.cfg文件,修改添加内容如下:
4.修改spark相关配置
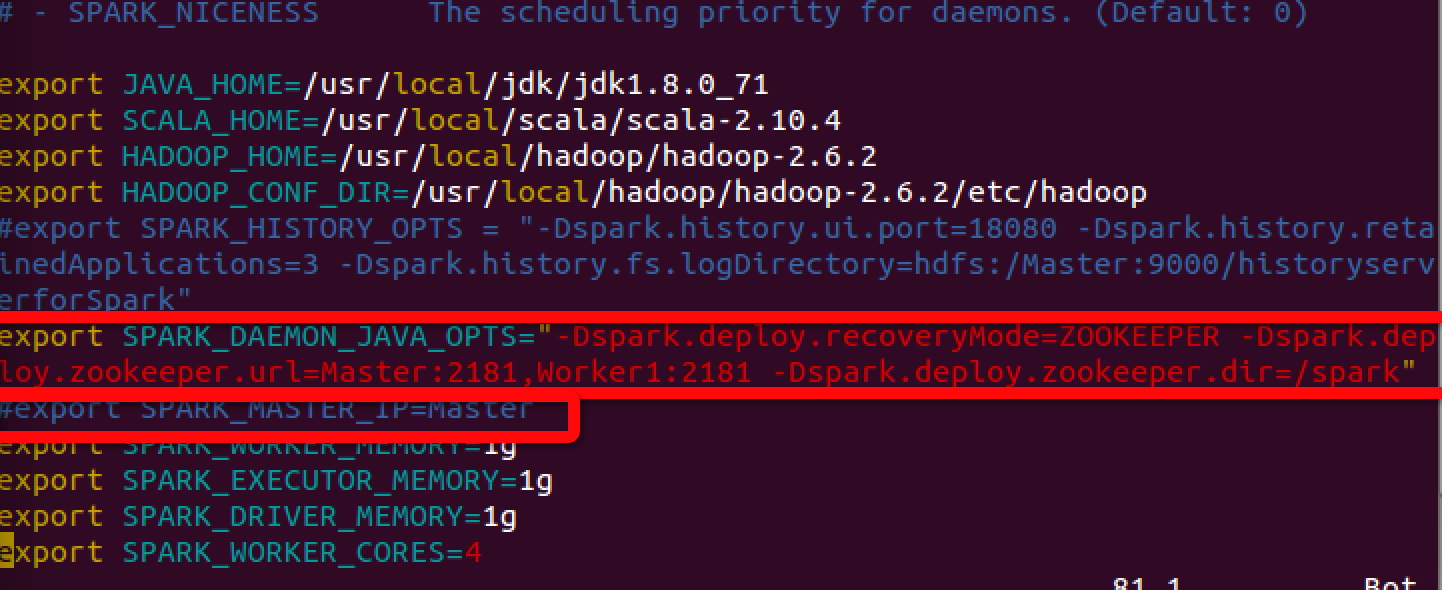
再进入spark的conf里面修改spark-env.sh文件,注意还要去掉以前配置的SPARK_MASTER_IP=MASTER: 
5.启动zookeeper
这里要在master和Worker1上都启动一下才行,如下分别在master和worker1上用zkServer.sh start命令启动。 
可以用jps命令查看 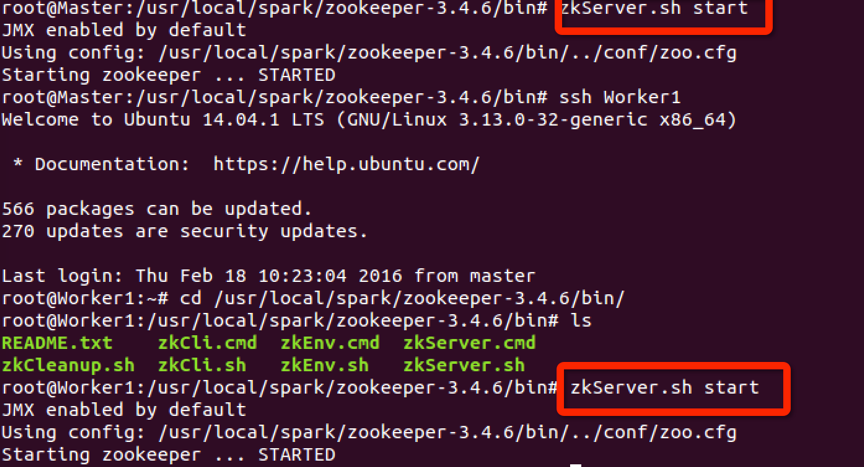
然后启动hadoop和spark。根据以前的方法启动hadoop-dfs.sh,spark-all.sh,spark-history-server.sh(这里测试用不启动hadoop-yarn.sh了)。
6.查看节点状态
在8080里查看,master显示为alive,worker显示为standby
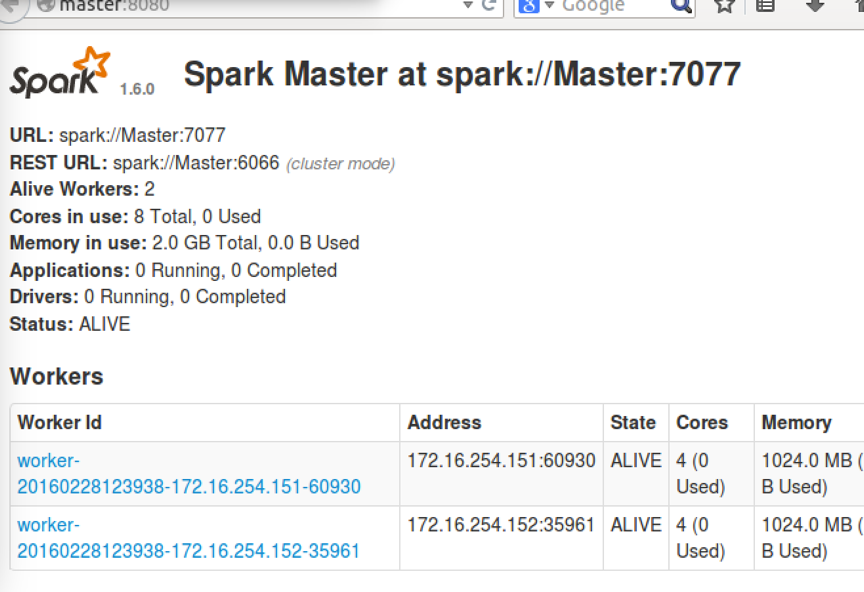
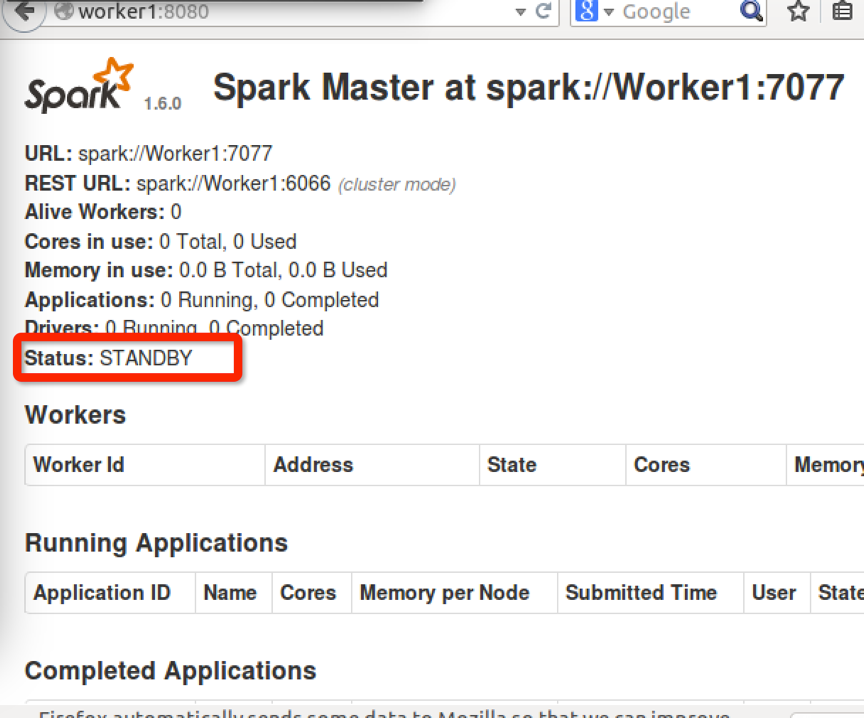
(当然可以再命令行下查看zookeeper的状态,用命令zkServer.sh status)
7.测试zookeeper
关闭master节点上的master 
再看master:8080查看,发现master挂了,Worker1作为了新的master
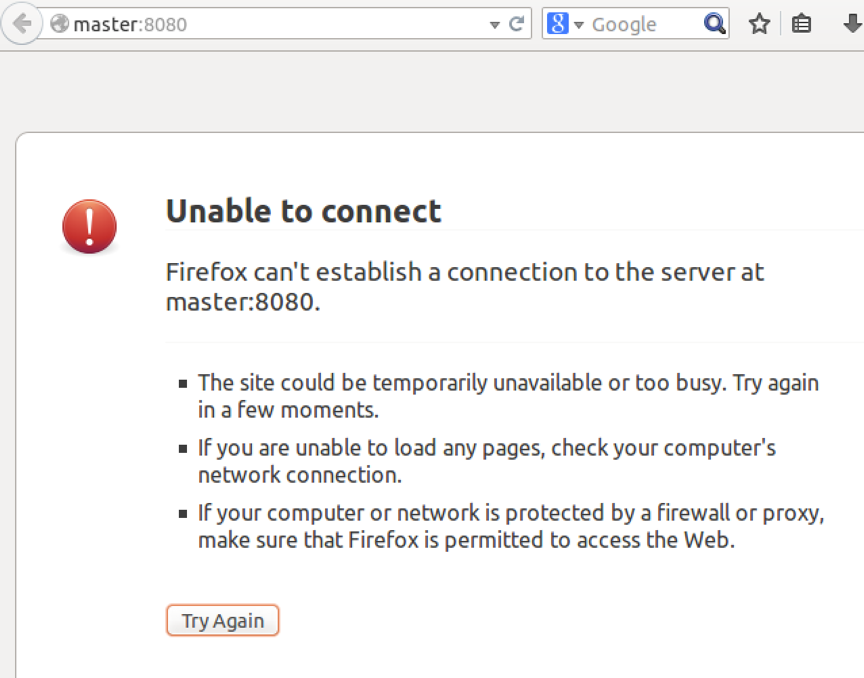
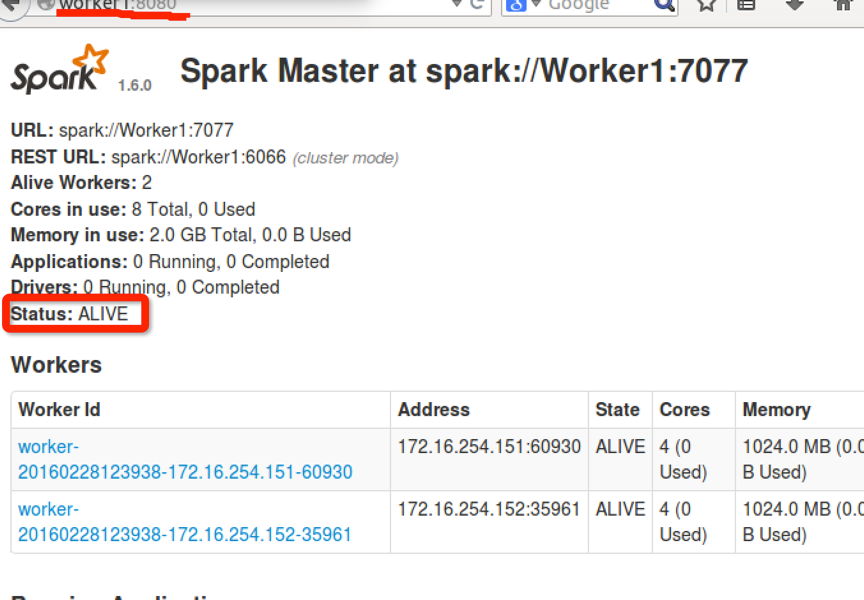
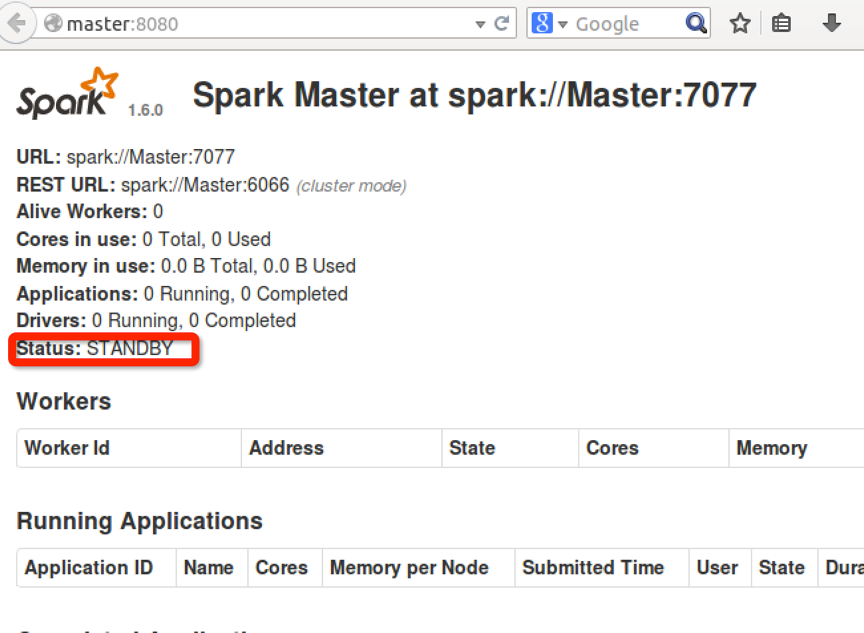
再启动master中的master,看到master作为了新的standby,也就是作为了Worker1的备用。


云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)