
GEAK HIP:将 GEAK 扩展到 HIP 代码优化
我们在Qwen3-32B 的 TP=2 设置下,基于 ROCm 的 AITER 框架[9],对这些规则进行了测试,并将“智能体生成的启发式”与 AITER 的“默认启发式”以及“离线调优启发式”做对比。本文介绍如何使用面向 AI 的高效内核生成(Generating Efficient AI-centric Kernels,GEAK)智能体对 HIP 代码进行自动化优化,展示 GEAK 的智能体流
GEAK HIP:将 GEAK 扩展到 HIP 代码优化
原文作者:Ethan Yang, Chao Xu, Jianghui Wang, Bin Ding, Saptarshi Majumder, Ziqiong Liu, Pratik Prabhanjan Brahma, Dong Li, Zicheng Liu, Emad Barsoum.

本文介绍如何使用面向 AI 的高效内核生成(Generating Efficient AI-centric Kernels,GEAK)智能体对 HIP 代码进行自动化优化,展示 GEAK 的智能体流水线如何帮助开发者与客户优化内核代码,并在 AMD 平台上提升 AI 性能。
要点速览:
-
我们将GEAK 扩展到 HIP 代码优化,让 AI 智能体借助前沿 LLM 对 HIP kernel 进行迭代改写与调优,提高效率。
-
提供面向HIP 的评测示例:在基础 ROCm~~™~~ 与MMCV kernel 集合上,平均加速分别为 1.08x 与 1.20x。
-
面向实际客户瓶颈:Voxelization 与 SwiGLU,实测分别获得 2.07x 与 1.68x 的加速,相比工程师手工优化版本也有提升。
-
针对GEMM 启发式规则优化,智能体生成的规则相较手写规则平均获得 1.28x 的加速。
基于此前GEAK 框架(最初用于从高层描述生成 Triton kernel)[1],我们现将 GEAK 扩展到“优化现有 HIP 代码”,把 baseline 的 HIP 实现迭代为更高效、面向 AMD 硬件的版本。
HIP kernel 语言是类 CUDA 的 C++ 方言,用于编写可在 AMD 硬件上运行、同时可移植到 NVIDIA GPU 的 GPU kernel。它支持 single-source C++ 特性,便于开发高性能且具可移植性的代码。对 AI 负载而言,HIP kernel 的优化质量至关重要:未充分调优的实现会成为瓶颈;而精心打磨的实现则能显著降低时延、提升吞吐,并更好地利用现代硬件资源。
与先前专注Triton 的“从文本到内核”不同,将 GEAK 适配为 HIP 优化需做关键调整:以“已有代码”为输入、在指令中体现 HIP 语法、构建可编译/可调试的闭环、并将目标聚焦于“迭代降时延”而非“从零生成”。同时,也建议读者了解新增的 GEAK-Triton v2 框架[2],其在Triton kernel 优化上融合了更多面向硬件的反馈环路。
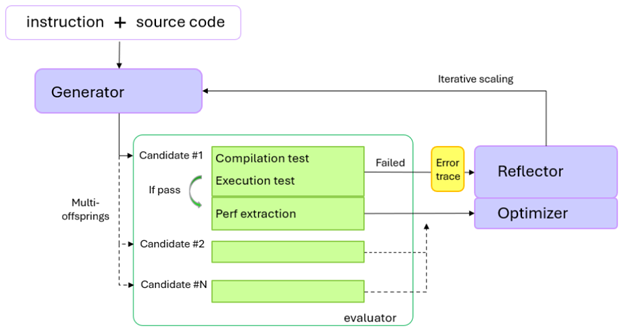
图1:用于 HIP 代码优化的 GEAK 智能体概览
如图1 所示,面向 HIP kernel 的优化智能体系统与原始 Triton 生成框架在总体结构上一致。主要差异如下:
-
Generator(生成器):接收指令与可运行的HIP 源码,输出可能更优的改写版本。
-
Evaluator(评测器):在目标kernel 文件原地替换后进行编译、运行与性能抽取,收集编译/运行阶段的报错信息。若无错误,则将性能指标与代码交给 Optimizer 以生成进一步的优化方向。
-
Reflector(反思器):当编译/运行失败,或在单测中无法正确抽取性能/验证指标时触发,帮助反思和纠错。
-
可配置“多后代”数为 1到N,决定每次同时生成多少个代码变体。需要注意的是,增大该数会增大整体时长,因为相同的迭代系数也会作用于每个变体的迭代次数。
此外,先前在Triton 生成中介绍的可组合、可配置技术,同样适用于 HIP kernel 优化。
HIP 优化示例与案例
本节给出一组HIP 优化示例与真实案例,覆盖从入门到产业场景的不同上下文,展示 GEAK 的使用流程、性能收益与必要的适配:
-
ROCm 示例:用来演示在 HIP 优化中的基础使用方法。
-
MMCV 示例:取自广泛使用的计算机视觉库 MMCV 的 10 个 kernel,使用 GEAK 进行优化。
-
案例1:Voxelization。来自客户侧的瓶颈 kernel,GEAK 的结果优于手工调优。
-
案例2:SwiGLU。另一个客户瓶颈 kernel,GEAK 优化优于手工工程化方案。
-
案例3:GEMM 启发式。面向 C++/HIP 的启发式流程,关注 GEMM 的超参数选择。
以上示例的系统配置见文末“附注”。
想快速上手,请参考GitHub 仓库:AMD-AGI/GEAK-agent:GEAK-HIP[3]。
ROCm 示例
我们选取ROCm 示例仓库[4]中的简单应用,示范基础优化技巧。该仓库帮助新用户快速上手 ROCm,同时也包含进阶示例。我们在这些示例中使用智能体,展示 GEAK 如何带来速度与效率的提升。
具体做法:直接在单个HIP 源文件中复用原有的 C++ 单测代码,并加入性能评测逻辑,同时验证正确性与性能。
示例列表(来自ROCm examples 仓库):
- bitonic_sort, convolution, floyd_warshall, histogram, monte_carlo_pi, prefix_sum
评测结果如下:
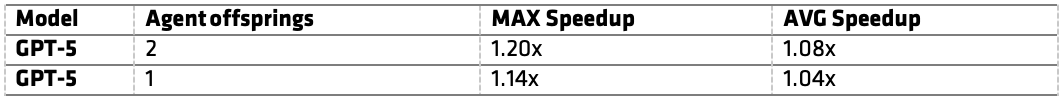
表1:在 6 个 ROCm-examples 上评估 GEAK OptimAgent。MAX Speedup 为原始 HIP 与优化后 HIP 的时延比的最大值;AVG Speedup 为各 kernel 加速比的平均值。
MMCV 示例
我们从MMCV 仓库[5]提取了需要优化的 kernel。MMCV 是 OpenMMLab 的基础视觉库,为图像/视频处理、数据变换、CNN 结构、可视化及高效 CPU/GPU 运算提供核心能力,并与 PyTorch 深度集成,支持 MMDetection、MMSegmentation 等下游工具。其许多单测基于 PyTorch 绑定,并与 PyTorch 运算结果做对齐。
我们改造了这些单测,通过PyTorch extensions 编译并装载 HIP kernel。准确性与速度由 Python/PyTorch 侧验证。原始单测多为较小输入,不能充分体现 kernel 的典型时延,我们适度增大了输入尺寸,使之更贴近实际使用;准确性方面则将原始 HIP 与 GEAK 改写版的结果逐项对齐。
示例列表(来自MMCV):
- assign_score_withk, ball query, furthest_point_sample, gather_points, knn, points_in_box, roi aware_pool3d, roipoint_pool3d, three_interpolate, three_nn
评测结果如下:
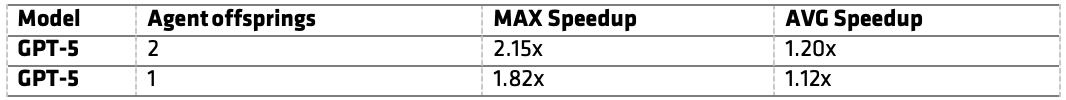
表2:在 10 个 MMCV kernel 上评估 GEAK OptimAgent。
案例 1:Voxelization
我们将voxelization 作为一个代表性用户案例,用来对比智能体生成的代码与原实现。Voxelization 将 3D 点云中具有相同整数坐标 (x, y, z) 的点分到同一 voxel,以降低点密度,便于神经网络高效处理。这一操作常见于基于 LiDAR 的自动驾驶场景(PointPillars、MMCV 等),使用量化传感器数据(LiDAR、深度相机)并启用稀疏卷积,满足实时检测、分割与场景理解。
GEAK 在保证每个点在其 voxel 组内“局部索引”验证正确的前提下,对原 MMCV 实现做了以下方向的优化:
- 缓存(Caching):将前驱点的坐标(x,y,z) 与有效标记按 tile 缓存在共享内存(LDS)中,避免每个线程重复从全局内存取数。
o 关键代码如下(节选,保持原样):
// Use shared memory as a tile cache for predecessor coordinates (x,y,z) when NDim==3extern __shared__ int4 smem_xyzv[]; // x,y,z,valid_flag...// Coalesced loads into LDS; pack validity as .wif (load_idx < num_points) { const int base = load_idx * 3; const int x = coor[base + 0]; const int valid = (x != -1); const int y = valid ? coor[base + 1] : 0; const int z = valid ? coor[base + 2] : 0; smem_xyzv[threadIdx.x] = make_int4(x, y, z, valid);} else { // out-of-bounds: mark as invalid smem_xyzv[threadIdx.x] = make_int4(-1, 0, 0, 0);}__syncthreads();
- 并行(Parallelism):Block 内线程协同并行装载 tile 数据(合并访问);每个线程独立扫描其前驱片段,通过 barrier 保持同步。
o 关键代码如下(节选):
const int load_idx = tile_start + threadIdx.x;...smem_xyzv[threadIdx.x] = make_int4(...);__syncthreads();
- 分块(Tiling):按 block 大小切分点列表,每次在共享内存中处理一个 tile,降低全局内存访问。
o 关键代码如下(节选):
for (; l + 8 <= ub && !done; l += 8) { int4 v0 = smem_xyzv[l + 0]; int4 v1 = smem_xyzv[l + 1]; ... if (v0.w && v0.x == coor_x && v0.y == coor_y && v0.z == coor_z) { num++; ... } if (!done && v1.w && v1.x == coor_x && v1.y == coor_y && v1.z == coor_z) { num++; ... } ...}
- 指令级并行(Instruction-Level Parallelism,ILP):对循环做展开,每个周期做多次比较,重叠操作提升吞吐。
- 占用率(Occupancy):使用 launch_bounds 等提示约束每块寄存器,增加每个 SM 的并发块数,提高GPU利用率。
- 早停:当达到max_points 或无更多前驱时提前退出,减少无效扫描。
评测结果如下:

表3:voxelization kernel 的评测结果。智能体优化相较于工程师手工优化,取得了更高的加速。
整体上,GEAK 智能体生成的优化版本在该案例中达到 2.07x 的加速,较手工优化进一步提升。
案例 2:SwiGLU
SwiGLU(SiLU-Gated Linear Unit)由 Shazeer(2020)提出[7],现已成为现代 transformer 中的关键组件。其做法是将前馈输入分为两支:一支经过 SiLU 激活,另一支保持线性,再做逐元素乘法。该设计相较 ReLU/GELU 改善了梯度流与表达能力,已被 LLaMA、Qwen、DeepSeek 等广泛采用,有助于训练稳定性与下游指标。
在实现上,SwiGLU 涉及大规模矩阵乘(线性投影)以及轻量的激活/门控步骤。我们聚焦后者:在 GEMM 之后执行 SiLU(x) * y。若内存访问与并行没有优化好,仍会成为瓶颈。
我们在AMD GPU 平台上开展优化。GEAK 从 vLLM 的原实现[6]中总结并改进了以下方向:
- 向量化:以bf16x2 与 uint4(128-bit)成组进行更宽、更一致的 load/store。
o 关键代码如下(节选):
const __hip_bfloat162* __restrict__ row_x2 = reinterpret_cast<const __hip_bfloat162*>(row_x);const __hip_bfloat162* __restrict__ row_y2 = reinterpret_cast<const __hip_bfloat162*>(row_y); __hip_bfloat162* __restrict__ row_o2 = reinterpret_cast< __hip_bfloat162*>(row_o);
const uint4* __restrict__ row_x4 = reinterpret_cast<const uint4*>(row_x2);const uint4* __restrict__ row_y4 = reinterpret_cast<const uint4*>(row_y2); uint4* __restrict__ row_o4 = reinterpret_cast< uint4*>(row_o2);
for (int64_t base_p = (int64_t)t * 4; base_p < bulk_pairs; base_p += tile_stride_4p) { ...
__hip_bfloat162 x2_0 = *reinterpret_cast<const __hip_bfloat162*>(&lx.x); __hip_bfloat162 y2_0 = *reinterpret_cast<const __hip_bfloat162*>(&ly.x); float2 fx0 = __bfloat1622float2(x2_0); float2 fy0 = __bfloat1622float2(y2_0); fx0.x = silu_f(fx0.x) * fy0.x; fx0.y = silu_f(fx0.y) * fy0.y; __hip_bfloat162 o2_0 = __float22bfloat162_rn(fx0);
// (similar pattern for each part for o2)}
- 对齐处理:检查16B 对齐以走 128-bit 向量路径;不满足则退化到配对的展开循环。
o 关键代码如下(节选):
const bool aligned16 = ((reinterpret_cast<uintptr_t>(row_x2) % 16u) == 0) && ((reinterpret_cast<uintptr_t>(row_y2) % 16u) == 0) && ((reinterpret_cast<uintptr_t>(row_o2) % 16u) == 0);
if (aligned16) { // Use 128-bit vectorized path ...} else { // Fallback scalar bf16x2 loop for (; p < num_pairs; p += stride) { __hip_bfloat162 x2 = row_x2[p]; __hip_bfloat162 y2 = row_y2[p]; float2 fx = __bfloat1622float2(x2); float2 fy = __bfloat1622float2(y2); fx.x = silu_f(fx.x) * fy.x; fx.y = silu_f(fx.y) * fy.y; row_o2[p] = __float22bfloat162_rn(fx); }}
- 快速数学:使用快速exp、除法与 FMA 等 intrinsic,充分利用 AMD 原生指令。
o 关键代码如下(节选):
__device__ __forceinline__ float silu_f(float x) { const float e = __expf(-x); return __fdividef(x, (1.0f + e)); }
- 指令交错:在多元素上交替执行SiLU 与乘法,提高 ILP、隐藏时延。
- 尾部优化:对奇数维度(H)用单线程补尾,避免分叉。
- 占用提示:控制寄存器占用,提升并发块数。
评测结果如下:

表4:SwiGLU kernel 的评测结果。该案例中,智能体优化版本较基线获得明显提升,并超过手工优化。
案例 3:GEMM 启发式
GEMM 是高性能计算与 AI 的核心。高性能库(如 rocBLAS、hipBLASLt)常依赖离线/在线调优选择最优 kernel。但穷举超参数空间代价高、耗时长,当无法充分调优时,启发式规则是务实替代方案:根据问题规模(MNK)与运行环境匹配 kernel 实例。然而,启发式若设计不佳,性能可能欠佳;而要写好规则并不容易,受硬件与应用差异影响很大。
我们使用GEAK HIP OptimAgent 强化启发式选择,将硬件特征与运行时观测纳入策略,期望在无法做全面调优的情况下依然获得更好的性能与体验。作为示例,我们在AMD GPU上面向 FP8 GEMM,基于 Composable Kernel(CK)库[8]的内核实例开展规则生成。在 CK 中,每个 kernel 由一组参数(如 block/tile 尺寸等)唯一指定,决定 GEMM 的计算结构与效率。智能体会理解这些参数集合,并在给定 CK 实例集合之上生成一条启发式选择规则。
主要参数如下:
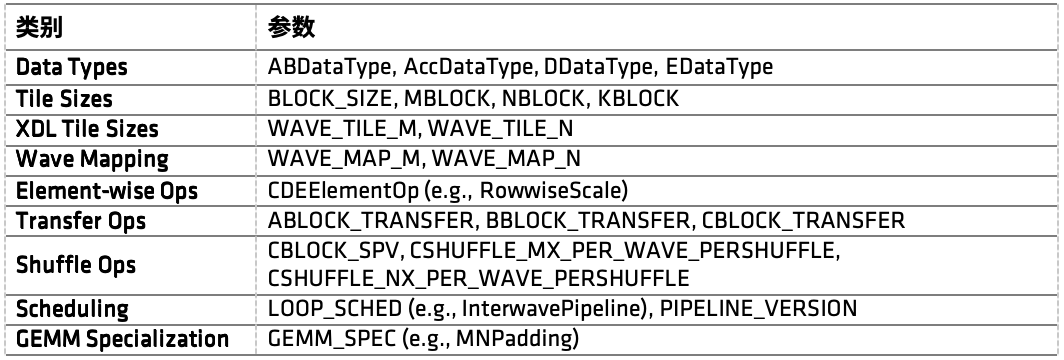
表5:CK 中 GEMM kernel 的主要参数分组。
为让OptimAgent 生成启发式规则,我们准备了一个单测,将“可用内核实例集合”暴露给智能体,并随机选取若干 GEMM 尺寸(覆盖从小到大),用其运行时延作为反馈信号,驱动智能体对规则迭代反思。
智能体生成的启发式规则概要(节选):
// Optimized heuristic-based selector: for all (M,N,K) of small batch/skinny, large batch, or fallback if ((M <= 128 && N >= 4096) || (M == 1) || (N == 1)) { // Small batch + wide or batch/vector return a8w8_blockscale_1x128x128_256x16x64x256_16x16_16x16_16x16x1_16x16x1_1x16x1x16_4_1x1_intrawave_v1<DDataType, EDataType>; } else if ((M > 128 && M <= 512 && N >= 4096)) { // Slightly larger batch still wide return a8w8_blockscale_1x128x128_256x32x256x128_16x16_32x32_8x32x1_8x32x1_1x32x1x8_8_1x1_intrawave_v1<DDataType, EDataType>; } else if ((M >= 512 && N >= 512 && K >= 1024)) { // Large and square return a8w8_blockscale_1x128x128_256x128x128x128_16x16_32x32_8x32x1_8x32x1_1x32x1x8_8_1x1_intrawave_v3<DDataType, EDataType>; } else if ((M < 256 && N < 256 && K < 256)) { // Very tiny tiles return a8w8_blockscale_1x128x128_256x64x64x256_16x16_32x32_16x16x1_16x16x1_1x32x1x8_8_1x1_intrawave_v1<DDataType, EDataType>; } else if (N <= 128 && M >= 512) { // Tall and skinny return a8w8_blockscale_1x128x128_256x64x128x128_16x16_32x32_8x32x1_8x32x1_1x32x1x8_8_1x1_intrawave_v3<DDataType, EDataType>; } else { // General fallback return a8w8_blockscale_1x128x128_256x128x64x128_16x16_32x32_8x32x1_8x32x1_1x32x1x8_8_1x1_intrawave_v3<DDataType, EDataType>; }
我们在Qwen3-32B 的 TP=2 设置下,基于 ROCm 的 AITER 框架[9],对这些规则进行了测试,并将“智能体生成的启发式”与 AITER 的“默认启发式”以及“离线调优启发式”做对比。下图给出 40 组规模上的速度比(默认启发式时延 vs. 测试启发式时延):
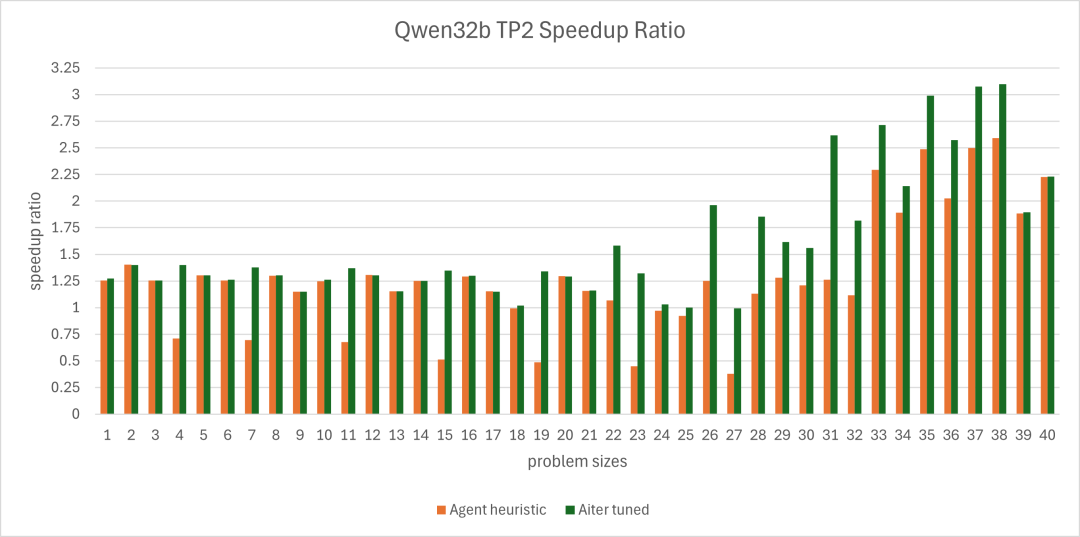
图2:Qwen32b 在张量并行=2 设置下,40 个问题规模的 GEMM 加速比。
从图中可以看到:
-
智能体启发式相对AITER 原始启发式(全量 GEMM)的总体速度比:1.28x
-
智能体启发式相对AITER 离线调优启发式(全量 GEMM)的总体速度比:0.8x
尽管个别规模不及AITER 原始启发式,但整体上,针对 Qwen3-32B,智能体已能生成接近“充分调优”效果的启发式,验证了方法的可行性。
总结
本文介绍了“面向 HIP 代码优化”的 GEAK,这是对原有“面向 Triton 生成”的 GEAK 的扩展,可用于为 AMD GPU优化现有 HIP 代码。GEAK 借助前沿 LLM,通过智能体的迭代优化实现由“生成器-评测器-反思器”构成的闭环。我们在 ROCm HIP 示例、MMCV 示例及三个真实案例(Voxelization、SwiGLU、GEMM 启发式)中展示了其效果,均取得了可观的性能提升。
这项工作体现了利用GEAK 智能体框架开展 AI 负载自动化优化的价值。欢迎开发者与研究者体验智能体与评测集,并与社区一起共建高性能 kernel,进一步提升 AI 训练与推理效率。若你关注 Triton 方向的 kernel 优化,请参考配套博文“GEAK-Triton v2”[2]。
附加资源
-
Kernel Agent 代码:AMD-AGI/GEAK-agent:GEAK-HIP[3]
-
往期博文:GEAK: Introducing Triton Kernel AI Agent & Evaluation Benchmarks — ROCm Blogs[1]
偏见、风险与限制
该智能体代码仅供研究用途,不适用于需要高事实性、安全关键、医疗健康等场景;不用于生成虚假信息或助长有害对话。
该智能体以“原样”提供,不保证安全。用户应根据自身场景进行充分评估,并部署必要的安全过滤。
在特定提示下,智能体可能生成不准确、有害、暴力、偏见或令人反感的内容;即便非此意图的提示也可能触发此类输出。请务必保持警惕并负责任地使用。
尚未验证多语言能力,因此跨语言提示可能被误解并导致错误输出。
致谢
感谢以下同事在本工作期间提供的讨论与反馈:Fan Wang、Chang Cui、Ji Liu、Yixiong Huo、Arthur Huang、Fuwei Yang、Mehdi Rezagholizadeh、Stephen Youn、Guihong Li、Vikram Appia、Li Li、Carlus Huang、Peng Sun、Sharon Zhou、Vincent Ouyang、Sina Rafati、Arseny Moskvichev。
附注
系统配置 #1
AMD GPU 平台:
-
ORACLE SERVER X10-2c
-
CPU:2× Intel Xeon Platinum 8480+,每路 56 核(共 112 物理核,224 线程)
-
NUMA:共 2 个节点,关闭 auto-balancing
-
内存:2048 GiB(32 条,4800 MT/s,64 GiB/条)
-
磁盘:1× 256 GB BlockVolume(系统盘)+ 8× 3.5 TB Intel SSDPF2KX038T1S(NVMe)
-
GPU:8× AMD GPU,192 GB HBM3,750W
-
OS:Ubuntu 22.04.4 LTS
-
BIOS:79007700,Vendor:American Megatrends International, LLC.
-
驱动:amdgpu/6.10.5-2084815.22.04,ROCm 6.4.3
-
固件:BKC 24.12.10
系统配置 #2
AMD GPU平台:
-
System Model:AS2211TG5
-
CPU:2× Intel® Xeon® Platinum 8480C,56 核/路(共 112 物理核,224 线程
-
NUMA:共 2 个节点,关闭 auto-balancing
-
内存:2.0 TiB(32× 64 GB DIMMs,Samsung,标称 5600 MT/s,配置 4400 MT/s)
-
磁盘:2× 447.1 GB SAMSUNG MZNL3480(系统盘)+ 4× 3.5 TB SAMSUNG MZQL23T8HCLS-00BAL(NVMe)
-
GPU:8× AMD GPU,206 GB HBM3/GPU
-
OS:Red Hat Enterprise Linux 8.6 (Ootpa)
-
BIOS:3.0.ES.AL.P.070.30,Vendor:American Megatrends International, LLC
-
驱动:amdgpu/6.12.12,ROCm 6.4.3
-
固件:BKC 25.01.00
免责声明
第三方内容由该第三方直接授权给你,不由AMD 授权。所有链接的第三方内容均按“现状”提供,不作任何明示或暗示担保。使用该等第三方内容的风险由你自行承担,AMD 在任何情况下均不对因你使用第三方内容而产生的任何损失承担责任。请在使用前进行充分评估。
参考链接
1) GEAK: Introducing Triton Kernel AI Agent & Evaluation Benchmarks: https://www.amd.com/en/blogs.html
2) GEAK-Triton v2: Kernel Optimization for AMD GPUs:请参考本期第三篇文章:《GEAK-Triton v2 系列 AI 代理:面向 AMD GPUs 的 Triton 内核优化》
3) AMD-AGI/GEAK-agent:GEAK-HIP:https://github.com/AMD-AGI/GEAK-agent/tree/GEAK-HIP
4) ROCm Examples(Applications):https://github.com/ROCm/rocm-examples/tree/develop/Applications/
5) MMCV(OpenMMLab):https://github.com/open-mmlab/mmcv/tree/main
6) vLLM:https://github.com/vllm-project/vllm/tree/main
7) SwiGLU 论文(2002.05202):https://arxiv.org/pdf/2002.05202
8) Composable Kernel:https://github.com/ROCm/composable_kernel
9) AITER(AI Tensor Engine for ROCm):https://github.com/ROCm/aiter
获取更多AMD开发者资源及技术支持,欢迎添加小助手微信:
AMD_Developer(备注:开发者)

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 8
8 0
0- 0


 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)