
CrewAI vs AutoGen vs LangGraph vs MetaGPT vs OpenAI Agents SDK:智能体框架大比拼
CrewAI vs AutoGen vs LangGraph vs MetaGPT vs OpenAI Agents SDK —— 智能体框架到底该怎么选?
CrewAI vs AutoGen vs LangGraph vs MetaGPT vs OpenAI Agents SDK —— 智能体框架到底该怎么选?
01
五个框架,选错比不选更痛
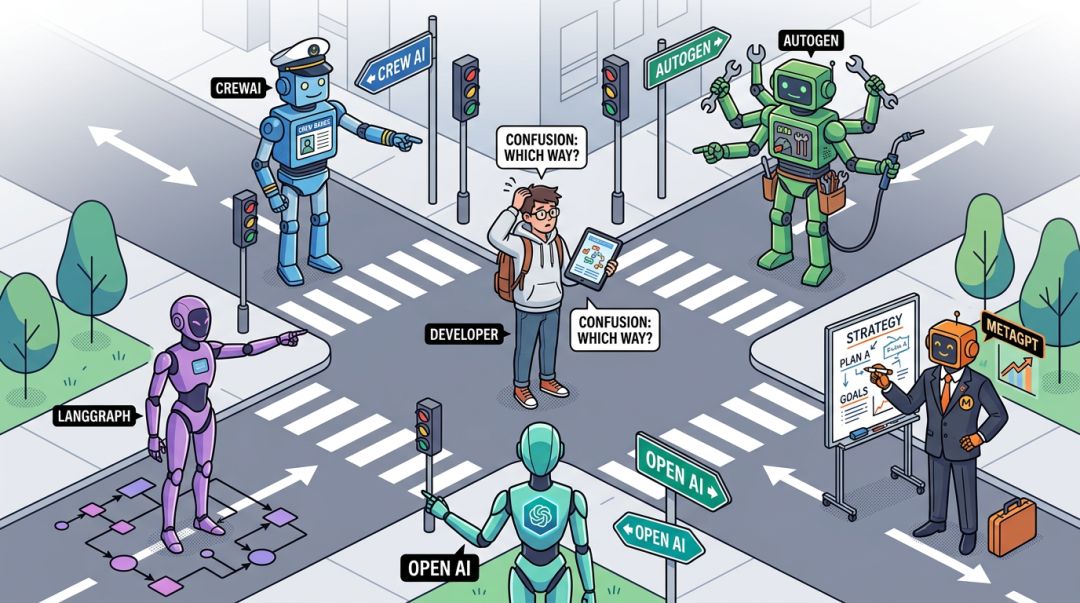
开发智能体第一步是:找个框架。
一搜,至少五个名字反复出现: CrewAI、AutoGen、LangGraph、MetaGPT、OpenAI Agents SDK 。智能体框架生态在过去一年爆发式增长。文档都看起来很美好,Demo 都能跑通,README 都写着"最好用的多智能体框架"。
但实际用了之后你会发现: 选错框架比不选更痛。
CrewAI 上手 10 分钟跑通 Demo,到了要加条件分支的时候发现没有原生支持,只能自己绕;AutoGen 的对话模式很灵活,结果 Agent 聊着聊着跑偏了,你想拉回来却不知道该抓哪根线;LangGraph 功能最强,但你得先花两天理解"状态图"是怎么回事;MetaGPT 开箱即用的"软件团队"很酷,但你想改个角色发现得啃源码;OpenAI Agents SDK 设计很优雅,但你发现它跟其他四个的定位不太一样……
这篇文章就是为了帮你避开这些坑。我会用 同一个任务跑这些框架 ,不只是看代码怎么写,更重要的是告诉你: 每个框架的甜蜜点在哪、天花板在哪、什么时候该用它、什么时候别碰它。
02
先搞清定位:五种完全不同的思路
选框架之前,得先知道它们底层的协作范式不一样——这不是"哪个更好"的问题,而是"它们压根在解决不同的问题"。
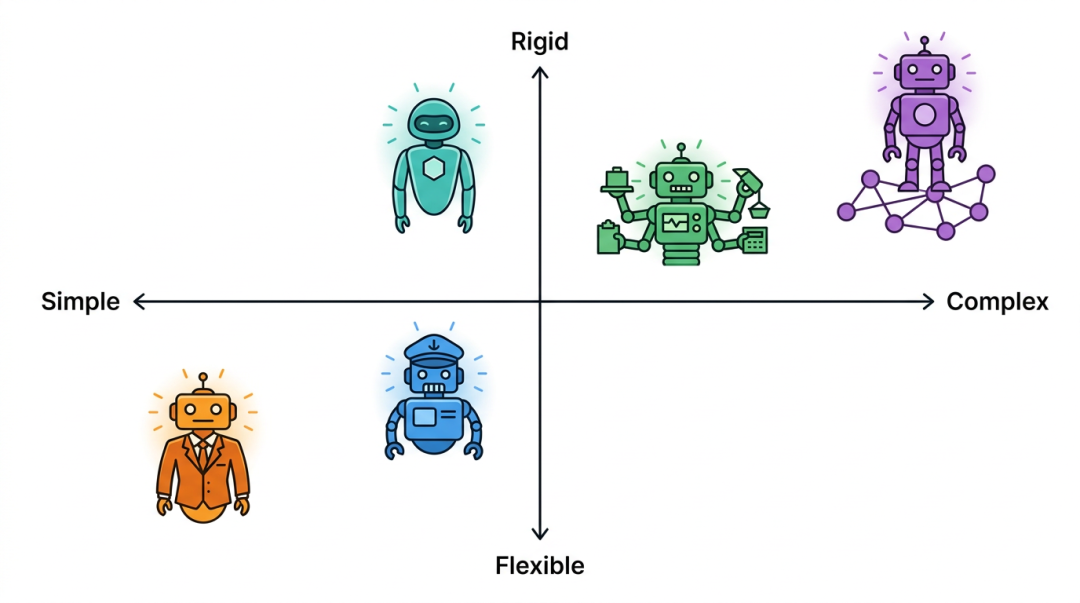
CrewAI:任务分配型 —— 像一个项目经理
核心概念就三个: Agent(角色)+ Task(任务)+ Crew(团队) 。你招几个人,给他们分配活,让他们按顺序或层级干完。
思维模型 :想象你是项目经理,把一个大需求拆成三个子任务,分别指派给研究员、分析师、写手,每个人干完把成果传给下一个。
适合的场景 :角色固定、流程清晰、步骤不需要来回跳转的任务。比如"调研→分析→写报告"这种线性流水线。
不适合的场景 :需要根据中间结果动态调整流程的任务。比如"分析结果太短就让研究员补充调研"——这种条件分支 CrewAI 没有原生支持。
AutoGen(微软出品):对话协作型 —— 像一个群聊
Agent 之间通过 聊天 协作。你一句我一句,框架用 LLM 决定"下一个谁说话",直到某个终止条件被触发。
思维模型 :想象一个微信群,里面有研究员、分析师、写手,你把需求丢进去,他们自己聊,自己接话,聊完了结论就出来了。
适合的场景 :需要多轮讨论、互相补充、辩论推理的任务。比如"让一个 Agent 提方案,另一个挑毛病,第三个综合改进"——这种你来我往在 AutoGen 里最自然。
不适合的场景 :需要精确控制执行顺序的任务。因为"谁下一个说话"是 LLM 决定的,你没法100%控制流程走向。
LangGraph(LangChain 出品):图工作流型 —— 像一张流程图
把智能体流程建模成 状态机 :节点是函数,边是条件跳转。执行引擎按图走,遇到分支就判断条件选路。
思维模型 :想象你画了一张 Visio 流程图,每个方框是一步操作,箭头上写着条件。代码就是在"编程画这张图"。
适合的场景 :需要条件分支、循环重试、并行执行的复杂工作流。比如"分析结果不满意就重做"“根据报告质量决定是直接输出还是再润色一遍”——这些在 LangGraph 里改条件边就行。
不适合的场景 :简单的线性流程。用 LangGraph 写"A→B→C"就像用大炮打蚊子,代码量比 CrewAI 多一倍,但没多出任何价值。
MetaGPT:角色模拟型 —— 像一个外包软件团队
内置产品经理、架构师、工程师等角色,你给一句话需求,它自动分工——产品经理写 PRD、架构师画设计图、工程师写代码。
思维模型 :想象你把需求扔给一个外包团队,他们内部自己流转,最后交付代码。
适合的场景 :代码生成、软件开发类任务。给一句自然语言需求,自动产出可运行的项目。
不适合的场景 :非代码类任务。用 MetaGPT 做调研写报告就像让装修队帮你写论文,能干但别扭。而且它比较"重",想改内置角色或流程得啃源码。
OpenAI Agents SDK(OpenAI 出品):轻量编排型 —— 像一条接力赛跑道
从 OpenAI 的 Swarm(教学项目)进化而来,是 OpenAI 官方的 生产级 智能体框架。核心概念极简:Agent + Tools + Handoffs。一个 Agent 干不了的事,通过 Handoff 交给另一个 Agent,像接力棒一样传递。
思维模型 :想象一条接力赛跑道,每个运动员跑自己擅长的那一段,到了交接区把棒传给下一个人。
适合的场景 :需要 多个专精 Agent 串联工作 的任务,尤其是"分诊+路由"模式。比如一个入口 Agent 判断用户意图,然后把请求转给对应的专家 Agent 处理。内置 Guardrails(安全护栏)、Tracing(调用追踪)、MCP 协议支持。
不适合的场景 :需要复杂条件分支、循环重试的工作流。Handoff 本质是"单向交接",想做"回退到上一步"这种操作不太方便。另外它更适合 单 Agent 增强 或 简单多 Agent 串联 ,复杂编排还是得用 LangGraph。
重要补充 :虽然叫 OpenAI Agents SDK,但它 不锁定 OpenAI 模型 ——通过可以接入 100+ 其他模型。名字有误导性,实际是通用框架。
一句话记忆法 :CrewAI 是"任务板"(Trello),AutoGen 是"群聊"(微信群),LangGraph 是"流程图"(Visio),MetaGPT 是"外包团队"(交付代码),OpenAI Agents SDK 是"接力赛"(轻量交接)。
03
统一任务:同一道题,五种解法
为了公平对比,用同一个任务跑所有框架:
任务 :调研 Python Web 框架(Django / Flask / FastAPI),输出一篇对比分析报告。
为什么选这个任务?三个原因:
- 需要多角色协作 :研究员搜集信息、分析师做对比、写手撰写报告——三个步骤,考验框架的分工和信息传递能力
- 不涉及代码执行 :省掉工具调用的复杂度,让我们专注在"框架本身的差异"上
- 结果容易评估 :最终输出是一篇报告,好不好一眼能看出来
下面每个框架我会给出: 完整可运行代码 → 模拟运行效果 → 核心优势 → 真实踩坑 。
注意 :下面代码里的 API 可能随版本更新有变化,以各框架官方文档为准。
04
CrewAI 实现:三板斧,10 分钟跑通
CrewAI 的思路最直观:定义 Agent → 定义 Task → 组装 Crew → kickoff。
pip install crewai crewai-tools
import osos.environ["OPENAI_API_KEY"] = "your-api-key"from crewai import Agent, Task, Crew, Process# ==================== 定义三个 Agent ====================researcher = Agent( role="技术研究员", goal="搜集 Django、Flask、FastAPI 的官方文档和社区评价", backstory="你是资深 Python 开发者,擅长技术调研", allow_delegation=False, # 不允许把任务委派给别人 verbose=True)analyst = Agent( role="技术分析师", goal="对比三个框架的优缺点、适用场景和性能表现", backstory="你是架构师,擅长技术选型分析", allow_delegation=False, verbose=True)writer = Agent( role="技术写手", goal="将分析结果整理成结构清晰的对比报告", backstory="你是技术文档作者,擅长把复杂信息讲清楚", allow_delegation=False, verbose=True)# ==================== 定义三个 Task ====================research_task = Task( description="调研 Django、Flask、FastAPI 三个 Python Web 框架,包括:特性、生态、社区活跃度", expected_output="一份调研笔记,包含三个框架的核心信息", agent=researcher)analysis_task = Task( description="基于调研笔记,对比三个框架的优缺点、适用场景和性能表现", expected_output="一份对比分析表格和结论", agent=analyst, context=[research_task] # 关键:声明依赖,analyst 能拿到 researcher 的输出)write_task = Task( description="根据对比分析,撰写一篇完整的 Python Web 框架对比报告,适合技术选型参考", expected_output="一篇 1500 字左右的对比分析报告,含结论和推荐", agent=writer, context=[research_task, analysis_task] # 写手能拿到前两步的所有输出)# ==================== 组装 Crew 并执行 ====================crew = Crew( agents=[researcher, analyst, writer], tasks=[research_task, analysis_task, write_task], process=Process.sequential # 按顺序执行:研究 → 分析 → 撰写)result = crew.kickoff()print(result)
模拟运行效果:
[Researcher] 正在调研 Django、Flask、FastAPI...[Researcher] 调研完成,输出:Django 全栈、ORM 内置;Flask 轻量、灵活;FastAPI 异步、高性能...[Analyst] 基于调研笔记进行对比分析...[Analyst] 分析完成:Django 适合大型项目,Flask 适合快速原型,FastAPI 适合 API 服务...[Writer] 撰写对比报告...[Writer] 报告完成。--- 最终输出 ---# Python Web 框架对比分析报告## 一、综述Django、Flask、FastAPI 是 Python 生态中最主流的三个 Web 框架...## 二、详细对比| 维度 | Django | Flask | FastAPI ||------|--------|-------|---------|| 定位 | 全栈框架 | 微框架 | 异步 API 框架 |...
[UserProxy] 请帮我调研 Python Web 框架(Django、Flask、FastAPI),输出一篇对比分析报告。[Researcher] 正在调研...- Django: 全栈框架,内置 ORM、Admin、认证...- Flask: 微框架,轻量灵活,扩展丰富...- FastAPI: 基于 Starlette,异步高性能...DONE[Analyst] 基于调研,对比分析如下:- 选型建议:大型项目用 Django,快速原型用 Flask,API 服务用 FastAPIDONE[Writer] 撰写报告...[Writer] 报告完成。以下是完整对比报告:...TERMINATE
[research_node] 执行调研...[analysis_node] 执行分析...[write_node] 执行撰写...--- 最终输出 ---# Python Web 框架对比分析报告...
[技术研究员] 调研 Django、Flask、FastAPI... → Handoff to 技术分析师[技术分析师] 对比三个框架的优缺点... → Handoff to 技术写手[技术写手] 撰写对比报告...--- 最终输出 ---# Python Web 框架对比分析报告...
核心优势
-
API 最简洁 :++ 三板斧,概念少,上手快
-
依赖关系清晰 :参数让下游 Task 能拿到上游输出,数据流一目了然
-
10 分钟跑通 Demo :从安装到看到结果,五个框架里 CrewAI 最快
真实踩坑
坑 1:流程是死的。
就是 A→B→C,就是"经理分配任务"。但你想要"如果分析结果不满意就让研究员补充调研"这种条件分支?对不起,没有原生支持。得自己在外面套循环 + 人工判断,写出来既丑又难维护。
坑 2:调试体验一般。 开了能看到执行日志,但日志是纯文本流,Agent 之间传递的中间结果不容易单独拿出来看。一旦最终报告有问题,你很难快速定位是哪个 Agent 出了岔子。
坑 3:backstory 不是装饰。 刚上手的时候觉得是噱头,随便写两句。后来发现它直接影响 Agent 的输出质量——同样的任务,写得详细具体 vs 敷衍了事,出来的结果差距明显。这个参数本质上是 system prompt 的一部分,值得认真写。
05
AutoGen 实现:让 Agent 自己聊出结论
AutoGen 的核心理念不一样:不预设固定流程,而是让 Agent 之间通过 对话 协作。框架用 LLM 选择"下一个谁说话",直到触发终止条件。
pip install "autogen-agentchat" "autogen-ext[openai]"
import osimport asyncioos.environ["OPENAI_API_KEY"] = "your-api-key"from autogen_agentchat.agents import AssistantAgentfrom autogen_agentchat.teams import SelectorGroupChatfrom autogen_agentchat.conditions import TextMentionTermination, MaxMessageTerminationfrom autogen_agentchat.ui import Consolefrom autogen_ext.models.openai import OpenAIChatCompletionClientmodel_client = OpenAIChatCompletionClient(model="gpt-4o-mini")# ==================== 定义三个 Agent ====================# 注意:AutoGen 的 Agent 定义更偏"人设 + 行为指令"# 通过 system_message 控制每个 Agent 的职责边界researcher = AssistantAgent( name="Researcher", description="负责搜集技术信息,输出调研笔记", model_client=model_client, system_message=( "你是技术研究员。搜集 Django、Flask、FastAPI 的信息," "用 bullet points 输出调研结果。完成后说 DONE。" ))analyst = AssistantAgent( name="Analyst", description="负责对比分析,输出结论", model_client=model_client, system_message=( "你是技术分析师。基于 Researcher 的调研结果," "对比三个框架的优缺点和适用场景。完成后说 DONE。" ))writer = AssistantAgent( name="Writer", description="负责撰写最终报告", model_client=model_client, system_message=( "你是技术写手。根据调研和分析结果," "撰写完整对比报告。完成后说 TERMINATE。" ))# ==================== 终止条件 ====================# 两条线兜底:写手说 TERMINATE 就停,或者最多聊 15 轮强制停termination = ( TextMentionTermination("TERMINATE") | MaxMessageTermination(max_messages=15))# ==================== 创建团队 ====================# SelectorGroupChat:LLM 自动选下一个发言人# 也可以用 RoundRobinGroupChat 按固定顺序轮流说team = SelectorGroupChat( [researcher, analyst, writer], model_client=model_client, termination_condition=termination,)# ==================== 执行(异步) ====================asyncdef main(): await Console( team.run_stream( task="请调研 Python Web 框架(Django、Flask、FastAPI),输出一篇对比分析报告。" ) )asyncio.run(main())
模拟运行效果:
核心优势
-
对话式协作最自然 :Agent 之间能来回讨论、互相补充、互相挑战
-
适合推理密集型任务 :比如让一个 Agent 出初稿,另一个挑毛病,第三个根据反馈再改——这种"你来我往"在 AutoGen 里写起来最顺
-
灵活的团队编排 :(LLM 选人)、(轮流说)、(根据 handoff 跳转)多种模式可选
真实踩坑
坑 1:流程不可控是最大的痛。
让 LLM 选"下一个谁说话",但 LLM 不一定选对。实测中经常出现:Researcher 还没说完 Analyst 就抢话了,或者三个 Agent 聊着聊着跑题了。你得靠兜底,但这等于承认"我没法精确控制流程"。
坑 2:终止条件是个玄学。 你靠让 Agent 自己说"TERMINATE"来停,但大模型有时候就是不按套路出牌——它会说"TERMINATED"、"terminate"或者干脆忘了说。所以你几乎 必须 加一个做兜底,否则可能一直聊下去。
坑 3:Token 消耗容易失控。 对话式协作意味着每个 Agent 发言时要看到之前所有人的对话历史。3 个 Agent 聊 10 轮,上下文长度飙得很快。如果任务简单(比如咱们这个调研任务),用 AutoGen 的 Token 开销可能是 CrewAI 的 2-3 倍,性价比不高。
06
LangGraph 实现:把流程画成图
LangGraph 把流程建模成 有向图 :节点是函数,边是跳转规则,状态在节点间流转。
pip install langgraph langchain-openai
import osos.environ["OPENAI_API_KEY"] = "your-api-key"from typing import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langchain_openai import ChatOpenAIfrom langchain_core.messages import HumanMessage# ==================== 定义状态 ====================# 这是 LangGraph 的核心概念:所有数据通过 State 在节点间传递# 每个节点读取 State、处理、写回 Stateclass ResearchState(TypedDict): research: str analysis: str report: strllm = ChatOpenAI(model="gpt-4o-mini", temperature=0)# ==================== 定义节点函数 ====================# 每个节点就是一个普通 Python 函数# 入参是当前 State,返回值是要更新的 State 字段def research_node(state: ResearchState) -> ResearchState: prompt = """调研 Django、Flask、FastAPI 三个 Python Web 框架, 输出调研笔记,包含特性、生态、社区活跃度。""" response = llm.invoke([HumanMessage(content=prompt)]) return {"research": response.content}def analysis_node(state: ResearchState) -> ResearchState: prompt = f"""基于以下调研笔记,对比三个框架的优缺点和适用场景: {state['research']} 输出对比分析表格和结论。""" response = llm.invoke([HumanMessage(content=prompt)]) return {"analysis": response.content}def write_node(state: ResearchState) -> ResearchState: prompt = f"""根据调研和分析结果,撰写一篇 Python Web 框架对比报告: 调研:{state['research']} 分析:{state['analysis']} 输出 1500 字左右的完整报告,含结论和推荐。""" response = llm.invoke([HumanMessage(content=prompt)]) return {"report": response.content}# ==================== 构建图 ====================# 这段代码在"画流程图":声明节点、连线、设定起终点workflow = StateGraph(ResearchState)workflow.add_node("research", research_node)workflow.add_node("analysis", analysis_node)workflow.add_node("write", write_node)workflow.add_edge(START, "research") # 起点 → 调研workflow.add_edge("research", "analysis") # 调研 → 分析workflow.add_edge("analysis", "write") # 分析 → 撰写workflow.add_edge("write", END) # 撰写 → 结束# 编译成可执行的 appapp = workflow.compile()result = app.invoke({"research": "", "analysis": "", "report": ""})print(result["report"])
上面是最简版——线性流程。但 LangGraph 真正的威力在于 条件分支 。比如你想加一个"报告质量不够就让分析师重做"的逻辑:
def quality_check(state: ResearchState) -> str: """根据报告长度决定下一步走哪条边""" if len(state["report"]) < 500: return "analysis" # 太短,回到分析节点重做 return END # 质量合格,结束# 把固定边改成条件边workflow.add_conditional_edges("write", quality_check)
这种"根据运行时状态决定走哪条路"的能力,是 CrewAI 和 AutoGen 不容易做到的。
模拟运行效果:
核心优势
-
流程可视化、有状态管理 :图结构天然可以画出来看,State 在节点间的流转一目了然
-
条件分支和循环是一等公民 :让你轻松实现"失败重试""质量不达标就重做"等逻辑
-
可中断、可恢复 :LangGraph 支持 checkpointing,长流程可以中途暂停,下次接着跑
-
LangChain 生态加持 :跟 LangSmith(可观测性)、LangServe(部署)无缝对接
真实踩坑
坑 1:学习曲线是五个里最陡的。 你得先理解 StateGraph、Node、Edge、Conditional Edge、State 更新机制……这套概念体系不复杂但需要转换思维。如果你没写过状态机或者没画过流程图,上手会明显慢。
坑 2:简单任务写起来啰嗦。 就这个"调研→分析→写报告"的线性流程,LangGraph 的代码量是 CrewAI 的 1.5 倍。如果你的任务不需要条件分支或循环,选 LangGraph 就是大材小用。
坑 3:调试要靠 LangSmith。 LangGraph 本身的错误信息不够友好,State 在节点间传递时如果出错(比如字段名写错了),报错信息让人一头雾水。接上 LangSmith 之后可以可视化看到每一步的输入输出,体验才好起来。但 LangSmith 是个独立的收费服务,等于额外增加了依赖。
07
MetaGPT 实现:一句话需求,自动出代码
MetaGPT 的定位跟前三个不太一样——它是"开箱即用的软件开发团队"。内置产品经理、架构师、工程师等角色,你给一句需求,它自动分工、写 PRD、画架构图、生成代码。
用它做咱们的调研任务有点"杀鸡用牛刀",但可以看看它的用法和边界。
pip install metagpt
import osos.environ["OPENAI_API_KEY"] = "your-api-key"from metagpt.software_company import generate_repo# 一句话需求,MetaGPT 自动分工执行generate_repo( idea="Create a Python script that researches Django, Flask, FastAPI and outputs a comparison report", investment=2.0, # 预算:控制生成深度,数值越大产出越详尽 n_round=3, # 迭代轮数:团队内部协作的最大轮次 code_review=True, # 是否启用代码审查角色 run_tests=False)
MetaGPT 内置的团队会自动走这个流程:
产品经理(写 PRD)→ 架构师(画架构图)→ 工程师(写代码)→ QA(审查)
你不需要自己定义角色和任务,框架全包了。
核心优势
-
开箱即用 :给需求就能出代码,不需要定义角色、任务、流程
-
内置 SOP 流程 :产品经理→架构师→工程师→QA 这套流水线是参考真实软件开发流程设计的
-
学术团队背景 :底层有比较扎实的多智能体协作研究支撑
真实踩坑
坑 1:太重了。 MetaGPT 的依赖链很长,安装经常报依赖冲突。而且它默认走完整的软件开发流程(写 PRD → 画架构图 → 写代码 → 审查),即使你只想做个简单调研,它也会走完全套,Token 消耗远高于其他框架。
坑 2:定制化极难。 想加一个自定义角色?得继承类,重写方法,理解、等内部概念。想改执行流程?得啃的源码。对比 CrewAI 的三行代码加个 Agent,MetaGPT 的定制成本高一个量级。
坑 3:非代码类任务体验一般。 MetaGPT 是为"给需求出代码"这个场景优化的。做调研、写报告、数据分析这类任务,它的内置角色(产品经理、架构师)反而是多余的。你用前面三个框架会轻量得多。
08
OpenAI Agents SDK 实现:轻量级接力赛
OpenAI Agents SDK 是 Swarm(OpenAI 之前的教学级框架)的 生产级进化版 。设计哲学是"极简原语":Agent + Tools + Handoffs,代码写起来很 Pythonic。
pip install openai-agents
import asynciofrom agents import Agent, Runner# ==================== 定义三个 Agent ====================# OpenAI Agents SDK 的定义非常简洁# 每个 Agent 就是 instructions + 可选的 tools/handoffswriter = Agent( name="技术写手", instructions=( "你是技术写手。根据调研和分析结果," "撰写一篇 1500 字的 Python Web 框架对比报告,含结论和推荐。" ),)analyst = Agent( name="技术分析师", instructions=( "你是技术分析师。基于调研笔记," "对比 Django、Flask、FastAPI 的优缺点和适用场景。" "分析完成后,交给技术写手撰写报告。" ), handoffs=[writer], # 分析完后交接给写手)researcher = Agent( name="技术研究员", instructions=( "你是技术研究员。搜集 Django、Flask、FastAPI 的特性、生态、社区活跃度。" "调研完成后,交给技术分析师做对比分析。" ), handoffs=[analyst], # 调研完后交接给分析师)# ==================== 执行 ====================# Runner.run 会自动处理 Agent 间的 Handoff 链# researcher → analyst → writer,整个流程自动流转asyncdef main(): result = await Runner.run( researcher, input="请调研 Python Web 框架(Django、Flask、FastAPI),输出一篇对比分析报告。" ) print(result.final_output)asyncio.run(main())
模拟运行效果:
核心优势
-
API 设计最优雅 :Agent 定义就是+,几乎没有多余概念。整个 SDK 的核心就三个原语,学习成本极低
-
内置 Tracing :不需要外接服务,SDK 自带调用追踪,能看到每个 Agent 的输入输出、Handoff 流转、Tool 调用过程
-
Guardrails 是一等公民 :内置输入/输出校验机制,可以在 Agent 执行前后自动做安全检查——这在生产环境非常重要,其他框架需要自己写
-
MCP 协议原生支持 :可以直接接入 MCP Server 作为工具源,不需要自己写 JSON Schema
真实踩坑
坑 1:Handoff 是单向的。 Agent A 把任务交给 Agent B 之后,B 没法再"退回"给 A。如果你的流程需要"分析师觉得调研不够,让研究员补充"这种回退逻辑,Handoff 做不到,得用 LangGraph。
坑 2:名字有误导性。 叫"OpenAI Agents SDK",很多人以为只能用 OpenAI 的模型。其实它通过支持任何兼容 OpenAI API 的模型(DeepSeek、通义千问等都行)。但第一印象确实会劝退不想绑定 OpenAI 的团队。
坑 3:复杂编排力不从心。 它的设计哲学就是"极简",所以条件分支、循环、并行这些高级编排能力统统没有。如果你的多 Agent 场景比较复杂(5 个以上 Agent、有循环依赖),OpenAI Agents SDK 会显得力不从心,还是得上 LangGraph。
09
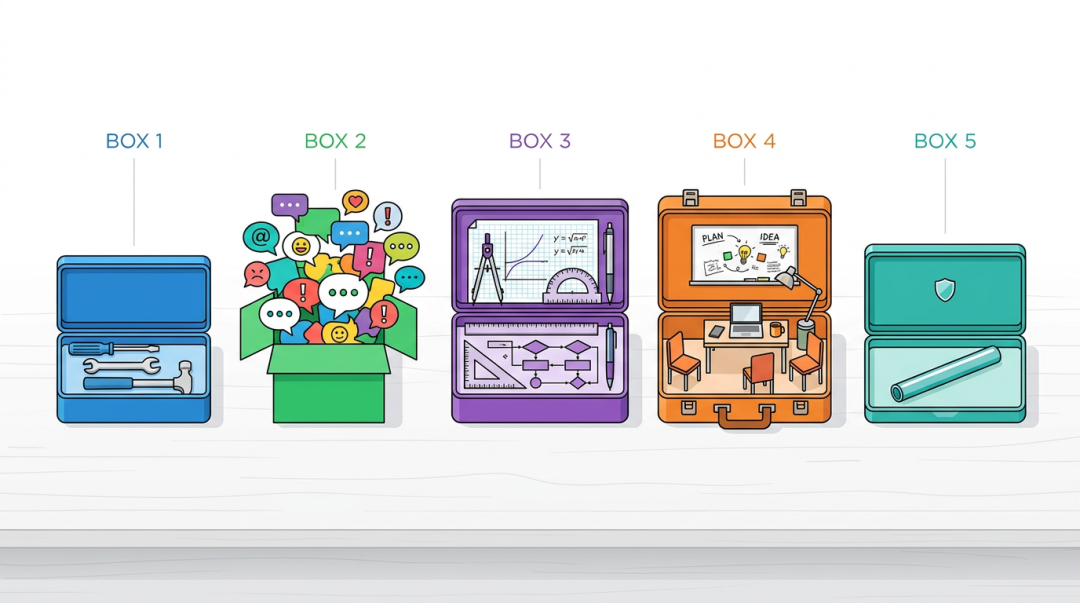
正面对比:一张表看清差异
| 维度 | CrewAI | AutoGen | LangGraph | MetaGPT | OpenAI Agents SDK |
|---|---|---|---|---|---|
| 上手难度 | 最低 | 中等 | 较高 | 中等 | 低 |
| 核心范式 | 任务分配 | 对话协作 | 图状态机 | 角色模拟 | Handoff 交接 |
| 流程灵活性 | 低(线性/层级) | 高(LLM 选路) | 最高(条件/循环) | 低(固定 SOP) | 中(单向链式) |
| 条件分支 | 不支持 | 隐式(LLM 决定) | 原生支持 | 不支持 | 不支持 |
| 调试体验 | 一般 | 较差 | 好(接 LangSmith) | 一般 | 好(内置 Tracing) |
| Token 消耗 | 低 | 高 | 中 | 高 | 低 |
| 安全护栏 | 无 | 无 | 需自建 | 无 | 内置 Guardrails |
| 最佳场景 | 通用多 Agent | 推理/讨论 | 复杂工作流 | 代码生成 | 分诊路由/轻量串联 |
| 生态与背景 | 社区增长快(44K+ Star) | 微软背书 | LangChain 生态(25K+ Star) | 学术背景 | OpenAI 官方 |
| 生产就绪度 | 较好 | 好 | 最好 | 一般 | 好 |
| 定制化难度 | 低 | 中 | 中 | 高 | 低 |
| 模型锁定 | 无 | 无 | 无 | 无 | 无(名字有误导) |
10
选型决策:别看"最强",看"最合适"
选型不是选"最厉害"的框架,而是选"成本最低的够用方案"。我的决策逻辑是这样的:

先问自己四个问题
- 问题 1:你的任务需要条件分支、循环或并行吗?
-
需要(失败重试、质量检查、动态路由)→ LangGraph ,其他框架做条件分支都很别扭
-
不需要 → 继续往下看
- 问题 2:你的任务需要 Agent 之间来回讨论吗?
-
需要(辩论、多轮推理、方案迭代)→ AutoGen ,对话式协作是它的舒适区
-
不需要 → 继续往下看
- 问题 3:你的任务是代码生成类的吗?
-
是(给需求出代码、自动化开发)→ MetaGPT ,开箱即用的软件团队
-
不是 → 继续往下看
- 问题 4:你的任务是"分诊→路由→处理"这种链式交接吗?
-
是(比如客服入口识别意图,再转给专家 Agent)→ OpenAI Agents SDK ,Handoff 天然适合这种模式,而且内置 Guardrails 和 Tracing
-
不是,或者不确定 → CrewAI ,最简单、最快、够用就好
几个常见场景的推荐
| 场景 | 推荐 | 原因 |
|---|---|---|
| 调研 + 分析 + 写报告 | CrewAI | 线性流程,三板斧搞定 |
| 技术方案评审(出方案→挑毛病→改进) | AutoGen | 需要多轮讨论和互相挑战 |
| 客服工单处理(分类→路由→处理→质检) | LangGraph | 需要条件分支和失败重试 |
| 给自然语言需求自动生成代码 | MetaGPT | 专门为这个场景设计的 |
| 数据 ETL 流水线编排 | LangGraph | 需要并行、条件、循环 |
| 多角色创意写作 | AutoGen | 角色之间互相激发创意 |
| 智能客服(意图识别→转专家) | OpenAI Agents SDK | Handoff 天然适合分诊路由 |
| 需要安全护栏的生产 Agent | OpenAI Agents SDK | 内置 Guardrails,其他框架需自建 |
一条万能原则
不确定选哪个?先用 CrewAI。 它上手最快、概念最少、生态在快速增长。等你跑通之后发现它满足不了需求了(比如需要条件分支了),再迁移到 LangGraph——因为你已经知道自己需要什么了,迁移方向也就清楚了。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 4
4 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)