
OpenClaw之Memory配置成本地模式,Ubuntu+CUDA+cuDNN+llama.cpp
本文介绍了在Windows 11基于WSL2运行OpenClaw时解决Memory设置为local不生效问题的方法。通过修改openclaw.json配置,安装CUDA和cuDNN,编译支持CUDA的llama.cpp,并安装node-llama-cpp,最终实现了本地(local)模式的Memory配置。文章详细记录了配置过程中的关键步骤,包括环境变量设置、模型路径指定、CUDA安装验证等,为遇
文章目录
承接上文:Windows11基于WSL2首次运行Openclaw,并对接飞书应用,我已经在电脑上安装了OpenClaw,接下来解决Memory问题。走了很多弯路,下面主要讲我总结的正确的安装过程。
总结来说:针对Memory不生效的问题,又不想用OpenAI或Gemini,或者只想单纯的节省token,可以按照如下的方式,设置为local模式:
- 修改openclaw.json配置
- 安装CUDA和cuDNN
- 编译llama.cpp,使用cuda
- 安装node-llama-cpp
- 验证
背景:Memory不生效的问题
执行openclaw doctor命令,有如下提示
◇ Memory search
Memory search is enabled but no embedding provider is configured.
Semantic recall will not work without an embedding provider. Fix (pick one):
- Set OPENAI_API_KEY or GEMINI_API_KEY in your environment
- Add credentials: openclaw auth add --provider openai
- For local embeddings: configure agents.defaults.memorySearch.provider and local model
path
- To disable: openclaw config set agents.defaults.memorySearch.enabled false
Verify: openclaw memory status --deep
这是因为“长期记忆检索”(memory_search)的 provider 只支持 openai | gemini | local,其中 openai/gemini 都需要单独的 API Key(或 remote.apiKey)。
这一块网上的资料很少,且部分缺少上下文。我就决定自己来配置使用本地(local)模式的Memory。
OpenClaw的Memory配置
参考官网上的Memory介绍,我做了如下修改。
1、修改openclaw.json:如下,在~/.openclaw/openclaw.json中,增加/修改如下内容
"agents": {
"defaults": {
"model": {
"primary": "zai/glm-5"
},
"models": {
"zai/glm-5": {
"alias": "GLM"
}
},
"workspace": "/home/band/.openclaw/workspace",
"compaction": {
"mode": "safeguard",
"reserveTokensFloor": 20000,
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 4000,
"systemPrompt": "Session nearing compaction. Store durable memories now.",
"prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store."
}
},
"maxConcurrent": 4,
"subagents": {
"maxConcurrent": 8
},
"memorySearch": {
"provider": "local",
"local": {
"modelPath": "hf:ggml-org/embeddinggemma-300M-GGUF/embeddinggemma-300M-Q8_0.gguf"
},
"fallback": "none",
"sources": [
"memory",
"sessions"
],
"experimental": {
"sessionMemory": true
},
"store": {
"vector": {
"enabled": true,
"extensionPath": "~/.npm-global/lib/node_modules/sqlite-vec/node_modules/sqlite-vec-linux-x64/vec0.so"
}
}
}
}
}
注意:
- modelPath采用官方建议的模型,注意是模型名称,不是本地的目录,我就是在这卡了很久。
- extensionPath后文有讲到,修改为本地的目录
Ubuntu24.04安装CUDA和cuDNN
按照官网的教程安装,地址:https://developer.nvidia.com/cuda-downloads
mkdir /opt/nvidia
cd /opt/nvidia
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-ubuntu2404.pinsudo mv cuda-ubuntu2404.pin /etc/apt/preferences.d/cuda-repository-pin-600wget https://developer.download.nvidia.com/compute/cuda/13.1.1/local_installers/cuda-repo-ubuntu2404-13-1-local_13.1.1-590.48.01-1_amd64.debsudo dpkg -i cuda-repo-ubuntu2404-13-1-local_13.1.1-590.48.01-1_amd64.debsudo cp /var/cuda-repo-ubuntu2404-13-1-local/cuda-*-keyring.gpg /usr/share/keyrings/sudo apt-get updatesudo apt-get -y install cuda-toolkit-13-1
安装后,还需要设置环境变量
echo 'export PATH=/usr/local/cuda-13.1/bin${PATH:+:${PATH}}' | sudo tee -a /etc/profile.d/cuda.sh
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-13.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}' | sudo tee -a /etc/profile.d/cuda.sh
source /etc/profile.d/cuda.sh
验证:nvcc --version,提示如下表明已经cuda toolkit安装成功。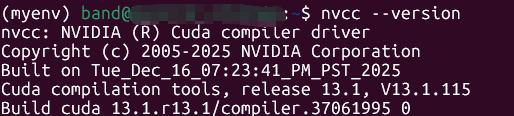
安装cuDNN
wget https://developer.download.nvidia.com/compute/cudnn/9.19.0/local_installers/cudnn-local-repo-ubuntu2404-9.19.0_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2404-9.19.0_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2404-9.19.0/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn
使用如下命令查看安装的目录
# 注意大小写
dpkg -L libcudnn9-cuda-13
dpkg -l |grep cudnn
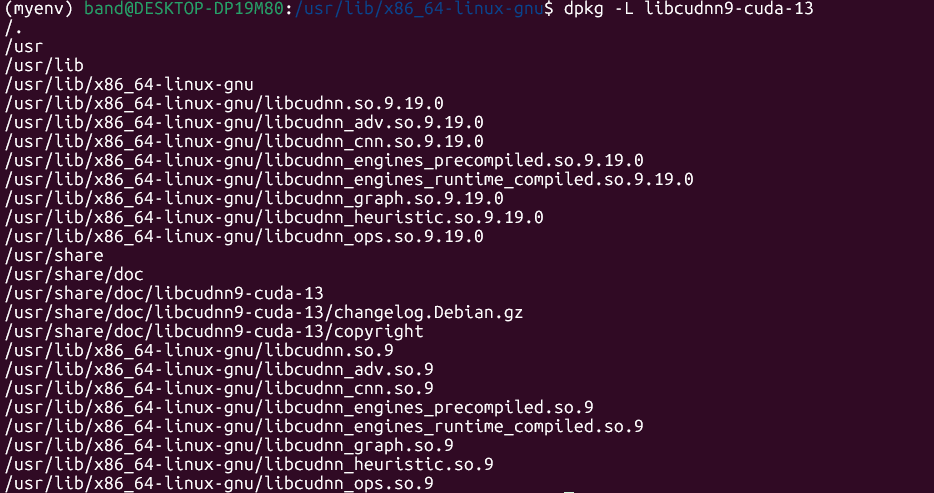

验证,与前文类似,先安装Anaconda,再安装pytorch,所有工作完成后。执行如下命令:python test_cuda.py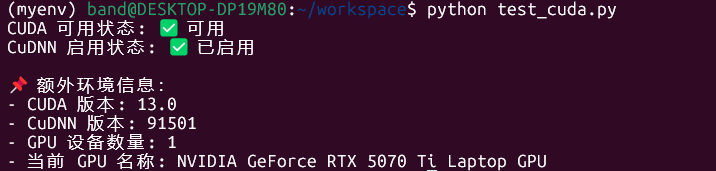
编译llama.cpp
node-llama-cpp 会尝试构建 CUDA / Vulkan / CPU 三种版本,最终 fallback 到 CPU 版成功。为了避免用CPU版本,我先安装调试好CUDA。我估计这一步可以采用官网的指引,Install llama.cpp using brew, nix or winget。
https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
git clone https://github.com/ggml-org/llama.cpp.git
# 前提,要设置好环境变量,DLLAMA_OPENSSL是必要的,后面会有提示
cd llama.cpp
cmake -B build -DGGML_CUDA=ON -DLLAMA_OPENSSL=ON
cmake --build build --config Release
验证llama.cpp是否已经安装好
验证方案1:
访问: https://huggingface.co/Qwen/Qwen3-0.6B-GGUF/tree/main ,点击Use this model,选择llama.cpp,出现下面的窗口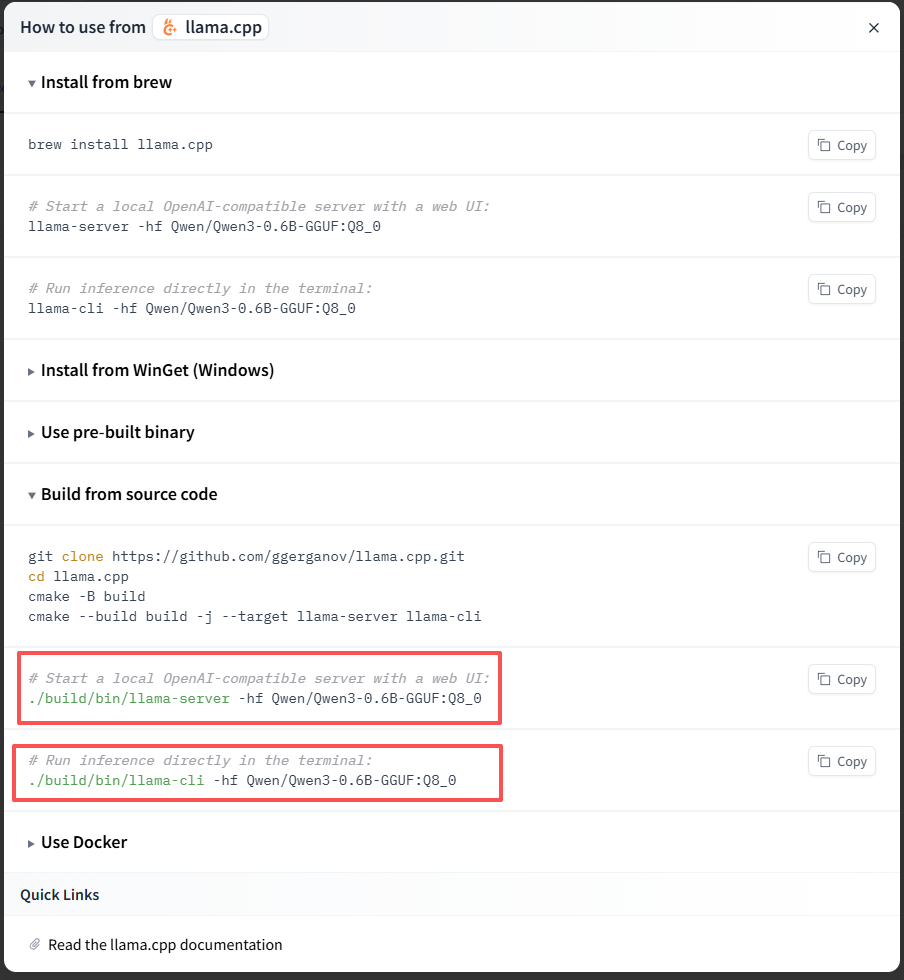
因为我是再WSL种运行,就选择cli方案:
# Run inference directly in the terminal:
./build/bin/llama-cli -hf Qwen/Qwen3-0.6B-GGUF:Q8_0
如果出现下面的错误,加上-DLLAMA_OPENSSL=ON参数,重新编译llama.cpp。
解决之后又有新的报错。暂时先到这里,没有继续验证,TODO
验证方案2:下载并运行Llama-2 7B模型
# 安装并初始化git-lfs(GIt Large File Storage)
$ sudo apt install git-lfs
$ git lfs install
这个方案我没有做完。
安装node-llama-cpp
npm install -g node-llama-cpp
# 此处官网文档和网上的资料都给了我误导
node-llama-cpp --version
# 3.16.1
验证Memory
openclaw gateway restart
openclaw memory status --deep
正在下载模型到~/.node-llama-cpp/models,说明已经起作用了。
sqlite-vec unavailable
在openclaw doctor或openclaw memory status --deep,还有个错误。
[memory] sqlite-vec unavailable: /home/band/sqlite-vec.so: cannot open shared object file: No such file or directory
循着网上的信息,找到正主:https://github.com/asg017/sqlite-vec,安装教程在:https://alexgarcia.xyz/sqlite-vec/installation.html,编译教程:https://alexgarcia.xyz/sqlite-vec/compiling.html
# 缺少什么安装什么
sudo apt-get update
sudo apt-get install unzip
sudo apt install -y libsqlite3-dev
git clone https://github.com/asg017/sqlite-vec
cd sqlite-vec
./scripts/vendor.sh
make loadable
按照官网的编译教程还是有误,就没继续。
我用了一个取巧的办法,
# 先安装,安装的目录在~/.npm-global/lib/node_modules/sqlite-vec/node_modules/sqlite-vec-linux-x64/vec0.so。
# 如果不知道在哪,可以先用whereis node-llama-cpp/pnpm,找到~/.npm-global/bin/,lib在同一个目录
npm install -g sqlite-vec
修改如下配置,重启gateway,再执行openclaw memory status --deep,问题修复
"extensionPath": "~/.npm-global/lib/node_modules/sqlite-vec/node_modules/sqlite-vec-linux-x64/vec0.so"
踩过的坑
安装node-llama-cpp的一些提示
openclaw的文档提示如下:
### [本地嵌入自动下载]
- 默认本地嵌入模型:`hf:ggml-org/embeddinggemma-300M-GGUF/embeddinggemma-300M-Q8_0.gguf`(约 0.6 GB)。
- 当 `memorySearch.provider = "local"` 时,`node-llama-cpp` 解析 `modelPath`;如果 GGUF 缺失,它会自动下载到缓存(或 `local.modelCacheDir`,如果已设置),然后加载它。下载在重试时会续传。
- 原生构建要求:运行 `pnpm approve-builds`,选择 `node-llama-cpp`,然后运行 `pnpm rebuild node-llama-cpp`。
- 回退:如果本地设置失败且 `memorySearch.fallback = "openai"`,我们自动切换到远程嵌入(`openai/text-embedding-3-small`,除非被覆盖)并记录原因。
运行openclaw doctor,提示如下
Memory search provider is set to "local" but no local model file was found.
Fix (pick one):
- Install node-llama-cpp and set a local model path in config
- Switch to a remote provider: openclaw config set agents.defaults.memorySearch.provider
openai
Verify: openclaw memory status --deep
看起来必须要安装node-llama-cpp。于是继续搜寻资料。
cd ~/.openclaw/extensions
npm install node-llama-cpp
# 此时node-llama-cpp安装到~/.openclaw/extensions/node_modules,没有起作用。
pnpm approve-builds
# 提示没有需要编译的:There are no packages awaiting approval
npx --no node-llama-cpp inspect gpu
# 提示报错
安装node-llama-cpp的前置条件
OpenClaw 依赖 node-llama-cpp,网上说要原生编译安装。需要从源码编译 llama.cpp(大型 C++ AI 库)。所以要先编译llama.cpp,还依赖CUDA和cuDNN。所以正确的安装顺序是:
- 安装CUDA
- 安装cuDNN
- 编译llama.cpp
- 原生编译安装node-llama-cpp
# https://github.com/withcatai/node-llama-cpp.git
sudo apt-get update
sudo apt-get install build-essential cmake git libstdc++6 libgomp1
npx node-llama-cpp source download
npx node-llama-cpp source build
当我尝试执行npx node-llama-cpp source download,一直报错。
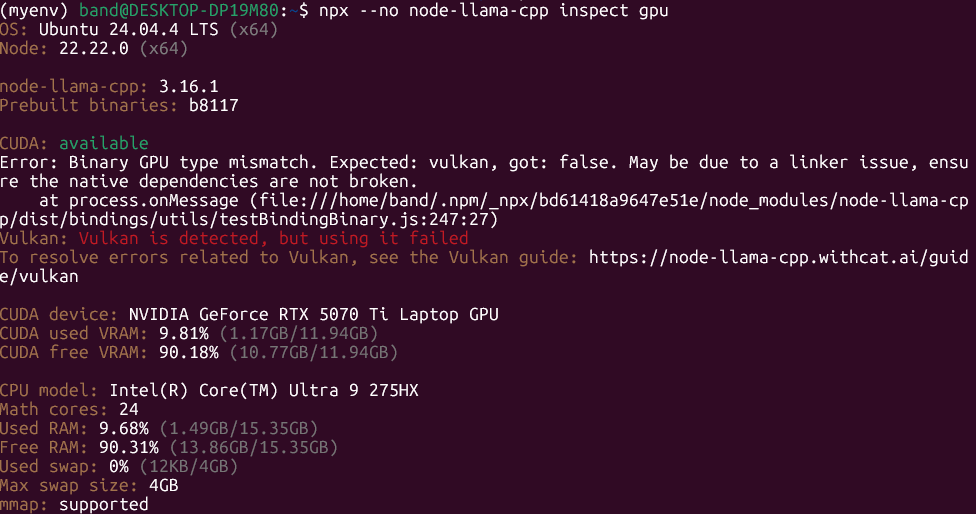
此时我再尝试执行npx --no node-llama-cpp inspect gpu,能正确执行,但是报错如下。让我很意外,怀疑是因为我把llama.cpp已经编译成功的缘故。
Vulkan: Vulkan is detected, but using it failed
To resolve errors related to Vulkan, see the Vulkan guide: https://node-llama-cpp.withcat.ai/guide/vulkan
Using node-llama-cpp With Vulkan
这个问题是在处理node-llama-cpp时遇到的,目前看没有影响,后面也没处理。
关键词:openclaw, Memory_search, node-llama-cpp, 本地模式,cuda等

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 37
37 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)