
别搞混了!MCP和Agent Skill到底有什么区别
MCPSkill「哲学」连接主义知识打包「问的问题」“AI 能访问什么?“AI 知道怎么做什么?「层级」集成层知识层「Token 策略」预加载所有能力按需加载知识记住这句话:❝❞MCP 让 AI 能"碰到"数据,Skill 教 AI 怎么"处理"数据。它们不是替代关系,而是互补关系。一个成熟的 AI Agent 系统,两者都需要。
文章详细对比了AI Agent中的MCP和Skill。MCP是连接AI与外部世界的协议,解决"能访问什么";Skill是教AI如何做任务的方法论,解决"怎么做"。两者在架构层级上不同,MCP在集成层,Skill在提示/知识层,是互补而非替代关系。文章从设计哲学、技术架构、使用场景三个维度解析了它们的区别与应用。
 (✨年终技术征文火热进行中,速戳上图了解详情🔍)
(✨年终技术征文火热进行中,速戳上图了解详情🔍)
用 AI Agent 工具(Claude Code、Cursor、Windsurf 等)的时候,经常会遇到两个概念:
- MCP(Model Context Protocol)
- Skill(Agent Skill)
它们看起来都是"扩展 AI 能力"的方式,但具体有什么区别?为什么需要两套机制?什么时候该用哪个?
这篇文章会从设计哲学、技术架构、使用场景三个维度,把这两个概念彻底讲清楚。
一句话区分
先给个简单的定位:
❝
「MCP 解决"连接"问题:让 AI 能访问外部世界」****「Skill 解决"方法论"问题:教 AI 怎么做某类任务」
❞
用 Anthropic 官方的说法:
❝
“MCP connects Claude to external services and data sources. Skills provide procedural knowledge—instructions for how to complete specific tasks or workflows.”
❞
打个比方:MCP 是 AI 的"手"(能触碰外部世界),Skill 是 AI 的"技能书"(知道怎么做某件事)。
你需要两者配合:MCP 让 AI 能连接数据库,Skill 教 AI 怎么分析查询结果。
MCP:AI 应用的 USB-C 接口
MCP 是什么
MCP(Model Context Protocol)是 Anthropic 在 2024 年 11 月发布的**「开源协议」**,用于标准化 AI 应用与外部系统的交互方式。
官方的比喻是"AI 应用的 USB-C 接口"——就像 USB-C 提供了一种通用的方式连接各种设备,MCP 提供了一种通用的方式连接各种工具和数据源。
「关键点:MCP 不是 Claude 专属的。」
它是一个开放协议,理论上任何 AI 应用都可以实现。截至 2025 年初,已经被多个平台采用:
- 「Anthropic」: Claude Desktop、Claude Code
- 「OpenAI」: ChatGPT、Agents SDK、Responses API
- 「Google」: Gemini SDK
- 「Microsoft」: Azure AI Services
- 「开发工具」: Zed、Replit、Codeium、Sourcegraph
到 2025 年 2 月,已经有超过 1000 个开源 MCP 连接器。
MCP 的架构
MCP 基于 「JSON-RPC 2.0」 协议,采用**「客户端-主机-服务器」**(Client-Host-Server)架构:
┌─────────────────────────────────────────────────────────┐
- 「Host」:用户直接交互的应用(Claude Desktop、Cursor、Windsurf)
- 「Client」:Host 应用中管理与特定 Server 通信的组件
- 「Server」:连接外部系统的桥梁(数据库、API、本地文件等)
MCP 的三个核心原语
MCP 定义了三种 Server 可以暴露的原语:
1. Tools(工具)—— 模型控制
可执行的函数,AI 可以调用来执行操作。
{
AI 决定什么时候调用这些工具。比如用户问"这个月的收入是多少",AI 判断需要查数据库,就会调用 query_database 工具。
2. Resources(资源)—— 应用控制
数据源,为 AI 提供上下文信息。
{
资源由应用控制何时加载。用户可以通过 @ 引用资源,类似于引用文件。
3. Prompts(提示)—— 用户控制
预定义的提示模板,帮助结构化与 AI 的交互。
{
用户显式触发这些提示,类似于 Slash Command。
MCP 与 Function Calling 的关系
很多人会问:MCP 和 OpenAI 的 Function Calling、Anthropic 的 Tool Use 有什么区别?
「Function Calling」 是 LLM 的能力——把自然语言转换成结构化的函数调用请求。LLM 本身**「不执行」**函数,只是告诉你"应该调用什么函数,参数是什么"。
「MCP」 是在 Function Calling 之上的**「协议层」**——它标准化了"函数在哪里、怎么调用、怎么发现"。
两者的关系:
用户输入 → LLM (FunctionCalling) → "需要调用 query_database"
「Function Calling 解决"决定做什么",MCP 解决"怎么做到"。」
MCP 的传输方式
MCP 支持两种主要的传输方式:
| 传输方式 | 适用场景 | 说明 |
|---|---|---|
| 「Stdio」 | 本地进程 | Server 在本地机器运行,适合需要系统级访问的工具 |
| 「HTTP/SSE」 | 远程服务 | Server 在远程运行,适合云服务(GitHub、Sentry、Notion) |
大部分云服务用 HTTP,本地脚本和自定义工具用 Stdio。
MCP 的代价
MCP 不是免费的午餐,它有明显的成本:
「1. Token 消耗大」
每个 MCP Server 都会占用上下文空间。每次对话开始,MCP Client 需要告诉 LLM “你有这些工具可用”,这些工具定义会消耗大量 Token。
连接多个 MCP Server 后,光是工具定义可能就占用了上下文窗口的很大一部分。社区观察到:
❝
“We’re seeing a lot of MCP developers even at enterprise build MCP servers that expose way too much, consuming the entire context window and leading to hallucination.”
❞
「2. 需要维护连接」
MCP Server 是持久连接的外部进程。Server 挂了、网络断了、认证过期了,都会影响 AI 的能力。
「3. 安全风险」
Anthropic 官方警告:
❝
“Use third party MCP servers at your own risk - Anthropic has not verified the correctness or security of all these servers.”
❞
特别是能获取外部内容的 MCP Server(比如网页抓取),可能带来 prompt injection 风险。
MCP 的价值
尽管有这些代价,MCP 的价值在于**「标准化和可复用性」**:
- 「一次实现,到处使用」:同一个 GitHub MCP Server 可以在 Claude Desktop、Cursor、Windsurf 中使用
- 「动态发现」:AI 可以在运行时发现有哪些工具可用,而不是写死在代码里
- 「供应商无关」:不依赖特定的 LLM 提供商
Skill:上下文工程的渐进式公开
Skill 是什么
Skill(全称 Agent Skill)是 Anthropic 在 2025 年 10 月发布的特性。官方定义:
❝
“Skills are organized folders of instructions, scripts, and resources that agents can discover and load dynamically to perform better at specific tasks.”
❞
翻译一下:Skill 是一个文件夹,里面放着指令、脚本和资源,AI 会根据需要自动发现和加载。
「Skill 在架构层级上和 MCP 不同。」
用 Anthropic 的话说:
❝
“Skills are at the prompt/knowledge layer, whereas MCP is at the integration layer.”
❞
Skill 是"提示/知识层",MCP 是"集成层"。两者解决不同层面的问题。
Skill 的核心设计:渐进式信息公开
Skill 最精妙的设计是**「渐进式信息公开」**(Progressive Disclosure)。这是 Anthropic 在上下文工程(Context Engineering)领域的重要实践。
官方的比喻:
❝
“Like a well-organized manual that starts with a table of contents, then specific chapters, and finally a detailed appendix.”
❞
就像一本组织良好的手册:先看目录,再翻到相关章节,最后查阅附录。
Skill 分三层加载:
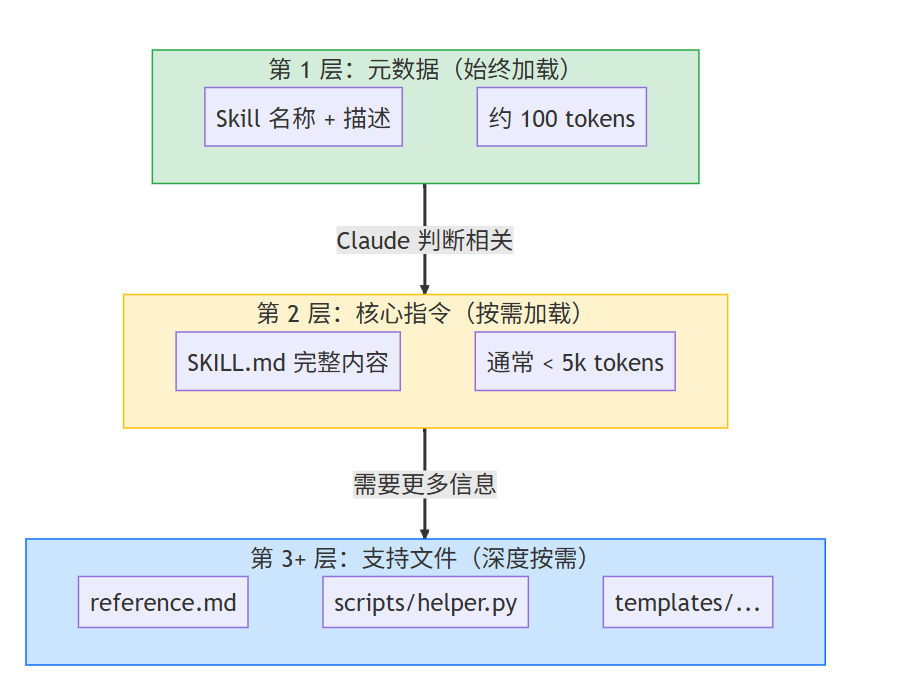
「这个设计的好处是什么?」
传统方式(比如 MCP)在会话开始时就把所有信息加载到上下文。如果你有 10 个 MCP Server,每个暴露 5 个工具,那就是 50 个工具定义——可能消耗数千甚至上万 Token。
Skill 的渐进式加载让你可以有几十个 Skill,但同时只加载一两个。「上下文效率大幅提升。」
用官方的话说:
❝
“This means that the amount of context that can be bundled into a skill is effectively unbounded.”
❞
理论上,单个 Skill 可以包含无限量的知识——因为只有需要的部分才会被加载。
上下文工程:Skill 背后的思想
Skill 是 Anthropic “上下文工程”(Context Engineering)理念的产物。官方对此有专门的阐述:
❝
“At Anthropic, we view context engineering as the natural progression of prompt engineering. Prompt engineering refers to methods for writing and organizing LLM instructions for optimal outcomes. Context engineering refers to the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference.”
❞
简单说:
- 「Prompt Engineering」:怎么写好提示词
- 「Context Engineering」:怎么管理上下文窗口里的信息
LLM 的上下文窗口是有限的(即使是 200k 窗口,也会被大量信息撑爆)。Context Engineering 的核心问题是:「在有限的窗口里,放什么信息能让 AI 表现最好?」
Skill 的渐进式加载就是 Context Engineering 的具体实践——只加载当前任务需要的信息,让每一个 Token 都发挥最大价值。
Skill 的触发机制
Skill 是**「自动触发」**的,这是它和 Slash Command 的关键区别。
工作流程:
- 「扫描阶段」:Claude 读取所有 Skill 的元数据(名称 + 描述)
- 「匹配阶段」:将用户请求与 Skill 描述进行语义匹配
- 「加载阶段」:如果匹配成功,加载完整的 SKILL.md
- 「执行阶段」:按照 Skill 里的指令执行任务,按需加载支持文件
用户不需要显式调用。比如你有一个 code-review Skill,用户说"帮我 review 这段代码",Claude 会自动匹配并加载。
「Skill 的本质是什么?」
技术上,Skill 是一个**「元工具」**(Meta-tool):
❝
“The Skill tool is a meta-tool that manages all skills. Traditional tools like Read, Bash, or Write execute discrete actions and return immediate results. Skills operate differently—rather than performing actions directly, they inject specialized instructions into the conversation history and dynamically modify Claude’s execution environment.”
❞
Skill 不是执行具体动作,而是**「注入指令」**到对话历史中,动态修改 Claude 的执行环境。
Skill 的文件结构
一个标准的 Skill 长这样:
my-skill/
SKILL.md 是核心,必须包含 YAML 格式的元数据:
---
「关键字段:」
name:Skill 的唯一标识,小写字母 + 数字 + 连字符,最多 64 字符description:描述做什么、什么时候用,最多 1024 字符
description 的质量直接决定 Skill 能不能被正确触发。
Skill 的安全考虑
Skill 有一个潜在的安全问题:「Prompt Injection」。
研究人员发现:
❝
“Although Agent Skills can be a very useful tool, they are fundamentally insecure since they enable trivially simple prompt injections. Researchers demonstrated how to hide malicious instructions in long Agent Skill files and referenced scripts to exfiltrate sensitive data.”
❞
因为 Skill 本质上是注入指令,恶意的 Skill 可以在长文件中隐藏恶意指令,窃取敏感数据。
「应对措施:」
- 「只使用可信来源的 Skill」
- 「审查 Skill 中的脚本」
- 「使用
allowed-tools限制 Skill 的能力范围」
---
Skill 的平台支持
Agent Skills 目前支持:
- Claude.ai(Pro、Max、Team、Enterprise)
- Claude Code
- Claude Agent SDK
- Claude Developer Platform
需要注意的是,**「Skill 目前是 Anthropic 生态专属」**的,不像 MCP 是跨平台的开放协议。
MCP vs Skill:架构层级对比
现在我们可以从架构层级来理解两者的区别:
┌─────────────────────────────────────────────────────────┐
「Skill 在上层(知识层),MCP 在下层(集成层)。」
两者不是替代关系,而是互补关系。你可以:
- 用 MCP 连接 GitHub
- 用 Skill 教 AI 如何按照团队规范做 Code Review
详细对比表
| 维度 | MCP | Skill |
|---|---|---|
| 「核心作用」 | 连接外部系统 | 编码专业知识和方法论 |
| 「架构层级」 | 集成层 | 提示/知识层 |
| 「协议基础」 | JSON-RPC 2.0 | 文件系统 + Markdown |
| 「跨平台」 | 是(开放协议,多平台支持) | 否(目前 Anthropic 生态专属) |
| 「触发方式」 | 持久连接,随时可用 | 基于描述的语义匹配,自动触发 |
| 「Token 消耗」 | 高(工具定义持久占用上下文) | 低(渐进式加载) |
| 「外部访问」 | 可以直接访问外部系统 | 不能直接访问,需要配合 MCP 或内置工具 |
| 「复杂度」 | 高(需要理解协议、运行 Server) | 低(写 Markdown 就行) |
| 「可复用性」 | 高(标准化协议,跨应用复用) | 中(文件夹,可以 Git 共享) |
| 「动态发现」 | 是(运行时发现可用工具) | 是(运行时发现可用 Skill) |
| 「安全考虑」 | 外部内容带来 prompt injection 风险 | Skill 文件本身可能包含恶意指令 |
什么时候用 MCP,什么时候用 Skill
用 MCP 的场景
- 「需要访问外部数据」:数据库查询、API 调用、文件系统访问
- 「需要操作外部系统」:创建 GitHub Issue、发送 Slack 消息、执行 SQL
- 「需要实时信息」:监控系统状态、查看日志、搜索引擎结果
- 「需要跨平台复用」:同一个工具在 Claude Desktop、Cursor、其他支持 MCP 的应用中使用
用 Skill 的场景
- 「重复性的工作流程」:代码审查、文档生成、数据分析
- 「公司内部规范」:代码风格、提交规范、文档格式
- 「需要多步骤的复杂任务」:需要详细指导的专业任务
- 「团队共享的最佳实践」:标准化的操作流程
- 「Token 敏感场景」:需要大量知识但不想一直占用上下文
结合使用
很多时候,两者是配合使用的:
用户:"Review PR #456 并按照团队规范给出建议"
「MCP 负责"能访问什么",Skill 负责"怎么做"。」
写好 Skill 的关键
Skill 能不能被正确触发,90% 取决于 description 写得好不好。
差的 description
description: Helpswith data
太宽泛,Claude 不知道什么时候该用。
好的 description
description: >
好的 description 应该包含:
- 「做什么」:具体的能力描述
- 「什么时候用」:明确的触发场景
- 「触发词」:用户可能说的关键词
最佳实践
官方建议:
- 「保持专注」:一个 Skill 做一件事,避免宽泛的跨域 Skill
- 「SKILL.md 控制在 500 行以内」:太长的话拆分到支持文件
- 「测试触发行为」:确认相关请求能触发,不相关请求不会误触发
- 「版本控制」:记录 Skill 的变更历史
关于 Slash Command
文章标题是 MCP vs Skill,但很多人也会问到 Slash Command,简单说一下。
「Slash Command」 是最简单的扩展方式——本质上是存储的提示词,用户输入 /命令名 时注入到对话中。
「Skill vs Slash Command 的关键区别是触发方式:」
| Slash Command | Skill | |
|---|---|---|
| 触发方式 | 用户显式输入 /命令 |
Claude 自动匹配 |
| 用户控制 | 完全控制何时触发 | 无法控制,Claude 决定 |
问自己一个问题:「用户是否需要显式控制触发时机?」
- 需要 → Slash Command
- 不需要,希望 AI 自动判断 → Skill
总结
MCP 和 Skill 是 AI Agent 扩展的两种不同哲学:
| MCP | Skill | |
|---|---|---|
| 「哲学」 | 连接主义 | 知识打包 |
| 「问的问题」 | “AI 能访问什么?” | “AI 知道怎么做什么?” |
| 「层级」 | 集成层 | 知识层 |
| 「Token 策略」 | 预加载所有能力 | 按需加载知识 |
记住这句话:
❝
「MCP connects AI to data; Skills teach AI what to do with that data.」
❞
MCP 让 AI 能"碰到"数据,Skill 教 AI 怎么"处理"数据。
它们不是替代关系,而是互补关系。一个成熟的 AI Agent 系统,两者都需要。
普通人如何抓住AI大模型的风口?
为什么要学习大模型?
在DeepSeek大模型热潮带动下,“人工智能+”赋能各产业升级提速。随着人工智能技术加速渗透产业,AI人才争夺战正进入白热化阶段。如今近**60%的高科技企业已将AI人才纳入核心招聘目标,**其创新驱动发展的特性决定了对AI人才的刚性需求,远超金融(40.1%)和专业服务业(26.7%)。餐饮/酒店/旅游业核心岗位以人工服务为主,多数企业更倾向于维持现有服务模式,对AI人才吸纳能力相对有限。
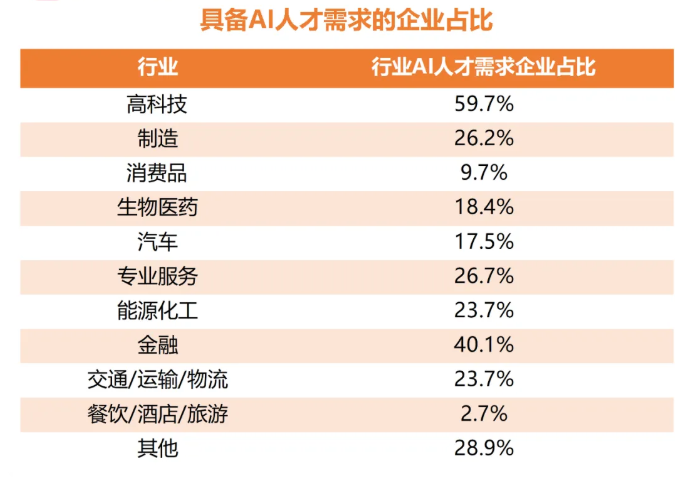
这些数字背后,是产业对AI能力的迫切渴求:互联网企业用大模型优化推荐算法,制造业靠AI提升生产效率,医疗行业借助大模型辅助诊断……而餐饮、酒店等以人工服务为核心的领域,因业务特性更依赖线下体验,对AI人才的吸纳能力相对有限。显然,AI技能已成为职场“加分项”乃至“必需品”,越早掌握,越能占据职业竞争的主动权
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
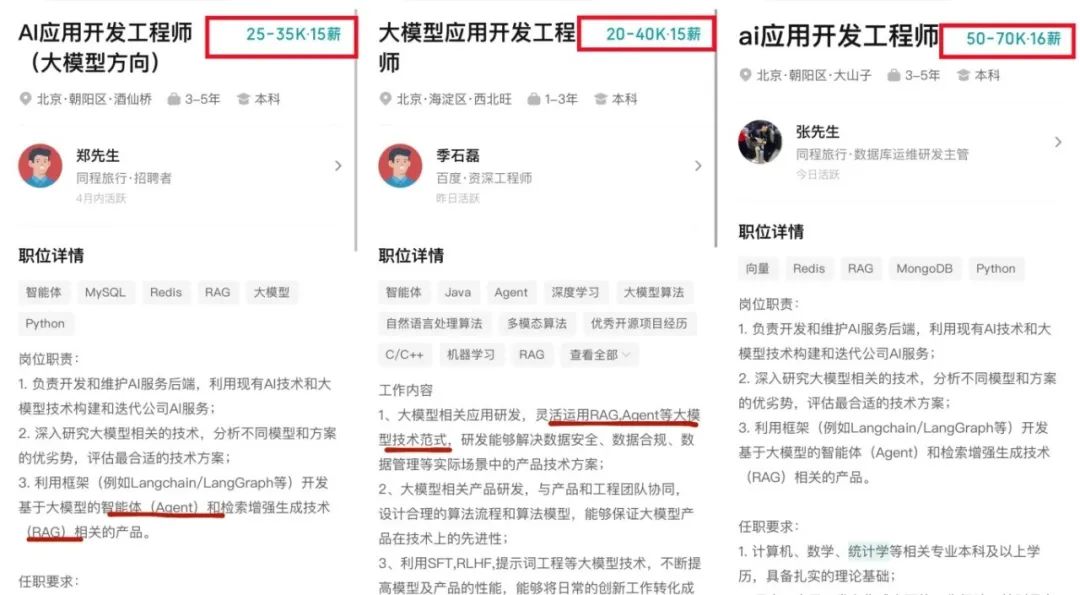
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可

部分资料展示
一、 AI大模型学习路线图
这份路线图以“阶段性目标+重点突破方向”为核心,从基础认知(AI大模型核心概念)到技能进阶(模型应用开发),再到实战落地(行业解决方案),每一步都标注了学习周期和核心资源,帮你清晰规划成长路径。

二、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

三、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

四、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 36
36 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)