
Claude Agent SDK深度解析:构建可扩展的多智能体研究系统【实战教程·收藏必看】
本文介绍了一种基于Claude Agent SDK构建的多智能体Deep Research系统,采用"指挥官-执行者"架构,由Lead Agent协调Researcher、Data Analyst和Report Writer三个专业Agent协同工作。系统通过全链路追踪机制、精心设计的Prompt工程和Skill技能包系统,实现从信息检索、数据分析到报告生成的自动化流程。文章详
本文详细介绍了基于Claude Agent SDK构建的多智能体Deep Research系统,采用"指挥官-执行者"架构,通过Lead Agent协调Researcher、Data Analyst和Report Writer四个专业Agent并行工作。系统实现了全链路追踪机制、精心设计的Prompt工程和Skill技能包系统,能够自动完成从信息检索、数据分析到报告生成的完整流程。文章提供了详细的工程实践指南,包括架构设计、技术实现、调试技巧和优化方向,为构建高效可追溯的多智能体协作系统提供了完整参考。
Claude Agent SDK Deep Research:多智能体研究系统的工程实践
unsetunset前言unsetunset
在AI应用开发领域,如何构建一个能够自主协作、分工明确的多智能体系统,一直是个颇具挑战的课题。最近Claude官方基于Claude Agent SDK实现了一个深度研究系统(Deep Research),通过主控Agent协调多个专业子Agent并行工作,自动完成从信息检索、数据分析到报告生成的完整流程。这篇文章将从工程实践角度,剖析这套系统的设计思路和核心实现。
unsetunset👉 欢迎关注我的开源项目unsetunset
🎬 运行效果预览
unsetunset一、系统架构概览unsetunset
1.1 整体设计思路
Deep Research采用了典型的"指挥官-执行者"架构模式。主控Agent(Lead Agent)负责任务分解和调度,不直接执行具体的研究工作,而是将任务委派给专业的子Agent并行处理。这种设计带来了几个明显的优势:
- 职责分离:每个Agent专注于自己擅长的领域
- 并行执行:多个研究任务可以同时进行,大幅提升效率
- 可扩展性:新增专业Agent只需定义配置,无需修改核心逻辑
- 可追溯性:通过Hook机制记录所有工具调用,便于调试和审计
1.2 Agent角色定义
系统包含4个核心Agent,各司其职:
| Agent类型 | 可用工具 | 核心职责 | 模型选择 |
|---|---|---|---|
| Lead Agent | Task | 任务分解、子Agent调度、流程编排 | claude-haiku |
| Researcher | WebSearch, Write | 网络信息检索、研究笔记撰写 | claude-haiku |
| Data Analyst | Glob, Read, Bash, Write | 数据提取、图表生成、量化分析 | claude-haiku |
| Report Writer | Skill, Write, Glob, Read, Bash | 综合报告撰写、PDF生成 | claude-haiku |
1.3 工作流程
整个研究流程分为5个阶段,严格按序执行:
用户请求 ↓[阶段1] Lead Agent分析需求,拆解为2-4个子课题 ↓[阶段2] 并行启动多个Researcher,每个负责一个子课题 ↓[阶段3] 等待所有Researcher完成,启动Data Analyst提取数据并生成图表 ↓[阶段4] 启动Report Writer整合研究笔记和图表,生成PDF报告 ↓[阶段5] 返回报告路径给用户
unsetunset二、核心技术实现unsetunset
DeepSeek模型已适配并接入到Anthropic API生态中- 本地调试在.env文件配置成DeepSeek模型
ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropicANTHROPIC_API_KEY=sk-xxx
官方文档: https://api-docs.deepseek.com/zh-cn/guides/anthropic_api
2.1 Agent定义与配置
使用Claude Agent SDK的AgentDefinition来声明子Agent,这是整个系统的基础配置:
from claude_agent_sdk import AgentDefinitionagents = { "researcher": AgentDefinition( description=( "Use this agent when you need to gather research information on any topic. " "The researcher uses web search to find relevant information, articles, and sources " "from across the internet. Writes research findings to files/research_notes/ " "for later use by report writers." ), tools=["WebSearch", "Write"], prompt=researcher_prompt, model="haiku" ), "data-analyst": AgentDefinition( description=( "Use this agent AFTER researchers have completed their work to generate quantitative " "analysis and visualizations. Reads research notes, extracts numerical data, and generates " "charts using Python/matplotlib via Bash." ), tools=["Glob", "Read", "Bash", "Write"], prompt=data_analyst_prompt, model="haiku" ), "report-writer": AgentDefinition( description=( "Use this agent when you need to create a formal research report document. " "Reads research findings and synthesizes them into professionally formatted PDF reports." ), tools=["Skill", "Write", "Glob", "Read", "Bash"], prompt=report_writer_prompt, model="haiku" )}

关键设计点:
description:告诉Lead Agent何时使用该子Agent,这是任务路由的依据tools:限定每个Agent的工具权限,避免越权操作prompt:每个Agent有独立的系统提示词,定义其行为准则model:统一使用haiku模型,在成本和性能间取得平衡
2.2 Hook机制:全链路追踪的核心
系统通过PreToolUse和PostToolUse两个Hook实现了完整的工具调用追踪。这是理解子Agent行为的关键机制。
Hook配置
from claude_agent_sdk import HookMatcherhooks = { 'PreToolUse': [ HookMatcher( matcher=None, # 匹配所有工具 hooks=[tracker.pre_tool_use_hook] ) ], 'PostToolUse': [ HookMatcher( matcher=None, # 匹配所有工具 hooks=[tracker.post_tool_use_hook] ) ]}
SubagentTracker实现
SubagentTracker是整个追踪系统的核心类,负责:
- 监听消息流,识别Task工具调用(子Agent启动)
- 通过
parent_tool_use_id关联工具调用与子Agent - 记录每个工具的输入、输出和执行时间
- 生成人类可读的transcript和结构化的JSONL日志
class SubagentTracker: def __init__(self, transcript_writer=None, session_dir: Optional[Path] = None): # 存储所有子Agent会话:parent_tool_use_id -> SubagentSession self.sessions: Dict[str, SubagentSession] = {} # 存储所有工具调用记录:tool_use_id -> ToolCallRecord self.tool_call_records: Dict[str, ToolCallRecord] = {} # 当前执行上下文(从消息流中获取) self._current_parent_id: Optional[str] = None # 子Agent计数器,用于生成唯一ID(如RESEARCHER-1) self.subagent_counters: Dict[str, int] = defaultdict(int) # 日志文件句柄 self.tool_log_file = open(session_dir / "tool_calls.jsonl", "w")
PreToolUse Hook:捕获工具调用
async def pre_tool_use_hook(self, hook_input, tool_use_id, context): """在工具执行前被调用""" tool_name = hook_input['tool_name'] tool_input = hook_input['tool_input'] timestamp = datetime.now().isoformat() # 判断是否为子Agent的工具调用 is_subagent = self._current_parent_id and self._current_parent_id in self.sessions if is_subagent: session = self.sessions[self._current_parent_id] agent_id = session.subagent_id # 如 "RESEARCHER-1" # 创建工具调用记录 record = ToolCallRecord( timestamp=timestamp, tool_name=tool_name, tool_input=tool_input, tool_use_id=tool_use_id, subagent_type=session.subagent_type, parent_tool_use_id=self._current_parent_id ) # 存储记录 session.tool_calls.append(record) self.tool_call_records[tool_use_id] = record # 记录日志 self._log_tool_use(agent_id, tool_name, tool_input) self._log_to_jsonl({ "event": "tool_call_start", "agent_id": agent_id, "tool_name": tool_name, "tool_input": tool_input }) return {'continue_': True}
PostToolUse Hook:捕获执行结果
async def post_tool_use_hook(self, hook_input, tool_use_id, context): """在工具执行后被调用""" tool_response = hook_input.get('tool_response') record = self.tool_call_records.get(tool_use_id) if record: # 更新记录的输出 record.tool_output = tool_response # 检查错误 error = tool_response.get('error') if isinstance(tool_response, dict) elseNone if error: record.error = error # 记录完成日志 self._log_to_jsonl({ "event": "tool_call_complete", "tool_use_id": tool_use_id, "success": error isNone, "output_size": len(str(tool_response)) }) return {'continue_': True}
2.3 子Agent注册与上下文管理
当Lead Agent使用Task工具启动子Agent时,系统需要建立追踪关系:
def register_subagent_spawn(self, tool_use_id: str, subagent_type: str, description: str, prompt: str) -> str: """注册新的子Agent启动""" # 生成唯一ID self.subagent_counters[subagent_type] += 1 subagent_id = f"{subagent_type.upper()}-{self.subagent_counters[subagent_type]}" # 创建会话记录 session = SubagentSession( subagent_type=subagent_type, parent_tool_use_id=tool_use_id, # 关键:用于关联后续工具调用 spawned_at=datetime.now().isoformat(), description=description, prompt_preview=prompt[:200] + "...", subagent_id=subagent_id ) self.sessions[tool_use_id] = session return subagent_id
关键机制:parent_tool_use_id是整个追踪系统的核心。当子Agent执行工具时,SDK会自动在消息中附带这个ID,Tracker通过它识别出工具调用来自哪个子Agent。
2.4 消息流处理
主循环通过异步流接收Agent响应,并实时处理:
async for msg in client.receive_response(): if type(msg).__name__ == 'AssistantMessage': # 更新追踪器的上下文 parent_id = getattr(msg, 'parent_tool_use_id', None) tracker.set_current_context(parent_id) for block in msg.content: if type(block).__name__ == 'TextBlock': # 输出文本内容 transcript.write(block.text) elif type(block).__name__ == 'ToolUseBlock': # 处理工具调用 if block.name == 'Task': # 注册子Agent启动 subagent_id = tracker.register_subagent_spawn( tool_use_id=block.id, subagent_type=block.input['subagent_type'], description=block.input['description'], prompt=block.input['prompt'] ) transcript.write(f"\n[🚀 Spawning {subagent_id}]\n")
unsetunset三、Prompt工程:Agent行为的精准控制unsetunset
3.1 Lead Agent Prompt设计
Lead Agent的Prompt是整个系统的"指挥手册",需要明确定义:
核心约束:
**CRITICAL RULES:**1. You MUST delegate ALL research and report writing to specialized subagents2. Keep ALL responses SHORT - maximum 2-3 sentences3. Get straight to work immediately - analyze and spawn subagents right away
工作流程:
STEP 1: ANALYZE USER REQUEST- Identify 2-4 distinct subtopics or angles to investigateSTEP 2: SPAWN RESEARCHER SUBAGENTS (IN PARALLEL)- Use Task tool to spawn 2-4 researcher subagents simultaneously- Give EACH researcher a specific, focused subtopicSTEP 3: WAIT FOR RESEARCH COMPLETIONSTEP 4: SPAWN DATA-ANALYST SUBAGENT- Instruct it to read ALL research notes and generate chartsSTEP 5: SPAWN REPORT-WRITER SUBAGENT- Instruct it to create comprehensive PDF reportSTEP 6: CONFIRM COMPLETION
任务分解示例:
User asks: "Research quantum computing"Subtopics breakdown:- Researcher 1: "Current state of quantum hardware and qubit technology"- Researcher 2: "Quantum algorithms and real-world applications"- Researcher 3: "Major companies and investments in quantum computing"- Researcher 4: "Challenges and timeline to practical quantum advantage"
3.2 Researcher Prompt:数据优先策略
Researcher的核心使命是收集量化数据,而非泛泛的描述性内容。Prompt中强调:
**CRITICAL: You MUST prioritize QUANTITATIVE DATA**Types of data to prioritize:- Market sizes (e.g., "$384 billion market in 2024")- Growth rates (e.g., "25.3% year-over-year growth")- Percentages (e.g., "63% of users prefer...")- Rankings (e.g., "Tesla leads with 19.5% market share")- Comparisons (e.g., "40% faster than previous generation")
搜索策略:
# 数据导向的搜索查询queries = [ "[topic] statistics 2024 2025", "[topic] market research report", "[topic] survey results", "[topic] industry data"]
输出格式要求:
## Key Statistics- Market size: $384 billion (2024)- Growth rate: 25.3% YoY- Total units sold: 17.1 million## Rankings & Comparisons| Company | Market Share | YoY Change ||---------|-------------|------------|| Tesla | 19.5% | -2.1% || BYD | 16.2% | +4.3% |
质量标准:每份研究笔记必须包含至少10-15个具体数字/统计数据,否则视为不合格。
3.3 Data Analyst Prompt:可视化生成
Data Analyst的任务是将Researcher收集的数据转化为图表:
# 图表生成模式python3 << 'EOF'import matplotlib.pyplot as pltimport osos.makedirs('files/charts', exist_ok=True)# 示例:市场份额柱状图companies = ['Tesla', 'BYD', 'VW Group', 'GM', 'Others']market_share = [19.5, 16.2, 8.3, 6.1, 49.9]plt.figure(figsize=(10, 6))plt.bar(companies, market_share, color=['#e41a1c', '#377eb8', '#4daf4a', '#984ea3', '#999999'])plt.title('Global EV Market Share 2024', fontsize=14, fontweight='bold')plt.ylabel('Market Share (%)')plt.xlabel('Company')for i, v in enumerate(market_share): plt.text(i, v + 0.5, f'{v}%', ha='center', fontsize=10)plt.savefig('files/charts/ev_market_share.png', dpi=150, bbox_inches='tight')plt.close()EOF
图表类型选择:
| 数据类型 | 推荐图表 | 使用场景 |
|---|---|---|
| 对比数据 | 柱状图 | 市场份额、公司排名、功能对比 |
| 时间序列 | 折线图 | 增长趋势、采用曲线 |
| 占比分布 | 饼图 | 市场分布、类别占比 |
| 排名列表 | 横向柱状图 | 排名或带数值的列表 |
3.4 Report Writer Prompt:PDF报告生成
Report Writer使用reportlab库生成专业PDF报告:
from reportlab.lib.pagesizes import letterfrom reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, Image# 创建文档doc = SimpleDocTemplate( "files/reports/topic_report_20251216.pdf", pagesize=letter, rightMargin=72, leftMargin=72, topMargin=72, bottomMargin=72)story = []# 标题story.append(Paragraph("Research Report Title", styles['Title']))story.append(Spacer(1, 0.25*inch))# 执行摘要story.append(Paragraph("Executive Summary", styles['Heading1']))story.append(Paragraph("Summary text...", styles['Justify']))# 嵌入图表if os.path.exists('files/charts/chart.png'): img = Image('files/charts/chart.png', width=5*inch, height=3*inch) story.append(img)# 关键发现story.append(Paragraph("Key Findings", styles['Heading1']))story.append(Paragraph("• Finding 1 with citation", styles['Justify']))# 生成PDFdoc.build(story)
unsetunset四、Skill技能包系统unsetunset
4.1 Skill机制概述
Claude Agent SDK支持通过Skill技能包扩展Agent的能力。Skill本质上是预定义的知识库和最佳实践指南,Agent可以通过Skill工具调用来获取专业领域的指导。
在Deep Research系统中,.claude/skills/目录下包含两个核心技能包:
| Skill名称 | 用途 | 主要使用者 | 激活方式 |
|---|---|---|---|
| PDF文档处理全套工具指南 | Report Writer | 显式调用Skill工具 | |
| executive-briefing | 高管简报格式化指南 | Report Writer | 关键词自动激活 |
4.2 Skill的目录结构
每个Skill都遵循标准的目录结构:
.claude/skills/├── pdf/│ ├── SKILL.md # 主要技能文档(快速参考)│ ├── REFERENCE.md # 高级参考文档│ ├── FORMS.md # PDF表单处理专题│ ├── LICENSE.txt # 许可证信息│ └── scripts/ # 辅助脚本└── executive-briefing/ └── SKILL.md # 高管简报格式指南
4.3 PDF技能包详解
技能包元数据
---name:pdfdescription:ComprehensivePDFmanipulationtoolkitforextractingtextandtables, creatingnewPDFs,merging/splittingdocuments,andhandlingforms.license:Proprietary---
核心能力矩阵
| 功能类别 | 推荐工具 | Python库 | 命令行工具 |
|---|---|---|---|
| 文本提取 | pdfplumber | page.extract_text() |
pdftotext |
| 表格提取 | pdfplumber | page.extract_tables() |
- |
| PDF创建 | reportlab | Canvas/Platypus | - |
| PDF合并 | pypdf | writer.add_page() |
qpdf --empty --pages |
| PDF拆分 | pypdf | 逐页写入 | qpdf --pages |
| OCR扫描件 | pytesseract | image_to_string() |
- |
| 表单填写 | pdf-lib/pypdf | 见FORMS.md | - |
典型使用场景
场景1:Report Writer生成PDF报告
# Report Writer调用Skill获取指导# Agent会使用Skill工具查询PDF创建的最佳实践from reportlab.lib.pagesizes import letterfrom reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, Imagefrom reportlab.lib.styles import getSampleStyleSheet# 创建多页PDF文档doc = SimpleDocTemplate("report.pdf", pagesize=letter)styles = getSampleStyleSheet()story = []# 添加标题title = Paragraph("Research Report", styles['Title'])story.append(title)story.append(Spacer(1, 12))# 添加内容body = Paragraph("Report content here...", styles['Normal'])story.append(body)# 嵌入图表if os.path.exists('files/charts/chart.png'): img = Image('files/charts/chart.png', width=5*inch, height=3*inch) story.append(img)# 构建PDFdoc.build(story)
场景2:提取研究笔记中的表格数据
# 如果研究笔记包含PDF格式的数据表import pdfplumberimport pandas as pdwith pdfplumber.open("data_source.pdf") as pdf: all_tables = [] for page in pdf.pages: tables = page.extract_tables() for table in tables: if table: df = pd.DataFrame(table[1:], columns=table[0]) all_tables.append(df) # 合并所有表格 combined_df = pd.concat(all_tables, ignore_index=True) combined_df.to_excel("extracted_data.xlsx", index=False)
Skill调用流程
Report Writer需要生成PDF ↓调用Skill工具: Skill(name="pdf", query="how to create PDF with reportlab") ↓SDK返回SKILL.md中的相关内容 ↓Report Writer根据指导编写Python代码 ↓使用Bash工具执行Python脚本 ↓生成PDF文件到files/reports/
4.4 Executive Briefing技能包
自动激活机制
Executive Briefing技能包采用关键词自动激活模式,当对话中出现以下关键词时自动生效:
executive summary,executive briefingC-suite,board presentation,leadership teamstakeholder update,management reportone-pager,key takeaways
BLUF原则(Bottom Line Up Front)
高管简报的核心原则是结论先行,标准格式如下:
═══════════════════════════════════════════════════════════EXECUTIVE BRIEFING: [主题]Date: [日期] | Prepared for: [受众]═══════════════════════════════════════════════════════════BOTTOM LINE━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[2-3句话:核心结论和建议行动]KEY FINDINGS━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━• [发现1 - 附带数据支撑]• [发现2 - 附带数据支撑]• [发现3 - 附带数据支撑]IMPLICATIONS━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━对[公司/团队]的影响:• [影响1]• [影响2]RECOMMENDED ACTIONS━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━1. [行动] - [负责人] - [时间线]2. [行动] - [负责人] - [时间线]3. [行动] - [负责人] - [时间线]RISKS & CONSIDERATIONS━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━• [风险/考量1]• [风险/考量2]═══════════════════════════════════════════════════════════Sources: [简要引用列表]Contact: [联系人]═══════════════════════════════════════════════════════════
风格指南对比
| 应该做(Do) | 不应该做(Don’t) |
|---|---|
| 使用数字和指标 | 使用未解释的术语 |
| 保持句子简短直接 | 包含冗长背景信息 |
| 大量使用项目符号 | 埋藏核心建议 |
| 突出需要决策的点 | 使用被动语态 |
| 包含明确的下一步行动 | 包含不驱动决策的信息 |
数据呈现最佳实践
❌ 不好的表达:"市场增长显著,用户数量大幅增加"✅ 好的表达:"市场规模达$2.3M(同比增长3倍),用户数从50K增至180K"❌ 不好的表达:"性能提升了900%"✅ 好的表达:"处理速度提升10倍(从2秒降至0.2秒)"
置信度指标
每个关键发现都应标注置信度:
- HIGH CONFIDENCE:多个可靠来源,数据已验证
- MEDIUM CONFIDENCE:良好来源但存在部分空白
- LOW CONFIDENCE:数据有限,新兴信息
4.5 Skill在Agent配置中的使用
在Agent定义中,Report Writer被授予了Skill工具权限:
"report-writer": AgentDefinition( description="...", tools=["Skill", "Write", "Glob", "Read", "Bash"], # 包含Skill工具 prompt=report_writer_prompt, model="haiku")
在Report Writer的Prompt中,明确指导何时使用Skill:
STEP 4: Invoke the "pdf" skill if you need guidance on reportlab usageAvailable Skills:- pdf: For PDF creation, manipulation, and processing guidance- executive-briefing: Automatically activated when creating executive summaries
4.6 Skill调用的实际案例
案例:生成高管简报
用户输入: "Create an executive briefing on quantum computing research"Report Writer识别关键词"executive briefing" ↓Executive-briefing技能自动激活 ↓Report Writer按照BLUF格式组织内容: 1. Bottom Line: 量子计算市场预计2030年达$125B,建议立即投资 2. Key Findings: 3个关键数据点 3. Implications: 对公司的2个影响 4. Recommended Actions: 3个具体行动项 ↓调用PDF技能获取格式化指导 ↓生成专业的高管简报PDF
4.7 自定义Skill的开发
如果需要扩展新的专业领域,可以创建自定义Skill:
# 创建新的Skill目录mkdir -p .claude/skills/data-visualization# 创建SKILL.mdcat > .claude/skills/data-visualization/SKILL.md << 'EOF'---name: data-visualizationdescription: Best practices for creating impactful data visualizations---# Data Visualization Guide## Chart Selection Matrix| Data Type | Best Chart | When to Use ||-----------|-----------|-------------|| Comparison | Bar Chart | Comparing categories || Trend | Line Chart | Showing change over time || Distribution | Histogram | Showing data distribution |...EOF
在Agent配置中启用:
options = ClaudeAgentOptions( setting_sources=["project"], # 从.claude目录加载Skills ...)
4.8 Skill系统的优势
- 知识复用:将最佳实践固化为可复用的知识库
- 降低Prompt复杂度:不需要在系统Prompt中塞入大量细节
- 按需加载:Agent只在需要时调用相关Skill,节省token
- 易于维护:更新Skill文档即可改进Agent行为,无需修改代码
- 团队协作:不同专家可以贡献各自领域的Skill
unsetunset五、文件组织与数据流unsetunset
5.1 目录结构
research-agent/├── research_agent/│ ├── agent.py # 主入口│ ├── prompts/ # 各Agent的系统提示词│ │ ├── lead_agent.txt│ │ ├── researcher.txt│ │ ├── data_analyst.txt│ │ └── report_writer.txt│ └── utils/│ ├── subagent_tracker.py # 追踪系统│ ├── transcript.py # 日志记录│ └── message_handler.py # 消息处理├── files/ # 运行时生成的文件│ ├── research_notes/ # Researcher输出│ ├── data/ # Data Analyst数据摘要│ ├── charts/ # 生成的图表│ └── reports/ # 最终PDF报告└── logs/ # 会话日志 └── session_YYYYMMDD_HHMMSS/ ├── transcript.txt # 人类可读的对话记录 └── tool_calls.jsonl # 结构化工具调用日志
5.2 数据流转
用户输入 ↓Lead Agent (Task工具) ↓Researcher-1, 2, 3, 4 (并行) ↓ (WebSearch → Write)files/research_notes/*.md ↓Data Analyst ↓ (Glob → Read → Bash → Write)files/data/data_summary.mdfiles/charts/*.png ↓Report Writer ↓ (Glob → Read → Bash)files/reports/report.pdf ↓返回给用户
5.3 日志输出示例
transcript.txt(人类可读):
You: Research quantum computing developmentsAgent: Researching 4 areas: hardware/qubits, algorithms/applications, industry players/investments, and challenges/timeline. Spawning researchers.[🚀 Spawning RESEARCHER-1: Quantum hardware and qubits][RESEARCHER-1] → WebSearch Input: query='quantum computing hardware 2024 statistics'[RESEARCHER-1] → WebSearch Input: query='qubit technology market size data'[RESEARCHER-1] → Write Input: file='quantum_hardware.md' (2847 chars)[🚀 Spawning RESEARCHER-2: Quantum algorithms][RESEARCHER-2] → WebSearch Input: query='quantum algorithms applications 2024'...
tool_calls.jsonl(结构化):
{"event":"tool_call_start","timestamp":"2025-12-16T10:30:15","agent_id":"RESEARCHER-1","tool_name":"WebSearch","tool_input":{"query":"quantum computing hardware 2024 statistics"}}{"event":"tool_call_complete","timestamp":"2025-12-16T10:30:18","agent_id":"RESEARCHER-1","tool_name":"WebSearch","success":true,"output_size":15234}{"event":"tool_call_start","timestamp":"2025-12-16T10:30:19","agent_id":"RESEARCHER-1","tool_name":"Write","tool_input":{"file_path":"files/research_notes/quantum_hardware.md","content":"..."}}{"event":"tool_call_complete","timestamp":"2025-12-16T10:30:19","agent_id":"RESEARCHER-1","tool_name":"Write","success":true}
unsetunset六、技术栈总览unsetunset
| 层级 | 技术选型 | 说明 |
|---|---|---|
| 核心框架 | Claude Agent SDK | Anthropic官方Agent开发框架 |
| 语言模型 | Claude 3.5 Haiku | 快速响应、成本优化 |
| 编程语言 | Python 3.10+ | 异步IO、类型提示 |
| 依赖管理 | uv | 快速的Python包管理器 |
| 数据可视化 | matplotlib | 图表生成 |
| PDF生成 | reportlab | 专业文档输出 |
| 环境配置 | python-dotenv | API密钥管理 |
| 日志格式 | JSONL | 结构化日志存储 |
unsetunset七、使用示例unsetunset
7.1 快速启动
# 安装依赖uv sync# 配置API密钥export ANTHROPIC_API_KEY="your-api-key"# 启动系统uv run python research_agent/agent.py
7.2 交互示例
You: Research electric vehicle market trends in 2024Agent: Breaking this into 4 research areas: battery technology, market trends, major manufacturers, and charging infrastructure. Spawning researchers now.[🚀 Spawning RESEARCHER-1: Battery technology developments][🚀 Spawning RESEARCHER-2: EV market trends and statistics][🚀 Spawning RESEARCHER-3: Major manufacturers and market share][🚀 Spawning RESEARCHER-4: Charging infrastructure growth][RESEARCHER-1] → WebSearch[RESEARCHER-2] → WebSearch[RESEARCHER-3] → WebSearch[RESEARCHER-4] → WebSearch...[🚀 Spawning DATA-ANALYST-1: Generate charts and data analysis][DATA-ANALYST-1] → Glob[DATA-ANALYST-1] → Read[DATA-ANALYST-1] → Bash Generating market share chart... Generating growth trend chart...[🚀 Spawning REPORT-WRITER-1: Synthesize research into PDF report][REPORT-WRITER-1] → Glob[REPORT-WRITER-1] → Read[REPORT-WRITER-1] → Bash Creating PDF report...Agent: Research complete. PDF report with charts saved to files/reports/electric_vehicle_market_report_20251216.pdf
7.3 斜杠命令(Slash Commands)
7.3.1 斜杠命令的实现原理
斜杠命令是Claude Agent SDK提供的"快捷指令"功能,通过在用户输入前加/前缀来触发预定义的研究模板。实现分为三个核心步骤:
1. 客户端(前端/用户界面)解析
用户的输入会被应用程序代码监听并解析:
# 工作原理示例(伪代码)user_input = input("You: ")# 识别斜杠命令if user_input.startswith('/'): # 提取命令名和参数 parts = user_input.split(' ', 1) command_name = parts[0][1:] # 去掉 '/' 前缀 arguments = parts[1] if len(parts) > 1else"" # 加载对应的命令模板 command_template = load_command(f".claude/commands/{command_name}.md") # 替换 $ARGUMENTS 占位符 actual_prompt = command_template.replace("$ARGUMENTS", arguments) # 发送到Claude API await client.query(prompt=actual_prompt)
2. 提取命令令牌和参数
- 命令名:如
/summarize→summarize - 命令参数:如
/translate to Spanish→ 参数为to Spanish
3. 模式转换
根据命令类型,决定发送给Claude API的请求类型:
| 用户输入示例 | 命令解析 | Claude API请求类型 |
|---|---|---|
/summarize the text below + [长文本] |
命令: summarize, 内容: [长文本] |
Prompt Engineering |
/translate to Spanish |
命令: translate, 语言: Spanish |
Prompt Engineering |
/search weather in Taipei |
命令: search, 查询: weather in Taipei |
Function Calling (Tool Use) |
7.3.2 命令定义结构
每个斜杠命令都是一个Markdown文件,存放在.claude/commands/目录下:
---description: 命令的简短描述argument-hint: "<参数提示>" # 可选---命令的详细指令内容可以使用 $ARGUMENTS 占位符来引用用户输入的参数
7.3.3 系统内置的5个斜杠命令
| 命令 | 参数 | 功能描述 | 研究策略 |
|---|---|---|---|
/research <topic> |
研究主题 | 启动专注研究 | 拆分2-4个子课题,并行研究 |
/competitive-analysis <company> |
公司/产品名 | 竞品分析 | 5维度分析:概览、产品、市场、动态、战略 |
/market-trends <industry> |
行业领域 | 行业趋势研究 | 7方面:现状、趋势、技术、行为、政策、投资、预测 |
/fact-check <claim> |
待核查声明 | 事实核查 | 5步验证:分解、搜索、评估、上下文、来源质量 |
/summarize |
无需参数 | 总结当前研究成果 | 读取所有研究笔记,生成执行摘要 |
7.3.4 命令详解
命令1: /research - 通用研究命令
---description: Start a focused research session on any topicargument-hint: "<topic>"---Research the following topic thoroughly: $ARGUMENTS## Research Strategy1. **Break Down the Topic** - Identify 2-4 key subtopics or angles to investigate - Ensure comprehensive coverage without redundancy2. **Parallel Research** - Spawn researcher subagents for each subtopic - Each researcher should conduct 3-7 web searches - Focus on authoritative, recent sources (2024-2025)3. **Source Quality** - Prioritize: academic papers, official docs, reputable news - Cross-reference claims from multiple sources4. **Output Requirements** - Save findings to files/research_notes/ - Include source URLs for citations5. **Synthesis** - After all research is complete, spawn report-writer - Create comprehensive synthesis in files/reports/
使用示例:
You: /research quantum computing applications in healthcareAgent: Researching quantum computing applications in healthcare.Breaking into 4 subtopics:1. Drug discovery and molecular simulation2. Medical imaging and diagnostics3. Genomics and personalized medicine4. Healthcare data security[Spawning 4 researcher subagents...]
7.3.5 自定义斜杠命令
创建新的斜杠命令非常简单:
# 1. 创建命令文件cat > .claude/commands/swot-analysis.md << 'EOF'---description: Perform SWOT analysis on a company or projectargument-hint: "<company or project name>"---Conduct a comprehensive SWOT analysis for: $ARGUMENTS## SWOT Framework### Strengths (内部优势)- What advantages does it have?- What does it do better than others?- What unique resources can it draw upon?### Weaknesses (内部劣势)- What could be improved?- Where are there fewer resources?- What are competitors doing better?### Opportunities (外部机会)- What trends could benefit it?- How can it turn strengths into opportunities?- What market gaps exist?### Threats (外部威胁)- What obstacles does it face?- What is the competition doing?- Are changing regulations a threat?## Research ApproachSpawn 4 researchers for parallel investigation of each SWOT dimension.## Output FormatCreate a 2x2 SWOT matrix with detailed bullet points in each quadrant.EOF# 2. 使用新命令# You: /swot-analysis Tesla
7.3.6 命令执行流程图
用户输入: /research quantum computing ↓[客户端解析] ├─ 命令名: research └─ 参数: quantum computing ↓[加载命令模板] 读取: .claude/commands/research.md ↓[参数替换]$ARGUMENTS → "quantum computing" ↓[生成完整Prompt]"Research the following topic thoroughly: quantum computing ## Research Strategy 1. Break Down the Topic... ..." ↓[发送到Claude API] await client.query(prompt=完整Prompt) ↓[Lead Agent执行] ├─ 分析主题 ├─ 拆分子课题 ├─ 启动Researcher子Agents ├─ 启动Data Analyst └─ 启动Report Writer ↓[返回结果] files/reports/quantum_computing_report_20251216.pdf
7.3.7 命令vs普通对话
| 对比维度 | 斜杠命令 | 普通对话 |
|---|---|---|
| 输入方式 | /command <args> |
自然语言描述 |
| 处理方式 | 加载预定义模板 | Lead Agent自由理解 |
| 一致性 | 高(固定框架) | 低(依赖Agent理解) |
| 灵活性 | 低(受模板限制) | 高(可自由表达) |
| 适用场景 | 重复性任务、标准化流程 | 探索性研究、复杂需求 |
| 学习成本 | 需要记住命令 | 无需记忆 |
7.3.8 最佳实践
- 命令命名:简短、直观、符合用户直觉
- 参数设计:尽量单参数,复杂需求用自然语言
- 模板结构:清晰的框架 + 详细的指导
- 输出规范:明确指定输出格式和文件位置
- 错误处理:在模板中包含边界情况的处理指导
示例:好的命令设计
---description: Compare two technologies or products side-by-sideargument-hint: "<tech1> vs <tech2>"---Compare the following: $ARGUMENTS## Comparison Dimensions1. Performance benchmarks2. Cost and pricing3. Ease of use4. Ecosystem and community5. Use cases and best fit## Output FormatCreate a comparison table with scores (1-10) for each dimension.Include a "Winner" recommendation with rationale.
unsetunset八、核心优势与挑战unsetunset
8.1 系统优势
1. 并行执行效率高
- 多个Researcher同时工作,相比串行执行节省60-70%时间
- 实测:4个子课题并行研究耗时约2-3分钟,串行需8-10分钟
2. 职责分离清晰
- 每个Agent只使用必要的工具,降低误操作风险
- Lead Agent不做具体工作,专注于编排,避免角色混淆
3. 完整的可追溯性
- Hook机制记录每个工具调用的输入输出
- JSONL格式便于后续分析和审计
- 可精确定位哪个子Agent在何时做了什么
4. Prompt工程的最佳实践
- 明确的约束规则(CRITICAL RULES)
- 详细的工作流程(STEP BY STEP)
- 丰富的示例(GOOD vs BAD)
- 质量标准(至少10-15个数据点)
8.2 面临的挑战
1. 成本控制
- 多Agent并行意味着多次API调用
- 需要在并行度和成本间权衡
- 当前使用Haiku模型降低成本,但牺牲了部分能力
2. 错误传播
- 如果某个Researcher失败,可能影响后续Data Analyst
- 需要增强错误处理和重试机制
3. 数据质量依赖
- Data Analyst和Report Writer的质量完全依赖Researcher的输出
- 如果Researcher没找到足够数据,后续环节会受影响
4. 调试复杂度
- 多Agent并行执行时,问题定位较困难
- 需要依赖详细的日志和追踪系统
unsetunset九、工程经验总结unsetunset
9.1 Prompt设计要点
- 明确约束优先:在Prompt开头用
**CRITICAL**标注不可违反的规则 - 流程步骤化:用
STEP 1, STEP 2...清晰定义工作流程 - 正反示例:提供GOOD和BAD的对比示例,比单纯描述更有效
- 量化标准:用具体数字定义质量要求(如"至少10-15个数据点")
- 工具使用模式:提供完整的代码模板,减少Agent试错
9.2 架构设计建议
- 单一职责原则:每个Agent只做一件事,通过组合实现复杂功能
- 工具权限最小化:只给Agent必需的工具,避免滥用
- 异步优先:充分利用并行能力,但要控制并发度
- 日志分层:人类可读的transcript + 结构化的JSONL,满足不同需求
- 文件作为通信媒介:Agent间通过文件传递数据,简单可靠
9.3 调试技巧
- 善用Hook:在开发阶段打印所有工具调用,快速定位问题
- 检查中间产物:查看
files/research_notes/等目录,验证每个阶段的输出 - 逐步测试:先测试单个Agent,再测试完整流程
- 保留会话日志:每次运行的日志都保存,便于复现问题
unsetunset十、未来展望unsetunset
10.1 可能的优化方向
1. 动态Agent数量
- 根据任务复杂度自动决定启动几个Researcher
- 简单任务1-2个,复杂任务4-6个
2. 增量式报告
- 不等所有Researcher完成,先完成的数据先生成部分报告
- 提升用户体验,减少等待时间
3. 知识库集成
- 将历史研究结果存入向量数据库
- 新任务先检索已有知识,减少重复研究
4. 多模态支持
- 支持图片、视频等多媒体内容的研究
- 生成包含多媒体的富文本报告
5. 人机协作模式
- 在关键决策点(如任务分解)请求用户确认
- 允许用户中途调整研究方向
10.2 扩展应用场景
- 竞品分析:自动收集竞品信息并生成对比报告
- 投资研究:分析公司财报、行业趋势,生成投研报告
- 学术文献综述:检索论文、提取关键发现、生成综述
- 政策影响分析:研究政策变化对行业的影响
unsetunset十一、总结unsetunset
Claude Agent SDK Deep Research展示了如何通过精心设计的多Agent协作系统,实现复杂任务的自动化处理。核心要点包括:
- 架构设计:指挥官-执行者模式,职责分离,并行执行
- 追踪机制:Hook + parent_tool_use_id实现全链路追踪
- Prompt工程:明确约束、详细流程、正反示例、量化标准
- Skill技能包:知识库复用、按需加载、降低Prompt复杂度
- 数据流转:文件作为媒介,各Agent按序处理
- 工程实践:异步优先、工具权限最小化、日志分层
这套系统不仅能够高效完成研究任务,更重要的是提供了一个可扩展、可追溯、可维护的多Agent协作框架。通过调整Agent定义和Prompt,可以快速适配不同的应用场景。
在AI应用开发中,技术选型固然重要,但更关键的是系统设计和工程实践。希望这篇文章能为你在构建类似系统时提供一些参考和启发。
项目地址:https://github.com/anthropics/claude-agent-sdk-demos.git
核心依赖:claude-agent-sdk >= 0.1.0
运行环境:Python 3.10+
模型选择:DeepSeekV3.2
unsetunset📚 完整代码unsetunset
- 项目地址: https://github.com/apconw/sanic-web
🌈 项目亮点
- ✅ 集成 MCP 多智能体架构
- ✅ 支持 Dify / LangChain / LlamaIndex / Ollama / vLLM / Neo4j/Cluade Agent
- ✅ 前端采用 Vue3 + TypeScript + Vite5,现代化交互体验
- ✅ 内置 ECharts / AntV 图表问答 + CSV 表格问答
- ✅ 支持对接主流 RAG 系统 与 Text2SQL 引擎
- ✅ 轻量级 Sanic 后端,适合快速部署与二次开发
- ✅ 项目已被蚂蚁官方推荐收录
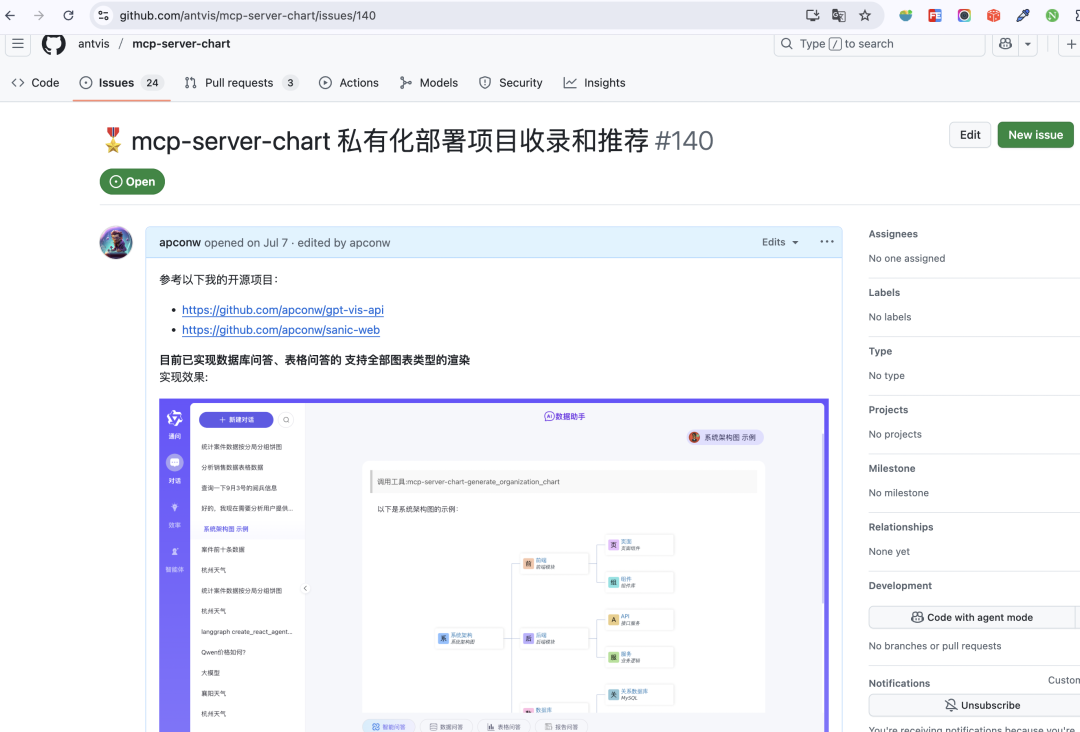
AntV
运行效果:
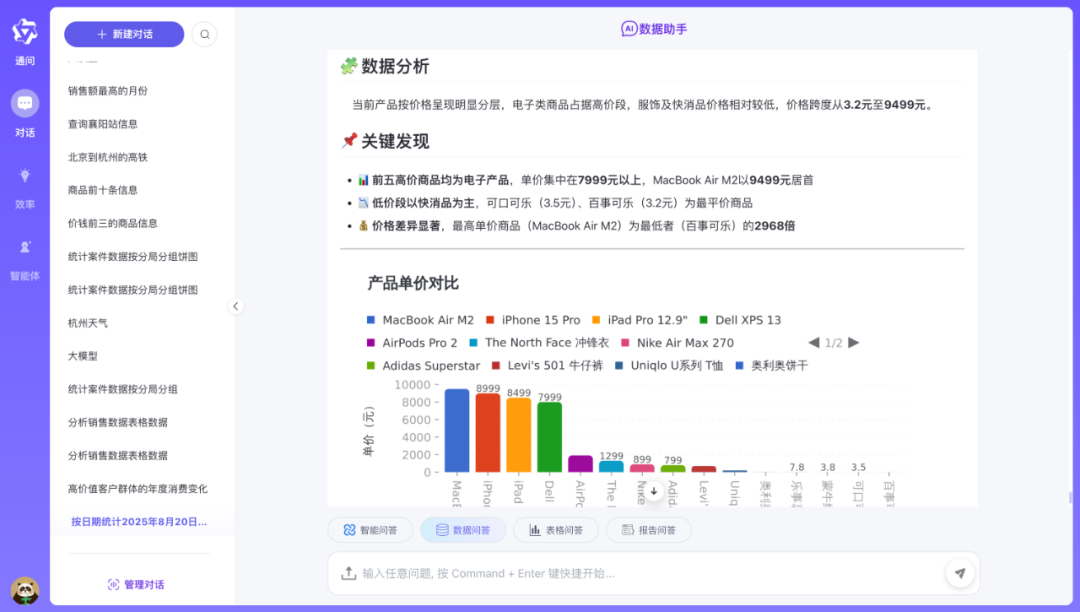
数据问答
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
完整的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
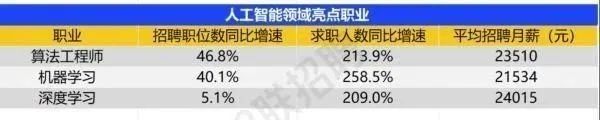
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程⑤⑥
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 10
10 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)