
【人工智能】【MCP】 ② MCP 协议深度实践:9 种企业级架构设计模式与落地指南
摘要: MCP(Model Context Protocol)作为AI领域的通用接口标准,通过标准化协议将模型与外部能力的集成复杂度从M×N降至M+N,显著提升开发效率与生态扩展性。本文系统解析了9种企业级MCP架构模式,包括全本地私有化、智能检索增强、多智能体协同等,涵盖金融、医疗、语音交互等场景。每种模式通过可视化流程图展示架构逻辑,并配套技术栈与适用场景分析。最后提供业务场景与架构模式的匹配
📖目录
一、引言
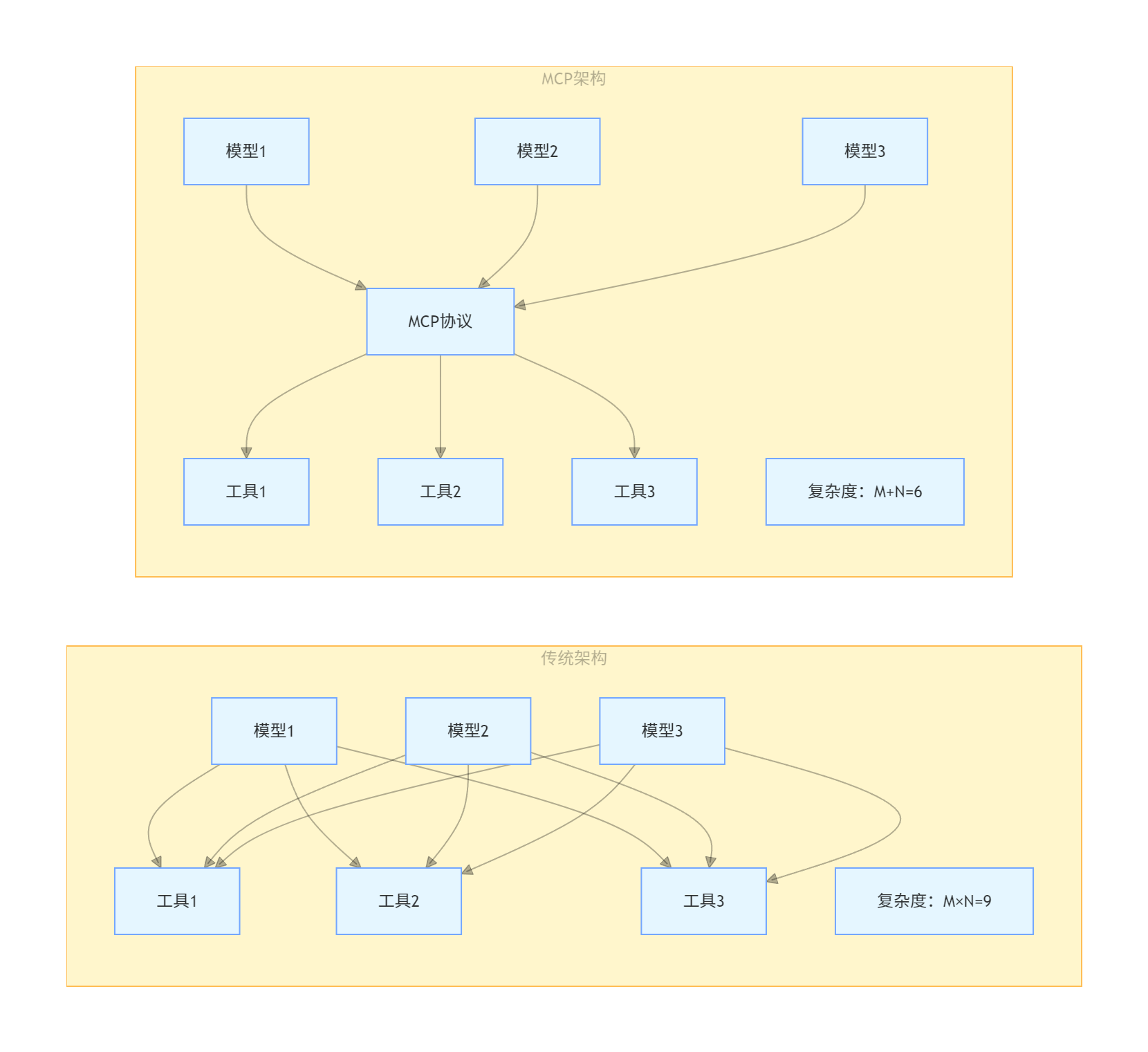
在大模型应用爆发的当下,AI 生态面临着工具、数据源与模型之间的 “连接困境”—— 传统架构中 N 个模型与 M 个外部能力的集成需付出 M×N 的适配成本,严重制约了开发效率与生态扩展性。MCP(Model Context Protocol)作为 AI 领域的 “通用接口标准”,通过标准化协议将集成复杂度优化为 M+N,成为打破数据孤岛、实现能力互通的核心支撑。本文将深度拆解 9 种企业级 MCP 架构设计模式,以极简可视化图表呈现核心逻辑,结合实际业务场景剖析选型要点,助力开发者快速落地高质量 MCP 应用。
二、MCP 协议的核心价值与生态定位
MCP 协议的本质是为 AI 模型与外部能力(工具、数据源、服务)建立标准化的双向通信链路,其核心价值体现在三个维度:
-
解耦集成逻辑:替代传统硬编码集成方式,通过统一接口实现模型与各类外部能力的灵活对接
-
降低开发成本:将多对多的集成复杂度转化为 “模型 - MCP - 外部能力” 的线性结构,适配效率提升 50% 以上
-
增强生态扩展性:支持本地部署与云端服务双重模式,开发者可快速接入生态资源或共享自有能力
从技术架构来看,MCP 生态由五大核心组件构成:MCP Host(大模型应用 / 智能体)、MCP Client(通信中介)、MCP Server(能力提供者)、数据源(外部资源集合)、MCP Hub(服务托管平台),各组件通过标准化协议实现高效协同。
传统架构 vs MCP 架构对比图
三、9 种企业级 MCP 架构设计模式详解
模式1:全本地私有 MCP Client
核心定位:满足数据隐私要求极高的场景,所有交互均在本地环境完成,不涉及外部网络传输。
架构流程图
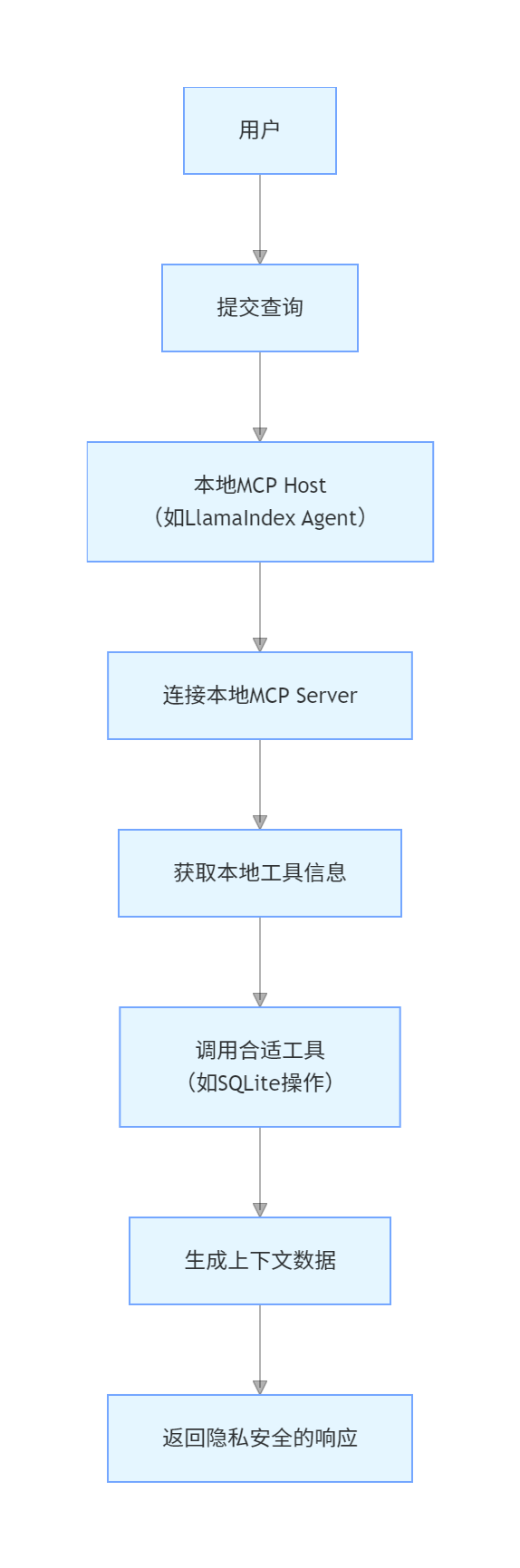
核心特性与技术栈
-
数据全程本地化,杜绝隐私泄露风险
-
无网络依赖,响应速度快(毫秒级)
-
技术栈:LlamaIndex(智能体构建)、Ollama(本地 LLM 部署)、SQLite(本地数据库)、LightningAI(开发托管)
适用场景:金融核心数据处理、医疗隐私信息分析、涉密单位内部工具调用
模式2:MCP 驱动的智能检索增强(Agentic RAG)
核心定位:融合向量数据库与网络搜索能力,解决静态知识库更新不及时、覆盖范围有限的问题。
架构流程图
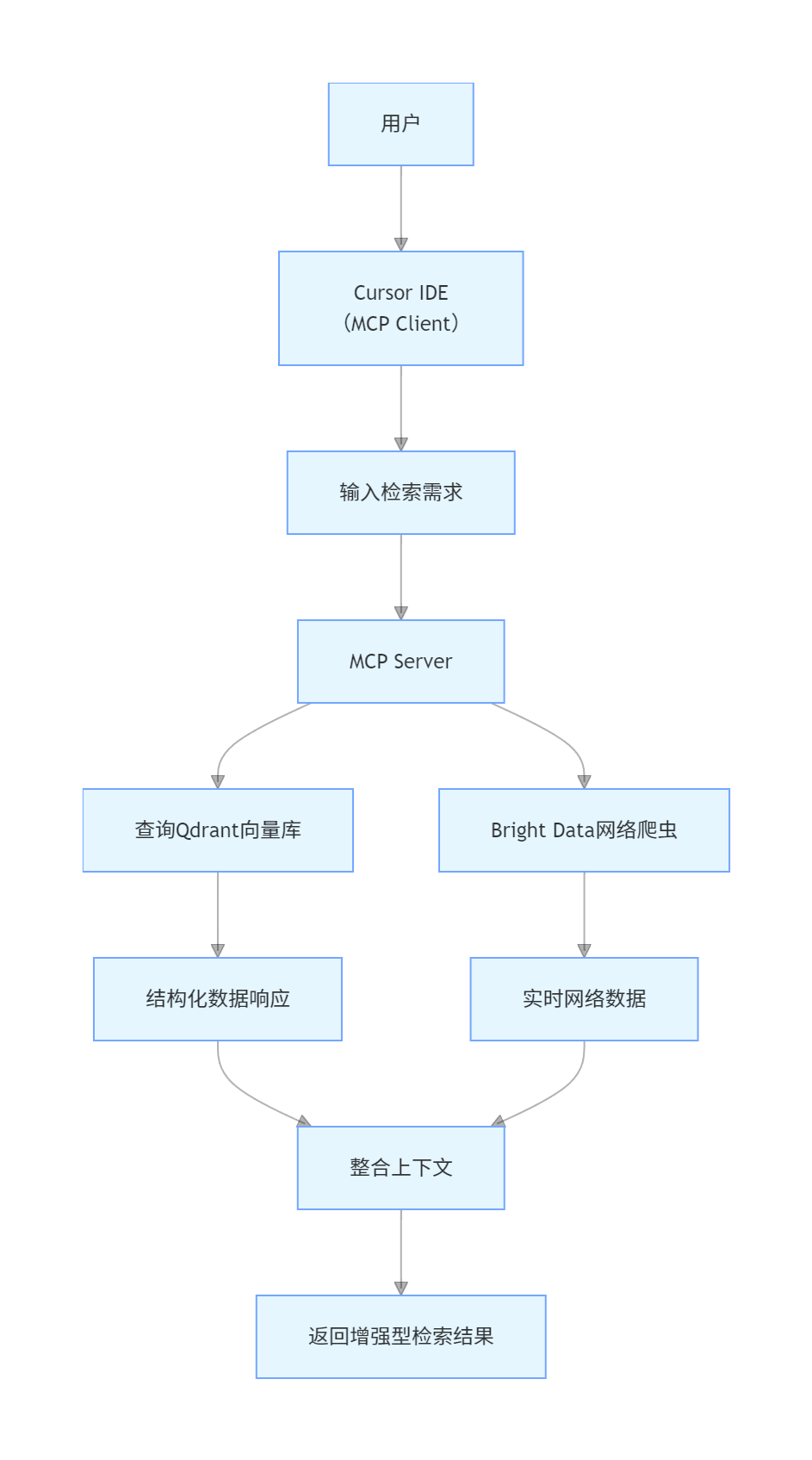
核心特性与技术栈
-
动态切换检索源:优先从向量库获取精准结果,缺失时自动触发网络搜索
-
支持大规模数据抓取与高效向量检索结合
-
技术栈:Qdrant(向量数据库)、Bright Data(网络爬虫)、Cursor(MCP Client)、MCP Tool(检索工具封装)
适用场景:行业动态分析、学术文献检索、产品市场调研、实时信息聚合
模式3:MCP 协同多智能体架构
核心定位:通过 MCP 协议实现多智能体分工协作,解决复杂业务场景下的专业化处理需求。
架构流程图
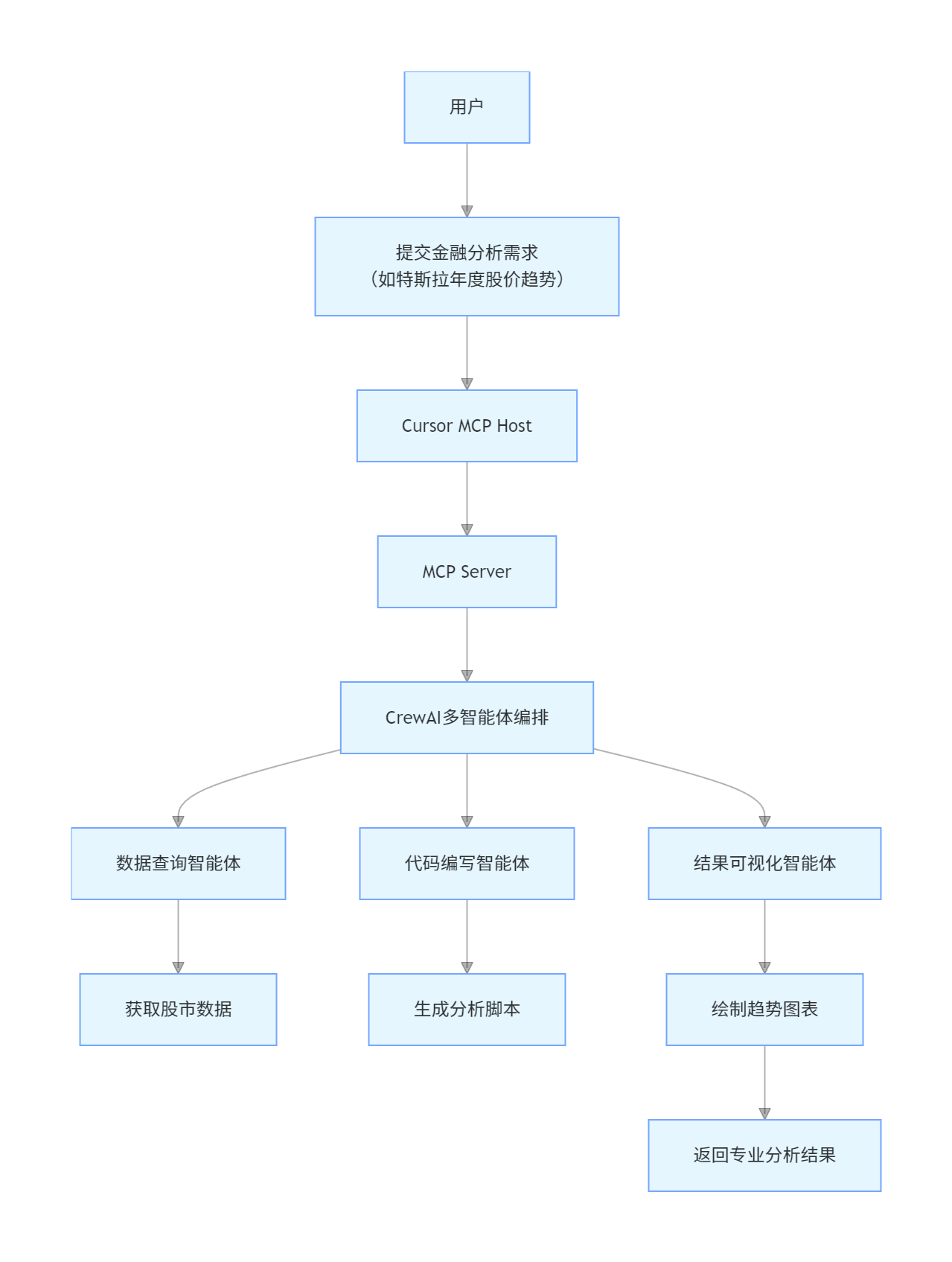
核心特性与技术栈
-
智能体各司其职:数据采集、代码执行、结果可视化分工协作
-
基于 MCP 协议实现智能体间上下文共享与能力调用
-
技术栈:CrewAI(多智能体编排)、Ollama(本地 DeepSeek-R1 部署)、Cursor(MCP Host)、Python(脚本执行)
适用场景:金融市场分析、企业经营数据洞察、复杂业务流程自动化、多步骤数据分析任务
模式4:语音交互型 MCP 智能体
核心定位:以语音为交互入口,结合多工具调用能力,打造自然流畅的语音助手体验。
架构流程图
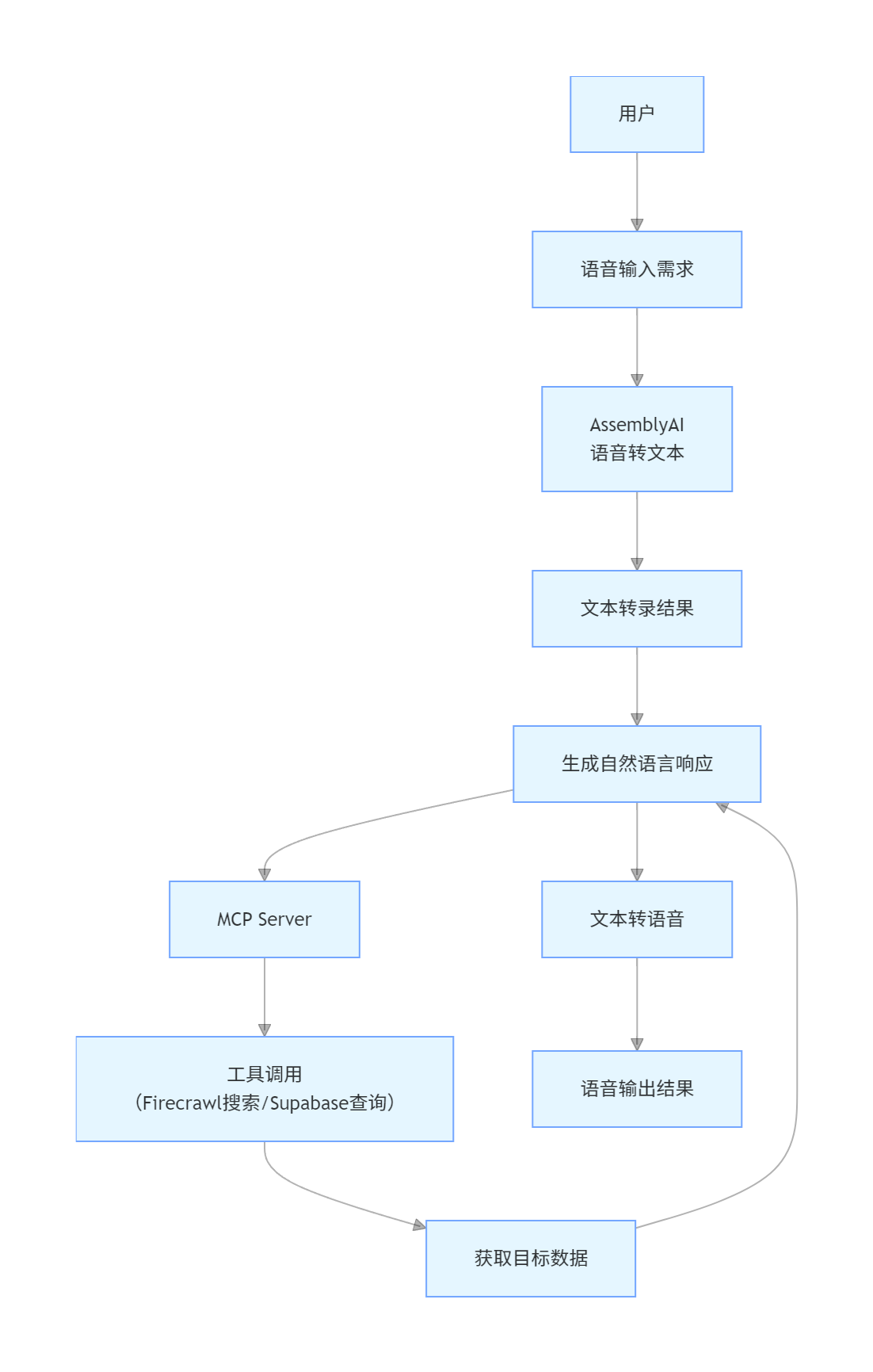
核心特性与技术栈
-
端到端语音交互:支持复杂语义理解与多轮对话
-
自动匹配工具能力:根据语音需求智能选择搜索、数据库查询等工具
-
技术栈:AssemblyAI(语音转文本)、Qwen3(LLM)、Firecrawl(网络搜索)、Supabase(数据库)、Livekit(实时协调)
适用场景:智能车载助手、智能家居控制、无障碍访问工具、语音驱动的数据分析
模式5:统一数据源接入 MCP Server
核心定位:构建统一数据接入网关,支持通过自然语言访问多类型数据源,打破数据孤岛。
架构流程图
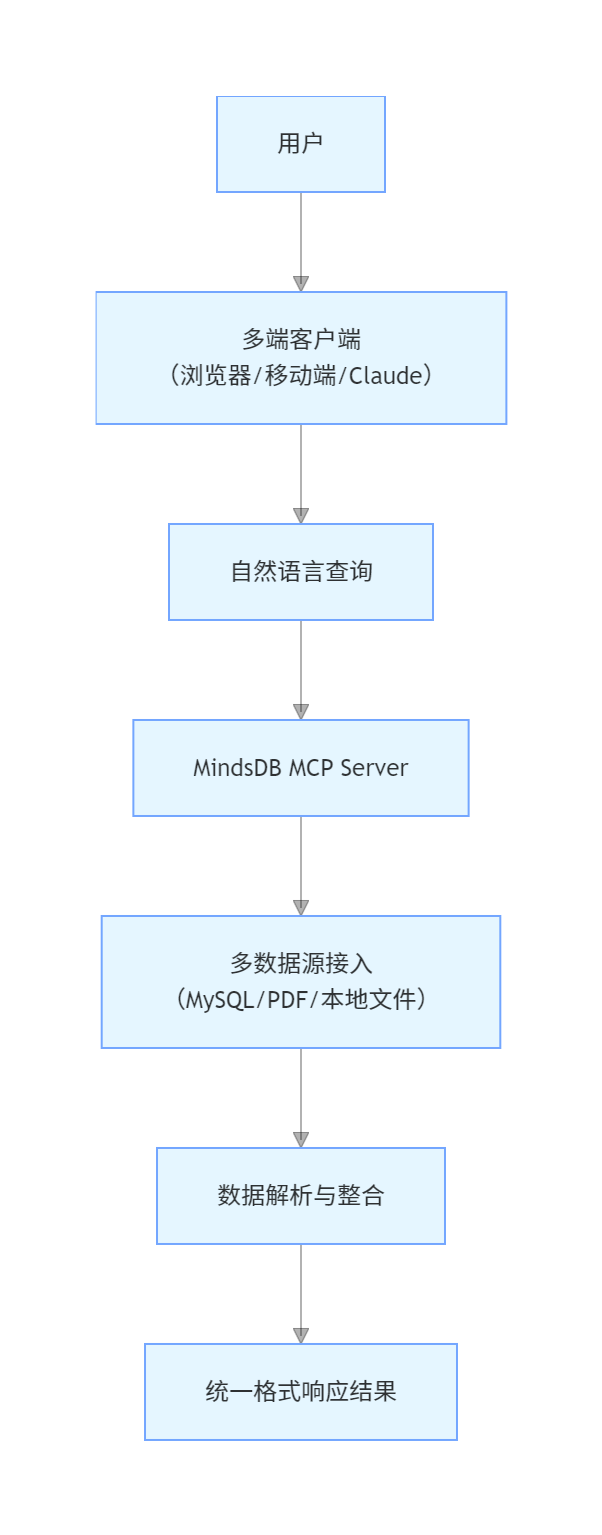
核心特性与技术栈
-
支持 200 + 数据源接入,无需关注底层数据格式差异
-
自然语言直接查询:无需编写 SQL 或其他查询语句
-
技术栈:MindsDB(MCP Server 核心)、Cursor(MCP Host)、Docker(服务容器化)、MySQL(关系型数据库)
适用场景:企业多系统数据整合、跨部门数据查询、非技术人员数据访问、多格式文档数据提取
模式6:跨应用共享内存 MCP 架构
核心定位:解决多 MCP Host 间上下文不互通的问题,实现跨应用的状态共享与协作。
架构流程图
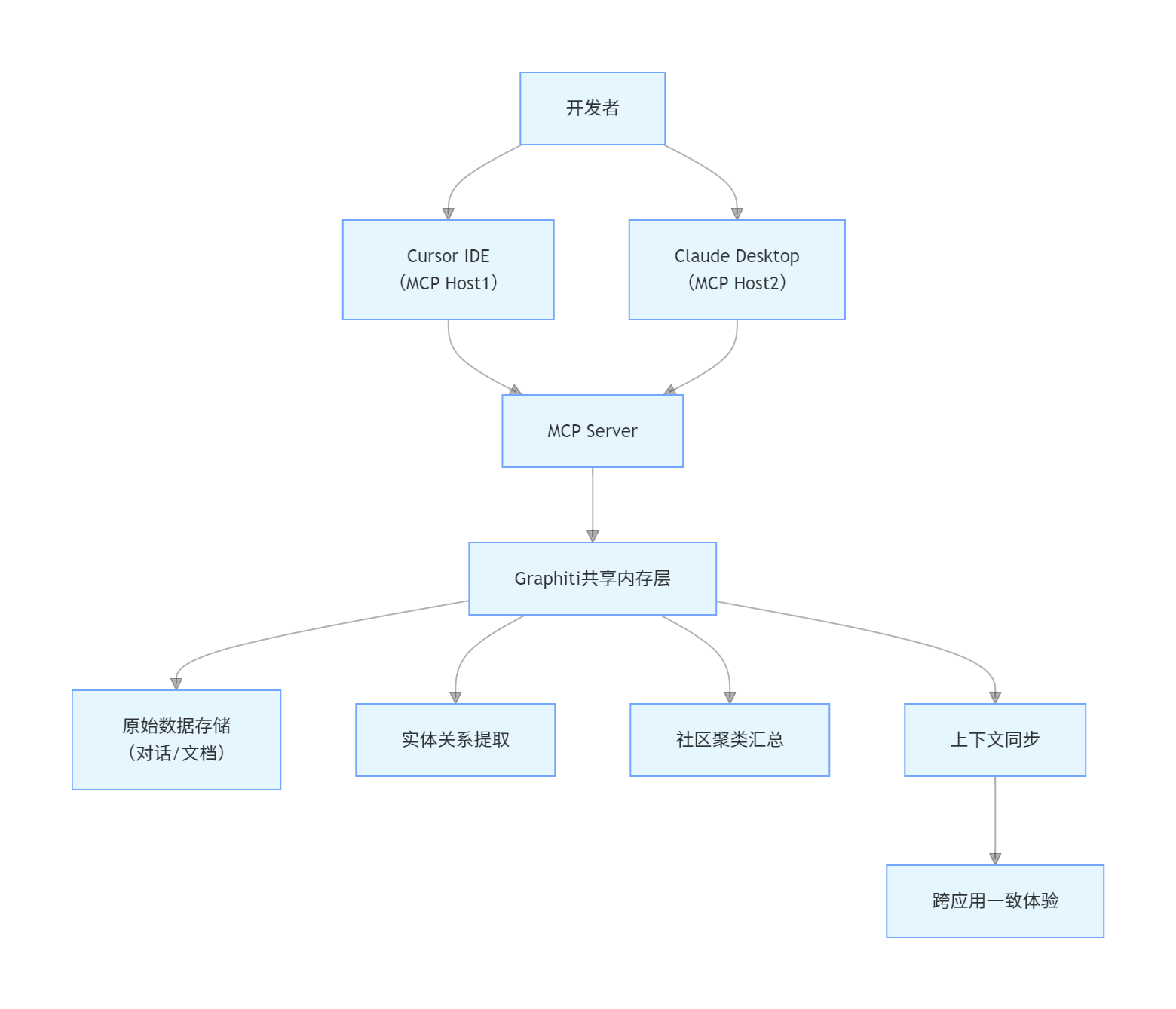
核心特性与技术栈
-
三层内存结构:支持原始数据、实体关系、聚类汇总的多维度存储
-
实时同步多应用上下文,避免重复操作与信息丢失
-
技术栈:Graphiti(共享内存核心)、Cursor/Claude(多 MCP Host)、Docker(部署容器)、JSON(数据序列化)
适用场景:多工具协同开发、跨平台工作流、团队协作中的上下文共享、多应用联动操作
模式7:复杂文档处理 MCP-RAG
核心定位:针对表格、图表、复杂布局的专业文档,提供高精度内容提取与检索能力。
架构流程图
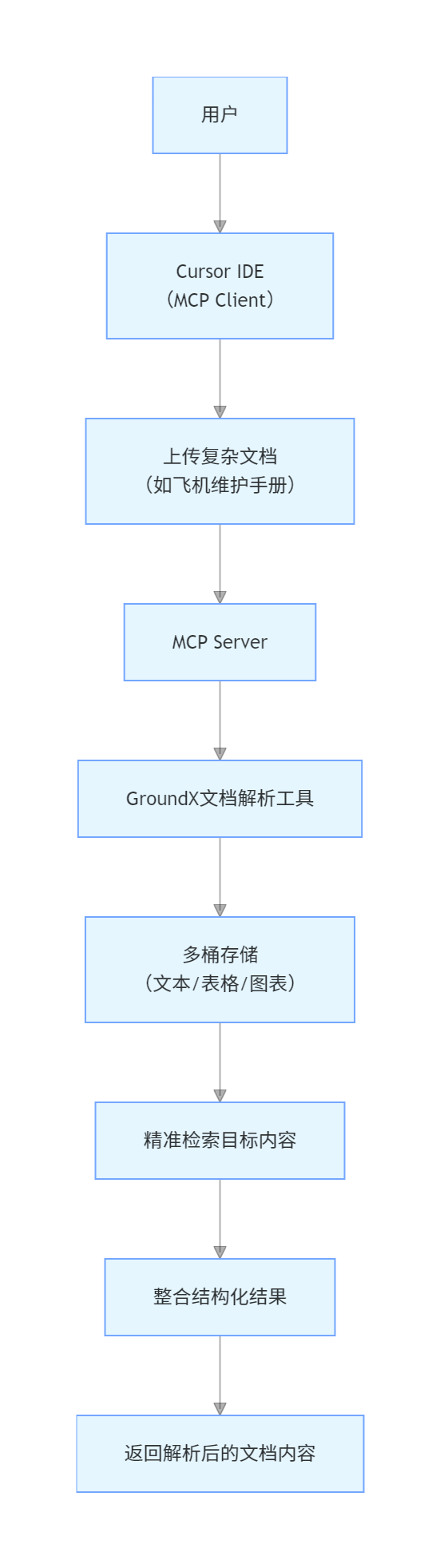
核心特性与技术栈
-
支持复杂格式解析:表格提取、图表识别、多布局文档结构化处理
-
高精度内容检索:可定位到具体章节、表格单元格、图表数据
-
技术栈:EyelevelAI GroundX(复杂文档处理)、Cursor IDE(MCP Client)、分布式存储(多类型内容存储)
适用场景:专业手册查询、学术论文解析、商业报表分析、工程图纸信息提取
模式8:本地合成数据生成 MCP 服务
核心定位:在本地环境生成高仿真合成数据,满足模型训练、功能测试的数据需求,同时规避隐私风险。
架构流程图
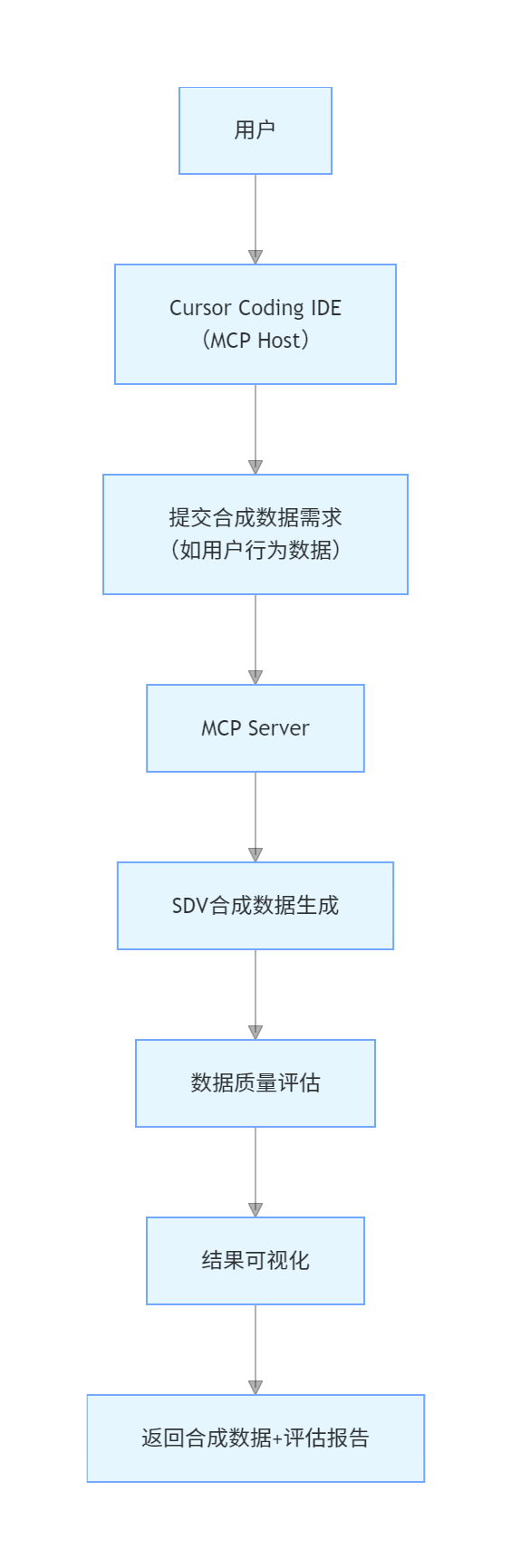
核心特性与技术栈
-
100% 本地生成:数据不流出本地环境,保障隐私安全
-
高仿真度:基于机器学习模拟真实数据分布与关联关系
-
技术栈:SDV(合成数据生成库)、Cursor IDE(MCP Host)、Data Vault(数据存储)、可视化工具(结果展示)
适用场景:模型训练数据补充、隐私数据脱敏替代、功能测试数据集生成、数据分析算法验证
模式九:深度研究型多智能体 MCP 框架
核心定位:模拟学术研究流程,通过多智能体协同完成深度调研、分析与报告生成,支持引用溯源。
架构流程图
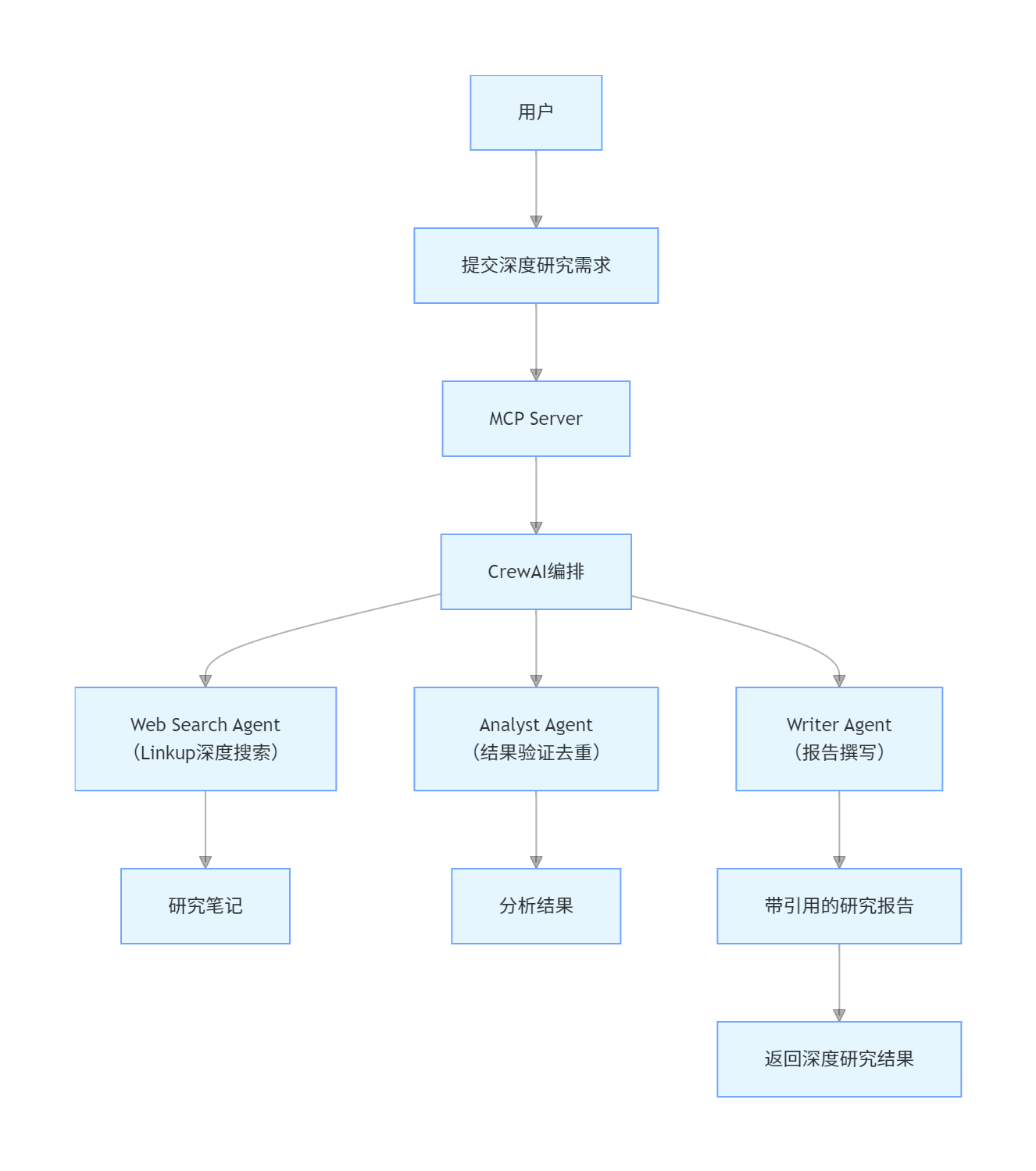
核心特性与技术栈
-
标准化研究流程:搜索 - 验证 - 分析 - 撰写全流程自动化
-
支持引用溯源:所有结论均可关联原始信息来源
-
技术栈:Linkup(深度网络搜索)、CrewAI(多智能体编排)、Ollama(本地 LLM)、Cursor(MCP Host)
适用场景:学术研究辅助、行业趋势深度分析、市场调研报告生成、技术方案可行性论证
四、架构选型指南:业务场景与模式匹配
| 业务类型 | 核心需求 | 推荐架构模式 | 关键考量因素 |
|---|---|---|---|
| 数据密集型 | 大规模数据检索、实时数据获取 | 模式二(Agentic RAG) | 检索速度、数据覆盖范围、更新频率 |
| 多步骤协作型 | 专业化分工、复杂流程自动化 | 模式三(多智能体)/ 模式九(深度研究) | 智能体协同效率、任务拆解合理性 |
| 隐私敏感型 | 数据安全、本地处理 | 模式一(全本地 Client)/ 模式八(本地合成数据) | 隐私保护级别、无网络依赖需求 |
| 跨应用协作型 | 上下文共享、多工具联动 | 模式六(共享内存) | 同步延迟、数据一致性 |
| 文档处理型 | 复杂格式解析、精准检索 | 模式七(复杂文档 RAG) | 解析精度、检索准确率 |
| 多源数据整合型 | 统一访问入口、多格式兼容 | 模式五(统一 MCP Server) | 数据源适配能力、查询便捷性 |
| 语音交互型 | 自然交互、语音驱动 | 模式四(语音智能体) | 语音识别准确率、响应速度 |
五、总结与实践建议
MCP 协议的核心价值在于 “连接” 与 “解耦”,9 种架构模式本质是基于不同业务场景对 “模型 - 工具 - 数据” 关系的优化组合。在实际落地过程中,建议遵循以下原则:
-
需求先行:明确业务的核心诉求(如隐私保护、检索效率、协作需求),再选择匹配的架构模式
-
技术栈适配:优先选择团队熟悉的技术栈,降低落地成本(如向量库可选 Qdrant/Chroma,LLM 可替换为本地 / 云端版本)
-
渐进式落地:从简单场景入手(如先实现单一数据源的 MCP 接入),再逐步扩展复杂能力
-
可扩展性设计:预留接口扩展空间,支持后续新增工具、数据源或智能体类型
六、福利资源
如果需要获取架构选型思维导图,欢迎在评论区留言交流!也可分享你的具体业务场景,一起探讨最适合的 MCP 架构方案~
要不要我帮你整理一份MCP 架构落地 checklist,包含环境搭建、核心组件配置、性能优化、测试验证等关键步骤?
更多推荐


 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)