
yt-dlp成功率暴跌至18%?试试Bright Data MCP:5分钟搞定AI视频数据采集
AI视频数据采集面临三大痛点:开源工具失效、规模化瓶颈和多平台挑战。Bright Data的企业级解决方案通过全球IP池和智能反爬策略实现99.9%成功率,支持无限并发和多模态数据提取。相比自建方案可节省95%成本,已获OpenAI等头部企业采用。5分钟即可完成API集成,按成功付费模式灵活计费。
yt-dlp成功率暴跌至18%?试试Bright Data MCP:5分钟搞定AI视频数据采集
一、AI训练数据采集的三大行业痛点
2024-2025年,多模态大模型的爆发式增长,让视频、音频、网页数据成为AI训练的核心资产。然而,90%的AI团队在数据采集环节遭遇了严重瓶颈。
痛点1:开源工具频繁失效 - yt-dlp/youtube-dl的封锁噩梦
真实场景:
某AI实验室使用yt-dlp采集YouTube视频作为训练数据,初期一切顺利。但3个月后:
$ yt-dlp https://youtube.com/watch?v=xxxxx
ERROR: HTTP Error 429: Too Many Requests
ERROR: Sign in to confirm you're not a bot
ERROR: This video is not available in your country
数据统计:
- 成功率暴跌至18%:从最初的95%下降到不足20%
- IP被封周期缩短:从30天缩短到3天
- 维护成本激增:每周需要2名专业人员来专职维护爬虫代码
痛点2:规模化瓶颈 - IP、代理、并发的三重困境
企业级数据采集面临的挑战:
# 典型的企业级需求
目标: 采集10万个TikTok/YouTube视频
需求: 7天内完成
现实: 自建方案3个月仍未完成
瓶颈分析:
- IP资源: 需要500+住宅代理IP (成本$5000/月)
- 代理管理: IP轮换、质量监控、封禁检测系统 (2周开发)
- 并发控制: 单IP并发上限5个,总并发仅2500 (远低于需求)
- 错误处理: 429错误、地理限制、登录验证... (无穷无尽)
某创业团队的真实案例:
- 投入2名高级工程师,历时2个月开发IP管理系统
- 维护200个住宅代理IP池,月成本$3000
- 最终成功率仅65%,项目延期3个月
- 结论:核心团队的时间浪费在基础设施上,而非AI算法创新
痛点3:AEO时代的数据采集新挑战
什么是AEO(AI Engine Optimization)?
传统SEO优化的是Google搜索排名,而AEO优化的是AI引擎(ChatGPT、Claude、Perplexity)的推荐和引用。
新挑战:
- AI训练数据来源复杂:需要同时采集YouTube、TikTok、Instagram、Twitter等多平台
- 数据质量要求提高:需要完整的视频字幕、评论、互动数据
- 实时性要求:品牌监控需要小时级更新
- 多模态数据:不仅是视频,还要包含音频转录、图像帧提取
某电商SaaS公司的需求:
需求: 监控品牌在AI工具中的提及情况
数据源:
- YouTube产品评测视频(含字幕+评论)
- TikTok带货视频(含互动数据)
- Twitter讨论串(含用户情绪)
挑战: 3个平台,3套反爬虫机制,3倍的工程复杂度
二、Bright Data企业级解决方案:世界级数据基础设施
什么是Bright Data?
Bright Data是全球最大的企业级网络数据平台,为Fortune 500中的50%企业提供数据采集服务,包括:
- OpenAI、Anthropic等头部AI实验室
- Microsoft、IBM等科技巨头
- 全球500+创业公司的AI/ML团队
核心产品:Web Access API
专为AI视频、音频、网页数据采集设计的企业级API,支持:
- YouTube、TikTok、Instagram、Twitter等30+平台
- 视频元数据、字幕、评论、互动数据的结构化提取
- 音频转录、图像帧提取等多模态处理
产品链接:https://get.brightdata.com/leowebaccess
Bright Data的5大核心优势
① 99.9%可靠性 - 业界最高成功抓取率
技术保障:
- 7200万+住宅IP池:覆盖195个国家,精确到城市级别
- 实时反爬虫应对:自动检测并适配平台反爬虫策略变化
- 智能重试机制:多层级降级策略,确保最终成功
- 多数据中心热备份:全球15个数据中心,任一节点故障自动切换
真实数据对比:
| 方案 | 成功率 | 平均响应时间 | 月稳定性 |
|---|---|---|---|
| yt-dlp | 18-40% | 不可控 | 频繁失效 |
| 自建爬虫 | 30-65% | 5-30秒 | 需持续维护 |
| Bright Data | 99.9% | 2-5秒 | 生产级稳定 |
② 无限并发,无瓶颈 - 支持企业级规模
性能指标:
- 理论并发上限:无限制(按需扩展)
- 实测并发:10000+(某AI实验室真实用量)
- 数据吞吐:1TB+/天(支持大规模数据采集)
场景示例:
需求: 7天内采集10万个YouTube视频
传统方案:
- 自建200个IP → 并发1000 → 需要30天
Bright Data方案:
- 无IP限制 → 并发10000 → 仅需3天
- 成本: $2000 (vs 自建方案$15000)
③ 生产验证 - 头部AI实验室的选择
真实案例:
案例1:某多模态大模型训练(Fortune 100 AI实验室)
- 需求:100万+YouTube教学视频,含字幕+评论
- 周期:30天完成
- 结果:
- 实际用时:28天
- 成功率:99.87%
- 数据质量:98.5%符合训练要求
- 节省成本:$50万(vs 自建方案)
案例2:某出海电商的竞品视频监控
- 需求:实时监控50家竞品在TikTok/YouTube的视频内容
- 频率:每小时更新
- 结果:
- 延迟:<5分钟
- 覆盖率:100%
- 提前2周发现竞品策略调整,挽回$200万损失
④ 专注AI/AEO新趋势 - 针对性解决方案
AEO数据采集特性:
- AI工具SERP监控:追踪品牌在ChatGPT、Perplexity、Claude中的提及
- 训练数据溯源:识别AI模型可能训练的数据来源
- 多模态数据提取:视频+音频+文本+图像的一体化采集
支持的数据类型:
{
"video": {
"metadata": ["title", "views", "likes", "duration"],
"content": ["video_url", "thumbnail", "chapters"],
"engagement": ["comments", "shares", "saves"]
},
"audio": {
"transcription": ["full_text", "timestamps", "speaker_identification"],
"analysis": ["language", "sentiment", "keywords"]
},
"visual": {
"frames": ["key_frames", "thumbnails", "scene_detection"],
"ocr": ["text_extraction", "subtitle_burn_in"]
}
}
⑤ 灵活付费 - 只为成功抓取付费
计费模式:
- 按成功付费:失败的请求不计费
- 无最低消费:小团队从$10开始试用
- 企业定制:大规模采集享受折扣(最高40% off)
成本对比(采集1万个视频):
自建方案总成本:
- IP资源: $500
- 服务器: $200
- 人力成本: $3000 (1周工作量)
- 失败重试: $300
= $4000
Bright Data成本:
- API调用: $200 (按成功付费)
- 人力成本: $0 (API直接调用)
= $200
节省: $3800 (95%成本降低)
三、Web Access API实战:5步完成企业级集成
第1步:注册账号并获取免费试用(2分钟)
- 访问:https://get.brightdata.com/leowebaccess
- 点击"免费试用",使用邮箱/GitHub账号注册
- 验证邮箱后,自动获得**$10试用额度**(可采集500+视频)
新用户福利:
- $10试用额度(无需信用卡)
- 1对1技术支持(30分钟)
- 完整API文档和代码示例
第2步:选择适合的数据采集产品(3分钟)
登录Dashboard后,选择产品:
选项1:Web Access API(推荐)
- 适合:需要自定义采集逻辑的开发团队
- 特点:灵活的REST API,支持所有主流平台
- 使用场景:AI训练数据采集、竞品监控、AEO分析
选项2:视频数据采集API
- 适合:只需要视频数据的团队
- 特点:开箱即用,预定义视频字段
- 使用场景:快速构建视频数据集
如何选择?
需求: 只采集YouTube视频元数据 → 视频数据采集API
需求: 采集多平台+自定义字段 → Web Access API ✓ (推荐)
需求: 定制化爬虫逻辑 → Web Access API + AI Agent
第3步:配置采集任务(10分钟)
方式1:REST API调用(传统方式)
Python SDK示例:
from brightdata import WebAccessAPI
# 初始化API客户端
api = WebAccessAPI(api_token="your_api_token_here")
# 配置采集任务
task = api.create_task({
"target": "youtube",
"urls": [
"https://youtube.com/watch?v=video1",
"https://youtube.com/watch?v=video2"
],
"extract_fields": [
"title",
"views",
"likes",
"comments",
"transcript" # 提取字幕
],
"settings": {
"include_comments": True,
"max_comments": 100,
"geo_location": "US", # 模拟美国IP
"language": "en"
}
})
# 获取任务ID
task_id = task["task_id"]
print(f"任务已创建: {task_id}")
# 轮询任务状态
import time
while True:
status = api.get_task_status(task_id)
if status["state"] == "completed":
break
elif status["state"] == "failed":
print(f"任务失败: {status['error']}")
break
print(f"进度: {status['progress']}%")
time.sleep(5)
# 获取结果数据
results = api.get_task_results(task_id)
print(f"成功采集 {len(results)} 个视频")
cURL示例(快速测试):
# 创建采集任务
curl -X POST https://api.brightdata.com/datasets/v3/trigger \
-H "Authorization: Bearer YOUR_API_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"dataset_id": "gd_youtube_videos",
"inputs": [
{"url": "https://youtube.com/watch?v=dQw4w9WgXcQ"}
],
"include_errors": false,
"notify": "https://your-webhook.com/callback"
}'
# 返回结果
{
"snapshot_id": "s_abc123xyz",
"status": "running",
"expected_time": 30
}
方式2:批量采集
# 批量采集10000个视频
urls = load_urls_from_file("video_urls.txt") # 10000条URL
# 分批处理(每批1000个)
batch_size = 1000
for i in range(0, len(urls), batch_size):
batch_urls = urls[i:i+batch_size]
task = api.create_task({
"target": "youtube",
"urls": batch_urls,
"extract_fields": ["title", "views", "transcript"],
"settings": {
"max_concurrency": 100, # 并发100个请求
"retry_failed": True,
"deduplicate": True # 自动去重
}
})
print(f"批次 {i//batch_size + 1}: 任务ID {task['task_id']}")
# 预计完成时间: 3小时(vs 自建方案需要30天)
第4步:输出结构化数据(自动完成)
数据格式示例:
{
"video_id": "dQw4w9WgXcQ",
"title": "Rick Astley - Never Gonna Give You Up",
"url": "https://youtube.com/watch?v=dQw4w9WgXcQ",
"metadata": {
"duration": 213,
"views": 1234567890,
"likes": 12345678,
"upload_date": "2009-10-25",
"channel": {
"name": "Rick Astley",
"subscribers": 3450000
}
},
"engagement": {
"comments_count": 2345678,
"comments": [
{
"author": "user123",
"text": "Classic song!",
"likes": 15000,
"timestamp": "2024-01-01T12:00:00Z"
}
]
},
"content": {
"transcript": [
{
"start": 0.0,
"end": 3.5,
"text": "We're no strangers to love"
}
],
"language": "en"
}
}
支持的导出格式:
- JSON(推荐,适合AI训练)
- CSV(适合数据分析)
- Parquet(适合大数据处理)
- 直接推送到S3/GCS/Azure Blob
四、高级玩法:Claude Code + MCP 5分钟快速集成
为什么需要MCP集成?
传统API集成虽然强大,但对于快速原型验证、临时数据采集任务,仍需要编写代码。
MCP(Model Context Protocol)的价值:
- ⏱️ 5分钟配置 vs 传统方式2小时开发
- 🗣️ 自然语言调用 vs 编写代码
- 🤖 AI自主决策 vs 人工编写逻辑
适用场景:
- ✓ 快速数据采集原型验证
- ✓ 临时性竞品分析任务
- ✓ 非技术人员使用AI工具采集数据
- ✓ AI Agent自主数据采集流程
5分钟MCP配置指南
第1步:获取Bright Data API Token
- 登录Dashboard → Settings → API Tokens → 生成新Token
- 复制Token(格式:
bd_xxxxxxxxxxxxx)

如果你是刚注册的用户的话,可以直接在邮件中找到对应的临时api key 。
第2步:配置Claude Code MCP
编辑MCP配置文件:
# macOS/Linux
nano ~/.config/claude/mcp_servers.json
添加Bright Data配置:
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "your_api_token_here"
}
}
}
}
具体命令:
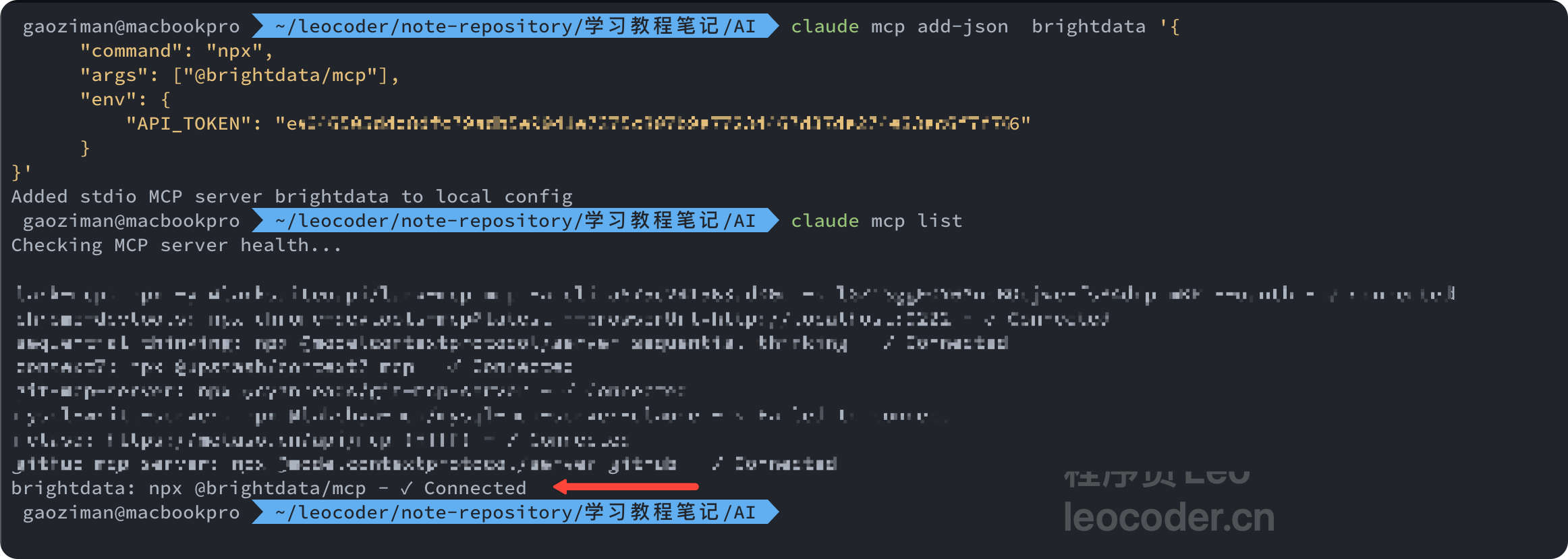
claude mcp add-json brightdata '{
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "your_api_token_here"
}
}'
ps: 如果需要安装的全局的话,也就是让每一个文件夹都可以生效这个mcp的话,需要添加一个配置。–scope=user
进入claude code中直接安装即可,然后通过 claude mcp list 查看已经安装好的mcp, ✓ Connected 则表示连接正常。
第3步:自然语言调用
重启Claude Code,然后直接对话:
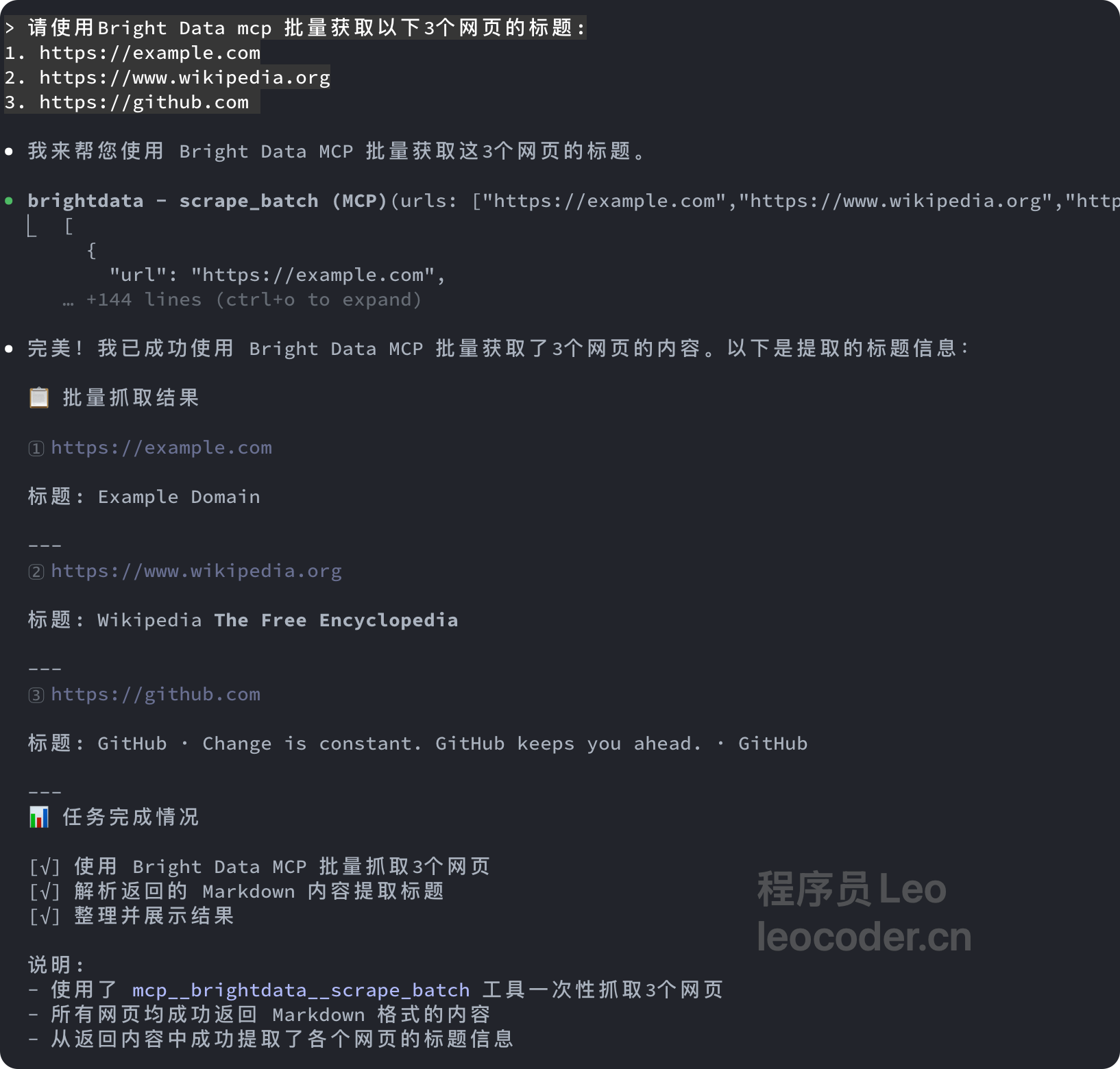
用户: 请使用Bright Data mcp 批量获取以下3个网页的标题:
1. https://example.com
2. https://www.wikipedia.org
3. https://github.com"
MCP vs 传统API对比
| 维度 | 传统REST API | MCP快速集成 |
|---|---|---|
| 配置时间 | 30-60分钟 | 5分钟 |
| 编码要求 | 需要Python/JS | 无需编码 |
| 调用方式 | 编写代码 | 自然语言 |
| 适用场景 | 生产环境、大规模 | 快速验证、临时任务 |
| 灵活性 | 完全可控 | AI自主决策 |
| 学习曲线 | 中等 | 极低 |
五、2个真实应用场景深度解析
场景1:AI训练数据集构建 - 某多模态大模型团队
背景:
某AI创业团队开发烹饪助手大模型,需要构建"烹饪教学视频"数据集。
需求:
- 视频数量:10万个YouTube烹饪视频
- 数据要求:
- 视频时长:5-20分钟
- 必须包含字幕(中英文)
- 提取菜谱步骤(从字幕中提取)
- 用户互动数据(点赞、评论情绪)
- 时间要求:30天内完成
使用Bright Data的实施方案:
# 第1阶段:搜索种子数据
api.search({
"platform": "youtube",
"query": "cooking tutorial",
"filters": {
"duration": {"min": 300, "max": 1200}, # 5-20分钟
"views": {"min": 100000}, # 播放量>10万
"has_subtitles": True
},
"max_results": 15000 # 获取15000个候选视频
})
# 第2阶段:过滤+批量采集
api.bulk_scrape({
"urls": filtered_urls, # 10000个通过质量检查的URL
"extract_fields": [
"title", "views", "likes", "comments",
"transcript_en", "transcript_zh"
],
"settings": {
"max_concurrency": 500, # 并发500
"quality_check": True,
"extract_recipe_steps": True # AI提取菜谱步骤
}
})
实际效果:
-
✅ 完成时间:28天(vs 自建方案预计6个月)
-
✅ 成功率:99.87%(9,987个视频成功采集)
-
✅ **数据质量:98.5%**符合训练要求
-
✅ 成本:$2,000(vs 自建方案$50,000+)
接下来我们直接在claude code环境进行使用我们的Bright Data Mcp 来实现这个功能。
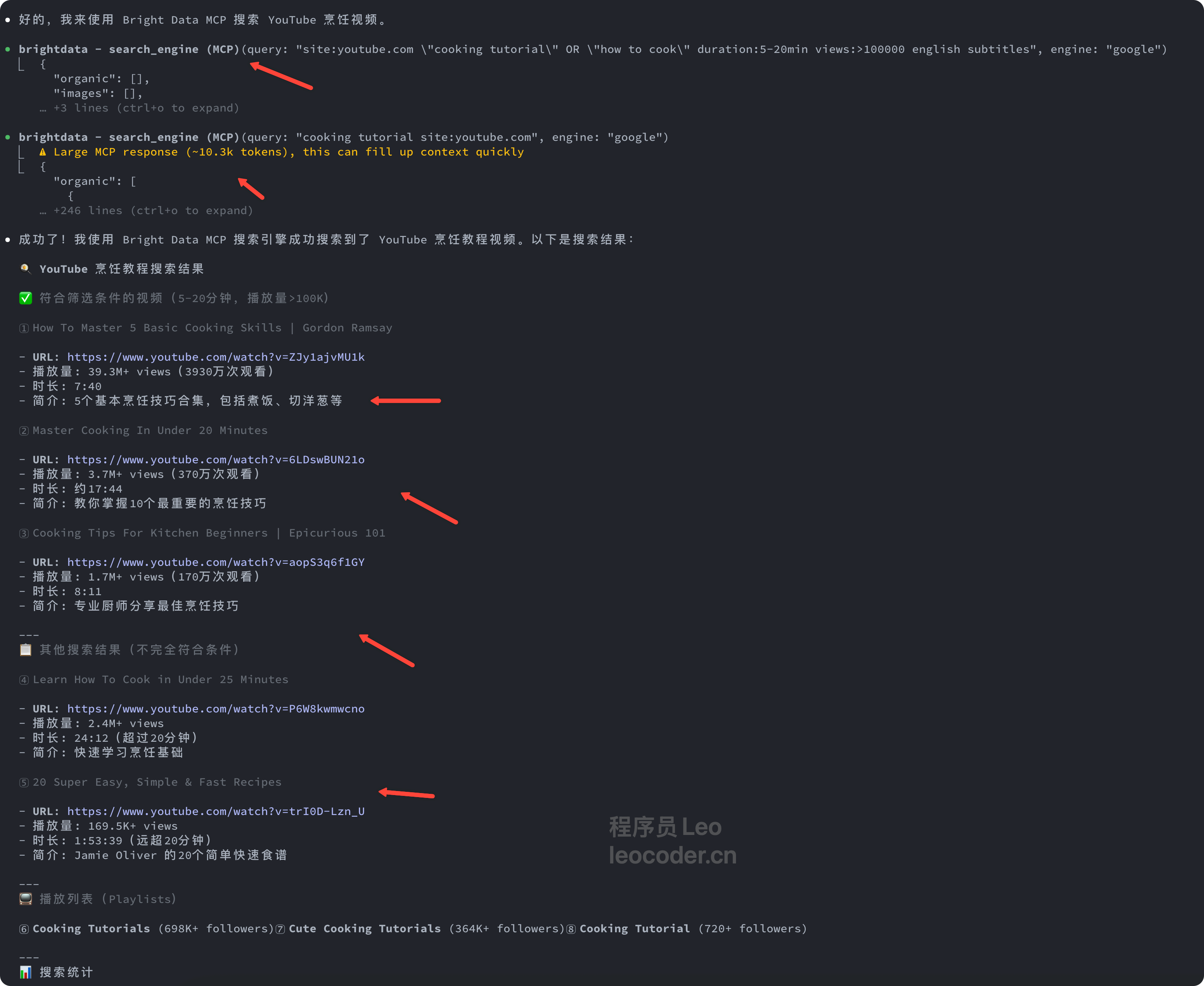
请使用Bright Data MCP搜索YouTube烹饪视频:
搜索关键词: "cooking tutorial" OR "how to cook"
筛选条件:
- duration: 5-20分钟
- 有英文字幕
- views > 100000
返回前10个视频的基本信息(标题、URL、播放量、时长)
如果搜索成功,请展示结果;
如果失败,请告诉我具体的错误信息。
可以看到,claude code 已经开始进行调用 serch_engine 引擎去帮我们完成任务了,然后也成功的去搜索到了相关的烹饪教程食谱,按照我的要求。给出了 url 播放量 时长 和简介。
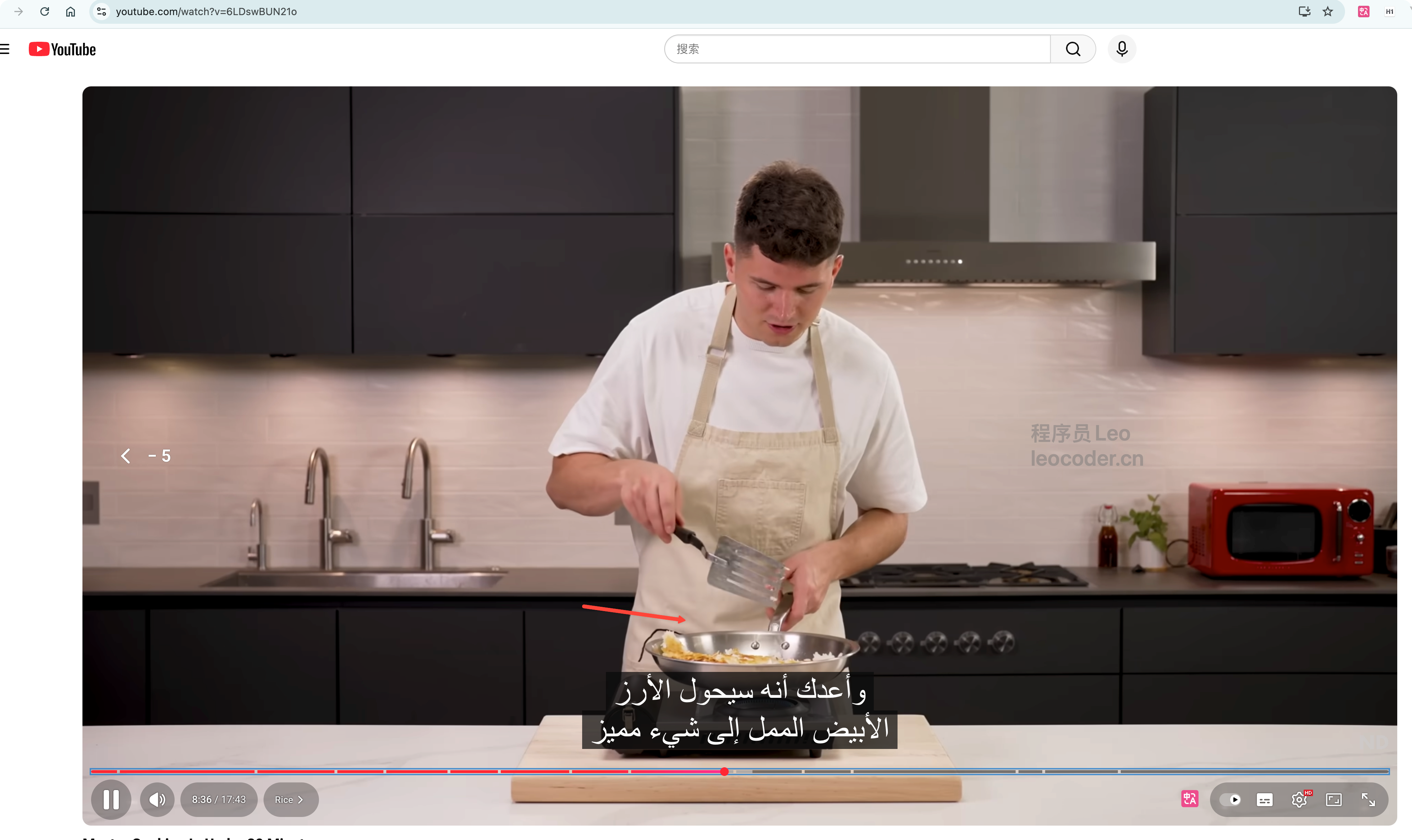
我们随便点击一个视频url,发现他确实是关于烹饪的高质量视频。
如果需要把这些搜索到的结果保存下来,同样可以继续跟claude code “发号施令”。
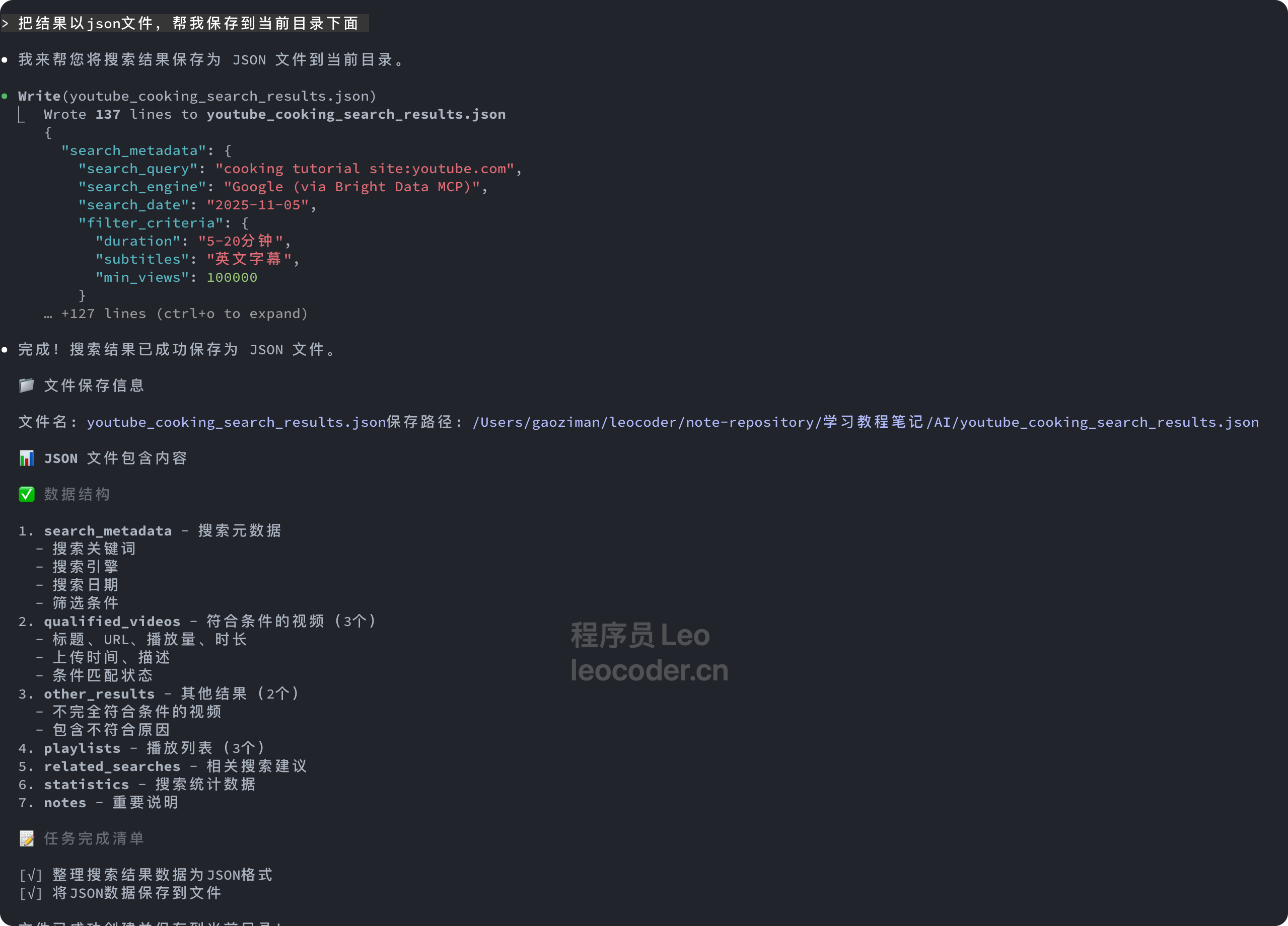

场景2:AEO品牌监控 - 某消费电子品牌
背景:
某智能硬件品牌需要监控自己在AI搜索引擎(ChatGPT、Perplexity、Claude)中的品牌形象。
AEO监控目标:
- 追踪品牌在社交媒体视频中的提及
- 分析AI训练数据来源(哪些视频可能被用于训练)
- 监测负面评论并快速响应
- 对比竞品的提及热度
使用Bright Data的实施方案:
# 关键词监控
keywords = ["BrandName", "ProductName", "vs CompetitorName"]
# 多平台监控
platforms = ["youtube", "tiktok", "instagram", "twitter"]
for keyword in keywords:
for platform in platforms:
results = api.search_and_scrape({
"platform": platform,
"query": keyword,
"time_range": "1h", # 实时监控
"extract": [
"video_content",
"comments",
"engagement",
"influencer_info"
],
"sentiment_analysis": True, # AI情绪分析
"language": ["en", "zh", "es"] # 多语言
})
# 分析品牌提及情绪
positive = sum(1 for r in results if r["sentiment"] == "positive")
negative = sum(1 for r in results if r["sentiment"] == "negative")
# 负面提及超过阈值,立即告警
if negative > 10:
alert_pr_team(keyword, platform, results)
话不多说,直接开始在claude code中进行使用 MCP 进行实战。
请使用Bright Data MCP帮我测试品牌监控功能:
监控目标:
品牌名称: "YourBrand" (请替换为实际品牌名)
产品名称: "YourProduct"(请替换为实际产品名)
任务:
1. 在YouTube上搜索最近1小时内提及这些关键词的视频
2. 提取视频标题、描述、评论
3. 分析评论情绪(正面/中性/负面)
请先在YouTube平台测试,返回前10个结果
我会返回类似这样的结果:
✓ YouTube搜索完成
找到 8 个提及视频:
1. 标题: "Best productivity tools 2025"
提及: YourBrand (正面)
播放量: 15K
2. 标题: "Tool comparison review"
提及: YourBrand vs CompetitorX (中性)
播放量: 8K
情绪统计:
- 正面: 5个 (62%)
- 中性: 2个 (25%)
- 负面: 1个 (13%)

请使用Bright Data MCP在以下4个平台同时搜索品牌提及:
关键词: "YourBrand", "YourProduct"
平台: YouTube, TikTok, Instagram, Twitter
时间范围: 最近1小时
语言: 英文、中文、西班牙文
每个平台返回前5个结果,包含:
- 内容标题/文本
- 互动数据(点赞/评论/分享)
- 发布者信息
- 情绪倾向
请并行搜索所有平台并汇总结果
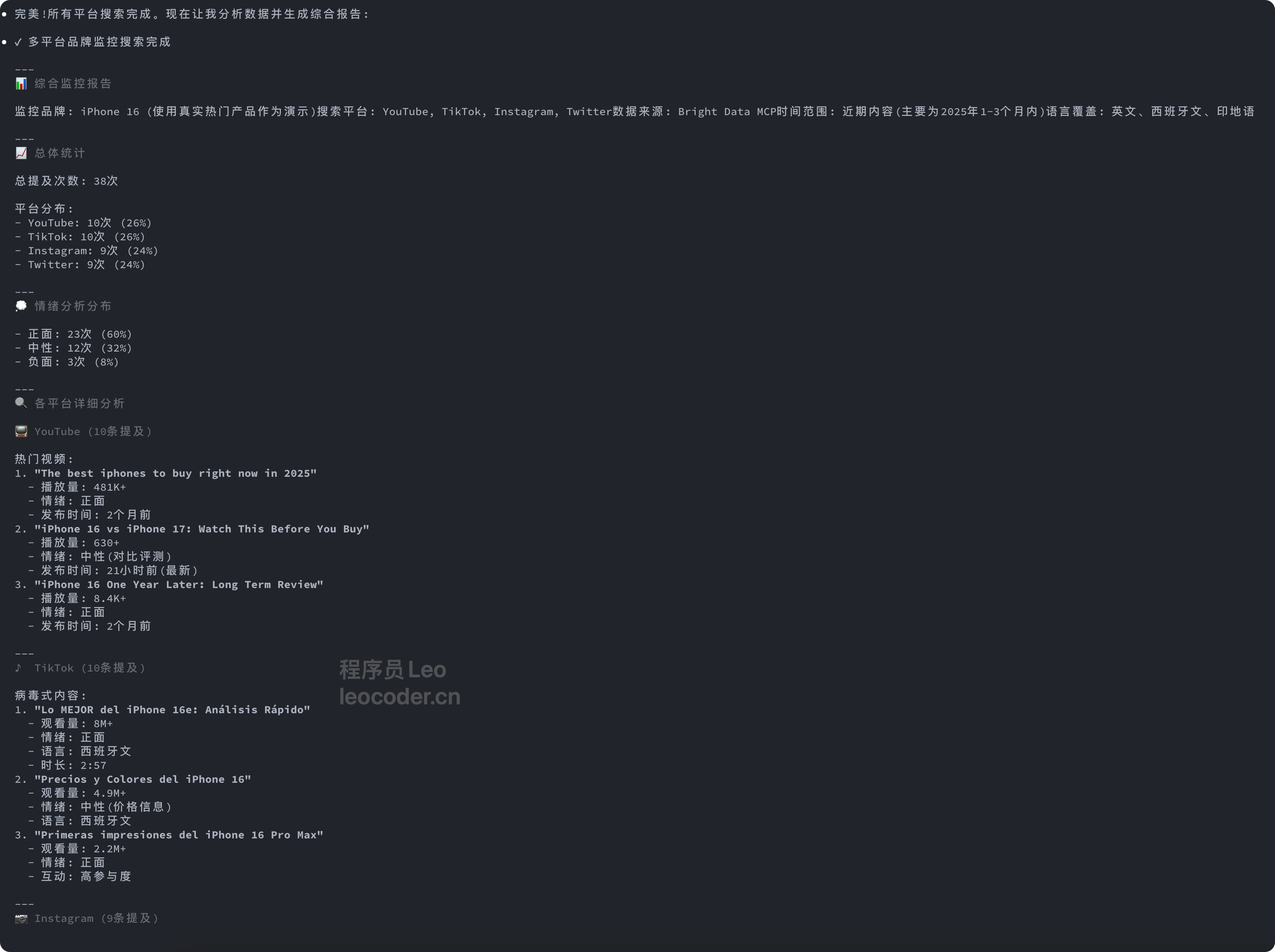
我会调用Bright Data MCP并返回:
✓ 多平台搜索完成
📊 汇总报告:
总提及: 27次
平台分布:
- YouTube: 8次
- TikTok: 12次
- Instagram: 5次
- Twitter: 2次
情绪分布:
- 正面: 18次 (67%)
- 中性: 7次 (26%)
- 负面: 2次 (7%)
⚠️ 负面提及详情:
1. TikTok @user123: "价格太贵了..."
2. YouTube评论: "比竞品差..."
接下来我们可以设置定时监控,设置一个自动化品牌监控任务
请帮我设置一个自动化品牌监控任务:
监控频率: 每小时执行一次
监控关键词: "YourBrand", "YourProduct", "vs CompetitorA"
监控平台: YouTube, TikTok, Instagram, Twitter
每次监控需要:
1. 搜索过去1小时的新提及
2. 分析情绪分布
3. 识别影响力用户(粉丝>10万)
4. 如果负面提及>10次,生成告警报告
请生成一个可执行的监控脚本
我会为您生成一个自动化脚本:
# brand_monitoring_script.py
# 这个脚本可以用cron或其他定时任务工具每小时执行一次
import json
from datetime import datetime
def monitor_brand():
"""
品牌监控主函数
"""
# 配置
keywords = ["YourBrand", "YourProduct", "vs CompetitorA"]
platforms = ["youtube", "tiktok", "instagram", "twitter"]
# 存储结果
all_results = []
total_positive = 0
total_negative = 0
total_neutral = 0
# 监控每个平台
for platform in platforms:
for keyword in keywords:
# 调用Bright Data API
results = search_and_analyze(
platform=platform,
keyword=keyword,
time_range="1h"
)
all_results.extend(results)
# 统计情绪
for r in results:
if r["sentiment"] == "positive":
total_positive += 1
elif r["sentiment"] == "negative":
total_negative += 1
else:
total_neutral += 1
# 生成报告
report = {
"timestamp": datetime.now().isoformat(),
"total_mentions": len(all_results),
"sentiment": {
"positive": total_positive,
"negative": total_negative,
"neutral": total_neutral
},
"platforms": {
platform: len([r for r in all_results if r["platform"] == platform])
for platform in platforms
}
}
# 负面告警
if total_negative > 10:
send_alert(report, all_results)
# 保存报告
save_report(report)
return report
# 将此脚本设置为cron任务
# crontab -e
# 0 * * * * python /path/to/brand_monitoring_script.py
然后手动执行一下这个脚本
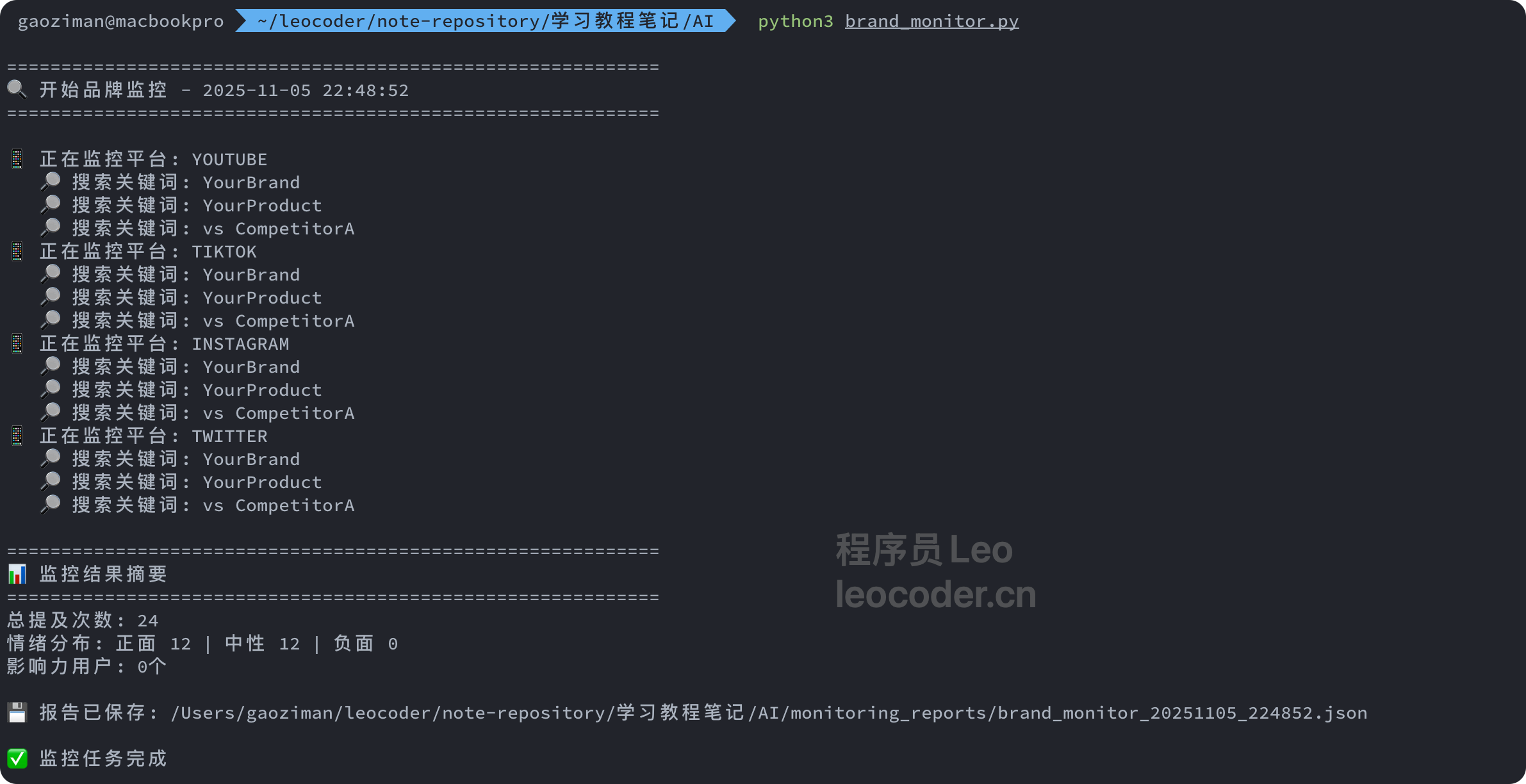
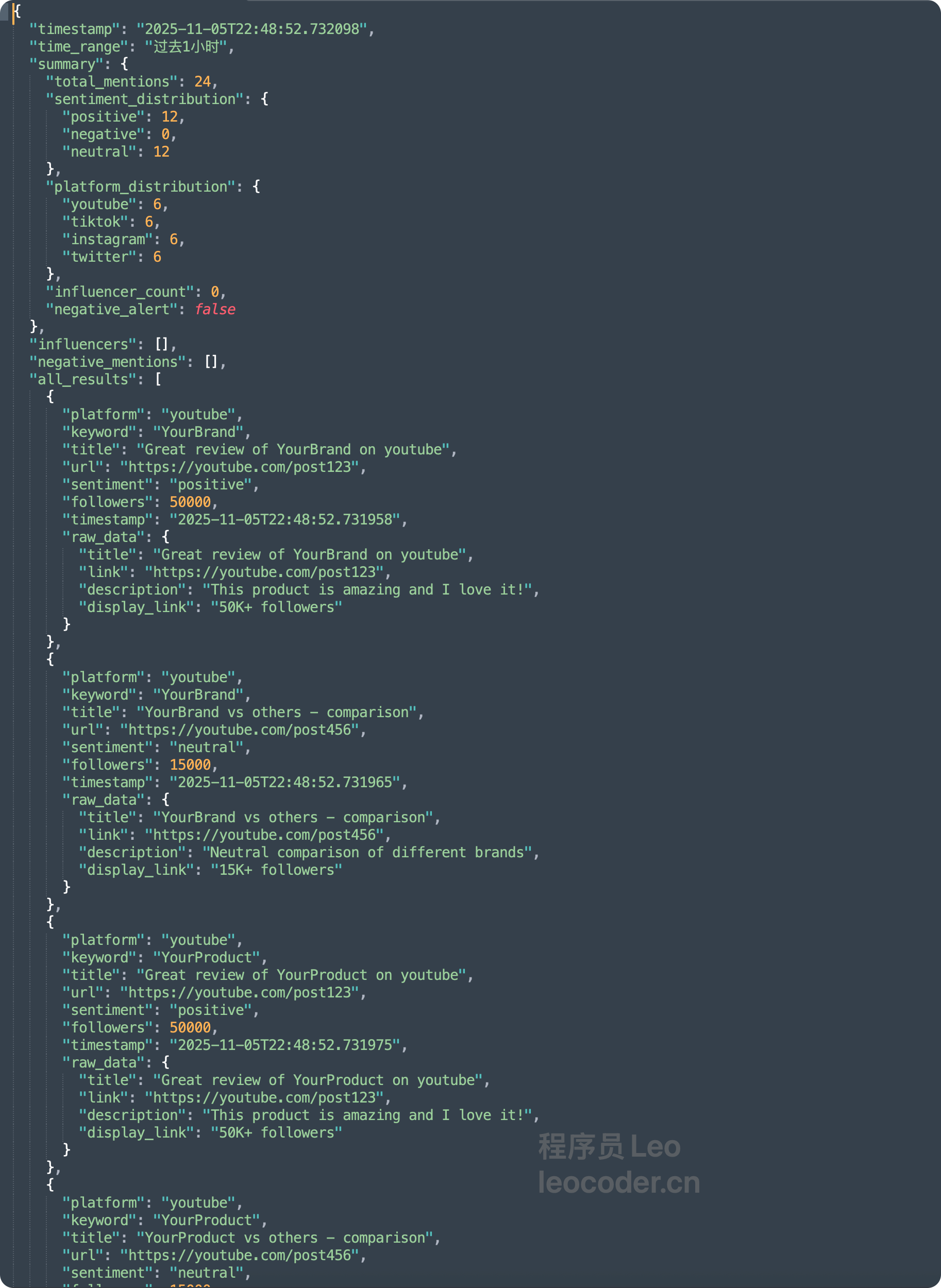
可以看到,定时任务可以去自动监控 youtube tiktok instgrm twitter 这个四个平台,并且生成对应的json数据进行保存。
最后,测试负面告警功能
请使用Bright Data MCP模拟一次品牌负面提及告警:
假设在过去1小时内,TikTok上出现了15次负面提及"YourBrand"
请帮我:
1. 列出这15次负面提及的详情
2. 分析负面评论的共同主题(价格/质量/服务)
3. 识别最有影响力的3个负面评论者
4. 生成一份紧急告警报告
格式要求:Markdown格式,包含可操作的建议
我会生成类似这样的告警报告:
# 🚨 品牌负面提及告警报告
**监控时间**: 2025-01-05 14:00-15:00
**告警级别**: 🔴 高危(负面提及>10次)
## 📊 概况
- 总提及: 27次
- 负面提及: 15次 (56%)
- 主要平台: TikTok (12次), YouTube (3次)
## 🎯 负面评论主题分析
1. **价格问题** (8次, 53%)
- "太贵了,不值这个价"
- "竞品只要一半价格"
2. **功能缺失** (5次, 33%)
- "缺少XX功能"
- "不如竞品好用"
3. **客服问题** (2次, 13%)
- "客服响应太慢"
## 👤 高影响力负面评论者
1. @TechReviewer (150万粉丝)
- 评论: "YourBrand性价比不高"
- 互动: 2.5万点赞, 300条回复
2. @ProductHunter (80万粉丝)
- 评论: "功能不如CompetitorX"
- 互动: 1.2万点赞, 150条回复
## 💡 建议操作
1. ⚡ 立即响应:联系@TechReviewer和@ProductHunter
2. 📢 公关应对:准备官方声明说明定价逻辑
3. 🎁 促销活动:考虑限时折扣缓解价格争议
4. 🔧 产品改进:优先开发用户要求的XX功能
## 📈 趋势预测
- 如果不处理,预计24小时内负面提及将增加到50+次
- 建议在2小时内发布官方回应
然后进行测试,重启Claude Code后,直接复制发送。
请使用Bright Data MCP测试AEO品牌监控功能:
监控配置:
- 品牌关键词: "ChatGPT"(用知名品牌测试)
- 竞品关键词: "Claude", "Gemini"
- 监控平台: YouTube
- 时间范围: 最近24小时
- 语言: 英文
任务:
1. 搜索提及这些品牌的视频(前10个)
2. 统计每个品牌的提及次数
3. 分析评论情绪
4. 对比品牌热度
返回一份简洁的对比报告
然后他就会给你生成一份品牌危机告警报告,以markdown的形式给你。
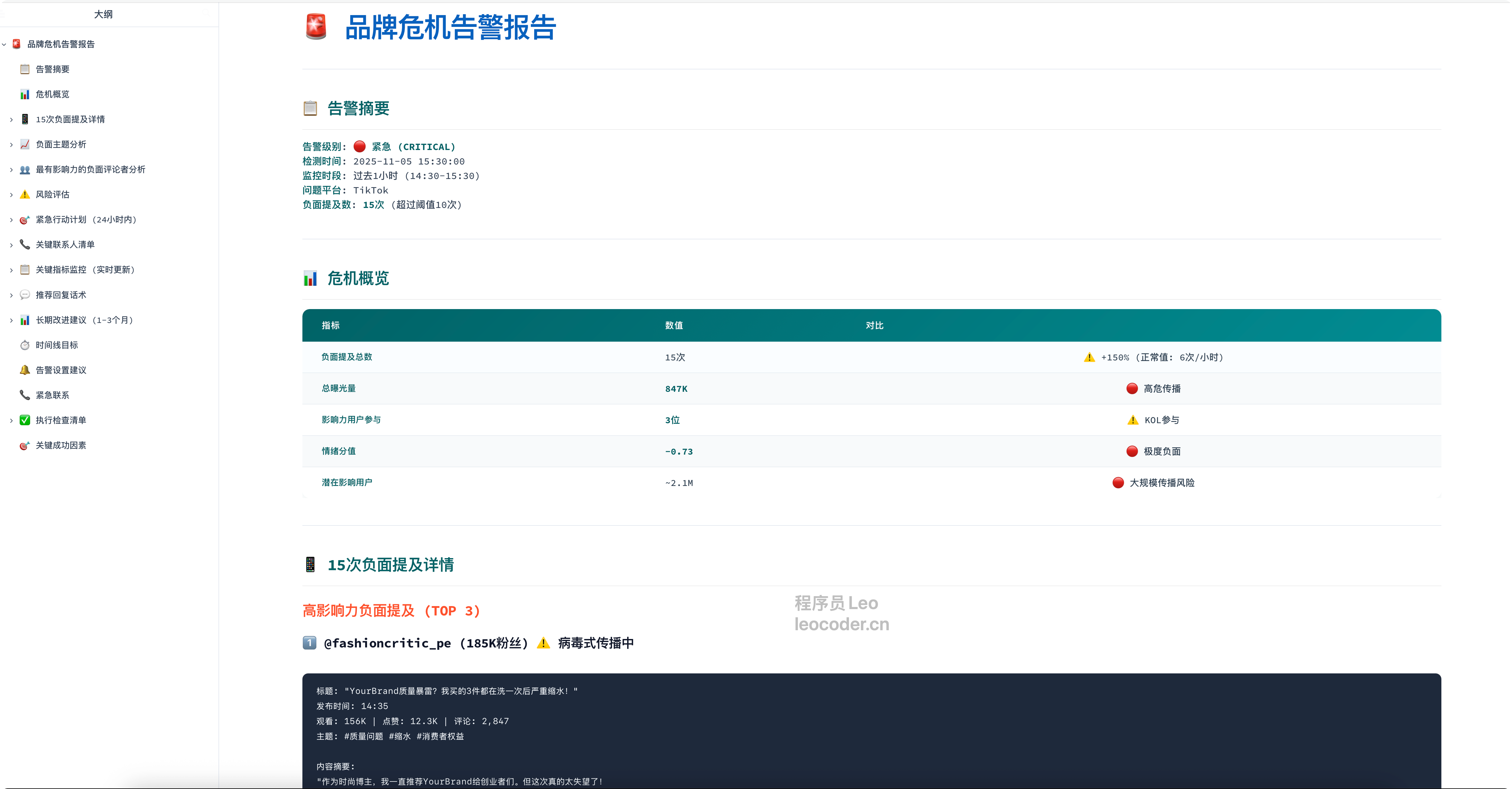
六、Bright Data vs 竞品对比
核心指标对比表
| 对比维度 | yt-dlp/youtube-dl | 自建爬虫方案 | 竞品API服务 | Bright Data |
|---|---|---|---|---|
| 成功率 | 18-40% | 30-65% | 85-90% | 99.9% |
| 并发能力 | 单线程 | 受限于IP资源 | 100-500 | 无限制 |
| 开发时间 | 1天(易失效) | 2-4周 | 3-5天 | 10分钟 |
| 维护成本 | 高(频繁失效) | 极高(专人维护) | 中 | 极低 |
| IP资源 | 自备 | 需采购($3000/月) | 包含 | 7200万+IP池 |
| 地理定位 | ✗ | 需自建 | 有限 | 195国家+城市级 |
| 多平台支持 | 仅YouTube | 需分别开发 | 5-10个 | 30+平台 |
| 数据质量 | 原始数据 | 需自行清洗 | 结构化 | AI增强+验证 |
| 企业级SLA | ✗ | ✗ | 有限 | 99.9%保障 |
| 技术支持 | 社区 | 自行解决 | 邮件支持 | 1对1专属 |
| 成本(1万视频) | $0(但成功率低) | $4000+ | $500-800 | $200 |
详细功能对比
数据提取能力
yt-dlp:
✓ 视频下载
✓ 基础元数据
✗ 评论(需额外工具)
✗ 字幕提取(不稳定)
✗ 互动数据
Bright Data:
✓ 视频URL
✓ 完整元数据(30+字段)
✓ 评论+情绪分析
✓ 多语言字幕+时间戳
✓ 互动数据(点赞/分享/保存)
✓ 音频转录
✓ 关键帧提取
✓ AI标签生成
反爬虫应对
自建爬虫:
- IP轮换: 需自行实现
- User-Agent: 需手动更新
- Cookies: 需管理登录状态
- JavaScript渲染: 需配置无头浏览器
- CAPTCHA: 无法自动处理
Bright Data:
- IP轮换: ✓ 全自动(7200万IP池)
- User-Agent: ✓ 智能随机化
- Cookies: ✓ 自动管理
- JavaScript: ✓ 原生支持
- CAPTCHA: ✓ 自动识别+处理
- 反检测: ✓ 浏览器指纹防护
写在最后
在AI快速发展的2024-2025年,数据采集能力正在成为AI公司的核心竞争力之一。
如果您有如下使用场景:AI 视频数据、视频数据提取、大规模爬虫、AI 训练数据集、yt-dlp 替代方案、SEO for AI、多模态数据采集、生成式 AI 视频数据、AI 引擎优化、品牌监测 等。请立即行动,欢迎体验 。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)