
大模型应用技术二:RAG高级技术和实践
Qwen-Agent是一个开发框架。充分利用基于通义千问模型(Qwen)的指令遵循、工具使用、规划、记忆能力。Qwen-Agent支持的模型形式:DashScope服务提供的Qwen模型服务支持通过OpenAI API方式接入开源的Qwen模型服务Ragas (Retrieval-Augmented Generation Assessment) 它是一个框架,它可以帮助我们来快速评估RAG系统的性
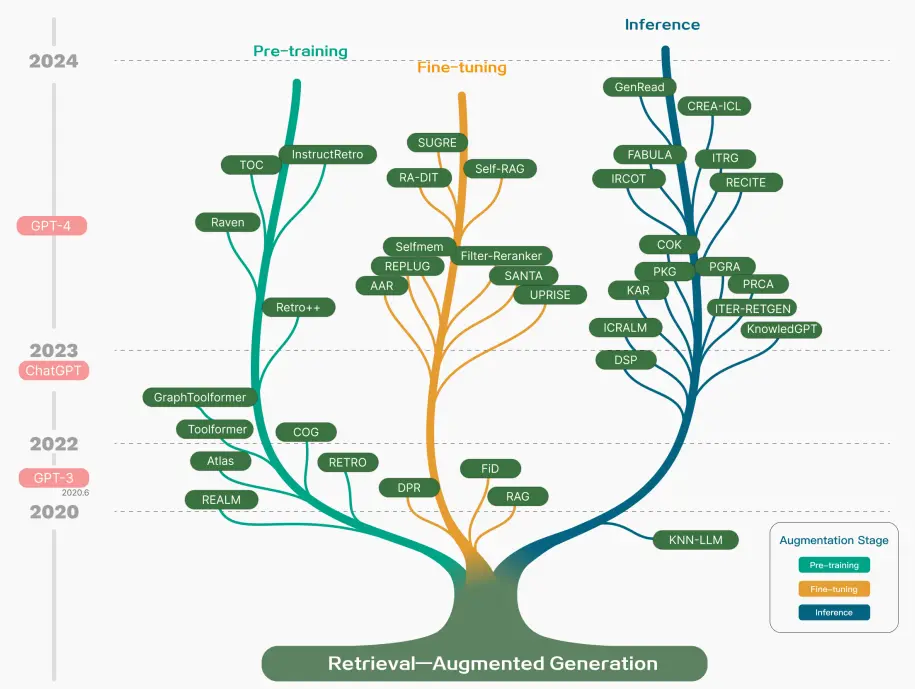
1. RAG 发展历程
RAG研究的技术树主要涉及预训练(Pre-training)、微调(Fine-tuning)和推理(Inference)等阶段。随着LLM的出现,RAG的研究最初侧重于利用LLMs强大的上下文学习能力,主要集中在推理阶段。随后的研究进一步深入,逐渐与LLMs的微调阶段更加融合。研究人员也在探索通过检索增强技术来提升预训练阶段的语言模型性能。
参考文章 https://www.promptingguide.ai/research/rag
2. RAFT 方法论
RAFT方法(Retrieval Augmented Fine Tuning)
RAFT: Adapting Language Model to Domain Specific RAG, 2024 https://arxiv.org/pdf/2403.10131
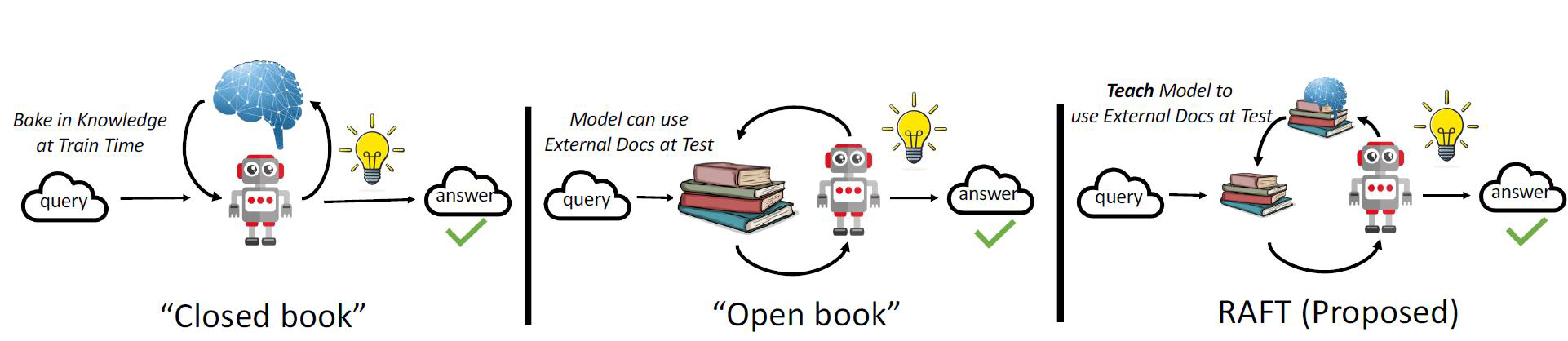
如何最好地准备考试?
- 基于微调的方法通过“学习”来实现“记忆”输入文档或回答练习题而不参考文档。
- 或者,基于上下文检索的方法未能利用固定领域所提供的学习机会,相当于参加开卷考试但没有事先复习。
- 相比之下,我们的方法RAFT利用了微调与问答对,并在一个模拟的不完美检索环境中参考文档——从而有效地为开卷考试环境做准备。
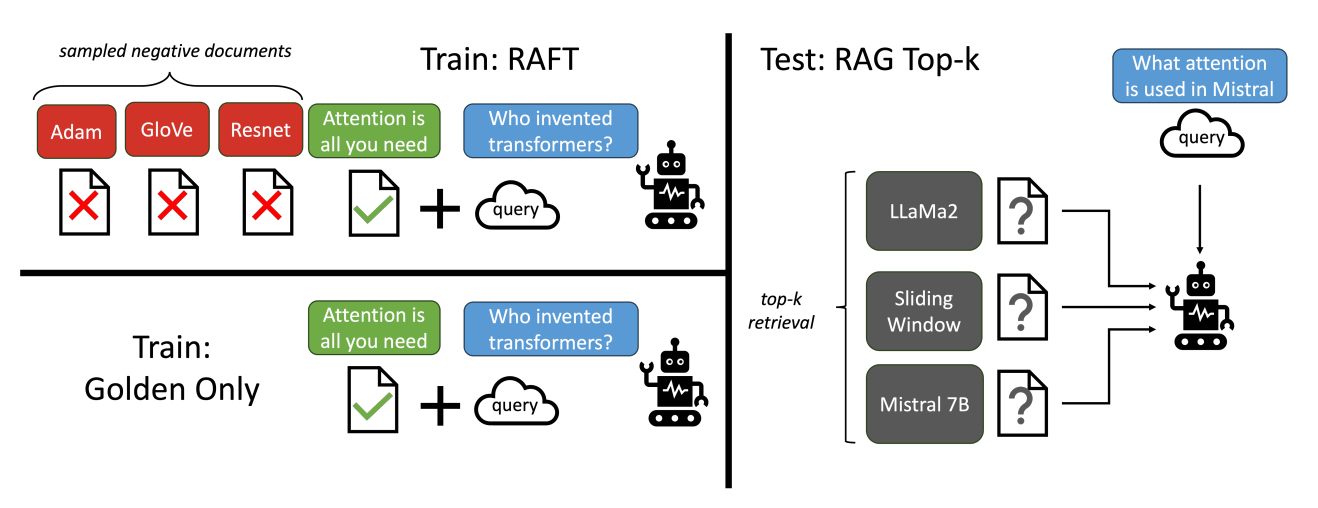
让LLMs从一组正面和干扰文档中读取解决方案,这与标准的RAG设置形成对比,因为在标准的RAG设置中,模型是基于检索器输出进行训练的,这包含了记忆和阅读的混合体。在测试时,所有方法都遵循标准的RAG设置,即提供上下文中排名前k的检索文档。
 微调数据集准备样例:
微调数据集准备样例:
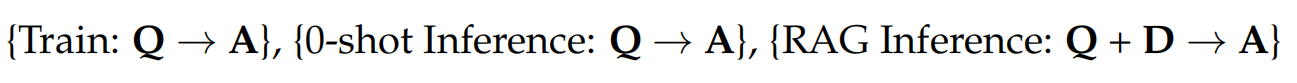
上图中的 D(文档),有正向文档也有干扰文档。
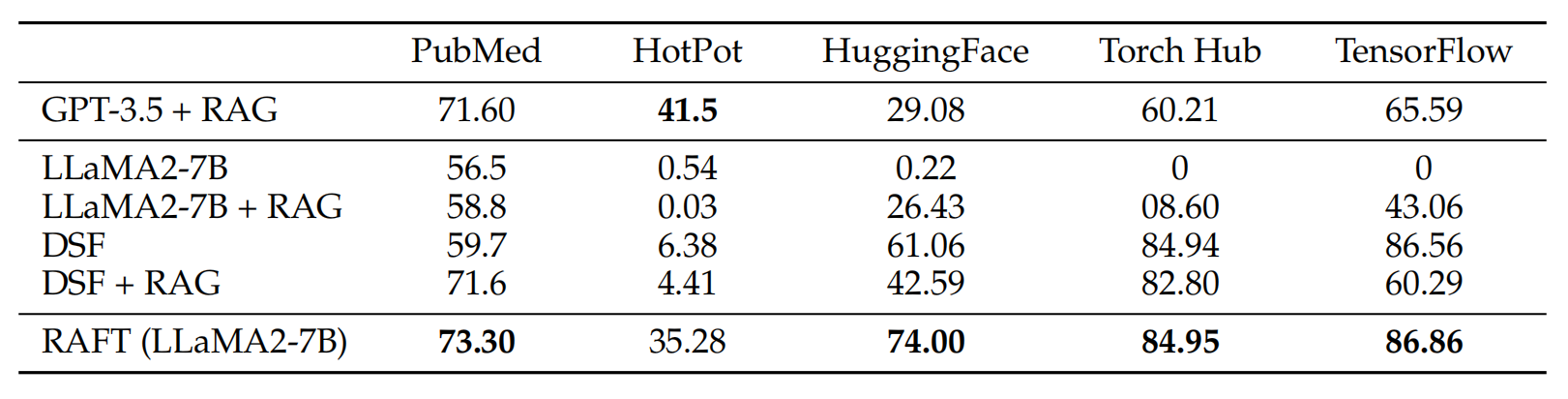
RAFT在所有专业领域的RAG性能上有所提升(在PubMed、HotPot、HuggingFace、Torch Hub和TensorflowHub等多个领域),领域特定的微调提高了基础模型的性能,RAFT无论是在有RAG的情况下还是没有RAG的情况下,都持续优于现有的领域特定微调方法。这表明了需要在上下文中训练模型。
总结:
RAFT方法(Retrieval Augmented Fine Tuning):
-
适应特定领域的LLMs对于许多新兴应用至关重要,但如何有效融入信息仍是一个开放问题。
-
RAFT结合了检索增强生成(RAG)和监督微调(SFT),从而提高模型在特定领域内回答问题的能力。
-
训练模型识别并忽略那些不能帮助回答问题的干扰文档,只关注和引用相关的文档。
-
通过在训练中引入干扰文档,提高模型对干扰信息的鲁棒性,使其在测试时能更好地处理检索到的文档。
训练示例:https://github.com/lumpenspace/raft
备注:7b 模型需要1000-2000条的样本就能达到不错的效果。但是对这些样本有要求:样本要有多样性。
3. RAG 高效召回方法
3.1 设置合理的Top K
docs = knowledgeBase.similarity_search(query, k=5)3.2 改进索引算法
知识图谱:利用知识图谱中的语义信息和实体关系,增强对查询和文档的理解,提升召回的相关性。
基于知识图谱的 RAG:GraphRAG 和 LightRAG。蚂蚁金服的 RAG 框架: DB-GPT https://github.com/eosphoros-ai/DB-GPT?ref=openi.cn。
3.3 引入重排序(Reranking)
重排序模型:对召回结果进行重排,提升问题和文档的相关性。常见的重排序模型有 BGE-Rerank 和 Cohere Rerank。Hugging Face 或者魔搭社区都能下载到这些模型。
-
场景:用户查询“如何提高深度学习模型的训练效率?”
-
召回结果:初步召回10篇文档,其中包含与“深度学习”、“训练效率”相关的文章。
-
重排序:BGE-Rerank对召回的10篇文档进行重新排序,将与“训练效率”最相关的文档(如“优化深度学习训练的技巧”)排在最前面,而将相关性较低的文档(如“深度学习基础理论”)排在后面。
混合检索:结合向量检索和关键词检索的优势,通过重排序模型对结果进行归一化处理,提升召回质量。
3.4 优化查询扩展
相似语义改写: 使用大模型将用户查询改写成多个语义相近的查询,提升召回多样性。
- 例如,LangChain的
MultiQueryRetriever支持多查询召回,再进行回答问题。
import os
from langchain_classic.retrievers import MultiQueryRetriever
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.llms import Tongyi
# 初始化大语言模型
DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY")
llm = Tongyi(
model_name="qwen-max",
dashscope_api_key=DASHSCOPE_API_KEY
)
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=DASHSCOPE_API_KEY
)
# 加载向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化
vectorstore = FAISS.load_local("./vector_db", embeddings, allow_dangerous_deserialization=True)
# 创建MultiQueryRetriever
retriever = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
# 示例查询
query = "客户经理的考核标准是什么?"
# 执行查询
results = retriever.invoke(query)
# 打印结果
print(f"查询: {query}")
print(f"找到 {len(results)} 个相关文档:")
for i, doc in enumerate(results):
print(f"\n文档 {i+1}:")
print(doc.page_content[:200] + "..." if len(doc.page_content) > 200 else doc.page_content)3.5 双向改写
将查询改写成文档(Query2Doc)或为文档生成查询(Doc2Query),缓解短文本向量化效果差的问题。
3.5.1 Query2Doc:将查询改写成文档
-
用户查询:“如何提高深度学习模型的训练效率?”
-
Query2Doc 改写:
-
原始查询较短,可能无法充分表达用户意图。
-
通过 Query2Doc 生成一段扩展文档:
-
提高深度学习模型的训练效率可以从以下几个方面入手:
- 使用更高效的优化算法,如AdamW或LAMB。
- 采用混合精度训练(Mixed Precision Training),减少显存占用并加速计算。
- 使用分布式训练技术,如数据并行或模型并行。
- 对数据进行预处理和增强,减少训练时的冗余计算。
- 调整学习率调度策略,避免训练过程中的震荡。
3.5.2 Doc2Query:为文档生成关联查询
原理:对文档做阅读理解,然后生成多个Query。
-
文档内容:
本文介绍了深度学习模型训练中的优化技巧,包括:
-
使用AdamW优化器替代传统的SGD。
-
采用混合精度训练,减少显存占用。
-
使用分布式训练技术加速大规模模型的训练……
-
-
通过 Doc2Query 生成一组可能的查询:
-
如何选择深度学习模型的优化器?
-
混合精度训练有哪些优势?
-
分布式训练技术如何加速深度学习?
-
如何减少深度学习训练中的显存占用?
-
深度学习模型训练的最佳实践是什么?
-
3.6 索引扩展
-
离散索引扩展: 使用关键词抽取、实体识别等技术生成离散索引,与向量检索互补,提升召回准确性。
-
连续索引扩展: 结合多种向量模型(如OpenAI的Ada、智源的BGE)进行多路召回,取长补短。
-
混合索引召回: 将BM25等离散索引与向量索引结合,通过Ensemble Retriever实现混合召回,提升召回多样性
3.6.1 离散索引
使用关键词抽取、实体识别等技术生成离散索引,与向量检索互补,提升召回准确性。
1. 关键词抽取: 从文档中提取出重要的关键词,作为离散索引的一部分,用于补充向量检索的不足。
文档内容:
本文介绍了深度学习模型训练中的优化技巧,包括:
1. 使用AdamW优化器替代传统的SGD。
2. 采用混合精度训练,减少显存占用。
3. 使用分布式训练技术加速大规模模型的训练。
通过关键词抽取技术(如TF-IDF、TextRank)提取出以下关键词:
["深度学习", "模型训练", "优化技巧", "AdamW", "混合精度训练", "分布式训练"]
当用户查询“如何优化深度学习模型训练?”时,离散索引中的关键词能够快速匹配到相关文档。
2. 实体识别: 从文档中识别出命名实体(如人名、地点、组织等),作为离散索引的一部分,增强检索的精确性。
文档内容:
2023年诺贝尔物理学奖授予了三位科学家,以表彰他们在量子纠缠领域的研究成果。
通过实体识别技术(如SpaCy、BERT-based NER)提取出以下实体:
["2023年", "诺贝尔物理学奖", "量子纠缠"]
当用户查询“2023年诺贝尔物理学奖的获奖者是谁?”时,离散索引中的实体能够快速匹配到相关文档。
3.6.2 混合索引召回
将离散索引(如关键词、实体)与向量索引结合,通过混合召回策略提升检索效果。
文档内容:
本文介绍了人工智能在医疗领域的应用,包括:
1. 使用深度学习技术进行医学影像分析。
2. 利用自然语言处理技术提取电子病历中的关键信息。
3. 开发智能诊断系统辅助医生决策。
关键词抽取:["人工智能", "医疗领域", "深度学习", "医学影像分析", "自然语言处理", "电子病历", "智能诊断系统"]
实体识别:["人工智能", "医疗领域", "深度学习", "自然语言处理"]
当用户查询“人工智能在医疗领域的应用有哪些?”时: 离散索引通过关键词和实体匹配到相关文档。 向量索引通过语义相似度匹配到相关文档。 综合两种召回结果,提升检索的准确性和覆盖率。
3.6.3 Small-to-Big
Small-to-Big 索引策略: 一种高效的检索方法,特别适用于处理长文档或多文档场景。核心思想是通过小规模内容(如摘要、关键句或段落)建立索引,并链接到大规模内容主体中。这种策略的优势在于能够快速定位相关的小规模内容,并通过链接获取更详细的上下文信息,从而提高检索效率和答案的逻辑连贯性。
小规模内容(索引部分):
摘要:从每篇论文中提取摘要作为索引内容。
摘要1:本文介绍了Transformer 模型在机器翻译任务中的应用,并提出了改进的注意力机制。
摘要2:本文探讨了Transformer 模型在文本生成任务中的性能,并与RNN 模型进行了对比。
关键句:从论文中提取与查询相关的关键句。
关键句1:Transformer 模型通过自注意力机制实现了高效的并行计算。
关键句2:BERT 是基于Transformer 的预训练模型,在多项NLP 任务中取得了显著效果。
大规模内容(链接部分):
每篇论文的完整内容作为大规模内容,通过链接与小规模内容关联。
-
论文1:链接到完整的PDF 文档,包含详细的实验和结果。
-
论文2:链接到完整的PDF 文档,包含模型架构和性能分析。
Small-to-Big机制:
1. 小规模内容检索: 用户输入查询后,系统首先在小规模内容(如摘要、关键句或段落)中检索匹配的内容。小规模内容通常是通过摘要生成、关键句提取等技术从大规模内容中提取的,并建立索引。
2. 链接到大规模内容: 当小规模内容匹配到用户的查询后,系统会通过预定义的链接(如文档ID、URL 或指针)找到对应的大规模内容(如完整的文档、文章)。大规模内容包含更详细的上下文信息,为RAG 提供丰富的背景知识。
3. 上下文补充: 将大规模内容作为RAG 系统的上下文输入,结合用户查询和小规模内容,生成更准确和连贯的答案。
实现原理:
-
文档 -> 生成摘要(LLM + Prompt)
原始文档文件夹 -> 向量数据库 faiss-1
摘要文档文件夹 -> 向量数据库 faiss-2
两者建立1v1对应关系
-
Small-to-Big 检索策略
query -> faiss-2 -> faiss-1
4. Qwen-Agent 构建 RAG
4.1 基本介绍
Qwen-Agent是一个开发框架。充分利用基于通义千问模型(Qwen)的指令遵循、工具使用、规划、记忆能力。
Qwen-Agent支持的模型形式:
-
DashScope服务提供的Qwen模型服务
-
支持通过OpenAI API方式接入开源的Qwen模型服务
Github:https://github.com/QwenLM/Qwen-Agent
4.2 构建智能体
Qwen-Agent构建的智能体包含三个复杂度级别,每一层都建立在前一层的基础上
4.2.1 Level-1:检索
处理100万字上下文的一种朴素方法是简单采用增强检索生成(RAG)。 RAG将上下文分割成较短的块,每块不超过512个字,然后仅保留最相关的块在8k字的上下文中。 挑战在于如何精准定位最相关的块。经过多次尝试,我们提出了一种基于关键词的解决方案:
-
步骤1:指导聊天模型将用户查询中的指令信息与非指令信息分开。
- 例如,将用户查询"回答时请用2000字详尽阐述,我的问题是,自行车是什么时候发明的?请用英文回复。"转化为{"信息": ["自行车是什么时候发明的"], "指令": ["回答时用2000字", "尽量详尽", "用英文回复"]}。
-
步骤2:要求聊天模型从查询的信息部分推导出多语言关键词。
- 例如,短语"自行车是什么时候发明的"会转换为{"关键词_英文": ["bicycles", "invented", "when"], "关键词_中文": ["自行车", "发明", "时间"]}。
-
步骤3:运用BM25这一传统的基于关键词的检索方法,找出与提取关键词最相关的块。
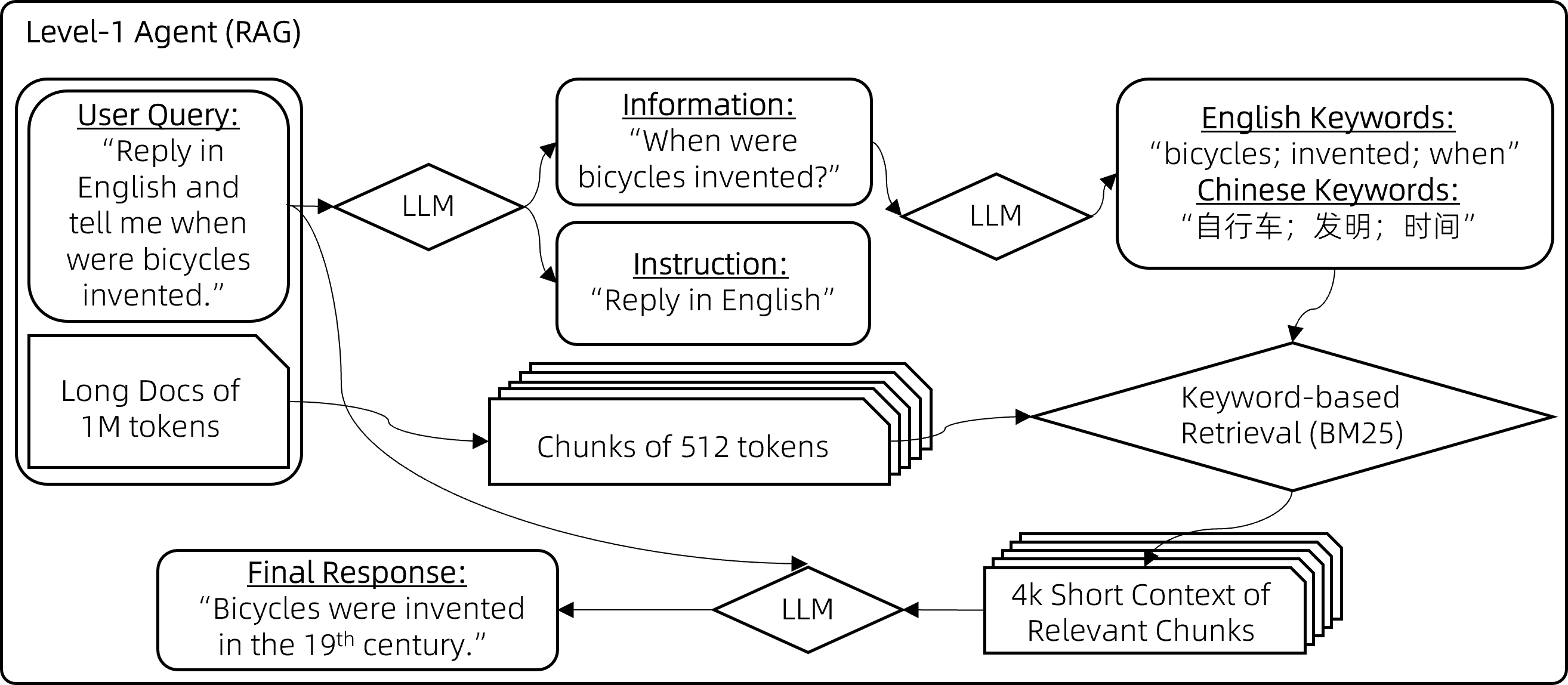
RAG CODE:https://github.com/QwenLM/Qwen-Agent/blob/main/examples/assistant_rag.py
4.2.2 Level-2:分块检索
上述RAG方法很快速,但常在相关块与用户查询关键词重叠程度不足时失效,导致这些相关的块未被检索到、没有提供给模型。尽管理论上向量检索可以缓解这一问题,但实际上效果有限。 为了解决这个局限,我们采用了一种暴力策略来减少错过相关上下文的几率:
-
步骤1:对于每个512字块,让聊天模型评估其与用户查询的相关性, 如果认为不相关则输出"无", 如果相关则输出相关句子。这些块会被并行处理以避免长时间等待。
-
步骤2:然后,取那些非"无"的输出(即相关句子),用它们作为搜索查询词,通过BM25检索出最相关的块 (总的检索结果长度控制在8k上下文限制内)。
-
步骤3:最后,基于检索到的上下文生成最终答案, 这一步骤的实现方式与通常的RAG相同。
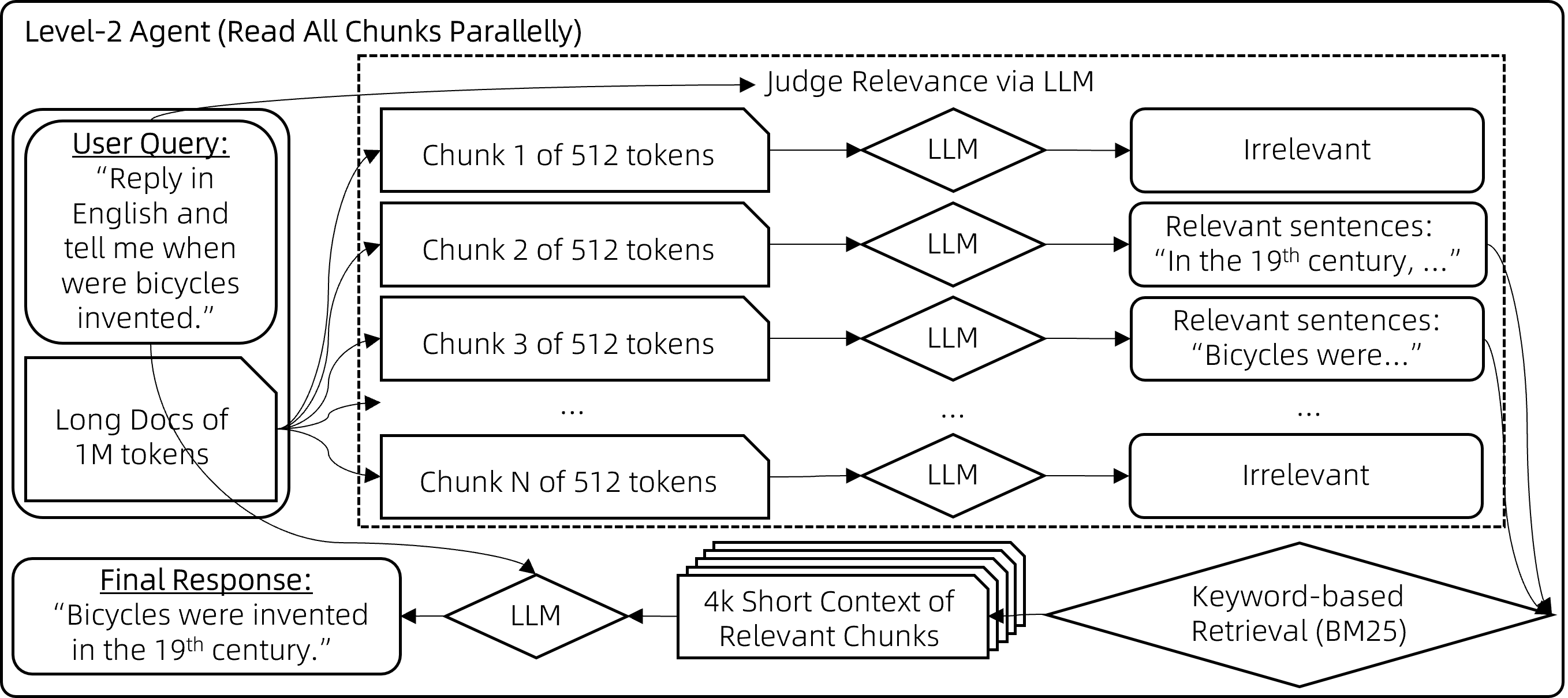
AGENT CODE:https://github.com/QwenLM/Qwen-Agent/blob/main/examples/parallel_doc_qa.py
4.2.3 Level-3:逐步推理
在基于文档的问题回答中,一个典型的挑战是多跳推理。
-
例如,考虑回答问题:“与第五交响曲创作于同一世纪的交通工具是什么?
-
模型首先需要确定子问题的答案,“第五交响曲是在哪个世纪创作的?”即19世纪。
-
然后,它才可以意识到包含“自行车于19世纪发明”的信息块实际上与原始问题相关的。
-
工具调用(也称为函数调用)智能体或ReAct智能体是经典的解决方案,它们内置了问题分解和逐步推理的能力。因此,我们将前述级别二的智能体(Lv2-智能体)封装为一个工具,由工具调用智能体(Lv3-智能体)调用。工具调用智能体进行多跳推理的流程如下:
向Lv3-智能体提出一个问题。
while (Lv3-智能体无法根据其记忆回答问题) {
Lv3-智能体提出一个新的子问题待解答。
Lv3-智能体向Lv2-智能体提问这个子问题。
将Lv2-智能体的回应添加到Lv3-智能体的记忆中。
}
Lv3-智能体提供原始问题的最终答案。

例如,Lv3-智能体最初向Lv2-智能体提出子问题:“贝多芬的第五交响曲是在哪个世纪创作的?
-
”收到“19世纪”的回复后,Lv3-智能体提出新的子问题:“19世纪期间发明了什么交通工具?”
-
通过整合Lv2-智能体的所有反馈,Lv3-智能体便能够回答原始问题:“与第五交响曲创作于同一世纪的交通工具是什么?”
4.3 RAG评测结果
我们在两个针对256k上下文设计的基准测试上进行了实验:
-
NeedleBench,一个测试模型是否能在充满大量无关句子的语境中找到最相关句子的基准,类似于“大海捞针”。回答一个问题可能需要同时找到多根“针”,并进行多跳逐步推理。
-
LV-Eval是一个要求同时理解众多证据片段的基准测试。我们对LV-Eval原始版本中的评估指标进行了调整,因为其匹配规则过于严苛,导致了许多假阴性结果。
我们比较了以下方法:
-
32k-模型:这是一个7B对话模型,主要在8k上下文样本上进行微调,并辅以少量32k上下文样本。为了扩展到256k上下文,我们采用了无需额外训练的方法,如基于RoPE的外推。
-
4k-RAG:使用与32k-模型相同的模型,但采取了Lv1-智能体的RAG策略。它仅检索并处理最相关的4k上下文。
-
4k-智能体:同样使用32k-模型的模型,但采用前文描述的更复杂的智能体策略。该智能体策略会并行处理多个片段,但每次请求模型时至多只使用模型的4k上下文。
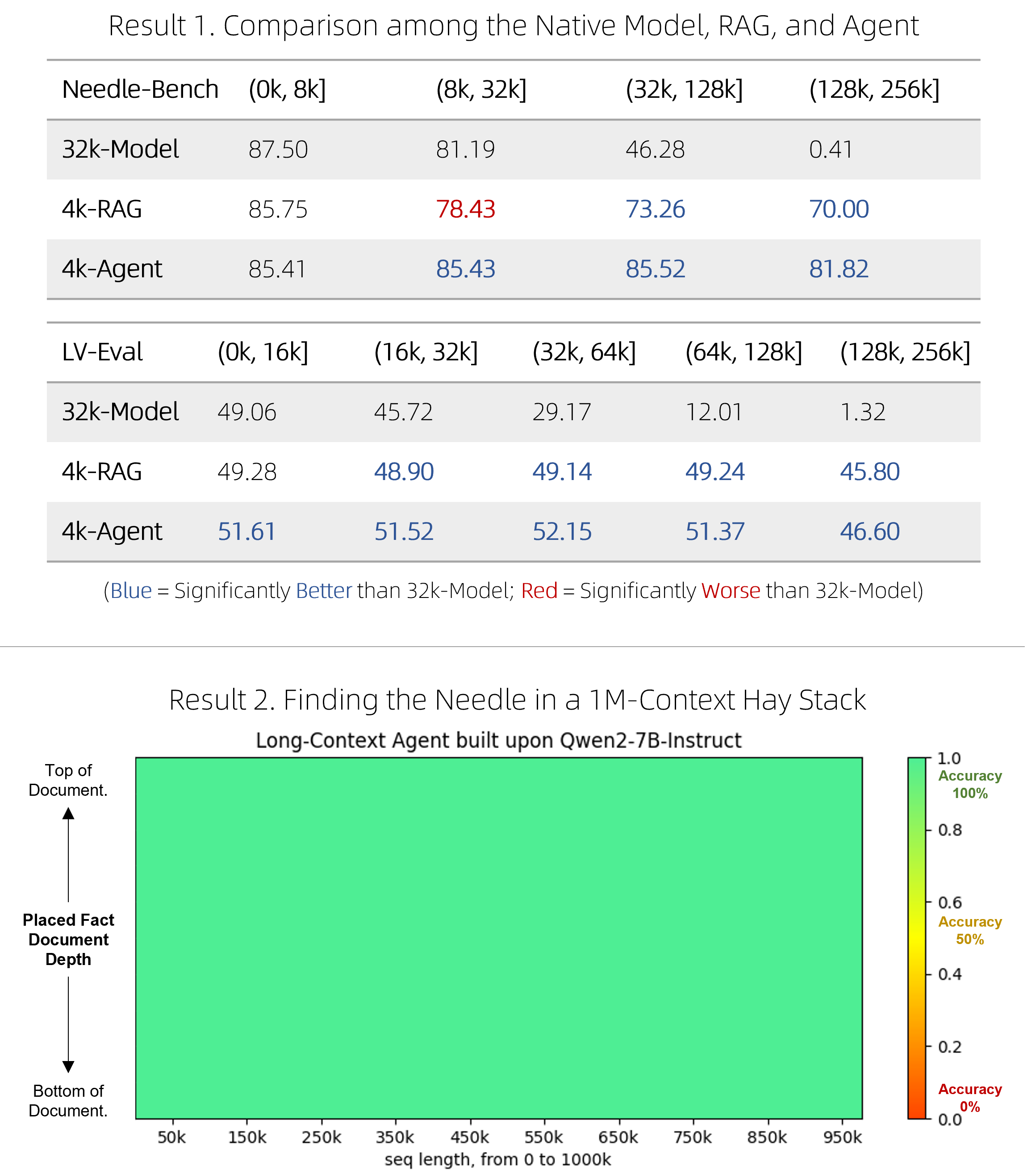
实验结果说明了以下几点:
-
在短上下文场景中,4k-RAG的表现可能不如32k-模型。这可能是由于RAG方案难以检索到正确的信息或理解多个片段造成的。
-
相反,随着文档长度的增加,4k-RAG越发表现出超越32k-模型的趋势。这一趋势表明32k-模型在处理长上下文方面并没有训练到最优的状态。
-
值得注意的是,4k-智能体始终表现优于32k-模型和4k-RAG。它分块阅读所有上下文的方式使它能够避免原生模型在长上下文上训练不足而带来的限制。
总的来说,如果得到恰当的训练,32k-模型理应优于所有其他方案。然而,实际上由于训练不足,32k-模型的表现不及4k-智能体。
最后,我们还对该智能体进行了100万个字词的压力测试(在100万个字词的大海中寻找一根针),并发现它能够正常运行。
4.4 Qwen-Agent 使用
5. RAG 质量评估
当我们完成了一个RAG系统的开发工作以后,我们还需要对RAG系统的性能进行评估,那如何来对RAG系统的性能进行评估呢?我们可以仔细分析一下RAG系统的产出成果,比如检索器组件它产出的是检索出来的相关文档即context,而生成器组件它产出的是最终的答案即answer,除此之外还有我们最初的用户问题即question。因此RAG系统的评估应该是将question、context、answer结合在一起进行评估。
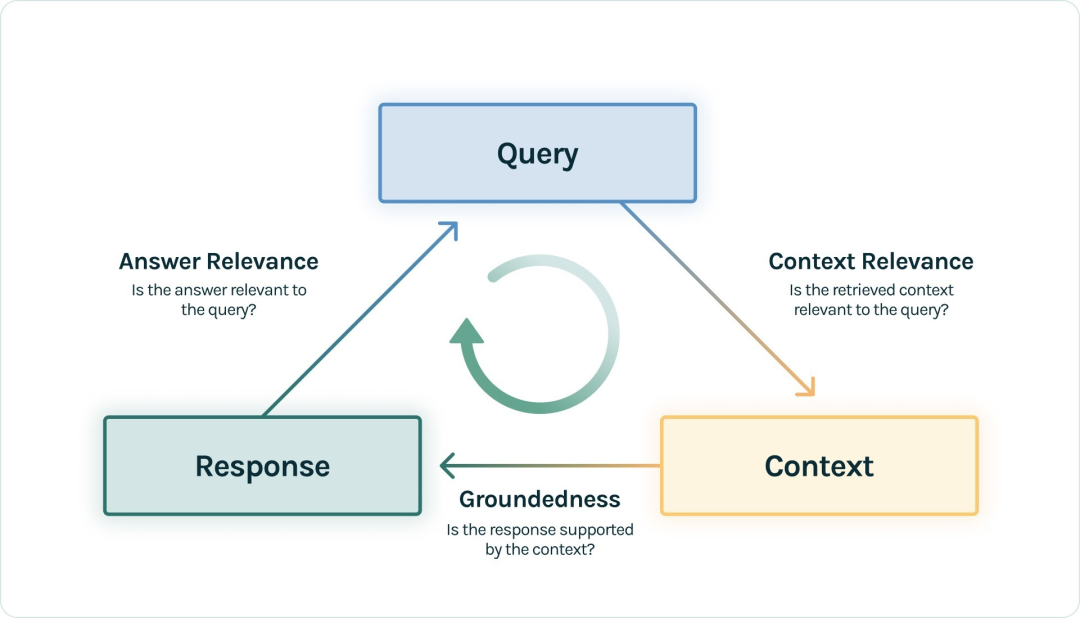
5.1 RAG 三元组
标准的 RAG 流程就是用户提出 Query 问题,RAG 应用去召回 Context,然后 LLM 将 Context 组装,生成满足 Query 的 Response 回答。那么在这里出现的三元组:—— Query、Context 和 Response 就是 RAG 整个过程中最重要的三元组,它们之间两两相互牵制。我们可以通过检测三元组之间两两元素的相关度,来评估这个 RAG 应用的效果:
-
Context Relevance: 衡量召回的 Context 能够支持 Query 的程度。如果该得分低,反应出了召回了太多与Query 问题无关的内容,这些错误的召回知识会对 LLM 的最终回答造成一定影响。
-
Groundedness: 衡量 LLM 的 Response 遵从召回的 Context 的程度。如果该得分低,反应出了 LLM 的回答不遵从召回的知识,那么回答出现幻觉的可能就越大。
-
Answer Relevance: 衡量最终的 Response 回答对 Query 提问的相关度。如果该得分低,反应出了可能答不对题。
5.2.1 什么是RAGAs评估
Ragas (Retrieval-Augmented Generation Assessment) 它是一个框架,它可以帮助我们来快速评估RAG系统的性能,为了评估RAG系统,Ragas需要以下信息:
-
question:用户输入的问题。
-
answer:从 RAG 系统生成的答案(由LLM给出)。
-
contexts:根据用户的问题从外部知识源检索的上下文即与问题相关的文档。
-
ground_truths: 人类提供的基于问题的真实(正确)答案。 这是唯一的需要人类提供的信息。
5.2.2 评估指标
Ragas提供了五种评估指标包括:
-
忠实度(faithfulness)
-
答案相关性(Answer relevancy)
-
上下文精度(Context precision)
-
上下文召回率(Context recall)
-
上下文相关性(Context relevancy)
1. 忠实度(faithfulness)
忠实度(faithfulness)衡量了生成的答案(answer)与给定上下文(context)的事实一致性。它是根据answer和检索到的context计算得出的。并将计算结果缩放到 (0,1) 范围且越高越好。
如果答案(answer)中提出的所有基本事实(claims)都可以从给定的上下文(context)中推断出来,则生成的答案被认为是忠实的。为了计算这一点,首先从生成的答案中识别一组claims。然后,将这些claims中的每一项与给定的context进行交叉检查,以确定是否可以从给定的context中推断出它。忠实度分数由以下公式得出:
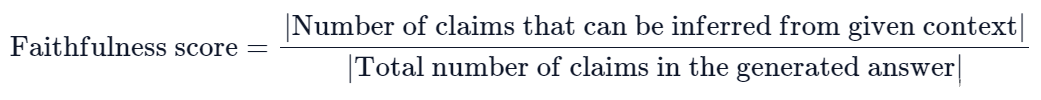
示例:

2. 答案相关性(Answer relevancy)
评估指标“答案相关性”重点评估生成的答案(answer)与用户问题(question)之间相关程度。不完整或包含冗余信息的答案将获得较低分数。该指标是通过计算question和answer获得的,它的取值范围在 0 到 1 之间,其中分数越高表示相关性越好。
当答案直接且适当地解决原始问题时,该答案被视为相关。重要的是,我们对答案相关性的评估不考虑真实情况,而是对答案缺乏完整性或包含冗余细节的情况进行惩罚。为了计算这个分数,LLM会被提示多次为生成的答案生成适当的问题,并测量这些生成的问题与原始问题之间的平均余弦相似度。基本思想是,如果生成的答案准确地解决了最初的问题,LLM应该能够从答案中生成与原始问题相符的问题。
示例:

3. 上下文精度(Context precision)
上下文精度是一种衡量标准,它评估所有在上下文(contexts)中呈现的与基本事实(ground-truth)相关的条目是否排名较高。理想情况下,所有相关文档块(chunks)必须出现在顶层。该指标使用question和计算contexts,值范围在 0 到 1 之间,其中分数越高表示精度越高。

4. 上下文召回率(Context recall)
上下文召回率(Context recall)衡量检索到的上下文(Context)与人类提供的真实答案(ground truth)的一致程度。它是根据ground truth和检索到的Context计算出来的,取值范围在 0 到 1 之间,值越高表示性能越好。
为了根据真实答案(ground truth)估算上下文召回率(Context recall),分析真实答案中的每个句子以确定它是否可以归因于检索到的Context。 在理想情况下,真实答案中的所有句子都应归因于检索到的Context。
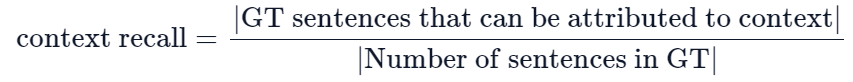
示例:

5. 上下文相关性(Context relevancy)
该指标衡量检索到的上下文(Context)的相关性,根据用户问题(question)和上下文(Context)计算得到,并且取值范围在 (0, 1)之间,值越高表示相关性越好。理想情况下,检索到的Context应只包含解答question的信息。 我们首先通过识别检索到的Context中与回答question相关的句子数量来估计 |S| 的值。 最终分数由以下公式确定:
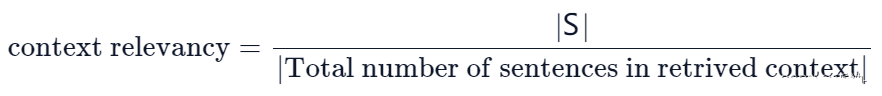

5.3. Ragas评估实操
5.3.1. 父文档检索器
文档切割时传统的做法是使用像CharacterTextSplitter, RecursiveCharacterTextSplitter这样的文档分割器将文档按指定的块大小(chunk_size)来均匀的切割文档,然后将每个文档块做向量化处理(Embedding)后将其保存到向量数据库中,而当我们在做文档检索时,会将用户的问题转换成的向量与向量数据库中的文档块的向量做相似度计算,并从中获取k个与用户问题向量相似度最高的文档块(也就是和用户问题相关的文档块),然后我们会把用户的问题以及相关的文档块一起发送给LLM, 最后LLM会给出一个对用户友好的回复。这就是一般的传统文档检索的方法。
传统检索方法其实存在一定的局限性,这是因为文档块的大小会影响和用户问题的匹配度,也就是说当我们切割的文档块越大时,它与用户问题的匹配度就会越低,当文档块越小时,它与用户问题的匹配度会越高,这是因为较大的文档块可能会包含较多的内容,当它被转换成一个固定维度的向量时,该向量可能不能够准确反应出该文档块中的所有内容,因而对用户问题的匹配度就会降低,而小的文档块包含的内容较少,当它被转换成一个固定维度的向量时,该向量基本能够准确反应出该文档块中的内容,因此它与用户问题的匹配度会教高,但是较小的文档块可能因为所包含的信息量较少,因而它可能不是一个全面且正确的答案。为了解决这些问题今天来介绍Langchain中的父文档检索器,它能够有效的解决文档块大小与用户问题匹配的问题。
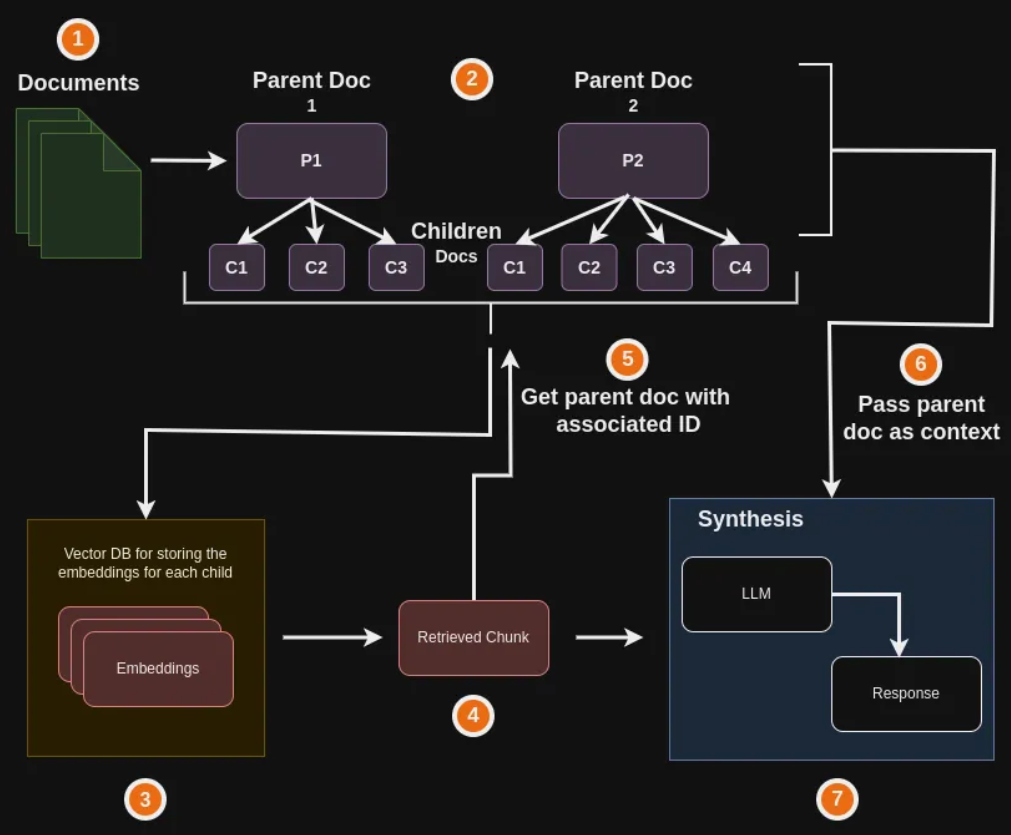
由于我们在利用大模型进行文档检索的时候,常常会有相互矛盾的需求,比如:
- 希望得到较小的文档块,以便它们Embedding以后能够最准确地反映出文档的含义,如果文档块太大,Embedding就失去了意义。
- 希望得到较大的文档块以保留教多的内容,然后将它们发送给LLM以便得到全面且正确的答案。
面对这样矛盾的需求,Langchain的父文档检索器为我们提供了两种有效的解决方案:
- 检索完整文档
- 检索较大的文档块
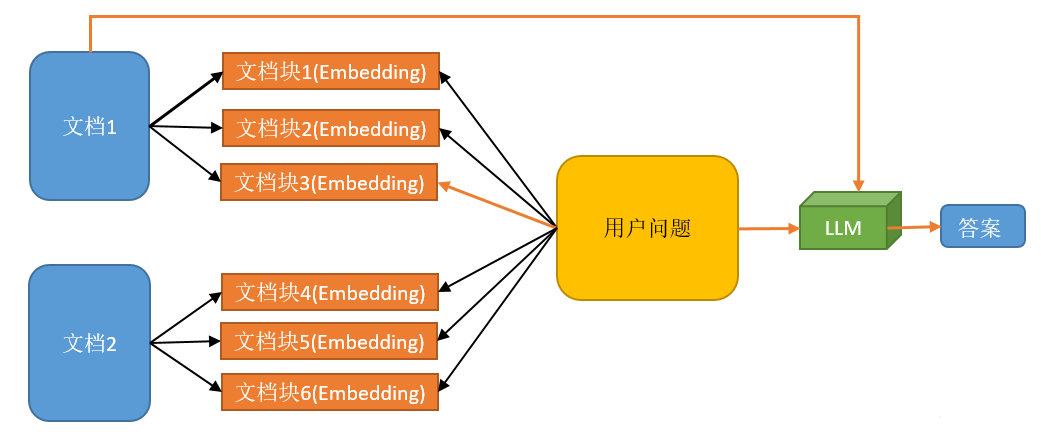
5.3.2. 检索完整文档
所谓检索完整文档是指将原始文档均匀的切割成若干个较小的文档块,然后将它们与用户的问题进行匹配,最后将匹配到的文档块所在原始文档和用户问题一起发送给llm后由llm生成最终答案,如下图所示:
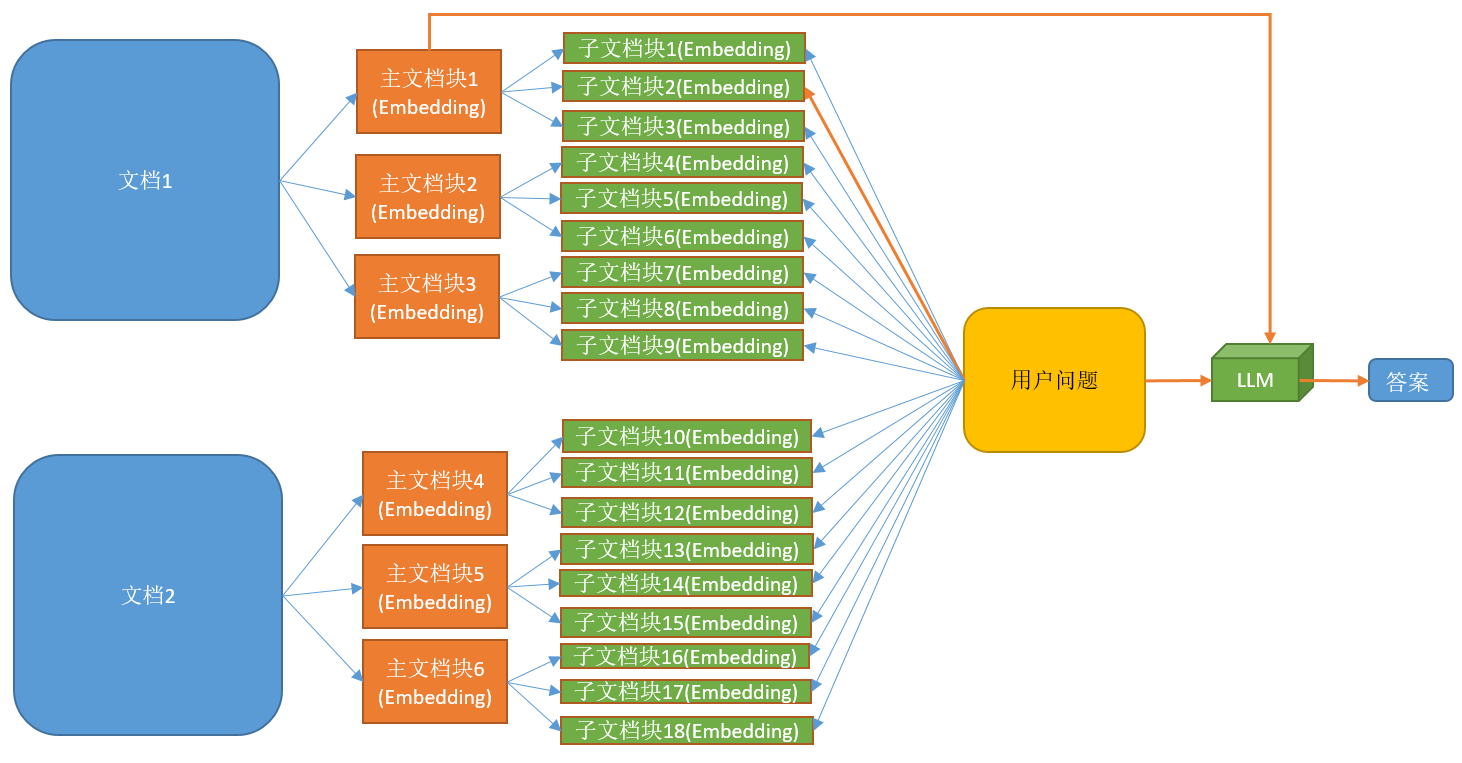
5.3.3. 检索较大的文档块
当原始文档比较大时,我们需要将原始文档按照两个层级进行切割,即切割成主文档块和子文档块,而用户的问题会与所有的子文档块进行匹配(相似度比较) ,当匹配到特定的子文档块后,将该子文档块所属的主文档块的全部内容以及用户问题发送给llm,最后由llm来生成答案。
准备环境,依赖安装
pip install pypdf
pip install ragas
pip install Pillow
pip install dashscope
pip install chromadb
pip install langchain
pip install langchain-chroma
pip install langchain_community基于 langchain 的 rag 方案:
import os
from langchain_classic.retrievers import ParentDocumentRetriever
from langchain_community.document_loaders.pdf import PyPDFLoader
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.llms import Tongyi
from langchain_chroma import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableMap
from langchain_core.stores import InMemoryStore
from langchain_text_splitters import RecursiveCharacterTextSplitter
docs = PyPDFLoader("./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf").load()
# 初始化大语言模型
DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY")
llm = Tongyi(
model_name="qwen-max",
dashscope_api_key=DASHSCOPE_API_KEY
)
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=DASHSCOPE_API_KEY
)
# 创建主文档分割器
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=512)
# 创建子文档分割器
child_splitter = RecursiveCharacterTextSplitter(chunk_size=256)
# 创建向量数据库对象
vectorstore = Chroma(
collection_name="split_parents", embedding_function=embeddings
)
# 创建内存存储对象
store = InMemoryStore()
# 创建父文档检索器
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
search_kwargs={"k": 2}
)
# 添加文档集
retriever.add_documents(docs)
# 切割出来主文档的数量
len(list(store.yield_keys()))
# 创建prompt模板(RAG Prompt)
template = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use two sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
# 由模板生成prompt
prompt = ChatPromptTemplate.from_template(template)
# 创建 chain(LCEL langchain 表达式语言)
chain = RunnableMap({
"context": lambda x: retriever.invoke(x["question"]),
"question": lambda x: x["question"]
}) | prompt | llm | StrOutputParser()
query = "客户经理被投诉了,投诉一次扣多少分?"
response = chain.invoke({"question": query})
print(response)
5.3.4 准备评估的QA数据集
准备评估数据集,对 RAG 方案进行评估
from datasets import Dataset
# 保证问题需要多样性,场景化覆盖
questions = [
"客户经理被投诉了,投诉一次扣多少分?",
"客户经理每年评聘申报时间是怎样的?",
"客户经理在工作中有不廉洁自律情况的,发现一次扣多少分?",
"客户经理不服从支行工作安排,每次扣多少分?",
"客户经理需要什么学历和工作经验才能入职?",
"个金客户经理职位设置有哪些?"
]
ground_truths = [
"每投诉一次扣2分",
"每年一月份为客户经理评聘的申报时间",
"在工作中有不廉洁自律情况的每发现一次扣50分",
"不服从支行工作安排,每次扣2分",
"须具备大专以上学历,至少二年以上银行工作经验",
"个金客户经理职位设置为:客户经理助理、客户经理、高级客户经理、资深客户经理"
]
answers = []
contexts = []
# Inference
for query in questions:
answers.append(chain.invoke({"question": query}))
contexts.append([docs.page_content for docs in retriever.invoke(query)])
# To dict
data = {
"user_input": questions,
"response": answers,
"retrieved_contexts": contexts,
"reference": ground_truths
}
# Convert dict to dataset
dataset = Dataset.from_dict(data)
print(dataset)
# 评测结果
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
result = evaluate(
dataset=dataset,
metrics=[
context_precision, # 上下文精度
context_recall, # 上下文召回率
faithfulness, # 忠实度
answer_relevancy, # 答案相关性
],
embeddings=embeddings,
llm=llm,
)
df = result.to_pandas()6. 商业落地实施 RAG 工程核心步骤
1. 数据集的准备(语料)
- 文档结构化处理:采用现代的智能文档技术
2. 测试集的准备(QA对)
- 使用主流的 LLM 模型来根据文档来生成 QA 对
3. 技术选型
- 零代码搭建: DB-GPT / Dify / RAGFlow / Coze Studio...
- 低代码搭建: Qwen-Agent / TrustRAG / GraphRAG / LightRAG
- 高度定制开发:LlamaIndex / LangChain / LangGraph
如果公司没有技术团队,可以基于Dify、RAGFlow等零代码工具做一个初版。如果要写抖音文案,Coze是首选;如果要处理复杂的 pdf ,基于公司资料回答问题,RAGFlow 效果很好。如果有工作流的链式可以用 Dify。
如果你是一个开发者,可以用 Qwen-Agent 和 TrustRAG 进行快速开发。GraphRAG 和 LightRAG 是基于知识图谱的。
如果公司里有技术团队,需要定制化开发相应的 AI 系统,推荐使用 LangChain 和 LangGraph。LlamaIndex 的优点在于知识库的处理。
LangChain 关心的是怎么做 AI 应用,怎么把模型的能力给用起来,怎么帮助我们解决一些特定的问题给出一些开发范式,比如说怎么去对长文本在有限上下文的前提下去处理。LangChain 提出了文档切片,链式的对文档切片进行处理,也可以构建一个更好的生产链,来完成对大型文档的处理。ChatPDF 就是基于 LangChain 来实现的一个产品。
4. 构建知识库
- 离线向量数据库
5. 测试和优化
- 根据不同的阶段来进行优化处理
- 数据预处理,结构化处理
- 切片策略
- 召回策略
- 重排序
- RAFT
6. 最终效果评估
- Ragas 来进行 RAG 性能的评估
7. 生产环境部署
- 本地模型部署 vLLM
更多推荐

 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)