
在SCNet超算平台用LLaMA Factory 训练与微调大模型 以GLM4-9B为例
LLaMAFactory是一个高效的大语言模型训练与微调平台,通过模块化设计降低使用门槛。在SCNet超算平台上,用户可快速创建LLaMAFactory环境,选择模型镜像后启动服务。系统支持端口转发(如7860端口),用户可通过浏览器访问WebUI界面。平台提供实时训练监控功能,包括loss值、学习率等指标变化,如示例中GLM4模型的微调过程显示loss持续下降,验证了训练的有效性。该平台整合了1
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。官网:GitHub - hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
快速入门教程:LLaMA-Factory QuickStart - 知乎
LLaMA Factory作为当前主流的大模型微调框架,其核心价值在于通过模块化设计降低技术门槛
在SCNet超算平台启动LLaMA Factory环境
创建超算LLaMA Factory环境
登录之后,进入“控制台” - “创建notebook”,选择“异构网络”
之所以选择异构网络,是因为目前它有一定的优惠额度,比如赠送一部分机时。
“开发镜像” 直接选模型镜像里的第一个jupyterlab-llamafactory
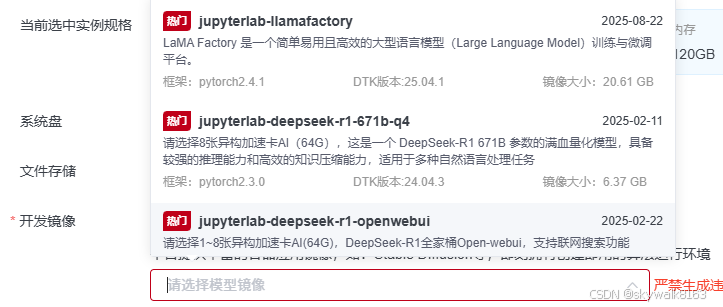
启动LLaMA Factory
启动镜像,会自动打开一个notebook,运行里面的指令
%cd /root/LLaMA-Factory
!USE_MODELSCOPE_HUB=1 MODELSCOPE_CACHE=/root/private_data/llamafactory/ HF_HOME=/root/private_data/llamafactory/ llamafactory-cli webuiLLaMA Factory服务一会儿就启动成功了。
[2025-10-21 19:32:47,138] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect) INFO 10-21 19:32:50 [importing.py:53] Triton module has been replaced with a placeholder. INFO 10-21 19:32:50 [__init__.py:240] Automatically detected platform rocm. Visit http://ip:port for Web UI, e.g., http://127.0.0.1:7860 * Running on local URL: http://0.0.0.0:7860
设定自定义服务转发服务器端口7860
超算网络非常棒的一点就是,它能公开一个端口服务。比如LLaMA Factory服务端口是7860, 那么设定服务器端口号7860,系统就会自动把这个服务转发出来。
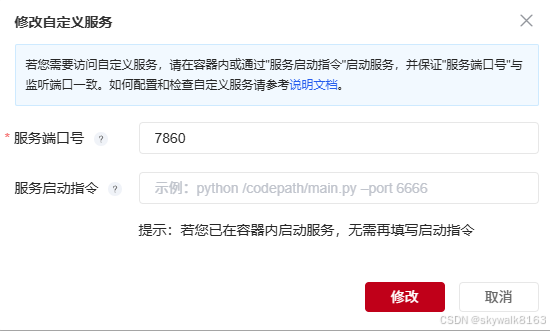
比如转成这个地址:
https://c-1980597850741735425.ksai.scnet.cn:58043/每个人的转发域名和端口都是不一样的。
在本地,就可以用浏览器来登录LLaMA Factory的服务器了。
进行LLaMA Factory大模型微调服务
进入LLaMA Factory界面,如图:
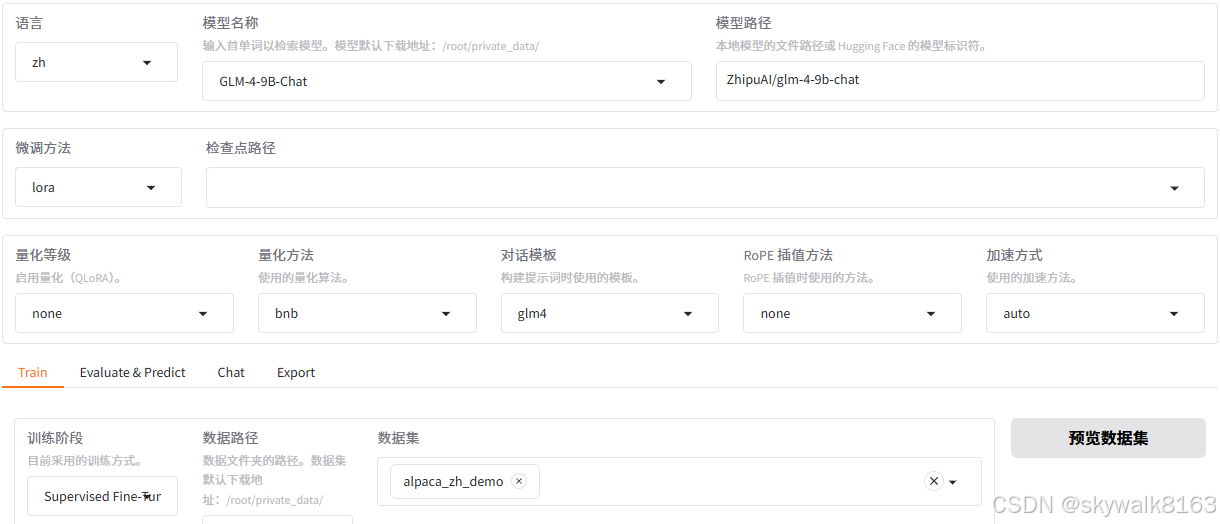
这时候就可以动动鼠标,选择自己心仪的模型进行微调了,比如这次用的是glm4模型进行微调。
微调跟踪信息如下:
[INFO|2025-10-21 20:01:59] trainer.py:2422 >> Total optimization steps = 186
[INFO|2025-10-21 20:01:59] trainer.py:2423 >> Number of trainable parameters = 21,176,320
[INFO|2025-10-21 20:02:14] logging.py:143 >> {'loss': 2.5381, 'learning_rate': 5.0000e-05, 'epoch': 0.02, 'throughput': 190.47}
[INFO|2025-10-21 20:02:20] logging.py:143 >> {'loss': 2.4014, 'learning_rate': 4.9996e-05, 'epoch': 0.03, 'throughput': 271.37}
[INFO|2025-10-21 20:02:25] logging.py:143 >> {'loss': 1.9824, 'learning_rate': 4.9986e-05, 'epoch': 0.05, 'throughput': 326.51}
[INFO|2025-10-21 20:02:32] logging.py:143 >> {'loss': 1.7461, 'learning_rate': 4.9968e-05, 'epoch': 0.06, 'throughput': 365.96}
[INFO|2025-10-21 20:02:37] logging.py:143 >> {'loss': 2.3477, 'learning_rate': 4.9943e-05, 'epoch': 0.08, 'throughput': 370.33}
[INFO|2025-10-21 20:02:43] logging.py:143 >> {'loss': 2.1494, 'learning_rate': 4.9911e-05, 'epoch': 0.10, 'throughput': 382.59}
[INFO|2025-10-21 20:02:48] logging.py:143 >> {'loss': 2.0664, 'learning_rate': 4.9872e-05, 'epoch': 0.11, 'throughput': 390.36}
[INFO|2025-10-21 20:02:55] logging.py:143 >> {'loss': 1.9404, 'learning_rate': 4.9825e-05, 'epoch': 0.13, 'throughput': 396.26}
[INFO|2025-10-21 20:03:00] logging.py:143 >> {'loss': 1.9365, 'learning_rate': 4.9772e-05, 'epoch': 0.14, 'throughput': 392.07}
.......
[INFO|2025-10-21 20:07:33] logging.py:143 >> {'loss': 1.4414, 'learning_rate': 3.9626e-05, 'epoch': 0.91, 'throughput': 468.26}
[INFO|2025-10-21 20:07:39] logging.py:143 >> {'loss': 1.2930, 'learning_rate': 3.9282e-05, 'epoch': 0.93, 'throughput': 465.94}可以看到,loss一直在减小,证明微调正在进行中。
好几年没有进行模型的训练了,看loss一点点减少感觉好亲切啊!
微调之后eval、chat和导出
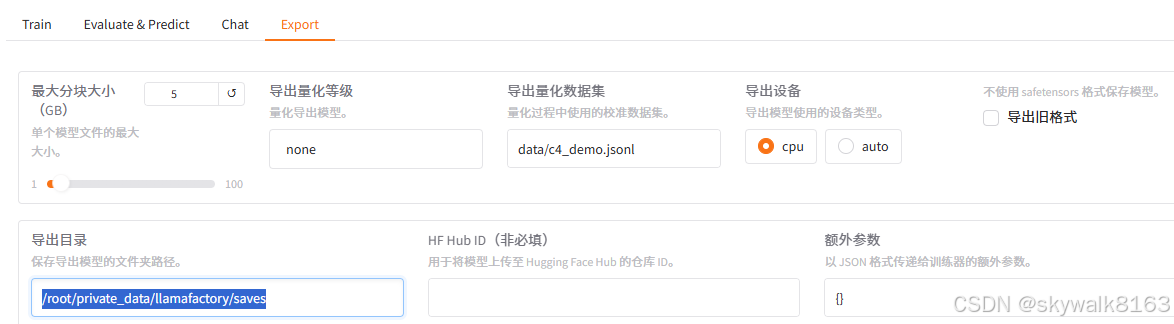
直接鼠标点击eval ,就可以进行评估操作。
点击chat可以进行文本chat交互
点击export,即可导出微调的模型。比如模型导出到/root/private_data/llamafactory/saves 目录。
更多推荐


 47
47 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)