
verl: an Open-SourceLarge-Scale LLM RL Framework forAgentic Tasks
RL与SFT对比:SFT基于标注数据训练单个模型,而RL通过多模型奖励优化。RL在LLM领域日益重要,涉及人类对齐、数学推理、多模态生成和智能体应用。RL数据流复杂,包含多模型、多阶段和多任务,且面临数据依赖和资源限制的挑战。Verl开源项目(GitHub 10k+星)提供高效RL解决方案,支持多种算法扩展、3D混合引擎优化、模块化API集成和灵活设备映射,并兼容超大规模模型(如671B参数)。其
SFT vs RL
Supervised fine-tuning
● Learning from labeled examples
● Play with a single model
Reinforcement learning
● Optimization based on rewards
● Play with multiple models
RL is becoming important
• Human Alignment with RLHF
• Reasoning: O1/Claude-3.7 performance on math benchmarks
• Image/video/music generation
• Agentic LLM tool using
• Desktop operator, coding assistant, Gaming
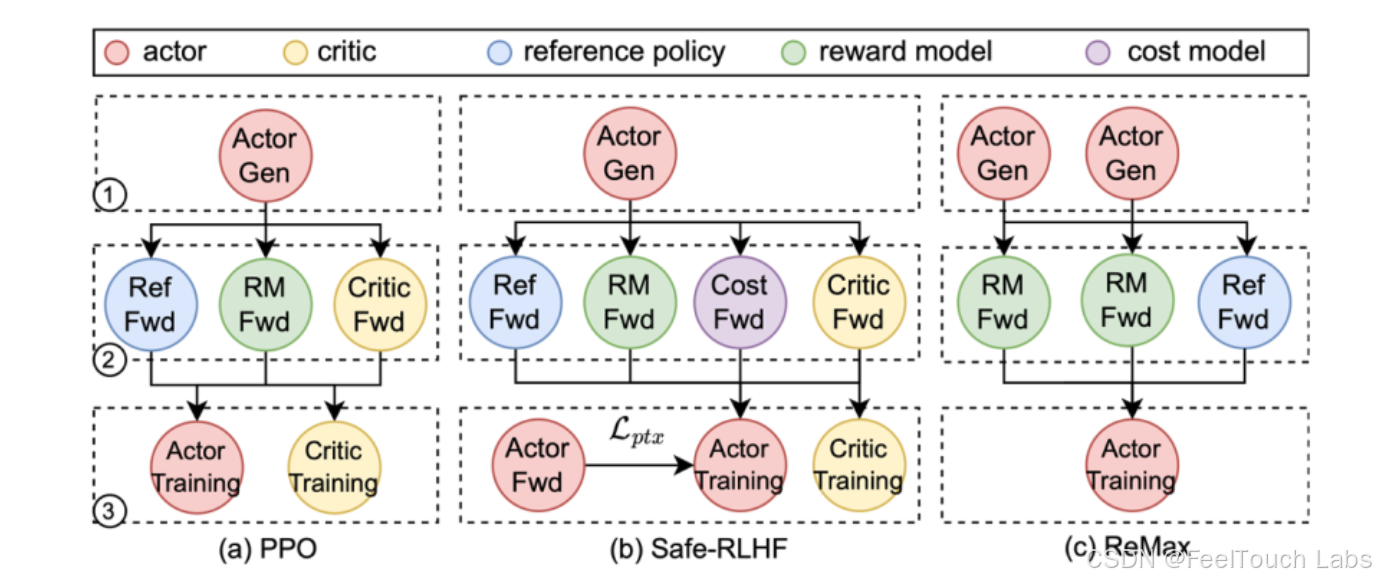
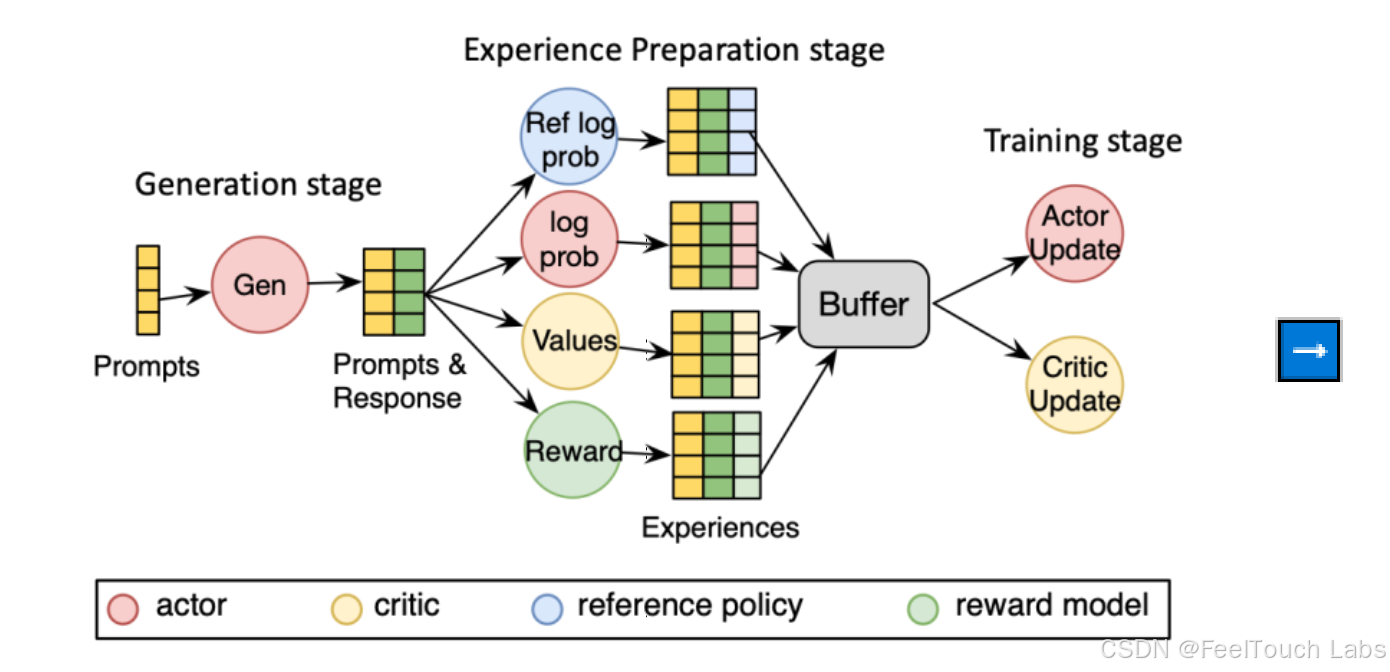
RL is Complex Dataflow
Reinforcement Learning (RL) can be modelled as complex dataflow graph
(Schaarschmidt et al. 2019; Liang et al. 2021; Sheng et al. 2025), consisting of:,
● multiple models: actor, critic, reference, reward model, etc.
● multiple stages: generating, preparing experiences, training
● multiple workloads: generation, inference, training
RL with LLMs is Large-Scale Distributed Dataflow
Training needs ND parallelisms (Megatron-LM)
● Growing model size: Qwen 235B, Deepseek 671B
● Growing sequence length: 8k -> 1M
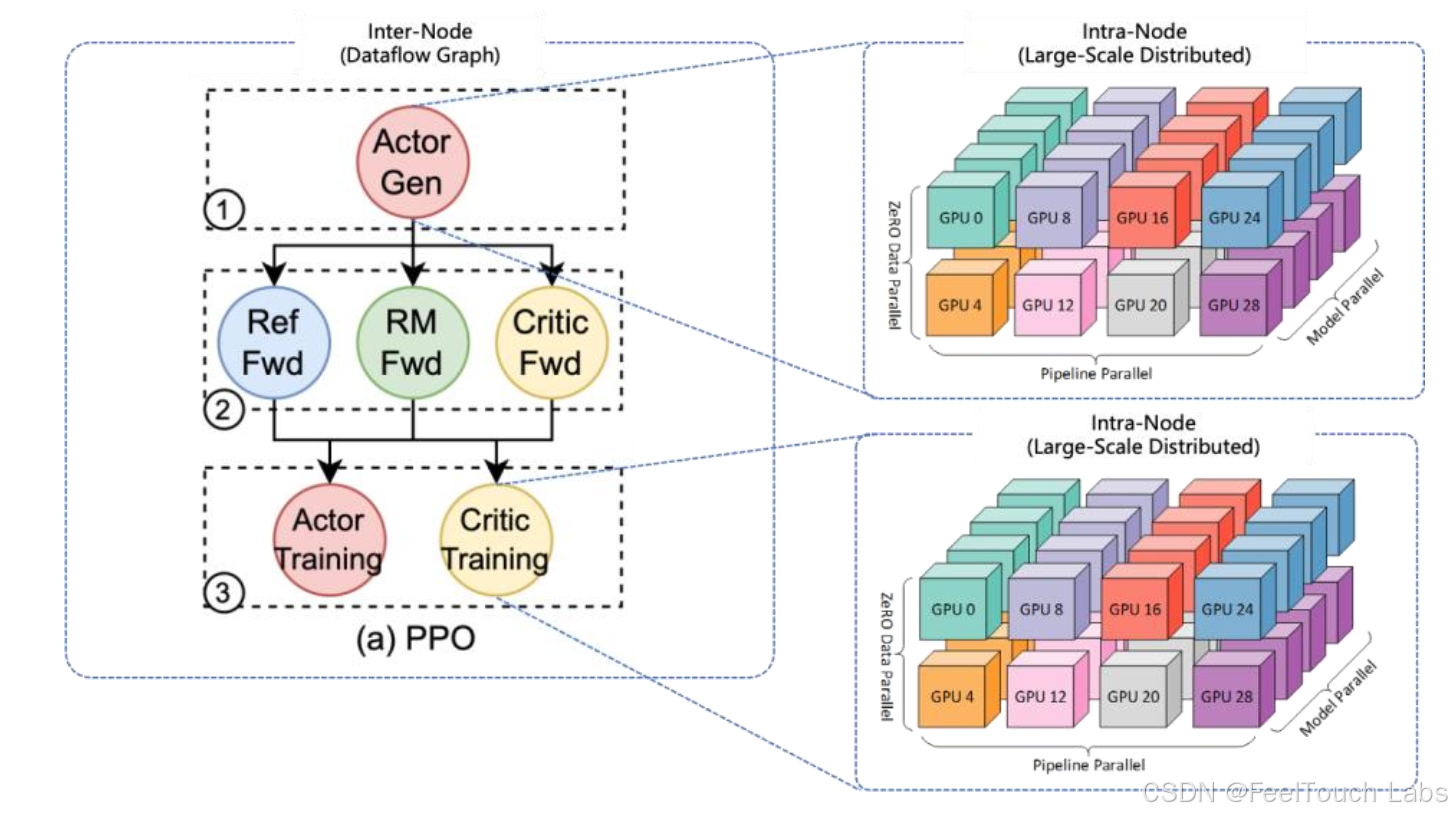
Each operator in the RL dataflow = a large-scale distributed computing workload
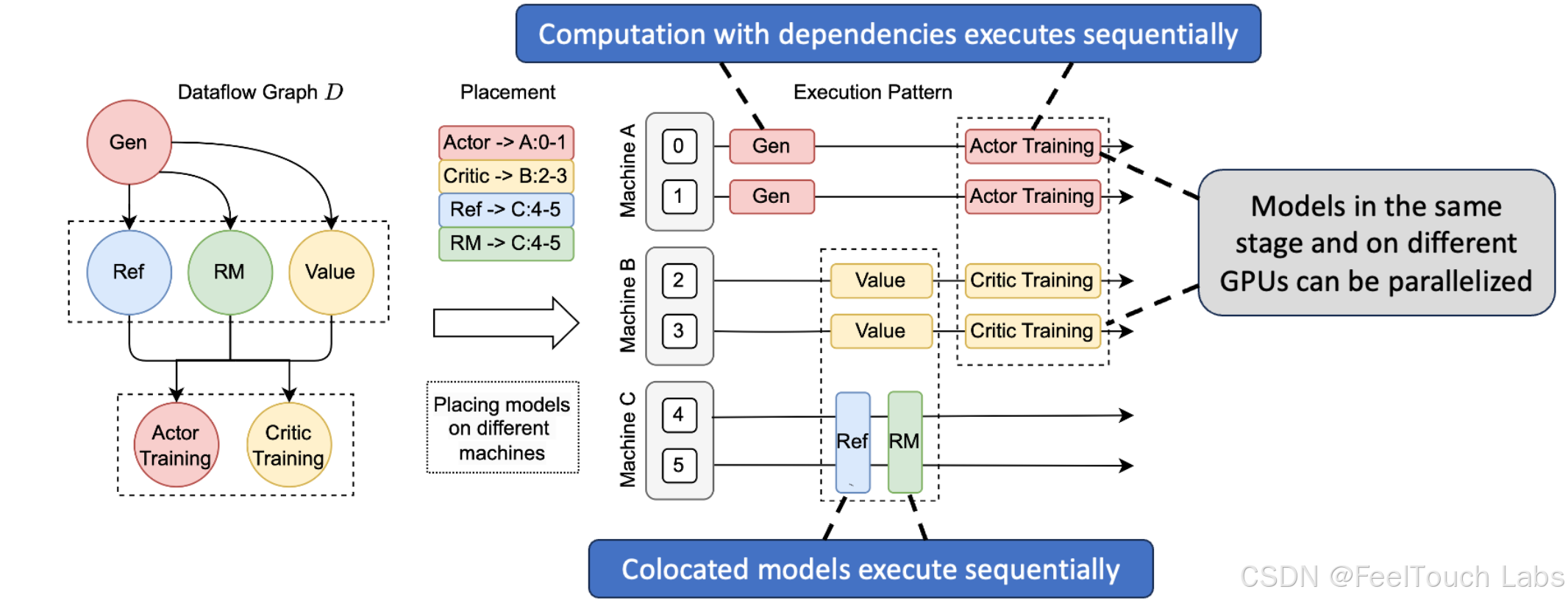
RL dataflow is hard to implementation: Data Dependencies & Resource Limitations
Implementing RL algorithm with LLMs requires complex trade-offs between
various constraints.
Verl’s Open-Source Community
https://github.com/volcengine/verl
So far, verl has gained:
● 10k+ stars
● 1k+ forks
● 1.1k+ PRs
● 250+ contributors
Many popular RL projects are
built on top of verl, including:
● TinyZero (12k stars)
● SimpleRL-Zoo (3.6k stars)
● rllm (3.3k stars)
● SkyThought (3.3k stars)
● OpenManus-RL (2.9k stars)
● …
Verl’s Highlight Features
• Easy extension of diverse RL algorithms: The hybrid-controller programming model enables
building RL dataflows such as GRPO, PPO in a few lines of code.
• Efficient actor model resharding with 3D-HybridEngine: Eliminates memory redundancy and
significantly reduces communication overhead during transitions between training and generation
phases.
• Seamless integration of existing LLM infra with modular APIs: Decouples computation and data
dependencies, reuses existing LLM frameworks, such as FSDP, Megatron-LM, vLLM, SGLang, etc
• Flexible device mapping: Supports various placement of models onto different sets of GPUs for
efficient resource utilization and scalability across different cluster sizes.
• Wide Model Supports: besides from Qwen 7/32B small models, large MoEs like DeepSeek
671B/Qwen 235B are also supported.
• State-of-the-art throughput: SOTA LLM training and inference engine integrations and SOTA RL
throughp
Verl’s Distributed Paradigm: Hybrid-Controller
1. Single-Controller (MPMD)
A centralized controller manages all the workers, running different programs
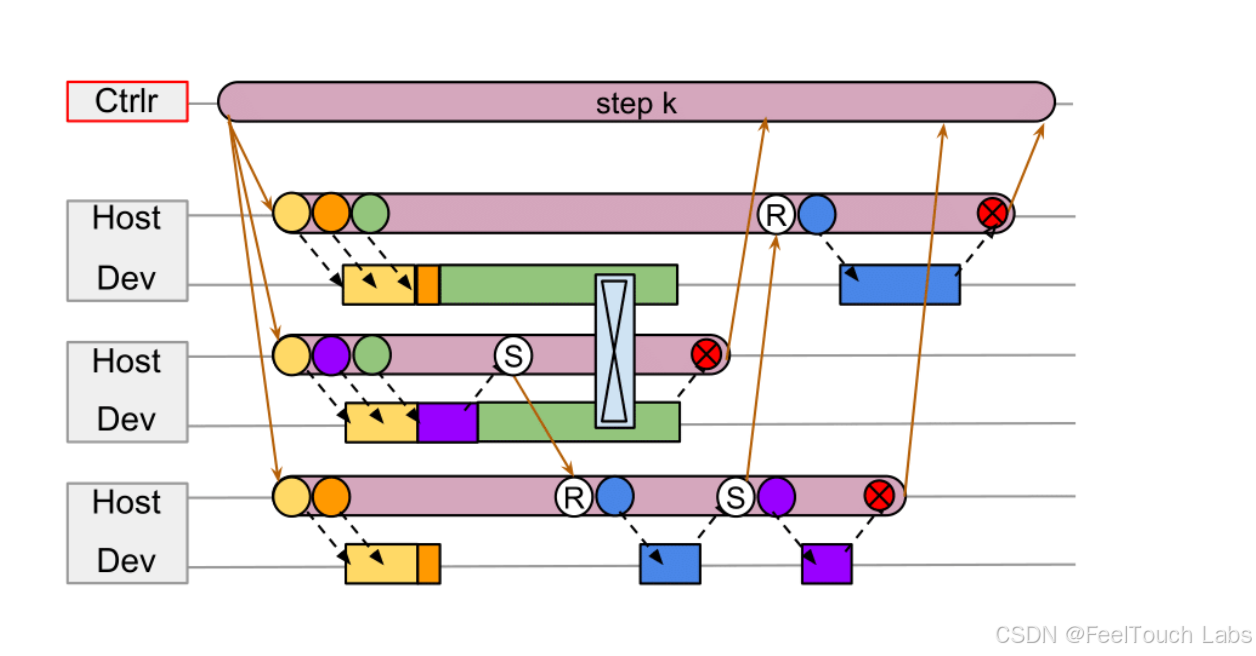
2. Multi-Controller (SPMD)
Each worker has its own controller,running the same program with different data
3. Hybrid-Controller
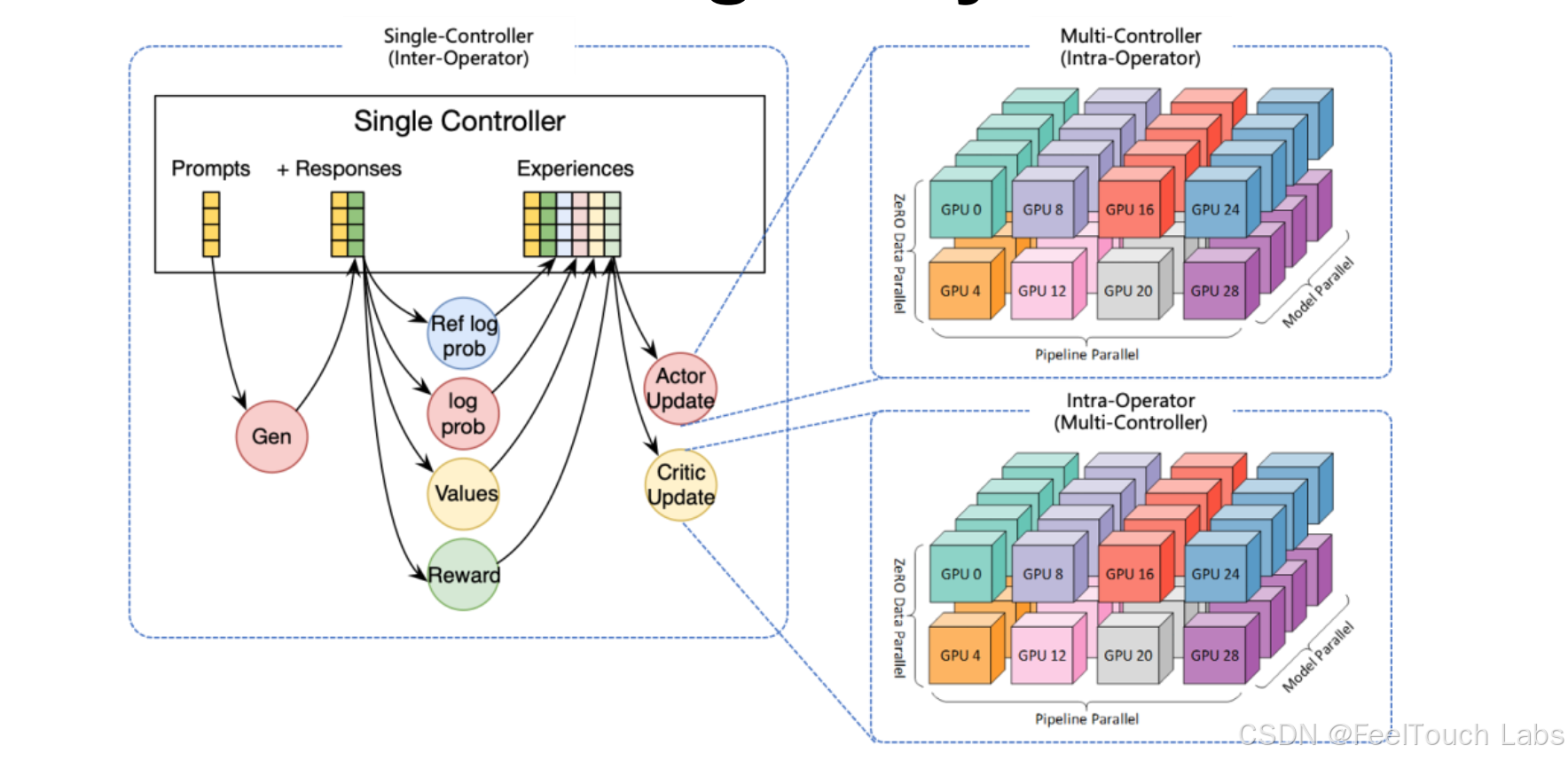
● Hybrid-Controller = Single-Controller + N x Multi-Controller
● In the hybrid-controller, a single-controller manages multiple multi-controllers
to process the dataflow
Flexibility in Programming: “Single-Controller”

With single-controller, RL algorithm core logic is implemented in a few lines of
code! Facilitate diverse RL algorithms
like: PPO, GRPO, RLOO, ReMax, PRIME, DAPO, etc
Efficiency: “Multi-Controller”
“multi-controller” paradigm is efficient for intra-operator executions and includes features like:
Parallelism Algorithms:
● Data Parallelism
● Tensor Parallelism
● Pipeline Parallelism
● Context / Sequence Parallelism
● …
Efficient Kernels:
● Flash Attention 2/3
● Torch Compile
● Liger Kernel
● …
Training Backends:
● FSDP
● FSDP2
● Megatron
● torchtitan
Inference Backends:
● vLLM
● SGLang
● …
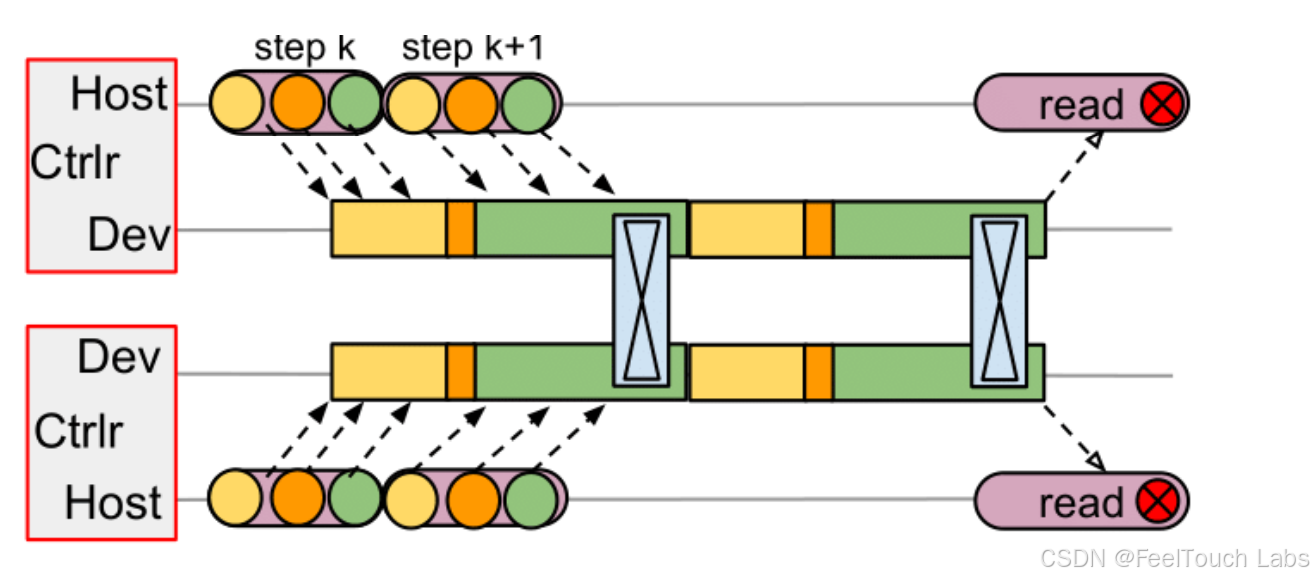
Hybrid Engine: Speedup Collocating Rollout and Trainer
Collocate Strategy: Uses the same grouping strategy in both training and generation stages.
Split Strategy: Uses the different grouping strategy in training and generation stages.
Collocate Strategy is efficient with 3D-HybridEngine:
● Significantly reduces communication overhead during transitions between training and
generation phases.
● Offloading & reloading enables fully utilizing the GPU memory
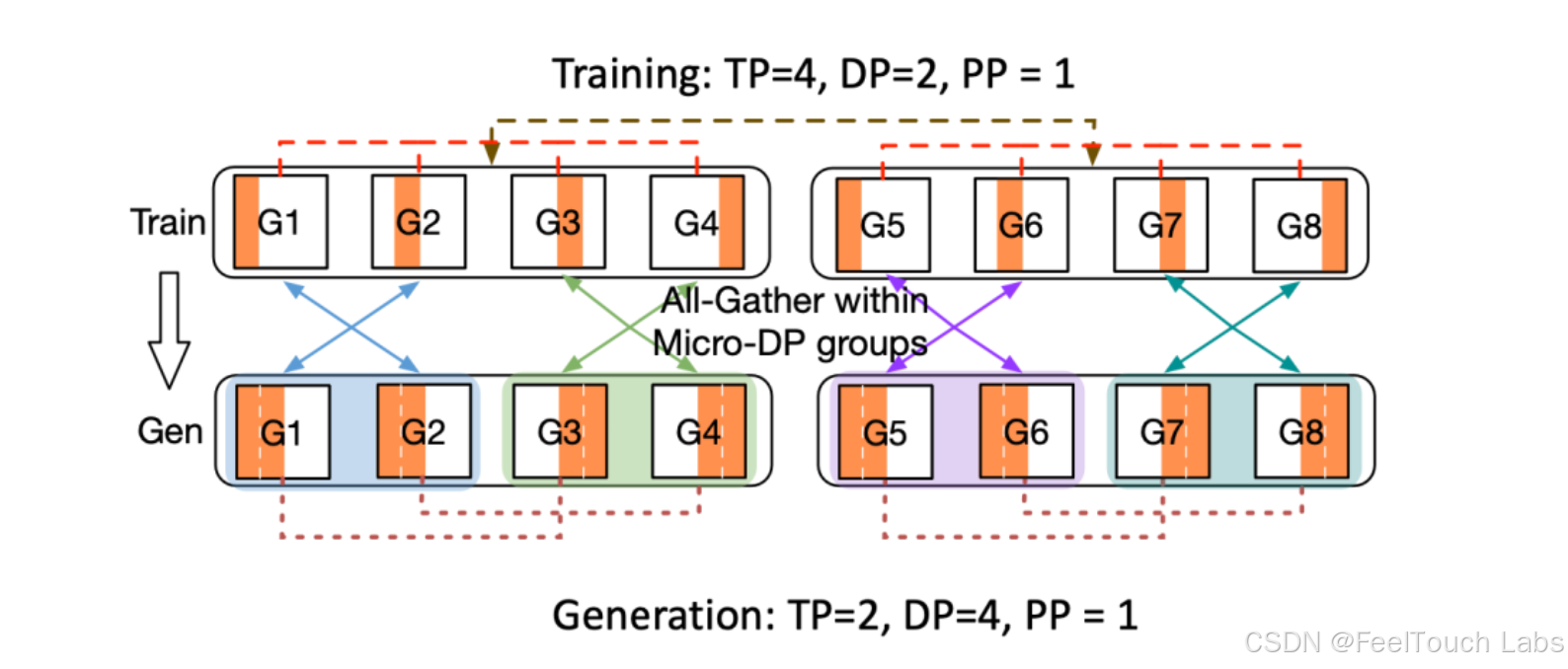
Programming using verl

● Each call in the single-controller
(e.g. critic.compute_values, actor.update_actor) is an RPC to a multicontroller worker group
● The register decorator utility manages the distributed data transfer between
dataflow nodes, which also makes multi-controller programming easier
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)