
放弃微调,斯坦福联合发布智能体上下文工程(ACE),模型性能提高10%,token成本降低83%
斯坦福、桑巴诺瓦系统公司(SambaNova Systems)和伯克利联手搞了个新框架,叫“智能体上下文工程”(Agentic Context Engineering, ACE),让模型像人一样,通过复盘和迭代来自我进化。关键是,这个过程不动模型权重,成本还暴降。看看这性能提升:这事儿挺颠覆的。
斯坦福、桑巴诺瓦系统公司(SambaNova Systems)和伯克利联手搞了个新框架,叫“智能体上下文工程”(Agentic Context Engineering, ACE),让模型像人一样,通过复盘和迭代来自我进化。关键是,这个过程不动模型权重,成本还暴降。

看看这性能提升:
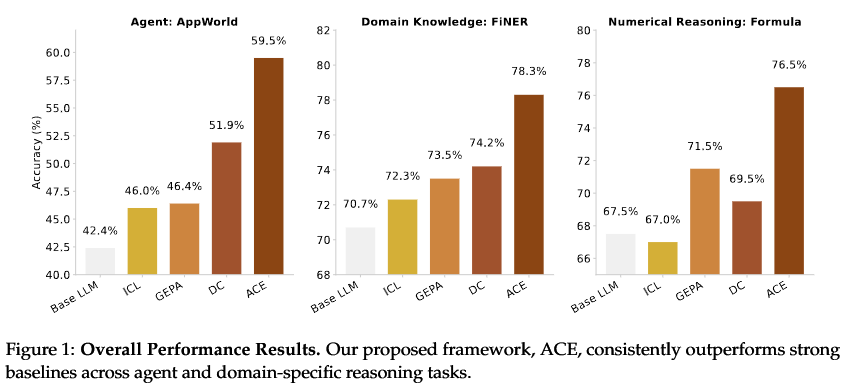
这事儿挺颠覆的。
增强模型性能的微调路子
大模型训练好后,想让它在特定领域干活干得更漂亮,传统手艺是微调。
就是拿一堆特定领域的数据,去重新训练模型的一部分参数。这法子有效,但缺点跟优点一样突出。
微调一次,计算资源烧消耗大,迭代周期也长。对于需要快速响应市场变化的企业来说,这节奏太慢。
它像个黑箱,参数调完,模型为什么表现变好了,或者为什么在某个地方搞砸了,你很难说清楚。这种不可解释性在金融、医疗这些高风险领域是要命的。
微调过的模型容易“灾难性遗忘”,学了新知识,忘了老本行。
所以,圈内人一直在找新出路。
“上下文适应”(context adaptation)技术就这么出现了:别去动模型那几千亿个参数了,咱们直接在给模型的输入(也就是“上下文”)上做文章。
跟人沟通,想让对方更好地理解任务,最好要把任务要求、背景资料、注意事项写得清清楚楚递给他,并进行多轮沟通。
这个上下文也类似,可以是系统提示(system prompt),可以是一些成功的案例(证据),也可以是模型之前犯错后总结的经验(记忆体)。
它的好处显而易见:内容看得懂,能修改,能调试,还能在不同模型之间共享。加上现在LLM的上下文窗口越来越长,像打了激素一样能塞进几十万甚至上百万个词,再配合KV缓存复用(KV cache reuse)这种让长文本推理变快的技术,上下文适应俨然成了新时代的宠儿。
上下文方法的两个缺陷
当然,通往成功的路总是坑坑洼洼。
之前的上下文适应方法,虽然方向对了,但普遍走进了两个死胡同。
第一个叫“简洁性偏见”(brevity bias)。很多自动优化上下文的方法,总想着把指令写得越短越好,越通用越好。比如一个叫GEPA的框架就觉得简洁是优点。
这在一些简单任务上没问题,但在需要大量领域知识和细节操作的复杂场景,比如让一个智能代理(Agent)去调用各种工具完成一个多步骤任务,这种“少即是多”的哲学就行不通了。
第二个叫“上下文坍塌”(context collapse)。这个问题发生在让LLM自己去迭代和重写整个上下文的时候。你想让它总结经验,变得更好,结果它总结一次,信息就丢一点,像复印机一样,越复印越模糊。几轮迭代下来,模型的表现断崖式下跌。
在高可靠性、高细节要求的场景里,我们需要的是知识的积累和丰富,而不是无休止的压缩。
ACE框架,让上下文“活”起来
面对这两个大坑,斯坦福、SambaNova和伯克利的联合团队提出的ACE框架,给出了一个全新的解法。
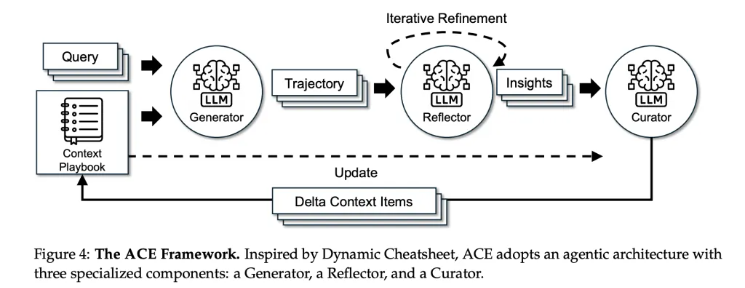
ACE的核心思想,是把上下文从一张静态的“说明书”,变成一本动态演进的“战术手册”(playbook)。这本手册不是每次都重写,而是采用增量更新的方式,不断把新的经验教训补充进去。
这个过程被巧妙地设计成了一个由三个角色协同工作的流水线,而且这三个角色都由同一个基础LLM(实验用的是非推理增强版的DeepSeek-V3.1)扮演,这样就能确保性能的提升完全来自于上下文的优化,而不是模型本身的能力差异。
这三个角色分别是:
-
生成器(Generator):它的任务就是干活。像一个初出茅庐的代理,去执行具体的任务,比如调用工具、进行推理。它会生成一串完整的操作记录,这里面有成功的操作,也有失败的踩坑记录。
-
反思器(Reflector):这是个事后诸葛亮。它会分析生成器留下的操作记录,从中提炼出具体、可操作的经验教训。比如,“在处理A类文件时,用B工具总是会报错,应该改用C工具”,或者“当遇到X情况时,直接执行Y步骤比先问询更高效”。它把这些零散的感悟,变成结构化的文本。
-
策展人(Curator):这是战术手册的总编辑。它接收反思器提炼出的经验,把它转换成标准格式的“增量项”(delta items),然后用一种确定性的方式合并到现有的战术手册里。这个合并过程包括了去重、修剪和整理,确保手册内容越来越丰富、有针对性,同时又保持清晰和可管理。
这个“生成-反思-策展”的循环,有点像一个顶级的运动队。
生成器是场上比赛的球员,负责打比赛,所有的成功和失误都被录像记录下来。反思器是赛后看录像的教练组,逐帧分析,找出问题所在,总结出战术要点。策展人是负责更新战术板的助理教练,把教练组的新战术清晰、准确地画到板上,供下一场比赛使用。
通过这种增量更新的“增长-精炼”(Grow-and-Refine)原则,ACE彻底避免了上下文坍塌。知识只会被积累和优化,不会被遗忘和简化。而且整个过程是无监督的,它不需要人工标注的数据,只需要任务本身的执行反馈(比如成功或失败的信号)就能自我驱动。
ACE的测试表现
ACE框架在两类任务上进行了严格的测试:智能代理和领域专用基准。
AppWorld智能代理任务,是一个专门用来评测AI代理在模拟的手机应用世界里完成日常任务能力的基准。任务很复杂,需要模型能理解指令,调用API,和环境进行多轮互动。
结果怎么样?
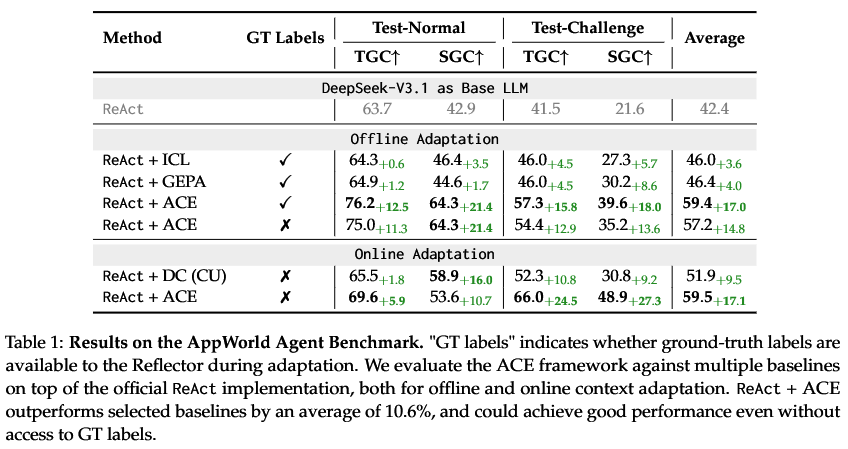
相较于所选基准模型,平均性能提升了 10.6%;即便在无法获取“GT 标签”(对数据或任务结果的真实标注,是评估模型性能的参照标准)的情况下,该方案仍能实现良好性能。
更惊人的是,在2025年9月20日的AppWorld公开排行榜上,ReAct+ACE的成绩是59.4%,跟当时排名第一、基于更强大GPT-4.1模型的商业级代理IBM CUGA(60.3%)几乎持平。在难度更高的“挑战”子集上,ACE甚至还超过了CUGA。要知道,ACE用的是一个更小的开源模型。
金融领域的专业任务,包括金融命名实体识别(FiNER)和XBRL公式数值推理。这类任务需要精准的领域知识和专门的策略。
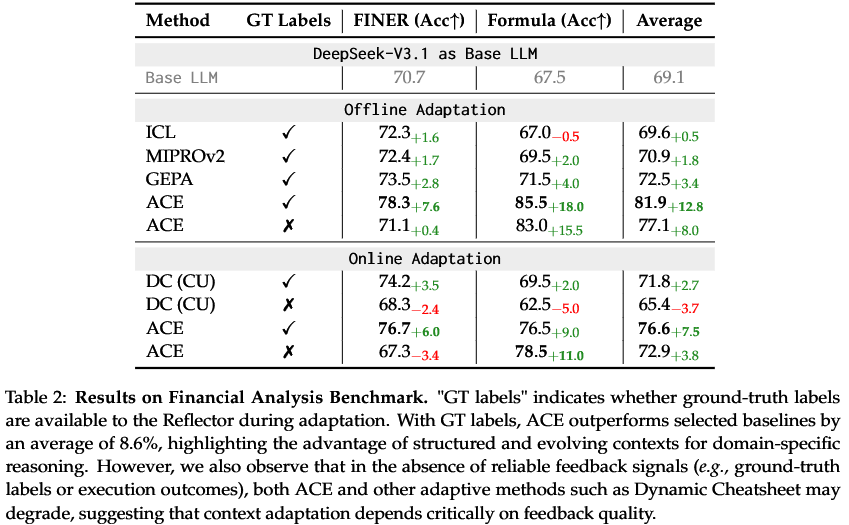
结果同样亮眼。ACE在这些任务上平均性能比基线提升了8.6%。就算没有人工标注的正确答案,只靠程序执行的反馈,ACE也能有效地进行自我优化。
成本方面,ACE更是把前辈们拍在了沙滩上。
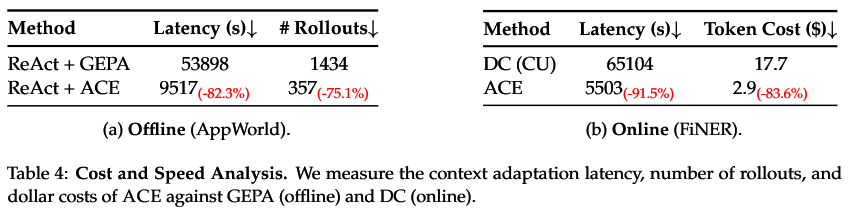
跟同样是自动优化上下文的GEPA方法相比,在离线适应任务上,ACE把延迟降低了82.3%,API调用次数减少了75.1%。
跟Dynamic Cheatsheet相比,在在线适应任务上,延迟降低了91.5%,token成本降低了83.6%。
为什么能这么省?因为它避免了让LLM去反复重写整个越来越长的上下文,策展人的合并操作是确定性的、非LLM的,开销极小。
ACE框架一经发布,立刻在学术界和工业界引起了不小的震动。
ACE通过上下文工程实现LLM的自我提升,为构建低成本、高可解释性的AI系统开辟了新道路。
商业价值上,ACE的长上下文和增量更新机制,为企业级AI应用的快速迭代和部署提供了关键技术支撑。
当模型性能逼近瓶颈时,智能体上下文工程凭借更灵活的适配性、更高的运行效率与更强的可解释性,为智能体能力的提升打开了全新空间,显著拉高了性能上限。
参考资料:
https://arxiv.org/abs/2510.04618
https://www.marktechpost.com/2025/10/10/agentic-context-engineering-ace-self-improving-llms-via-evolving-contexts-not-fine-tuning
https://X.com/omarsar0/status/1976746822204113072
https://X.com/rohanpaul_ai/status/1975732878739665393
https://X.com/DataScienceDojo/status/1976407325180117284
END
更多推荐


 21
21 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)