
SAM 3震撼发布!即将引爆CV圈!!!
【重磅来袭!SAM 3震撼发布:不止分割万物,更能“理解”概念,交互式分割迎来智能新纪元】
就在刚刚,CV圈即将被再次引爆!Segment Anything Model的史诗级续作——SAM 3 正式登场!它不再是那个只会根据你的点击框选目标的“工具”,而是进化成了一个能真正“理解”你心中所想的视觉智能体。
这一次,SAM 3的野心远不止于“分割万物”。它带来了革命性的Promptable Concept Segmentation!
🤖 这意味着什么?
-
从“指哪打哪”到“心领神会”:你不再需要费力地在每个物体上点点画画。只需对它说一个简单的名词短语,比如“黄色的校车”、“条纹猫”,甚至直接给它看一张图片范例,SAM 3就能瞬间在图像或视频中,找出并分割出所有符合你描述的对象!它真正理解了“概念”。
-
交互式分割迎来新篇章:SAM 3将交互智能提升到了全新高度。当结果不完美时,你不仅可以像以前一样用点击来修正,更能通过提供正负范例的方式来“教”它:“我要的是这种,不是那种”。模型会立刻举一反三,智能调整所有同类目标,效率呈指数级提升。
-
性能碾压,全面超越:官方数据显示,SAM 3在全新的SA-Co基准上,性能达到了前代模型及同类最强竞品的2倍以上!无论是在图像中的开放词汇识别,还是在复杂视频中的追踪与分割,它都树立了全新的技术标杆。
SAM 3的发布,标志着我们向“通用视觉智能”又迈进了坚实的一步。它不再是一个被动的分割工具,而是一个能够主动理解视觉概念、并与人类协同工作的强大伙伴。
想象一下:视频剪辑、机器人导航、医学影像分析、内容创作……所有需要精准识别与分割的场景,都将被重新定义。

-
论文标题:SAM 3: Segment Anything with Concepts
-
研究团队:Meta AI
-
项目主页:https://ai.meta.com/sam3/
-
综述地址:https://github.com/liliu-avril/Awesome-Segment-Anything
摘要
本文提出了分割任意目标模型(Segment Anything Model, SAM)3,这是一种统一模型,能够基于概念提示对图像和视频中的目标进行检测、分割与跟踪。我们将概念提示定义为简短名词短语(如 “黄色校车”)、图像示例或两者的组合。可提示概念分割(Promptable Concept Segmentation, PCS)任务接收此类提示后,会返回所有匹配目标实例的分割掩码及唯一标识。为推动可提示概念分割任务的发展,我们构建了一个可扩展的数据引擎,生成了高质量数据集,涵盖图像和视频领域,包含 400 万个独特概念标签,其中还包括难负样本。该模型包含一个视觉骨干网络,同时为图像级检测器和基于记忆的视频跟踪器所共享。模型通过一个存在头(presence head)将识别与定位解耦,显著提升了检测精度。在图像和视频可提示概念分割任务中,SAM 3 的性能较现有系统提升了 2 倍,且在交互式视觉分割任务中改进了前代 SAM 模型的性能。我们开源了 SAM 3,并发布了全新的 “基于概念的任意目标分割”(Segment Anything with Concepts, SA-Co)基准测试集。
1 引言
在视觉场景中实现 “任意目标的查找与分割” 是多模态人工智能的基础能力,可支撑机器人技术、内容创作、增强现实、数据标注及科学研究等多个领域的应用。SAM 系列模型(Kirillov 等人,2023;Ravi 等人,2024)提出了 “可提示分割” 任务,通过交互式提示(包括标记特定目标的点、框、掩码等视觉输入,或描述目标的文本输入)对图像和视频中的目标进行分割。然而,SAM 1 和 SAM 2 主要聚焦于视觉提示,且每次提示仅能分割单个目标实例。尽管这些方法在该关键任务上取得了突破性进展,但未能解决更广泛的任务需求 —— 即查找并分割输入中所有出现的某一概念实例(例如,视频中所有的 “猫”)。
本文提出的 SAM 3 模型,在图像和视频可提示分割任务上实现了跨越式提升:相较于 SAM 2,其改进了可提示视觉分割(Promptable Visual Segmentation, PVS)性能;同时,为可提示概念分割(PCS)任务树立了新标杆。我们将可提示概念分割任务正式定义为:以文本和 / 或图像示例为输入,预测所有匹配该概念的目标实例掩码和语义掩码,并在视频帧间保持目标的唯一标识(详见第 2 章)。本文聚焦于识别原子级视觉概念,因此将文本提示限定为简单名词短语(Noun Phrases, NPs),例如 “红苹果” 或 “带条纹的猫”。任务输出示例如图 1 所示。
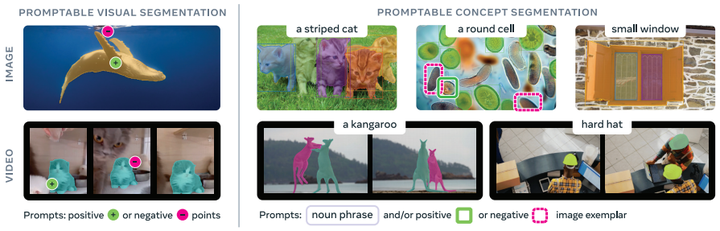
图 1:SAM 3 在使用点击的可提示视觉分割上(左)相比 SAM 2 有所改进,同时推进了可提示概念分割(右),用户可以通过短名词短语、图像范例或两者的组合来分割视觉概念的所有实例。
需说明的是,SAM 3 并非为处理长指代语言表达式或需推理的查询任务而设计,但我们实验表明,它可与多模态大型语言模型(Multimodal Large Language Model, MLLM)轻松结合,以处理更复杂的语言提示。
由于可提示概念分割任务具有开放词汇特性,其本质存在歧义性 —— 许多概念存在多种解读。例如,“小窗户” 具有主观性(“小” 与 “大” 的界定)且边界模糊(是否包含百叶窗)。我们的方法在任务的各个阶段(包括数据收集、指标设计和模型构建)均系统性地考虑了这些歧义问题。与前代 SAM 模型一致,SAM 3 具备完全交互能力,用户可通过添加优化提示来消除歧义,引导模型生成符合预期的输出。
本文提出的模型(详见第 3 章)包含检测器和跟踪器两部分,二者共享一个视觉编码器(Bolya 等人,2025)。检测器基于 DETR 架构(Carion 等人,2020),受文本、几何信息和图像示例的条件约束。为解决开放词汇概念检测的难题,我们引入了独立的存在头,将识别与定位解耦 —— 这在使用具有挑战性的负样本短语训练时效果尤为显著。跟踪器继承了 SAM 2 的 Transformer 编解码器架构,支持视频分割和交互式优化。检测器与跟踪器的解耦设计避免了任务冲突:检测器无需关注目标标识,而跟踪器的核心目标是在视频中区分不同目标的标识。
为实现性能的大幅提升,我们构建了一个高效的 “人机协同” 数据引擎(详见第 4 章),用于标注大规模、多样化的训练数据集。该数据引擎在现有数据引擎设计基础上,从三个关键方面进行了创新:
-
媒体筛选:相较于依赖同质化网络数据源的传统方法,我们筛选的媒体领域更具多样性;
-
标签筛选:利用本体论和多模态大型语言模型作为 “AI 标注器”,生成名词短语和难负样本,显著提升了标签的多样性和难度;
-
标签验证:通过微调多模态大型语言模型,构建高效的 “AI 验证器”(性能接近人类水平),使标注吞吐量提升一倍。
从含噪声的 “媒体 - 短语 - 掩码” 伪标签出发,我们的数据引擎通过人机协同验证,检查掩码质量与完整性:筛选出标注正确的样本,并识别出具有挑战性的错误案例;随后,人类标注员专注于修正这些错误,手动调整掩码。借助该数据引擎,我们标注了高质量训练数据(含 400 万个独特短语和 5200 万个掩码)以及一个合成数据集(含 3800 万个短语和 14 亿个掩码)。此外,我们还为可提示概念分割任务构建了 “基于概念的任意目标分割”(SA-Co)基准测试集(详见第 5 章),包含 21.4 万个独特概念,在 12.4 万张图像和 1700 个视频中提供了完整掩码标注,概念数量是现有基准测试集的 50 倍以上。
实验结果(详见第 6 章)表明,SAM 3 在可提示分割任务中达到了最新技术水平(state-of-the-art):例如,在 LVIS 数据集上的零样本掩码 AP(平均精度)达到 47.0,远超当前最佳水平 38.5;在全新的 SA-Co 基准测试集上,性能至少是基线模型的 2 倍;同时,在可提示视觉分割基准测试集上也优于 SAM 2。消融实验(详见附录 B)验证了骨干网络选择、新型存在头设计以及添加难负样本均能提升模型性能,并揭示了高质量数据集和合成数据集在可提示概念分割任务上的规模扩展规律。我们开源了 SA-Co 基准测试集,并发布了 SAM 3 的检查点(checkpoints)和推理代码。在 H200 GPU 上,SAM 3 处理单张含 100 个以上检测目标的图像仅需 30 毫秒;在视频任务中,推理延迟随目标数量增加而线性增长,对约 5 个并发目标可维持近实时性能。下文将详细介绍任务定义,并在附录 A 中综述相关工作。
2 可提示概念分割(PCS)
我们将可提示概念分割任务定义如下:给定一张图像或一段短视频(≤30 秒),检测、分割并跟踪所有符合 “概念提示” 的目标实例。概念提示可通过简短文本短语、图像示例或两者组合来指定。其中,概念限定为 “简单名词短语” 所定义的范畴 —— 这类短语由一个名词和可选修饰词构成。若提供名词短语提示,其对图像 / 视频的所有帧均全局有效;而图像示例可在单个帧上以 “正 / 负边界框” 形式提供,用于迭代优化目标掩码(如图 2 所示)。
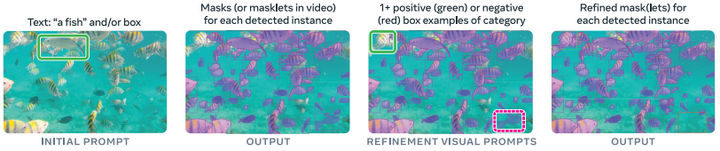
图 2:PCS 任务中支持的初始和可选交互式细化提示的图示。
所有提示的类别定义必须一致,否则模型行为将无法确定。例如,若文本提示为 “鱼”,后续不能用仅包含 “鱼尾” 的示例提示进行优化,而应先更新文本提示。当模型初始检测遗漏部分实例,或概念较为罕见时,示例提示的作用尤为突出。
我们的词汇库包含所有可在视觉场景中 “接地”(groundable)的简单名词短语,这使得任务本质存在歧义性。短语的歧义来源包括:一词多义(“mouse” 可指 “鼠标” 或 “老鼠”)、主观描述词(“舒适的”“大的”)、模糊或依赖上下文的不可接地短语(“品牌标识”)、边界模糊(“镜子” 是否包含镜框),以及遮挡、模糊等导致目标范围不清晰的因素。尽管在大型闭词汇语料库(如 LVIS(Gupta 等人,2019))中也存在类似问题,但可通过精心筛选词汇库和明确定义所有目标类别来缓解。为解决歧义问题,我们采取了以下措施:
-
由三名专家提供测试标注;
-
调整评估协议,允许多种有效解读(详见附录 F.3);
-
设计数据处理流程和标注指南,最大限度减少标注过程中的歧义;
-
在模型中引入歧义模块(详见附录 D.2)。
3 模型
SAM 3 是 SAM 2 的扩展,既支持全新的可提示概念分割(PCS)任务,也兼容可提示视觉分割(PVS)任务。模型接收概念提示(简单名词短语、图像示例)或视觉提示(点、框、掩码),确定需进行时空分割的目标(可单个分割)。在单个帧上,可迭代添加图像示例和视觉提示以优化目标掩码:通过图像示例可移除假阳性目标或添加假阴性目标;借鉴 SAM 2 的方式,通过可提示视觉分割可优化单个掩码(或子掩码)。
SAM 3 的架构主要基于 SAM 系列模型(Ravi 等人,2024;Kirillov 等人,2023)和 DETR 系列模型(Carion 等人,2020),采用双编解码器 Transformer 结构(如图 3 所示),包含:
-
检测器:负责图像级分割能力;
-
跟踪器与记忆模块:协同工作以实现视频分割。
检测器和跟踪器均接收来自 “对齐感知编码器”(Perception Encoder, PE)骨干网络(Bolya 等人,2025)的视觉 - 语言输入。下文将概述模型架构,详细内容见附录 D。
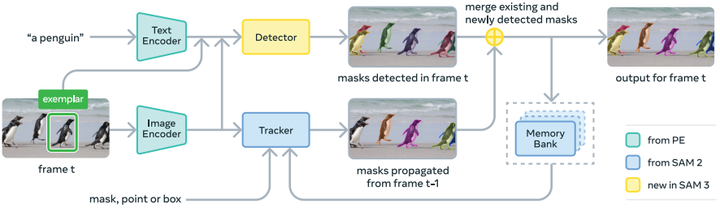
图 3:SAM 3 架构概述。更详细的图示见图 8。
3.1 检测器架构
检测器架构遵循 DETR 的通用范式,具体流程如下:
-
编码阶段:图像和文本提示首先由感知编码器(PE)编码;若存在图像示例,则由示例编码器编码。我们将图像示例 tokens 和文本 tokens 统称为 “提示 tokens”。
-
融合编码:融合编码器接收来自图像编码器的 “无条件嵌入”,并通过与提示 tokens 进行交叉注意力计算,对无条件嵌入进行条件约束,生成 “条件约束图像嵌入”。
-
解码阶段:融合编码后接入 DETR 风格的解码器,其中学习到的 “目标查询”(object queries)与融合编码器输出的条件约束图像嵌入进行交叉注意力计算。在每一层,每个目标查询都会预测一个分类 logit(本文中为二分类标签,指示目标是否与提示匹配),并基于前一层预测的边界框输出一个偏移量(遵循 Zhu 等人,2020 的方法)。
-
注意力优化:采用 “框 - 区域位置偏置”(box-region-positional bias)(Lin 等人,2023)帮助注意力聚焦于每个目标,但与最新 DETR 模型不同,我们保留了 vanilla 注意力机制。
-
损失函数:训练过程中,采用 DAC-DETR(Hu 等人,2023)的双重监督和 Align 损失(Cai 等人,2024)。
-
掩码头与语义分割头:掩码头改编自 MaskFormer(Cheng 等人,2021);此外,还设有语义分割头,为图像中每个像素预测二分类标签,指示该像素是否与提示匹配。
3.2 存在 Token(Presence Token)
在图像 / 帧中,每个候选查询(proposal query)需同时完成 “识别(是什么)” 和 “定位(在哪里)” 任务,这具有一定难度。对于识别任务,整幅图像的上下文信息至关重要;但强制候选查询理解全局上下文会产生反效果,因为这与定位任务固有的 “局部性” 目标相冲突。
为解决这一问题,我们引入一个学习到的 “全局存在 token”,将识别与定位解耦。该 token 仅负责预测名词短语(NP)形式的目标概念是否存在于图像 / 帧中(即 p(名词短语存在于输入中));而每个候选查询 qi 只需解决定位问题(即 p(qi 匹配目标 | 名词短语存在于输入中))。最终,每个候选查询的得分是其自身得分与存在得分的乘积。
3.3 图像示例与交互性
SAM 3 支持图像示例提示,形式为 “边界框 + 二进制标签(正 / 负)”,可单独使用或补充文本提示。模型会检测所有与提示匹配的实例。例如,给定一个包含 “狗” 的正边界框,模型会检测图像中所有的狗。这与 SAM 1 和 SAM 2 的可提示视觉分割任务不同 —— 在后者中,几何 / 视觉提示仅能输出单个目标实例。
每个图像示例由示例编码器单独编码:将位置嵌入、标签嵌入(正 / 负)和 ROI 池化视觉特征拼接,形成 “示例 tokens”,再通过小型 Transformer 处理。处理后的示例提示与文本提示拼接,构成最终的提示 tokens。基于当前检测结果中的错误,可交互式提供图像示例,以优化模型输出。
3.4 跟踪器与视频架构
给定视频和提示 P,模型通过检测器和跟踪器(如图 3 所示),在整个视频中检测并跟踪与提示匹配的目标。在每一帧 t 上:
-
检测器发现新目标 \(O_t\);
-
跟踪器将前一帧(\(t-1\))的子掩码(masklets,即时空掩码)\(M_{t-1}\) 传播到当前帧的新位置 \(\hat{M}_t\);
-
通过匹配函数,将传播后的子掩码 \(\hat{M}_t\) 与当前帧新检测到的目标掩码 \(O_t\) 关联,更新得到当前帧的目标掩码 \(M_t\)。
上述过程可表示为:\(\hat{\mathcal{M}}_{t}=\text{propagate}(\mathcal{M}_{t-1}),\quad \mathcal{O}_{t}=\text{detect}(I_{t}, P),\quad \mathcal{M}_{t}=\text{match\_and\_update}(\hat{\mathcal{M}}_{t}, \mathcal{O}_{t})\)
3.4.1 基于 SAM 2 风格传播的目标跟踪
在第一帧检测到每个目标后,为其初始化一个子掩码。在后续每一帧,跟踪器模块基于已跟踪目标在前一帧的位置 \(M_{t-1}\),通过 “单帧传播” 步骤(与 SAM 2 中的视频目标分割任务类似),预测这些目标在当前帧的新子掩码位置 \(\hat{M}_t\)。跟踪器与检测器共享相同的图像 / 帧编码器(PE 骨干网络)。训练完检测器后,冻结 PE 骨干网络,借鉴 SAM 2 的方法训练跟踪器,包括提示编码器、掩码解码器、记忆编码器和记忆库 —— 记忆库利用过去帧和条件帧(首次检测到目标或用户提示的帧)的特征,对目标外观进行编码。记忆编码器是一个 Transformer,可对当前帧的视觉特征进行自注意力计算,并将视觉特征与记忆库中的空间记忆特征进行交叉注意力计算。
在推理阶段,仅保留 “目标高置信度存在” 的帧到记忆库中。掩码解码器是一个双向 Transformer,在编码器隐藏状态和输出 tokens 之间进行注意力交互。为处理歧义,对每个跟踪目标,在每一帧预测三个输出掩码及对应的置信度,选择置信度最高的作为当前帧的预测掩码。
3.4.2 基于检测结果的匹配与更新
得到跟踪掩码 \(\hat{M}_t\) 后,通过基于 IoU 的简单匹配函数(详见附录 D.3),将其与当前帧检测结果 \(O_t\) 匹配,并添加到当前帧的 \(M_t\) 中;对于所有未匹配的新检测目标,生成新的子掩码。在拥挤场景中,掩码融合可能存在歧义,为此我们提出两种时间消歧策略:
-
基于子掩码检测得分的抑制:定义 “子掩码检测得分”(masklet detection score,详见附录 D.3),衡量子掩码在时间窗口内(基于过去帧中与检测结果匹配的次数)与检测结果匹配的一致性。若子掩码检测得分低于阈值,则抑制该子掩码。
-
基于检测器输出的重提示:利用检测器输出来解决跟踪器因遮挡或干扰物导致的特定失效问题。定期使用高置信度检测掩码 \(O_t\) 对跟踪器进行 “重提示”,替换跟踪器自身的预测 \(\hat{M}_t\),确保记忆库中存储的是近期、可靠的参考信息(而非仅依赖跟踪器预测)。
3.4.3 基于视觉提示的实例优化
获得初始掩码(或子掩码)后,SAM 3 允许通过正 / 负点击优化单个掩码(或子掩码)。具体而言,用户点击后,提示编码器对点击信息进行编码,将编码后的提示输入掩码解码器,预测调整后的掩码。在视频任务中,该掩码会在整个视频中传播,得到优化后的子掩码。
3.5 训练阶段
SAM 3 的训练分为四个阶段,逐步增加数据规模并扩展模型能力,具体如下:
-
感知编码器(PE)预训练;
-
检测器预训练;
-
检测器微调;
-
冻结骨干网络后的跟踪器训练。
详细训练流程见附录 D.4.1。
4 数据引擎
要在可提示概念分割任务上实现跨越式提升,SAM 3 需要在 “概念覆盖范围” 和 “视觉领域多样性” 远超现有数据集的训练数据上进行训练(如图 10 所示)。我们的解决方案是构建一个高效的数据引擎,通过 SAM 3、人类标注员和 AI 标注员之间的反馈循环,迭代生成标注数据 —— 主动挖掘当前版本 SAM 3 无法生成高质量训练数据的 “媒体 - 短语” 对,进一步改进模型。
通过将部分任务委派给 “性能接近或超越人类” 的 AI 标注员,数据引擎的吞吐量较 “纯人类标注流水线” 提升一倍以上。该数据引擎的开发分为四个阶段,每个阶段均增加 AI 模型的使用比例,将人类精力引导至最具挑战性的失效案例,同时扩展视觉领域覆盖范围。其中,阶段 1-3 仅聚焦于图像数据,阶段 4 扩展至视频数据。下文将介绍关键步骤,详细内容和指标见附录 E。
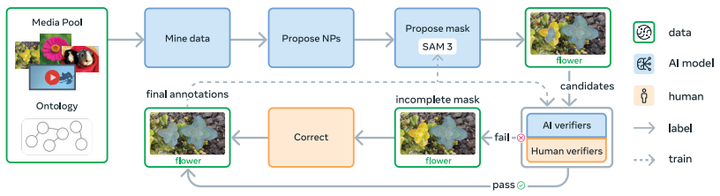
图 4:最终 SAM 3 数据引擎概述。收集数据的细节见 §F.1。
4.1 数据引擎组件(如图 4 所示)
-
媒体输入:图像或视频从大型媒体库中挖掘,挖掘过程借助精心构建的本体论(ontology)指导。
-
名词短语(NP)生成:由 AI 模型生成描述视觉概念的名词短语。
-
掩码候选生成:另一模型(如 SAM 3)为每个生成的名词短语生成实例掩码候选。
-
掩码验证(MV):标注员根据掩码质量和与名词短语的相关性,对掩码候选进行 “接受” 或 “拒绝” 判断。
-
完整性验证(EV):标注员检查图像中所有符合名词短语的实例是否均已被掩码覆盖。
-
手动修正:未通过完整性验证的 “媒体 - 短语” 对将进入手动修正阶段 —— 人类标注员使用基于浏览器的 SAM 1 工具添加、删除或编辑掩码;对于小型、难以分离的目标,使用 “组掩码”(group masks)标注。标注员可拒绝 “不可接地” 或 “歧义” 短语。
-
最终标注:通过验证和修正的 “媒体 - 短语 - 掩码” 三元组构成最终标注数据,用于训练 SAM 3。
4.2 数据引擎阶段
4.2.1 阶段 1:人类验证
初始阶段,通过随机采样图像进行数据挖掘;利用简单的图像描述生成器(captioner)和解析器生成名词短语;掩码候选生成模型采用 SAM 2,提示信息来自现成的开放词汇检测器输出;验证环节完全由人类完成。该阶段收集的 430 万 “图像 - 名词短语” 对构成初始 SA-Co/HQ 数据集。将该数据集用于训练 SAM 3,得到的模型作为下一阶段的掩码候选生成模型。
4.2.2 阶段 2:人机协同验证
在该阶段,利用阶段 1 收集的 “掩码验证(MV)” 和 “完整性验证(EV)” 任务中的人类标注标签,微调 Llama 3.2 模型(Dubey 等人,2024),构建 AI 验证器,实现 MV 和 EV 任务的自动化。这些 AI 验证器接收 “图像 - 短语 - 掩码” 三元组,输出关于掩码质量或完整性的多选题判断。自动化验证流程将人类精力聚焦于最具挑战性的案例。
同时,持续使用新收集的数据重新训练 SAM 3,共更新 6 次。随着 SAM 3 和 AI 验证器性能提升,自动生成标签的比例增加,进一步加速数据收集。AI 验证器的引入使数据引擎的吞吐量提升一倍。此外,名词短语生成步骤升级为基于 Llama 的流水线,可生成对 SAM 3 具有 “对抗性” 的难负样本短语。该阶段为 SA-Co/HQ 数据集新增 1.22 亿 “图像 - 名词短语” 对。
4.2.3 阶段 3:规模扩展与领域拓展
此阶段,利用 AI 模型挖掘更具挑战性的案例,并将 SA-Co/HQ 的视觉领域覆盖范围扩展至 15 个数据集(如图 11 所示)。在新领域中,掩码验证(MV)AI 验证器的零样本性能良好,而完整性验证(EV)AI 验证器通过少量领域特定人类监督即可提升性能。
同时,通过以下方式扩展概念覆盖范围至 “长尾概念” 和 “细粒度概念”:
-
从图像的替代文本(alt-text)中提取名词短语(若有);
-
从包含 2240 万个节点的 SA-Co 本体论(基于维基数据(Wikidata),含 17 个顶层类别、72 个子类别)中挖掘概念。
该阶段共迭代训练 SAM 3 7 次、AI 验证器 3 次,为 SA-Co/HQ 数据集新增 1950 万 “图像 - 名词短语” 对。
4.2.4 阶段 4:视频标注
该阶段将数据引擎扩展至视频领域。利用性能成熟的 SAM 3,收集针对 “视频特有挑战” 的高质量标注数据。数据挖掘流水线包含场景 / 运动筛选、内容平衡、排序和定向搜索等步骤:
-
对视频帧进行采样(随机采样或基于目标密度采样);
-
将采样帧送入阶段 3 的图像标注流程;
-
利用 SAM 3(扩展至视频任务)生成子掩码,通过去重和移除 “无意义掩码” 进行后处理。
由于视频标注难度更高,人类标注员优先处理 “目标密集” 和 “跟踪失效” 的视频片段。该阶段收集的视频数据集 SA-Co/VIDEO 包含 5.25 万个视频和 46.7 万个子掩码。详细信息见附录 E.6。
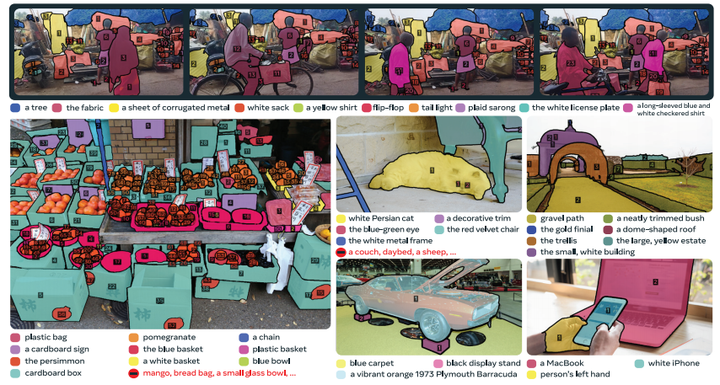
图 5:来自 SA-Co 的示例视频(顶部)和图像(底部),带有标注的短语和实例掩码/ID。
5 基于概念的任意目标分割(SA-Co)数据集
5.1 训练数据
为可提示概念分割任务,我们收集了三个图像数据集和一个视频数据集,具体如下:
-
SA-Co/HQ:高质量图像数据集,来自数据引擎阶段 1-4,包含 520 万张图像和 400 万个独特名词短语,是目前规模最大的高质量开放词汇分割数据集;
-
SA-Co/SYN:合成图像数据集,由数据引擎阶段 3 的成熟版本生成,无需人类参与标注;
-
SA-Co/EXT:外部数据集集合,包含 15 个具有实例掩码标注的外部数据集,通过 SA-Co 本体论流水线补充难负样本;
-
SA-Co/VIDEO:视频数据集,包含 5.25 万个视频和 2.48 万个独特名词短语,构成 13.4 万 “视频 - 名词短语” 对,视频平均长度为 84.1 帧(6 帧 / 秒)。
详细统计信息、与现有数据集的对比及概念分布见附录 F.1。
5.2 SA-Co 基准测试集
SA-Co 评估基准测试集共包含 21.4 万个独特短语、12.6 万张图像和视频,以及超过 300 万 “媒体 - 短语” 对(含挑战性难负样本标签),用于测试开放词汇识别能力。测试集包含多个子集:
-
SA-Co/Gold:涵盖 7 个领域,每个 “图像 - 名词短语” 对由 3 名不同标注员标注(用于衡量人类性能);
-
SA-Co/Silver:涵盖 10 个领域,每个 “图像 - 名词短语” 对仅含 1 个人类标注;
-
SA-Co/Bronze 和 SA-Co/Bio:由 9 个现有数据集构成,部分含现有掩码标注,部分通过将边界框作为提示输入 SAM 2 生成掩码;
-
SA-Co/VEval:视频评估子集,涵盖 3 个领域,每个 “视频 - 名词短语” 对含 1 个人类标注。
数据集统计信息见表 29,标注示例见图 5。
5.3 评估指标
我们的目标是衡量模型在下游应用中的实用性。传统检测指标(如平均精度 AP)未考虑 “校准性”,导致模型在实际应用中难以使用。为解决这一问题,我们仅评估置信度高于 0.5 的预测结果 —— 通过设置阈值模拟下游应用场景,确保模型具备良好的校准性。
可提示概念分割任务可自然拆分为 “定位” 和 “分类” 两个子任务,对应指标如下:
-
定位评估:对 “至少含一个真值掩码和一个预测掩码” 的正 “媒体 - 短语” 对,采用正宏观 F1(positive macro F1, pmF₁);
-
分类评估:采用图像级马修斯相关系数(Image-Level Matthews Correlation Coefficient, IL MCC),取值范围为 [-1,1],评估图像级二分类预测(“目标是否存在”),不考虑掩码质量。
核心指标 “分类门控 F1(Classification-Gated F1, CGF₁)” 结合了上述两个指标,定义为:\(CGF_1 = 100 \times pmF_1 \times IL\_MCC\)
指标详细定义见附录 F.3。
6 实验
我们从多个维度评估 SAM 3 的性能:图像 / 视频分割、面向检测和计数基准的少样本适配、结合多模态大型语言模型(MLLM)处理复杂语言查询的分割任务。同时,展示部分消融实验结果(更多结果见附录 B)。相关参考文献、更多实验结果及细节见附录 G。
6.1 基于文本的图像可提示概念分割
我们在外部基准和 SA-Co 基准上,评估实例分割、边界框检测和语义分割性能。SAM 3 每次接收一个名词短语提示,输出实例掩码、边界框或语义掩码。基线模型包括:
-
边界框检测:OWLv2、GroundingDino、LLMDet;
-
分割:用上述基线模型的边界框提示 SAM 1,得到分割结果;
-
其他:APE、DINO-X、通用大型语言模型 Gemini 2.5 Flash。
表 1 结果显示:
-
在零样本设置下,SAM 3 在闭词汇 COCO、COCO-O 和 LVIS 边界框检测任务上具有竞争力,在 LVIS 掩码分割任务上表现显著更优;
-
在开放词汇 SA-Co/Gold 基准上,SAM 3 的 CGF₁得分是最强基线模型 OWLv2⋆的 2 倍,达到人类性能估计下限的 88%;
-
在其他 SA-Co 子集上,性能提升更为显著;
-
在 ADE-847、PascalConcept-59 和 Cityscapes 开放词汇语义分割任务上,SAM 3 优于强基线模型 APE。
详细结果见附录 G.1。
6.2 少样本适配
我们在 ODinW13 和 Roboflow100-VL 基准上,评估 SAM 3 的零样本和少样本迁移能力,使用基准的原始标签作为提示,不进行任何提示微调。在微调 SAM 3 时不使用掩码损失,报告边界框平均 mAP(见表 2)。结果显示,SAM 3 在 10 样本设置下达到最新技术水平,性能超过 Gemini 的上下文提示和专业目标检测模型(如 GroundingDino)。
Roboflow100-VL 包含部分 “超出 SAM 3 当前范围” 的专业提示领域,但 SAM 3 通过微调实现了比基线模型更高效的适配。详细结果见附录 G.3。
6.3 基于单个示例的可提示概念分割
我们使用 “从真值中随机采样的单个输入框” 作为图像示例,仅在 “正样本数据”(提示目标存在于图像中)上进行评估,报告对应 AP⁺(仅在正样本上评估的平均精度)。实验设置包括:
-
T:仅文本提示;
-
I:仅图像示例提示;
-
T+I:文本 + 图像示例组合提示。
表 3 结果显示,在 COCO(+17.2)、LVIS(+9.7)和 ODinW(+20.1)数据集上,SAM 3 的性能显著优于前代最新模型 T-Rex2。SA-Co/Gold 上的更多细节和结果见附录 G.2。
6.4 基于多个示例的可提示概念分割
在交互式场景下(模拟与人类标注员协作),我们评估 SAM 3 的性能:从文本提示开始,每次迭代添加一个示例提示 —— 未检测到的真值作为正提示候选,高置信度假阳性检测作为负提示候选。结果(如图 6 所示)与 “理想可提示视觉分割(PVS)基线” 对比 —— 该基线模拟用户通过 “理想框到掩码修正” 手动修复错误。
实验表明:
-
SAM 3 的可提示概念分割(PCS)性能提升更快,因为它能从示例中泛化(如检测或抑制相似目标),而可提示视觉分割(PVS)仅能修正单个实例;
-
添加 3 次点击后,交互式可提示概念分割的 CGF₁得分较 “仅文本提示” 高 18.6 个百分点,较 “可提示视觉分割优化” 高 9.7 个百分点;
-
添加 4 次点击后,性能趋于平稳(示例无法修复低质量掩码);此时切换至可提示视觉分割(PVS)进行混合优化,性能可进一步提升,表明两种方法具有互补性。
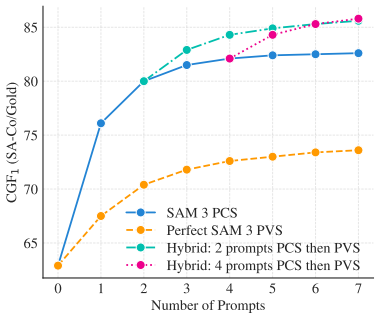
图 6:在 SA-Co 上,SAM 3 的交互式范例提示与理想 PVS 基线的比较。我们报告 CGF11 相对于框提示数量的关系,对所有 SA-Co/Gold 短语取平均。
6.5 目标计数
在 CountBench 和 PixMo-Count 目标计数基准上,我们将 SAM 3 与多个多模态大型语言模型(MLLM)对比,评估指标为准确率(%)和平均绝对误差(MAE)(结果见表 4)。实验表明,SAM 3 不仅实现了优异的目标计数准确率,还能提供大多数多模态大型语言模型无法输出的目标分割结果。
6.6 基于文本的视频可提示概念分割
我们在 SA-Co/VEval 基准和现有公共基准上,评估基于文本提示的视频分割性能:
-
SA-Co/VEval:报告 CGF₁和 pHOTA 指标(定义见附录 G.5),覆盖 SA-V、YT-Temporal-1B、SmartGlasses 等子集;
-
公共基准:使用官方指标,基线模型包括开放词汇图像和视频分割模型 GLEE、“LLMDet + SAM 3 跟踪器”(用 LLMDet 替换 SAM 3 的检测器)、“SAM 3 检测器 + T-by-D”(用基于 “检测跟踪” 范式的关联模块替换 SAM 3 的跟踪器)。
表 5 结果显示,SAM 3 显著优于所有基线模型,尤其在含大量名词短语的基准上表现突出。在 SA-Co/VEval 上,SAM 3 的 pHOTA 得分达到人类水平的 80% 以上。详细结果见附录 G.5。
6.7 可提示视觉分割(PVS)
我们在多个几何任务上评估 SAM 3,包括视频目标分割(VOS)和交互式图像分割:
-
视频目标分割(VOS):表 6 对比 SAM 3 与最新模型,结果显示 SAM 3 在大多数基准上显著优于 SAM 2,尤其在挑战性 MOSEv2 数据集上,性能较前代模型提升 6 个百分点;
-
交互式图像分割:在 SAM 2 引入的 37 数据集基准上评估,表 7 结果显示 SAM 3 的平均 mIoU(交并比)优于 SAM 2。
6.8 SAM 3 智能体(SAM 3 Agent)
我们将 SAM 3 作为工具,与多模态大型语言模型(MLLM)结合,构建 “SAM 3 智能体”,以处理复杂文本查询(如 “坐着且手中未拿礼品盒的人”)。多模态大型语言模型生成名词短语查询以提示 SAM 3,分析返回的掩码,迭代优化直至得到满意结果。
表 8 结果显示,在 ReasonSeg(Lai 等人,2024)和 OmniLabel(Schulter 等人,2023)基准上,零样本设置的 SAM 3 智能体性能超过未在 “指代表达式分割” 或 “推理分割” 数据上训练的前代模型。此外,SAM 3 智能体在 RefCOCO+(Kazemzadeh 等人,2014)和 RefCOCOg(Mao 等人,2016)上的零样本性能也优于前代结果。SAM 3 可与多种多模态大型语言模型结合,且对所有模型使用相同的系统提示,体现出良好的鲁棒性。详细内容见附录 H。
6.9 精选消融实验
表 9 展示部分消融实验结果(更多结果见附录 B):
-
存在头的影响:存在头使 CGF₁得分提升 5.7 个百分点(表 9a),主要提升了图像级识别能力(通过 IL MCC 衡量);
-
难负样本的影响:添加难负样本显著提升模型性能,尤其使图像级 IL MCC 从 0.44 提升至 0.68(表 9b);
-
训练数据的影响:合成数据(SYN)较外部数据(EXT)使 CGF₁提升 8.8 个百分点,高质量标注数据(HQ)在该基线基础上进一步提升 14.6 个百分点(表 9c);
-
AI 验证器的影响:用完整性验证(EV)AI 验证器的存在得分替换 SAM 3 的存在得分,使 IL MCC 提升 4.6 个百分点;用掩码验证(MV)AI 验证器移除低质量掩码,使 pmF₁提升 2.5 个百分点(表 9d)。
合成数据和高质量数据的详细规模扩展规律见附录 B.2,结果表明它们在域内和域外测试集上均有效。
7 结论
本文提出 “基于概念的任意目标分割” 方法,支持将开放词汇文本和示例作为交互式分割的提示。主要贡献包括:
-
提出可提示概念分割(PCS)任务和 SA-Co 基准测试集;
-
设计 “识别 - 定位解耦” 架构,在保留可提示视觉分割(PVS)能力的同时,将 SAM 2 扩展至可提示概念分割(PCS)任务;
-
构建高效的 “人机协同” 数据引擎,生成高质量训练数据。
实验结果表明,SAM 3 在图像和视频可提示概念分割任务上的性能较前代系统提升一倍,达到最新技术水平。我们相信,SAM 3 和 SA-Co 基准测试集将成为计算机视觉领域的重要里程碑,为未来研究和应用奠定基础。
参考资料:
SAM首篇全面综述: A Comprehensive Survey on Segment Anything Model for Vision and Beyond
SAM & SAM2 for Videos综述: Segment Anything for Videos: A Systematic Survey
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)