
大模型基础入门与 RAG 实战:从理论到 llama-index 项目搭建(有具体代码示例)
大模型是参数量达数十亿至万亿级的深度学习模型,具有参数量大、泛化能力强、多任务处理等特点,但也存在知识时效性差、易产生幻觉等局限。RAG(检索增强生成)技术通过结合外部知识检索与大模型生成,有效解决知识过时和幻觉问题。其核心流程包括数据索引(加载、分割、嵌入、索引)和查询生成(预处理、检索、生成)。
引路者👇:
四、实战:基于 llama-index 搭建 RAG 聊天项目
4.3 配置 DeepSeek 模型:解决 API 调用问题
4.3.3 解决 “Unknown model 'deepseek-chat'” 报错
一、初识大模型:生成式 AI 时代的核心动力
1.1 大模型的定义与核心特点
大模型是指参数量达数十亿至数千亿级、基于深度学习技术构建的机器学习模型,在自然语言处理(NLP)、计算机视觉(CV)等领域展现出卓越能力。其核心特点可概括为以下 10 点:
| 特点 | 详细说明 |
|---|---|
| 参数量大 | 通常包含数十亿至数千亿参数,能捕捉数据中复杂模式与细微特征,如 GPT-4 参数量超万亿 |
| 训练数据规模大 | 依赖海量多模态数据(文本、图像、音频等),涵盖互联网公开数据与领域私有数据 |
| 计算资源需求高 | 训练需 GPU/TPU 集群,单轮训练耗时数周甚至数月,成本可达数百万美元 |
| 泛化能力强 | 预训练后可迁移至多种任务,无需从零训练,如 GPT 模型可直接用于翻译、摘要生成 |
| 多任务处理能力 | 单一模型支持文本生成、问答、代码编写等多任务,无需针对每个任务单独建模 |
| 生成能力突出 | 能生成连贯、高质量的内容,如 GPT-4 可撰写论文、DALL-E 可生成创意图像 |
| 可解释性差 | 决策过程类似 “黑箱”,难以追溯答案生成逻辑,排查错误时缺乏明确依据 |
| 支持微调与迁移 | 可通过少量领域数据微调,快速适配特定场景,降低全量训练成本 |
| 资源消耗高 | 训练过程耗电巨大,碳足迹较高,如某大模型训练一次碳排放相当于一辆汽车行驶数年 |
| 伦理安全风险 | 可能生成虚假信息、偏见内容,训练数据中敏感信息存在泄露风险 |
1.2 大模型的交互流程与局限性
1.2.1 核心交互流程
大模型与人类 / 应用的交互遵循 “输入 - 处理 - 输出 - 反馈” 闭环,流程如下:
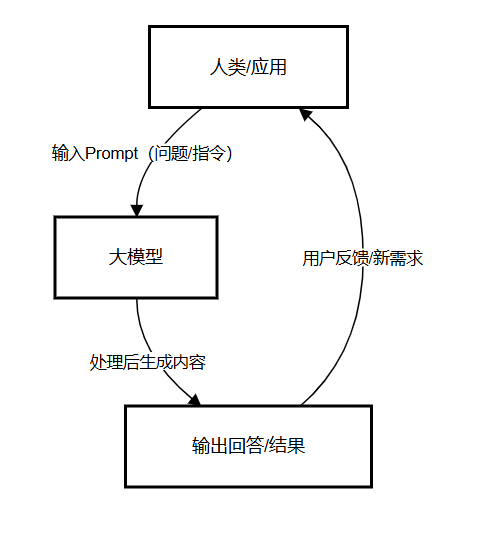
示例:当用户输入 “介绍大模型” 时,大模型会解析 Prompt,调用内部训练知识,生成包含定义、特点、应用的回答;若用户进一步提问 “大模型如何微调”,则触发新一轮交互。
1.2.2 大模型并非无所不能
尽管大模型能力强大,但存在明显局限性:
- 知识时效性差:训练数据有 “截止日期”,无法获取实时信息(如 2025 年无法回答 2024 年后的新事件);
- 易产生 “幻觉”:可能生成看似合理但不符合事实的内容,如虚构文献引用、错误数据;
- 领域适配弱:在医疗、法律等专业领域,未微调的大模型输出准确性低;
- 上下文窗口限制:单次交互能处理的文本长度有限(如早期 GPT-3 仅支持 2048 Token)。
二、什么是 RAG?解决大模型痛点的关键技术
2.1 为什么需要 RAG?
为解决大模型 “知识过时、幻觉严重、领域适配差” 的问题,检索增强生成(Retrieval-Augmented Generation,RAG) 技术应运而生。其核心思想是:将 “大模型生成” 与 “外部知识检索” 结合,让大模型在生成回答时参考实时、可靠的外部数据,而非仅依赖内部训练知识。
RAG 的价值体现在三个核心场景:
- 企业级知识问答:如客服机器人需调用企业最新产品手册、订单数据;
- 实时信息查询:如新闻摘要、股票行情等需获取最新数据的场景;
- 专业领域辅助:如医疗诊断需参考最新临床指南,法律问答需关联现行法规。
2.2 RAG 的核心流程(附架构图)
RAG 技术架构分为数据索引阶段和数据查询阶段,完整流程如下:
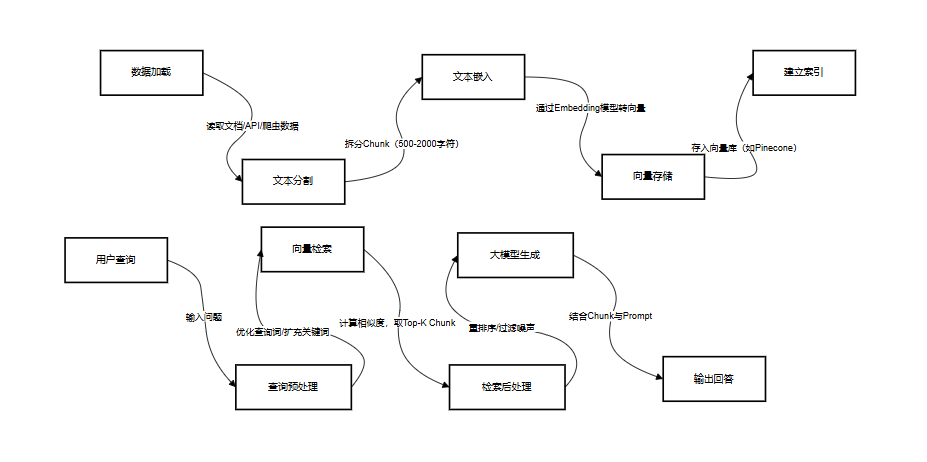
2.2.1 数据索引阶段:准备可检索的知识
- 加载(Loading):支持多源数据接入,如本地 PDF/Word 文档、数据库表、API 接口数据、网页爬虫结果;
- 分割(Splitting):将长文档拆分为小知识块(Chunk),常用策略:
- 按固定长度分割(如每 500 字符一个 Chunk);
- 按语义分割(如段落、章节边界);
- 示例:将 100 页产品手册拆分为 200 个 Chunk,每个 Chunk 包含 1-2 个产品功能说明;
- 嵌入(Embedding):通过 Embedding 模型(如 OpenAI text-embedding-3-small)将 Chunk 转为高维向量,捕捉语义信息;
- 代码示例(使用 OpenAI Embedding):
from openai import OpenAI client = OpenAI(api_key="your-api-key") def embed_text(text: str) -> list[float]: response = client.embeddings.create( input=text, model="text-embedding-3-small" ) return response.data[0].embedding # 测试:将Chunk转为向量 chunk = "大模型微调是指用少量领域数据更新模型参数,适配特定场景" vector = embed_text(chunk) print(f"向量维度:{len(vector)}") # 输出:768(text-embedding-3-small默认维度)
- 代码示例(使用 OpenAI Embedding):
- 索引(Indexing):将向量存入向量库(如 Pinecone、Milvus),建立快速检索索引,支持按语义相似度查询。
2.2.2 数据查询阶段:生成精准回答
- 查询预处理:优化用户输入,如将 “咋查订单” 转为 “如何查询我的电商订单物流状态”,提升检索准确性;
- 检索(Retrieval):将用户查询转为向量,在向量库中计算相似度(如余弦相似度),获取 Top-K(如 Top-5)最相关的 Chunk;
- 检索后处理:对 Chunk 重排序(如用 Cross-Encoder 模型优化排序)、过滤无关内容(如去除重复 Chunk);
- 生成(Generation):将 “用户查询 + Top-K Chunk” 拼接为 Prompt,送入大模型生成回答,示例 Prompt:
基于以下参考信息,回答用户问题: 参考信息1:电商订单物流查询需提供订单号,路径为「我的订单-订单详情-物流跟踪」 参考信息2:若订单发货后超过3天未更新物流,可联系客服补发 用户问题:如何查询我的电商订单物流?若物流3天没更新怎么办?
2.3 RAG 的典型应用场景:客户服务聊天机器人
以电商客服为例,RAG 的应用流程如下:
- 用户输入:“我上周买的手机什么时候到?”;
- 检索外部知识:RAG 系统自动检索 “用户订单数据库”,获取订单号、发货时间、物流单号;
- 增强回答:大模型结合检索到的信息(如 “订单 12345 已于 2024-12-25 发货,物流单号 YT6789”),生成回答;
- 输出结果:“您购买的手机已于 2024-12-25 发货,物流单号 YT6789,预计 2024-12-30 送达,可在「我的订单」中查看实时物流。”
三、大模型、RAG、Agent 的核心区别
三者并非替代关系,而是 “基础 - 增强 - 应用” 的层级关系,核心差异如下表:
| 对比维度 | 大模型(Large Model) | RAG(检索增强生成) | Agent(智能体) |
|---|---|---|---|
| 核心定义 | 百亿级参数神经网络,预训练获取通用能力 | 结合 “检索外部知识 + 大模型生成”,增强准确性 | 以大模型为 “大脑”,能自主规划、调用工具完成任务 |
| 知识来源 | 静态训练数据,知识截止后无法更新 | 实时外部数据库 / 文档 / API,无需重训 | 融合大模型知识、RAG 结果、工具返回数据 |
| 知识时效性 | 受训练数据限制,需重训 / 微调更新 | 外部数据实时更新,天然支持最新信息 | 结合 RAG 后支持实时数据,可主动抓取更新 |
| 生成准确性 | 易产生幻觉,专业领域准确率低 | 依赖可靠 Chunk,显著降低幻觉 | 多轮验证(如交叉查询多个数据源),错误率更低 |
| 成本 | 训练成本极高(百万级),推理成本随参数增加 | 仅需构建向量库,推理成本低(减少 Token 消耗) | RAG 成本 + 工具调用成本,可通过缓存优化 |
| 典型应用 | 文本创作、翻译、通用问答 | 企业文档助手、客服机器人、专业领域问答 | 旅行规划、智能运维、自动数据分析 |
| 技术组件 | Transformer、自注意力机制、预训练 + 微调 | Embedding 模型、向量库、检索器、重排序模型 | 规划器、工具集、记忆模块、执行器 |
三者关系:大模型是基础能力提供者,RAG 是大模型的 “知识增强插件”,Agent 是将两者落地到实际任务的 “应用载体”。
四、实战:基于 llama-index 搭建 RAG 聊天项目
4.1 环境准备:创建虚拟环境与依赖管理
4.1.1 搭建 Python 虚拟环境
使用 PyCharm 或终端创建虚拟环境,避免依赖冲突:
# 1. 创建项目目录
mkdir llama-index-rag-demo && cd llama-index-rag-demo
# 2. 创建虚拟环境(Python 3.10+)
python -m venv .venv
# 3. 激活虚拟环境(Windows)
.venv\Scripts\activate
# 激活虚拟环境(Mac/Linux)
source .venv/bin/activate
# 4. 查看已安装模块
pip list
4.1.2 依赖导出与导入
为便于项目迁移,需将依赖保存到requirements.txt:
# 导出依赖方式1:pip freeze(包含所有依赖,适合完整环境复制)
pip freeze > requirements.txt
# 导出依赖方式2:pipreqs(仅导出项目实际使用的依赖,推荐)
pip install pipreqs
pipreqs . --ignore .venv --encoding=utf8 --force
# 导入依赖(新环境中执行)
pip install -r requirements.txt
4.2 安装 llama-index 框架
llama-index 是专注于 “大模型 + 外部数据” 集成的框架,简化 RAG 开发流程:
# 基础安装(包含核心功能)
pip install llama-index
# 若需集成OpenAI/DeepSeek等模型,安装对应扩展
pip install llama-index-llms-openai
pip install llama-index-embeddings-openai
验证安装是否成功:
pip show llama-index
# 输出示例:Version: 0.12.8,Summary: Interface between LLMs and your data
4.3 配置 DeepSeek 模型:解决 API 调用问题
4.3.1 注册 DeepSeek 与获取 API Key
- 访问DeepSeek 开放平台注册账号;
- 进入 “API Keys” 页面,点击 “创建 API Key”,保存生成的 Key(仅显示一次)。
4.3.2 编写模型配置文件(llms.py)
llama-index 默认支持 OpenAI 模型,需手动配置 DeepSeek:
from llama_index.llms.openai import OpenAI
def deepseek_llm(**kwargs):
"""配置DeepSeek聊天模型"""
return OpenAI(
api_key="sk-你的DeepSeek-API-Key", # 替换为实际Key
model="deepseek-chat", # DeepSeek聊天模型名称
api_base="https://api.deepseek.com/v1", # DeepSeek API基础地址
temperature=0.7, # 创造性:0(严谨)~1(灵活)
**kwargs
)
def moonshot_llm(**kwargs):
"""可选:配置Moonshot( kimi )模型"""
return OpenAI(
api_key="sk-你的Moonshot-API-Key",
model="kimi-k2-0711-preview",
api_base="https://api.moonshot.cn/v1",
temperature=0.7,
**kwargs
)
4.3.3 解决 “Unknown model 'deepseek-chat'” 报错
llama-index 默认不识别 DeepSeek 模型,需手动添加模型配置:
- 找到 llama-index 的模型配置文件:
.venv/Lib/site-packages/llama_index/llms/openai/utils.py; - 在文件中添加 DeepSeek 模型定义:
from typing import Dict # 新增DeepSeek模型配置(token限制64000) DEEPSEEK_MODELS: Dict[str, int] = { "deepseek-chat": 64000, } # 新增Moonshot模型配置(可选) MOONSHOT_MODELS: Dict[str, int] = { "kimi-k2-0711-preview": 128000, } # 更新可用模型列表 ALL_AVAILABLE_MODELS.update(DEEPSEEK_MODELS) ALL_AVAILABLE_MODELS.update(MOONSHOT_MODELS) CHAT_MODELS.update(DEEPSEEK_MODELS) CHAT_MODELS.update(MOONSHOT_MODELS)
4.4 编写聊天核心代码(main.py)
基于 llama-index 创建简单的 RAG 聊天引擎,支持实时交互:
from llama_index.core import Settings
from llama_index.core.chat_engine import SimpleChatEngine
from llms import deepseek_llm # 导入自定义DeepSeek模型
# 1. 配置全局大模型
Settings.llm = deepseek_llm()
# 2. 创建聊天引擎(SimpleChatEngine适合基础交互)
chat_engine = SimpleChatEngine.from_defaults()
# 3. 启动流式交互循环(REPL:Read-Eval-Print Loop)
print("进入聊天模式,输入'exit'退出")
while True:
user_input = input("Human: ")
if user_input.lower() == "exit":
print("Chat Engine: 再见!")
break
# 流式获取回答(逐Token输出,提升体验)
response = chat_engine.stream_chat(message=user_input)
print("Chat Engine: ", end="")
for token in response.response_gen:
print(token, end="", flush=True)
print("\n" + "-"*50)
4.5 运行与测试
- 执行
main.py:python main.py - 测试交互示例:
进入聊天模式,输入'exit'退出 Human: 介绍RAG技术的核心流程 Chat Engine: RAG(检索增强生成)的核心流程分为数据索引和数据查询两个阶段... -------------------------------------------------- Human: 如何用llama-index配置DeepSeek模型 Chat Engine: 首先需在DeepSeek开放平台注册账号并获取API Key,然后创建llms.py文件配置模型参数... --------------------------------------------------
五、总结
项目核心流程回顾
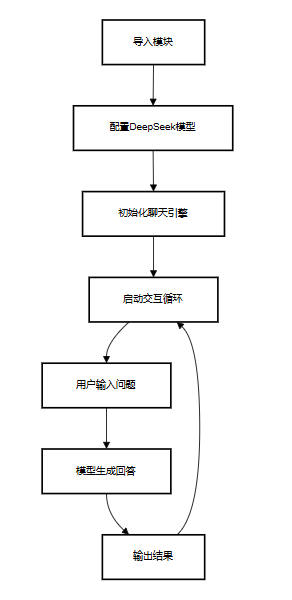
通过本文,你已掌握大模型基础、RAG 核心原理,以及基于 llama-index 的实战开发流程。
如果实践操作中遇到其他问题,也可以在评论区留言,Fly帮你在线答疑!!!
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)