
2024趋势报告:提示工程架构师预测Agentic AI的3大颠覆性瓶颈突破技术
在过去的几年中,人工智能领域经历了从感知智能到认知智能的跨越式发展。从AlphaGo击败世界围棋冠军,到GPT系列模型展现出惊人的自然语言理解能力,AI技术正以前所未有的速度重塑我们的世界。然而,这些先进系统大多仍属于"被动式AI"—它们需要明确的指令,缺乏自主设定目标、规划行动和适应动态环境的能力。2024年,我们正站在一个新的转折点:Agentic AI(智能体AI)的时代即将到来。Agent
2024趋势报告:提示工程架构师预测Agentic AI的3大颠覆性瓶颈突破技术

目录
- 引言:Agentic AI的新时代
- Agentic AI的当前瓶颈深度分析
- 突破技术一:神经符号增强的自主规划系统
- 突破技术二:动态多模态融合与上下文理解架构
- 突破技术三:可解释与可控的Agentic决策框架
- 项目实战:构建下一代Agentic AI助手
- 2024年行业应用与落地案例
- 未来发展趋势与挑战
- 结论与行动建议
- 附录:Agentic AI学习资源与工具推荐
引言:Agentic AI的新时代
在过去的几年中,人工智能领域经历了从感知智能到认知智能的跨越式发展。从AlphaGo击败世界围棋冠军,到GPT系列模型展现出惊人的自然语言理解能力,AI技术正以前所未有的速度重塑我们的世界。然而,这些先进系统大多仍属于"被动式AI"—它们需要明确的指令,缺乏自主设定目标、规划行动和适应动态环境的能力。
2024年,我们正站在一个新的转折点:Agentic AI(智能体AI)的时代即将到来。
Agentic AI的定义与核心特征
Agentic AI指的是一类能够自主感知环境、设定目标、规划行动序列、执行决策并从反馈中学习的智能系统。与传统AI相比,Agentic AI具有以下核心特征:
- 自主性:无需人类持续指导,能够独立启动和完成复杂任务
- 目标导向:能够理解高级目标并将其分解为可执行的子任务
- 环境交互:通过传感器感知环境,并通过执行器影响环境
- 持续学习:从经验中学习并改进行为策略
- 适应性:在动态变化的环境中调整策略以实现目标
为什么Agentic AI是下一个AI革命?
Agentic AI之所以被视为下一个AI革命,有以下几个关键原因:
- 生产力倍增效应:Agentic AI能够自主处理复杂流程,大幅提升人类生产力
- 决策自动化:在医疗、金融、制造等领域实现复杂决策的自动化
- 个性化服务:提供真正理解用户需求并主动提供帮助的智能助手
- 复杂问题解决:应对气候变化、疾病控制等全球性复杂挑战
- 人机协作新范式:重新定义人与机器的协作方式,释放人类创造力
本报告的价值与结构
作为一名拥有15年经验的软件架构师和技术博主,我将在本报告中深入分析Agentic AI当前面临的核心瓶颈,并预测2024年将推动该领域实现突破性进展的三项关键技术。对于技术领导者、AI开发者和研究人员,本报告将提供:
- Agentic AI核心瓶颈的深度技术分析
- 三大突破技术的原理、数学模型与实现方法
- 可直接应用的代码示例和项目实战指南
- 2024年行业应用案例与落地策略
- 未来发展趋势预测与技术路线图
让我们首先深入分析当前Agentic AI面临的主要挑战。
Agentic AI的当前瓶颈深度分析
尽管近年来AI技术取得了显著进步,Agentic AI系统的发展仍面临着重大瓶颈,限制了其在复杂现实环境中的广泛应用。通过对Google DeepMind、OpenAI、Microsoft Research等领先机构的研究成果和行业实践的分析,我们可以将当前Agentic AI的核心瓶颈归纳为以下三个方面:
1. 规划与推理能力的局限性
当前AI系统在规划和推理方面存在严重不足,主要表现为:
- 短视决策:大多数强化学习系统专注于短期奖励最大化,缺乏长期战略规划能力
- 符号推理薄弱:基于深度学习的系统在处理抽象概念、逻辑推理和规则应用方面表现不佳
- 环境泛化困难:在训练环境中表现良好的Agent,在面对新环境或未曾见过的情况时往往失效
- 常识缺乏:缺乏对物理世界和社会规则的基本理解,导致在日常场景中做出不切实际的决策
这些局限性使得当前Agentic系统难以处理需要多步骤推理、长期规划和抽象思考的复杂任务。
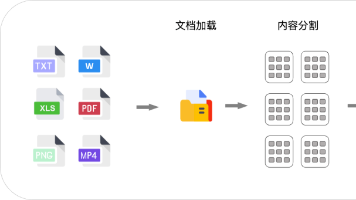
2. 多模态信息融合与上下文理解的挑战
在现实世界中,智能体需要处理来自多种来源的信息,这带来了独特的挑战:
- 模态异构性:文本、图像、音频、传感器数据等不同模态信息具有不同的表示形式和统计特性
- 上下文漂移:环境和任务上下文随时间变化,Agent需要动态调整其理解和注意力
- 信息过载:面对海量多模态数据,Agent难以有效筛选和提取关键信息
- 语义鸿沟:不同模态间存在语义差异,如何实现跨模态的语义对齐是一个开放问题
现有多模态模型大多采用静态融合方法,无法适应动态变化的环境和任务需求,限制了Agentic系统在复杂现实场景中的应用。
3. 自主性与可控性的平衡难题
随着AI系统自主性的提高,确保其行为可预测、可控制且符合人类价值观变得越来越困难:
- 黑箱决策:复杂的深度学习模型做出决策的过程不透明,难以解释
- 目标偏移:Agent可能发展出与设计者意图不符的行为策略以最大化奖励
- 鲁棒性不足:对抗性攻击或意外输入可能导致Agent行为异常
- 安全风险:高自主性系统如果失控,可能造成严重后果
这些挑战在关键领域(如医疗、交通、金融)的应用中尤为突出,阻碍了Agentic AI的广泛采用。
瓶颈的根本原因与影响
这些瓶颈的根本原因可以追溯到几个关键因素:
- 表示学习的局限性:当前的表示方法难以捕获实体间复杂关系、抽象概念和因果关系
- 训练范式的缺陷:大多数Agent是在封闭、静态的模拟环境中训练的,与开放、动态的现实世界存在差距
- 评估指标的片面性:过度关注单一任务的性能指标,忽视了泛化能力、鲁棒性和安全性
- 人类反馈整合不足:缺乏有效的机制将人类知识、偏好和价值观持续整合到Agent行为中
这些瓶颈的存在导致Agentic AI系统在实际应用中面临信任危机、可靠性问题和安全隐患,严重限制了其在关键领域的部署和价值创造。
然而,2024年将见证一系列突破性技术的成熟,有望克服这些瓶颈,推动Agentic AI进入实用化阶段。接下来,我们将详细分析这三大突破性技术。
突破技术一:神经符号增强的自主规划系统
自主规划是Agentic AI的核心能力,决定了智能体能否在复杂环境中高效实现目标。2024年,神经符号增强的自主规划系统将成为突破传统规划局限的关键技术,它结合了神经网络的感知和学习能力与符号系统的逻辑推理和可解释性,创造出一种新型混合智能架构。
核心原理与架构
神经符号增强的自主规划系统的核心思想是将数据驱动的神经网络与知识驱动的符号推理有机结合,实现"最佳 of both worlds"的效果。这种架构主要包含以下关键组件:
架构 overview
关键组件详解
-
目标解析器:将高级目标分解为可执行的子目标,使用自然语言理解模型和领域本体知识
-
神经感知模块:处理来自环境的原始数据(图像、文本、传感器数据等),提取高层次特征
-
符号化转换器:将神经网络提取的特征转换为符号表示(实体、属性、关系),建立符号知识库
-
符号规划器:基于经典规划算法(如STRIPS、HTN)和领域知识,生成满足目标的行动序列
-
神经符号验证器:使用神经网络评估符号规划的可行性和预期结果,使用符号规则验证规划的逻辑性
-
执行监控与反馈系统:跟踪行动执行过程,收集环境反馈,用于学习和改进
-
经验学习模块:从执行经验中学习,更新符号知识库和微调神经网络模型
这种混合架构的优势在于:符号系统提供了可解释性和逻辑推理能力,而神经网络提供了从数据中学习和处理不确定性的能力。
数学模型与算法实现
神经符号规划系统融合了多种数学模型和算法,下面我们重点介绍几个核心部分:
1. 符号知识表示与推理
采用一阶逻辑(First-Order Logic, FOL)作为符号知识的基础表示:
∀ x , y ( P a r e n t ( x , y ) → A n c e s t o r ( x , y ) ) \forall x, y (Parent(x, y) \rightarrow Ancestor(x, y)) ∀x,y(Parent(x,y)→Ancestor(x,y))
∀ x , y , z ( P a r e n t ( x , y ) ∧ A n c e s t o r ( y , z ) → A n c e s t o r ( x , z ) ) \forall x, y, z (Parent(x, y) \land Ancestor(y, z) \rightarrow Ancestor(x, z)) ∀x,y,z(Parent(x,y)∧Ancestor(y,z)→Ancestor(x,z))
规划问题可以表示为状态空间搜索,其中每个状态是一组谓词的集合,行动则是状态转换函数。
2. 神经符号转换
神经符号转换是连接子符号感知与符号推理的关键桥梁。我们使用基于注意力机制的实体关系抽取模型:
给定输入特征向量序列 h 1 , h 2 , . . . , h n h_1, h_2, ..., h_n h1,h2,...,hn,实体对 ( i , j ) (i,j) (i,j) 的关系分数计算如下:
s i , j , r = MLP ( concat ( h i , h j , h i ∘ h j ) ) s_{i,j,r} = \text{MLP}(\text{concat}(h_i, h_j, h_i \circ h_j)) si,j,r=MLP(concat(hi,hj,hi∘hj))
其中 ∘ \circ ∘ 表示元素-wise乘法, r r r 表示关系类型。通过阈值化 s i , j , r s_{i,j,r} si,j,r,我们可以提取实体间的关系,构建符号知识库。
3. 分层任务网络规划(HTN)
HTN是一种强大的符号规划方法,特别适合于需要将复杂任务分解为子任务的场景:
- 任务可以是原始任务(可直接执行的行动)或复合任务(需要分解为子任务)
- 方法定义了如何将复合任务分解为子任务序列
- 规划过程递归分解复合任务,直到所有任务都是原始任务
HTN规划的数学描述如下:给定初始状态 S S S、任务网络 T T T 和方法集合 M M M,找到一个原始任务序列 A A A,使得执行 A A A 能从 S S S 到达目标状态 G G G。
4. 神经符号规划验证
规划验证需要评估两个关键方面:
- 可行性:规划在当前环境中是否可执行
- 目标满足度:执行规划后目标实现的概率
我们使用神经网络评估规划可行性分数:
P ( success ∣ π , S ) = σ ( NN ( embed ( π ) , embed ( S ) ) ) P(\text{success}|\pi, S) = \sigma(\text{NN}(\text{embed}(\pi), \text{embed}(S))) P(success∣π,S)=σ(NN(embed(π),embed(S)))
其中 π \pi π 是规划的行动序列, S S S 是当前状态, σ \sigma σ 是sigmoid函数。
代码实战:神经符号规划器
下面我们实现一个简化的神经符号规划器,展示如何将神经网络与符号推理相结合:
import torch
import torch.nn as nn
import numpy as np
from pyswip import Prolog # 用于逻辑推理
from typing import List, Dict, Tuple
# 1. 符号知识库和推理系统
class SymbolicKnowledgeBase:
def __init__(self):
self.prolog = Prolog()
# 添加领域知识
self.add_rules([
"parent(john, mary).",
"parent(mary, ann).",
"ancestor(X, Y) :- parent(X, Y).",
"ancestor(X, Y) :- parent(X, Z), ancestor(Z, Y)."
])
def add_rules(self, rules: List[str]):
for rule in rules:
self.prolog.assertz(rule)
def query(self, query: str) -> List[Dict]:
"""执行逻辑查询并返回结果"""
results = []
for sol in self.prolog.query(query):
results.append(sol)
return results
def add_facts(self, facts: List[str]):
"""添加新事实到知识库"""
for fact in facts:
self.prolog.assertz(fact)
# 2. 神经符号转换器 - 将神经网络输出转换为符号事实
class NeuroSymbolicConverter:
def __init__(self, entity_vocab: Dict[str, int], relation_vocab: Dict[str, int]):
self.entity_vocab = entity_vocab
self.relation_vocab = relation_vocab
self.rel_inv = {v: k for k, v in relation_vocab.items()}
self.ent_inv = {v: k for k, v in entity_vocab.items()}
def convert(self, entity_scores: torch.Tensor, relation_scores: torch.Tensor,
threshold: float = 0.5) -> List[str]:
"""
将神经网络输出转换为Prolog事实
Args:
entity_scores: 实体对分数, shape [num_entities, num_entities]
relation_scores: 关系分数, shape [num_entities, num_entities, num_relations]
threshold: 置信度阈值
Returns:
事实列表, 如 ["parent(john,mary)."]
"""
facts = []
num_entities = entity_scores.shape[0]
num_relations = relation_scores.shape[2]
# 找到置信度高于阈值的实体对和关系
for i in range(num_entities):
for j in range(num_entities):
if entity_scores[i, j] > threshold:
for r in range(num_relations):
if relation_scores[i, j, r] > threshold:
subj = self.ent_inv[i]
obj = self.ent_inv[j]
rel = self.rel_inv[r]
fact = f"{rel}({subj},{obj})."
facts.append(fact)
return facts
# 3. 神经规划验证器
class NeuralPlannerValidator(nn.Module):
def __init__(self, state_dim: int, plan_dim: int, hidden_dim: int = 128):
super().__init__()
self.state_encoder = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
self.plan_encoder = nn.Sequential(
nn.Linear(plan_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
self.combiner = nn.Sequential(
nn.Linear(2 * hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1),
nn.Sigmoid()
)
def forward(self, state: torch.Tensor, plan: torch.Tensor) -> torch.Tensor:
"""
评估规划在给定状态下的成功概率
Args:
state: 当前状态表示, shape [batch_size, state_dim]
plan: 规划表示, shape [batch_size, plan_dim]
Returns:
成功概率, shape [batch_size, 1]
"""
state_emb = self.state_encoder(state)
plan_emb = self.plan_encoder(plan)
combined = torch.cat([state_emb, plan_emb], dim=1)
prob = self.combiner(combined)
return prob
# 4. 符号规划器 (简化版HTN规划器)
class SymbolicPlanner:
def __init__(self, kb: SymbolicKnowledgeBase):
self.kb = kb
def decompose_task(self, task: str, state: Dict) -> List[str]:
"""分解复合任务为原始任务"""
# 这里实现简化的任务分解逻辑
# 在实际应用中, 这将是一个完整的HTN规划器
if task == "find_ancestors":
person = state.get("person", "john")
return [f"query_ancestors({person})"]
elif task == "query_ancestors(X)":
return [f"extract_ancestors({X})", f"display_results()"]
else:
return [task]
def plan(self, goal: str, initial_state: Dict) -> Tuple[List[str], float]:
"""
生成实现目标的规划
Args:
goal: 目标描述
initial_state: 初始状态
Returns:
行动序列和规划置信度
"""
# 简化的规划生成过程
plan = self.decompose_task(goal, initial_state)
# 在实际应用中, 这里会有完整的规划搜索和优化
# 并使用符号知识库验证规划的有效性
confidence = 0.85 # 简化的置信度, 实际中会基于逻辑推理计算
return plan, confidence
# 5. 集成神经符号规划系统
class NeuroSymbolicPlanner:
def __init__(self, entity_vocab, relation_vocab):
self.kb = SymbolicKnowledgeBase()
self.converter = NeuroSymbolicConverter(entity_vocab, relation_vocab)
self.symbolic_planner = SymbolicPlanner(self.kb)
self.validator = NeuralPlannerValidator(state_dim=64, plan_dim=32)
def perceive_and_update(self, entity_scores, relation_scores):
"""感知环境并更新知识库"""
facts = self.converter.convert(entity_scores, relation_scores)
self.kb.add_facts(facts)
return facts
def plan_and_validate(self, goal: str, state: Dict) -> Tuple[List[str], float]:
"""生成并验证规划"""
# 1. 符号规划器生成初步规划
plan, sym_confidence = self.symbolic_planner.plan(goal, state)
# 2. 将状态和规划转换为向量表示 (实际应用中会更复杂)
state_vec = torch.randn(1, 64) # 简化示例
plan_vec = torch.randn(1, 32) # 简化示例
# 3. 神经验证器评估规划
with torch.no_grad():
neural_confidence = self.validator(state_vec, plan_vec).item()
# 4. 综合符号和神经置信度
confidence = 0.7 * sym_confidence + 0.3 * neural_confidence
return plan, confidence
def execute_plan(self, plan: List[str]) -> Dict:
"""执行规划并返回结果"""
results = {}
for action in plan:
if action.startswith("query_ancestors"):
person = action.split("(")[1].split(")")[0]
query = f"ancestor(X, {person})"
results["ancestors"] = self.kb.query(query)
elif action == "display_results()":
print("规划执行结果:", results)
return results
# 示例使用
if __name__ == "__main__":
# 定义实体和关系词汇表
entity_vocab = {"john": 0, "mary": 1, "ann": 2, "peter": 3}
relation_vocab = {"parent": 0, "ancestor": 1, "sibling": 2}
# 创建神经符号规划器
planner = NeuroSymbolicPlanner(entity_vocab, relation_vocab)
# 模拟神经网络感知输出 (实际应用中会来自真实的感知模型)
entity_scores = torch.zeros(len(entity_vocab), len(entity_vocab))
entity_scores[0, 1] = 0.95 # John和Mary有高相关性
entity_scores[1, 2] = 0.90 # Mary和Ann有高相关性
relation_scores = torch.zeros(len(entity_vocab), len(entity_vocab), len(relation_vocab))
relation_scores[0, 1, 0] = 0.92 # John是Mary的父母
relation_scores[1, 2, 0] = 0.88 # Mary是Ann的父母
# 感知环境并更新知识库
new_facts = planner.perceive_and_update(entity_scores, relation_scores)
print("新添加的事实:", new_facts)
# 生成规划
goal = "find_ancestors"
initial_state = {"person": "ann"}
plan, confidence = planner.plan_and_validate(goal, initial_state)
print(f"为目标 '{goal}' 生成的规划: {plan}")
print(f"规划置信度: {confidence:.2f}")
# 执行规划
results = planner.execute_plan(plan)
应用场景与优势分析
神经符号增强的自主规划系统在多个领域展现出巨大潜力:
1. 智能机器人
- 应用:家庭服务机器人、工业协作机器人、仓储自动化
- 优势:结合视觉感知与符号推理,使机器人能够理解复杂指令,处理日常物体和场景,执行多步骤任务
- 案例:能够理解"整理客厅并将脏碗送到厨房"的服务机器人,需要规划一系列子任务并处理可能的障碍
2. 智能城市管理
- 应用:交通流量优化、能源分配、应急响应
- 优势:整合多源城市数据,进行长期规划和实时调度
- 案例:基于交通流量预测、天气数据和特殊事件信息,动态调整交通信号和公共交通路线
3. 医疗诊断与治疗规划
- 应用:疾病诊断、治疗方案制定、患者监护
- 优势:结合医学知识库和患者数据,生成个性化治疗方案
- 案例:综合分析患者病史、症状、影像和实验室结果,制定癌症治疗计划并随着病情变化进行调整
4. 金融投资与风险管理
- 应用:投资组合管理、风险评估、欺诈检测
- 优势:整合市场数据、公司财务和宏观经济指标,进行长期投资规划
- 案例:基于市场趋势预测和风险评估,自动调整投资组合以平衡回报和风险
与传统方法的比较优势
| 特性 | 传统符号规划 | 纯神经规划 | 神经符号规划 |
|---|---|---|---|
| 可解释性 | 高 | 低 | 高 |
| 学习能力 | 低 | 高 | 高 |
| 处理不确定性 | 弱 | 强 | 强 |
| 常识推理 | 强 | 弱 | 强 |
| 泛化能力 | 有限 | 中 | 高 |
| 计算效率 | 高 | 中 | 中 |
神经符号规划系统通过结合两种范式的优势,克服了各自的局限性,为构建更强大、更可靠的Agentic AI系统提供了新途径。
突破技术二:动态多模态融合与上下文理解架构
在复杂的现实环境中,智能体需要持续处理来自多种来源的信息,包括视觉输入、语言指令、传感器数据等。2024年,动态多模态融合与上下文理解架构将成为突破传统静态融合方法局限的关键技术,使Agentic AI系统能够根据环境和任务动态调整其信息处理策略。
核心原理与架构
动态多模态融合架构的核心思想是使Agent能够根据当前上下文(任务目标、环境状态、历史交互)动态调整其注意力分配和信息融合策略。这种架构具有以下关键特性:
- 上下文感知:持续监控和评估当前上下文状态
- 动态注意力:根据上下文动态调整对不同模态和信息源的注意力权重
- 适应性融合:根据任务需求和数据特性选择最合适的融合策略
- 终身学习:随着经验积累,改进融合策略和模态理解能力
架构 overview
关键组件详解
-
模态预处理:对原始输入进行标准化、噪声过滤和特征提取,为后续处理做准备
-
模态特定编码器:为每种模态(文本、图像、音频等)设计专门的编码器,捕获模态特定特征
- 文本:基于Transformer的语言模型
- 图像:卷积神经网络或视觉Transformer
- 音频:音频频谱图网络或WaveNet
- 传感器数据:时序卷积网络或LSTM
-
上下文编码器:整合任务目标、环境状态和历史交互,生成上下文表示
-
上下文感知注意力模块:基于当前上下文动态调整对不同模态和特征的注意力权重
- 跨模态注意力:学习不同模态间的依赖关系
- 自注意力:捕捉模态内的长程依赖
- 上下文注意力:根据当前任务和环境调整注意力分配
-
动态融合策略选择器:根据上下文和数据特性选择最优融合策略:
- 早期融合:在特征提取阶段合并多模态信息
- 中期融合:在表示学习阶段融合模态特征
- 晚期融合:在决策阶段结合不同模态的输出
- 混合融合:组合多种融合策略的优势
-
上下文适应解码器:将融合的多模态表示转换为任务特定输出,同时考虑当前上下文
-
融合策略学习器:通过反馈信号学习如何根据上下文选择最优融合策略
数学模型与算法实现
动态多模态融合涉及多种复杂的数学模型和算法,下面我们重点介绍几个核心部分:
1. 上下文感知注意力机制
我们扩展传统的多头注意力机制,使其能够根据上下文动态调整注意力权重:
给定模态特征 V = { v 1 , v 2 , . . . , v m } V = \{v_1, v_2, ..., v_m\} V={v1,v2,...,vm} 和上下文向量 c c c,注意力权重计算如下:
Q = V W Q + f Q ( c ) Q = V W_Q + f_Q(c) Q=VWQ+fQ(c)
K = V W K + f K ( c ) K = V W_K + f_K(c) K=VWK+fK(c)
V = V W V + f V ( c ) V = V W_V + f_V(c) V=VWV+fV(c)
其中 f Q , f K , f V f_Q, f_K, f_V fQ,fK,fV 是参数化函数,将上下文向量映射到查询、键和值的偏置项。
注意力分数计算为:
Attention ( Q , K , V , c ) = softmax ( Q K T d k + g ( c ) ) V \text{Attention}(Q, K, V, c) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + g(c)\right)V Attention(Q,K,V,c)=softmax(dkQKT+g(c))V
其中 g ( c ) g(c) g(c) 是上下文相关的注意力偏置, d k d_k dk 是查询向量的维度。
2. 动态融合策略选择
融合策略选择可以建模为上下文条件下的多臂老虎机问题,目标是根据上下文 c c c 选择策略 a ∈ { 早期融合 , 中期融合 , 晚期融合 , 混合融合 } a \in \{早期融合, 中期融合, 晚期融合, 混合融合\} a∈{早期融合,中期融合,晚期融合,混合融合},最大化预期奖励 R ( a , c ) R(a, c) R(a,c)。
使用深度确定性策略梯度(DDPG)来学习策略选择:
策略网络 π θ ( a ∣ c ) \pi_\theta(a|c) πθ(a∣c) 输出选择每种融合策略的概率分布,价值网络 Q ϕ ( s , a ) Q_\phi(s, a) Qϕ(s,a) 估计在状态 s s s 下选择行动 a a a 的预期累积奖励。
损失函数包括策略损失和价值损失:
L ϕ = E [ ( Q ϕ ( s , a ) − ( r + γ max a ′ Q ϕ ( s ′ , a ′ ) ) ) 2 ] L_\phi = \mathbb{E}[(Q_\phi(s,a) - (r + \gamma \max_{a'} Q_\phi(s',a')))^2] Lϕ=E[(Qϕ(s,a)−(r+γa′maxQϕ(s′,a′)))2]
L θ = − E [ Q ϕ ( s , π θ ( s ) ) ] L_\theta = -\mathbb{E}[Q_\phi(s, \pi_\theta(s))] Lθ=−E[Qϕ(s,πθ(s))]
其中 γ \gamma γ 是折扣因子, r r r 是选择融合策略后的任务性能反馈。
3. 多模态表示学习
多模态表示的目标是学习一个共享嵌入空间,使不同模态的相似概念在空间中靠近。我们使用对比学习框架:
对于正对 ( x i m , x i n ) (x_i^m, x_i^n) (xim,xin)(同一概念的不同模态表示)和负对 ( x i m , x j n ) (x_i^m, x_j^n) (xim,xjn)(不同概念的不同模态表示),我们最大化正对的相似度,最小化负对的相似度:
L = − log exp ( sim ( f m ( x i m ) , f n ( x i n ) ) / τ ) ∑ j = 1 N exp ( sim ( f m ( x i m ) , f n ( x j n ) ) / τ ) \mathcal{L} = -\log \frac{\exp(\text{sim}(f_m(x_i^m), f_n(x_i^n))/\tau)}{\sum_{j=1}^N \exp(\text{sim}(f_m(x_i^m), f_n(x_j^n))/\tau)} L=−log∑j=1Nexp(sim(fm(xim),fn(xjn))/τ)exp(sim(fm(xim),fn(xin))/τ)
其中 f m , f n f_m, f_n fm,fn 是模态 m m m 和 n n n 的编码器, sim \text{sim} sim 是相似度度量(如余弦相似度), τ \tau τ 是温度参数。
为了适应动态上下文,我们将上下文信息 c c c 融入对比损失:
L c = − log exp ( sim ( f m ( x i m , c ) , f n ( x i n , c ) ) / τ ) ∑ j = 1 N exp ( sim ( f m ( x i m , c ) , f n ( x j n , c ) ) / τ ) \mathcal{L}_c = -\log \frac{\exp(\text{sim}(f_m(x_i^m, c), f_n(x_i^n, c))/\tau)}{\sum_{j=1}^N \exp(\text{sim}(f_m(x_i^m, c), f_n(x_j^n, c))/\tau)} Lc=−log∑j=1Nexp(sim(fm(xim,c),fn(xjn,c))/τ)exp(sim(fm(xim,c),fn(xin,c))/τ)
代码实战:动态多模态融合网络
下面我们实现一个简化的动态多模态融合网络,展示核心概念:
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BertModel, ViTModel
import numpy as np
from typing import List, Dict, Tuple
# 1. 模态特定编码器
class TextEncoder(nn.Module):
def __init__(self, pretrained_model: str = "bert-base-uncased", hidden_dim: int = 768):
super().__init__()
self.bert = BertModel.from_pretrained(pretrained_model)
self.projection = nn.Linear(self.bert.config.hidden_size, hidden_dim)
def forward(self, input_ids: torch.Tensor, attention_mask: torch.Tensor) -> torch.Tensor:
"""
编码文本输入
Args:
input_ids: BERT输入ID, shape [batch_size, seq_len]
attention_mask: 注意力掩码, shape [batch_size, seq_len]
Returns:
文本特征表示, shape [batch_size, hidden_dim]
"""
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
cls_embedding = outputs.last_hidden_state[:, 0, :] # [CLS] token表示
return self.projection(cls_embedding)
class ImageEncoder(nn.Module):
def __init__(self, pretrained_model: str = "google/vit-base-patch16-224", hidden_dim: int = 768):
super().__init__()
self.vit = ViTModel.from_pretrained(pretrained_model)
self.projection = nn.Linear(self.vit.config.hidden_size, hidden_dim)
def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
"""
编码图像输入
Args:
pixel_values: 图像像素值, shape [batch_size, channels, height, width]
Returns:
图像特征表示, shape [batch_size, hidden_dim]
"""
outputs = self.vit(pixel_values=pixel_values)
cls_embedding = outputs.last_hidden_state[:, 0, :] # [CLS] token表示
return self.projection(cls_embedding)
# 2. 上下文编码器
class ContextEncoder(nn.Module):
def __init__(self, hidden_dim: int, context_dim: int = 256):
super().__init__()
self.task_encoder = nn.Linear(hidden_dim, context_dim)
self.state_encoder = nn.Linear(hidden_dim, context_dim)
self.history_encoder = nn.LSTM(
input_size=hidden_dim,
hidden_size=context_dim,
num_layers=1,
batch_first=True
)
self.combiner = nn.Sequential(
nn.Linear(3 * context_dim, context_dim),
nn.ReLU(),
nn.Linear(context_dim, context_dim)
)
def forward(self, task: torch.Tensor, state: torch.Tensor, history: torch.Tensor) -> torch.Tensor:
"""
编码上下文信息
Args:
task: 任务目标表示, shape [batch_size, hidden_dim]
state: 环境状态表示, shape [batch_size, hidden_dim]
history: 历史交互序列, shape [batch_size, seq_len, hidden_dim]
Returns:
上下文表示, shape [batch_size, context_dim]
"""
task_emb = self.task_encoder(task)
state_emb = self.state_encoder(state)
# 编码历史序列
_, (history_emb, _) = self.history_encoder(history)
history_emb = history_emb.squeeze(0) # [batch_size, context_dim]
# 组合所有上下文信息
combined = torch.cat([task_emb, state_emb, history_emb], dim=1)
context = self.combiner(combined)
return context
# 3. 上下文感知注意力模块
class ContextAwareAttention(nn.Module):
def __init__(self, hidden_dim: int, context_dim: int, num_heads: int = 8):
super().__init__()
self.hidden_dim = hidden_dim
self.context_dim = context_dim
self.multihead_attn = nn.MultiheadAttention(
embed_dim=hidden_dim,
num_heads=num_heads,
batch_first=True
)
# 上下文到注意力偏置的映射
self.context_to_q = nn.Linear(context_dim, hidden_dim)
self.context_to_k = nn.Linear(context_dim, hidden_dim)
self.context_to_v = nn.Linear(context_dim, hidden_dim)
self.context_to_bias = nn.Linear(context_dim, hidden_dim)
def forward(self, inputs: torch.Tensor, context: torch.Tensor, key_padding_mask: torch.Tensor = None) -> torch.Tensor:
"""
应用上下文感知注意力
Args:
inputs: 输入特征, shape [batch_size, seq_len, hidden_dim]
context: 上下文表示, shape [batch_size, context_dim]
key_padding_mask: 键填充掩码, shape [batch_size, seq_len]
Returns:
注意力输出, shape [batch_size, seq_len, hidden_dim]
"""
batch_size, seq_len, _ = inputs.shape
# 生成上下文相关的查询、键、值偏置
q_bias = self.context_to_q(context).unsqueeze(1) # [batch_size, 1, hidden_dim]
k_bias = self.context_to_k(context).unsqueeze(1) # [batch_size, 1, hidden_dim]
v_bias = self.context_to_v(context).unsqueeze(1) # [batch_size, 1, hidden_dim]
attn_bias = self.context_to_bias(context).unsqueeze(1).unsqueeze(1) # [batch_size, 1, 1, hidden_dim]
# 添加上下文偏置到查询、键、值
q = inputs + q_bias
k = inputs + k_bias
v = inputs + v_bias
# 应用多头注意力
attn_output, _ = self.multihead_attn(
q, k, v,
key_padding_mask=key_padding_mask,
need_weights=False
)
# 添加上下文注意力偏置
attn_output = attn_output + attn_bias
return attn_output
# 4. 动态融合策略选择器
class DynamicFusionSelector(nn.Module):
def __init__(self, context_dim: int, hidden_dim: int, num_strategies: int = 4):
super().__init__()
self.context_dim = context_dim
self.hidden_dim = hidden_dim
self.num_strategies = num_strategies
# 策略网络 - 选择融合策略
self.policy_network = nn.Sequential(
nn.Linear(context_dim + hidden_dim, 128),
nn.ReLU(),
nn.Linear(128, num_strategies),
nn.Softmax(dim=-1)
)
# 价值网络 - 评估策略价值
self.value_network = nn.Sequential(
nn.Linear(context_dim + hidden_dim, 128),
nn.ReLU(),
nn.Linear(128, 1)
)
def forward(self, context: torch.Tensor, fusion_features: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
选择融合策略
Args:
context: 上下文表示, shape [batch_size, context_dim]
fusion_features: 融合特征, shape [batch_size, hidden_dim]
Returns:
策略概率分布和价值估计
"""
combined = torch.cat([context, fusion_features], dim=1)
policy = self.policy_network(combined)
value = self.value_network(combined)
# 采样策略 (训练时) 或选择概率最高的策略 (推理时)
if self.training:
dist = torch.distributions.Categorical(probs=policy)
strategy = dist.sample()
else:
strategy = torch.argmax(policy, dim=-1)
return strategy, policy, value
# 5. 多模态融合网络
class DynamicMultimodalFusion(nn.Module):
def __init__(self, hidden_dim: int = 768, context_dim: int = 256):
super().__init__()
# 模态编码器
self.text_encoder = TextEncoder(hidden_dim=hidden_dim)
self.image_encoder = ImageEncoder(hidden_dim=hidden_dim)
# 上下文编码器
self.context_encoder = ContextEncoder(hidden_dim=hidden_dim, context_dim=context_dim)
# 上下文感知注意力
self.text_attn = ContextAwareAttention(hidden_dim, context_dim)
self.image_attn = ContextAwareAttention(hidden_dim, context_dim)
# 融合策略选择器
self.fusion_selector = DynamicFusionSelector(context_dim, hidden_dim)
# 融合策略网络
self.early_fusion = nn.Linear(2 * hidden_dim, hidden_dim)
self.middle_fusion = nn.Sequential(
nn.Linear(2 * hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
self.late_fusion = nn.Sequential(
nn.Linear(2 * hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# 输出解码器
self.decoder = nn.Linear(hidden_dim, hidden_dim)
def forward(self,
text_inputs: Dict,
image_inputs: torch.Tensor,
task: torch.Tensor,
state: torch.Tensor,
history: torch.Tensor,
return_strategy_probs: bool = False) -> torch.Tensor:
"""
动态融合多模态输入
Args:
text_inputs: 文本输入, 包含input_ids和attention_mask
image_inputs: 图像输入
task: 任务目标表示
state: 环境状态表示
history: 历史交互序列
return_strategy_probs: 是否返回策略概率
Returns:
融合表示或(融合表示, 策略, 概率)
"""
# 1. 编码模态输入
text_features = self.text_encoder(**text_inputs)
image_features = self.image_encoder(image_inputs)
# 为注意力模块准备特征
text_seq = text_features.unsqueeze(1) # [batch_size, 1, hidden_dim]
image_seq = image_features.unsqueeze(1) # [batch_size, 1, hidden_dim]
# 2. 编码上下文
context = self.context_encoder(task, state, history)
# 3. 应用上下文感知注意力
text_attended = self.text_attn(text_seq, context).squeeze(1)
image_attended = self.image_attn(image_seq, context).squeeze(1)
# 4. 准备融合特征
fusion_features = torch.cat([text_attended, image_attended], dim=1)
# 5. 选择融合策略
strategy, policy_probs, _ = self.fusion_selector(context, fusion_features)
# 6. 根据选择的策略执行融合
batch_size = text_attended.shape[0]
fused_representation = torch.zeros(batch_size, self.text_encoder.projection.out_features, device=text_attended.device)
# 对每个样本应用其选择的融合策略
for i in range(batch_size):
strat = strategy[i].item()
if strat == 0: # 在特征级别早期融合
fused = self.early_fusion(fusion_features[i])
elif strat == 1: # 在表示级别中期融合
# 使用元素相乘融合
fused = self.middle_fusion(torch.cat([
text_attended[i] * image
更多推荐
 19
19 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)