
向量化和向量数据库、嵌入式模型的概念
向量化和向量数据库是最关键的技能,如果是AI大模型开发技能的必选必备面试必问笔试必考工作中必用的技能
向量、向量文本化、向量数据库这三个概念是最重要的概念
传统的关系型数据库MySQL
分布式内存数据库Redis
还有一个向量数据库,也叫矢量数据库,专门存向量化后的数据
这三种数据库在简历上体现才可以脱颖而出
一、向量是什么

二、文本向量化
把文本以向量化的方式进行表达,进行转换,也叫文生向
任何转换都有一个接口
如果是聊天 T2T,则是ChatModel
如果是文生图T2I,则是ImageModel
如果是文生音T2V,则是speechSynthesisModel
如果是文本向量化,则是EmbeddingModel
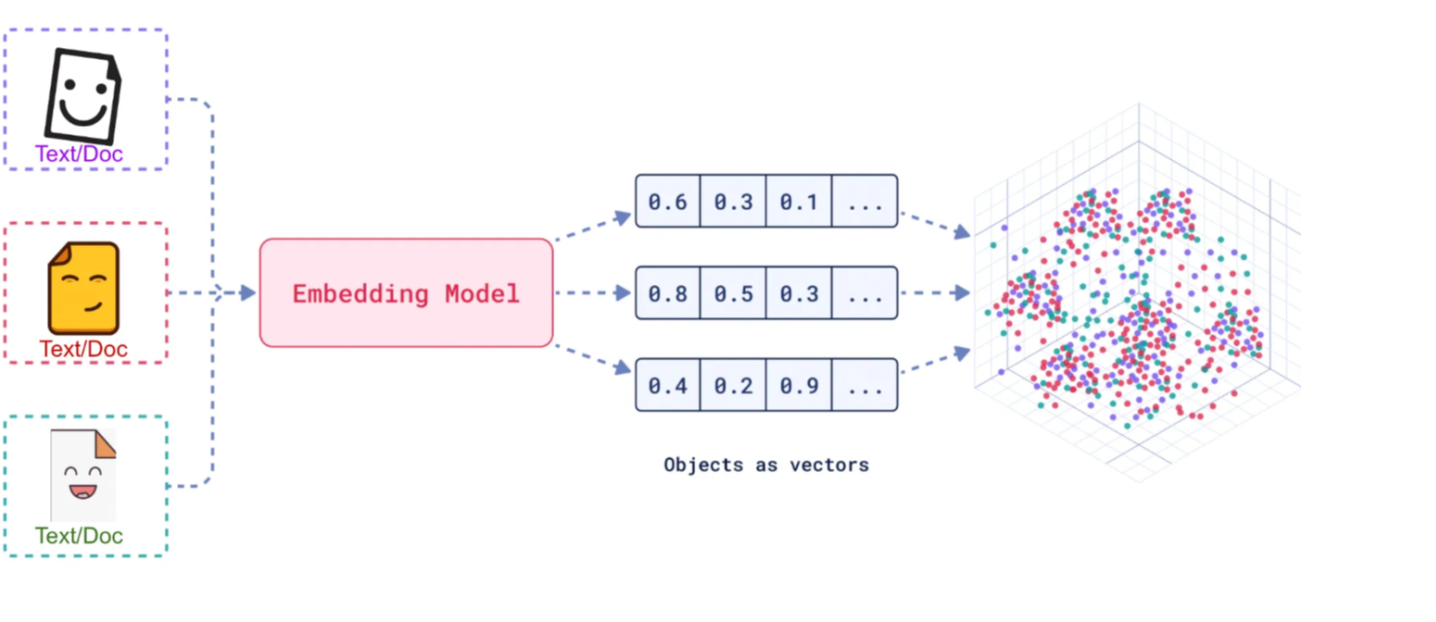
左边是文字,通过这个Model接口可以生成数组,然后打到XYZ轴的三维坐标的图细化空间里面,来进行各个维度的特征比对
数组的数字代表大小,数组的各个指针就成为了方向,这样就完成了这段文字到向量化的指针表达,大小和方向的体现
嵌入模型 (Embedding Model)
官方文档:

嵌入(
Embedding)的工作原理是将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度(Dimensionality)。
三、向量的维度
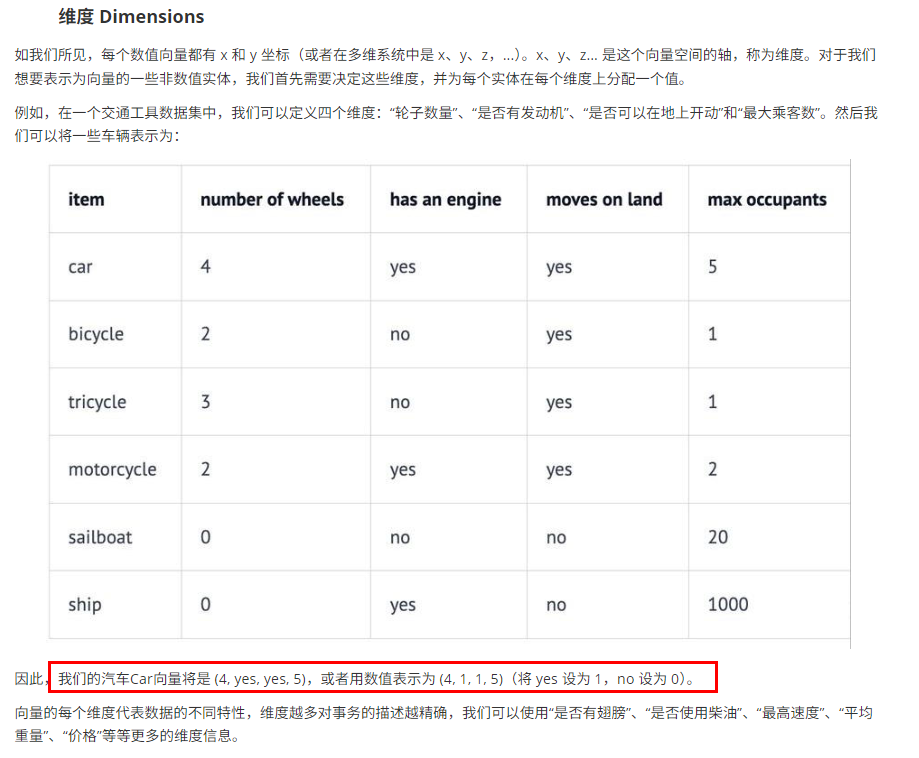
在坐标上进行指征的描述,也叫指征向量,是特征和维度的意思
怎么进行维护和说明呢,比如一辆车有几个轮子、是否有发动机、是否可以在地上开、以及最大乘客数量,这就是四个维度,也就是四个指征
把这个浮点数打到坐标里面,则又有方向又有大小,向量的每个维度代表数据的不同特征维度越多对事务描述越精确,一般转换成的浮点数数组的长度是1024,足够表达
四.如何确定相似
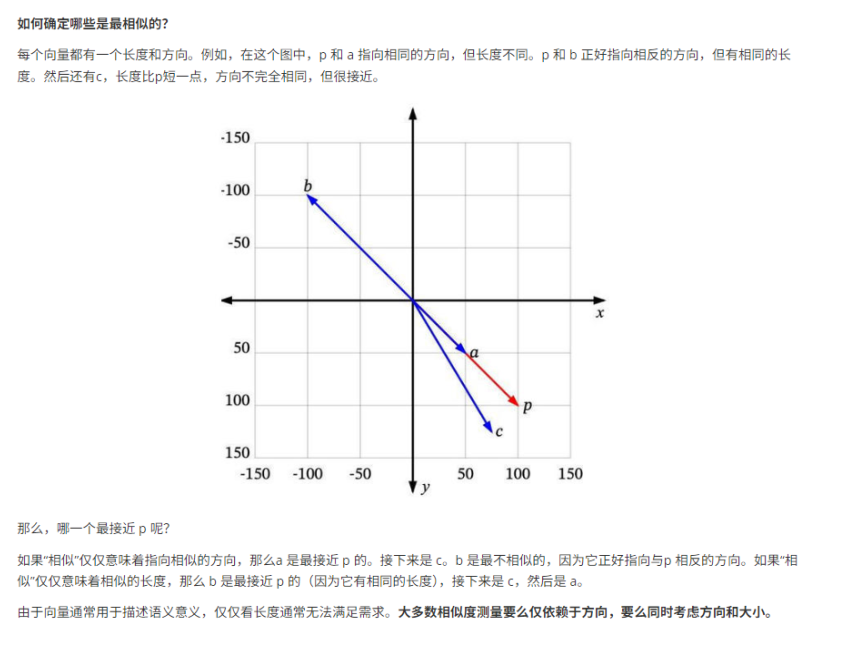
那么,哪一个最接近p呢?
如果"相似"仅仅意味着指向相似的方向,那么a 是最接近p的。接下来是c。b是最不相似的,因为它正好指向与, 相反的方向。如果"相似“仅仅意味着相似的长度,那么b是最接近p的(因为它有相同的长度),接下来是c,然后是 a。由于向量通常用于描述语义意义,仅仅看长度通常无法满足需求。大多数相似度测量要么仅依赖于方向,要么同时考虑方向和大小。一般情况下都是进行纯粹的向量比较,也就是同时比较方向和大小
对应sin和cos按照角度张开闭合的程度,有一个东西叫做余弦相似度,例如P和C的夹角角度就是0,因为他们在坐标轴上重合了
P和C之间有一定角度,相似的可以根据角度配合余弦相似度的复杂的数学公式,可以推算出这两个向量指征和对应的数据的匹配重合度,这样就可以进行相似度查询

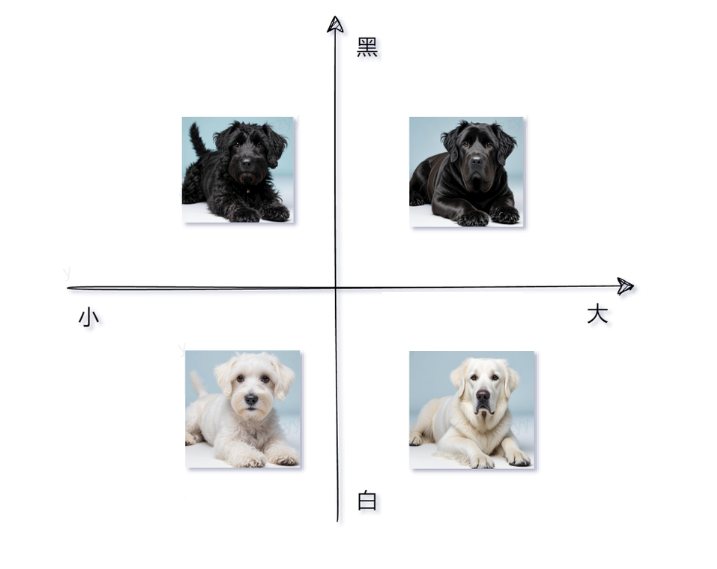
比如一条狗的特征,是否国内或者国外,年龄、是否有培养成警犬的能力
类似于这样的维度越多,比较的浮点数数组就越长,这样比较的就越精确
五、总结

苹果的[8,5,7]分别代表甜度大小和颜色,要查是否相似就是按照各个维度来查每个数组中的值代表的意义,然后查某个水果的特征与这个水果是否一致或者接近,这样就使得相似的水果进行分组变得非常容易

同义就是向量大小和方向都重合
多义可能是两个向量之间有个夹角
反义一般是夹角180度
向量嵌入为检索增强生成 (RAG) 应用程序提供支持
更多推荐

 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)