
从架构角度对比gemma3 vs qwen3
gemma3和qwen3是当前最新最优秀的开源大模型,gemma3提供了1B、4B、12B、27B多个版本,其27B量化版支持在一个GPU部署,支持140多种语言。qwen3提供了4B, 8B, 14B, 30B MoE, 32B, 235B MoE等,32B版本支持单GPU部署,支持100多种语言。
gemma3和qwen3是当前最新最优秀的开源大模型,gemma3提供了1B、4B、12B、27B多个版本,其27B量化版支持在一个GPU部署,支持140多种语言。qwen3提供了4B, 8B, 14B, 30B MoE, 32B, 235B MoE等,32B版本支持单GPU部署,支持100多种语言。
这里结合网络资料,从架构角度分析对比gemma3和qwen3。
1 gemma3
1.1 多模态能力
gemma3是google开源的多模态LLM模型,支持基于图片输入的问答和推理,示例如下。

1.2 架构特性
gemma3采用了分组查询注意力(GQA, grouped-query attention),结合RMSNorm的后归一化和前归一化,使用QK-Norm替换了softcapping,其架构具备如下特点。
1)局部和全局层交错
在设计自注意力块时交替使用局部滑动窗口自注意力和全局自注意力,即5层局部层对应1层全局层,第一层为局部层,有效缓解了长序列上下文时KVCache的内存爆炸问题。这对应了gemma3具备较长上下文处理能力并维持较小内存消耗的原因。
2) RoPE基准频率
在全局自注意力层,将RoPE的基准频率从10k提升到1M,采用位置插值扩展全局自注意力适用范围。局部自注意力层的RoPE基准频率则保持10k,
3)128k上下文
gemma3支持最长128k上下文,这是支持知识库里应用的基础,也是目前实用型大模型的标配。
4)视觉编码器
使用基于vision transformer的一个400M的SigLIP编码器变体,并采用类似Clip对齐进行训练,标准其视频编码器的固定分辨率为896x896。
2 qwen3
1.1 能力描述
qwen3是阿里的旗舰模型,采用MoE以及强化逻辑推理、代码生成、数学运算的思考模式,采用Apache 2.0,使得其适合各种本地部署和集成,qwen3原生模型不支持多模态输入,其多模态能力可能要等qwen3-VL版本。
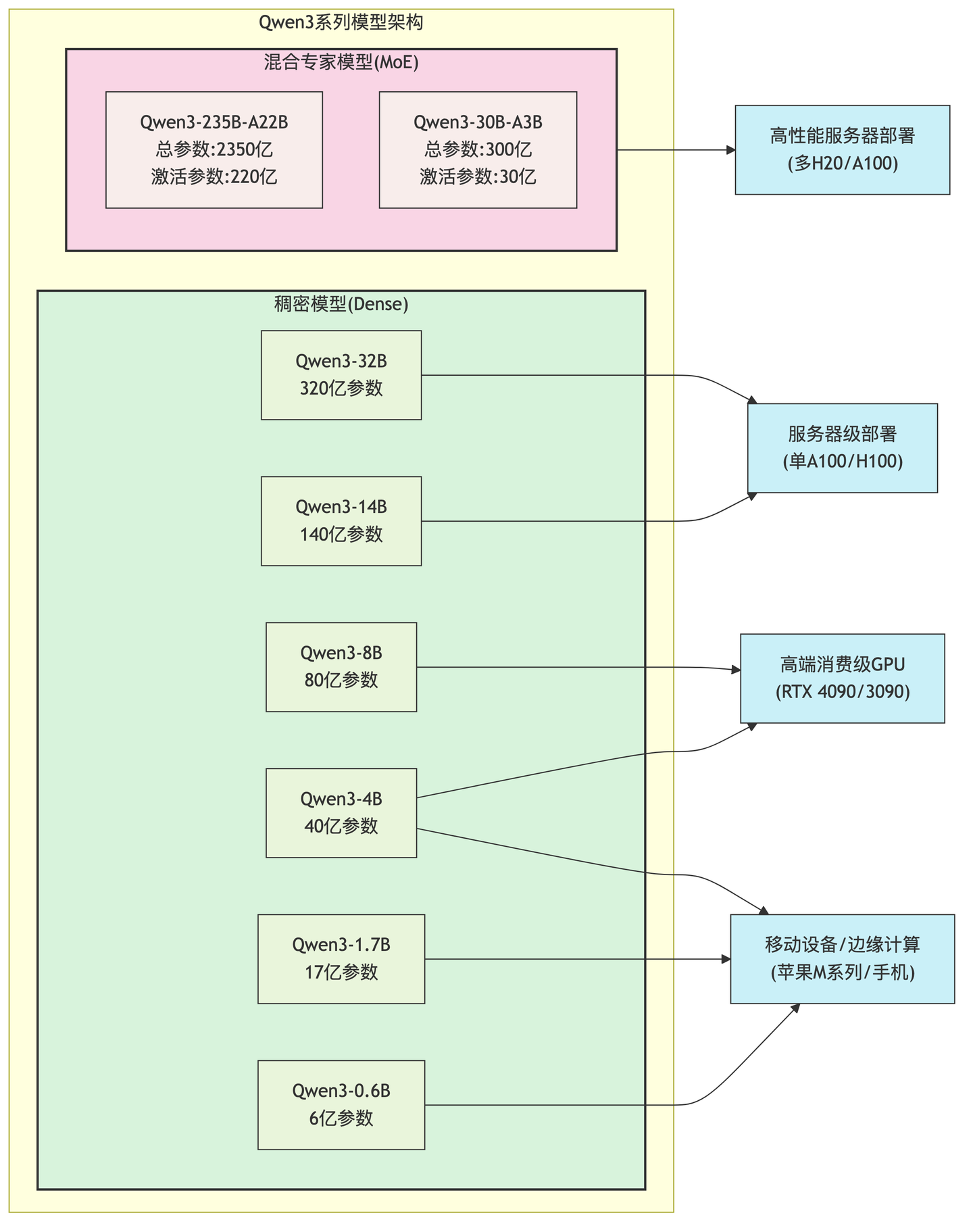
Qwen3覆盖从移动端到企业级的系应用需求,示例如下
超小型模型(0.6B-1.7B): 适用于移动设备、边缘计算和资源受限环境
小型模型(4B-8B): 适合个人电脑、汽车端侧和单GPU服务器部署
中型模型(14B-32B): 面向企业级应用和高性能服务
大型MoE模型(30B-A3B/235B-A22B): 提供顶级性能,同时优化计算资源需求
1.2 架构特性
1)混合推理能力
Qwen3引入了混合推理,实现了思考模式(Thinking Mode)和非思考模式(Non-thinking Mode)的无缝切换。
API参数控制:enable_thinking=True/False参数设置
提示词控制:在用户提示/系统提示中添加 "/think"或"/no_think"指令
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 开启思考模式,默认为True
)qwen3在思考模式下的性能,随思考预算(token数)的增长而提升,用户可以通过设置思考预算来平衡推理质量和计算成本。
2)MoE
Qwen3 MoE模型采用混合专家架构,实现了参数和效率提升。
稀疏激活,总参数量庞大(如235B),每次推理仅激活其中一小部分(如22B)
路由机制,动态选择最适合处理特定输入的专家子网络
计算效率,在保持高性能的同时大幅降低计算成本和显存需求
Qwen3-235B-A22B能以4张H20 GPU提供Deepseek R1(and 671B)类似的性能,显存占用仅为Deepseek R1的三分之一。
3)agent能力
Qwen3原生支持模型上下文协议MCP,提供函数调用能力。
Qwen3可通过Qwen-Agent实现复杂工具调用和任务执行。
reference
---
Qwen3
https://github.com/QwenLM/Qwen3
Gemma 3 vs Qwen 3: In-Depth Comparison of Two Leading Open-Source LLMs
https://codersera.com/blog/gemma-3-vs-qwen-3-in-depth-comparison-of-two-leading-open-source-llms
Gemma 3 Technical Report
https://arxiv.org/pdf/2503.19786
基于ollama运行27b gemma3解决ffmpeg命令生成问题
https://blog.csdn.net/liliang199/article/details/152279809
python代码中阻塞和流式调用ollama模型示例
https://blog.csdn.net/liliang199/article/details/149961157
qwen3 attention架构的整理和学习
https://blog.csdn.net/liliang199/article/details/151793207
Qwen3系列模型全面解析:技术特点、性能实测与应用前景
更多推荐

 24
24 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)