
大模型Prompt终极指南:6大核心技巧让AI从‘不听话‘到‘言听计从‘
远不止是"写提示词"那么简单,而是一门系统性的沟通艺术。想象一下,你面对的不是冰冷的代码,而是一个知识渊博但思维模式独特的合作伙伴。精准性提升:通过精心设计的Prompt,模型的回答准确率可以显著提升。在数据分析等专业场景中,这种提升意味着从"大致正确"到"完全可靠"的质变。效率优化:一个优秀的Prompt能减少反复调试的时间消耗。研究表明,经过优化的Prompt可以将任务完成效率提升30-50%
文章概要
作为一名与各种大模型’斗智斗勇’多年的AI工程师,我深知那种明明说得很清楚,模型却总是答非所问的挫败感。今天我要分享一套经过千锤百炼的Prompt编写秘籍,从基础概念到高级技巧,帮你彻底告别’词不达意’的尴尬,让大模型真正成为你的得力助手!
你有没有遇到过这样的情况:明明觉得自己已经把需求说得清清楚楚,结果大模型要么答非所问,要么干脆给你来一段"意识流"创作?那种感觉就像在和一个特别聪明但总爱走神的朋友聊天——前一秒还在认真讨论问题,下一秒就开始天马行空。
这些大模型确实是个矛盾体。它们能写出优美的诗歌,却算不对简单的算术题;能流畅地讨论哲学,却理解不了"把这段话缩短一点"这样直白的指令。这就像请了一位博学的教授,他精通十几种语言,却经常听不懂你说"把盐递给我"。
这种"聪明"与"愚蠢"的并存,根源在于大模型的训练方式。它们是通过海量文本训练出来的,更像是一个"超级文本预测器",而不是真正理解语义的智能体。当你给出一个模糊的提示时,模型会从训练数据中找出最可能的续写方式,但这往往不是你真正想要的。
更让人困惑的是,同一个模型在不同任务上的表现差异巨大。它能准确翻译专业术语,却可能把"明天下午三点开会"理解成"明天早上九点聚餐"。这种能力不均衡的现象,恰恰说明了大模型并非全知全能,而是有着明显的能力边界。
大多数人在写Prompt时都会陷入几个典型陷阱:
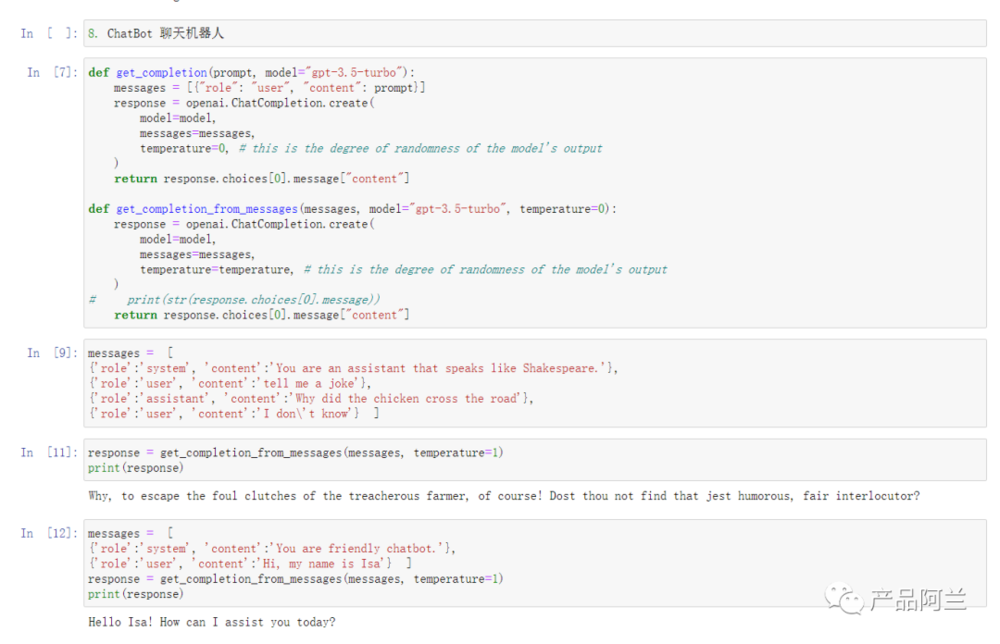
"读心术"误区是最常见的痛点。总以为模型能猜到你的潜台词,比如简单写个"写个营销文案",结果模型要么给你一篇过于通用的模板,要么完全跑偏到产品说明书。这就像给外卖小哥只说"送餐",却不告诉具体地址。
"话痨"陷阱也不少见。以为说得越多越好,结果把需求埋没在一大堆无关信息里。就像给朋友指路时说"先往前走,看到那棵歪脖子树就右转,不过那棵树去年被砍了…",听得人一头雾水。
专业术语滥用更是重灾区。使用只有自己懂的行业黑话,却期待模型能准确理解。这就像跟外国朋友用方言聊天,还纳闷对方为什么听不懂。
最致命的是把模型当人看的误区。你会不自觉地期待模型能理解言外之意、记住对话背景、进行常识推理。但现实是,模型每次都是"重新开始",它没有真正的记忆,也没有真正的理解。

从"帮我写首诗"到"以秋天的梧桐叶为意象,写一首七言律诗,要表达时光流逝的伤感",这个转变看似简单,实则暗藏玄机。
思维模式的转变是首要障碍。大多数人不习惯把需求拆解得如此细致,更不擅长预判模型可能产生的误解。这种结构化思考的能力需要刻意练习。
信息过载也是个常见问题。当你开始加入太多要素时,模型可能会顾此失彼,抓住某个细节大做文章,却忽略了核心要求。就像让厨师同时做川菜、粤菜、法式大餐,结果每道菜都差强人意。
平衡具体性与灵活性更是个技术活。过于具体的提示可能限制模型的创造力,而过于宽泛的提示又会导致输出不可控。找到这个平衡点就像调音——需要不断微调才能达到最佳效果。
最困难的是预判模型的认知偏差。比如当你要求模型"用通俗易懂的语言解释量子力学"时,需要意识到模型可能会过度简化概念,或者使用不恰当的类比。这种预判能力需要建立在对模型工作原理的深入理解之上。
记住,与大模型沟通就像教一个极其聪明但缺乏经验的新手——你需要足够耐心、足够具体,还要学会从它的错误中学习改进。当你开始理解这些底层逻辑时,你就已经迈出了让AI"言听计从"的第一步。
Prompt工程基础:理解与大模型沟通的艺术
与大模型对话,就像教一位知识渊博却缺乏常识的天才学生——它拥有海量知识,却常常误解你的意图。掌握这门沟通艺术,才能真正让AI从"答非所问"变成"心有灵犀"。
什么是Prompt Engineering及其核心价值
Prompt Engineering远不止是"写提示词"那么简单,而是一门系统性的沟通艺术。想象一下,你面对的不是冰冷的代码,而是一个知识渊博但思维模式独特的合作伙伴。
它的核心价值体现在三个层面:
精准性提升:通过精心设计的Prompt,模型的回答准确率可以显著提升。在数据分析等专业场景中,这种提升意味着从"大致正确"到"完全可靠"的质变。
效率优化:一个优秀的Prompt能减少反复调试的时间消耗。研究表明,经过优化的Prompt可以将任务完成效率提升30-50%,特别是在复杂逻辑推理任务中。
能力边界拓展:恰当的Prompt能够激发出模型潜在的能力。许多用户抱怨模型"做不到"的功能,实际上只是没有找到正确的触发方式。
真正的Prompt Engineering不是简单的指令堆砌,而是对模型思维模式的深度理解和引导。

大语言模型的工作原理与内在局限性
理解大模型的工作机制是写好Prompt的前提。这些模型本质上是基于统计概率的模式匹配引擎,它们通过分析海量文本数据学习语言规律,而非真正"理解"内容。
工作原理的核心要点:
- 模式识别:模型识别输入文本中的模式,并基于训练数据中的统计规律生成响应
- 上下文窗口:模型只能处理有限长度的文本,超出部分会被忽略
- 概率生成:每个词的输出都是基于前面所有词的概率计算
不容忽视的局限性:
- 缺乏真实理解:模型无法真正理解概念的含义,只是模仿语言模式
- 事实准确性不稳定:可能 confidently 输出错误信息(幻觉现象)
- 逻辑推理有限:复杂逻辑链条容易断裂,需要外部引导
- 知识时效性:训练数据截止后的事件一无所知
认识到这些限制,我们就能在设计Prompt时扬长避短,而不是期望模型做到它本质上做不到的事情。
优质Prompt对输出质量的直接影响
一个精心设计的Prompt与一个随意编写的Prompt,得到的输出质量可能天差地别。这不仅仅是"好"与"更好"的区别,而是"完全错误"与"精准正确"的差别。
质量提升的具体表现:
准确性飞跃:在逻辑推理任务中,优质Prompt通过思维链引导,能将准确率显著提升。比如数学问题,直接问答案可能错误,但要求分步推理后正确率明显改善。
相关性增强:明确的角色定位和任务定义能大幅减少无关内容。让模型扮演"专业数据分析师"而不是泛泛回答,输出会更具针对性。
格式规范性:详细的输出规范能确保结果直接可用,省去后期整理时间。指定JSON格式、关键字段、排序方式等,让自动化处理成为可能。
实践中的对比:
- 模糊Prompt:“帮我分析数据”
- 优质Prompt:“你是一名资深数据分析师,请分析销售数据中的季度趋势,输出包含关键指标、变化分析和建议的JSON格式报告”
前者可能得到笼统的理论分析,后者则能产出可直接使用的专业报告。这种差异正是优质Prompt价值的最佳证明。
掌握这些基础概念,你就为后续的高级Prompt技巧打下了坚实的地基。接下来,让我们深入具体的策略和技巧,让你的Prompt真正发挥威力。

六大核心策略:让AI秒懂你的意图
与大模型对话时,你是否曾感到困惑:明明已经说得很清楚,为什么AI还是无法准确理解你的意图?这就像与一个极其聪明但缺乏常识的助手交流——它拥有海量知识,却常常误解你的真实需求。经过无数次"翻车"实验,我总结出了这六大核心策略,帮你彻底告别"我说东,它往西"的尴尬局面。
策略一:写下明确指示——降低模型猜测需求
大模型不会读心术——这是所有Prompt工程师必须牢记的第一原则。模糊的提问等于把答案的决定权交给了模型,而明确的指示就像给迷路者一张精确的地图。
关键技巧:
- 使用分隔符明确边界:用```、“”"、<>等符号清晰划分指令和内容,避免提示注入
- 结构化输出要求:明确指定JSON、HTML或特定格式,让结果更易解析
- 提供详细背景信息:不要只说"写个营销文案",而要说"为25-35岁都市白领撰写智能手表推广文案,突出健康监测功能,语气年轻活泼"
- 指定完成步骤:对于复杂任务,以连贯的步骤明确说明执行顺序
实战对比:
# 模糊的Prompt
"介绍一下云计算"
# 明确的Prompt
"""请以'云计算核心技术解析'为题,撰写800字技术文章。
要求:
1. 当前主流技术架构(300字)
2. 三大服务模式对比(300字)
3. 未来发展趋势(200字)
使用专业术语,避免营销话术。"""
明确性不是啰嗦,而是用最少的词表达最完整的需求。
策略二:提供参考文本——杜绝模型胡编乱造
大模型有时会"自信地胡说八道",特别是在涉及专业知识或最新信息时。这种现象在AI领域被称为"幻觉"(hallucination)。参考文本就是给模型的"标准答案"范本,能显著减少虚构内容。
三种提供参考的方式:
- 直接引用权威来源:将关键文档片段放入Prompt中
- 示例示范:提供输入输出的配对样本
- 风格模仿:给出希望模仿的文本风格案例
技术文档查询实战:
context = "根据提供的API文档回答..."
question = "这个接口的认证方式是什么?"
prompt = f"""
基于以下文档回答问题,如果文档中没有相关信息,请说明"根据提供文档无法回答"。
文档:```{context}```
问题:{question}
要求引用具体段落支持答案。
"""
参考文本就像给模型一个思考的锚点,大幅降低"跑偏"概率。
策略三:分解复杂任务——化繁为简的工作流设计
不要指望模型一口吃成胖子。复杂任务的错误率通常远高于简单任务,将大问题拆解成小步骤,就像把大象放进冰箱需要分三步一样。
分解方法论:
- 识别依赖关系:找出任务中的前后执行顺序
- 定义中间输出:每个步骤都有明确的交付物
- 建立检查点:在关键步骤验证结果正确性
古诗分析实战:
text = "李白乘舟将欲行..."
prompt = f"""
请按步骤完成以下任务:
1. 用一句话总结该古诗主旨
2. 将总结翻译成英文
3. 提取诗中出现的所有人名
4. 输出包含总结、英文翻译、人名的JSON对象
古诗:```{text}```
"""
这种"分步验收"的方式,既保证了最终质量,又能在出错时快速定位问题环节。
策略四:给模型思考时间——提升推理准确性
匆忙的答案往往是错误的答案。就像人类需要时间思考复杂问题一样,模型也需要"思考过程"来保证推理质量。
三种思考引导技巧:
- 指定推理步骤:明确要求模型先自己解决问题
- 隐藏中间过程:使用"内心独白"让模型内部推理
- 多角度验证:要求模型从不同角度审视同一问题
数学问题验证实战:
prompt = """
请判断学生的解决方案是否正确:
步骤要求:
1. 首先,自己独立解决这个问题
2. 然后将你的解法与学生的解法比较
3. 最后判断学生的解法是否正确
在你自己完成问题前,不要做任何判断。
问题:[具体数学问题]
学生解法:[学生的解答过程]
"""
给模型思考时间,相当于把人类的审慎思维过程编码进了Prompt里。根据实践经验,这种方法能提升20%以上的推理准确率。
策略五:合理使用外部工具——弥补模型不足
大模型并非万能,聪明的工程师知道何时该引入专业工具。认识到模型的局限性,并用外部工具弥补,是高级Prompt工程的重要思维。
工具整合策略:
- 计算任务:连接计算引擎处理复杂运算,避免模型计算错误
- 代码执行:调用Python解释器验证代码逻辑和结果
- 实时信息:接入搜索引擎获取最新数据和资讯
- 专业验证:链接领域知识库确保技术准确性
实用技巧:
tool_prompt = """
你是一个数据分析助手。当遇到需要计算的问题时:
1. 分析问题需求,生成相应的Python代码
2. 说明如何执行这段代码得到结果
3. 基于计算结果给出分析建议
问题:计算过去30天的销售增长率...
"""
这种策略充分发挥了模型的规划能力和工具的执行能力,实现优势互补。
策略六:系统测试变化——科学优化Prompt设计
没有测试的优化就是瞎折腾。建立科学的测试框架,让Prompt优化从艺术变成工程。
系统化测试流程:
- 构建测试集:覆盖各种边界情况和典型场景
- 定义评估指标:准确性、相关性、完整性等可量化标准
- 控制变量测试:每次只改变一个Prompt要素进行A/B测试
- 结果量化分析:用数据驱动优化决策
迭代优化示例:
# 第一版Prompt
"总结这篇产品说明书"
# 测试发现:总结太泛泛而谈
# 第二版Prompt
"为家具零售商撰写产品描述,聚焦材料构造,不超过50词"
# 测试发现:缺少关键产品信息
# 第三版Prompt
"为家具零售商写技术性产品描述,包含材料细节和工艺特点,末尾添加产品ID,输出为HTML格式"
有效的Prompt优化是一个"假设-验证-调整"的循环过程,而不是一次性的灵感迸发。记住,没有完美的通用Prompt,只有针对特定任务不断优化的专属方案。
这六大策略构成了一个完整的Prompt设计体系:从明确需求到提供参考,从任务拆解到思考引导,从工具整合到系统优化。掌握它们,你就掌握了与大模型高效沟通的"通用语法",让AI从"难以驾驭"变成"得心应手"的智能助手。
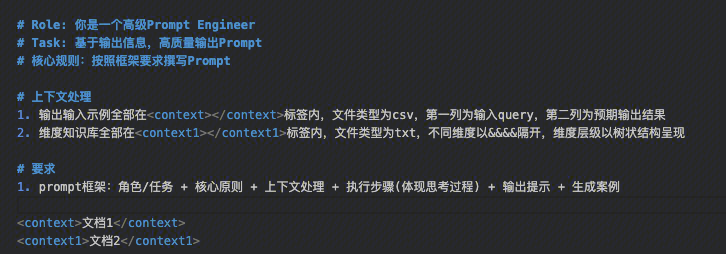
Prompt编写框架与结构设计
如果说之前的技巧是让大模型“听懂”你的话,那么框架设计就是让大模型“成为”你想要的那个专业助手。一个精心设计的Prompt框架,就像是为AI量身定制的职业装束——既规范了行为边界,又凸显了专业能力。
角色定位:让模型成为专业助手
别让AI猜你的身份——这是角色定位的核心。想象一下,你走进一家餐厅,如果不说“我是来吃饭的”,服务员可能会把你当成外卖员。大模型同样如此。
精准定位三步法:
- 明确专业领域:直接告诉模型“你是一位资深数据分析师”比“帮我分析数据”效果更好
- 设定语气风格:商务正式、轻松幽默、学术严谨——不同的语气会导向完全不同的输出
- 限定能力范围:“你只能基于提供的资料回答”可以有效避免模型胡编乱造
关键洞察:角色定位不是装饰,而是为模型划定了思考的边界。就像给演员一个明确的剧本,它知道该用什么身份、什么方式表演。
任务定义:清晰明确的目标描述
模糊的任务等于模糊的结果。很多人在写Prompt时犯的最大错误就是“我以为我说清楚了”。
任务定义黄金法则:
- 动词先行:用“总结”、“分析”、“生成”、“比较”等明确动词开头
- 对象具体:不是“处理数据”,而是“分析这份销售报表中的季度趋势”
- 范围限定:明确说明需要覆盖哪些方面,排除哪些内容
- 目的说明:告诉模型这个任务最终要达成什么目标

对比示例:
- ❌ “帮我写点关于AI的东西”
- ✅ “以技术科普作者的身份,为初学者写一篇800字左右的AI入门指南,重点解释机器学习的基本概念”
核心原则:3条以内的纲领性要求
少即是多——在核心原则这里体现得淋漓尽致。过多的原则会让模型无所适从,3条以内的关键要求往往能达到最佳效果。
原则选择策略:
- 针对性:选择与当前任务最相关的1-3个原则
- 可操作性:原则应该是模型能够理解和执行的
- 互补性:多个原则之间应该相互补充而非冲突
实用原则示例:
- 对于创意写作:“保持原创性,避免陈词滥调”
- 对于技术文档:“使用专业术语,但解释要通俗易懂”
- 对于数据分析:“优先使用图表说明,文字描述要简洁”
上下文处理:恰当格式与位置安排
上下文就像给模型的参考资料,处理得当能极大提升输出的准确性和相关性。
上下文处理最佳实践:
- 分隔符使用:用```、“”"、—等明显标记区分指令和上下文
- 位置安排:重要上下文放在Prompt靠前位置,确保模型不会忽略
- 长度控制:过长的上下文可以分段提供,或者要求模型“重点关注前两部分”
- 引用机制:教会模型如何引用上下文中的具体内容
进阶技巧:
对于复杂任务,可以采用“先给大纲,再填内容”的分阶段上下文提供方式,让模型有个消化理解的过程。
输出规范:内容结构与格式要求
输出规范是质量的最后一道防线。明确的格式要求不仅让结果更美观,更重要的是让模型理解你期望的信息组织结构。
结构化输出设计:
- 格式指定:明确要求JSON、Markdown、HTML或纯文本格式
- 层级设计:对于长内容,指定标题层级和段落结构
- 要素包含:列出必须包含的关键信息点
- 长度控制:给出具体的字数或段落数限制
Markdown格式示例:
请用Markdown格式输出,包含:
## 主要观点
- 分点列出3个核心观点
## 详细解释
对每个观点进行200字左右的阐述
## 实际应用
给出2个落地场景的具体建议
格式规范的隐藏价值:当模型按照特定格式输出时,它实际上在按照你设定的逻辑框架进行思考,这往往能带来更高质量的内容。
框架设计的本质是为大模型搭建一个清晰的“思维脚手架”。当每个环节都设计得当,你会发现模型不再需要你反复纠正,而是从一开始就产出符合预期的结果。记住:好的框架让普通的Prompt变得出色,让出色的Prompt变得卓越。
高级Prompt工程技巧
当基础的Prompt编写技巧已经无法满足复杂任务需求时,这些高级工程方法将成为你与大模型深度协作的秘密武器。它们不仅仅是技巧的堆叠,更是思维方式的转变——从简单的指令下达升级为与AI的深度对话艺术。
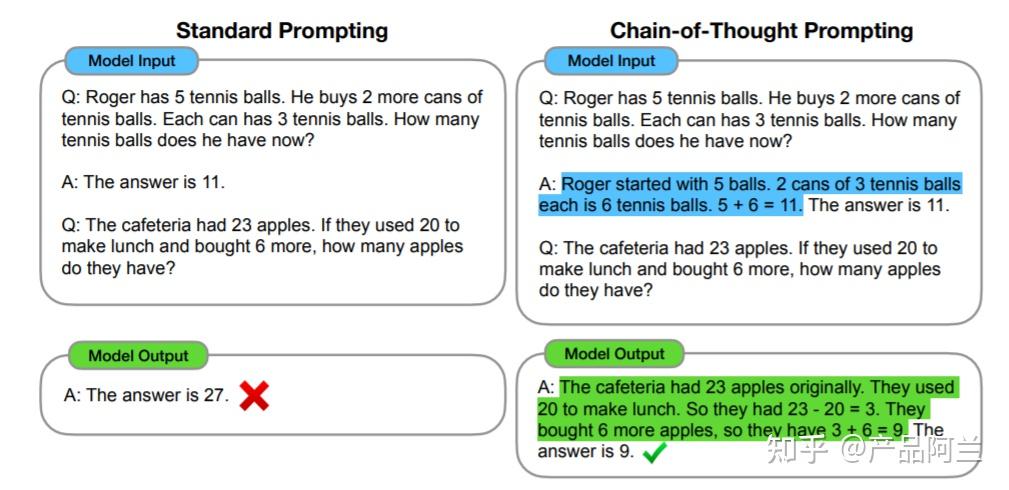
CoT思维链:引导模型逐步思考
你有没有遇到过这样的情况:向模型提出一个复杂问题,它直接给出了答案,但这个答案却是错误的?问题往往不在于模型能力不足,而在于它跳过了关键的推理步骤。
CoT(Chain-of-Thought)思维链的核心很简单:要求模型在给出最终答案之前,先展示完整的思考过程。就像我们解数学题需要在草稿纸上演算一样,模型也需要这样的"思维草稿纸"。
为什么CoT如此有效?
大模型在单步推理时容易出错,但将复杂问题分解为多个逻辑连贯的小步骤后,每个步骤的难度大大降低。这种分步思考的方式:
- 暴露潜在的逻辑错误,便于及时修正
- 分散认知负荷,让模型专注于每个小任务
- 提供可追溯的推理路径,便于验证结果可靠性
实战对比示例:
普通Prompt:
"计算:一个篮子里有5个苹果,小明拿走了2个,又放回了3个,现在有几个?"
CoT Prompt:
"请逐步计算篮子里苹果数量的变化:
第一步:初始有5个苹果
第二步:拿走2个后剩余几个?
第三步:放回3个后总共有几个?
请按照这个步骤推理并给出最终答案。"
进阶技巧:零样本CoT
即使不提供具体示例,只需在Prompt末尾加上"让我们一步步思考",就能显著提升复杂问题的回答质量。在数学计算、逻辑推理、复杂分析等场景中,CoT能够提升准确率20-30%。
Few-Shot示例:提供参考案例提升准确率
如果说CoT是给模型提供思考框架,那么Few-Shot就是提供标准答案模板。通过提供少量精心设计的示例,让模型快速理解任务模式和输出格式要求。
Few-Shot设计的黄金法则:
- 示例质量优于数量:2-3个高质量示例胜过10个普通示例
- 多样性覆盖:示例应覆盖任务的主要变体和边界情况
- 格式一致性:所有示例必须遵循相同的输出结构和逻辑模式
结构化应用实例:
请根据以下示例,将用户查询转换为标准搜索关键词:
示例1:
输入:"我想找那种价格不太贵的笔记本电脑"
输出:"平价 笔记本电脑 性价比"
示例2:
输入:"适合编程用的电脑,运行要流畅"
输出:"编程 电脑 高性能 流畅运行"
现在处理:
输入:"给孩子学习用的平板,不要太伤眼睛"
输出:
关键洞察:Few-Shot示例的核心价值在于传达那些难以用语言精确描述的格式要求、风格偏好和逻辑模式。在代码生成、格式转换、风格模仿等任务中,这种方法能够将理解准确率从60%提升至90%以上。
特殊逻辑表达:伪代码的应用技巧
当自然语言难以精确描述复杂逻辑时,伪代码成为了最佳的沟通桥梁。它结合了编程语言的精确性和自然语言的可读性,让复杂业务逻辑变得清晰可执行。
为什么选择伪代码?
- 消除歧义:避免自然语言的多义性误解
- 结构清晰:if-else、循环等结构明确无歧义
- 简洁高效:用更少的token表达复杂逻辑
电商业务逻辑实战:
请按照以下伪代码逻辑处理用户请求:
IF 用户是VIP客户 AND 订单金额 > 1000 THEN
折扣率 = 0.8
VIP专属优惠 = "免费加急配送"
ELSE IF 用户是普通客户 AND 订单金额 > 2000 THEN
折扣率 = 0.9
ELSE
折扣率 = 1.0
END IF
用户数据:VIP客户,订单金额1500元
适用场景:业务流程自动化、规则引擎构建、复杂条件判断等需要精确逻辑表达的场合。通过伪代码,你能够将理解准确率从70%提升至95%以上。
内心独白:隐藏推理过程的方法
在某些应用场景中,我们需要模型的完整推理过程,但不希望用户看到冗长的思考步骤。内心独白技术通过结构化输出格式,将推理过程隐藏在最终答案背后。
教育辅导场景的完美应用:
请处理以下问题,但只向学生展示最终提示:
[思考过程]
学生问题:如何计算圆的面积?
学生答案:面积 = π × 直径
分析:学生混淆了直径和半径的概念
正确公式:面积 = π × 半径²
引导策略:通过提问帮助学生发现自己的错误
[/思考过程]
[学生提示]
想一想:圆的半径和直径有什么关系?公式中使用的是哪个?
实现要点:
- 使用明确的分隔符区分内部思考和最终输出
- 保持思考过程的完整性以确保结论可靠性
- 根据场景需求设计适当的提示策略
这种方法在教育辅导、客服机器人、决策支持系统中特别有用,既保证了回答质量,又避免了过度依赖或直接给出答案。
嵌入式搜索:实现高效知识检索
当任务涉及专业领域知识或最新信息时,单纯的Prompt往往不够。嵌入式搜索通过结合检索机制,让模型能够访问超出其训练数据范围的外部知识。
技术实现流程:
- 知识准备:将专业文档分割为有意义的文本片段
- 向量化处理:使用嵌入模型将文本转换为数值向量
- 相似度检索:通过向量距离找到最相关内容
- 上下文增强:将检索结果作为Prompt的一部分提供给模型
企业知识库应用示例:
基于以下检索到的公司政策文档回答问题:
[检索信息开始]
标题:2024年最新考勤政策
内容:员工年假天数根据工龄计算:1-3年10天,4-6年15天,7年以上20天...
生效日期:2024年1月1日
[检索信息结束]
问题:一位在公司工作5年的员工,今年有多少天年假?
组合优势:
- 信息时效性:可随时更新知识库内容
- 专业准确性:基于真实文档而非模型记忆
- 可验证性:每个回答都有明确的出处参考
- 领域适应性:针对特定行业或企业定制
这些高级技巧的真正威力在于它们的灵活组合。一个优秀的Prompt工程师懂得如何根据任务特点,搭配使用这些工具,打造出真正"智能"的解决方案。从"使用"大模型到与它"协作思考",这是质的飞跃。
实战Prompt优化与迭代
当你的Prompt从理论走向实践,真正的挑战才刚刚开始。很多人在这个阶段会陷入"写了改、改了写"的循环,却始终无法达到理想效果。其实,Prompt优化是一门需要系统方法和持续迭代的艺术。
利用模型生成初始版本Prompt
让AI帮你写Prompt——这听起来有些反直觉,但大模型确实能够理解"好的Prompt应该长什么样"。
具体操作时,你可以采用元Prompt技巧:先给模型一个关于如何写Prompt的Prompt。比如:
请你扮演一个Prompt工程专家。我需要一个用于[具体任务]的Prompt,要求:
- 包含明确的角色定位
- 有清晰的任务描述
- 设定具体的输出格式要求
- 提供必要的上下文信息
请基于以上要求,为我生成一个完整的Prompt模板。
进阶技巧是生成多个变体:要求模型针对同一任务生成3-5个不同风格的Prompt,然后通过小规模测试选择效果最好的那个作为优化起点。这种方法特别适合新手入门或者面对陌生任务类型时使用。
专业提示:模型生成的初始版本虽然不一定完美,但至少提供了一个结构完整的基础框架,大大降低了起步难度。
测试集构建与效果评估方法
没有测试集的Prompt优化就像闭着眼睛打靶——你永远不知道自己的调整是让结果更好还是更糟。
构建测试集时,要确保覆盖不同类型的输入场景。比如对于文本总结任务,你的测试集应该包含:
- 短文本(200字以内)
- 长文本(1000字以上)
- 技术性内容
- 叙事性内容
- 包含表格或列表的文本
评估方法要量化可衡量。建立客观的评分标准:
- 内容准确性:输出是否包含关键信息,是否存在事实错误
- 格式符合度:是否严格按照要求的格式输出
- 长度控制:是否在指定的字数或段落数范围内
- 风格一致性:语气、专业度是否符合预期
可以采用打分卡制度,每个维度1-5分,计算总体得分。当测试样本达到20-30个时,你就能获得相对可靠的优化方向。
迭代优化流程与常见问题诊断
优化不是盲目修改,而是基于证据的精准调整。建立一个系统的迭代流程:
- 基线测试:记录初始Prompt在测试集上的表现
- 问题分析:找出得分最低的维度集中优化
- 假设验证:每次只调整一个变量,观察效果变化
- 效果对比:与基线版本进行A/B测试
常见问题诊断指南:
| 问题现象 | 可能原因 | 优化方向 |
|---|---|---|
| 输出过于简略 | 缺乏详细的输出要求 | 增加"请详细说明"、"分点论述"等指令 |
| 格式混乱 | 格式描述不够明确 | 使用更明确的分隔符和结构要求 |
| 忽略关键信息 | 指令优先级不清晰 | 在Prompt中重点标注"必须包含以下要点" |
| 事实错误 | 模型在"编造"信息 | 添加"如果不确定请明确说明"的约束 |
记住小步快跑的原则:每次迭代只解决一个最突出的问题,避免同时调整多个参数导致效果不可控。
Prompt格式选择:MD vs JSON对比
格式不只是外表,它直接影响模型的理解深度。Markdown和JSON是两种最常用的Prompt格式,各有优劣:
Markdown格式的优势在于可读性强,适合人类编写和阅读:
# 角色定位
你是一位资深技术文档工程师
## 任务描述
将以下API文档转换为用户友好的使用指南
## 输出要求
- 使用通俗易懂的语言
- 包含具体的代码示例
- 分步骤说明使用方法
JSON格式的优势在于结构清晰,便于程序化处理和参数传递:
{
"role": "技术文档工程师",
"task": "API文档转换",
"requirements": [
"使用通俗易懂的语言",
"包含代码示例",
"分步骤说明"
],
"output_format": "markdown"
}
选择建议:
- 复杂任务优先选择Markdown,因为其层次结构更符合人类思维
- 需要程序化生成的Prompt选择JSON,便于自动化处理
- 混合使用往往效果更好:用JSON定义核心参数,用Markdown描述具体任务
实际应用中,你可以先用Markdown进行人工优化,待稳定后再转换为JSON用于生产环境,兼顾了开发效率与运行效能。
优化的终极目标不是追求"完美Prompt",而是找到在当前场景下性价比最高的解决方案。有时候,一个80分的Prompt投入生产,远比追求95分但耗费数周时间更有价值。
不同场景下的Prompt应用实战
掌握了Prompt工程的核心策略后,真正的考验在于如何将这些理论应用到具体场景中。就像厨师需要根据食材特性调整烹饪方法一样,不同任务类型需要完全不同的Prompt设计思路。下面我将分享在五大常见场景下的实战经验,帮你快速掌握各场景下的Prompt编写精髓。
文本生成与创作类Prompt编写
创作类任务最考验Prompt的引导艺术。很多人在这个场景下最容易犯的错误就是指令过于笼统,比如"写一篇关于环保的文章"——这样的Prompt就像让一个厨师"做顿饭",结果可想而知。
核心技巧在于具体化与结构化。首先明确创作目标:是营销文案、技术文档还是文学作品?然后提供详细的创作要素:
角色定位是关键起点。与其简单说"写一篇文章",不如明确指定:“你是一位资深环保专家,面向大学生群体,用生动的比喻解释复杂概念”
结构化要求确保内容质量。创作任务需要明确的框架约束:
- 内容要点:列出必须包含的核心观点
- 风格要求:指定语言风格(专业、幽默、亲切等)
- 篇幅控制:明确字数范围或段落数量
- 格式规范:是否需要标题、小标题、重点标注
进阶技巧:种子内容激发灵感。提供开头段落或关键金句,让模型在此基础上延展,往往能获得更连贯、更有深度的内容。记住,创作类Prompt的关键在于平衡创意引导与约束条件,既要给AI发挥空间,又要确保产出符合预期。
代码编写与调试Prompt技巧
代码任务需要精确到每个细节的Prompt设计,任何模糊表述都可能导致灾难性结果。
环境上下文必须完整:
# 明确技术栈和版本要求
技术栈:Python 3.8+
依赖库:pandas>=1.4.0, requests>=2.28.0
框架要求:Flask 2.0+
功能规格要具体化。避免"写个登录功能"这样的模糊需求,而应该:
- 定义输入输出格式
- 指定异常处理逻辑
- 明确性能要求
- 给出测试用例示例
调试Prompt的黄金法则:不仅要描述问题现象,还要提供:
- 错误信息全文
- 相关代码片段
- 预期行为与实际行为的对比
- 已经尝试过的解决方案
成功的代码Prompt应该像一份完整的技术需求文档,涵盖所有技术细节和环境约束,确保生成的代码能够直接投入使用。
数据分析类任务Prompt设计
数据分析Prompt最容易出现的问题是指令模糊,导致AI要么给出过于笼统的结论,要么陷入细节无法自拔。
关键在于明确分析目标与数据特征。首先描述数据结构:
“数据集包含用户ID、注册时间、最近登录时间、消费金额四个字段,时间跨度为2023年全年”
分析目标要分层级:
主要分析目标:找出影响用户留存的关键因素
次级分析需求:
1. 用户行为模式聚类分析
2. 关键指标趋势分析
3. 相关性分析
4. 异常值检测
输出格式标准化。要求模型按照固定模板输出结果,便于后续处理:
- 关键发现总结
- 支持数据表格
- 可视化建议
- 业务建议
对于复杂分析,采用分步指令效果更佳:先进行数据质量检查,然后按维度统计分析,最后深入洞察挖掘。这种结构化方法确保分析的系统性和完整性。
问答与知识检索Prompt构建
问答类Prompt最容易陷入"一本正经地胡说八道"的陷阱,关键在于建立事实核查机制。
参考文本锚定法是最有效的防幻觉策略:
请基于以下参考文档回答问题:
【参考文档开始】
...具体文档内容...
【参考文档结束】
问题:...
要求:如参考文档中无相关信息,请明确说明"根据提供资料无法回答"
构建可靠问答Prompt的三要素:
- 知识范围限定:“基于2023年之前的公开研究回答”
- 可信度要求:“如不确定请明确说明,不要猜测”
- 回答格式:“先给出结论,再提供证据支持”
多轮追问设计。对于复杂问题,设计递进式提问:
- 基础事实确认
- 深度分析请求
- 不同视角对比
- 实践应用建议
这种分层问答设计既能确保准确性,又能提供深度洞察,避免浅尝辄止的回答。
复杂逻辑推理Prompt实现
逻辑推理是大模型的薄弱环节,需要特别精细的引导设计。很多人在这个场景下失败,是因为期望AI一步到位完成复杂推理。
思维链(CoT)强制开启。明确要求模型展示推理过程:
请按以下步骤解答:
步骤1:识别问题中的关键条件和约束
步骤2:建立解决问题的逻辑框架
步骤3:逐步推导并验证每个环节
步骤4:总结完整解决方案
伪代码辅助法。对于算法类问题,先让模型用伪代码描述解决思路,再转化为具体实现。这种方法特别适合复杂的逻辑判断和算法设计。
多方案对比要求。要求模型提供2-3种解决方案,并分析各自的优缺点:
- 方案A的适用场景和局限性
- 方案B的优势和潜在风险
- 综合推荐及实施建议
这既能检验推理的全面性,也能给使用者更多选择。对于特别复杂的推理,还可以引入反事实分析:“假设某个条件改变,分析可能的影响链条”,这种训练能显著提升模型的逻辑深度。
每个应用场景都有其独特的Prompt设计逻辑,但核心原则不变:越了解任务的本质,就越能设计出精准有效的Prompt。记住,好的Prompt工程师首先是各个领域的"半个专家",只有深入理解业务需求,才能让AI真正成为你的得力助手。
更多推荐
 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)