
清华117页综述:强化学习如何塑造大型推理模型
综述系统回顾了强化学习(RL)在大型语言模型(LLM)推理能力构建中的最新进展,探讨了如何通过RL将LLM转变为更强大的大型推理模型(LRMs),并为通往通用人工智能(ASI)开辟一条可扩展路径。
引言
综述系统回顾了强化学习(RL)在大型语言模型(LLM)推理能力构建中的最新进展,探讨了如何通过RL将LLM转变为更强大的大型推理模型(LRMs),并为通往通用人工智能(ASI)开辟一条可扩展路径。
研究背景与科学问题
强化学习(RL)最初因其在人类对齐任务中的成功而备受瞩目,其中以人类反馈强化学习(RLHF)和直接偏好优化(DPO)为代表的方法,显著提升了模型的有益性、诚实性和无害性。然而,近年来出现了一个新趋势:应用RL不再仅仅为了“对齐”,而是为了直接激励和训练模型的“推理”本身。
以OpenAI的o1和DeepSeek-R1为里程碑,研究者证明了利用可验证奖励的强化学习(RLVR)(例如,数学题的答案正确性或代码的单元测试通过率)能够有效训练模型进行规划、反思和自我修正等长程推理。将推理能力视为一种可被显式训练和扩展的能力,为提升模型性能开辟了独立于预训练参数和数据规模的新维度。
RL在赋能大型推理模型(LRMs)时面临着算法设计、训练数据和基础设施等多方面的挑战。因此,系统性地回顾该领域的发展历程,评估其技术轨迹,并探索未来扩展策略,对于推动AI迈向更高层次的智能至关重要。
研究设计与核心方法
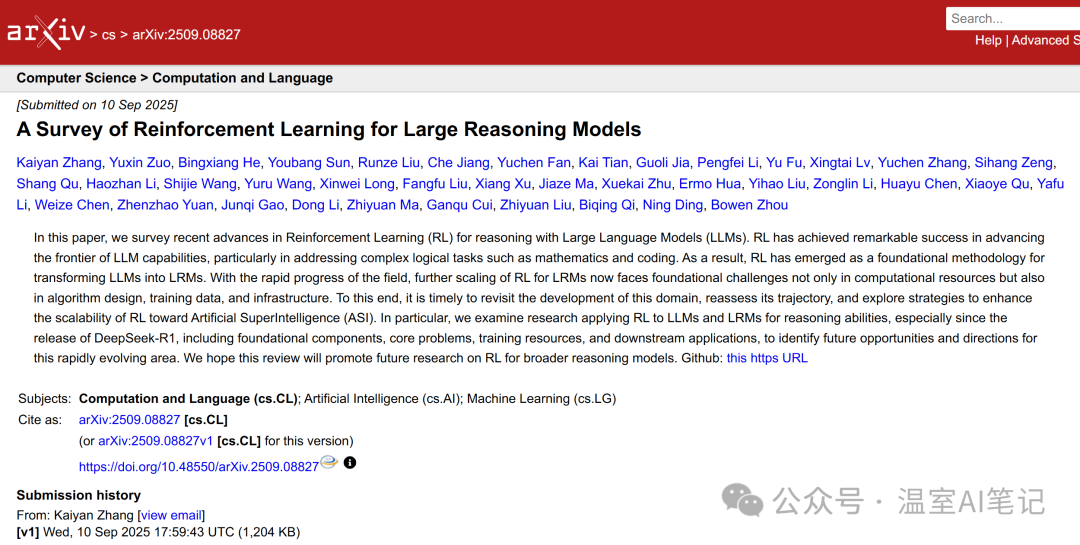
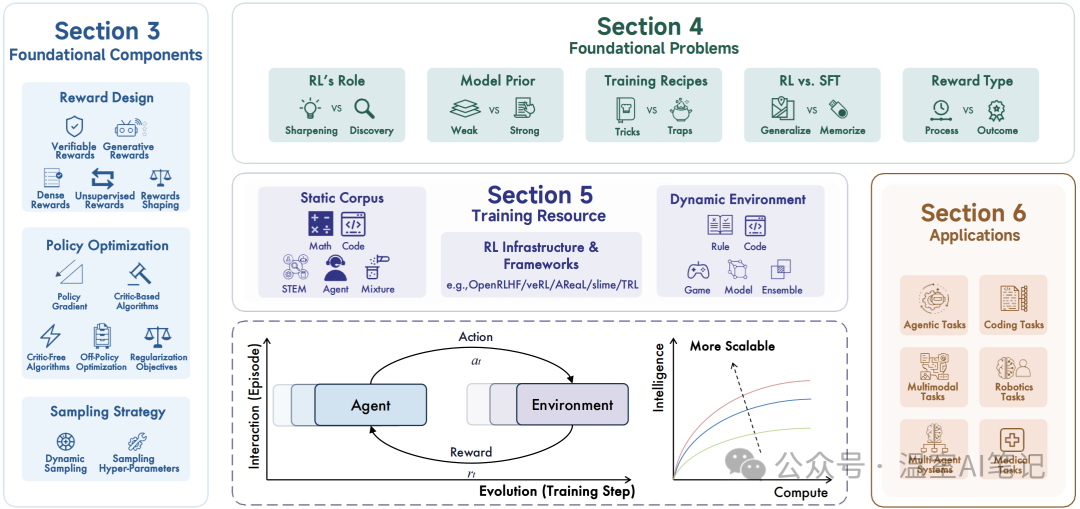
研究对应用RL提升LLM推理能力的研究进行了全面梳理。其核心框架围绕语言智能体与环境的长期演化和交互展开,系统地剖析了RL赋能LRMs的各个层面,包括基础构成、核心问题、训练资源和下游应用。
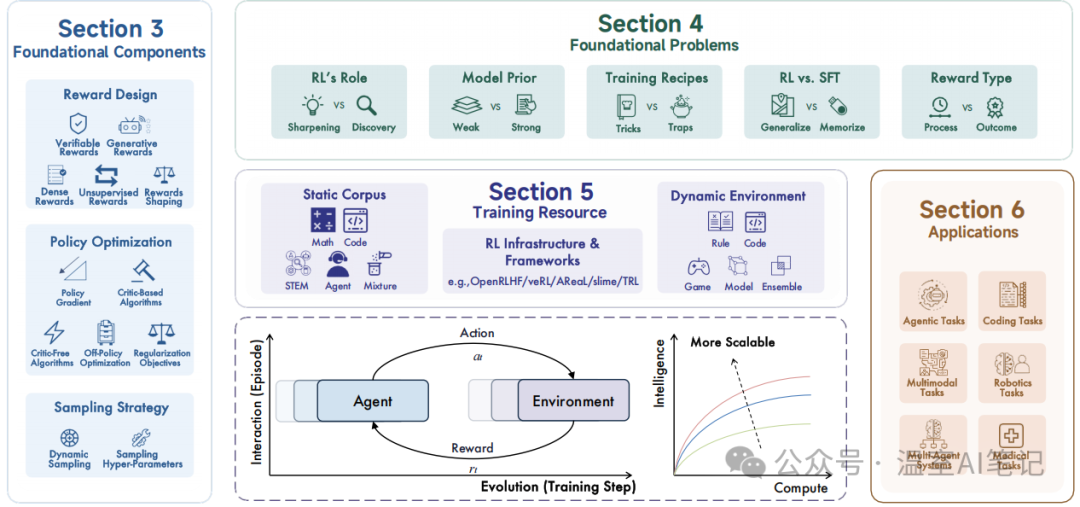
图1. 综述概览,涵盖RL赋能LRMs的基础组件、核心问题、训练资源及应用
文章追溯了RL方法论的演变,从经典的RLHF和DPO,发展到当前主流的RLVR,并展望了更具挑战性的开放式RL,清晰地展示了RL从行为对齐向能力提升的范式转移。
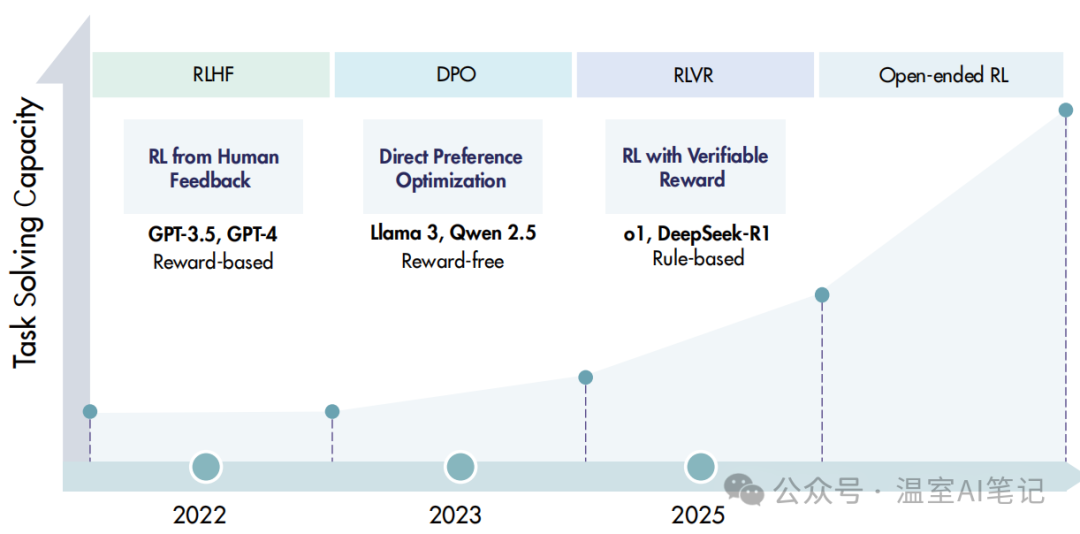
图2. 近年来RL在LLM中应用的方法论演进
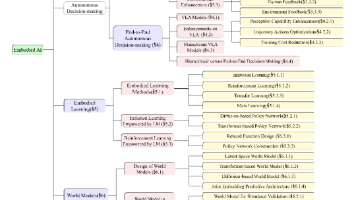
在技术层面,综述详细拆解了RL训练流程的三大基础组件:奖励设计(如可验证奖励、生成式奖励、稠密奖励等)、策略优化(涵盖基于评论家和无评论家的算法)以及采样策略。
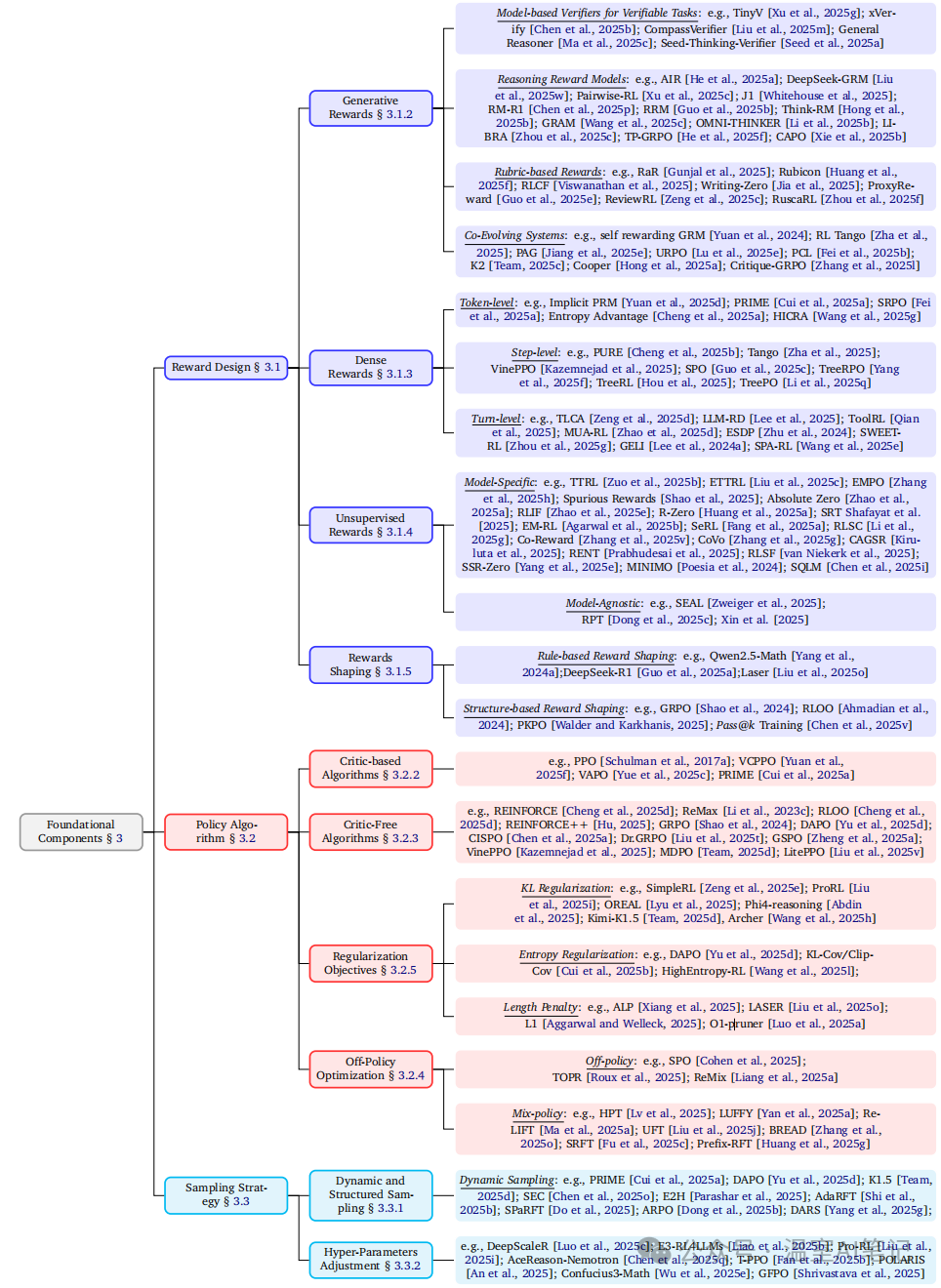
图3. RL基础组件的分类及代表性工作
核心结果与讨论
在对现有工作进行系统梳理的基础上,综述提炼出了当前领域内几个亟待解决的基础性问题。最核心的争议在于RL在模型能力提升中扮演的角色:究竟是“磨砺”(Sharpening)还是“发现”(Discovery)?“磨砺”观点认为,RL只是优化和重新加权了模型在预训练阶段已获得的潜在能力;而“发现”观点则主张,RL能够引导模型探索并学习到全新的推理模式。
另一个关键辩题是RL与监督微调(SFT)的对比,即模型是在“泛化”(Generalize)还是在“记忆”(Memorize)。大量证据表明,RL在分布外任务上表现出更强的泛化能力,而SFT则更容易过拟合到训练数据,导致表征漂移。然而,RL并非万能药,其效果严重依赖初始模型(即模型先验)的质量。对于能力较弱的基础模型,往往需要通过中段训练(Mid-training)注入高质量的推理数据来“预热”,才能更好地适应RL训练。
综述还强调了训练资源的重要性,包括高质量的静态数据集和动态交互环境。近年来,开源社区涌现出大量专为RL推理训练设计的模型、数据集和框架,极大地推动了领域发展。
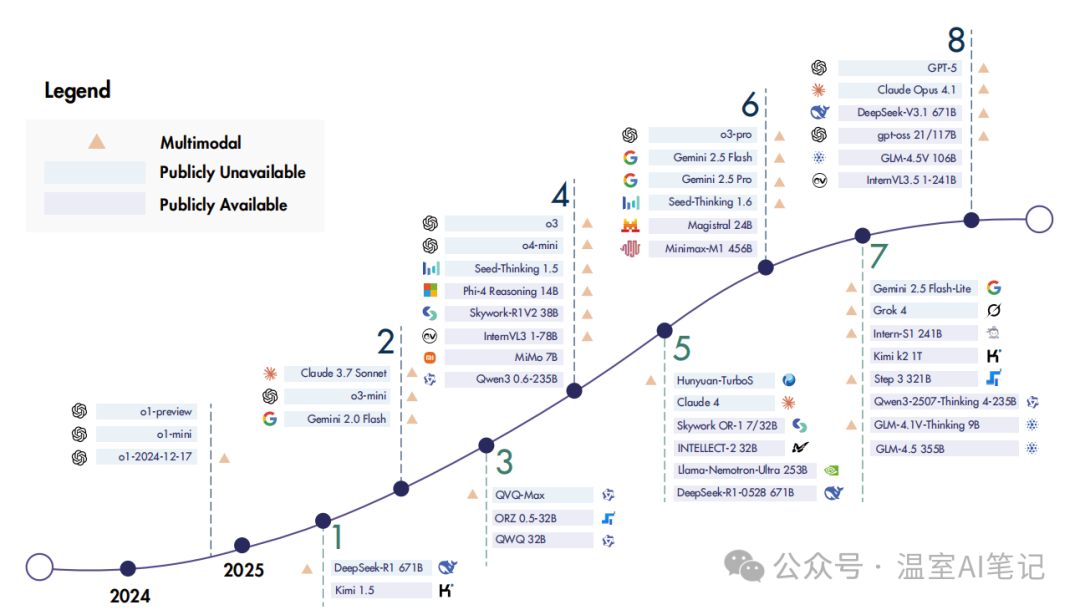
图4. 代表性的开源与闭源推理模型发展时间线
在应用层面,RL已在代码生成、智能体任务、多模态理解与生成、多智能体系统、机器人技术和医疗等多个领域展现出巨大潜力,催生了众多前沿模型和应用。
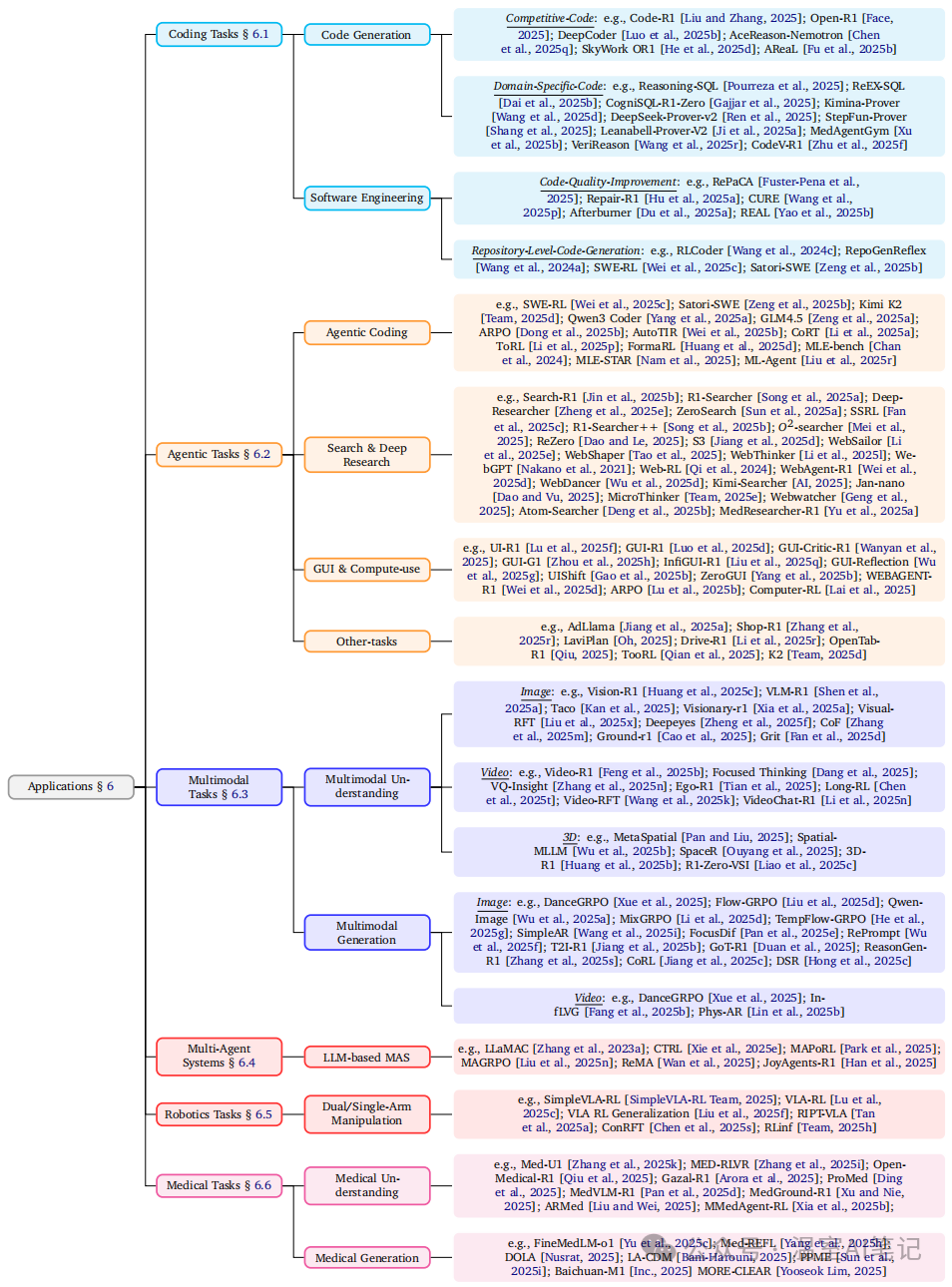
图8. RL在各项下游任务中的应用分类
研究展望
未来研究应聚焦:面向LLM的持续强化学习(Continual RL),以适应动态变化的任务和数据;基于记忆和世界模型的RL,以增强智能体的长期规划和理解能力;将RL应用于预训练阶段,从根本上提升模型的基础能力;以及面向扩散模型架构的RL等前沿探索。
AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以点扫描下方👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐

 22
22 0
0- 0



 已为社区贡献351条内容
已为社区贡献351条内容

所有评论(0)