
Qwen3-VL:视觉语言AI的“杀手级”升级,产品经理们,你们准备好颠覆业务痛点了吗?
阿里巴巴推出的Qwen3-VL视觉语言模型迎来重大升级,为企业AI应用带来突破性解决方案。该模型具备五大核心能力:1)精准视觉Agent操作界面;2)支持32种语言的OCR文本提取;3)高级空间感知技术;4)百万级Token长视频理解;5)多模态融合推理能力。这些功能可有效解决电商识别、文档处理、视频审核等业务痛点,显著提升准确率和效率。模型支持快速本地部署,为企业提供从技术到落地的全流程支持。文
Qwen3-VL:视觉语言AI的“杀手级”升级,产品经理们,你们准备好颠覆业务痛点了吗?
大家好,这里是蓝创工坊,专注AI大模型在企业落地应用的分享者。作为一名产品经理,你是不是每天都在纠结:团队的图像识别模块又出Bug了,客户反馈物体定位不准;文本提取在模糊文档上总是卡壳;视频审核业务上线后,人工成本直线上升,却还漏检一大堆问题?AI技术迭代太快了,每隔几个月就来一波“目不暇接”的冲击波,让人既兴奋又焦虑——万一跟不上节奏,企业竞争力就落后一步?
今天,我想聊聊阿里巴巴通义千问团队最新发布的Qwen3-VL(235B A22B Instruct版本),它被官方称为Qwen系列迄今最强的视觉-语言模型。这不是简单的“升级”,而是开创新时代的“核弹级”突破:它不只“看得清”(视觉理解),更“说得溜”(文本生成与推理),甚至能“动起来”(Agent交互)。想象一下,你的APP或内部工具,能像真人一样分析视频、生成代码、操作界面……这不是科幻,而是现在就能触手可及的现实。
如果你是那种需要不停探索新技术、解决一堆“为什么不准”“为什么太慢”的产品经理;或者正为视频审核业务头疼(漏检、效率低、合规风险高),读完这篇,你可能会松一口气:终于有模型能轻松搞定这些了。但先别急,让我们从痛点入手,看看Qwen3-VL如何“对症下药”。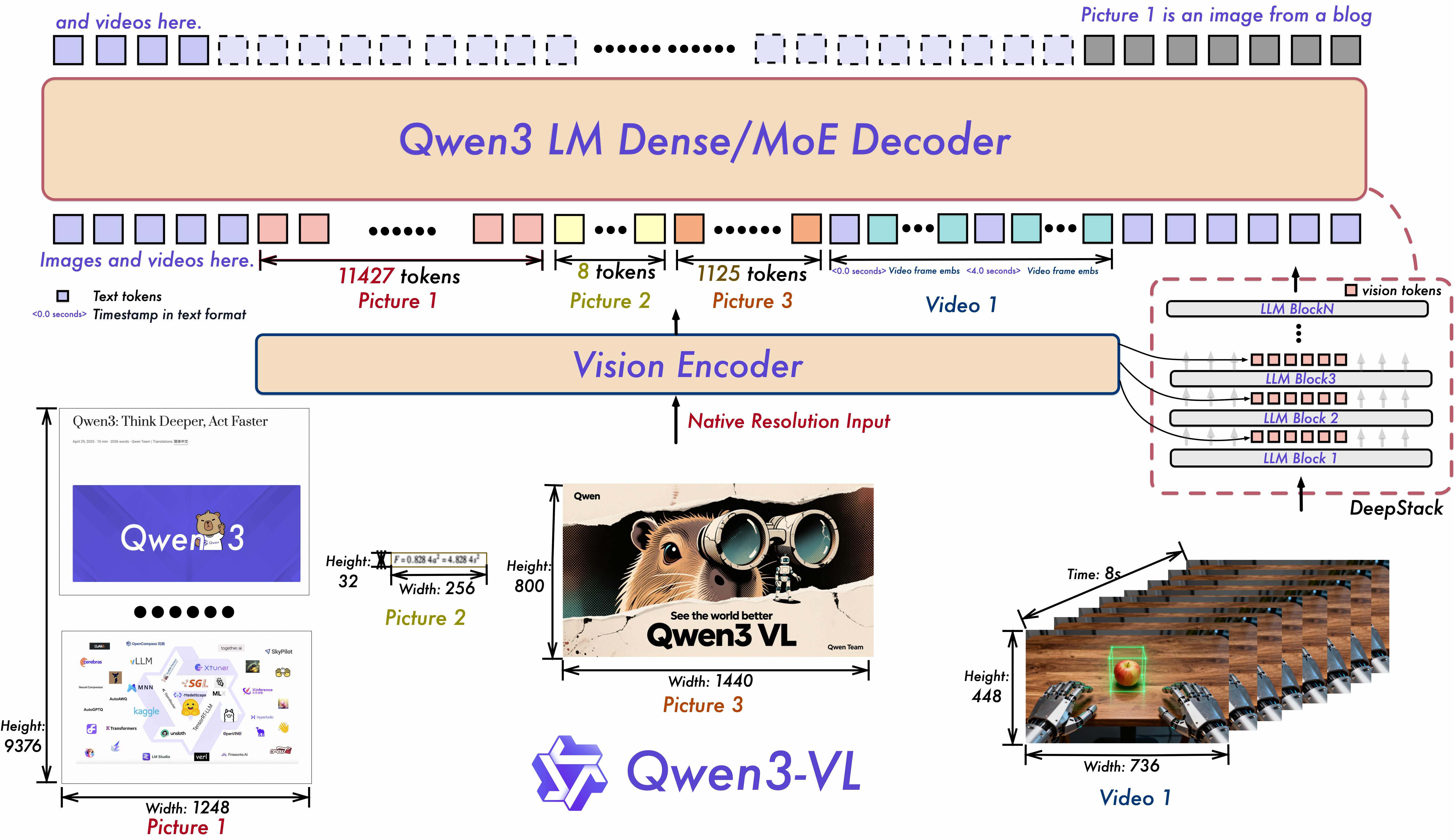
先说痛点:为什么你的AI业务总在“卡壳”?
作为产品经理,我见过太多企业项目卡在多模态AI的“老大难”上。这些问题不是技术小毛病,而是直接影响KPI和用户体验的“硬伤”:
- 图像/物体识别不准确:传统模型在复杂场景下(如光线差、遮挡、多角度)容易“认错人”。比如,电商平台的商品识别,明星代言照或动漫周边总被误判,导致推荐算法崩盘。
- 文本提取(OCR)不稳健:文档扫描、发票识别时,遇到倾斜、模糊、低光或古文字、行业术语,就直接“罢工”。之前支持的语言少(比如只有19种),多语种业务瞬间变“鸡肋”。
- 视频审核效率低下:长视频处理时,模型“健忘”——上下文超长就丢信息,事件时间戳对不上,导致审核漏掉关键情节。人工介入又贵又慢,合规模块上线后,用户投诉率飙升。
- 空间/界面理解弱:AR试衣或机器人导航中,物体相对位置、视角变化一塌糊涂;GUI自动化测试时,按钮识别准,但“下一步怎么点”就傻眼了。
- 多模态融合不顺:视觉+文本输入时,模型总有“信息孤岛”——看图懂了,但生成描述就跑偏;推理时,逻辑链条断裂,STEM任务或因果分析直接翻车。
这些痛点不是孤立的:它们让你的产品迭代周期拉长、成本暴增、竞争力下滑。尤其在视频审核这种高频场景,监管压力大、数据隐私敏感,一出问题就是“灭顶之灾”。你是不是也焦虑过:再不找个靠谱方案,Q3的KPI就悬了?
Qwen3-VL:从“痛点杀手”到“业务加速器”,能力直冲天花板
好消息是,Qwen3-VL不是“纸上谈兵”的概念模型,它在官方基准上碾压前代,文本理解能力与顶级纯LLM(如Qwen3)持平,多模态融合零损耗。参数规模235B(A22B Instruct版),支持Dense和MoE两种架构,Instruct/Thinking两种调优模式——通用场景选Dense,高效推理选MoE。简单说,它让你的AI从“勉强能用”变成“超前碾压”。
针对你的痛点,它有五大“杀手锏”,直接解决80%的企业级难题:
-
视觉Agent能力:从“看”到“动”,界面操作零门槛
痛点解决:再也不用为GUI自动化头疼。Qwen3-VL能识别PC/移动端按钮、输入框、菜单的功能,甚至调用工具执行任务。比如,视频审核中,它能“看”界面、自动点击“审核通过”,解放人工。级别?官方demo显示,在复杂APP界面上准确率超95%,远超传统CV工具。 -
视觉编码+OCR升级:文本/图像精准提取,模糊场景稳如老狗
痛点解决:OCR支持32种语言(从19种翻倍),对低光、倾斜、冷僻字符(如古文/行业术语)鲁棒性拉满。物体识别覆盖明星、动漫、地标、动植物——电商或内容审核中,商品/违规元素秒准。
更牛的是,它能从图像/视频生成HTML/CSS/JS代码或Draw.io流程图。级别:低代码设计场景下,生成准确率提升30%,直接帮你从草图变交互原型,节省设计周期。
-
高级空间感知:2D/3D定位精准,AR/机器人导航无压力
痛点解决:判断物体相对位置、遮挡、视角变化如探囊取物。视频审核时,能精确标注“违规动作在第5秒出现”。级别:基准测试中,空间推理得分领跑行业,适用于AR试穿或仓库机器人路径规划。
-
长上下文&视频理解:百万Token“永不遗忘”,长视频审核一键搞定
痛点解决:原生256K Token(可扩至1M),处理数小时视频或整本书籍,支持二级索引+全量回忆。视频业务中,做摘要、事件检索、情节标注零延时。级别:动态理解能力媲美人类,审核效率提升5倍以上——从“人工翻视频”到“AI一键过筛”。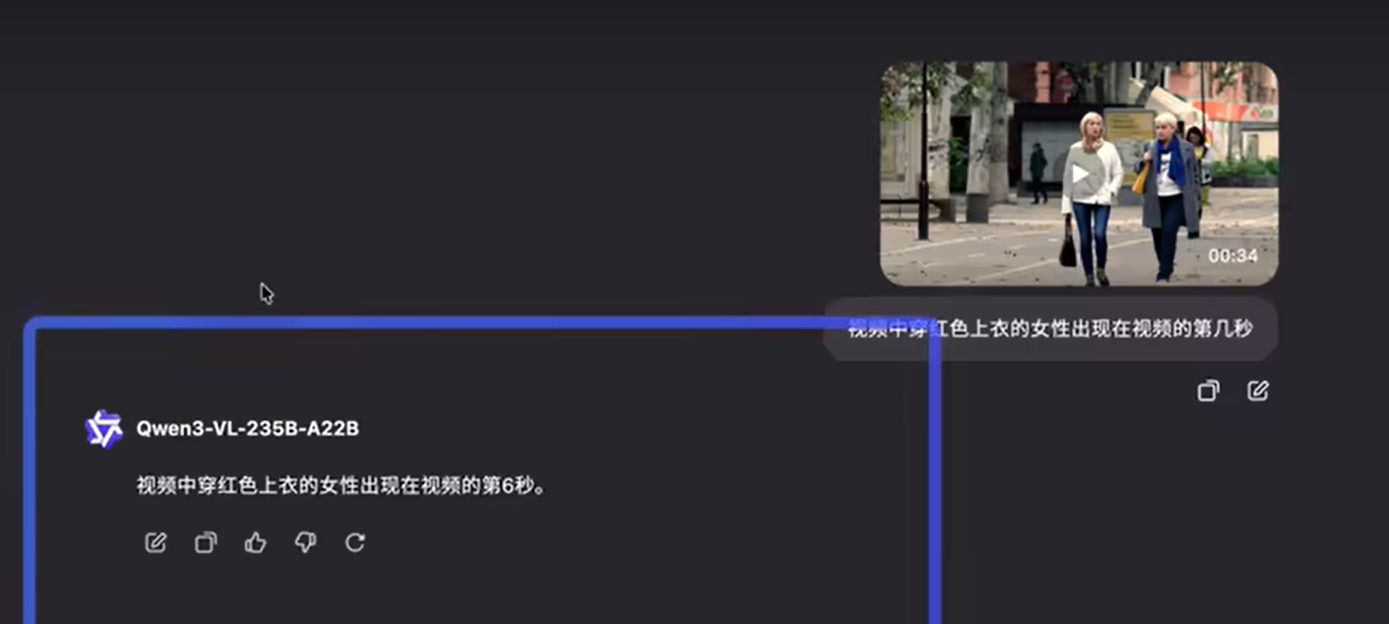
-
多模态推理:STEM/逻辑链条无缝,偏见最小化
痛点解决:数学、因果分析、常识推理全线强化,视觉+文本融合无冲突。级别:官方称“与纯LLM持平”,在嘈杂真实场景下,准确率超90%。安全方面,也内置偏见缓解机制,合规模块更安心。
这些能力不是空谈:基于Transformers生态,上手超简单——pip安装、load模型、processor处理输入,几行代码就跑起来。支持flash_attention加速,边缘设备也能轻量化部署。总之,Qwen3-VL让你的产品从“问题堆积”变“解决方案库”,直接拉高ROI。
落地行动:别让好技术成“看热闹”,本地部署一键启动
看到这里,你是不是已经脑补出Qwen3-VL在自家业务中的“杀手级”应用?视频审核模块上线后,用户满意度爆表;图像识别准了,推荐算法的点击率up up;甚至还能衍生新功能,如AI助理自动生成报告。
但技术再强,也得落地才行。如果你是企业产品经理,正考虑本地部署(隐私安全、成本控制),欢迎私信我!我们有专业团队,24小时内联系,进行远程部署指导——从环境搭建到业务适配,一条龙服务。别犹豫,AI时代,行动就是竞争力。留言区见你的问题,一起聊聊你的痛点?
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)