LazyLLM实战--金庸小说阅读辅助器
本文介绍了基于LazyLLM框架开发的金庸小说阅读辅助器项目。LazyLLM是一个开箱即用的AI应用框架,相比LangChain更注重快速部署和简洁API。项目采用RAG(检索增强生成)技术,通过Document类处理多种文档格式,使用Embedding模型生成文本向量,并利用Retriever组件实现语义检索。以《神雕侠侣》为例,展示了如何构建一个"边读边问"的阅读辅助系统,可快速检索小说内容并
前言
这个项目是csdn的一个活动
活动内容包括两个项目:
一个是快速部署,一个是落地实战。目的是让大家使用一个新的框架LazyLLMAgent。
框架介绍
这个框架是一个“现成可用”的 AI 应用框架,重点是把问答 Agent、RAG 检索增强这类常见需求,做成“10 分钟跑起来”的工程模板。目标是“少折腾,快上线”,而不是从零搭积木。
对比langchain,langgraph框架:
LangChain 模块特别多、生态巨大。你可以非常灵活地拼,但也更容易写出又长又碎的工程。
LangGraph 是“把 Agent 流程画成图”的流程引擎,适合复杂、多分支、可恢复的长流程编排。
LazyLLM的定位:把“常用的 Agent + RAG 产品形态”封装成简洁 API,开箱即用。
快速部署
项目的部署非常简单,官方也有对应的文档:https://blog.csdn.net/csdnstudent/article/details/151827710。在这里就不重复这个过程了。
项目实战:金庸小说阅读辅助器
项目目的:
一时间也没想到更好的课题,但是既然是结合RAG的agent,那么就可以利用RAG来制作一个金庸小说阅读辅助器,让读者“边读边问、带检索地读”金庸小说:对人物、情节、设定、武功、地理等问题,实时检索原文证据,再生成解释与延伸。比较金庸小说这么长篇幅的小说的内容十分之多,也很容易遗漏,需要时可以进行提问查看,减少翻阅的时间。同理也可以作为其他内容的阅读辅助器。
rag
RAG的核心是从文档集合进行文档检索,集合内的文档格式各异,针对这些不同格式的文档,我们需要特定的解析器来提取其中有用的文本、图片、表格、音频和视频等内容。
Document
在 LazyLLM 中,文档集合被抽象为Document类,其支持传入不同的文件/文件路径集合、选择多种向量模型及存储类型,并提供高效的方法注册不同格式的解析器(Reader)、创建不同类型的“节点组”,以生成我们想要的切片种类。
目前 LazyLLM 内置的 Document可以支持 DOCX,PDF,PPT,EXCEL 等常见格式的解析与提取,您也可以自定义 Reader 读取特定格式的文档(在后续的教程中我们会进行详细介绍)。
Document的主要参数如下:
- dataset_path (str) – 数据集目录的路径。此目录应包含要由文档模块管理的文档(注意:暂不支持指定单个文件)。
- embed (Optional[Union[Callable, Dict[str, Callable]]], default: None ) – 用于生成文档 embedding 的对象。如果需要对文本生成多个 embedding,此处需要通过字典的方式指定多个 embedding 模型,key 标识 embedding 对应的名字, value 为对应的 embedding 模型。
- manager (bool, default: False ) – 指示是否为文档模块创建用户界面的标志。默认为 False。
- launcher (optional, default: None ) – 负责启动服务器模块的对象或函数。如果未提供,则使用 lazyllm.launchers 中的默认异步启动器 (sync=False)。
- store_conf (optional, default: None ) – 配置使用哪种存储后端
- doc_fields (optional, default: None ) – 配置需要存储和检索的字段及对应的类型
Embedding
Embedding介绍:
LazyLLM 支持调用线上和线下 Embedding 模型,其中线上模型通过 OnlineEmbeddingModule调用,线下模型通过 TrainableModule调用。
Embedding的主要参数如下:
- OnlineEmbeddingModule 用来管理创建市面主流的在线Embedding服务模块,可配置参数有:
- source (str) – 指定要创建的模块类型,可选为 openai / sensenova / glm / qwen / doubao
- embed_url (str) – 指定要访问的平台的基础链接,默认是官方链接
- embed_model_name (str) – 指定要访问的模型,默认值为 text-embedding-- ada-002(openai) / nova-embedding-stable(sensenova) / embedding-2(glm) / text-embedding-v1(qwen) / doubao-embedding-text-240715(doubao)
Retriever
Retriever介绍:
LazyLLM 中执行检索功能的是 Retriever 组件, Retriever 组件可以创建一个用于文档查询和检索的检索模块。此构造函数将会初始化一个检索模块,该模块根据指定的向量模型/相似度度量配置文档检索功能。
Retriever的主要参数如下:
- doc (object) – 文档模块实例,可以是单个实例,也可以是一个实例的列表。如果是单个实例,表示对单个Document进行检索,如果是实例的列表,则表示对多个Document进行检索。
- group_name (str) – 在哪个 node group 上进行检索。(lazyllm_root,
- group_name 有三种内置切分策略,都是用 SentenceSplitter 切分,区别在于块大小不同:
- CoarseChunk: 块大小为 1024,重合长度为 100
- MediumChunk: 块大小为 256,重合长度为 25
- FineChunk: 块大小为 128,重合长度为 12
- similarity (Optional[str], default: None ) – 用于设置文档检索的相似度函数。候选集包括 [“bm25”, “bm25_chinese”, “cosine”]
- similarity_cut_off (Union[float, Dict[str, float]], default: float('-inf') ) – 当相似度低于指定值时丢弃该召回节点。在多 embedding 场景下,如果需要对不同的 embedding 指定不同的值,则需要使用字典的方式指定,key 表示指定的是哪个 embedding,value 表示相应的阈值。如果所有的 embedding 使用同一个阈值,则只指定一个数值即可。
- index (str, default: 'default' ) – 用于文档检索的索引类型。目前仅支持 ‘default’。
- topk (int, default: 6 ) – 表示取相似度最高的多少篇文档。
- embed_keys (Optional[List[str]], default: None ) – 表示通过哪些 embedding 做检索,不指定表示用全部 embedding 进行检索。
- similarity_kw – 传递给 similarity 计算函数的其它参数。
具体的用法可看:https://blog.csdn.net/csdnstudent/article/details/151999341
这里以神雕侠侣为例:https://pdfs.top/book/0b863 在此处下载pdf后放入根目录的data文件夹
利用上述说到的Document,Embedding,Retriever进行一个简单的测试:
import lazyllm
from lazyllm import Retriever, Document, OnlineEmbeddingModule
from get_api import APIKEY
import os
import time
embed_model = OnlineEmbeddingModule(source='glm', embed_model_name='embedding-2', api_key=APIKEY)
start_time = time.time()
doc = Document(dataset_path="data", embed=embed_model)
retriever = Retriever(doc, group_name='CoarseChunk', similarity="cosine", topk=3)
end_time = time.time()
print(f'Document time: {end_time - start_time} seconds')
llm = lazyllm.OnlineChatModule(source='glm',model='glm-4.5',api_key=APIKEY)
print(llm)
# prompt 设计
prompt = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions.'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
start_time = time.time()
query = "介绍一下杨过"
# 将Retriever组件召回的节点全部存储到列表doc_node_list中
doc_node_list = retriever(query=query)
# 将query和召回节点中的内容组成dict,作为大模型的输入
res = llm({"query": query, "context_str": "".join([node.get_content() for node in doc_node_list])})
end_time = time.time()
print(f'With RAG Answer: {res}')
print(f'With RAG Answer time: {end_time - start_time} seconds')
输出:
(pytorch) PS D:\python\LazyLLM-main> python .\jinyong_ragtest.py
42416: 2025-09-24 15:42:27 lazyllm INFO: (lazyllm.tools.rag.utils:121) DocManager use file-system monitoring worker: True
Document time: 0.02466750144958496 seconds
<Module type=OnlineChat url=https://open.bigmodel.cn/api/paas/v4/ stream=True return_trace=False>
42416: 2025-09-24 15:42:28 lazyllm INFO: (lazyllm.tools.rag.data_loaders:21) DirectoryReader loads data, input files: ['D:\\python\\LazyLLM-main\\data\\神雕侠 侣(三联版).pdf']
42416: 2025-09-24 15:44:12 lazyllm INFO: (lazyllm.tools.rag.data_loaders:35) DirectoryReader loads data done!
42416: 2025-09-24 15:45:07 lazyllm INFO: (lazyllm.tools.rag.doc_processor:57) Add documents done!
With RAG Answer: <think>嗯,用户让我介绍一下杨过,我需要根据提供的上下文来回答。首先,我得仔细看看这段文字里关于杨过的信息。
首先,开头提到杨过从未见过大军启程,被蒙古军的壮观所震撼。这里说明他之前可能没经历过战争场面,对军事不太熟悉。接着他遇到两个小军,对方射箭,他轻松接住,显示他 武功高强,但小军被吓住,不敢追他。这部分突出他的武艺,也侧面反映他可能年轻,因为小军称他为"蛮子",有点轻视的意思。
然后他回到铁匠铺,和冯默风对话。冯默风建议他投军抗蒙,但杨过拒绝,理由是要找姑姑小龙女。这里可以看出他的首要目标是寻找小龙女,而不是国家大义。他提到蒙古军势大 ,自己一人之力无用,表现出他个人的考量,也反映他对宋朝朝廷的不满,因为小时候受官吏之苦,觉得宋朝皇帝未必好,不值得效力。这点很重要,说明他性格中的独立和叛逆, 不盲从权威。
接下来是郭靖出场,责备杨过,提到他的名字"过"和表字"改之"。郭靖解释名字的含义是希望他有过能改,这里揭示了杨过名字的由来,以及郭靖对他的期望。杨过听到后内心震动 ,想起童年往事,说明他与郭靖有渊源,但内心可能有矛盾,因为郭靖严厉,而杨过可能经历过不少挫折。
后面小龙女出现,杨过情绪激动,流泪问她是否还会离开。小龙女回答不知道,杨过则表示要永远跟随她。在众人面前他们旁若无人,显示两人感情的深厚,以及杨过对小龙女的依 赖。同时,小龙女下山找杨过,不识路,不懂钱物,闹笑话,但路人因她美貌而宽容,这里衬托出小龙女的单纯和杨过在她心中的重要性。
需要整合这些点:杨过的武功高强,性格独立,重视个人情感(尤其是小龙女),对传统忠义观念有保留,与郭靖有师徒关系但存在理念差异。名字"过"和"改之"象征郭靖对他的期 望,但他内心可能有挣扎。他与小龙女的感情是核心驱动力,甚至超过家国大义。
还要注意他的经历:幼年流落江湖,受官吏之苦,导致对朝廷不信任。在冯默风的劝告中,他选择个人目标而非集体责任,显示他更注重个人情感和自由。在英雄宴上与小龙女重逢 ,情感外露,不顾他人眼光,体现他的真性情和叛逆。
可能遗漏的点:上下文中提到孙不二、尹志平等人对小龙女的反应,但杨过似乎不在意这些,专注小龙女。郭靖的严厉教导与杨过内心的抵触形成对比,暗示后续冲突。但用户的问 题只是介绍杨过,所以重点放在他的性格、能力、关系和动机上。
总结时,要突出他的武功、性格特点(独立、叛逆、重情)、与小龙女的关系、名字的寓意,以及他与郭靖的复杂关系。避免涉及未提及的内容,如其他情节或结局,严格基于提供 的文本。</think>根据提供的上下文,以下是关于杨过的关键信息整理:
---
### **身份与背景**
1. **名字由来**:
- 单名“过”,表字“改之”,由郭靖所取,寓意“有过则改”。郭靖对其寄予厚望,希望他立身端正。
2. **身世经历**:
- 自幼流落江湖,深受官吏欺凌,对宋朝朝廷缺乏信任,认为“蒙古人残暴,宋朝皇帝也未必是好人”。
- 与郭靖、黄蓉有深厚渊源(郭靖是其伯父,黄蓉曾教授他经书)。
---
### **性格特点**
1. **重情重义**:
- 将寻找小龙女(姑姑)视为人生最重要的事,甚至高于抗蒙救国。重逢时情感外露,流泪恳求“不再撇下我”,并誓言“你到哪里,我便跟到哪里”。
2. **独立叛逆**:
- 拒绝冯默风投军抗蒙的建议,认为“一人之力无用”,且不愿为宋朝效力,体现其不盲从权威、重视个人自由的一面。
- 在众人面前与小龙女旁若无人互动,无视世俗眼光。
3. **内心矛盾**:
- 郭靖的严厉教导(如质问“过”字含义)会触动他童年伤心的回忆,显示其成长中存在压抑与挣扎。
---
### **能力与表现**
1. **武功高强**:
- 轻松接住蒙古小军劲急射来的箭,令对方畏惧。冯默风称其“正当英年”,暗示潜力巨大。
2. **见识有限**:
- 初见蒙古大军行军阵势时“惊心动魄”,显示其缺乏军事经验,对战争残酷性认知不足。
---
### **核心关系**
1. **与小龙女**:
- 情感羁绊极深,小龙女是他行动的唯一驱动力。小龙女下山寻他时不懂世故(如不识路、不知付钱),他却始终守护。
2. **与郭靖**:
- 郭靖对他“爱之切,责之深”,既欣赏他的才华,又对其行为严加管教(如当众斥责其“身败名裂”)。杨过对郭靖有敬畏,但理念存在冲突。
3. **对抗蒙的态度**:
- 认可蒙古军骑射术“非宋兵所能抵挡”,但选择置身事外,专注个人目标,与郭靖的家国情怀形成鲜明对比。
---
### **关键事件**
1. **蒙古军南下**:
目睹蒙古军威势后,与铁匠冯默风讨论时局,拒绝参与抗蒙,执意北上寻小龙女。
2. **英雄宴重逢**:
在陆家庄英雄宴上与小龙女相拥而泣,无视全场两千余人,展现二人超越世俗的情感联结。
3. **名字训诫**:
郭靖借“改之”表字严厉教导他“立定脚跟,好好做人”,引发他内心震动,回忆童年伤痛。
---
### **总结**
杨过是金庸笔下极具矛盾魅力的角色:他武功卓绝、情感炽烈,却因童年创伤对世俗规则疏离;他重视个人情义胜于家国大义,与郭靖的“侠之大者”理念形成深刻对立。其名字“过改之”既承载郭靖的期望,也暗喻他一生在叛逆与救赎间的挣扎。对小龙女的执着是他生命的核心动力,也是他对抗世界的铠甲。
With RAG Answer time: 197.34557247161865 seconds
可以看到LazyLLMAgent的RAG能力还是很ok的,检索到的内容也是正确的,因为pdf确实很长,耗时有点久,第一次的RAG肯定是会消耗时间的。
rag改进
这里的数据是存储在内存中,也就是每一次运行都需要编码分块一次,重复耗时,其实可以直接存储到本地,可以减少搜索的时间。代码如下:
首先安装:pip install "chromadb>=0.4.24" 用来存储
import os
import time
from pathlib import Path
import lazyllm
from lazyllm import Document, Retriever, OnlineEmbeddingModule
from get_api import APIKEY
def main():
# 确保持久化目录存在(向量库与分片库会落在这里)
# 注意:将持久化目录放在数据集目录之外,避免被文档读取器误当作原始文件解析
store_dir = Path("kb_store")
store_dir.mkdir(parents=True, exist_ok=True)
embed_model = OnlineEmbeddingModule(source='glm', embed_model_name='embedding-2', api_key=APIKEY)
# 配置持久化存储:
# - 向量库:Chroma -> data/rag_store/chroma.sqlite3
# - 分片内容与元数据:SQLite -> data/rag_store/segments.db
store_conf = {
"vector_store": {
"type": "ChromadbStore",
"kwargs": {"dir": str(store_dir)}
},
"segment_store": {
"type": "MapStore",
"kwargs": {"uri": str(store_dir / "segments.db")}
}
}
t0 = time.time()
# 第一次运行会解析/切分/入库;之后将直接复用本地索引,显著加速
doc = Document(dataset_path="data", embed=embed_model, store_conf=store_conf)
retriever = Retriever(doc, group_name=Document.CoarseChunk, similarity="cosine", topk=3)
t1 = time.time()
print(f"Document init (with persistent store) time: {t1 - t0:.2f}s")
# 进行一次简单查询验证读取是否正常
llm = lazyllm.OnlineChatModule(source='glm', model='glm-4.5', api_key=APIKEY)
prompt = 'You are an assistant. Answer using provided context.'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
query = "介绍一下杨过"
nodes = retriever(query=query)
ctx = "".join([n.get_content() for n in nodes])
t2 = time.time()
print(f"Retrieve time: {t2 - t1:.2f}s, nodes={len(nodes)}")
res = llm({"query": query, "context_str": ctx})
t3 = time.time()
print(f"Answer: {res}")
print(f"LLM time: {t3 - t2:.2f}s")
if __name__ == "__main__":
main()
输出:
(pytorch) PS D:\python\LazyLLM-main> python .\jinyong_regtest_local.py
39796: 2025-09-24 15:57:08 lazyllm INFO: (lazyllm.tools.rag.utils:121) DocManager use file-system monitoring worker: True
Document init (with persistent store) time: 0.04s
39796: 2025-09-24 15:57:09 lazyllm INFO: (lazyllm.tools.rag.store.hybrid.map_store:100) [MapStore] SQLite DB kb_store\segments.db does not exist, creating...
39796: 2025-09-24 15:57:10 lazyllm SUCCESS: (lazyllm.tools.rag.store.vector.chroma_store:97) Initialzed chromadb in path: kb_store
39796: 2025-09-24 15:57:10 lazyllm INFO: (lazyllm.tools.rag.data_loaders:21) DirectoryReader loads data, input files: ['D:\\python\\LazyLLM-main\\data\\神雕侠侣(三联版).pdf']
39796: 2025-09-24 15:58:53 lazyllm INFO: (lazyllm.tools.rag.data_loaders:35) DirectoryReader loads data done!
39796: 2025-09-24 15:59:51 lazyllm INFO: (lazyllm.tools.rag.doc_processor:57) Add documents done!
Retrieve time: 163.75s, nodes=3
Answer: <think>我需要根据提供的上下文内容来介绍杨过。从文本中,我可以提取关于杨过的以下信息:
1. 杨过是一个武功高强的人,能够接住射来的箭,若非有武功,早被射死了。
2. 他似乎与小龙女有关系,在寻找小龙女("我要北上去寻我姑姑")。
3. 他自幼流落江湖,深受小官小吏之苦。
4. 他对蒙古人和宋朝皇帝都不太认同,觉得"蒙古人固然残暴,宋朝皇帝也未必就是好人"。
5. 他的名字"过"是郭靖取的,表字是"改之",意思是"有了过失就要悔改"。
6. 他与小龙女在陆家庄重逢,小龙女找到他时,他流下泪来,表明他非常在乎小龙女。
7. 他对小龙女非常忠诚,说"你今后到哪里,我便跟你到哪里"。
8. 郭靖对他"爱之切,就不免求之苛,责之深",表明郭靖很看重他,对他要求严格。
基于这些信息,我可以为杨过做一个介绍。</think>杨过是金庸武侠小说《神雕侠侣》中的主要人物。从文中可以看出,他是一位武功高强的年轻侠士,能够轻松接住射来的劲箭。他自幼流落江湖,深受小官小吏之苦,这让他对当权者没有太多好感。
杨过与小龙女有着深厚的感情,文中称小龙女为"姑姑",他一直在寻找她。当两人在陆家庄重逢时,杨过激动得流下泪来,并表示愿意追随小龙女到任何地方。这表明他对小龙女的感情非常深厚。
他的名字"过"是郭靖所取,表字"改之",寓意"有了过失就要悔改"。郭靖对他既关爱又严格要求,希望他能"立定脚跟,好好做人"。
杨过性格复杂,一方面有侠义精神,另一方面又有些叛逆。当冯默风建议他回南投军抵抗蒙古入侵时,他婉拒了,认为寻找小龙女更重要,且对宋朝皇帝也不甚认同。在陆家庄的英雄宴上,他与小龙女重逢时旁若无人的表现,也显示他不拘泥于世俗礼法的性格。
LLM time: 11.39s
第一次运行之后可以看到根目录下的:
就是对应的数据,接着进行第二次查询:
输出:
(pytorch) PS D:\python\LazyLLM-main> python .\jinyong_regtest_local.py
19584: 2025-09-24 16:04:00 lazyllm INFO: (lazyllm.tools.rag.utils:121) DocManager use file-system monitoring worker: True
Document init (with persistent store) time: 0.02s
19584: 2025-09-24 16:04:01 lazyllm SUCCESS: (lazyllm.tools.rag.store.vector.chroma_store:97) Initialzed chromadb in path: kb_store
Retrieve time: 1.61s, nodes=3
Answer: <think>我需要根据提供的上下文内容来介绍杨过。从文本中,我可以提取以下关于杨过的信息:
1. 杨过是一个年轻人,被称为"杨公子"。
2. 他有武功,能够接住射来的箭,这表明他身手不凡。
3. 他有一个叫"姑姑"的人,即小龙女,他想北上寻找她。
4. 他自幼流落江湖,受过小官小吏的苦。
5. 他的名字"过"是郭靖取的,表字是"改之",意思是"有了过失就要悔改"。
6. 在大厅上,有很多人,当小龙女找到他时,他流下眼泪,问小龙女是否还会撇下他,表明他与小龙女之间有深厚的感情。
7. 他在大厅上与小龙女交谈时,旁若无人。
8. 郭靖对他"爱之切,求之苛,责之深",表明郭靖对他很严厉但也很关心他。
根据这些信息,我可以对杨过做一个基本介绍。</think>杨过是《神雕侠侣》中的主要人物,是一位年轻有为的武林人士。他有不错的武功,能够接住射来的急箭,显示出身手不凡。
杨过自幼流落江湖,深受小官小吏之苦,这使他对社会有着复杂的看法。他有一个非常牵挂的人——小龙女(他称其为"姑姑"),寻找小龙女是他生活中最重要的事情。
他的名字"过"是由郭靖所取,表字为"改之",寓意是"有了过失就要悔改"。郭靖对他既严厉又关心,体现了"爱之切,求之苛,责之深"的态度。
杨过的性格比较复杂,他既有重情重义的一面(对小龙女的深情),也有不愿为宋朝皇帝出力的独立思想。当他与小龙女重逢时,情感外露,流下眼泪,表明他内心真挚而敏感。在关键时刻,他能够表现出勇气和决心,但有时也会因个人情感而忽视大局。
LLM time: 6.84s
可以看到总耗时只有7s,大大节省了时间。
Agent搭建
将Rag接入llm的回复中,同时也要指定刚才定义的数据库,可以减少时间的消耗。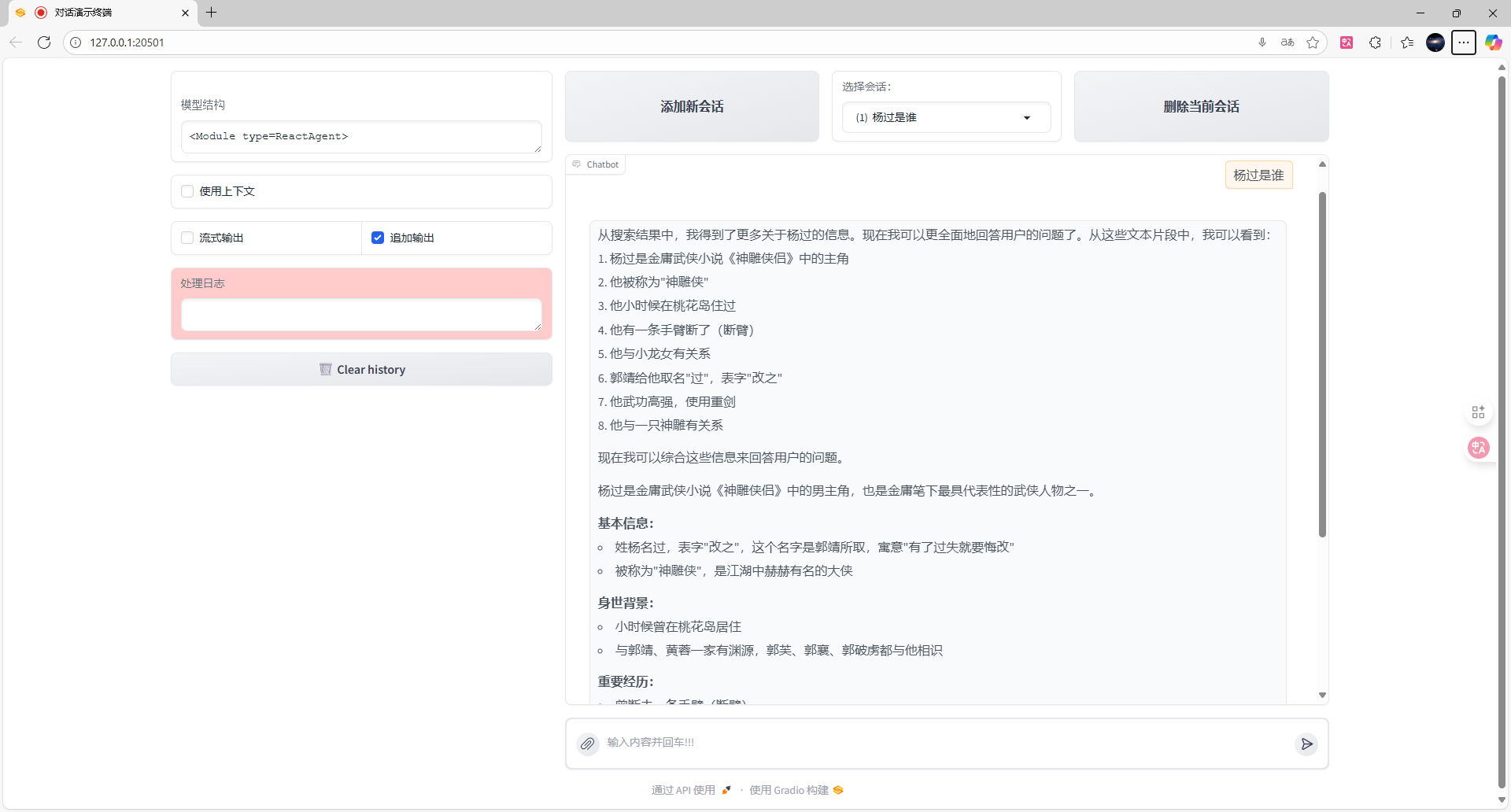
总耗时:
[Timing] answer: 2.10s
42864: 2025-09-24 16:13:10 lazyllm SUCCESS: (lazyllm.tools.rag.store.vector.chroma_store:97) Initialzed chromadb in path: kb_store
[Timing] answer: 2.60s
[Timing] answer: 7.99s
总共12s左右
三次输出时间是因为,对于function-call的大模型来说一般就是三个阶段:
- 决策阶段:要不要用工具/用哪个工具
- 汇总阶段:拿到工具结果后生成回答
- 收尾阶段:润色/补充说明(有些模型或 Agent 会再来一次“最终定稿”)
具体代码如下:
import lazyllm
import time
from lazyllm import (
fc_register, Document, Retriever,
OnlineEmbeddingModule, OnlineChatModule, WebModule,
ReactAgent
)
from get_api import APIKEY
embed_model = OnlineEmbeddingModule(source='glm', embed_model_name='embedding-2', api_key='8df34f9ec1894e5f9fdf863c9f1aef6a.aSipXmwYch69ymaD')
# 与本地持久化配置对齐(kb_store/)
store_conf = {
"vector_store": {
"type": "ChromadbStore",
"kwargs": {"dir": "kb_store"}
},
"segment_store": {
"type": "MapStore",
"kwargs": {"uri": "kb_store/segments.db"}
}
}
doc = Document(dataset_path="data", embed=embed_model, store_conf=store_conf)
retriever = Retriever(doc, group_name='CoarseChunk', similarity="cosine", topk=3)
# 注册RAG工具
@fc_register("tool")
def search_knowledge_base(query: str):
"""
搜索知识库并返回相关文档内容
Args:
query (str): 搜索查询字符串
"""
# 将Retriever组件召回的节点全部存储到列表doc_node_list中
doc_node_list = retriever(query=query)
# 将召回节点中的内容组合成字符串
context_str = "".join([node.get_content() for node in doc_node_list])
return context_str
# prompt 设计
prompt = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions. You can use the search_knowledge_base tool to find relevant information from the knowledge base.'
# 创建ReactAgent
# 终端耗时打印:封装一个带计时的 LLM 包装器
class TimedLLM:
def __init__(self, inner):
self._inner = inner
def prompt(self, *args, **kwargs):
return self._inner.prompt(*args, **kwargs)
def share(self, *args, **kwargs):
self._inner = self._inner.share(*args, **kwargs)
return self
def used_by(self, *args, **kwargs):
self._inner = self._inner.used_by(*args, **kwargs)
return self
def __call__(self, *args, **kwargs):
t0 = time.time()
res = self._inner(*args, **kwargs)
t1 = time.time()
print(f"[Timing] answer: {t1 - t0:.2f}s")
return res
def __getattr__(self, name):
# Delegate other attributes/methods to inner module
return getattr(self._inner, name)
timed_llm = TimedLLM(OnlineChatModule(source='glm', model='glm-4.5', api_key=APIKEY, stream=False))
agent = ReactAgent(
llm=timed_llm,
tools=['search_knowledge_base'],
prompt=prompt,
stream=False
)
# 创建Web模块并启动
w = WebModule(agent, stream=False)
w.start().wait()
输出的文本效果如下:
从搜索结果中,我得到了更多关于杨过的信息。现在我可以更全面地回答用户的问题了。从这些文本片段中,我可以看到:
杨过是金庸武侠小说《神雕侠侣》中的主角
他被称为"神雕侠"
他小时候在桃花岛住过
他有一条手臂断了(断臂)
他与小龙女有关系
郭靖给他取名"过",表字"改之"
他武功高强,使用重剑
他与一只神雕有关系
现在我可以综合这些信息来回答用户的问题。
杨过是金庸武侠小说《神雕侠侣》中的男主角,也是金庸笔下最具代表性的武侠人物之一。
基本信息:
姓杨名过,表字"改之",这个名字是郭靖所取,寓意"有了过失就要悔改"
被称为"神雕侠",是江湖中赫赫有名的大侠
身世背景:
小时候曾在桃花岛居住
与郭靖、黄蓉一家有渊源,郭芙、郭襄、郭破虏都与他相识
重要经历:
曾断去一条手臂(断臂)
与小龙女有着深厚的感情,是小说中的主要感情线
武功高强,尤其擅长使用重剑,达到了"无剑胜有剑"的境界
人物特点:
性格复杂,既有叛逆的一面,也有侠义之心
武功卓绝,被江湖人士尊称为"神雕侠"
与一只神雕为伴,神雕也帮助他修炼武功
杨过是金庸"射雕三部曲"中的重要人物,形象鲜明,深受读者喜爱。
Agent优化
实际上是对RAG的优化,rag中经常会使用到召回重排来提升回答效果。
在其他条件不变的情况下,使用召回重排的代码如下:
这里示例用的召回重排是用MediumChunk/FineChunk去做的,但是我们一开始建立的数据库是用CoarseChunk去做的,所以再调用的时候会冲突报错,所以需要重新建立一个MediumChunk/FineChunk的本地数据库。
import shutil
from pathlib import Path
import lazyllm
from lazyllm import Document, Retriever, OnlineEmbeddingModule
from get_api import APIKEY
def main():
# 重建与 jinyong_rag_optimized.py 对应的本地库(kb_store),包含 Medium/Fine 分组
store_dir = Path("kb_store_optimized")
if store_dir.exists():
print(f"[Reset] Removing store dir: {store_dir}")
shutil.rmtree(store_dir, ignore_errors=True)
store_dir.mkdir(parents=True, exist_ok=True)
embed_model = OnlineEmbeddingModule(source='glm', embed_model_name='embedding-2', api_key=APIKEY)
store_conf = {
"vector_store": {
"type": "ChromadbStore",
"kwargs": {"dir": str(store_dir)}
},
"segment_store": {
"type": "MapStore",
"kwargs": {"uri": str(store_dir / "segments.db")}
}
}
# 初始化 Document 并按 Medium/Fine 两种粒度建立索引
doc = Document(dataset_path="data", embed=embed_model, store_conf=store_conf)
retriever_med = Retriever(doc, group_name=Document.MediumChunk, similarity="cosine", topk=3)
retriever_fine = Retriever(doc, group_name=Document.FineChunk, similarity="cosine", topk=3)
# 触发一次检索以确保集合创建完成
_ = retriever_med(query="初始化索引")
_ = retriever_fine(query="初始化索引")
print("[Build] kb_store initialized with MediumChunk and FineChunk indices.")
if __name__ == "__main__":
main()
会出现新的数据库kb_store_optimized
接着再运行具有召回重排的Agent:
import lazyllm
import time
from lazyllm import (
fc_register, Document, Retriever,
OnlineEmbeddingModule, OnlineChatModule, WebModule,
ReactAgent
)
from get_api import APIKEY
# 模型与数据
embed_model = OnlineEmbeddingModule(source='glm', embed_model_name='embedding-2', api_key=APIKEY)
# 与本地持久化配置对齐(kb_store_optimized/)
store_conf = {
"vector_store": {
"type": "ChromadbStore",
"kwargs": {"dir": "kb_store_optimized"}
},
"segment_store": {
"type": "MapStore",
"kwargs": {"uri": "kb_store_optimized/segments.db"}
}
}
doc = Document(dataset_path="data", embed=embed_model, store_conf=store_conf)
# 多粒度召回:中粒度 + 细粒度
retriever_med = Retriever(doc, group_name=Document.MediumChunk, similarity="cosine", topk=8)
retriever_fine = Retriever(doc, group_name=Document.FineChunk, similarity="cosine", topk=12)
def _fuse_nodes(nodes_a, nodes_b, limit=10):
# 简单去重融合:按分数降序,基于 uid 去重
all_nodes = []
seen = set()
for n in list(nodes_a) + list(nodes_b):
uid = getattr(n, "_uid", None) or getattr(n, "uid", None)
if uid in seen:
continue
seen.add(uid)
all_nodes.append(n)
# 如果节点自带 score,按 score 排序;否则保持顺序
try:
all_nodes.sort(key=lambda x: getattr(x, "_score", None) or getattr(x, "score", 0), reverse=True)
except Exception:
pass
return all_nodes[:limit]
# 注册优化版 RAG 工具
@fc_register("tool")
def search_knowledge_base_optimized(query: str):
"""
使用多粒度检索(中粒度+细粒度)并融合结果,从知识库中返回相关内容。
Args:
query (str): 用户的问题或检索词,用于在知识库中查找相关片段。
"""
nodes_med = retriever_med(query=query)
nodes_fine = retriever_fine(query=query)
fused = _fuse_nodes(nodes_med, nodes_fine, limit=10)
context_str = "".join([node.get_content() for node in fused])
return context_str
# prompt 设计
prompt = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions. You can use the search_knowledge_base_optimized tool to find relevant information from the knowledge base.'
# 创建 ReactAgent(沿用 GLM 聊天)
# 终端耗时打印:封装一个带计时的 LLM 包装器
class TimedLLM:
def __init__(self, inner):
self._inner = inner
def prompt(self, *args, **kwargs):
return self._inner.prompt(*args, **kwargs)
def share(self, *args, **kwargs):
self._inner = self._inner.share(*args, **kwargs)
return self
def used_by(self, *args, **kwargs):
self._inner = self._inner.used_by(*args, **kwargs)
return self
def __call__(self, *args, **kwargs):
t0 = time.time()
res = self._inner(*args, **kwargs)
t1 = time.time()
print(f"[Timing] answer: {t1 - t0:.2f}s")
return res
def __getattr__(self, name):
return getattr(self._inner, name)
timed_llm = TimedLLM(OnlineChatModule(source='glm', model='glm-4.5', api_key=APIKEY, stream=False))
agent = ReactAgent(
llm=timed_llm,
tools=['search_knowledge_base_optimized'],
prompt=prompt,
stream=False
)
# Web 服务启动
w = WebModule(agent, stream=False)
w.start().wait()
输出:
耗时:
[Timing] answer: 1.77s
6756: 2025-09-24 17:03:20 lazyllm SUCCESS: (lazyllm.tools.rag.store.vector.chroma_store:97) Initialzed chromadb in path: kb_store_optimized
[Timing] answer: 3.35s
[Timing] answer: 11.55s
根据搜索结果,我现在可以更详细地回答关于杨过的问题了。从搜索到的文本片段中,我可以看到:
杨过是金庸武侠小说《神雕侠侣》中的主要人物
他的名字是郭靖取的,郭靖称呼他为"过儿"
他被称为"神雕侠",因为他一直和神雕为侣
他与小龙女有深厚的感情关系,苦候与小龙女重会之约
他曾漫游四方,行侠仗义
他与郭靖、黄药师等武林高手有关系
他经历了少年风流孽缘,与公孙绿萼、程英、陆无双等女性有感情纠葛
他经常戴着黄药师所制的人皮面具,不以真面目示人
他武功高强,使用重剑
他与独孤前辈(独孤求败)有某种联系
现在我可以给出一个完整的回答。
杨过是金庸武侠小说《神雕侠侣》中的男主角,是金庸笔下最著名的人物之一。
基本信息:
身份:神雕侠,武林中的传奇人物
名字由来:他的名字是郭靖取的,郭靖称呼他为"过儿"
称号:因一直与神雕为侣,闯下了"神雕侠"的名头
人物关系:
师父/长辈:郭靖(义伯父)、黄蓉
爱人:小龙女(与他有着刻骨铭心的爱情故事)
其他重要人物:与程英、陆无双、公孙绿萼等女性有感情纠葛
人物特点:
武功:武功高强,擅长使用重剑,与独孤求败有渊源
性格:少年时飞扬跳脱,中年经历与小龙女分手的痛苦磨练后收敛了许多
行为:行侠仗义,漫游四方,经常戴着黄药师所制的人皮面具,不以真面目示人
故事背景:
杨过在小说中经历了从少年到中年的成长过程,他与小龙女的爱情故事是《神雕侠侣》的核心情节。他苦候与小龙女重会之约,同时行侠仗义,成为武林中受人敬仰的"神雕侠"。
杨过这个人物形象复杂而深刻,既有侠义精神,又有儿女情长,是金庸武侠世界中极具魅力的角色之一。
可以看到耗时相对长些,但是召回重排后的输出还是稍微好一点的。
金庸小说阅读辅助器
当然上述的一个过程还是相对简单的。在正式的应用情况下。我对流程做了改进:
1.增加改写问题的llm和总结的llm,实现多agent协同合作。
2.增加tk编写的界面。
也就是说:用户问题并行走两条路:原始查询检索;用改写模型生成更贴近知识库的新查询再检索。两路检索都用 Medium/Fine 粒度,召回后去重融合,得到更稳的上下文。将“原始问题/回答 + 改写问题/回答”交给总结模型,面向原始问题产出最终答案。
但是说实话这个框架用下来一点都不比langgraph好用,不够灵活。具体总结看最后的内容。此处可以参考我以往的langgrah项目:
从零开始构建Agent(二):Gemini-fullstack-langgraph-quickstart项目,一个很经典的Reflection模型
从零开始构建Agent(三):手搓一个基于langgraph的agent,简略版“Manus”,实现分析文档等小部分功能
辅助阅读器具体代码如下:
import time
import threading
import tkinter as tk
from tkinter import ttk
import lazyllm
from lazyllm import Document, Retriever, OnlineEmbeddingModule, OnlineChatModule
from get_api import APIKEY
# 初始化模型与持久化文档(与 jinyong_rag_optimized.py 保持一致)
embed_model = OnlineEmbeddingModule(source='glm', embed_model_name='embedding-2', api_key=APIKEY)
store_conf = {
"vector_store": {
"type": "ChromadbStore",
"kwargs": {"dir": "kb_store_optimized"}
},
"segment_store": {
"type": "MapStore",
"kwargs": {"uri": "kb_store_optimized/segments.db"}
}
}
doc = Document(dataset_path="data", embed=embed_model, store_conf=store_conf)
retriever_med = Retriever(doc, group_name=Document.MediumChunk, similarity="cosine", topk=8)
retriever_fine = Retriever(doc, group_name=Document.FineChunk, similarity="cosine", topk=12)
def _fuse_nodes(nodes_a, nodes_b, limit=10):
all_nodes = []
seen = set()
for n in list(nodes_a) + list(nodes_b):
uid = getattr(n, "_uid", None) or getattr(n, "uid", None)
if uid in seen: continue
seen.add(uid)
all_nodes.append(n)
try:
all_nodes.sort(key=lambda x: getattr(x, "_score", None) or getattr(x, "score", 0), reverse=True)
except Exception:
pass
return all_nodes[:limit]
chat = OnlineChatModule(source='glm', model='glm-4.5', api_key=APIKEY, stream=False)
base_instruction = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions.'
chat.prompt(lazyllm.ChatPrompter(instruction=base_instruction, extra_keys=['context_str']))
rewrite_chat = OnlineChatModule(source='glm', model='glm-4.5', api_key=APIKEY, stream=False)
rewrite_instruction = (
'你是查询改写助手。已知本系统的知识库主要包含金庸小说(如神雕侠侣)原文片段、人物、情节、武学与设定等内容。'
'请根据用户的问题,改写出一个更贴近上述知识库、便于检索命中的中文查询,保持语义一致但更具体、更聚焦。'
'只输出改写后的中文查询,不要输出其他说明。'
)
summarize_chat = OnlineChatModule(source='glm', model='glm-4.5', api_key=APIKEY, stream=False)
summarize_instruction = (
'你是总结助手。现在有用户的原始问题与其回答,以及一个改写后的问题与其回答。'
'请依据两份回答中的证据,面向原始问题给出简洁、直接、可信的中文答案;若有引用冲突,以与原文更一致者为准。'
)
def ask_query(query: str) -> str:
t0 = time.time()
nodes_med = retriever_med(query=query)
nodes_fine = retriever_fine(query=query)
fused = _fuse_nodes(nodes_med, nodes_fine, limit=10)
ctx = "".join([n.get_content() for n in fused])
t1 = time.time()
ans = chat({"query": query, "context_str": ctx})
t2 = time.time()
print(f"[Timing] retrieve(med+fine+fuse): {t1 - t0:.2f}s, answer: {t2 - t1:.2f}s, total: {t2 - t0:.2f}s")
return str(ans)
# Tk 界面
root = tk.Tk()
root.title("金庸小说辅助阅读器 - Tk")
root.geometry("800x600")
frm_top = ttk.Frame(root)
frm_top.pack(fill=tk.X, padx=10, pady=10)
lbl = ttk.Label(frm_top, text="输入问题:")
lbl.pack(side=tk.LEFT)
query_var = tk.StringVar()
entry = ttk.Entry(frm_top, textvariable=query_var, width=80)
entry.pack(side=tk.LEFT, padx=8)
btn = ttk.Button(frm_top, text="提问")
btn.pack(side=tk.LEFT)
txt = tk.Text(root, wrap=tk.WORD)
txt.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
def on_ask_clicked():
q = query_var.get().strip()
if not q:
return
txt.delete(1.0, tk.END)
txt.insert(tk.END, "思考中,请稍候...\n")
def worker():
try:
res = ask_query(q)
# 直接以字符串形式调用,避免 provider 对参数键的要求
rewrite_input = (
f"{rewrite_instruction}\n"
f"用户问题: {q}\n"
f"只输出改写后的查询。"
)
rewrite_query = str(rewrite_chat(rewrite_input)).strip()
res_rewrite = ask_query(rewrite_query or q)
summarize_input = (
f"{summarize_instruction}\n"
f"原始问题: {q}\n"
f"原始回答: {str(res)}\n"
f"改写问题: {rewrite_query}\n"
f"改写回答: {str(res_rewrite)}\n"
f"请基于证据给出最终答案:"
)
res_summarize = summarize_chat(summarize_input)
print("res",res)
print("rewrite_query",rewrite_query)
print("res_rewrite",res_rewrite)
print("res_summarize",res_summarize)
except Exception as e:
res_summarize = f"发生错误:{e}"
def update():
txt.delete(1.0, tk.END)
txt.insert(tk.END, res_summarize)
root.after(0, update)
threading.Thread(target=worker, daemon=True).start()
btn.configure(command=on_ask_clicked)
entry.bind('<Return>', lambda e: on_ask_clicked())
root.mainloop()
这里的话其实可以针对prompt再进行优化,由于时间关系我主要是介绍流程和思路。
github项目地址:https://github.com/1105425455/LazyLLMAgent/tree/master。
具体可看readme执行项目内容。
结果展示:

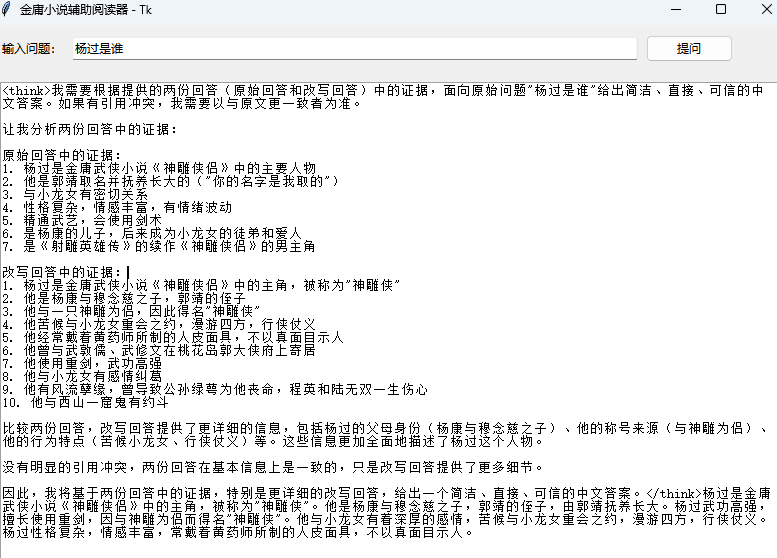
总体来说可以实现辅助阅读器。效果依据上面看下来还是很不错的,耗时上面也ok。项目的意义是当阅读的小说过多时,就可以利用辅助阅读器查询一些不太记得的内容。当然具体的效果跟所用的大模型和prompt也有很大的关系,可以根据个人需要去进行改动。
结论
这个框架确实搭建项目非常的简单和快,一个 OnlineChatModule 搭模型,一个 OnlineEmbeddingModule 搭向量,一个 Document + Retriever 就能把 RAG 跑起来。且支持多个供应商, SenseNova、GLM、Qwen、OpenAI、Doubao 等。同时自带常见文档读取器(md/pdf/csv/图片等)、分块、检索相似度、Prompt 拼接;还支持持久化向量库(如 Chroma)与段落库(SQLite)。
不足:极复杂流程的可视化编排与可恢复能力,LangGraph 应该做得更专业。同样的重写问题+总结流程用langgraph可以实现得更丝滑;这方面还是用langgraph感觉好点。而超大生态集成(数据库、工具、向量库、评测、观测)还是 LangChain 更全面。需要“任意组合”的特殊链路时,LazyLLM 的“套餐式”会显得不够自由。但是还是一个很好上手的框架的。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)