
爬虫学习笔记
1、基本请求(1)requests.get()参数的url需要加上http(2)response.ok可以查看返回的状态(3)response.text可以查看返回报文体2、加入请求头,伪装成浏览器访问,防止网站不响应爬虫(1)user-agent获取:3、提取书本价格(1)BeautifulSoup可以让返回的content成树状结构,使得查找方便(2)4、爬取所有书名(1)可以使用网站浏览书名
一、爬虫入门
1、基本请求
import requests
response = requests.get("http://books.toscrape.com/")
if response.ok:
print(response.text)
else:
print("请求失败")(1)requests.get()参数的url需要加上http
(2)response.ok可以查看返回的状态
(3)response.text可以查看返回报文体
2、加入请求头,伪装成浏览器访问,防止网站不响应爬虫
import requests
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0"
}
response = requests.get("https://movie.douban.com/top250/",headers=headers)
print(response.status_code)(1)user-agent获取:
3、提取书本价格
import requests
from bs4 import BeautifulSoup
content = requests.get("https://books.toscrape.com/").text
soup = BeautifulSoup(content,"html.parser")
all_prices = soup.findAll("p",attrs = {"class":"price_color"})
for price in all_prices:
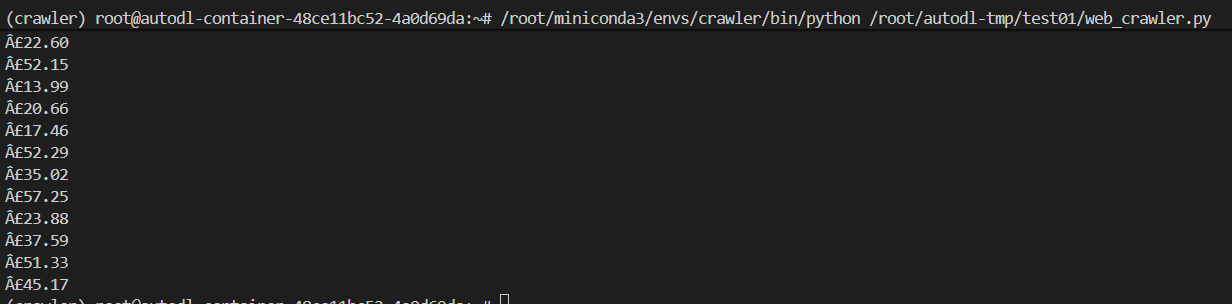
print(price.string)(1)BeautifulSoup可以让返回的content成树状结构,使得查找方便
(2)
4、爬取所有书名
import requests
from bs4 import BeautifulSoup
content = requests.get("https://books.toscrape.com/").text
soup = BeautifulSoup(content,"html.parser")
all_titles = soup.findAll("h3")
for title in all_titles:
all_links = title.find("a")
print(all_links.string)(1)可以使用网站浏览书名在哪个位置
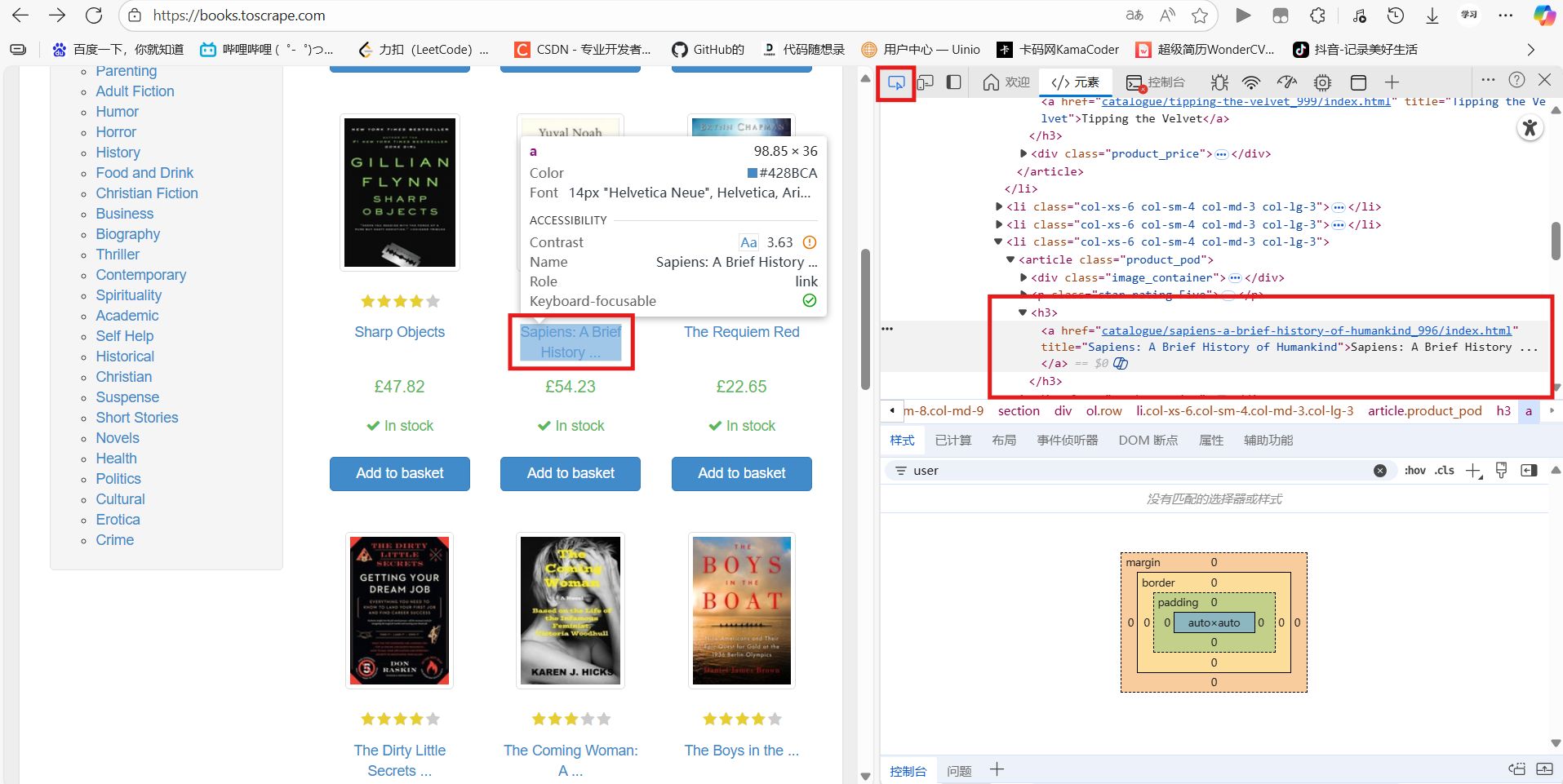
5、爬取豆瓣电影top250
import requests
from bs4 import BeautifulSoup
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)
html = response.text
soup = BeautifulSoup(html,"html.parser")
all_titles = soup.findAll("span",attrs={"class":"title"})
for title in all_titles:
title_string = title.string
if "/" not in title_string:
print(title_string)(1)用for循环一页一页的爬取
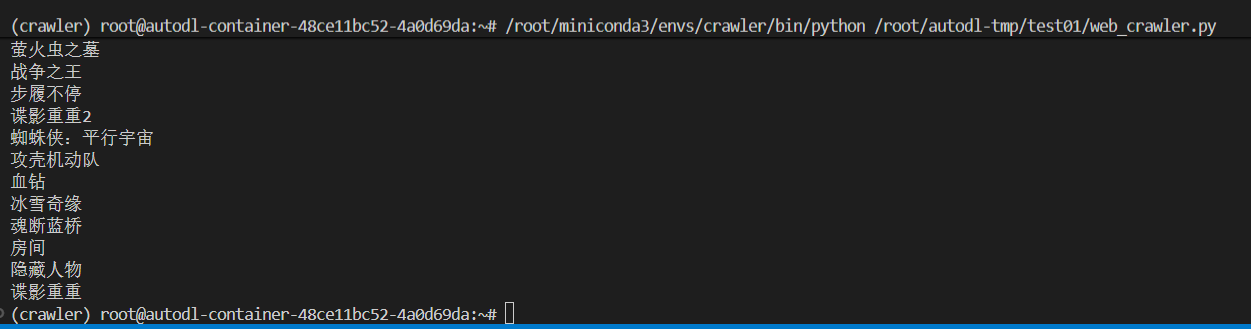
二、scrapy框架
1、基本架构
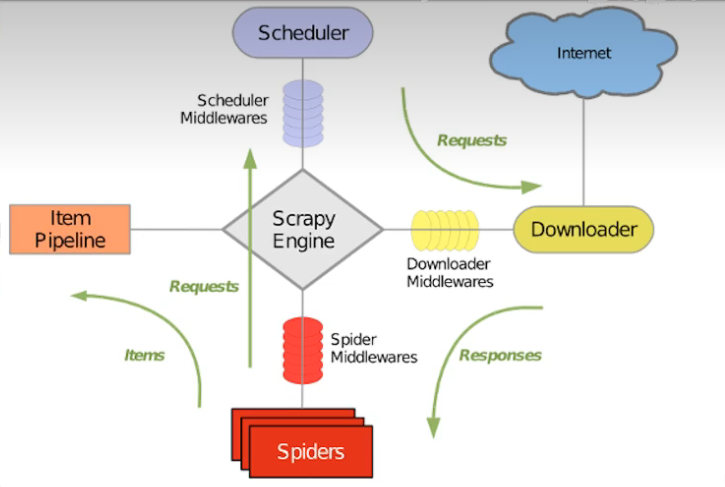
2、schedule可以理解为url的队列,根据url发送请求到Downloader,Downloader回复响应给Spider,Spider再将下一个url送给schedule,同时也会返回处理好的数据给pipeline
三、scrapy爬取信息
1、创建项目
scrapy startproject DoubanMovie2、数据建模
import scrapy
class DoubanmovieItem(scrapy.Item):
# 排名
ranking = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 评分
score = scrapy.Field()
# 评论人数
score_num = scrapy.Field()3、创建爬虫文件
cd DoubanMovie
scrapy genspider douban movie.douban.com/top2504、编辑爬虫
import scrapy
from DoubanMovie.items import DoubanmovieItem
from scrapy import Request
class DoubanSpider(scrapy.Spider):
name = "douban"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0"
}
def start_requests(self):
url = "https://movie.douban.com/top250"
yield Request(url, headers=self.headers)
def parse(self, response):
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item = DoubanmovieItem() # 需要在循环里面创建实例,否在会在同一个实例反复写入
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="bd"]/div/span[2]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="bd"]/div/span[4]/text()'
).extract()[0]
yield item # 输出实例
next_page = response.xpath('//span[@class="next"]/a/@href').get() #翻页
if next_page:
next_url = response.urljoin(next_page)
yield Request(next_url, headers=self.headers, callback=self.parse)
5、运行爬虫
scrapy crawl douabn -o douban.csv输出为csv
6、输出结果
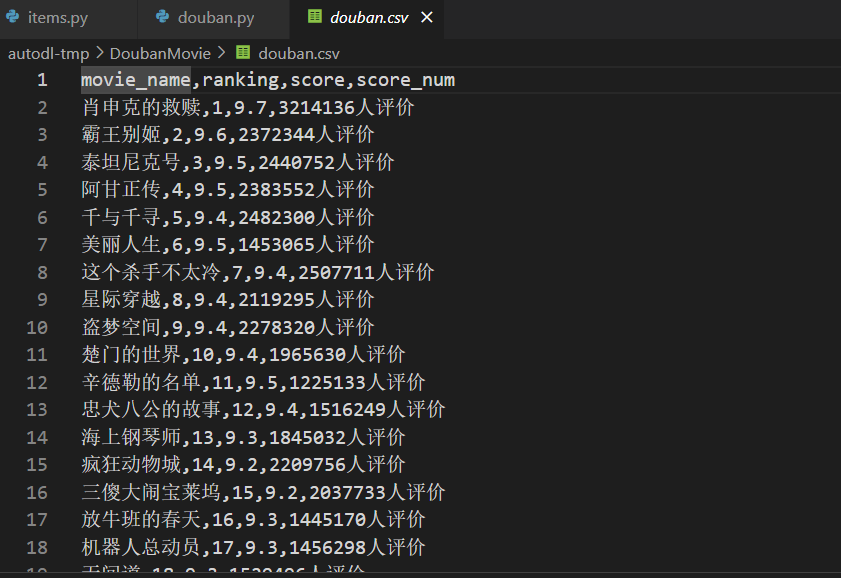
参考资料:(冒死上传)50分钟超快速入门Python爬虫 | 动画教学【2025新版】【自学Python爬虫教程】【零基础爬虫】_哔哩哔哩_bilibili
【scrapy爬虫框架】python爬虫最强框架——scrapy它来啦,学会了它爬什么都超简单!全程干货无废话,小白零基础教程,有手就会!!_哔哩哔哩_bilibili
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)