AI Agent学习
Agent =它会思考、会自己用工具、会执行。
📘 AI Agent 学习整理笔记
1. 基础概念
1.1 Agent 的定义
Agent = AI大模型(大脑) + 工具(手脚) + 自主行动(执行力)
它会思考、会自己用工具、会执行。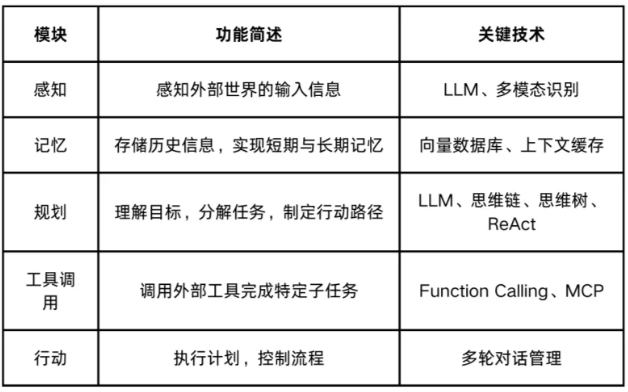
AI Agent 的核心循环:
- 接收目标(任务目标)
- 观察环境(感知当前状态)
- 规划行动(决定下一步)
- 执行行动(调用工具或API)
- 观察结果(评估效果)
- 调整策略(根据反馈优化)
→ 直到目标达成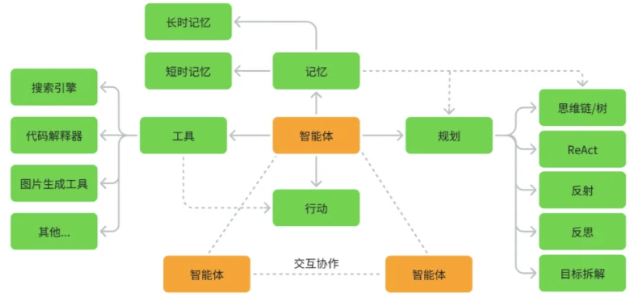
1.2 LLM(Large Language Model,大模型)
- 负责思考、推理、决策
- 优势:通用性强,能调用工具,具备上下文理解
- 限制:知识局限性、幻觉问题、数据安全风险
2. Agent 的关键能力
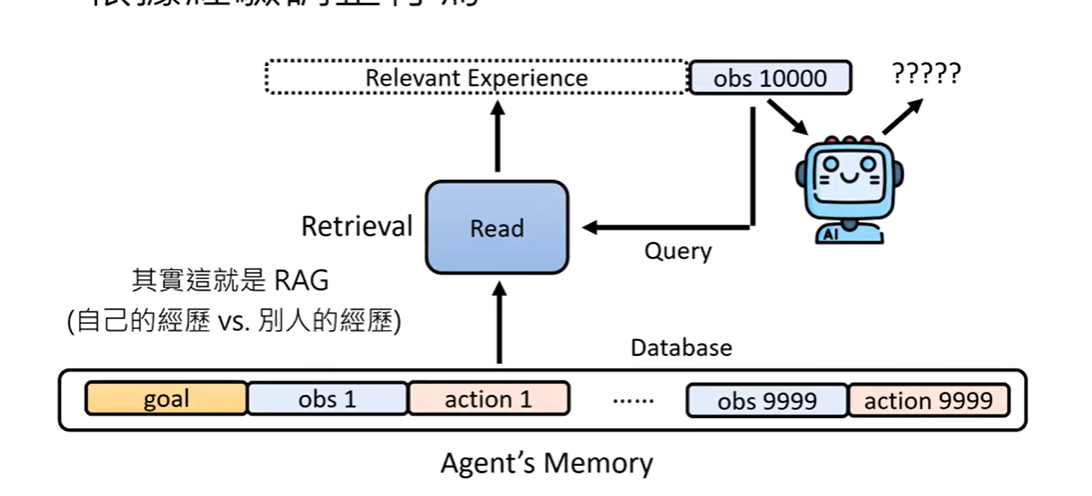
2.1 根据经验调整行为
-
上下文学习(In-Context Learning)
-
记忆(Memory)
- 短期记忆:当前任务(如正在订酒店)
- 长期记忆:偏好存储(如喜欢五星酒店)
-
反思模块(Reflection):总结、推理得到的经验
-
写入模块(Write):保存关键经验,而非所有信息
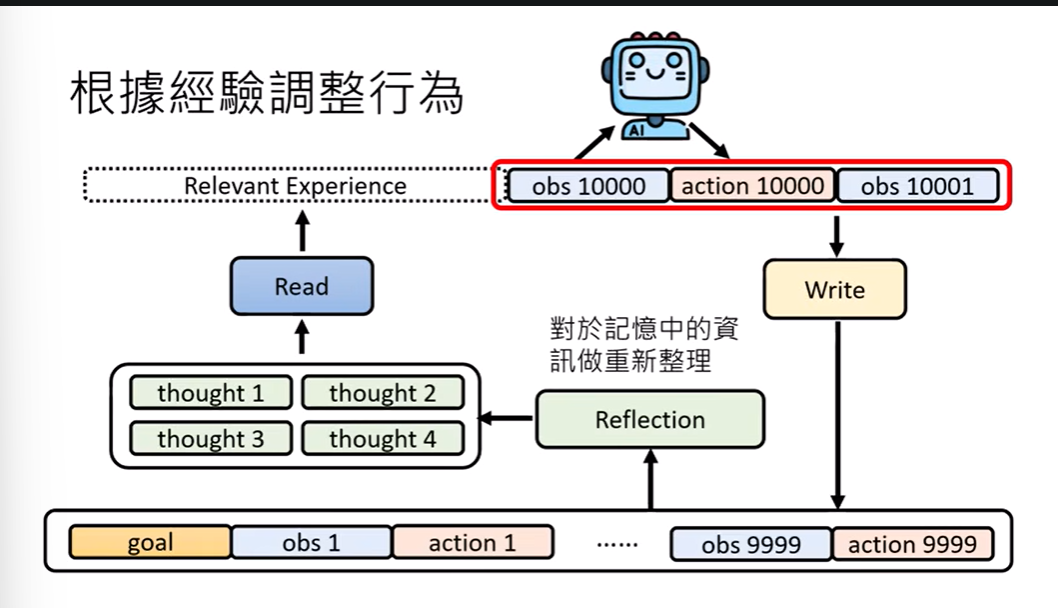
记忆的原则:只记重要的,不记流水账。正面经验比负面经验更有效。
2.2 使用工具
-
工具 = Function,调用工具 = Function Call
-
常见工具:
- 搜索引擎(获取实时信息)
- Python/代码执行器(运行代码)
- API调用(与其他系统交互)
- 数据库查询(检索私域信息)
示例: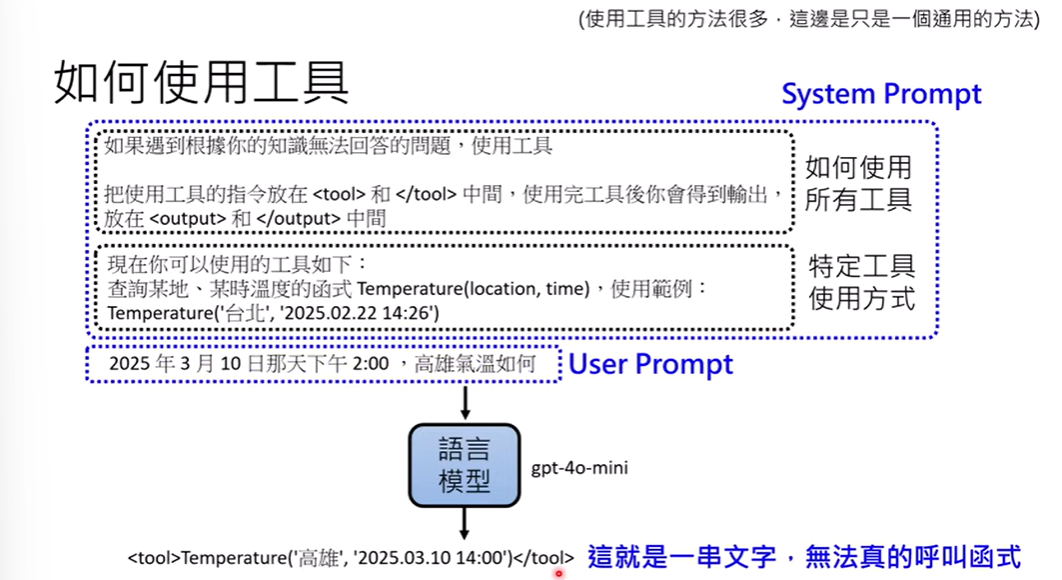
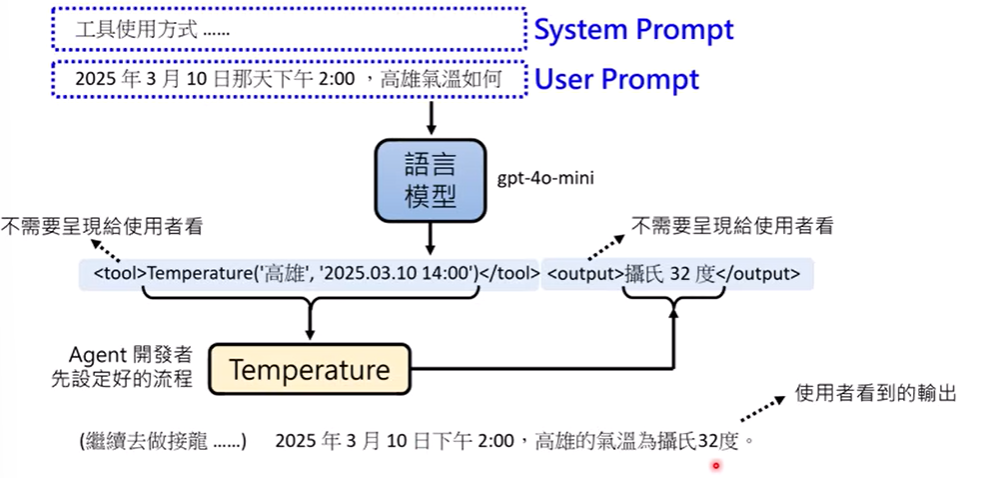
⚠️ 工具可能犯错(如搜索结果不准),Agent 需要具备一定判断力。
2.3 规划能力
- 任务分解:复杂目标 → 子任务
- 路径规划:最佳执行顺序
- 资源分配:合理使用工具
- 错误处理:应对异常情况
3. 提示工程(Prompting 技术)
3.1 零样本提示(Zero-Shot Prompting)
直接让模型执行任务,不提供示例。
适用场景:常见任务、格式明确。
示例:
将以下文本分类为“积极”、“消极”或“中性”。请用一个词给出分类结果。
文本:“这个新功能很棒,但文档可以做得更好。”
3.2 少样本提示(Few-Shot Prompting)
通过示例教学,确保输出格式一致。
适用场景:格式要求高、零样本效果差。
示例:
将以下日期转换为DD-MM-YYYY格式:
输入:2024年3月15日 → 输出:15-03-2024
输入:2023年12月1日 → 输出:01-12-2023
3.3 思维链提示(Chain-of-Thought Prompting)
要求模型逐步推理,像解数学题一样。
适用场景:复杂推理、准确性要求高。
示例:
商店120个苹果,周一卖30%,周二卖剩余的25%,还剩多少?
解法:120 - 36 - 21 = 63 个
3.4 思维树提示(Tree-of-Thought Prompting)
同时探索多条推理路径,评估、修剪保留最优路径。
适用场景:开放式问题、创意探索。
3.5 角色提示(Role Prompting)
让模型以特定身份或视角回答。
适用场景:需要专业知识、换角度思考。
示例:
扮演资深工程师,检查以下代码漏洞:
def process_user_input(input_string):
query = "SELECT * FROM users WHERE id = " + input_string
execute_query(query)
→ 会识别 SQL 注入风险,建议参数化查询。
4. 关键技术与协议
4.1 RAG(Retrieval Augmented Generation,检索增强生成)
= 检索技术 + LLM 提示
-
优势:减少幻觉、支持实时与私域知识
-
工作流程:
- 用户提问
- RAG 检索相关信息
- 把检索结果和问题注入提示
- LLM 生成答案
示例:
问题:“请分析上季度销售数据,找出表现最好的产品线。”
→ Agent 自动:连接数据库 → 清洗数据 → 分析 → 生成可视化报告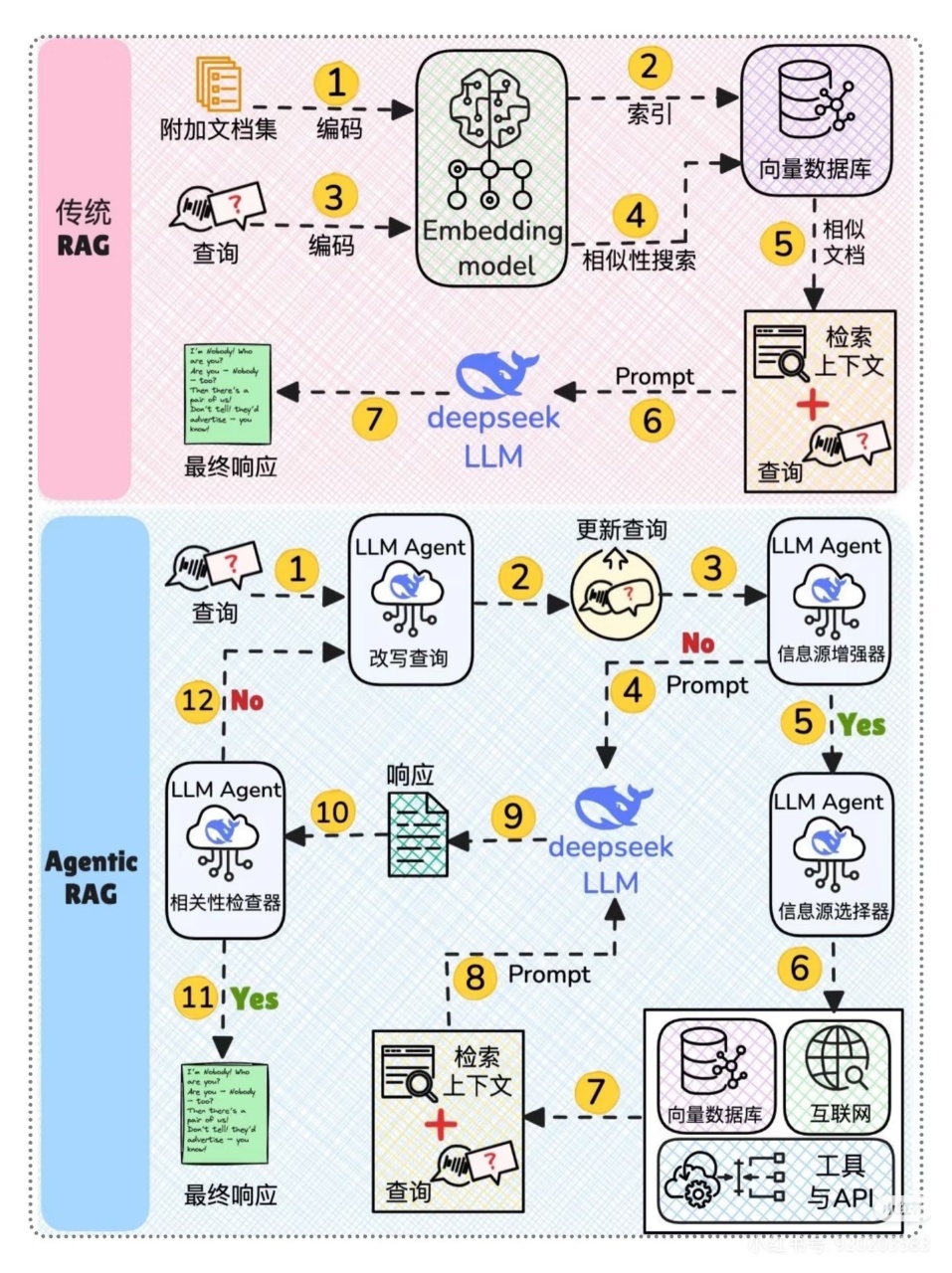
代理RAG通过在每个阶段引入代理来解决这些问题:
步骤1-2: 代理重写查询(修正拼写错误等)
步骤3-8: 代理判断是否需要更多上下文
.
若无需更多上下文,重写后的查询直接发送至大语言模型(LLM)
若需更多上下文,代理寻找最佳外部来源获取上下文,并传递至大语言模型
步骤9: 获得响应
步骤10-12: 代理检查响应是否相关
.
若相关,返回响应
若不相关,返回步骤1
.
这个过程会重复多次,直到系统获得一个满意的响应,或者系统承认无法回答该查询。
由于代理能确保每个单独的步骤都与最终目标保持一致,因此增强了代理RAG的稳健性。
- 传统 RAG 擅长的场景:
1.简单查询任务: 适合处理基于现有文档库的直接查询,如 FAQ 回答或标准文档检索
2.静态知识应用: 适用于信息变化不大的领域,例如法律条款、历史数据或静态教程
3.低复杂度需求: 在需要单一检索和生成响应的场景中表现良好,如基础客户支持或简单数据提取 - 代理 RAG 擅长的场景:
1.复杂查询任务: 适合需要多轮推理或动态信息补充的场景,如研究分析或多步骤问题解决
2.动态信息需求: 适用于需要实时更新或从外部来源获取数据的领域,如新闻总结或市场趋势分析
3.自适应策略: 在需要根据问题调整检索和生成策略的场景中表现优异,例如个性化教育或高级技术支持
4.迭代优化: 适合需要多次验证和改进响应的应用,如法律咨询或深度技术问题解决
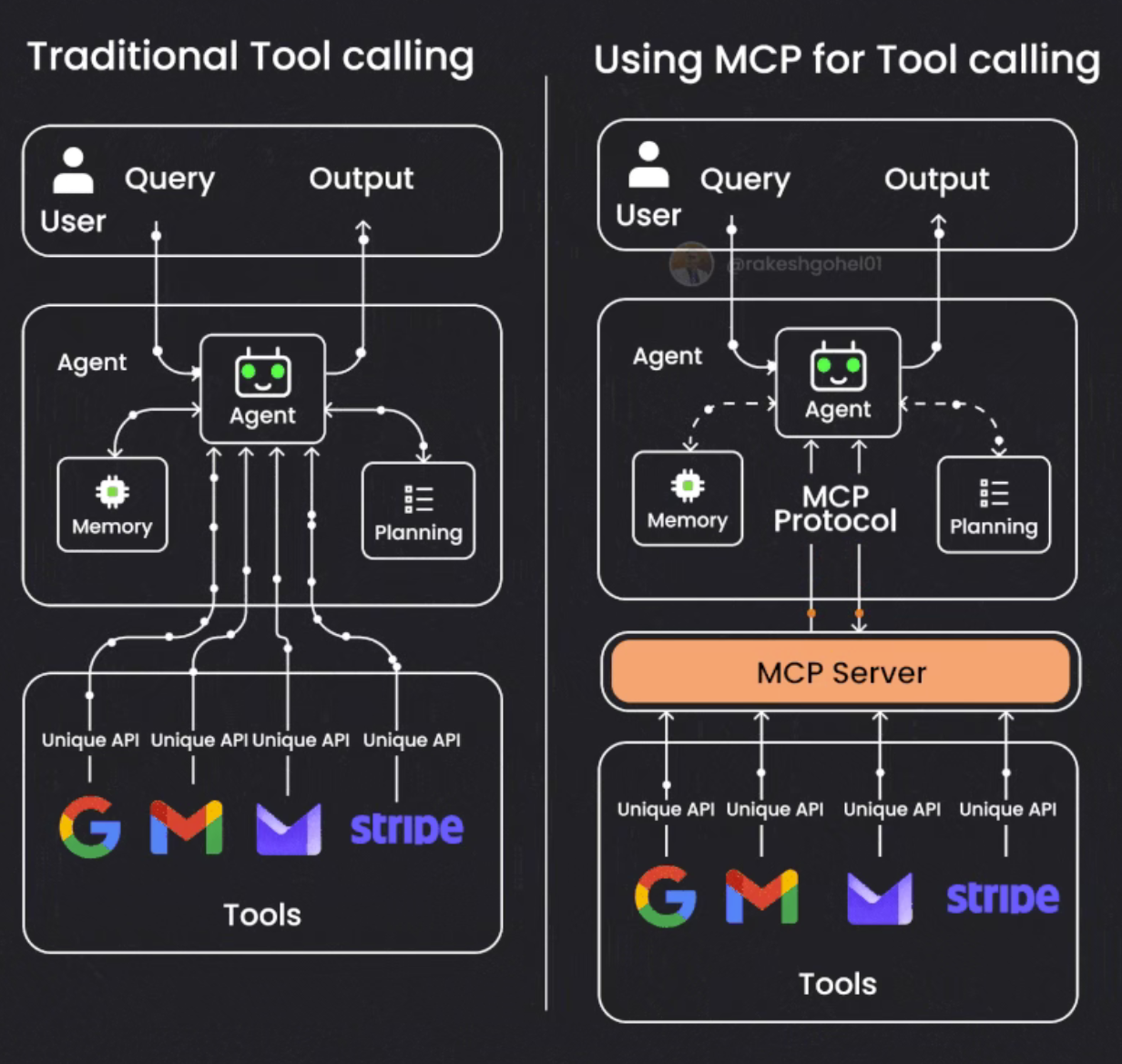
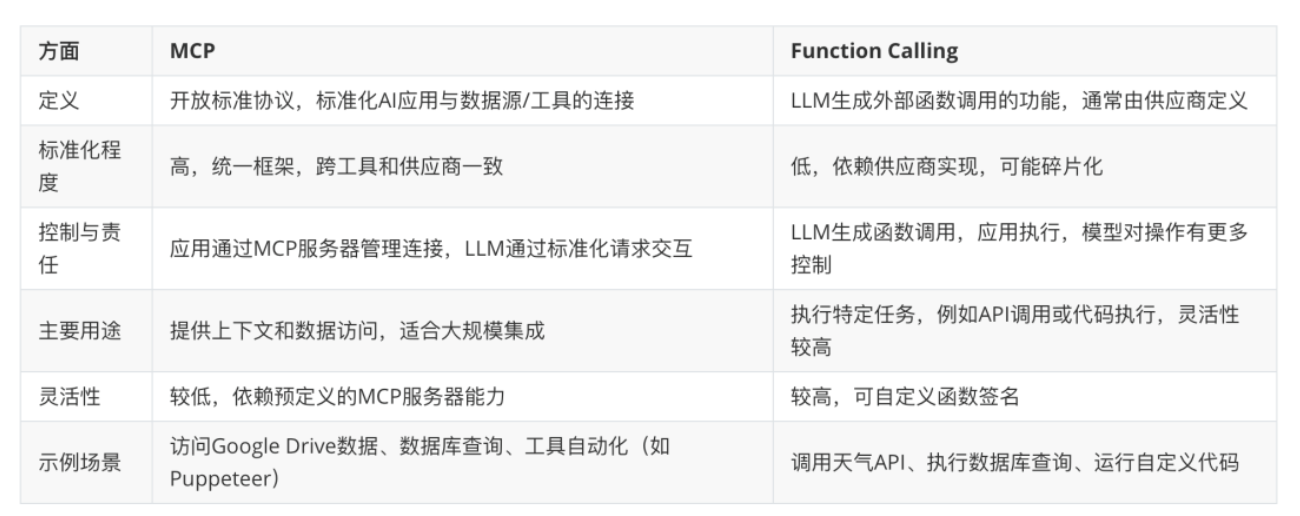
4.2 MCP(Model Context Protocol,模型上下文协议)
- 标准化协议,用于 AI模型与应用程序交换上下文信息
- 目标:简化 AI 应用开发和集成,提升通用性
5. 企业应用场景
- 智能客服:解答问题、处理订单、查询物流
- 数据分析:收集、清洗、分析、生成报告
- 流程自动化:处理重复性任务
- 决策支持:提供数据驱动建议
示例:
企业目标 → “分析上季度销售数据”
Agent → 自动查询数据库、生成报告、可视化结果

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐

 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)