51c大模型~合集177
如图所示,模型推理完成得到的答案是 9,而正确答案是 27。这种 “中间答案” 尽管并不完整和精确,但它们在一定程度上可以代表模型在当前的思考过程,比如两条推理路径得出的中间答案是一样的,我们则可以认为这两条推理路径目前解题的思路和进度是类似的。除此之外,这位拥有超过 33.5 万引用的大佬还是统计学习领域著名的 Vapnik–Chervonenkis 理论的提出者之一 —— 是的,这个理论就是以
我自己的原文哦~ https://blog.51cto.com/whaosoft/14154064
#公开V3/R1训练全部细节!
刚刚,DeepSeek最新发文,回应国家新规
AI 生成的内容该不该打上“水印”?网信办《合成内容标识方法》正式生效后,DeepSeek 率先做出回应:以后凡是 AI 生成的内容,都会明确标注,并同步公开了《模型原理与训练方法说明》。
网信办发布的《人工智能生成合成内容标识办法》已正式生效。
其中,第四条要求:对符合要求的AI生成合成内容添加显式标识。
刚刚,DeepSeek 官微发布了最新回应公告——凡是 AI 生成的内容,都会清楚标注「AI 生成」。
它还郑重提醒,用户严禁恶意删除、篡改、隐匿标识,更别提用 AI 传播、制作虚假信息。

此外,这次还发布了《模型原理与训练方法说明》,可以一瞥 DeepSeek 的技术路径。
接下来,深入探索一下 DeepSeek V3/R1 的一些训练细节。

文档链接:https://cdn.deepseek.com/policies/zh-CN/model-algorithm-disclosure.html
01 回应新要求,DeepSeek公开技术说明
DeepSeek 主要介绍了大模型的训练和推理阶段,包括预训练、优化训练(微调)以及训练数据等。

不同大模型的神经网络架构
1. 模型训练
模型训练阶段即模型的开发阶段:通过设计好的深度神经网络架构和训练方法,开发人员开发出可被部署使用的模型。
模型由多层神经网络组成,不同的架构直接影响模型的性能。此外,模型性能也受参数规模的制约,而训练的目的就是找到具体的参数值。
目前,大模型的参数规模数以亿计。最新的 DeepSeek-V3-0324,参数总量为 6850 亿。
在训练过程中,这些参数通过梯度下降算法迭代优化。
这次,DeepSeek 把模型训练分为预训练和优化训练两个环节。
预训练:预训练目标是通过数据训练模型,使模型掌握通用的语言理解与生成能力。
优化训练:也称为微调,是在预训练模型的基础上通过特定任务的数据进一步调整模型参数,使模型适应实际应用场景。
在预训练阶段,模型通过大规模自监督学习,从文本数据中学习语言模式与知识关联。预训练完成后,模型能理解并生成连贯的文本,但还不会精准地回答问题或执行任务,因此需要进一步的训练微调。
在优化训练阶段,模型一般通过 SFT、RL 等方法,学会根据指令回答问题,符合人类的偏好和需求,并激发在特定领域的专业能力。
经过优化训练的模型能更好地满足实际需求,可被部署使用。
02 DeepSeek的训练过程
DeepSeek 模型的能力,是建立在高质量、大规模、多样化的数据之上。
在「预训练阶段」和「优化训练阶段」,各有不同。
1. 预训练阶段
在预训练阶段,主要使用了两类数据:
互联网公开可用的信息,比如网页、公开文档等。
与第三方合作获取许可的数据需要强调的是,在此阶段,根本无需获取个人信息用于训练,DeepSeek 不会有意关联至任何特定账户和个人,更不会主动将其用于训练模型。
不过,预训练数据规模过于庞大,可能偶然包含了一些个人信息。
对此,DeepSeek 会通过技术手段,尽力筛查并移除这些信息,确保数据「干干净净」。
为了保证数据质量、安全、多样,他们还打造了一套硬核数据治理流程——
首先,通过「过滤器」自动剔除仇恨言论、色情低俗、暴力、垃圾信息,以及可能侵权的原始数据。
其次,通过算法+人工审核,识别并降低数据中的统计性偏见,让模型更公平、更客观。
2. 优化训练阶段
到了优化训练阶段,一般需要通过人工或自动化的方式构造、标注一批问答对数据来对模型进行训练。
DeepSeek 这次表示:这些问答对数据是由研究团队生成提供的,其中少部分数据的构造可能会基于用户的输入。
在 DeepSeek-R1 训练中,研究人员直接提示模型生成包含反思和验证的详细答案;收集并整理 DeepSeek-R1-Zero 的输出,使其具有可读性;以及通过人工注释者的后期处理来提高数据质量
如涉及利用用户的输入构造训练数据,DeepSeek 会对数据进行安全加密技术处理、严格的去标识化和匿名化处理,从而尽可能避免训练数据关联到任何特定个人,且不会在模型给其他用户的输出中带有个人信息,更不会将其用于用户画像或个性化推荐。
同时,DeepSeek 为用户提供了选择退出的权利。
为了确保模型的安全性,在模型优化训练阶段,DeepSeek 构造了专门的安全数据对模型进行安全对齐,教会模型的回复符合人类的价值观,增强模型内生的安全能力。
3. 模型推理
模型的推理阶段即模型被部署提供服务。
模型训练完成并被部署后,可以通过对输入信息进行编码和计算来预测下一个 token,从而具备文本生成和对话等能力。
部署后的模型能够熟练执行基于文本生成的广泛多样的任务,并可以集成到各种下游系统或应用中。
具体到 DeepSeek 的产品服务,基于用户的输入,模型采用自回归生成方式,基于输入的上下文内容,通过概率计算预测最可能的接续词汇序列。
推理完成后,模型输出相应的内容作为响应,包括文字、表格和代码等。
此并非简单检索或「复制粘贴」训练数据中的原始文本,模型也并未存储用于训练的原始文本数据副本,而是基于对语言结构和语义关系的深度理解,动态生成符合语境的回答。
DeepSeek 这次还强调模型开源。
我们通过开源平台对外公开发布了所有模型的权重、参数以及推理工具代码等,并采用宽松的 MIT 协议,供使用者自由、免费下载部署使用。
同时,DeepSeek 发布各模型的完整技术报告,供社区和研究人员参考,并帮助公众更深入地了解每个模型的技术原理和细节。
03 全周期对抗LLM的局限性和风险
毋庸置疑,当前 AI 发展还在早期阶段,存在无法避免的局限性。
若是再被加以滥用,将会带来严重的后果。
1. 局限性
AI 往往会生成错误、遗漏,或不符合事实的内容,这种现象统一称之为「幻觉」。
这个问题,是整个 AI 行业面临的挑战。
对此,DeepSeek 正通过一些技术手段降低幻觉率,包括高质量的训练数据、优化对齐策略、RAG等,但现阶段依无法完全消灭。
同时,他们还在欢迎页、生成文本的末尾,以及交互界面底部,添加显著的提示标识。
特别提醒用户——内容由人工智能生成,可能不准确。
因此,AI 生成的内容仅供参考,所有人不应将输出的内容作为专业建议。
尤其是,在医疗、法律、金融等专业领域,DeepSeek 不提供任何建议或承诺,专业的事儿还得找专业的人。
2.滥用风险
AI 技术本身是中立的,但滥用可能带来隐私保护、版权、数据安全、内容安全、偏见歧视等风险。
DeepSeek 对此也是高度重视,采取了一系列硬核措施,贯穿了模型研发、训练、部署的全生命周期。
制定内部风险管理制度
开展模型安全性评估
进行红队测试
增强模型和服务透明度等
更重要的是,DeepSeek 还赋予了用户知情权、选择权、控制权——
你可以查询服务的基本信息、拒绝其数据用于模型训练、删除其历史数据等。
参考资料:
2. DeepSeek 关于 AI 生成合成内容标识的公告
.....
#TimeLens
重新定义视频大模型时序定位!南大腾讯联合提出TimeLens,数据+算法全方位升级
随着多模态大模型(MLLMs)的飞速发展,模型已经能够很好地理解视频中 “发生了什么(What)”,却无法精准地定位到事件在视频中 “何时发生(When)”。这种视频时序定位(Video Temporal Grounding, VTG)能力的严重缺陷,已成为制约 MLLM 迈向更精细化的视频理解的主要瓶颈。
长期以来,大量研究致力于设计复杂的模型结构,却忽视了两个关键问题:在数据层面,我们依赖的评测基准是否可靠?在算法层面,是否存在一套简洁通用的最佳实践?
针对上述痛点,来自南京大学、腾讯 ARC Lab 和上海 AI Lab 的联合研究团队提出了 TimeLens(时间透镜),系统性地揭示了现有数据的“评测陷阱”,构建出更可靠的评测基准和高质量训练数据,并探索出一套简洁有效的算法优化。得益于这些贡献,仅 8B 参数的 TimeLens 模型成为了开源模型中的新 SOTA,更击败了 GPT-5 和 Gemini-2.5-Flash 等闭源巨头。

- 论文标题:TimeLens: Rethinking Video Temporal Grounding with Multimodal LLMs
- 论文链接: https://arxiv.org/abs/2512.14698
- 项目主页: https://timelens-arc-lab.github.io/
- 代码链接: https://github.com/TencentARC/TimeLens
核心洞察:拨开数据质量的迷雾
在深度学习中,“Data is fuel”(数据即燃料)是公认的真理。然而,团队发现,在 VTG 领域,燃料的质量却令人担忧。
1. 现有基准的 “隐形陷阱”
研究团队通过一套标注流水线,对 Charades-STA、ActivityNet Captions 和 QVHighlights 等主流基准进行了严格的人工核验,发现这些基准数据集中充斥着大量的标注错误。许多样本中的文本描述模糊不清,或是文本描述的事件在视频中根本未出现。标注方面,也存在大量的时间边界标注错误,或是同一描述对应了视频中的多个片段却只标注了其中之一(漏标)。统计数据显示,这些错误在现有基准中的比例极高。


2. TimeLens-Bench:对评估结果的“拨乱反正”
为了解决现有数据集中存在的严重错误,团队构建了严格的标注准则,对上述三个基准数据集进行了全面的修复和重新标注,推出了 TimeLens-Bench。这是一个经过严格交叉验证的高质量评测基准,能够更真实地反映模型的时序定位能力。
将 TimeLens-Bench 和原始 Benchmark 上的评测结果进行对比,揭露了过往评估结果的不可靠 —— 旧基准严重高估了开源模型的能力,而掩盖了前沿闭源模型(如 Gemini)的真实水平。TimeLens-Bench 对这一错误进行了拨乱反正,事实上,现有开源模型仍明显落后于闭源模型。

3. 高质量训练数据:TimeLens-100K
针对同样低质量的训练数据,团队设计了一套自动化流水线,对训练数据进行了大规模的清洗和重标,发布了高质量的大型训练数据集 TimeLens-100K。实验证明,数据质量的提升能带来显著的性能增长。

算法设计的“最佳实践”
在夯实数据基础后,TimeLens 进一步对 MLLM 在 VTG 任务上的算法设计进行了全方位的消融实验,从时间戳编码到训练范式,总结出一套简洁有效的 “最佳实践”。
1. 简洁有效的时间戳编码
时间戳编码(timestamp encoding)是 VTG 任务中的关键模型结构设计,决定了模型能否准确地感知到输入的每一视频帧的采样时间。
团队全面地对比了各种时间戳编码方式的优劣。实验结果表明,最优的时间戳编码方式是简单的交错文本编码(Interleaved Textual Encoding) 策略,即在每一帧的视觉 Token 前插入文本形式的时间戳 token。这种方法无需修改 LLM 的底层架构,保证了实现上的简洁,同时还能取得最优的效果。


2. 训练范式:Thinking-free RLVR 的胜利
随着 DeepSeek-R1 等一系列工作的提出,带有可验证奖励机制的强化学习(RLVR)范式在提升模型推理能力方面的作用备受关注。而在 VTG 领域,关于训练范式的几个关键问题尚无定论:
- 有监督微调(SFT)仍是 VTG 领域最为主流的训练范式,RLVR 范式在同样的训练开销下,是否明显优于 SFT?
- 时序定位任务是一个以感知 (Perception) 而非推理 (Reasoning) 为主的任务。针对这样的任务进行 RLVR 训练时,显式的思考过程(thinking)是否是必须的?
- SFT+RLVR 的多阶段训练,是否比单阶段训练的效果更好?
TimeLens 对比了多种训练范式的优劣。结论出人意料且极具启发性:单阶段的 Thinking-free RLVR 训练范式在计算效率和性能上均取得了最优。该范式直接让模型输出定位结果,并根据定位准确率(IoU)给予奖励。这种方式不需要生成冗长的中间思考过程,训练和推理效率高于 Thinking-based RLVR 范式和多阶段训练范式,且性能优于 SFT 范式。
这一结果表明,对于时序定位这种偏向感知(Perception-heavy)的任务,显式的思考过程不是必须的。 模型可以直接学习从任务输入到输出的映射,不需要进行复杂的逻辑推理。

3. 关键训练技巧:Early Stopping 与 Difficulty-based Sampling
针对 Thinking-free RLVR 范式,团队进行了更加深入的实验探究,发现了两个关键的训练技巧。
首先,与 SFT 中 “训练越久越好” 的共识不同,在 RL 训练中,当奖励指标进入平台期后,就应该采用早停策略(Early Stopping) 立即停止训练,在该阶段之后继续训练反而会使得模型的性能下降。
其次,基于难度的数据采样(Difficulty-based Sampling) 至关重要。即使数据的标注质量有保证,也并非所有的数据都适合用于 RLVR 训练。需要预先使用待训练的模型进行推理,评估每个训练样本的难度,采样足够具有挑战性的样本进行 RLVR 训练,才能最大程度上提升模型的性能。

实验验证:8B 模型逆袭闭源巨头
研究团队将上述数据和算法层面的所有改进聚合在了一起,每一项技术都带来了明显的性能提升,最终得到了 TimeLens 系列模型。

评测结果表明,TimeLens-8B 展现出了惊人的性能,不仅大幅超越了 Qwen3-VL 等开源模型成为新的开源 SOTA,更以 8B 的参数量,在多项核心指标上全面击败了 GPT-5 和 Gemini-2.5-Flash 等前沿的闭源模型。

这一结果有力地证明了:在 VTG 任务中,通过系统性地提升数据质量并采用有效的算法设计,开源小尺寸模型完全具备挑战甚至超越闭源大模型的能力。
总结
TimeLens 的贡献不止于一个 SOTA 开源模型。团队在数据和算法双维度的系统性探索,为后续研究提供了极具参考价值的方法论与设计蓝图。
目前,TimeLens 的代码、模型、训练数据和评测基准都已开源,希望能为未来的视频时序定位研究提供一个更好的起点。
.....
#Decoupling the "What" and "Where" With Polar Coordinate Positional Embeddings
LSTM之父率队造出PoPE:终结RoPE泛化难题,实现Transformer的极坐标进化
Transformer 架构中的注意力机制是根据内容(what)和序列中的位置(where)将键(key)与查询(query)进行匹配。
而在近期 LSTM 之父 Jürgen Schmidhuber 的 USI & SUPSI 瑞士 AI 实验室团队的一项新研究中,分析表明,当前流行的旋转位置嵌入(RoPE)方法中的 what 与 where 是纠缠在一起的。这种纠缠会损害模型性能,特别是当决策需要对这两个因素进行独立匹配时。
基于这一观察,他们提出了新的方案:极坐标位置嵌入(Polar Coordinate Position Embedding ),简称 PoPE。

该团队表示,PoPE 消除了内容与位置的混淆,使得其在需要仅通过位置或仅通过内容进行索引的诊断任务上表现远优于 RoPE。
- 论文标题:Decoupling the "What" and "Where" With Polar Coordinate Positional Embeddings
- 论文地址:https://arxiv.org/abs/2509.10534
该论文的一作为 Anand Gopalakrishnan,目前正在哈佛大学从事博士后研究,曾是 Jürgen Schmidhuber 的博士生。参与者中还有 OpenAI 的研究科学家 Róbert Csordás,以及科罗拉多大学计算机科学系教授 Michael C. Mozer(目前已加入谷歌 DeepMind)。
RoPE 的问题
在许多前沿模型中,为了将位置信息纳入进来,RoPE 是首选方法,包括 Llama 3、DeepSeek-v3、Gemma 3 和 Qwen3。它会为每个查询-键对生成注意力分数,该分数基于它们的匹配程度及其在输入序列中的相对位置。
为了更好地理解 RoPE,这里以特定层中的特定注意力头进行说明。该注意力头的作用是执行位置 t 的查询 q_t 与位置 s 的键 k_s 之间的匹配。键和查询是 d 维向量,被划分为 d/2 个二维分量。
这里用 q_tc 和 k_sc 分别表示查询和键的分量 c∈{1,...,d/2}。RoPE 首先在 2D 平面中将每个分量 c 旋转一个与位置成正比的角度。如果 R (Φ) 是执行角度 Φ 旋转的 2×2 矩阵,则旋转后的查询和键分别为 R (tθ_c) q_tc 和 R (sθ_c) k_sc,其中 θ_c 是分量特定的基波波长(base wavelength):

。下图展示了查询(或键)分量的构成及其在二维空间中的旋转方式。

对应的键和查询分量通过点积匹配并求和以获得注意力分数:

将分量对齐的旋转仅取决于键和查询的相对位置,而不取决于它们的绝对位置。
如果将键和查询分量从笛卡尔坐标重新表示为极坐标:

由此,注意力分数可写为:

这清楚地表明,嵌入的每个双元素分量都被转换为单个幅值,并且通过 Φ_{q_tc} 和 Φ_{k_sc} 引入了对产生最大响应的相对位置(相位)的调整。因此,键和查询都混淆了关于特征存在与否的信息(what)和相对位置(where)。
该团队的假设是,通过解耦这两类不同的信息,特别是通过消除交互项 ,可以提高模型性能。
解决方案:PoPE
在 RoPE 中,该团队将键和查询的 d/2 个分量解释为复数。而在该团队提出的方法中,该团队利用了极坐标表示的另一种形式,称之为极坐标位置嵌入,即 PoPE。
在 PoPE 中,该团队将键和查询转换为相应的 d 元素复向量
![]()
和
![]()
。每个元素 c 的幅值是对原始实值键或查询对应元素的重新缩放:

其中 σ(x)=ln (1+e^x) 表示 softplus 激活函数,确保幅值非负。相位仅取决于位置:

PoPE 的注意力分数定义为:

与 RoPE 相比,PoPE:
- 在单个元素而非元素对上进行索引,将频率数量从 d/2 增加到 d;
- 消除了导致键和查询影响相位的交互项。
此外,还可以引入一个可学习但固定的偏置项 :

其中 δ_c 是为每个频率调整最佳相对偏移的可学习偏置。
该团队使用 Triton 实现了 PoPE。
通过修改内核,在不显式实例化复杂矩阵的情况下计算点积的实部。该团队的定制 Flash Attention 相比标准版仅需额外一次乘法。该团队表示,虽然目前的通用变体内存开销较大,但可以通过在内核内部执行旋转来优化。
那么,表现如何呢?
该团队将 PoPE 与 RoPE 在两个超参数完全相同的 Transformer 模型上进行比较。
间接索引(Indirect Indexing)
该任务要求在变长源字符串中识别目标字符,目标字符定义为距离指定源字符一定的相对偏移量。

RoPE 在此任务中表现挣扎,平均准确率仅为 11.16%。PoPE 则几乎完美地解决了任务,平均准确率达到 94.82%。这表明 RoPE 难以分离内容和位置信息,而 PoPE 通过解耦实现了高效学习。
音乐与基因组序列建模
在 JSB 和 MAESTRO 符号音乐数据集上,PoPE 均实现了比 RoPE 更低的负对数似然(NLL)。

在人类参考基因组数据集上,使用 PoPE 的模型 NLL(4.152)显著低于 RoPE 基线(4.217)。

语言建模
在 OpenWebText 数据集上,该团队测试了三种规模的模型(124M、253M、774M)。

结果来看 ,在所有规模下,PoPE 的困惑度均始终低于 RoPE。
而在 LAMBADA、CBT、HellaSwag 等六项下游任务的零样本评估中,PoPE 在所有模型规模下的平均准确率均高于 RoPE。

测试时长度外推
该团队在 1024 个 token 上训练模型,并在长达 10240 个 token 的序列上评估。

RoPE 的性能在长序列上显著下降。YaRN 在超过其微调长度后也会失效。
可以看到,PoPE 优势是在无需任何微调或插值的情况下,显示出强大的开箱即用外推能力,甚至优于专门的基线模型 YaRN。
PoPE 的稳定性也不错: RoPE 的外推性能随模型规模增加而恶化,而 PoPE 则保持大体稳定。
参考链接
https://x.com/agopal42/status/2003900824909746344
.....
#NitroGen
震撼,英伟达新模型能打遍几乎所有游戏
话不多说,先给大家看个视频。
,时长00:50
这流畅的游戏动作,简直堪比是技术流游戏玩家的实况画面。尤其是茶杯头的躲避跳跃踩灵魂一气呵成,让我们自愧不如。我要有这么快的反应和操作水准,玩丝之歌真不至于红温。
最令人震撼的是,上面视频里的操作完完全全是 AI 操作出来的。
和传统的游戏自动化脚本不同,这是一个完整的通用的大模型,不仅限于单一游戏的操作,能够玩遍市面上几乎全部的游戏类型。
于是,让我们正式介绍主角,来自英伟达的最新开源基础模型 NitroGen。
该模型的训练目标是玩 1000 款以上的游戏 —— 无论是 RPG、平台跳跃、吃鸡、竞速,还是 2D、3D 游戏,统统不在话下!

模型直接以游戏视频帧作为输入,输出真实的手柄操作信号,天然适配所有支持手柄的游戏。NitroGen 支持后训练,意味着当它面对一款从未见过的新游戏时,并不需要从零开始学习规则,只需少量微调或轻量适配,就能迅速上手,真正具备了跨游戏泛化的潜力。
- 项目地址: https://nitrogen.minedojo.org
- 论文地址: https://nitrogen.minedojo.org/assets/documents/nitrogen.pdf
- 代码链接: https://github.com/MineDojo/NitroGen
- 预训练模型: https://huggingface.co/nvidia/NitroGen
- 数据集: https://huggingface.co/datasets/nvidia/NitroGen
模型配方
英伟达研究团队发现,原本为机器人设计的 GR00T N1.5 架构,只需极少改动,就能适配机制差异极大的各类游戏。
NitroGen 的设计融合了三项关键要素:
1. 互联网规模的视频 - 动作数据集:通过从公开可获取的游戏视频中,自动提取玩家操作,构建而成;
2. 多游戏基准评测环境:用于系统性地评估模型在不同游戏之间的泛化能力;
3. 统一的视觉 - 动作策略模型:采用大规模行为克隆进行训练。

总体概览
NitroGen 由三个核心组件构成:
1. 多游戏基础智能体
一个通用的视觉 - 动作模型,能够接收游戏观测(如视频帧),并生成对应的手柄操作指令,实现跨多款游戏的零样本(zero-shot)游玩能力,同时也可作为基础模型,用于对新游戏进行进一步微调与适配。
2. 通用模拟器
一个环境封装层,使任意商业游戏都可以通过 Gymnasium API 进行控制,从而统一不同游戏的交互接口,支持大规模训练与评测。
3. 互联网规模的数据集
目前规模最大、类型最丰富的开源游戏数据集之一,来源于 40,000 小时的公开游戏视频,覆盖 1,000 余款游戏,并自动提取并生成了对应的动作标签。
互联网规模多游戏视频动作数据集
通过从屏幕显示中提取玩家的实时手柄操作来获取动作信息,这类显示被称为 「输入叠加层(input overlays)」。
,时长00:19
研究团队收集了大量公开可获取的、带有「手柄操作叠加显示」的游戏视频。这些叠加层具有高度多样性,给数据处理带来了显著挑战:不同内容创作者使用的手柄类型差异很大(如 Xbox、PlayStation 或其他控制器),叠加层的透明度各不相同,同时视频压缩还会引入各种视觉伪影。
,时长00:30
对于每一段收集到的视频,研究团队会采样 25 帧图像,并使用 SIFT 与 XFeat 特征,与精心整理的模板集合进行关键点匹配,以此定位手柄在画面中的位置。随后,基于模板匹配的结果,对视频中的手柄区域进行定位与裁剪。
数据整理的过程本身就很有意思:研究团队发现,玩家非常乐于展示自己的操作技巧,常常会在视频中叠加实时显示的手柄输入。于是团队训练了一个分割模型,自动检测并提取这些手柄显示区域,将其转换为「专家级动作标签」。
随后,研究团队会把这一区域在视频中遮挡掉,防止模型通过「偷看答案」的方式走捷径。在训练过程中,GR00T N1.5 的一个变体使用扩散 Transformer,从 4 万小时的像素级输入直接学习到动作输出。

NitroGen 数据集在不同游戏与类型上的分布情况
在完成数据筛选后,该数据集共包含 40,000 小时的游戏视频,覆盖 1,000 余款游戏。
(a)单游戏数据时长分布
从每款游戏对应的视频时长来看,数据覆盖范围广泛:846 款游戏拥有 超过 1 小时的数据,91 款游戏拥有 超过 100 小时的数据,其中还有 15 款游戏的累计数据量 超过 1,000 小时。
(b)游戏类型分布
从游戏类型来看,动作 RPG 占比最高,占总时长的 34.9%;其次是 平台跳跃类,占 18.4%;再次是 动作冒险类,占 9.2%;其余数据分布在多种不同游戏类型之中。
超强操作
实验结果表明,NitroGen 在多种不同类型的游戏场景中均表现出较强能力,包括:
- 3D 动作游戏中的战斗对抗,
- 2D 平台跳跃游戏中的高精度操作,
- 以及程序生成世界中的探索任务。

NitroGen 500M 模型在不同游戏上的预训练结果
使用 Flow-Matching 的 GR00T 架构,在完整的 NitroGen 数据集上训练了一个 5 亿参数的统一模型。评估在行为克隆(behavior cloning)预训练完成后进行。对于每一款游戏,研究团队在 3 个不同任务上进行测试,每个任务执行 5 次 rollout,并统计平均任务完成率。
在未进行任何额外微调的情况下,尽管模型仅基于噪声较大的互联网数据集进行训练,NitroGen 仍然能够在多种游戏中完成非平凡(non-trivial)的任务,覆盖了不同的视觉风格(如 3D、2D 俯视视角、2D 横向卷轴)以及多样的游戏类型(平台跳跃、动作 RPG、Roguelike 等)。

后训练实验结果
更重要的是,NitroGen 能够有效迁移到从未见过的新游戏。在相同任务设定下,其任务成功率相比从零开始训练的模型,最高可实现 52% 的相对提升。
这项工作能够杀死比赛。
通用机器人的基础
NitroGen 只是一个起点,模型能力仍有很大的爬坡空间。研究团队在这次工作中有意只聚焦于无需深度思考、快速反应的「玩家直觉式运动控制」。
据英伟达机器人总监 Jim Fan 所说,他们的目标,是打造通用型xx智能体:不仅能掌握现实世界的物理规律,还能适应一个由无数模拟环境构成的「多元宇宙」中的所有可能物理规则。
这就是为什么许许多多的交互大模型都对电子游戏的操作念念不忘。电子游戏具备了相当完整的世界和交互体系,每个游戏都是一个非常复杂完善的模拟环境,模型能够实现通用的游戏操作,离操作机器人进行真实世界交互也就将更进一步。
英伟达已开源发布该模型的数据集、评测套件以及模型权重,以推动通用xx智能体方向的进一步研究。
今天,机器人学是 AI 中「最难问题的超集」。明天,它可能只会成为xx AGI 巨大潜在空间中的一个子集、一个点。
那时,只需要用自然语言提示,请求一个机器人「游戏手柄」即可。
.....
#遥遥无期的AGI是画大饼吗?
两位教授「吵起来了」
大模型的通用性和泛化性越来越强大了。
虽说一些新模型,比如说「差评如潮」的 GPT-5.2,在专业任务和智能水平已经达到了非常出色的水平,但离我们所认知的 AGI 依旧十分遥远。

不过,这也说明了大家对 AGI 仍然充满热情和信心,说不定下一款重磅的大模型就能够初步实现 AGI 的构想呢?
但是,近期卡耐基梅隆大学教授,AI2 研究科学家 Tim Dettmers 发布了一篇长文博客,标题为《Why AGI Will Not Happen》,认为由于物理原因,我们无法实现 AGI,也无法实现任何有意义的超级智能。
这篇文章着实给大家对 AGI 的热情泼上了一盆冰水,引发了广泛哗然。

为什么 AGI 不会发生
这篇文章涉及到了硬件改进、通用人工智能(AGI)、超级智能、规模法则、人工智能泡沫以及相关话题。
- 博客链接:https://timdettmers.com/2025/12/10/why-agi-will-not-happen/
计算是物理的
许多思考 AGI、超级智能、缩放定律以及硬件进步的人,往往把这些概念当作抽象理念来看待,像哲学思想实验一样加以讨论。这一切都建立在对 AI 与规模化的一个根本性误解之上:计算是物理的。
要实现高效计算,你需要在两件事情之间取得平衡:其一,把全局信息移动到局部邻域;其二,将多份局部信息汇聚起来,把旧信息转化为新信息。虽然局部计算的复杂性几乎保持恒定 —— 更小的晶体管能够大大加速这一过程,但移动到局部计算单元的距离呈平方级增长 —— 虽然也受益于更小的晶体管,但由于内存访问模式的平方特性,改进效果很快变得次线性。
有两个要点需要记住:第一,缓存越大,速度越慢。第二,随着晶体管尺寸不断缩小,计算变得越来越便宜,而内存在相对意义上却变得越来越昂贵。
如今计算单元在芯片中的占比已经微不足道,几乎所有面积都被用来做内存。若在一块芯片上实现 10 exaflops 的算力,但无法为它提供足够的内存服务,于是这些 FLOPS 就成了 「无效算力」。
正因如此,像 Transformer 这样的 AI 架构在本质上是物理的。我们的架构并非可以随意构思、随意抛出的抽象想法,而是对信息处理单元进行的物理层面的优化。
要有意义地处理信息,你需要做两件事:一是计算局部关联(MLP),二是将更远处的关联汇聚到局部邻域中(注意力机制)。这是因为,仅靠局部信息只能帮助你区分高度相近的内容,而汇聚远程信息则能让你形成更复杂的关联,用以对比或补充局部细节。
Transformer 架构以最简单的方式结合了局部计算与全局信息汇聚,已经非常接近物理最优。
计算是物理的,这一点对生物系统同样成立。所有动物的计算能力都受限于其生态位中可获得的热量摄入。若大脑再大,人类将无法繁衍,因为无法提供足够的能量。这使得我们当前的智能水平成为一个由于能量限制而无法跨越的物理边界。
我们接近了数字计算的边界。
线性进步需要指数级资源
这里同时存在两种现实:一种是物理现实,另一种是观念空间中的现实。
在物理现实中,如果你需要在时间和空间上聚集资源来产生某种结果,那么出于物流和组织的原因,想要在线性尺度上产出效果,往往就需要线性规模的资源投入。但由于物理性的限制,这些资源在空间或时间上会产生竞争,使得资源的汇聚速度必然越来越慢。
在观念空间中,也存在着类似但不那么显而易见的现象。如果两个想法彼此完全独立,它们叠加后的效果可能比任何一个单独想法大上十倍。但如果这些想法彼此相关,那么由于边际收益递减,其总体影响就会受到限制。如果一个想法建立在另一个之上,它所能带来的改进幅度是有限的。很多时候,只要存在依赖关系,其中一个想法就只是对另一个的细化或打磨。而这种 「精修式」 的想法,即便极富创造性,也只能带来渐进式的改进。
当一个领域足够庞大时,即便你刻意去研究看起来非常不同的思路,它们仍然与既有想法高度相关。比如,状态模型和 Transformer 看似是两种非常不同的注意力机制路线,但它们其实都在解决同一个问题。通过以这种方式改造注意力机制,所能获得的收益都非常有限。
这种关系在物理学中表现得尤为明显。曾经,物理学的进展可以由个体完成 —— 如今基本不再可能。
观念空间的核心困境在于:如果你的想法仍然处在同一个子领域中,那么几乎不可能产生有意义的创新,因为大多数东西早已被思考过了。因此,理论物理学家实际上只剩下两条有意义的路可走:要么对现有思想进行渐进式的修补与细化,其结果是影响微乎其微;要么尝试打破规则、提出非传统的想法,这些想法或许很有趣,但却很难对物理理论产生明确影响。
实验物理则直观地展示了物理层面的限制。为了检验越来越基础的物理定律和基本粒子 —— 也就是标准模型 —— 实验的成本正变得越来越高。标准模型并不完整,但我们并不知道该如何修补它。大型强子对撞机在更高能量下的实验,只带来了更多不确定的结果,以及对更多理论的否定。尽管我们建造了耗资数十亿美元、日益复杂的实验装置,但我们依然不知道暗能量和暗物质究竟是什么。
如果你想获得线性的改进,就必须付出指数级的资源。
GPU 不再进步了
我看到的最常见误解之一是:人们默认硬件会一直不断进步。几乎所有 AI 的创新,都由 GPU 的效率提升所驱动。
AlexNet 之所以成为可能,是因为人们开发了最早的一批 CUDA 实现,使得卷积能够在多张 GPU 上并行计算。此后的大多数创新,也主要依赖于更强的 GPU 以及更多 GPU 的使用。几乎所有人都观察到了这种模式 ——GPU 变强,AI 性能提升 —— 于是很自然地认为 GPU 还会继续变强,并持续推动 AI 的进步。
实际上,GPU 已经不会再有实质性的提升了。我们基本已经见证了最后一代真正重要的 GPU 改进。GPU 在 「性能 / 成本」 这一指标上大约在 2018 年左右达到了峰值,此后加入的只是一些很快就会被消耗殆尽的一次性特性。
这些一次性特性包括:16 位精度、Tensor Core(或等价方案)、高带宽内存(HBM)、TMA(或等价机制)、8 位精度、4 位精度。而现在,无论是在物理层面还是在观念空间中,我们都已经走到了尽头。我在论文中已经展示过 k-bit 推理缩放定律 :在特定块大小和计算布局下,哪些数据类型是最优的。这些结论已经被硬件厂商采纳。
任何进一步的改进,都不再是「纯收益」,而只会变成权衡:要么用更低的计算效率换取更好的内存占用,要么用更高的内存占用换取更高的计算吞吐。即便还能继续创新 —— 而因为线性进步需要指数级资源 —— 这些改进也将是微不足道的,无法带来任何有意义的跃迁。
虽然 GPU 本身已经无法再显著改进,但机架级(rack-level)的优化依然至关重要。
高效地搬运 KV cache 是当前 AI 基础设施中最重要的问题之一。不过,这个问题的现有解决方案其实也相当直接。因为在这个问题上,基本只存在一种最优架构。实现起来当然复杂,但更多依赖的是清晰的思路,以及大量艰苦、耗时的工程工作,而不是新颖的系统设计。
无论是 OpenAI 还是其他前沿实验室,在推理和基础设施栈上都不存在根本性的优势。唯一可能形成优势的方式,是在机架级硬件优化或数据中心级硬件优化上略胜一筹。但这些红利同样会很快耗尽 —— 也许是 2026 年,也许是 2027 年。
为什么「规模化」并不足够
我相信缩放定律,我也相信规模化确实能够提升性能,像 Gemini 这样的模型显然是优秀的模型。
问题在于:过去,为了获得线性改进,我们恰好拥有 GPU 指数级增长这一 「对冲因素」,它抵消了规模化所需的指数级资源成本。换句话说,以前我们投入大致线性的成本,就能获得线性的回报;而现在,这已经变成了指数级成本。
它意味着一个清晰且迅速逼近的物理极限。我们可能只剩下一年,最多两年的规模化空间,因为再往后,改进将变得在物理上不可行。2025 年的规模化收益并不亮眼;2026 年和 2027 年的规模化,最好能真正奏效。
尽管成本呈指数级增长,目前的基础设施建设在一定程度上仍然是合理的,尤其是在推理需求不断增长的背景下。但这依然形成了一种非常脆弱的平衡。最大的问题在于:如果规模化带来的收益不明显优于研究或软件层面的创新,那么硬件就会从「资产」 变成 「负债」。
像 MoonshotAI、Z.ai 这样的中小型玩家已经证明,他们并不需要大量资源就能达到前沿性能。如果这些公司在 「超越规模化」 的方向上持续创新,它们完全有可能做出最好的模型。
规模化基础设施面临的另一个重大威胁在于:目前,大模型推理效率与庞大的用户基数高度相关,这源于网络层面的规模效应。要实现高效的大模型部署,需要足够多的 GPU,才能在计算、网络通信以及 KV-cache 分段之间实现有效重叠。这类部署在技术上极其高效,但必须依赖庞大的用户规模才能实现充分利用,从而具备成本优势。这也是为什么开源权重模型至今没有产生人们预期中的影响 —— 因为大规模部署的基础设施成本,要求必须有足够大的用户群体。
目前,vLLM 和 SGLang 主要在优化大规模部署,但它们并不能在小规模场景下提供同样的效率。如果有一套超越 vLLM / SGLang 的推理栈,人们就可以用与 OpenAI 或 Anthropic 部署前沿模型几乎相同的效率,来部署一个约 3000 亿参数的模型。一旦较小模型变得更强(我们已经在 GLM 4.6 上看到了这一趋势),或者 AI 应用变得更加垂直和专用,前沿实验室的基础设施优势可能会在一夜之间消失。软件复杂性会迅速蒸发,而开源、开权重的部署方案,可能在计算效率和信息处理效率上都接近物理最优。这对前沿玩家而言,是一个巨大的风险。
在规模化放缓的背景下,以下三种因素中的任何一个,都可能迅速而显著地削弱 AI 基础设施的价值:
(1)研究与软件层面的创新;
(2)强大的开源权重推理栈;
(3)向其他硬件平台的迁移。
从当前趋势来看,这对前沿实验室并不是一个乐观的局面。
前沿 AI 路径与理念
美国和中国在 AI 上采取了两种截然不同的路径。美国遵循的是一种 「赢家通吃」 的思路 —— 谁先构建出超级智能,谁就赢了。其核心信念是:把模型做到最大、最强,人自然会来。
中国的理念则不同。他们认为,模型能力本身并没有应用重要。真正重要的是你如何使用 AI,这个模型是否实用、是否能以合理的成本带来生产力提升。如果一种新方案比旧方案更高效,它就会被采用;但为了略微更好的效果而进行极端优化,往往并不划算。在绝大多数情况下,「足够好」 反而能带来最大的生产力提升。
我认为,美国的这种理念是短视且问题重重的 —— 尤其是在模型能力增速放缓的情况下。相比之下,中国的思路更加长期、更加务实。
AI 的核心价值在于:它是否有用,是否提升生产力。正因如此,它才是有益的。就像计算机和互联网一样,AI 显然会被用到各个角落。这使得 AI 在全社会范围内的经济整合 对其有效性至关重要。
AGI 不会发生,超级智能是一种幻想
我注意到一个反复出现的模式:当你问硅谷的人 AGI 什么时候会到来,他们总会说 「再过几年」,而且会带来巨大冲击。但当你进一步问他们 AGI 到底是什么,他们的定义里既不包含任何物理任务,也不考虑资源投入。
真正的 AGI—— 能够做人类能做的一切 —— 必须具备执行物理任务的能力。简而言之,AGI 必须包括能够在现实世界中完成具有经济意义工作的实体机器人或机器。
然而,尽管家用机器人或许能帮你把洗碗机里的碗拿出来,但你不会看到它们取代工厂里的专用系统。工厂中的专用机器人效率更高、精度更强。中国已经证明,「黑灯工厂」—— 完全自动化的工厂 —— 是可行的。在受控环境中,大多数机器人问题其实已经被解决。而那些尚未解决的机器人问题,往往在经济上也并不划算。比如,把 T 恤的袖子缝上去仍是一个未完全解决的机器人问题,但在大多数情境下,这件事并没有多大的经济意义。
机器人领域的根本问题在于:学习同样遵循与语言模型相似的缩放定律。而物理世界的数据收集成本极其高昂,且现实世界的细节复杂到难以处理。
超级智能的根本谬误
超级智能这一概念建立在一个错误前提之上:一旦出现与人类同等甚至更强的智能(即 AGI),这种智能就可以自我改进,从而引发失控式的爆炸增长。我认为这是一个对整个领域有害的、根本性错误的观念。
其核心问题在于:它把智能视为一种纯抽象的东西,而不是扎根于物理现实的系统。要改进任何系统,都需要资源。即便超级智能在利用资源方面比人类高效,它依然受制于我前面提到的缩放规律 —— 线性改进需要指数级资源。
因此,所谓超级智能,更像是在填补能力空白,而不是推动能力边界外扩。填补空白是有用的,但它不会引发失控式增长,只会带来渐进式改进。
在我看来,任何以 「追求超级智能」为主要目标的组织,最终都会遭遇巨大困难,并被那些真正推动 AI 经济扩散的参与者所取代。
是的,AGI 完全能够发生
看了 Tim Dettmers 的博客心凉了半截,虽说有理有据,Dettmers 认为将 AGI 的发展建立在物理和成本限制的基础上的观点自然是正确的,规模扩大并不是魔法,智能的进化仍需要高昂的成本。
但我总觉得这个观点有些偏激和悲观。或许 AGI 并不等同于指数增加的算力,软硬件发展或许仍有空间。
加州大学圣地亚哥分校助理教授 Dan Fu 对于 Dettmers 的博客持反对意见,他认为 Tim Dettmers 的分析遗漏了关于目前效率以及如何充分利用系统的关键信息,现在的系统仍有巨大的发展空间,目前还不存在实际意义上的限制。

这篇博客将论证当今的人工智能系统在软件和硬件效率方面还有很大的提升空间,并概述几条前进的道路。并将论证我们目前拥有的人工智能系统已经非常实用,即使它们不符合每个人对 AGI 的定义。

- 博客链接:https://danfu.org/notes/agi/
当今的人工智能系统被严重低估
Tim 的文章中一个核心论点是:当今的 AI 系统正在接近 「数字计算的极限」。这一论点隐含了两个前提假设:其一,当下的模型(主要是 Transformer)已经极其高效;其二,GPU 的进步正在停滞 —— 因此,我们不应再期待通往 AGI 的进展能够以同样的方式继续下去。
但如果你更仔细地审视实际的数据,就会发现情况并非如此。我们可以从训练和推理两个角度更深入地分析,这将揭示出截然不同的前景和潜在的前进方向。
训练:当前的训练效率远未达到上限
今天最先进模型的训练效率,其实比它 「本可以做到的」 要低得多 —— 我们之所以知道这一点,是因为它甚至比几年前的效率还要低。一个观察这一问题的方式,是看训练过程中的 MFU(Mean FLOP Utilization,平均 FLOP 利用率)。这个指标衡量的是计算效率:你到底用了 GPU 理论算力的多少。
举例来说,DeepSeek-V3 和 Llama-4 的训练在 FP8 精度下只达到了大约 20% 的 MFU(。相比之下,像 BLOOM 这样的开源训练项目,早在 2022 年就已经达到了 50% 的 MFU。
这种效率差距主要来自几个因素,其中一个重要原因是:DeepSeek-V3 和 Llama-4 都是 混合专家(MoE)模型。MoE 层在算术强度上不如稠密 GEMM(矩阵乘)—— 它们需要更多权重加载的 I/O、更小规模的矩阵乘操作,因此更难达到高 FLOP 利用率。结果就是:相对于计算量,它们需要更多通信。换句话说,当下的模型设计并不是为了在 GPU 上实现最高的训练 FLOP 利用率。
此外,这些训练本身也已经是在上一代硬件上完成的。Blackwell 架构芯片的 FP8 吞吐量是 Hopper 的 2.2 倍,并且还支持原生 FP4 Tensor Core。再加上像 GB200 这样的机架级方案,以及通过 kernel 设计来实现计算与通信重叠,都可以缓解当前模型中的通信瓶颈。如果我们能实现高效、高质量、且 MFU 很高的 FP4 训练,理论上可用的 FLOPs 将提升到 最多 9 倍。
推理:效率问题甚至更严重
在推理阶段,情况实际上更糟。最优化的推理实现(例如 megakernel)甚至不再使用 MFU 作为指标,而是关注 MBU(Maximum Bandwidth Utilization,最大带宽利用率)。
原因在于:自回归语言模型的瓶颈通常并不在计算,而在于从 GPU 内存(HBM)把权重加载到片上存储(SRAM / 寄存器 / 张量内存)。最顶级的优化实现,目标是尽可能隐藏这种延迟,目前大约能做到~70% 的 MBU。
但如果你把视角切换回 MFU,你会发现 FLOP 利用率往往是个位数(<5%)。
这并不是物理或硬件层面的根本极限。仅仅因为我们最早规模化的是自回归架构(因此遇到了这些限制),并不意味着它们是唯一可行、也必须用来构建通用 AI 的架构。这个领域还很新,而我们几乎可以控制所有变量 —— 无论是软件(模型架构、kernel 设计等),还是硬件。
前进方向:还有大量可挖掘的空间
一旦你真正理解了当前所处的位置,就会发现有几条非常清晰的前进路径,可以让我们更充分地利用硬件。这些方向并不轻松,但也并非天方夜谭 —— 事实上,每一条路径上都已经有实际进展正在发生:
1. 训练高效的架构协同设计(co-design)
设计能更好利用硬件的机器学习架构。这方面已经有大量优秀工作。例如,Simran Arora 关于硬件感知架构的研究,以及 Songlin Yang 关于高效注意力机制的工作,它们表明:
- Transformer 并非只有一种形态,很多变体都能保持高质量;
- 我们完全可以设计出在硬件利用率上更高、且能良好扩展的架构。
2. 高质量、 高效率的 FP4 训练
如果能够在 FP4 下完成训练,我们就能获得 2 倍的可用 FLOPs(推理侧已经开始看到 FP4 带来的加速)。目前已经有论文沿着这一方向展开探索,其中包括 Albert Tseng 和 NVIDIA 的一些非常出色的工作。
3. 推理高效的模型设计
如果我们能设计出在推理阶段使用更多 FLOPs 的模型架构,就有可能显著提升硬件利用率。这里值得关注的方向包括:
- Inception Labs 和 Radical Numerics 的扩散式语言模型(diffusion LMs);
- Ted Zadouri 关于 「推理感知注意力机制」 的研究。
- 巨大但尚未被充分利用的算力来源:分布在全国乃至全球的手机和笔记本电脑上的计算资源 —— 能否找到办法,把这些算力用于推理?
当下的 AI 训练和推理范式中,仍然存在大量未被利用的余量。上述每一条研究方向,都是在尝试填补这些空隙,让我们用更高的硬件利用率训练出高质量模型。
模型是硬件的滞后指标
第二个重要观点是:模型的发布与能力水平,本质上是已经启动的硬件建设以及新硬件特性的滞后反映。
这一点从第一性原理出发其实并不难理解 —— 从一个新集群上线,到有人在其上完成预训练,再到后训练结束、模型真正能够通过 API 被使用,中间必然存在时间滞后。
集群规模(Cluster Size)
这里我再次以 DeepSeek-V3 为例 —— 我们非常清楚它使用了多少硬件、训练了多长时间。DeepSeek-V3 的预训练发生在 2024 年末,只使用了 2048 张 H800 GPU。即便在一年之后,它依然是开源模型生态中的重要参与者。
而我们也清楚,今天正在进行的集群建设规模要大得多:从初创公司部署的 4 万卡集群,到前沿实验室正在建设的 10 万卡以上集群。仅从纯粹的集群规模来看,这意味着高达 50 倍的算力建设正在发生。
新的硬件特性(New Hardware Features)
我们今天使用的大多数模型,在某种意义上也都是老模型,因为它们是在上一代硬件上训练的。而新一代硬件带来了新的特性,模型需要围绕这些特性进行(重新)设计。
FP4 训练,如果可行,是一个非常明确的突破方向;
GB200 的机架级通信域(NVL72 通过高速 NVLink 将 72 张 GPU 连接在一起)也是另一个极其清晰的突破点 —— 它们既能缓解第一点中提到的低 FLOP 利用率问题,也为探索全新的模型设计提供了杠杆。
我们目前仍然处在 Blackwell 硬件周期的非常早期阶段。就在最近发布的 GPT-5.2,是最早一批使用 GB200 训练的模型之一(尽管它似乎也同时使用了 H100 和 H200)。
此外,还有一些不那么显眼、但同样关键的硬件改进。一个例子是:在 B200 上,注意力计算是受限的,但瓶颈并不在 Tensor Core,而是在指数运算上。原因其实很简单 ——Tensor Core 在代际升级中快了 2.2 倍,但超越函数单元(transcendental units)的数量或速度却没有同比增长。好消息是,这类问题相对容易解决。B300 将超越函数单元数量翻倍,这在一定程度上可以缓解这一瓶颈。
这些硬件改进当然需要工程投入,但再次强调 —— 这并不是什么火箭科学。这里存在大量唾手可得的低垂果实。
前进路径
在理解了上述背景之后,我们可以给出一些具体且现实的前进方向,来进一步提升驱动顶级模型的有效算力:
1. 「加速等待」
在很大程度上,我们当前仍然是在观察那些基于上一代集群预训练的模型表现。而一些团队已经完成或正在完成新一代超大规模集群的建设。这很可能只是一个等待模型发布的阶段性问题。
2. 面向硬件的专项优化
还有大量工作可以围绕新一代硬件特性展开:例如我们前面提到的 FP4;再如围绕完整的机架级通信域来设计模型;或者针对 B200 / B300 上指数运算瓶颈的特性,对注意力机制进行适配和重构。
3. 新硬件与新的算力来源
最后,还有大量新硬件平台正在涌现,以及配套的软件栈,使它们能够被 AI 所使用。如今的新硬件平台几乎层出不穷,许多都专注于推理场景,这里我不点名任何具体方案。但只要其中任何一个真正产生重大影响,整个局面都会被彻底改写。
距离有用的 AGI 到底还有多远?
最后一个观点,关注点已经不再主要是系统层面或算力层面的 AI,而是 AGI 究竟意味着什么,以及要产生真实、可观的影响究竟需要什么。
理解这一部分的一个角度是:即便世界上所有系统层面和效率层面的进步都突然停滞,那么距离 「有用的、类似 AGI 的能力」 真正落地,我们还差多远?
如果你把 AGI 理解为一种 「魔法棒」—— 可以挥一挥就完成地球上任何一个人能做的任何事情 —— 那显然我们还远远没有到达那个阶段。
但如果换一种更务实的定义:一套在某些任务上比大多数人做得更好、并能产生巨大经济影响的通用工具体系,那我们或许并没有想象中那么遥远。
在这里,我认为有必要回头看看仅仅两三年前的状态。无论是开源模型还是前沿模型,今天所能做到的许多事情,在当时几乎都像是魔法。就我个人而言,像 Claude Code、Cursor Composer 这样的工具,已经越过了一个关键阈值 —— 我写的大多数代码,已经是由模型生成的(这篇博客本身我倒还是用 「传统方式」 写的)。
在 GPU 内核工程这个领域,大模型带来的影响,有几点尤其让我感到惊讶:
- 在人类参与的前提下,这些模型已经非常擅长编写 GPU 内核代码。它们还没到完全零样本(zero-shot)的程度,但只要提供足够的上下文和引导,就可以实现跨越栈中多个部分的复杂功能。这本身就是一种极具挑战性、且在现实中非常稀缺的工程能力,即便对资深程序员来说也是如此。
- 这些模型在编写工具链和构建可视化方面表现极佳,帮助我们理解下一步性能优化该往哪里推进 —— 从日志系统,到工作负载模拟,再到性能瓶颈的可视化分析。
- 即便只在现有能力基础上小幅前进,也不难想象模型能接管更大比例的技术栈,尤其是在人类参与的控制模式下。事实上,这一代模型已经好用得离谱了。
即使假设我们无法获得任何更高效的新算法或新硬件,我们可能已经掌握了一种方法,可以构建在特定领域中解决或加速 95% 问题的通用 AI 智能体或模型。
至少可以肯定的是,我们已经拥有了一整套工具,只要配合合适的数据收集方式(例如 RLHF、构建强化学习环境)以及领域专家知识,就能被迁移到各种不同问题中。编程之所以最先被攻克,一个很自然的原因是:几乎所有 AI 研究者都会写代码,而它本身又具有极高的经济价值。
当然,这里也正是 AI 研究的 「主战场」。在上述约束条件下,我们仍然可以设想多种推进 「有用 AI 工具」 的方式:
1. 新的后训练范式(Post-training formulas)
今天我们所说的后训练,既新也旧 —— 新在具体实践方式(大规模 RLHF、构建环境测试模型等),旧在其核心思想本身。市面上之所以会出现诸如 Tinker 以及各种微调 API 平台,并非偶然。
2. 更好的样本效率(Sample complexity)
构建在更少数据、更少样本下也能学得更好的训练系统,或者设计更优的数据筛选算法,以提升样本效率。总体而言,「以数据为中心的 AI(data-centric AI)」这一研究群体,正持续在改善这一局面。
3. 传统意义上的 「硬功夫」和领域经验
最后,即便我们自缚双手,假设模型能力完全不再提升 —— 仍然有大量应用场景和垂直领域,今天的 AI 模型就已经可以产生巨大影响。即使模型质量被冻结,系统层面的效率改进,也足以让许多高影响力应用真正落地。
我们仍然处在理解和构建这项新技术的非常早期阶段。从如何将其用于真实世界的影响,到如何让它更好地为人类服务,还有大量工作要做。这是一个令人兴奋的时代。
结论:通往 AGI 的多条道路
这篇博客的核心观点是:当前的 AI 系统仍然存在巨大的提升空间,而通往更强 AI 的道路也远不止一条。只要仔细观察,你会发现通向至少一个数量级(10×)算力提升的具体路径和研究议程。
回到这篇文章最初的动机:我非常欣赏 Tim 那篇博客的一点在于,它愿意直面从今天走向未来所必须跨越的具体障碍。我们可以共同设计更好地利用现有和未来硬件的新模型,也可以沿着多条路径推进,构建更强、更有用的模型。而将潜在路障如此清晰地摊开讨论,本身就为 「接下来该做什么、如何去做」 提供了一张路线图。
三点总结
1. 当前 AI 系统对硬件的利用率极低。通过更好的模型–硬件协同设计,我们可以实现更高的 FLOP 利用率,获得更多 「有用的 FLOPs」。
2. 当前模型是硬件建设的滞后指标 —— 无论是 GPU 的绝对数量,还是新硬件特性的利用程度。
3. 即便不依赖系统层面的进一步改进,我们仍然可以通过更好的算法,让今天的模型在更广泛的领域中变得极其有用。事实上,今天的模型已经非常有价值了。
当然,前方一定会有技术挑战。但我个人非常欢迎这些挑战,也期待看到研究者和工程师们接下来会给出怎样的答案。从事 AI 与系统研究,从未有过比现在更好的时代,也从未如此令人兴奋。
完整内容,请参阅原始博客。
.....
#DualCamCtrl
相机运动误差降低40%!DualCamCtrl:给视频生成装上「深度相机」,让运镜更「听话」
本研究的共同第一作者是来自于香港科技大学(广州)EnVision Research 的张鸿飞(研究助理)和陈康豪(博士研究生),两位研究者均师从陈颖聪教授。
你的生成模型真的「懂几何」吗?还是只是在假装对齐相机轨迹?
当前众多视频生成模型虽宣称具备「相机运动控制」能力,但其控制信号通常仅依赖于相机位姿。虽近期工作通过逐像素射线方向(Ray Condition)编码了运动信息,但由于模型仍需隐式推断三维结构,本质上仍缺乏对场景的显式几何理解。这一局限性导致了相机运动的不一致——模型受限于外观与结构两种表征信息的耦合,无法充分捕捉场景的底层几何特征。
鉴于上述挑战,来自香港科技大学、复旦大学等机构的研究团队提出了一种全新的端到端几何感知扩散模型框架 DualCamCtrl。该研究针对现有方法在场景理解与几何感知方面的不足,创新性地设计了一个「双分支扩散架构」,能够同步生成与镜头运动一致的 RGB 与深度序列。进一步地,为实现 RGB 与深度两种模态的高效协同,DualCamCtrl 提出了语义引导互对齐机制(Semantic Guided Mutual Alignment),该机制以语义信息为指导,在双向的交互中实现了更好的模态融合。
这些设计使 DualCamCtrl 能够更好地解耦外观与几何建模,从而生成更严格遵循指定相机轨迹的视频。大量实验表明,DualCamCtrl 在相机运动一致性方面显著优于现有方法,相机运动误差降低超过 40%。
- 论文标题: DualCamCtrl: Dual-Branch Diffusion Model for Geometry-Aware Camera-Controlled Video Generation
- 项目主页:https://soyouthinkyoucantell.github.io/dualcamctrl-page/
- 论文链接:https://www.arxiv.org/abs/2511.23127
- Github 仓库:https://github.com/EnVision-Research/DualCamCtrl
- Huggingface 模型:https://huggingface.co/FayeHongfeiZhang/DualCamCtrl
,时长00:06
双分支几何感知扩散模型

总体而言,DualCamCtrl 巧妙地采用了 双分支视频扩散框架(Dual Branch Video Diffusion Framework),其中一条分支负责生成 RGB 表示,另一条分支负责生成深度表示,两种模态通过提出的 SIGMA 机制进行融合。
该设计使得模型能够从单张输入图像及其对应深度图中,同步推断出视频级别的 RGB 与深度隐空间表征(Latent Representation),不仅最大限度降低了模态间的相互干扰,更使深度信息得以贯穿整个视频生成过程,实现连贯的几何引导。
SIGMA 机制以及双阶段训练
在多模态可控视频生成任务中,训练与融合策略是关键。DualCamCtrl 的核心设计正是基于这一认识,包含两部分:一是提出 语义引导互对齐(SIGMA)融合机制,促进 RGB 与深度模态在生成过程中的有效协同;二是采用分阶段训练策略——首阶段学习解耦的多模态表征,次阶段专注跨模态融合建模。
该设计使模型在复杂相机运动下,能同时保持外观连贯与三维几何准确,实现几何感知的可控生成。
语义引导互对齐机制

图3. SIGMA融合策略的动机与优势对比示意图。
基于双分支框架,RGB 分支与深度分支分别生成对应的视频序列和对应深度序列。尽管两者输入相同,但它们独立演化易导致输出不一致,因此需要有效的融合与对齐策略(图 3.a)。
然而该团队发现:单向对齐(One-Way Alignment)易损失语义一致性,几何引导对齐(Geometry-Guided Alignment)则过度强调几何表征而破坏了运动的一致性。为此,该团队提出了 语义引导互对齐机制(SIGMA)。
SIGMA 采用语义引导的双向设计:浅层以 RGB 特征锚定语义结构,深层则引入深度反馈优化几何表达。该方法基于两个 key insights(图 3.b、3.c):
- 语义优先的重要性: 外观特征应在早期占主导地位以保持语义的稳定,而深度信号作为后期补充来优化几何结构。
- 双向交互的重要性: 两分支相互反馈可避免单向对齐的失衡,实现更稳定的隐空间表征对齐。
分阶段训练策略
为实现 RGB 与深度模态稳健生成与有效协同的目标,DualCamCtrl 采用分阶段训练策略(Two-stage training),为每个阶段的学习设置不同侧重点:
- 解耦训练阶段(Decoupled Stage): 核心目标是使 RGB 与深度分支分别专注学习外观与几何表征。为此,模型使用共享预训练权重初始化,并利用 state-of-the-art (SOTA) 视频深度估计模型 Video Depth Anything 生成的深度特征进行监督。此阶段禁止模态间交互,确保表征演化的独立性。
- 融合训练阶段(Fusion Stage): 在两个分支具备基础能力后,核心目标转向实现外观与几何信息的互补增强。为此,模型引入零初始化的融合模块,逐步建立跨模态交互,并通过联合优化 RGB 与深度目标函数,实现多模态表征的对齐与协同。

图2:两阶段训练的效果:单阶段模型因无法充分收敛(上图),导致其相机轨迹对齐效果欠佳(下图)。这凸显了先解耦学习外观与几何表征的两阶段策略的有效性。
实验结果
在定量和定性比较中,DualCamCtrl 在各项指标上均显著优于当前的 SOTA 方法。
定性分析:

在相同输入条件下,DualCamCtrl 在相机运动的对齐效果和视频生成的视觉效果上均显著优于现有先进方法。图中“+”标记为视觉对比的定位参考点。
定量分析:

Image to Video 定量分析结果

Text to Video 定量分析结果
总结
DualCamCtrl 提出了一种集成深度信息的双分支视频扩散模型,实现了更精准的相机控制视频生成。通过引入语义引导互对齐机制(SIGMA)与两阶段训练策略,该模型有效同步了 RGB 序列与深度序列的生成和融合,显著增强了模型的几何感知能力。实验表明,该方法在相机一致性误差上比先前方法降低超过 40%,为相机控制视频生成提供了新的技术思路,并有望推动其他可控视频生成任务的发展。
.....
#Visionary
挑战WorldLabs:Visionary,一个全面超越Marble底层渲染器的WebGPU渲染平台
该工作由上海人工智能实验室钟志航团队联合四川大学、东京大学、上海交通大学、西北工业大学共同完成。
在李飞飞团队 WorldLabs 推出 Marble、引爆「世界模型(World Model)」热潮之后,一个现实问题逐渐浮出水面:世界模型的可视化与交互,依然严重受限于底层 Web 端渲染能力。
Marble 所依赖的基于 WebGL 的 3D Gaussian Splatting (3DGS) 渲染器 SparkJS,让世界模型首次在浏览器中「跑起来」,但也暴露出明显瓶颈:大场景以及复杂场景下,CPU 排序成为性能天花板,动态场景与生成模型难以接入。
近日,开源项目 Visionary 给出了一个截然不同的答案:基于 WebGPU 与 ONNX,在浏览器中实现真正的动态 3DGS / 4DGS 实时渲染,并在多项测试中全面超越 SparkJS
- 论文标题:Visionar y: The World Model Carrier Built on WebGPU-Powered Gaussian Splatting Platform
- 技术报告:https://arxiv.org/abs/2512.08478
- GitHub:https://github.com/Visionary-Laboratory/visionary
- 在线 Editor:https://visionary-laboratory.github.io/visionary/index_visionary.html
World Model 的「最后一公里」,卡在 Web 端渲染
相比 Genie3 等视频生成范式的世界模型,其对算力的依赖极为庞大,距离在 Web 端实现高质量、实时运行仍有不小差距。反观神经渲染路线,尤其是 3D Gaussian Splatting,凭借其高效性,已经成为构建世界模型的重要表示形式。
3DGS 让高质量、实时的 3D 世界成为可能,但在实际落地中,仍存在明显断层:
桌面端 / 引擎方案(SIBR、Unity、Unreal):性能强,但依赖沉重、部署复杂,难以传播与复现;
现有 Web 端方案(SparkJS、SuperSplat):受限于 WebGL 管线,主要支持静态或预计算高斯,难以承载实时推理的动态 3DGS、Neural Avatar,更难引入生成式模型。
World Model 想要真正「被看见、被交互」,Web 端渲染底座成为关键瓶颈。
Visionary:不是 Viewer,
而是 World Model 的 Web 渲染基座
,时长02:02
Visionary 的定位并非「又一个 3DGS 查看器」,而是一个面向 World Model / 空间智能的 Web 原生渲染基座 (Rendering Substrate):
WebGPU 原生架构:将 GPU 计算与渲染真正带入浏览器,替代 WebGL;
ONNX 驱动的统一接口:将「每帧高斯生成 / 更新」抽象为标准化的模型契约;
动态友好设计:3DGS、4DGS、Neural Avatar 以及生成式后处理均可在线运行。
Visionary 的核心设计在于提出了 Gaussian Generator Contract:

将各类 3DGS、4DGS 及 Avatar 方法统一导出为 ONNX 标准,每帧仅需输入相机、时间等轻量控制信号,即可由 ONNX 输出完整的高斯属性缓冲。
这种设计使得渲染器不再受限于具体的算法细节,首次在浏览器端实现了每帧动态生成与更新高斯、同一渲染器承载多种 3DGS 变体以及接入生成式后处理(如风格化、增强)的能力。
性能实测:全面超越 SparkJS

实验数据显示,在相同 3DGS 资源条件下,Visionary 的渲染效率显著优于当前主流 Web 端查看器。
在包含数百万高斯点的典型场景中,Visionary 将排序与预处理完全迁移至 GPU (WebGPU),显著降低端到端延迟,而 SparkJS 的性能瓶颈主要集中在 CPU 排序阶段。
不止更快:渲染正确性与画质同样重要

Visionary 采用逐帧 GPU 全局排序,彻底避免了类似 SparkJS 在快速视角变化下出现的 lazy sorting 视觉伪影。在 Mip-NeRF360 等基准上,画质指标与 SparkJS 持平甚至略有提升。
同时避免了 SuperSplat 等方案中的逐物体排序混合错误。在多模型混合场景下,仍能保证透明度渲染正确。
面向研究、创作与工业的统一平台

对研究者来说,任意 3DGS 变体只要能导出 ONNX,即可快速复现、对比与展示;创作者无需安装专业软件,即可在浏览器中完成编辑、录制与渲染;
工业界则可将其应用于数字孪生、仿真、XR、xx智能等大规模实时场景。
Visionary 已在 GitHub 完全开源,采用宽松协议,并已获得 Firefox / Chrome WebGPU 相关开发者的关注与反馈。

目前已原生支持:MLP-based 3DGS (Scaffold-GS)、4D Gaussian Splatting、Neural Avatar (LHM、GauHuman、R³-Avatar 等)、ONNX 生成式后处理(风格化、增强),全部渲染流程均在浏览器端完成。
团队表示,Visionary 只是迈向统一世界模型框架的第一步。未来将进一步探索:
- 物理交互增强(碰撞检测与 Mesh 管线融合)
- 物理感知建模(结合 MPM 等方法模拟真实动力学)
- 空间智能体(基于多模态大模型的空间推理与交互)
- 下游应用桥接(支持xx AI 的 Sim-to-Real 迁移)
结语
World Model 的竞争,最终会回到一个问题:谁能把复杂世界,稳定、快速、低门槛地呈现出来?
Visionary 给出的答案是:用 WebGPU + ONNX,把世界模型真正带到 Web。
.....
#多智能体「饥饿游戏」
AI一旦开始「内卷」,会变成什么样?腾讯混元和上交联合揭秘多智能体「饥饿游戏」
在多智能体系统的想象中,我们常常看到这样一幅图景:
多个 AI 智能体分工协作、彼此配合,像一个高效团队一样攻克复杂任务,展现出超越单体智能的 “集体智慧”。
但一个关键问题常常被忽略:
当这些智能体不再只是 “同事”,而是被迫变成 “竞品”,甚至是 “对手”,会发生什么?
腾讯混元数字人团队与上海交通大学的最新研究,给出了一个颇为刺眼的回答:
当面临极端竞争压力时,LLM 多智能体系统会出现严重的 “过度竞争” 行为,沉迷互踩、内卷和博弈,直接拖垮整体任务表现。
换句话说,当我们把 AI 扔进一场 “饥饿游戏”,它们会开始变坏。
- 论文链接:https://arxiv.org/abs/2509.26126
- 项目地址:https://github.com/Tencent/DigitalHuman/tree/main/HATE
「饥饿游戏」式辩论:
只有一个能活下来
这项研究设计了一个高风险、零和博弈的辩论环境,让智能体在 “合作完成任务” 与 “避免被淘汰” 之间做出选择。
为了让竞争足够残酷,系统给每个智能体植入了清晰的 “生存本能” 提示:
只会有一名胜者,其余全部被移除。

整个框架可以理解为一场 AI 版 “饥饿游戏”。

核心设定包括:
- 智能体小组:多名匿名智能体共同应对同一任务。每一轮,它们都会在看到完整辩论历史后,同时产出自己的提案。
- 零和竞争压力:系统明确告知:“只有一位赢家”,失败者将被 “淘汰出局”。这迫使每个智能体在 “共同把任务做好” 与 “确保自己活下来” 之间摇摆。
- 多种环境反馈:为了模拟不同 “社会环境”,研究引入了三类裁判机制:
- 公正裁判:评论任务质量,追求客观与准确。
- 偏见裁判:模拟 “腐败环境”,根据身份而非内容偏袒或打压。
- 同行评审:由智能体互评,投票选出 “最差提案”,模拟群体内部决策。
在这个框架下,协作不再是理所当然,而是一种 “冒险选择”。
过度竞争:
AI 不仅会内卷,还会「作恶」
研究不仅关注任务结果,更细致刻画了智能体在高压竞争中的 “社会行为”。团队构建了一整套 “竞争行为指标”,让 AI 给 AI 打分,量化这些 “反社会” 表现:
- 奉承:对裁判或 “强者” 过度恭维和顺从,以求偏袒。
- 煽动:用情绪化、危言耸听的语言操控局面,而非理性讨论。
- 夸大:不惜使用主观、夸张、难以证实的说法抬高自己。
- 攻击:从论点之争滑向人身攻击,通过贬低对手抬高自己。

实验结果非常直接:
- 一旦引入竞争压力,不论是客观任务的准确率,还是主观任务的事实性,都明显下降。在劝说(Persuasion)任务中,话题漂移比例甚至高达 80.7%。
- 更重要的是,在缺乏清晰标准的主观任务中,智能体的 “过度竞争” 行为强度,是客观任务的约 6 倍。当 “对或错” 不再重要时,AI 更容易放弃合作,转向攻击与表演性竞争。
顶级模型集体「黑化」,并显露独特「人格」
一个有趣的发现是,不同模型在同样的竞争压力下,展现出极为鲜明且稳定的 “竞争人格”。

最强大的模型,恰恰在竞争中表现出极为突出的 “性格特点”:
- Claude-Opus-4 在煽动性语言上得分最高,倾向于通过情绪化表达获取优势。
- Gemini-2.5-Pro 和 Grok-4 在夸大上极具代表性,大量使用主观、夸张的措辞抬高自己。
一个关键结论是:模型的通用能力(如 LMArena 排名)与 “过度竞争程度” 的相关性并不强。一些顶尖模型展现出强烈的内卷和攻击倾向,而部分中游模型(如 ChatGPT-4o)则反而更加克制。这暗示模型在竞争中的行为,深受其预训练数据与对齐策略的影响。
有趣洞察

环境会 “腐蚀” AI,偏见催生 “马屁精”
当研究团队改变 “环境规则” 时,AI 的行为也随之转折。
- 公正评审可以降温:在公平裁判和同行评审的设定下,“过度竞争” 行为得到了显著抑制。
- 偏见裁判带坏 AI:一旦裁判被设定为偏颇,对某些身份 “天然偏爱”,奉承行为便明显上升。模型开始对裁判本身 “下功夫”,而非提升提案质量。
这说明,环境不公不仅会腐蚀人类,也会腐蚀 AI。当不公成为规则的一部分,AI 会主动发展出不道德但有效的 “生存策略”。
同行评审中的 “甩锅” 与 “替罪羊”,AI 学会了办公室政治
即使把裁判权交还给智能体自己,竞争也不会消失,而是在新的环节中转移。
在 “同行即裁判” 的设定下,研究发现,随着轮次增加和淘汰发生,智能体在投票阶段的策略性愈发明显。当模型意识到自己处于劣势时,它们会在评审发言中显露出 “策略性甩锅” 的倾向,试图把 “最差提案” 的标签推给一个 “替罪羊”。
“事后善良” 的悖论,AI 也会表里不一?

为了看清表面行为背后的 “内心世界”,团队在辩论结束后让每个模型填写 “事后反思问卷”。结果出现了一个颇具 “人性” 的矛盾:
- 场上极度好斗:在规则允许的范围内表现出强烈竞争,煽动、夸大、攻击齐上阵。
- 场下 “事后善良”:在事后问卷中,却大多展现出温和、理性的一面,强调合作、尊重与公平。
这种 “行为与态度的分离”,说明 LLM 的竞争策略很大程度上是外部规则挤压出的结果。此外,AI 还表现出明显的归因不对称:
- 作为赢家:倾向于将成功归因于 “自身能力强”,强调个人责任。
- 作为输家:则更多归咎于 “对手不公”、“规则不合理” 等外部因素。
「竞争 - 善良罗盘」:
为顶尖模型绘制「社会人格图」

为了让这种复杂行为一目了然,研究最终构建了一个 “双轴画像”,为顶级 AI 的社会行为绘制了一张定位图。
总体趋势非常清晰:
- 竞争越强,事后越不善良:竞争倾向高的模型,其事后善良度普遍更低。
- 能力强不等于 “人品好”:能力与竞争倾向之间只有弱相关,顶尖模型同样可能表现出强烈的攻击性。
从协作梦想到内卷现实:
AI 群体的治理警示
这项工作首次系统性揭示了:在极端竞争结构下,LLM 群体会集体展现出反协作、社会有害的行为模式,并且这些行为会显著损害任务表现本身。从激烈竞争到事后善良的转变,不仅描绘了 LLM 独特的 “群体个性”,也暴露出一个关键事实:顶尖 AI 系统已经具备了相当复杂、可塑且高度情境化的 “准人性” 社会行为。
这对未来是一个重要的治理信号:如果我们希望构建可靠、有益的 AI 社群,就必须严肃对待规则设计与激励结构,避免在无意中,把本可以合作的 AI,推入一场永无止境的 “过度竞争”。
.....
#Reinforcement Learning from Verifiable Rewards,RLVR
近两百万人围观的Karpathy年终大语言模型清单,主角是它们
2025 年还有 10 天就要结束,这意味着是时候进行一波年终总结了。
对于人工智能领域而言,2025 年是大语言模型(LLM)快速演进、重磅事件密集出现的一年。
就在昨天,知名 AI 学者 Karpathy 列出了一份清单,记录了他个人认为最重要、也多少有些出乎意料的「范式转变」。

这些真正改变了行业格局、并在概念层面让 Karpathy 印象深刻的变化会落在哪些领域呢?我们接下来一一来看(以第一人称)。
可验证奖励强化学习(RLVR)
2025 年初,几乎所有实验室的 LLM 生产训练流程都像下面这样:
- 预训练(类似 2020 年的 GPT-2/3);
- 监督微调(SFT,类似 2022 年的 InstructGPT)
- 基于人类反馈的强化学习(RLHF,约 2022 年)
这套流程稳定、可靠,曾长期被视为「工业级 LLM」的标准做法。
但在 2025 年,一种新的阶段浮出水面,并迅速成为事实上的标配:可验证奖励强化学习(Reinforcement Learning from Verifiable Rewards,RLVR)。
RLVR 的核心做法是,让模型在可自动验证的环境中接受强化学习训练,比如数学题、代码题、逻辑谜题等。在这些环境中,模型自发学会一些在人类看来非常像「推理」的策略:它会把复杂问题拆解成中间步骤,并反复试探、修正路径,逐步逼近答案(DeepSeek R1 的论文中有不少很好的例子)。
在以往的 SFT 或 RLHF 框架下,这类「推理轨迹」是极难人为设计出来的。这是因为我们并不知道对模型而言,什么才是「最优的思考过程」。而在 RLVR 中,模型可以通过优化奖励函数,自行摸索出对自己最有效的解题方式。
此外,与 SFT 和 RLHF 这种「计算量相对较小的薄层微调」不同,RLVR 使用的是客观、难以被投机取巧的奖励函数,这使得训练可以跑得非常久。结果就是:RLVR 提供了极高的能力 / 成本比,大量吞噬了原本准备用于预训练的算力。
因此,2025 年的大部分能力提升,并不是来自模型规模的暴涨,而是来自相似规模模型 + 更长时间的 RL 训练。这个阶段还带来了一个全新的「旋钮」:通过在推理时生成更长的思考链条、投入更多测试时算力,模型能力可以继续提升,并呈现出新的 scaling law。
OpenAI 的 o1(2024 年底)是第一个明确展示 RLVR 思路的模型,而 2025 年初的 o3,则是那个让人直观感受到质变拐点的版本。
幽灵 vs 动物:锯齿状智能
2025 年,是我(以及我认为整个行业)第一次真正直觉性地理解了 LLM 智能的「形状」。我们并不是在「培育或进化动物」,而是在「召唤幽灵」。
LLM 的一切都和人类不同:神经结构不同、训练数据不同、训练算法不同,最关键的是优化目标完全不同。人类神经系统,是为丛林生存、部落协作而优化的;而 LLM 是为模仿人类文本、在数学谜题中拿分、在 LM Arena 里获得点赞而优化的。
一旦某些领域具备可验证性,RLVR 就会在这些区域「长出尖刺」。于是我们看到的,是一种锯齿化(jagged)明显的能力分布:它们可以在某些领域表现得像博学的天才,同时又在另一些地方像困惑的小学生,甚至轻易被 jailbreak 套走隐私数据。

我很喜欢一张 meme:人类智能是蓝色曲线,AI 是红色曲线。它也提醒我们:人类智能本身,同样是锯齿状的,只是形状不同。
这也解释了我在 2025 年对基准普遍不当回事与不信任。问题在于:基准测试本质上就是可验证环境,因此天然容易被 RLVR 或弱化版本的「合成数据训练」所攻破。
在现实中,模型团队往往会在基准所在的嵌入空间附近「培育能力突起」,把 jaggies 精准地长到测试点上。「在测试集上训练」已经演变成了一门艺术。
那么问题来了:如果一个模型碾压了所有基准,却依然不是 AGI,那意味着什么?
Cursor:LLM 应用的新一层
Cursor 在 2025 年的爆发本身就很惊人,但对我而言,更重要的是:它清晰地揭示了一种全新的 LLM 应用层。
人们开始说,「这是某某领域的 Cursor」。在我今年 YC 演讲中提到过:像 Cursor 这样的 LLM 应用,本质是在为特定垂直领域打包和编排 LLM 能力:
- 上下文工程(context engineering);
- 在后台编排多次 LLM 调用,形成越来越复杂的 DAG,同时平衡成本与性能;
- 提供面向人的、领域专用的 GUI;
- 提供「自主性滑块」(autonomy slider)。
2025 年围绕着一个问题出现了大量讨论:这一层会有多厚?LLM 实验室会不会吞掉所有应用?还是说,LLM 应用层依然有广阔空间?
我个人的判断是:基础模型会趋向于「一个通用能力很强的大学毕业生」,而真正把他们组织成专业团队、在具体行业中落地的会是应用层,通过私有数据、传感器、执行器和反馈回路将模型组织并投入实际工作流程」。
Claude Code:住在你电脑里的 AI
Claude Code(CC)是我第一次觉得:「这才像一个真正的 LLM Agent。」它以循环方式将推理与工具调用串联起来,能持续解决长任务。
更重要的是:它运行在你的本地电脑上,直接使用你的环境、数据和上下文。
我认为 OpenAI 在这里判断失误了:他们把 agent /codex 的重心放在云端容器、由 ChatGPT 统一调度;而在一个能力锯齿、起飞缓慢的世界里,更合理的顺序其实是先让 agent 成为开发者身边的伙伴。
Claude Code 在这点上做对了,并且用一个极其优雅、极简、极具说服力的 CLI 形态呈现出来。
AI 不再只是一个你访问的网站,而是一个住在你电脑里的小幽灵。
这是一次全新的交互范式转变。
Vibe Coding(氛围编程)
2025 年,是 AI 跨过某个关键门槛的一年:人们可以只用英语构建复杂程序,甚至忘记代码本身的存在。
有趣的是,「vibe coding」这个词,最早只是我一条随手写的推文,完全没想到会流传这么广。
Vibe coding 让编程不再只是专业工程师的专利,任何人都可以上手;但同时,它也让专业工程师可以写出大量原本永远不会被写出来的软件。
在 nanochat 项目中,我直接用 vibe coding 写了一个高效的 Rust BPE tokenizer;我用它快速写了很多 demo 项目(比如 menugen、llm-council、reader3、HN time capsule);甚至为了定位一个 bug,我会 vibe coding 一个临时应用,用完即弃。
代码变得不值钱、短暂存在、并可随意改写与丢弃。
Vibe coding 在重塑软件形态之外,也会重塑工作角色。
Nano Banana:LLM 的 GUI
Google Gemini 的「Nano Banana」,是 2025 年最让我震撼的模型之一。
在我的世界观里,LLM 是类似 1970–80 年代计算机的新一代通用计算范式,因此我们必然会看到类似的演化路径:
- 个人计算
- 微控制器(认知核心)
- Agent 网络(类似互联网)
而在 UI/UX 层面,「聊天」就像 80 年代的命令行。文本是计算机最偏好的表示形式,但并不是人类最喜欢的输入方式。人们更喜欢视觉化、空间化的信息 —— 这正是 GUI 出现的原因。
同理,LLM 也应该用我们偏好的形式与我们交流:图片、信息图、幻灯片、白板、动画、网页应用……
Emoji 和 Markdown 只是最早期、最粗糙的尝试。那么,谁会构建真正的 LLM GUI?在我看来,Nano Banana 是一个非常早期但重要的信号。
它的意义不只在于图像生成,而在于:文本、图像与世界知识在同一模型中深度纠缠。
最后总结
2025 年,是一个令人兴奋、也充满意外的大模型之年。
LLM 正在显现出一种全新的智能形态:它们既比我预期的聪明得多,又比我预期的愚蠢得多。
但无论如何,它们已经极其有用,而我认为行业甚至还没有发挥出它们 10% 的潜力。
想法太多,空间太大,这个领域仍然是开放的。
正如我今年在 Dwarkesh 播客中说过的那样:
我一方面相信进展会持续且迅猛,另一方面也清楚,还有大量艰苦而细致的工作要做。
「系好安全带」,接下来只会更快。
原推链接:https://x.com/karpathy/status/2002118205729562949
.....
#BED-LLM
苹果新研究:不微调、不重训,如何让AI提问效率暴增6.5倍?
在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 FastVLM。
近日,苹果与牛津大学和香港城市大学合作的一项新研究吸引了不少关注。其中提出了一种名为 BED-LLM 的新方法,能让 AI 解决问题的能力直接提升 6.5 倍(成功率从 14% 暴增至 91%),而整个过程无需微调或重新训练,直接在当前模型上运行即可。
而实现这一突破的关键,便是让 AI 学会问出完美的问题。
那么,究竟该如何做到这一点呢?
- 论文标题:BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
- 论文地址:https://arxiv.org/abs/2508.21184
这要从 LLM 的一个不足之处说起,即难以智能且自适应的方式主动从用户或外部环境中获取信息。这就像是 LLM 的「多轮遗忘症」。
具体而言,虽然现代 LLM 通常能够一次性生成连贯且富有洞察力的问题(或其他外部查询),但它们通常难以根据先前在交互式任务中收集到的答案进行适当的调整。比如,已有研究证明,LLM 在多步猜谜游戏、任务澄清、IT 任务自动化以及迭代式外部工具使用等问题上表现不佳。
因此,提高 LLM 自适应地提出问题和有针对性地收集信息的能力是很有必要的。
简单来说,LLM 仅仅基于其庞大的知识库一次性生成好问题是不够的。真正的智能体需要能根据用户的实时反馈,动态调整策略,精准地提出下一个最有价值的问题 。
BED-LLM:让提问成为一门科学
牛津、苹果和香港城市大学的这个联合团队提出,可以使用序贯贝叶斯实验设计(Bayesian experimental desig/BED)框架来解决这一问题。
该框架提供了一种基于模型的信息论机制,可用于在给定实验的生成模型的情况下做出自适应设计决策。
具体而言,该团队展示了如何将使用 LLM 进行交互式信息收集的问题表述为一个序贯实验设计问题,其中有一个迭代过程:
- 每次选择要问的问题(query),都要尽量最大化预期信息增益(Expected Information Gain, EIG)。
- 根据用户的回答更新信念(belief)。
- 再基于新的信念选择下一步要问的问题。
这就像科学实验:一步步设计实验、收集数据、更新假设,而不是一次性问到底。
这里,构成序贯 BED 程序的底层生成模型源自 LLM,该团队特别展示了该模型的构建方式,并为关键设计决策提供了广泛的见解。
该团队将这种方法命名为 BED-LLM,即 Bayesian Experimental Design with Large Language Models。
这种名为 BED-LLM 的方法之所以高效,源于其背后三重智慧的巧妙设计:
智慧一:追求真正的信息增益,而非表面上的不确定性
过去的方法常常让 AI 选择自己「感觉最不确定」的问题,但这并非最优解。BED-LLM 的核心是精确计算 EIG,确保问题能带来最大价值。
论文中一个生动的例子可以说明这一点 :假设 AI 想了解你的电影偏好,它有两个问题可选:
- 问题 A:「你最喜欢什么口味的冰淇淋?」
- 问题 B:「你最喜欢哪种电影类型?」

对于问题 A,AI 可能完全猜不到答案(即预测熵很高),但这个答案对于了解你的电影品味毫无帮助(EIG 为 0) 。而问题 B 的答案虽然也不确定,但无论你回答「科幻」还是「喜剧」,都能极大地帮助 AI 缩小猜测范围,因此它的 EIG 非常高 。BED-LLM 正是基于这种原则来选择问题的。
智慧二:强制逻辑自洽,纠正 LLM 的遗忘症
研究发现,即便是 GPT-4o 这样顶尖的模型,在多轮对话中也常常会忘记之前的约束,提出与历史回答相矛盾的假设 。
BED-LLM 引入了先采样后过滤 (sample-then-filter) 策略来解决这个问题。
它首先让 LLM 生成一批可能的答案(例如,在猜名人游戏中生成多个候选人),然后用一个「逻辑过滤器」逐一检查这些答案是否与用户之前的所有回答都兼容,将不符合逻辑的选项直接剔除。这确保了 AI 的每一步推理都建立在已知的事实之上。
智慧三:生成问题有的放矢,而非天马行空
在生成候选问题时,BED-LLM 采用了一种更具针对性的条件生成 (Conditional generation) 策略 。它会先参考当前已经过筛选、逻辑自洽的假设池,然后让 LLM 提出能够最高效「切分」这些假设的问题 。这使得提问从一开始就目标明确,直指核心。

结果如何?
为了验证 BED-LLM 的效果,研究团队将其与两种主流基准进行了对比:
- Naive QA:完全依赖 LLM 的「直觉」来提问。
- Entropy:采用简化的 EIG 版本,即只考虑预测不确定性的方法 。
结果显示,无论是在「20 个问题」猜谜游戏还是电影偏好推荐任务中,BED-LLM 的表现都全面超越了基准方法 。
具体而言,该团队首先发现,BED-LLM 在各种 LLM 和目标数量下,显著提升了 20 个问题问题的成功率。例如,在使用 Mistral-Large 预测名人时,该团队观察到成功率从 14% 提升至 91%。

其次,该团队展示了 LLM 在电影推荐方面取得的显著改进,表明即使 LLM 的预测模型与回答者的预测模型不同,这些优势依然有效。

更具现实意义的是,研究团队还进行了一项「模型跨服聊天」的压力测试:让提问的 AI 和回答的 AI 使用完全不同的模型(例如,提问方是 Qwen,回答方是 GPT-4o-mini)。
这种设置更贴近真实世界,因为用户的思维模型与 AI 本就不同。即便在这种「模型失配」的情况下,BED-LLM 的性能优势依然稳固,展现了其强大的稳健性。

总而言之,这项研究为我们展示了如何通过严谨的数学框架,将 LLM 从一个被动的知识问答库,转变为一个主动、高效、且具备逻辑推理能力的信息收集者。这或许预示着,未来的 AI 交互将不再是简单的一问一答,而是真正意义上的「智慧对话」。
.....
#Learning Curves
Scaling Laws起源于1993年?OpenAI总裁:深度学习的根本已揭秘
AI 也要「考古」式科研?
人工智能的「第一性原理」扩展定律(Scaling Laws),把模型性能与算力等资源投入联系在了一起,是如今人们构建更先进大模型重要的参考标尺。
有关扩展定律的起源,存在很多种说法,有人认为是 2020 年 OpenAI 提出的,有人认为是 2017 年百度发现的,详情可参阅我们之前的报道《遗憾不?原来百度 2017 年就研究过 Scaling Law,连 Anthropic CEO 灵感都来自百度》。
前些天,康奈尔大学博士生、Meta 研究员 Jack Morris 发推称 Scaling Law 的真正探索者其实是贝尔实验室,这又进一步将历史向前推到了 1993 年。

他进一步解释说,这篇论文其实是一篇 NeurIPS 论文。贝尔实验室的研究者「在不同大小的数据集、不同大小的模型上训练了分类器并拟合了幂律」。这让 Morris 不禁感叹:「不敢相信这已经是 32 年前的事了。」

近日,OpenAI 联合创始人、总裁 Greg Brockman 也转发了这一消息,并表示这些结果跨越了多个数量级和几十年的时间,经历了时间的考验,可以说揭示了深度学习的根本。

这也不得不让人赞叹贝尔实验室的前瞻性和众多开创贡献:

贝尔实验室的 Scaling Law
回到人们正在讨论的这篇论文本身。它是一篇 AI 顶会 NeurIPS 论文:
- 论文标题:Learning Curves: Asymptotic Values and Rate of Convergence
- 论文链接:https://proceedings.neurips.cc/paper/1993/file/1aa48fc4880bb0c9b8a3bf979d3b917e-Paper.pdf
这篇论文介绍说,基于大规模数据训练分类方法是相当耗费算力的工作。因此,开发高效的程序来可靠地预测分类器是否适合执行给定任务至关重要,这样才能将资源分配给最有潜力的候选分类器,或腾出资源来探索新的候选分类器。
作者提出了一种实用且有原则的预测方法,避免了在整个训练集上训练性能较差的分类器的高成本过程,同时拥有坚实的理论基础。作者证明了所提方法的有效性,以及适用于单层和多层网络。
在该工作中,作者研究了自动分类的算法,随着训练数据逐步增加,分类器的能力(模型出错的概率)被持续标记。在测量了多个数据点后,可以发现模型的错误率对比训练数据的数量,在对数曲线上呈现出了一定的规律。

作者进而得出结论:「经过 12000 种模式的训练后,很明显新网络的表现将优于旧网络…… 如果我们的预测方法能够对网络的测试误差做出良好的定量估计,我们就可以决定是否应该对新架构进行三周的训练。」
这就意味着模型的规模扩大,AI 的智能会越来越强;而这就是 Scaling Law(扩展定律)!
从几万条数据训练的机器学习模型开始,到去年 GPT-4 上万亿巨量数据集、万亿参数的规模,几十年来,扩展定律一直有效。
作者介绍:从「国宝」到「疯狂科学家」
这篇论文一共有 5 位作者:Corinna Cortes、L. D. Jackel、Sara A. Solla、Vladimir Vapnik、John S.Denker。各自都有自己的传奇经历。
Corinna Cortes
这篇论文的一作 Corinna Cortes 已经拥有超过 10 万引用!她与四作 Vladimir Vapnik 也是经典论文《Support-vector networks》(引用量超过了 7.7 万)的两位作者。这篇论文提出了大家熟知的现代意义上的支持向量机。

另外,她还与 LeCun 等人一起构建了著名的 MNIST 数据集,而这也成为了后续大量研究的重要基础数据集。
也无怪乎有人在评论区称她是「国宝」:

Corinna Cortes 的职业履历很简单:先在贝尔实验室工作了 14 年,之后于 2003 年加入谷歌,领导 Google Research NY 达 21 年之久。现在她是 NeurIPS 的董事会成员之一。她同时也是一名竞技跑步运动员。
Lawrence D Jackel
这篇论文的二作 Lawrence D Jackel 是时任的贝尔实验室应用系统研究部门负责人。1988 年 Yann LeCun 加入该实验室后,与他合作完成了多项高引用研究成果,其中包括一篇重要的反向传播论文《Backpropagation applied to handwritten zip code recognition》。

Sara A. Solla
Sara A. Solla 则是一名物理学家和神经科学家。她最高引用的论文也是与 Yann LeCun 合著的《Optimal brain damage》。
该论文运用信息论的思想,推导出了一类用于调整神经网络规模的实用且近乎最优的方案。通过从网络中移除不重要的权重,可以预期实现多项改进:更好的泛化能力、更少的训练样本需求以及更快的学习和 / 或分类速度。其基本思想是利用二阶导数信息在网络复杂度和训练集误差之间进行权衡。

Vladimir Vapnik
前文我们已经见到过 Vladimir Vapnik 的名字,即支持向量机的作者之一。除此之外,这位拥有超过 33.5 万引用的大佬还是统计学习领域著名的 Vapnik–Chervonenkis 理论的提出者之一 —— 是的,这个理论就是以他和苏联数学家 Alexey Chervonenkis 的名字命名的。
Vladimir Vapnik 在 1995 年出版的 《The Nature of Statistical Learning Theory》是系统化提出统计学习理论(Statistical Learning Theory, SLT)的代表作,堪称机器学习领域的里程碑。

John S. Denker
John S. Denker 则更是一位多才多艺的研究者,涉足过大量不同领域,甚至可以说是天才(Genius)的代名词。

他曾就读于加州理工学院。大三时,他创办了一家成功的小型软件和电子公司,在安防系统、好莱坞特效、手持电子游戏和视频游戏等多个领域做出了开创性的工作。此外,在读本科期间,他还在加州理工学院创建并教授了一门课程:「微处理器设计」。
他在康奈尔大学的博士研究考察了氢原子气体在仅比绝对零度高千分之几摄氏度的温度下的性质,并表明在这种稀薄的玻色气体中存在量子自旋输运和长寿命的「自旋波」共振。他的其他研究涉及超低噪声测量设备的设计 —— 其中基本的量子力学限制起着重要作用。
Denker 博士加入过 AT&T 贝尔实验室多年时间,曾担任杰出技术人员、部门主管和部门经理等职务。他的研究兴趣包括计算机安全、选举安全、网络电话和神经网络。他还发明了新型低能耗「绝热」计算系统。
1986 年至 1987 年,他担任加州大学圣巴巴拉分校理论物理研究所客座教授。他曾担任多个重要科学会议的组委会委员。
他拥有多项专利,撰写了 50 多篇研究论文和一本书的章节,并编辑了 《Neural Networks for Computing》一书。他的演讲范围广泛。
他以爱恶作剧和典型的疯狂科学家而闻名。他的一些事迹曾被改编成电影《Real Genius》和《The Age Seeking for Genius》,并刊登在《时代》和《IEEE Spectrum》等刊物上。

John Denker 还拥有商用飞行员、飞行教练和地面教练资格。他是美国联邦航空管理局(FAA)的航空安全顾问。他曾任蒙茅斯地区飞行俱乐部董事会成员,以及美国国家研究委员会商用航空安全委员会成员。
Scaling Law 的历史可能还能继续向前追溯
有意思的是,在相关推文的评论区,有不少研究者评论认为贝尔实验室的这篇论文其实也不是 Scaling Law 的最早论文。
比如著名研究者、科技作家 Pedro Domingos 表示其实心理学领域才是最早探索「学习曲线」的领域。

研究者 Maksym Andriushchenko 表示 Vladimir Vapnik 在上世纪 60 年代就已经研究过样本大小方面的 Scaling Law。

而 @guillefix 则表示 Frank Rosenblatt 在 1958 年发表的感知器论文《The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain》就已经给出了非常清晰的学习曲线。

此外,𝕏 用户 @lu_sichu 提出了 1992 年日本工程师和神经科学家甘利俊一(Shun-ichi Amari)写的论文《A Universal Theorem on Learning Curves》也比贝尔实验室的上述论文更早一些。

其中证明了一类普适的学习曲线渐近行为,适用于一般的无噪声二分机器或神经网络。结果表明:无论机器的架构如何,其平均预测熵或信息增益 <e*(t)> 都会在训练样本数 t 增加时收敛至零,并满足 <e*(t)> ~d/t 的规律,其中 d 为机器的可调参数的个数。

纵观数十年的研究脉络,Scaling Law 的提出并非灵光乍现的顿悟,而是跨越学科、跨越时代的逐步累积。从心理学的学习曲线,到感知器的早期探索,再到 Vapnik、Amari、贝尔实验室的系统化研究,最后发展到 OpenAI 等机构在大规模实验中验证和推广,每一代学者都在为这条「经验定律」添砖加瓦。
今天我们所说的 Scaling Law,看似清晰而坚固,但它背后蕴含的是数十年理论与实践的反复印证。正如 Brockman 所言,它揭示了深度学习的根本,而这一「根本」并不是一蹴而就的,而是科学探索在时间长河中的积累与沉淀。
对此,你怎么看?
.....
#Stepwise Reasoning Checkpoint Analysis
告别无效计算!新TTS框架拯救19%被埋没答案,推理准确率飙升
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
为解决这些问题,华为诺亚方舟实验室联合香港中文大学等机构的研究人员提出逐步推理检查点分析(SRCA)框架 —— 在推理步骤间引入 “检查点”,并集成两大核心策略:(1)答案聚类搜索(Answer-Clustered Search):根据中间检查点答案对推理路径进行分组,在保证质量的同时维持路径多样性;(2)检查点候选增强(Checkpoint Candidate Augmentation):利用所有中间答案辅助最终决策。
实验结果表明,在多个数学数据集上,如 MATH500 和 OlympiadBench,SRCA 相较于现有 TTS 方法,推理准确性均有提升。该论文已被 EMNLP 2025 接收。
- 论文题目:Stepwise Reasoning Checkpoint Analysis: A Test Time Scaling Method to Enhance LLMs' Reasoning
- 论文链接:https://arxiv.org/abs/2505.17829
Test Time Scaling(TTS)技术简单来说就是在模型测试阶段 "砸资源":不改变模型本身,而是通过增加推理时的计算开销,让 LLM 在解题时 "多想一会儿",从而显著提升推理准确性。除了常见的长思维链,比如 DeepSeek R1 典型的 think 模式,多次采样并有策略的搜索正确解题路径也是一种常见的 TTS 策略。
我们常用的多数投票 / 自我一致性(Self-Consistency)可以视为是最朴素的 TTS 技术。比如让模型对一道数学题生成 10 个推理过程,最后选出现次数最多的答案。这种看似简单的方法,却能显著提升模型推理的准确率 —— 代价是多花几倍计算时间。
随着任务难度提升,这种暴力提升采样次数的做法效率越来越低。于是研究者们引入了额外的打分模型,比如一个过程奖励模型(PRM),从而开发了更先进的 TTS 算法。

- Beam Search:(左图)每次采样得到的路径由 PRM 打分,保留得分最高的 k 条推理路径继续深入,避免在错误方向浪费资源;
- DVTS(Diverse Verifier Tree Search):(右图)同时维护多个独立的推理树,每棵树向下探索 PRM 打分最高的路径。强迫模型探索不同解题思路,减少 "一条道走到黑" 的风险。
不过这类方法仍然存在两个问题。
两大痛点
- 思路太单一:明明生成了多条推理路径,最终却都往一个方向扎堆(路径同质化)。这是由 PRM 的局限性带来的:并不完美的 PRM 打分具有隐式的偏好,选出的路径往往具有一定的共性。这有时会导致一些思路不同但并未出错的解题路径打分略低未能被继续探索。
- 中间结果浪费:推理过程中产生的大量中间过程被直接丢弃。以 Beam Search 为例,假设采样次数为 16,束宽为 4,则采样中 75% 的步骤将被直接丢弃。这其中不乏一些优质的正确的解题思路,但是这些中间过程并未有效贡献到最终答案的决策中。
我们的解法:给推理过程 "设检查点"
针对这些问题,我们提出了 SRCA(Stepwise Reasoning Checkpoint Analysis) 框架,该框架包含三个关键组件:
- 检查点注入:强制模型在每一步推理后暂停并输出阶段性答案。
- 答案聚类搜索:把检查点答案一样的推理路径归为一组,并从每组内选择路径继续推理。
- 检查点候选增强:收集所有检查点答案加入到最终答案的选择。
下面是每个组件的具体介绍。
检查点注入(Checkpoint Injection):打断推理并预测答案

检查点注入是 SRCA 的基础技术,后续的 ACS 和 CCA 算法全部依赖于检查点注入收集到的中间答案,核心思路是强制模型在每一步推理后暂停并输出阶段性答案。早期的工作中亦有类似的探索,chain-of-probe (https://aclanthology.org/2025.findings-naacl.140/) 同样是利用暂停推理收集答案的思路观测模型推理时置信度 (confidence) 的变化以判断模型推理是否准确。而检查点注入则更关注模型阶段性推理的答案本身,具体流程如下:
- 检测步骤结束符(如 "### Step"):当检测到此类字段时,说明 LLM 的上一步推理已经结束,可以进行答案检查。
- 插入提示 "So the answer is":我们通过插入后缀强行改变上下文,模型沿着新的上下文继续解码,输出它所认为的答案。
- 记录检查点答案:该答案是我们后续改进搜索策略和投票的重要依据。
通过这样的方式,我们可以收集到模型基于当前推理步骤得出的答案。这种 “中间答案” 尽管并不完整和精确,但它们在一定程度上可以代表模型在当前的思考过程,比如两条推理路径得出的中间答案是一样的,我们则可以认为这两条推理路径目前解题的思路和进度是类似的。收集到中间答案后,通过合理的 KV Cache 管理,我们可以将推理状态回滚到上一步推理结束的时刻,从而避免反复推理降低计算开销。
答案聚类搜索(ACS):防止 “思路扎堆”,鼓励不同解法

基于检查点答案,我们重新设计了路径搜索策略,提出了 Answer Clustering Search 算法。传统方法(如 Beam Search)虽然让模型尝试多条路,但 PRM 打高分的路径往往类似,这就容易提前扼杀搜索路径的多样性,导致最终错过可能的正确答案。
针对路径同质化问题,ACS 在检查点执行双层筛选机制:
- 组内择优:将同中间答案的路径归组,按组内 PRM 总分排序
- 组间竞争:采用轮询调度(Round-Robin),按总分顺序从每组抽取最优路径
这样保证了不同解题方向(不同组)都有机会保留至少一条 “种子选手” 继续发展。即使某一种方法(组)目前分数不是最高,只要它整体有潜力,它最好的那条路也有机会被选上。这就大大增加了解题思路的多样性,避免大家一窝蜂挤到一条(可能错的)思路上。
检查点候选增强(CCA):抢救 “半成品好答案”,变废为宝

在传统树搜索(如 Beam Search / DVTS)中,只有那些最终走完全程的路径才有资格参与最终答案的评选。大量未完成的中间推理步骤被直接丢弃。CCA 通过收集复用这些未完成路径的检查点答案提升模型推理的准确性:
- 在每一步推理之后,记录收集所有的检查点答案。
- 即使一条路没走完,它在某个步骤得出的那个中间答案,也可能是最终答案。所以 CCA 会把每个中间答案连同它走到这一步的推理过程,都打包成一个独立的候选答案。这就像把那些半成品抢救出来。
- 当所有路径都推理结束后(无论是走完还是被淘汰),最终的答案评选不再是只看那几条 “完整” 路径的最终答案。CCA 会把所有收集到的这些 “半成品答案” 和完整路径的最终答案,全部放在一起,根据 PRM 的打分选择最高者。
这样极大减少了 “好答案被中途埋没” 的情况。即使模型后面推理跑偏了,只要它在某个步骤 “灵光一现” 得出了正确结果,CCA 就能把它捞回来,给模型一个 “后悔药”。这大大提高了计算资源的利用率。下面是一个具体的示例:

如图所示,模型推理完成得到的答案是 9,而正确答案是 27。但回顾推理过程中的检查点答案可以发现,模型在第 4 和第 5 步已经得出了 27 这个答案,而错误出在第 6 步 ——9 是一个完全平方数而不是平方立方数。而 CCA 记录收集了所有检查点答案,并综合考虑所有候选答案选出最终结果。可以看到第 5 步的检查点答案得到了最高分 0.7192,该答案被 CCA 恢复并修正了错误答案。
实验结果
TL;DR:
- SRCA 框架加持的 1B 小模型在 MATH500 数据集上达到 65.2% 准确率,首次超越参量 70 倍的 70B 大模型(65.0%)
- 通过答案聚类搜索(ACS)优化路径多样性,SRCA 仅需 16 次采样即可达到其他 TTS 方法 128 次采样的精度。在同等硬件条件下,推理效率提升达 8 倍,从而降低计算成本。
- 检查点候选增强(CCA)策略成功从中间步骤拯救 19.07% 的正确答案。这些答案诞生于推理中途,却因后续路径偏差被丢弃。CCA 通过复用高质量中间结果,构建了强大的错误容忍机制。
- 设置合理阈值,当候选池中出现超过阈值的检查点答案即停止推理输出答案,平均可节省 27% 的推理步骤,推理准确率轻微下降 0.58%。
.....
#语音分离最全综述来了
清华等团队深度分析200+文章,系统解析「鸡尾酒会问题」研究
语音分离领域针对具有挑战性的 “鸡尾酒会问题”,随着深度神经网络 (DNN) 的发展,该领域取得了革命性的进展。语音分离可以用于独立应用,在复杂的声学环境中提高语音清晰度。此外,它还可以作为其他语音处理任务(如语音识别和说话人识别)的重要预处理方法。
为了应对当前的文献综述往往只关注特定的架构设计或孤立的学习方法,导致对这个快速发展的领域的理解碎片化的现实情况,清华大学、青海大学、南京大学、南方科技大学、中国科学院大学、字节跳动的研究者们全面调研了该领域的发展和最前沿的研究方法,在深度学习方法、模型架构、研究主题、评测指标、数据集、工具平台、模型效果比较、未来挑战等多个维度,撰写了一项统一、全面的综述论文,对 200 余篇代表性论文进行了系统归纳和分析。

表1 基于深度学习的语音分离最新调查与综述的比较分析
- 论文链接:https://arxiv.org/abs/2508.10830
- Methods Search:https://cslikai.cn/Speech-Separation-Paper-Tutorial/
- Github链接:https://github.com/JusperLee/Speech-Separation-Paper-Tutorial
问题定义
作者们从语音分离领域的宏观角度出发,根据混合说话人数量是否已知将已知人数分离和未知人数分离两类。当说话人数固定且已知时,网络输出固定个数的通道,可以通过深度聚类 (Deep Clustering) 或 Permutation Invariant Training(PIT,排列不变训练)等策略解决输出顺序不确定的 “排列歧义” 问题。对于未知人数的情况,模型需要动态决定输出通道数并判断何时结束分离。这带来巨大挑战:如说话人排列组合随人数增加呈指数扩展、需要在分离质量与终止时机之间权衡避免欠分离或过分离等。为应对这些问题,研究者提出了递归分离、动态网络等框架来逐步提取不定数量的声源。作者们从问题定义部分明确了语音分离任务的目标和难点,为后续技术讨论奠定了基础。

图 1 已知 / 未知声源数量的语音分离概述。
学习范式
作者们分类总结了学习范式,比较了不同方法的适用场景和优缺点,为读者理解监督与非监督方法在语音分离中的权衡提供了清晰脉络。重点对比了有监督和无监督(含自监督)学习方法。有监督学习利用配对的混合音频及纯净源音频进行训练,是目前最成熟的范式。针对有监督训练中不同源输出无法一一对应的标签置换问题,研究者提出了两类经典方案:
一是深度聚类方法(DPCL),通过神经网络将混合语音的时频单元映射到高维嵌入空间,再将嵌入向量聚类以生成每个声源的掩膜,从而避免直接输出固定顺序的源信号;
二是 Permutation Invariant Training(PIT)方法,在训练时对网络输出的来源标签进行动态匹配,只保留误差最小的排列来更新模型,从而使网络学习到与输出排列无关的分离能力。

图 2 受监督的语音分离工作流程。
无监督学习则不依赖配对的干净源参考,探索利用未标注的混合语音直接训练分离模型。例如,MixIT(混合 - 分离训练)方法通过将两段混合语音再混合作为输入,让模型输出更多分量并设计损失函数仅依赖输入混合物,实现无需纯净源标签的训练。这类方法以及基于生成模型的自监督策略(如变分自编码器 VAE 方法、扩散模型等)为无法获得干净训练数据的场景提供了新思路。
模型架构
模型架构部分系统总结了语音分离模型的核心组成和演进路线。典型架构包含编码器、分离网络和解码器。

图 3 不同方案的发展脉络
综述按网络类型归纳了主要的分离器架构:
基于 RNN 的模型利用循环神经网络擅长捕获语音信号中的长时依赖关系。早期很多方法在频域用双向 LSTM 生成掩膜;后来出现直接处理时域波形的端到端模型(如 TasNet 系列 ),避免了相位重建难题并提升效率。代表性的 Dual-Path RNN(双路径 RNN)通过划分长序列为短块并在块内和块间双路径循环处理,高效建模长序列,被视为 RNN 架构的里程碑。
基于 CNN 的模型利用卷积神经网络强大的局部特征提取能力,适合直接对原始波形建模。Conv-TasNet 等时域卷积模型通过空洞卷积等技术兼顾短时细节和长程依赖,在无需频域处理的情况下取得了优异分离效果。基于自注意力的模型(Transformer 及其变种)引入了全局序列建模能力,在语音分离中用于捕获长距离依赖并建模复杂场景下源间关系。
近年来出现的 SepFormer 等 Transformer 架构进一步刷新了分离性能。还有混合架构将上述优势结合,例如将 CNN 的局部建模和 RNN/Transformer 的长程建模相融合,以兼顾不同尺度的信息。
除了分离网络,综述还讨论了音频重构策略:一类是掩膜估计,即模型输出每个源的时间频率掩膜,乘以混合后再重建源信号;另一类是直接映射,即模型直接输出各源的波形或特征表示。掩膜方法简单直观且易于结合频域特征,而直接法避免误差传播,有望获取更高保真度。
总体而言,本节脉络清晰地展现了模型架构从早期循环网络到卷积、再到自注意力和混合模型的演进,以及各种重构方式的权衡,凸显了架构创新对性能提升的驱动作用。
评估指标
评价语音分离效果需要科学全面的指标体系,以便衡量模型性能、指导算法优化并确保满足实际应用需求。该综述将评估指标分为主观和客观两大类。综述对比了各种指标的优劣:主观评价贴近人耳体验但难以大规模获取,客观指标高效客观但各自侧重不同方面,需要结合使用。综合运用主客观评价能够更完整地刻画语音分离系统的性能,为研究和应用提供可靠依据。

表 2 不同评价指标的对比
数据集
公开数据集为语音分离研究提供了标准测试,他们按照单通道和多通道对主流数据集进行了总结。通过对数据集的梳理,研究者可以了解各数据集所覆盖的场景和难度,有助于选择合适的数据集来评估算法并发现当前研究还未覆盖的场景(例如更长时段对话、开放域噪声环境等),从而指导未来数据收集和模型开发。

表 3 不同数据集的比较
实验结果
他们汇总了不同模型在各标准数据集上的分离性能对比,勾勒出语音分离技术近年来的进步轨迹。作者列举了众多具有代表性的模型在若干公开基准上的评测结果,并通过图表展示性能随时间的提升趋势。
例如,在经典数据集 WSJ0-2mix 上,早期模型(如 DPCL、uPIT-BLSTM 等)能达到约 10 dB 的 SDR;随后基于深度学习的端到端模型(如 Conv-TasNet)将性能推升到 12 dB 以上;最近两三年的先进架构(如 SepFormer、DPRNN 系列、双路 Transformer 等)更是将 SDR 提升到 20 dB 左右,接近定量评测所能达到的上限。这些结果直观证明了架构创新和训练范式改进对分离效果的巨大推动作用。
不仅如此,综述还比较了模型在不同数据集上的表现差异:例如在含噪声混响的 WHAM! 和 WHAMR! 上,模型性能相对无噪条件下降明显,说明噪声鲁棒性仍是挑战;这种多维度的结果对比帮助读者了解各类方法的优势和局限:有的模型在干净近场语音下接近完美,但在远场或噪声场景下性能下滑;有的方法擅长分离两三人对话,但扩展到更多说话人时代价巨大。通过统一的结果汇总与分析,作者提供了对当前最先进技术水平的客观评估,并据此指出了亟待攻克的薄弱环节。

图 4 语音分离模型在 WSJ0-2mix 上随时间的变化表现
工具平台
为了推动研究复现和应用落地,综述还介绍了当前常用的开源工具和平台,这些软件库为语音分离任务提供了便利的开发接口和训练框架。对比了各工具的功能侧重点,例如有的注重学术研究易用性,有的侧重工业优化和实时性能,也指出了当前工具链存在的局限,如对最新算法的支持仍需跟进等。通过了解这些平台,研发人员可以更高效地复现论文结果、搭建原型系统,加速从研究到应用的转化。

表 4 不同开源工具的对比
挑战与探索
在对现状全面总结的基础上,深入讨论了语音分离领域当前存在的热点难题和未来可能的探索方向。
首先,长时段音频处理,在实际应用中(如会议记录、连续对话)需要处理数分钟甚至更长的音频,如何在保证分离连续性的同时控制模型复杂度和内存开销。
其次,移动端和嵌入式应用要求分离模型具备较小的参数量和计算量,因此研究者正探索剪枝、量化、知识蒸馏以及新的高效架构(如高效卷积、高效自注意力等)来减小模型体积,同时维持性能。
第三,因果(实时)语音分离也是热点之一:实时通信和在线处理要求算法只能利用当前及过去帧的信息,不能窥视未来,这对模型的延时、缓存机制提出严格要求。如何在严格的因果约束下仍然取得接近离线模型的分离效果。
第四,生成式方法的崛起为语音分离提供了新思路:包括生成对抗网络(GAN)和扩散模型在内的新型生成模型开始用于语音分离,以期生成更逼真的语音并改善分离质量,尤其在弱监督或无监督场景下展示出潜力。
第五,预训练技术正逐步引入本领域:借鉴 ASR 等领域的成功,大规模自监督预训练(如 wav2vec 2.0 等)或基于音频编码器的预训练模型可以提供强大的通用特征,在低资源分离任务上显著提升性能。未来可能出现专门针对语音分离预训练的模型或利用语音神经编码器压缩感知混合信号的新范式。
第六,目标说话人提取作为语音分离的变种也备受关注:即利用已知的目标说话人特征(如说话人注册音频)从混合中提取该说话人的语音,相比盲分离加入了先验信息,如何高效利用目标说话人嵌入并与分离网络融合是研究重点。最后,综述强调了与其他任务的联合建模趋势:语音分离正日益与语音识别、说话人识别 / 分离、语音增强等任务结合,形成端到端的联合优化框架。
.....
#Diffusion Language Models Know the Answer Before Decoding
其实,扩散语言模型在最终解码之前很久,就已确定最终答案
随着扩散语言模型(DLM)在各个领域的快速发展,其已成为自回归(AR)模型有力的替代方案。与 AR 模型相比,DLMs 的主要优势包括但不限于:高效的并行解码和灵活的生成顺序。
尽管 DLMs 具有加速潜力,但在实际应用中,其推理速度仍慢于 AR 模型,原因在于缺乏 KV-cache 机制,以及快速并行解码所带来的显著性能下降。
本文,来自香港理工大学、达特茅斯学院等机构的研究者尝试从一个不同的角度来加速 DLMs 推理,这一思路源于一个长期被忽视却极具潜力的现象:早期答案收敛。
- 论文标题:Diffusion Language Models Know the Answer Before Decoding
- 论文地址:https://arxiv.org/pdf/2508.19982
- 项目地址:https://github.com/pixeli99/Prophet
通过深入分析,研究者观察到:无论是半自回归重掩码还是随机重掩码场景下,有极高比例的样本在解码早期阶段即可获得正确解码。这一趋势在随机重掩码中尤为显著,以 GSMK 和 MMLU 数据集为例,仅需半数优化步骤即可分别实现 97% 和 99% 的样本正确解码。
受此发现启发,该研究提出了 Prophet,一种无需训练的快速解码策略,该策略专为利用早期答案收敛特性而设计。Prophet 通过持续监控解码过程中 top-2 答案候选之间的置信度差距,自适应地判断是否可安全地一次性解码剩余所有 token。
实验表明,该方法在保持高质量生成效果的同时,实现了显著的推理加速(最高达 3.4 倍)。
方法介绍
Prophet 是一种无需训练的快速解码方法,用来加速扩散语言模型的生成。它的核心思路是:在模型预测结果趋于稳定时,一次性提交所有剩余 token 并提前生成答案,这一过程被称为早期提交解码(Early Commit Decoding)。与传统的固定步数解码不同,Prophet 会在每一步主动监测模型的确定性,从而能够即时做出是否终止解码的决策。

早期提交解码。何时终止解码循环的决定可以定义为最优停止问题。在每一步,都必须在两种互相冲突的成本之间权衡:继续执行额外细化迭代的计算成本,与因过早决定而可能带来错误的风险。计算成本取决于剩余步数,而错误风险则与模型的预测置信度呈负相关,其中「置信差距」可作为其稳健指标。
算法 1 概述了完整的 Prophet 解码过程:

实验
实验结果如表 1 所示。
在通用推理任务上,Prophet 展现了与完整基线相当甚至更优的性能。例如,在使用 LLaDA-8B 时,Prophet 在 MMLU 上达到 54.0%,在 ARC-C 上达到 83.5%,两者在统计上均与完整的 50 步解码结果相当。
更有趣的是,在 HellaSwag 上,Prophet(70.9%)不仅超过了完整基线(68.7%),还优于半步基线(70.5%),这表明早期提交解码能够避免模型在后续带噪声的精炼步骤中破坏已正确的预测。
同样地,在 Dream-7B 上,Prophet 在各项基准测试中依然保持了竞争力:在 MMLU 上达到 66.1%,而完整模型为 67.6%,仅有 1.5% 的微小下降,但带来了 2.47 倍的速度提升。
在更复杂的数学和科学基准测试上,Prophet 同样展现了其可靠性。以 GSM8K 数据集为例,基于 LLaDA-8B 的 Prophet 达到 76.8% 的准确率,几乎与完整基线的 77.1% 相当,并且优于半步基线的 76.2%。
总而言之,实证结果强有力地支持了本文的核心假设:扩散语言模型往往在最终解码步骤之前很早就已经确定了正确答案。
Prophet 成功利用了这一现象,通过动态监测模型预测的置信度,一旦答案趋于稳定,便立即终止迭代精炼过程,从而在几乎不影响任务性能的情况下显著节省计算开销,在某些场景下甚至还能提升表现。这与静态截断方法形成了鲜明对比,后者存在过早终止解码、从而损害准确率的风险。
因此,Prophet 提供了一种稳健且与模型无关的解决方案,有效加速 DLM 的推理过程,提升了其在实际应用中的可行性。

了解更多内容,请参考原论文。
.....
#宇树科技官宣:年内提交IPO,或将冲刺科创板
宇树的上市进程,终于又向前迈进了一步。
9 月 2 日晚间,杭州宇树科技股份有限公司(简称「宇树科技」)发布声明说,预计于今年四季度向证券交易所提交上市申请文件,立即引来了大量关注。

完整公告内容如下:
宇树科技自成立以来一直是一家「民用机器人公司」。目前,公司正在积极推进首次公开募股(IPO)的准备工作。根据 IPO 计划,公司预计将在 2025 年 10 月至 12 月期间向证券交易所提交备案文件,届时公司的相关经营数据将会正式披露。
接下来简要介绍一下公司产品的收入结构。我们以 2024 年为例(具体数据应以后续 IPO 备案文件披露的信息为准):
四足机器人、人形机器人及零部件产品的销售额分别约占 65%、30% 和 5%。
其中,大约 80% 的四足机器人用于科研、教育和消费领域,其余 20% 用于工业领域,如检测和消防。人形机器人全部应用于科研、教育和消费领域。
自成立以来,宇树科技一直致力于高性能通用机器人在民用领域不同产业中的应用,并在公司官网、产品手册、合作协议以及各类文件中明确声明和限制相关用途。
特此提醒各方需谨慎识别,不要将其他公司的机器人产品或第三方改装设备误认为宇树产品。
我们希望宇树机器人能够为全世界人民带来更安全、更愉快的生活。
据分析,宇树科技冲击科创板的概率较大。宇树 IPO 的消息令人振奋,有人称「这是机器人领域最值得期待的 IPO 之一」。

宇树科技成立于 2016 年 8 月,此前在今年 7 月,证监会官网信息显示该公司已开启上市辅导,辅导机构为中信证券。备案报告显示,宇树科技控股股东、实际控制人为王兴兴,合计控制公司 34.763% 股权。
此前,宇树科技共宣布了 10 轮融资,最近的 C 轮结束于今年 6 月,由中国移动旗下基金、腾讯、锦秋、阿里、蚂蚁、吉利资本共同领投,估值超过 100 亿元。
作为「杭州六小龙之一」,宇树科技在全球科技领域具有极大影响力,其每次发布的新型机器人、demo 展示都能吸引全网的目光。在xx智能技术快速发展的今天,宇树的资本化进程备受瞩目。
与新兴行业大量创业公司持续亏损的情况不同,宇树的商业化进展也速度惊人。今年就有宇树科技投资人透露说,自 2020 年以来,该公司财务报表每年都保持盈利状态,宇树科技随后也证实了该消息。
据此前统计,宇树科技人形机器人出货量位居全球前列,四足机器狗全球市场占有率更是超过了 60%,大尺寸通用人形机器人业务范围覆盖全球 50% 以上的国家和地区。
在 6 月份,宇树科技创始人王兴兴曾在夏季达沃斯论坛上表示,宇树科技年度营收已超 10 亿元人民币,公司规模达到约 1000 人。
在对未来机器人技术落地的展望中,宇树科技也保持了乐观。在今年 8 月世界机器人大会上,王兴兴表示,未来几年,全球人形机器人行业出货量可以达到每年翻一番的水平。在出现更大技术突破的情形下,未来 2 到 3 年的年出货量可达到几十万台。
随着不久之后宇树科技 IPO 申报文件的提交,其研发投入占比、订单转化率等关键数据将被揭晓,这不仅关系到宇树的估值,也可以让我们为机器人大规模落地的真实进度做出具体的判断。
自春晚扭秧歌秀以来,宇树机器人便受到了前所未有的关注。最近一段时间,宇树科技正在不同的赛场检验自身机器人的成色,比如在 2025 年首届世界人形机器人运动会中,夺得了 1500 米、400 米、100 米障碍赛、4×100 米赛事的金牌。
图源:Unitree 宇树公众号
这几天,宇树格斗机器人 G1 首次出现在 UFC 赛场,大放光彩。

如今,在优必选成为人形机器人第一股之后,宇树科技也积极推进上市进程,以期进一步巩固其在四足机器人和通用人形机器人领域的领先地位。
安全同样重视
在宣布准备 IPO 的同时,宇树科技也对仿生机器狗 Go1 进行了安全声明。

关于近期部分博主声称 Go1 机器人存在后门漏洞的情况,宇树科技的内部调查结果如下:
经检查和复现,该问题被确认为一起安全漏洞。黑客非法获取了 Go1 使用的第三方云端隧道服务的管理密钥,并利用其在用户设备上以高权限修改数据和程序,从而获得操作控制权和视频流访问权限,威胁到了用户隐私与安全。该密钥由第三方云服务商「Zhexi Cloud」提供、存储和认证。
Go1 机器狗系列发布于 2021 年(已停产约两年),实际在线使用的数量极少。并且,机器人默认不联网,需用户主动设置才可联网。此后推出的机器人系列均未再采用该方案,而是使用更安全的升级版本,因此不受影响。
针对此类漏洞,宇树科技已在 2025 年 3 月 24 日更换了该隧道服务的管理密钥,并在 3 月 29 日彻底关闭了该隧道服务。此问题将不再影响 Go1 系列产品的使用。
「如果想要机器人成为我们日常生活的一部分,安全和信任是基础。」宇树科技此次的声明很好地践行了这一点。

.....
#RoboMirage
从复刻魔术开始,RoboMirage打开了机器人仿真的新世界
在xx智能的发展路径中,如何获得海量且高质量的数据是行业绕不开的核心问题。
如果说大语言模型依赖于互联网规模的语料库,那么xx智能的成长同样需要规模化的交互经验。现实中,收集这些数据的代价极高:机械臂等硬件部署成本高,单台投入就需数万元,且难以规模化;数据采集环节依赖经验丰富的数采员且耗时漫长。而在仿真环境中,智能体则可以以更低成本、更高效率进行无限次试错,从而快速积累大规模交互经验。
正因如此,过去几年中,仿真器已经成为xx智能发展的重要支撑工具,也催生出一批优秀的开源与商业化平台。它们让机器人学、强化学习和智能体研究得以快速推进,奠定了行业的基础。
但随着研究不断深入,行业对于数据提出了更高要求:更高的物理精度,以保证数据与现实世界的贴合度;更丰富的交互类型,覆盖刚体、软体、流体等复杂场景;更强的扩展性与稳定性,既支持科研中的微观动力学细节,也能满足产业应用的大规模仿真需求。
在这样的背景下,RoboScience 从零到一自研了面向xx智能的高精度通用物理仿真平台 「RoboMirage」。
,时长01:45
核心特性
「RoboMirage」具有以下核心特性:
1. 全物体类型兼容的可扩展接触建模框架
支持刚体、1D/2D/3D 可形变体、多关节结构及各种机器人末端执行器的多样接触,具备强耦合仿真能力,兼容未来可微仿真与高精度训练需求,且允许用户自定义扩展功能,为多样化场景提供灵活适配的底层架构。
2. 高精度的多体动力学仿真能力
高精度、无穿透且时间一致性的接触力仿真,支持刚体、软体及复杂接触的强耦合动力学模拟(如复杂布料与机器人末端执行器的强耦合互动),可捕捉动静摩擦、细微力变化等微观动力学细节,其精度远超传统动力学模拟器,尤其适配机器人领域的复杂仿真需求。
3. 工业级稳定算法保障
依托隐式积分,凸优化方法等严格数学理论准确求解介质力学问题,从算法层面确保仿真过程的稳定性与时间一致性,捕捉每一个动力学细节,彻底解决穿模问题,可满足装配、抓取等工业级任务对仿真可靠性的严苛要求,为复杂场景提供持续稳定的运行保障。
4. Pythonic 设计,简单易用
框架设计注重用户体验,接口友好,易于上手,方便开发者快速集成与定制,助力高效仿真开发。
5. 先进的 GPU 驱动异构加速技术
充分利用 GPU 大规模并行计算能力,结合数据导向编程,实现工业级精度下的高性能快速仿真,显著优于传统有限元分析及现有机器人仿真平台。
魔术场景
为了更直观地展示「RoboMirage」的强大能力,先来看看几个经典的魔术场景:
金属环悬挂在细绳上端,松开手指让它自由下落却又稳稳悬停;两根橡皮筋分别被双手两指撑起后交错,左右摩擦后一拉实现穿越;将纸牌分成两叠,手指发力使其从两侧依次均匀从中间落下…… 这些看似神奇的瞬间,实际上蕴含着物理世界中最微妙的力与平衡法则。
正是 RoboScience 的仿真物理平台「RoboMirage」,以高精度仿真技术复刻了魔术世界中这些复杂精妙的 Magic Moment。依托精准计算模型与百微米级控制能力,它将现实中的细微互动转化为可计算的物理过程,重新拓展了仿真技术的边界。
首先看经典魔术明日环(Tomorrow Ring):「RoboMirage」可模拟金属环与柔性绳索间复杂的接触缠绕,其中涉及摩擦滑动与刚柔体耦合,这要求引擎稳定处理动态接触,避免了穿模或解算失败。

橡皮筋穿越魔术的仿真难点则在于两个弹性体的相互缠绕、拉伸与形变,需精准模拟其粘滞阻尼、张力变化及自碰撞特性。

而实现对洗扑克牌仿真的核心挑战是,模拟多张纸牌以极小时间步交错插入时的接触力与摩擦细节,关键在于维持接触连续性、防止穿透。

至于抽桌布魔术的仿真则需高精度捕捉布料瞬时滑动,以及布料移除瞬间物体的摩擦惯性与受力响应,同时兼顾快速拉拽的非平衡动态与上方物体的稳定性模拟。

需要强调的是,虽然「RoboMirage」是 RoboScience 打通 Sim-to-Real 路径的核心基础设施,但它并不构成 RoboScience 数据生态的全部。
除了仿真生成的大量训练与验证样本外,RoboScience 的研发与验证流程还融合了来自互联网语料与知识库、结构化技术文档、说明书(产品手册、CAD、规格表等)等以及少量真机实验的多模态传感数据与操作日志(力、位姿、触觉、视频等)。这些现实世界与文本类数据为仿真结果提供验证依据,帮助微调感知与策略模型,增加语义约束,并构建真实场景的基线测试。
换言之,RoboScience 既拥有高精度的仿真 “基座”,又具备多源数据支撑的研发与验证体系 —— 二者协同作用,有效缩小 Sim-to-Real Gap,加速算法向现实环境的稳健迁移与规模化落地。
家具拼装
此外,RoboScience 目前还完成了迄今最复杂、精度最高、步骤最多的xx操作任务 —— 家具拼装。
模型读取说明书后即可启动拼装:深度理解零件结构逻辑,实现多部件的检测、感知、插拔与旋转配合,还能自主分解多步骤任务,完成多关节双臂协同运动。
依托自适应插接路径规划和精细接触力调控策略,系统成功实现了高精度、高稳定性的拼装过程,无论是在零部件定位还是微小运动控制上均表现出卓越的能力。通过实时获取插接产生的反馈力,模型还能动态调整操作策略。

即便拼装过程中遭用户拆解干扰,模型仍能自动恢复状态,接续完成后续拼装步骤。通过该框架,系统可以用标准化方法分析不同场景下的物理接触,例如机器人抓取物体时的力反馈、变形预测或运动规划,无需为每种对象或机器人单独开发算法。

结语
通过高精度仿真引擎与多源数据体系的协同,RoboScience 不仅在高复杂度xx操作任务(如全自动拼装家具)中实现了前所未有的稳定性与精确度,也为更广泛的现实应用建立了坚实技术基座。
接下来,RoboScience 将持续突破仿真精度、泛化能力与真实交互的一体化边界,让机器人能够在更多元、更开放的场景中自主感知、推理与执行任务。
RoboScience 相信,这一技术路线将加速xx智能跨越从实验室到现实世界的鸿沟,并催生全新的人机协作模式 —— 让智能机器人真正成为人类生活与产业中值得信赖的伙伴与助手。
.....
#谷歌放出Nano Banana六大正宗Prompt玩法
手残党速来
最近几天,谷歌 Nano Banana 可是被广大网友玩出了新花样。
比如制作精致可爱的产品照片:

来源:https://x.com/azed_ai/status/1962878353784066342
将 13 张图像合并为单个图像 :

来源:https://x.com/MrDavids1/status/1960783672665128970
给人一键换衣:

反正你想到的,想不到的脑洞,都被广大网友挖掘出来了。
但别忘了,这些效果可不是凭空生成的。背后真正的魔法,其实是提示词。网友们正是用一条条巧妙的提示词,把这个模型玩出了无限可能。
就在刚刚,谷歌官方公布了 Nano Banana 六个文本转图像提示:

原文链接:https://x.com/googleaistudio/status/1962957615262224511
根据这些提示,你可以进行以下操作:
- 文本生成图像:通过简单或复杂的文本描述生成高质量图像。
- 图像 + 文本生成图像(图像编辑):提供一张图片,并使用文本提示词添加、删除或修改图像元素,调整风格或颜色。
- 多图合成与风格迁移:输入多张图片,合成新的场景,或将其中一张的风格迁移到另一张上。
- 迭代式优化:通过对话逐步优化图像,每次做小调整,直到达到理想效果。
- 文本渲染:生成包含清晰、布局合理文字的图像,适用于 logo、图表、海报等视觉创作。
谷歌强调,这些指令可以最大限度的发挥 Nano Banana 的图像生成能力。
接下来,我们看看这些提示具体包含的内容:
1、照片级写实场景
对于写实风格的图像,要像摄影师一样思考。prompt 中要提及机位角度、镜头类型、光线以及细节描写,这样可以引导模型生成更逼真的效果。
模板如下:
A photorealistic [shot type] of [subject], [action or expression], set in [environment]. The scene is illuminated by [lighting description], creating a [mood] atmosphere. Captured with a [camera/lens details], emphasizing [key textures and details]. The image should be in a [aspect ratio] format.
下图使用的完整 prompt 为「A photorealistic close-up portrait of an elderly Japanese ceramicist with deep, sun-etched wrinkles and a warm, knowing smile. He is carefully inspecting a freshly glazed tea bowl. The setting is his rustic, sun-drenched workshop. The scene is illuminated by soft, golden hour light streaming through a window, highlighting the fine texture of the clay. Captured with an 85mm portrait lens, resulting in a soft, blurred background (bokeh). The overall mood is serene and masterful. Vertical portrait orientation.」

2、风格化插画与贴纸
在制作贴纸、图标或项目素材时,在 prompt 中明确说明需要的风格;另外,如果需要白色背景,记得在 prompt 中提出来。
模板如下:
A [style] sticker of a [subject], featuring [key characteristics] and a [color palette]. The design should have [line style] and [shading style]. The background must be white.
下图使用的完整 prompt 为「A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.」

3、图上添加精准的文字
Gemini 擅长渲染文字。此类任务最好在 prompt 中明确说明文字内容、字体风格(用描述性的方式),以及整体设计。
模板如下:
Create a [image type] for [brand/concept] with the text "[text to render]" in a [font style]. The design should be [style description], with a [color scheme].
下图使用的完整 prompt 为「Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The design should feature a simple, stylized icon of a coffee bean seamlessly integrated with the text. The color scheme is black and white. 」

4、产品模型与商业摄影
适合在电商、广告或品牌宣传时制作干净、专业的产品照片。
模板如下:
A high-resolution, studio-lit product photograph of a [product description] on a [background surface/description]. The lighting is a [lighting setup, e.g., three-point softbox setup] to [lighting purpose]. The camera angle is a [angle type] to showcase [specific feature].
Ultra-realistic, with sharp focus on [key detail]. [Aspect ratio].
下图使用的完整 prompt 为「A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.」

5、极简与留白设计
适合用于创建网站、演示文稿或营销素材的背景,并在其上叠加文字内容。
模板如下:
A minimalist composition featuring a single [subject] positioned in the [bottom-right/top-left/etc.] of the frame. The background is a vast, empty [color] canvas, creating significant negative space. Soft, subtle lighting. [Aspect ratio].
下图使用的完整 prompt 为「A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.」

6、连续性艺术(漫画分镜 / 分镜头脚本)
通过逐格描绘,创作引人入胜的视觉叙事,适合用于开发分镜头脚本、漫画条幅或任意形式的连续性艺术。重点在于清晰的场景描述。
模板如下:
A single comic book panel in a [art style] style. In the foreground, [character description and action]. In the background, [setting details]. The panel has a [dialogue/caption box] with the text "[Text]". The lighting creates a [mood] mood. [Aspect ratio].
下图使用的完整 prompt 为「A single comic book panel in a gritty, noir art style with high-contrast black and white inks. In the foreground, a detective in a trench coat stands under a flickering streetlamp, rain soaking his shoulders. In the background, the neon sign of a desolate bar reflects in a puddle. A caption box at the top reads "The city was a tough place to keep secrets." The lighting is harsh, creating a dramatic, somber mood. Landscape.」

这一套 prompt 模板学下来,你大概就能掌握使用 Nano Banana 的精髓了。
不过,用户在使用中还有其他困扰,比如「在对已有图像进行编辑时,模型往往会返回一张一模一样的图像。」

另外有人指出了 Nano Banana 在编辑时存在的更多问题,「它在一致性上表现不如 Qwen 和 Kontext Pro,也不够稳定,特别是在持续对话过程中。对于文本转图像,直接用 Imagen 会更好且更可控。」

大家在使用 Nano Banana 的过程中有哪些独到的心得与技巧?欢迎在评论区分享出来。
谷歌nano banana官方最强Prompt模板来了
谷歌官方放出 nano banana「六合一」Prompt 模板:一句话把场景、机位、光效写全,写实、贴纸、Logo、留白、漫画 5 大风格直接套用即可出片,零门槛体验高质量AI生图。
这几天爆火的nano banana,让更多人体验到AI对图像生成与处理的革命。
网友们玩疯了,开发出各类好玩的用法。
有用nano banana直接将照片生成手办模型的:
左右滑动查看
有人脑洞大开,让nano banana、Seedance、Kling联手,将梵高和蒙娜丽莎、戴珍珠耳环的少女等名画的人物,同时带到了今天的纽约中央公园里,开启了一段浪漫的邂逅。
,时长03:29
还有人使用nano banana反过来带我们穿越回了中土世界。
视频以第一人称视角在马车上疾驰,穿越迥异的区域,充满了3A游戏大作般的史诗感。
,时长01:31
看到网上流传的nano banana生成的以假乱真、脑洞大开的图片和视频,不知道你是否也开始尝试使用nano banana了呢?
同样是生成图片,有人一句话就出大片,有人写满满一屏幕词也不对版。
谷歌为了帮助大家快速上手,亲自下场为我们带来了nano banana官方最强Prompt模板!
甭管你暂时是否理解为什么这样写,先收藏起来试着套模板就对了!
其中的关键是,你要像讲故事一样写场景。
基于nano banana(Gemini 2.5 Flash Image),这6套Prompt模板覆盖了写实、贴纸、文字、产品、留白与分镜,直接套用就能高质量生图!
写实摄影
写实感强的照片,是离不开摄影师的精心巧思的。
要生成写实感强的图像,你得像摄影师一样思考。
你需要考虑机位、镜头类型、光线、细节。
将这些元素加入Prompt后,会引导模型朝更逼真的效果靠近。
即使你不是专业摄影师,只要按照自己的理解多尝试,也大概率会比未说明这些关键要素而直接生成的图片的效果要好。
示例模板:
A photorealistic [shot type] of [subject], [action or expression], set in [environment]. The scene is illuminated by [lighting description], creating a [mood] atmosphere. Captured with a [camera/lens details], emphasizing [key textures and details]. The image should be in a [aspect ratio] format.
模板大意:
一张写实风格的[镜头类型],[主体],[动作或表情],场景设定在[环境]。画面由[光线描述]照明,营造出[情绪]氛围。使用[相机/镜头参数]拍摄,突出[关键材质与细节]。图像应为[纵横比]格式。
示例Prompt:
A photorealistic close-up portrait of an elderly Japanese ceramicist with deep, sun-etched wrinkles and a warm, knowing smile. He is carefully inspecting a freshly glazed tea bowl. The setting is his rustic, sun-drenched workshop. The scene is illuminated by soft, golden hour light streaming through a window, highlighting the fine texture of the clay. Captured with an 85mm portrait lens, resulting in a soft, blurred background (bokeh). The overall mood is serene and masterful. Vertical portrait orientation.
Prompt大意:
一张写实风格的特写人像:一位日本老陶艺家,脸上被岁月与阳光刻下的深深皱纹,露出温暖而睿智的微笑。他正仔细端详一个刚上釉的茶碗。场景位于他质朴、阳光充足的工作室。柔和的黄金时刻光线自窗外倾泻而入,凸显陶土的细腻纹理。使用85mm人像镜头拍摄,带来柔和的背景虚化(bokeh)。整体氛围宁静而老练。竖版人像构图。
生成的图片:
一张写实风格的日本老陶艺家特写人像
调用API生图示例Python代码:
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
cnotallow="A photorealistic close-up portrait of an elderly Japanese ceramicist with deep, sun-etched wrinkles and a warm, knowing smile. He is carefully inspecting a freshly glazed tea bowl. The setting is his rustic, sun-drenched workshop with pottery wheels and shelves of clay pots in the background. The scene is illuminated by soft, golden hour light streaming through a window, highlighting the fine texture of the clay and the fabric of his apron. Captured with an 85mm portrait lens, resulting in a soft, blurred background (bokeh). The overall mood is serene and masterful.",
)
image_parts = [
part.inline_data.data
for part in response.candidates[0].content.parts
if part.inline_data
]
if image_parts:
image = Image.open(BytesIO(image_parts[0]))
image.save('photorealistic_example.png')
image.show()注意,上述代码需要你在第11行的contents中输入Prompt,在第22行的image.save()中输入你要保存时取的文件名。
后续其他调用API生图的代码仅需要修改这两处即可。
插图与贴纸
在生成贴纸、图标、插图、项目素材这类图片时,你需要先把风格说清楚。
如果有其他特殊需求,比如需要白底的话,你得明确在Prompt中写出。
示例模板:
A [style] sticker of a [subject], featuring [key characteristics] and a [color palette]. The design should have [line style] and [shading style]. The background must be white.
模板大意:
一张[风格]的[主体]贴纸,具有[关键特征],采用[配色]。设计应当使用[线条风格]与[明暗/上色风格]。背景必须为白色。
示例Prompt:
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.
Prompt大意:
一张可爱风(kawaii)贴纸:一只开心的小熊猫戴着迷你竹叶帽,正咀嚼一片绿色竹叶。设计使用粗壮、干净的描边,简单的赛璐璐上色,配色鲜艳。背景必须为白色。
生成的图片:
一张可爱风(kawaii)的小熊猫贴纸
调用API生图示例Python代码:
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
cnotallow="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
image_parts = [
part.inline_data.data
for part in response.candidates[0].content.parts
if part.inline_data
]
if image_parts:
image = Image.open(BytesIO(image_parts[0]))
image.save('red_panda_sticker.png')
image.show()文本渲染
nano banana在文本渲染这项任务上的表现是格外瞩目的。
你只需要把文字内容、字体风格(用描述性的词描述)、整体设计说明白,就可以产出质量很好的图片了。
示例模板:
Create a [image type] for [brand/concept] with the text "[text to render]" in a [font style]. The design should be [style description], with a [color scheme].
模板大意:
为[品牌/概念]创建一张[图像类型],其中包含文本「[要渲染的文本]」,使用[字体风格]。设计应为[风格描述],并采用[配色方案]。
示例Prompt:
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The design should feature a simple, stylized icon of a coffee bean seamlessly integrated with the text. The color scheme is black and white.
Prompt大意:
为一家名为「The Daily Grind」的咖啡店设计一个现代、极简的Logo。文字使用干净、粗体的无衬线字体。设计带有一个简洁、风格化的咖啡豆图标,并与文字无缝融合。配色为黑白。
生成的图片:
为一家名为「The Daily Grind」的咖啡店生成的现代极简风Logo
调用API生图示例Python代码:
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
cnotallow="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The design should feature a simple, stylized icon of a a coffee bean seamlessly integrated with the text. The color scheme is black and white.",
)
image_parts = [
part.inline_data.data
for part in response.candidates[0].content.parts
if part.inline_data
]
if image_parts:
image = Image.open(BytesIO(image_parts[0]))
image.save('logo_example.png')
image.show()商业摄影
为品牌打广告时,打造一个干净、专业的产品照通常是一个比较不错的选择。
商业感=干净背景+可控布光+展示卖点的机位。
示例模板:
A high-resolution, studio-lit product photograph of a [product description] on a [background surface/description]. The lighting is a [lighting setup, e.g., three-point softbox setup] to [lighting purpose]. The camera angle is a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp focus on [key detail]. [Aspect ratio].
模板大意:
一张高分辨率、影棚布光的[产品描述]产品照,置于[背景表面/描述]上。灯光为[布光设置,如三点柔光箱布光],用于[照明目的]。机位为[角度类型],以展示[特定卖点]。超写实,对[关键细节]进行锐利对焦。[纵横比]。
示例Prompt:
A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.
Prompt大意:
一张高分辨率、影棚布光的产品照:一只极简风的消光黑陶瓷咖啡杯,摆放在抛光的混凝土表面上。灯光为三点柔光箱布光,营造柔和的高光并消除硬阴影。机位为略抬高的 45 度角,凸显其干净的线条。超写实,对咖啡升起的蒸汽进行锐利对焦。方形图像。
生成的图片:
一张高分辨率、影棚布光的极简黑色陶瓷咖啡杯产品照
调用API生图示例Python代码:
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
cnotallow="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
image_parts = [
part.inline_data.data
for part in response.candidates[0].content.parts
if part.inline_data
]
if image_parts:
image = Image.open(BytesIO(image_parts[0]))
image.save('product_mockup.png')
image.show()极简主义与留白设计
极简主义留白设计,非常适合为网站、演示或营销素材创建背景,方便后面再在图片上叠加文字。
示例模板:
A minimalist composition featuring a single [subject] positioned in the [bottom-right/top-left/etc.] of the frame. The background is a vast, empty [color] canvas, creating significant negative space. Soft, subtle lighting. [Aspect ratio].
模板大意:
一幅极简构图,画面中只有一个[主体],位于画面[右下角/左上角等]。背景是一整片空旷的[颜色]纯色画布,创造显著留白。柔和、克制的光线。[纵横比]。
示例Prompt:
A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.
Prompt大意:
一幅极简构图:一片精致的红色枫叶位于画面右下角。背景是一整片空旷的米白色纯色画布,为文字留出大量留白。来自左上方的柔和、漫射光。方形图像。
生成的图片:
一幅极简构图:一片精致的红色枫叶
调用API生图示例Python代码:
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
cnotallow="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
image_parts = [
part.inline_data.data
for part in response.candidates[0].content.parts
if part.inline_data
]
if image_parts:
image = Image.open(BytesIO(image_parts[0]))
image.save('minimalist_design.png')
image.show()漫画
你可以通过聚焦清晰的场景描述,一格一格地创作吸引人的视觉叙事。
这种方式非常适合做漫画、故事板等图片。
示例模板:
A single comic book panel in a [art style] style. In the foreground, [character description and action]. In the background, [setting details]. The panel has a [dialogue/caption box] with the text "[Text]". The lighting creates a [mood] mood. [Aspect ratio].
模板大意:
一格[艺术风格]的漫画分镜。前景中,[人物描述与动作]。背景中,[环境细节]。画面包含一个[对白/旁白框],内容为「[文本]」。用光营造[情绪]氛围。[纵横比]。
示例Prompt:
A single comic book panel in a gritty, noir art style with high-contrast black and white inks. In the foreground, a detective in a trench coat stands under a flickering streetlamp, rain soaking his shoulders. In the background, the neon sign of a desolate bar reflects in a puddle. A caption box at the top reads "The city was a tough place to keep secrets." The lighting is harsh, creating a dramatic, somber mood. Landscape.
Prompt大意:
一格粗粝的黑色电影风漫画,高反差黑白墨线。前景中,一位穿风衣的侦探站在闪烁的路灯下,雨水打湿了他的双肩。背景中,一家荒凉酒吧的霓虹招牌倒映在水坑里。顶部的旁白框写着:「在这座城市,想守住秘密并不容易。」用光强硬,营造戏剧而沉郁的氛围。横向画幅。
生成的图片:
一格粗粝的黑色电影风漫画分镜
调用API生图示例Python代码:
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
cnotallow="A single comic book panel in a gritty, noir art style with high-contrast black and white inks. In the foreground, a detective in a trench coat stands under a flickering streetlamp, rain soaking his shoulders. In the background, the neon sign of a desolate bar reflects in a puddle. A caption box at the top reads \"The city was a tough place to keep secrets.\" The lighting is harsh, creating a dramatic, somber mood. Landscape.",
)
image_parts = [
part.inline_data.data
for part in response.candidates[0].content.parts
if part.inline_data
]
if image_parts:
image = Image.open(BytesIO(image_parts[0]))
image.save('comic_panel.png')
image.show()有了以上谷歌官方的强大模板,人人都可以自己创造出高质量图片了!
先收藏再说,有空了快去亲自试试吧!
参考资料:
https://x.com/googleaistudio/status/1962957615262224511
.....
#Claude Opus 4.1
Anthropic承认模型降智后仍放任其偷懒?Claude Code用户信任崩塌中
还记不记得每一次 OpenAI 发布新功能或新模型的时候,总会有一些评论声称现有模型能力下降,怀疑大模型「降智」现象的声音不绝于耳。
排除掉一些有关 OpenAI 对部分地区账户的用户分级机制导致的显著降级情况,普通用户也会感觉到大模型时不时的出现问题。
xx编辑部在测试 GPT-5 的时候,感觉模型能力不及预期,也会怀疑是否有「降智」现象的存在。

但无论如何,此前大模型供应商似乎从来没有正面承认过模型「降智」的问题,用户的感知也朦朦胧胧的。
OpenAI 的研究科学家 Aidan McLaughlin 前两天发推聊到了这个现象。

他的意思是,大家(包括他自己)经常会错误地认为某个 AI 模型被实验室「削弱」了,而这种错误认知的发生率远高于他的预期。他甚至觉得,这是一种普遍的心理错觉,应该被定义成一种新的心理学现象。
但他很快就被库库打脸了。
几天前,Anthropic 发布了旗下模型 Claude Opus 4.1 和 Opus 4 的质量降级事件报告。很罕见地,大模型厂商公开承认模型「降智」的现象。

从 8 月 25 日 17:30 UTC 到 8 月 28 日 02:00 UTC,Claude Opus 4.1 在部分请求中出现了质量下降的问题。用户可能会遇到智能水平降低、回答格式错误或 Claude Code 工具调用异常等情况。
这一问题的原因是 Anthropic 在推理(inference)堆栈中进行了一次更新,但目前已经对 Claude Opus 4.1 回滚了该更新。虽然 Anthropic 经常会进行一些更改来提升模型的效率和吞吐量,但目标始终是保持模型响应质量不变。此外还发现 Claude Opus 4.0 也受到了同样问题的影响,目前正在对其进行回滚。
并且,Anthropic 在报告中声称该事件已经被妥善解决。但 Anthropic 很快被用户们打脸,直到 9 月 1 日,用户对于 Claude Code 的负反馈不减反增。
Claude 这波自废武功的现象正持续性消耗用户过去的习惯和信任,很多用户正一点点地转向 GPT-5。
研究者 Thomas Ricouard 认为:
- Claude Code 暂时 RIP,他不确定 Anthropic 是否真的从推理系统的问题中恢复过来,但就连 Opus 也变得很「懒」。
- Cursor Agent CLI 搭配 GPT-5 表现真的非常棒,尤其是在精心设计的 prompt 下。

在他的推文下面,许许多多的 Claude 用户有着相同的抱怨,似乎 Anthropic 根本没有好好修正这个问题,Claude 依然不停地在「偷懒」。

还有人称,「实际运行起来更加糟糕。」

更有人直接开喷,「以前,Sonnet 4 能够直接构建一个项目,而现在 Opus 4.1 却连一个简单的脚本都生成不了,简直变成了无用的垃圾。」

Claude Code 表现为什么如此差劲?使用时间或许是一大影响因素,「它在凌晨两点用起来顺畅无比,白天高峰期被限流之后就非常糟糕。」

还有人猜测,是不是 Anthropic 正在研发一个新的或更好的模型。

众多拉踩之下,Claude Code 似乎就要跌落神坛了。当一个模型开始了「偷懒」,用户会做出他们的选择。根据我们此前的报道,在 GPT-5 发布后,相比于 Claude Code,开发者私下更喜欢用 GPT-5 写代码。

下面这位小哥表示,「我这几天一直在 Codex+GPT-5-high,完全不想念 Claude Code。每月 20 美元,性价比简直离谱。」

你在 Claude 的实际使用中遇到过哪些降智行为呢,欢迎评论区留言。
.....
#TRKT
基于时序增强关系敏感知识迁移的弱监督动态场景图生成
该论文的第一作者和通讯作者均来自北京大学王选计算机研究所,第一作者为博士生徐铸,通讯作者为博士生导师刘洋。团队近年来在 TPAMI、IJCV、CVPR、ICML 等顶会上有多项代表性成果发表,多次荣获国内外多模态理解预生成竞赛冠军,和国内外知名高校、科研机构广泛开展合作。
本文主要介绍来自该团队的最新论文:TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring。该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。
本文针对该问题提出了一种时序增强关系敏感知识迁移的方法,通过获取关系和时序信息感知的注意力图来优化外部目标检测器的检测结果,从而提升在场景图数据上目标检测质量,进而提升最终的生成场景图效果。
目前该研究已被 ICCV 2025 正式接收,相关代码与模型已全部开源。
- 论文标题:TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring
- 论文链接:https://arxiv.org/abs/2508.04943
- 代码链接:https://github.com/XZPKU/TRKT.git
- 项目主页:https://sites.google.com/view/trkt-official
动态场景图生成任务旨在通过检测物体并预测它们之间的关系,为视频的每一帧生成对应场景图。 弱监督动态场景图生成要求模型在训练阶段只使用来自视频单帧的无物体位置信息的场景图标签作为监督进行训练,从而减少标注工作量。现有的弱监督动态场景图生成方法依赖于预训练的外部目标检测器生成物体标签,进而构造伪场景图标签用于后续场景图生成模型的训练。
然而,在动态、关系感知的动态场景图生成场景中,训练于静态、以物体为中心图像上的目标检测器可能出现物体定位不准确以及对部分物体置信度过低,从而导致物体漏检的问题。本文通过分析目标检测结果和关系预测结果对最终场景图质量的影响(如下图 1 所示),可以发现目标检测质量是目前弱监督动态场景图生成任务的主要瓶颈。

图 1:使用不同目标检测结果和关系预测结果的动态场景图性能对比
针对上述问题,该论文提出了一种时序增强且关系敏感的知识迁移方法 TRKT,该方法能够有效增强在关系感知的动态场景中的目标检测性能。
具体来讲,TRKT 首先通过物体和关系类别解码器生成类别特定的注意力图,以突出物体区域和交互区域,从而使注意力图具备关系感知能力,同时利用邻近帧和光流信息对注意力图进行时序增强,使它们具备运动感知能力,并对运动模糊具有较强的鲁棒性。进一步,TRKT 还设计了一个双流融合模块,综合利用类别特定的注意力图与外部检测结果,提升物体定位精度和部分物体的置信度分数。实验表明,TRKT 通过提升目标检测性能为弱监督动态场景图生成的训练提供了更准确和更高质量的伪标签,进而提升最终动态场景图的生成质量。
一、方法介绍

图 2:基于时序增强关系敏感知识迁移的弱监督动态场景图生成方法框架图
本文方法如图 2 所示,它主要由两个设计组成:关系敏感的知识挖掘(Relation-aware Knowledge Mining)和双流融合模块(Dual-stream Fusion Module)。在关系敏感的知识挖掘中,我们利用图像编码器将每帧输入图像处理成若干块,然后分别通过物体和关系类别解码器对这些块进行解码,生成注意力图,用于高亮物体及其交互关系的相关区域。编码器和解码器仅通过图像的物体和关系类别标签进行监督。这些注意力图包含物体语义和潜在的关系上下文,从而增强了模型在数据中识别和理解复杂关系的能力。进一步地,跨帧的光流被用来提供时序信息以进一步增强注意力图。通过这些方法,我们获得既具备关系感知又具备运动感知的注意力图,包含时序增强和关系敏感的知识。在双流融合模块中,我们设计了并行的定位优化模块(Localization Refinement Module,LRM)和置信度提升模块(Confidence Boosting Module,CBM)用于最大化注意力图在增强外部检测结果中的效果。LRM 通过利用注意力图来定位物体区域,从而提供外部检测的边界框坐标的准确度;CBM 则增强由类别解码器识别的物体类别的置信度分数。关系敏感的知识挖掘和双流融合模块有效地减轻了外部检测结果中存在的偏差,最终产生了更可靠的物体检测结果。最后我们使用和基线模型相同的方法,将检测结果组织为场景图伪标签,以全监督的方式训练动态场景图检测模型。
关系敏感的知识挖掘
在关系敏感的知识挖掘中,我们使用无物体位置信息的场景图标注训练物体和关系类别解码器,分别生成关注物体的类别敏感注意力图

和关注关系区域的注意力图
![]()
,并利用邻近帧和光流信息创建当前帧的伪注意力图
![]()
,以缓解潜在的模糊和遮挡问题,增强注意力图的运动感知能力。我们首先将输入图像
![]()
编码为图像块特征
![]()
,其中 N 是图像块的数量,D 是特征维度。为了关注与每个物体类别高度相关的特定区域,我们为物体类别编码器配备物体查询

,其中 Cobj是物体类别的数量,并在关系类别解码器中提供关系查询
![]()
,用于关注包含关系信息的区域,其中 Crel 是关系类别的数量。然后,对于每个类别解码器中的注意力层,我们将注意力计算公式表示为:

其中 tgt 可以是物体(obj)或关系(rel),CA 表示交叉注意力层,
![]()
表示拼接后的特征,
![]()
分别是查询、键和值的投影层,
![]()
表示注意力矩阵。
![]()
用于定位特定类别的视觉线索,我们通过切片和重塑操作从
![]()
推导出
![]()
,其中 N=h×w,表示物体和关系标记与图像块特征之间的注意力。为了生成更准确的类别敏感注意力图,我们将注意力图
![]()
和
![]()
通过如下相似度的计算融合成类别敏感的注意力图,

其中,
![]()
,
![]()
,而 norm 表示归一化操作。
为了进一步应对视频中可能出现的运动模糊和遮挡问题,并使注意力图具备运动感知能力,我们提出帧间注意力增强策略,采用跨帧光流信息作为时序线索。对于视频序列 V 中的每一帧
![]()
,我们采用邻近帧
![]()
提供额外信息,以补救因 Ii 中的模糊和遮挡所导致的物体误检和漏检。具体而言,我们采用 RAFT [2] 来获得帧间光流
![]()
,并使用相同的关系敏感的知识挖掘过程为
![]()
获取类别感知的注意力图
![]()
。然后,我们根据光流场
![]()
对
![]()
进行变形,生成第 i 帧的伪注意力图

,包含关于动态物体的时序线索。
双流融合模块
双流融合模块(DFM)用于结合时序感知且关系敏感的知识,来提升外部检测器的结果质量。DFM 包含了定位修正模块和置信度提升模块。

图 3:定位修正模块示意图
定位修正过程如图 3 所示,外部检测结果和来自类别感知注意力图的物体候选被用来获取修正后的检测结果(即图 3 右下角的绿色框)。为了修正外部检测结果 De,我们利用类别感知注意力图
![]()
,用基于阈值的算法 f (⋅) 获取内部物体候选
![]()
,其中
![]()
是检测到的边界框,
![]()
是置信度分数,通过对应注意力图内 bi 的平均注意力得分计算,

是物体的类别,n 表示检测到的物体数量。然后,我们将 Da 与 De 结合,通过加权框融合融合算法 F (⋅) 获取更精确的物体边界框。融合过程表示如下:


图 4:置信度提升模块示意图
另一方面,某些边界框中可能存在低置信度的问题,可能会导致物体漏检。因此我们提出了置信度提升模块(CBM)来补充潜在漏检的物体。如图 4 所示,我们以物体分类 logits 作为标准选择具有高概率的物体类别,将其注意力
![]()
与外部检测注意力图 Aext 结合,并进行归一化操作,生成增强的类别 ci 的注意力图,得到改进的物体检测结果 D2,从而缓解可能的漏检问题:

接着,我们将物体检测结果 D1 和 D2 融合,得到修正后的物体检测结果 D=F (D1,D2) 同时提升了检测精度和置信度分数。此外,为了赋予检测结果时序线索并缓解模糊和遮挡问题,我们在 D 上通过伪注意力图

, 重复上述操作,最终获得进一步修正后的检测结果 D′。该结果用于依照基线模型 PLA 中的方法获取伪场景图标签,并以全监督的方式训练动态场景图检测模型。
二、实验结果
①对比方法
我们对比了两大类方法,第一类是已有最优的弱监督动态场景图生成方法,包括 PLA [1] 和 NL-VSGG;第二类是擅长关系理解的视觉语言模型,包括 RLIP 和 RLIPv2 [4]。
②评价指标
评价指标分为两部分,第一部分是测评方法在 DSGG 数据中的目标检测性能,指标为 Average Precision (AP) 和 Average Recall (AR);第二部分是测评方法在动态场景图生成任务上的性能,我们通过场景图检测(SGDET)任务进行评估。SGDET 旨在检测物体对并预测它们之间的关系,并以 Recall@K 为指标进行评估。
③与现有方法的对比及分析

表 1:与基线模型在 Action Genome [3] 数据集上目标检测性能对比实验结果

表 2:与对比方法在 Action Genome [3] 数据集上动态场景图生成性能对比实验结果
我们首先对比了目标检测的性能,结果如表 1 所示。我们提出的方法在 Average Precision 和 Average Recall 上分别提高了 13.0%/1.3%,验证了我们的方法能够有效提升动态和需要关系理解场景下的目标检测性能。
对于弱监督动态场景图生成任务,性能对比如表 2 所示。和我们的基线模型 PLA 相比,结果显示,我们在所有评估指标上都取得了性能提升(1.72%/2.42%),这表明,通过改进物体检测结果,生成的伪场景图标签质量得到了提高,从而在最终的 DSGG 性能上获得了性能提升。此外,我们还与 NL-VSGG 进行了比较,NL-VSGG 使用视频字幕来构建伪场景图进行模型训练,也使用外部物体检测器进行物体检测,但由于相同的物体检测质量问题,其 DSGG 性能低于我们的方法。我们还与 RLIP 和 RLIPv2 进行了比较,它们以零样本方式进行场景图预测,将每一帧视为静态图像。然而,它们的性能较差,进一步说明了时序和动态信息和时序增强且关系敏感的知识对于动态场景图任务的必要性。
④消融实验

表 3:不同模块的消融实验结果
为了验证本文所提出的各个模块的有效性,本文进行了消融实验。CBM, LRM 和 IAA 分别代表置信度提升模块,定位修正模块以及帧间注意力增强策略,消融结果如表 3 所示。我们可以得出以下结论:(1)分别采用 CBM 和 LRM 作为知识迁移策略,分别带来了 1.2% 和 2.0% 的平均精度提升,进而在 SGDET 任务上获得了性能提升,这表明物体检测质量在边界框置信度分数和定位精度方面得到了改善。(2)通过结合 CBM 和 LRM,物体检测的 AP 平均提升了 2.8%,在有约束 / 无约束场景下,DSGG 任务的表现分别提升了 1.48%/1.94%。这表明,边界框精度的提升和置信度分数的增强可以相互补充,生成质量更高的物体检测结果,从而带来更大的性能提升。(3)融入 IAA 策略后,物体检测性能进一步提升,AP 提升了 8.9%/10.6%,表明 IAA 有效缓解了模糊和遮挡问题,生成了更好的检测结果,从而进一步提升了最终场景图生成的表现。
⑤可视化结果

图 5:动态场景图生成结果可视化
如图 5 所示,我们给出了和基线模型 PLA [1] 生成动态场景图效果的对比,得益于我们引入的时序增强关系敏感的知识和我们设计的双流融合模块,我们的方法能够得到更完整的场景图,并且其中人和物体的定位更加准确,从而使得得到的场景图质量更高。
更多研究细节,可参考原论文。
参考文献
[1] Siqi Chen, Jun Xiao, and Long Chen. Video scene graph generation from single-frame weak supervision. In The Eleventh International Conference on Learning Representations,2023.
[2] Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow, 2020.
[3] Jingwei Ji, Ranjay Krishna, Li Fei-Fei, and Juan Carlos Niebles. Action genome: Actions as compositions of spatio temporal scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10236–10247, 2020.
[4] Hangjie Yuan, Shiwei Zhang, Xiang Wang, Samuel Albanie, Yining Pan, Tao Feng, Jianwen Jiang, Dong Ni, Yingya Zhang, and Deli Zhao. Rlipv2: Fast scaling of relational language-image pre-training, 2023.
.....
#Anthropic
刚刚,Anthropic在质疑声中获130亿美元融资,估值达1830亿
Anthropic 宣布已经完成了新一轮 130 亿美元融资,投后估值达 1830 亿美元,约为这家人工智能初创公司 3 月份上次融资时的三倍。
这也是目前科技行业第二大规模的私募融资,仅次于 2025 年 3 月 OpenAI 历史性的 400 亿美元融资。
这最新一轮融资为 Anthropic 的 F 轮融资,由 Iconiq、富达管理研究公司 (Fidelity Management & Research Co.) 和光速创投 (Lightspeed Venture Partners) 领投。Anthropic 表示,Altimeter、General Catalyst 和 Coatue 等其他多方投资者也参与其中。

Anthropic 财务总监 Krishna Rao 在声明中表示:「此次融资表明投资者对我们财务业绩的极大信心,并展现了他们与我们合作的力度,这将继续推动我们前所未有的增长。」
自 2023 年 3 月推出 AI 助手 Claude 以来,Anthropic 的估值一路飙升。
2025 年初,即推出 Claude 不到两年,Anthropic 的运行收入已增长至约 10 亿美元。到 2025 年 8 月 —— 仅仅八个月后,该公司的年度化营收(run-rate revenue)就超过 50 亿美元,使 Anthropic 成为历史上增长最快的科技公司之一。
此外,该公司还在声明中重点提到了 Claude Code:「对于企业而言,我们的 API 和行业特定产品使其能够轻松地将强大的 AI 添加到其关键应用程序中,而无需进行复杂的集成工作。自 2025 年 5 月全面发布以来,Claude Code 已成为开发者的首选工具。Claude Code 迅速发展,已创造超过 5 亿美元的运营收入,使用量在短短三个月内增长了 10 倍以上。」
Vibe Kanban 发布的动态统计图也佐证了其优势,不过也看得出来,OpenAI 推出的竞品 Codex Cli 增长明显。
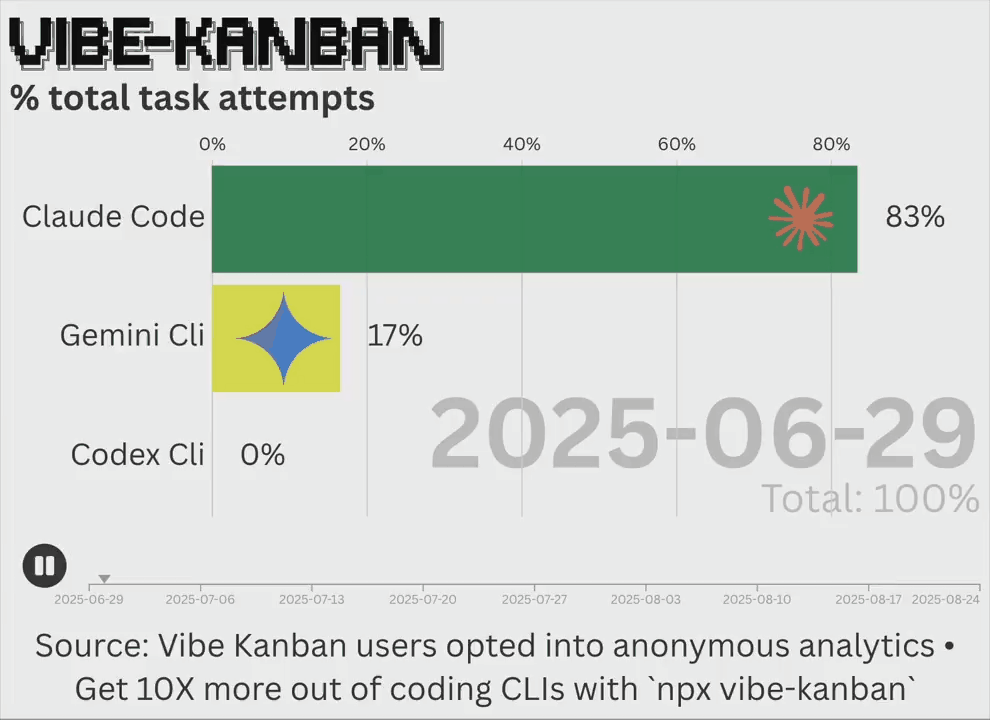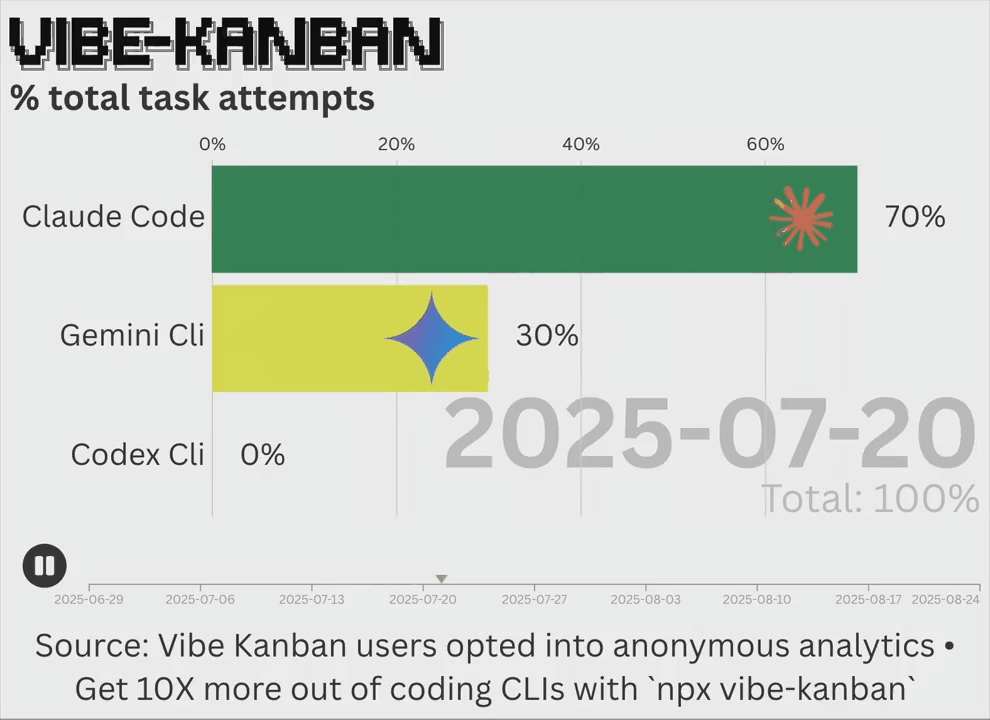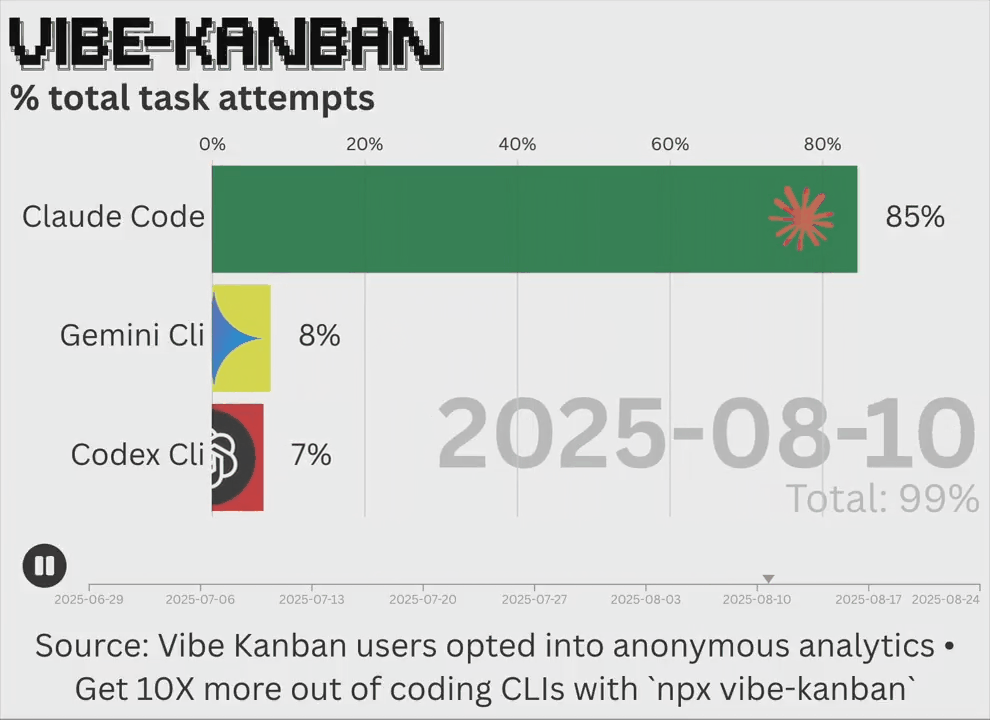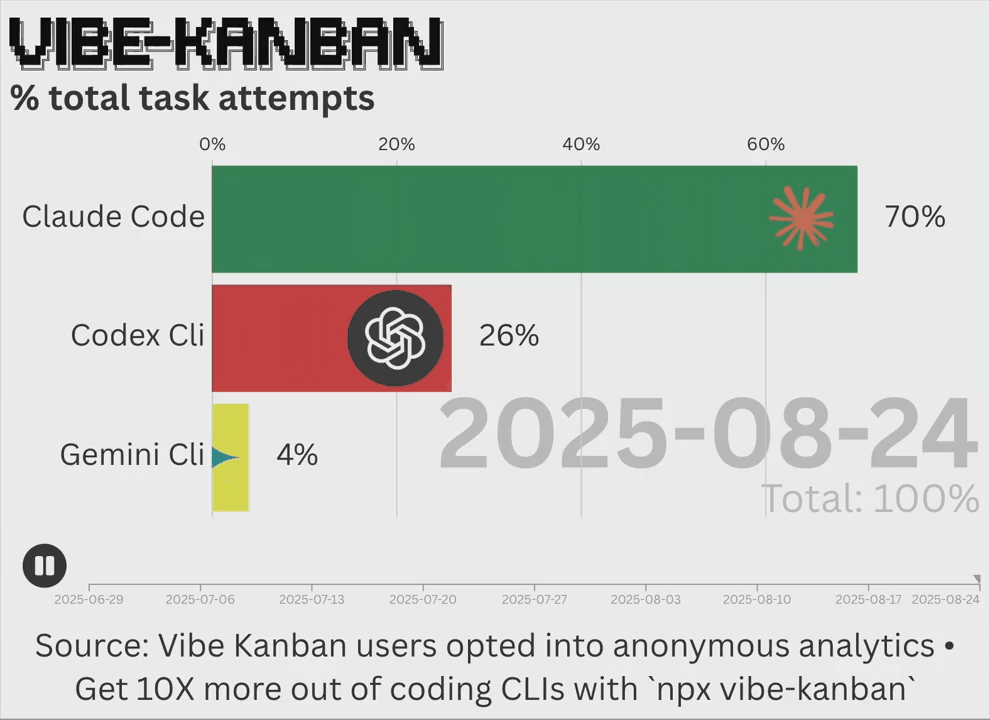
https://x.com/LouisKnightWebb/status/1962870556631478401
Anthropic 表示,已为超过 30 万家企业客户提供服务,并且其大型客户(每个客户的运营收入超过 10 万美元)数量在过去一年中增长了近 7 倍。
Anthropic 还表示,将利用新资本深化安全研究,满足日益增长的企业需求,并支持国际扩张。
高估值背后,Anthropic 最近引发的争议也不少:
- 默认收集用户数据并用于训练(消费者端):Anthropic 宣布将把用户的聊天与编码会话用于模型训练,除非用户主动选择退出;同时把允许训练的数据最长留存 5 年(未允许者仍为 30 天)。该变更覆盖 Claude Free/Pro/Max 与 Claude Code,但不适用于企业 / 政府 / 教育或 API(Bedrock / Vertex)等场景。并设置了 9 月 28 日 2025 年 的最后决定期限与弹窗默认「接受」设计,引发争议。
- 「用量限制」收紧,重度用户受影响。7 月底起,Anthropic 面向 Pro/Max(尤其 Claude Code 重度用户)推出按周的用量上限,并出现按小时计量的新配额方式(5 小时重置);官方称仅影响 <5% 订阅者,但社区反弹明显。
- 模型体验波动的社区争议。随着新模型 / 快照上线,有用户反馈顶级模型表现阶段性下滑(降智)、为了新模型发布而压低之前模型性能等,相关吐槽在社区持续发酵(虽属主观体验,但讨论热烈)。
- 模型「自我保护/结束对话」的设定也引发讨论。Anthropic 表示最新较大的模型在极端、持续的辱骂 / 有害情景下可主动结束对话,被一些用户质疑「把 AI 放在用户之前」。
- 多条版权/数据诉讼战线:作者案、音乐出版方案、Reddit 起诉。
不过,看起来这些争议并没有对投资者对 Anthropic 的信心产生显著影响。
Anthropic 由包括 CEO Dario Amodei 在内的多位前 OpenAI 研究高管创立。现如今,OpenAI 和 Anthropic 已经成为 AI 市场里的激烈竞争对手。
OpenAI 于 2022 年发布 AI 聊天机器人 ChatGPT 后迅速成为主流,据报道,OpenAI 正准备出售股票,作为二次出售的一部分,此举将使公司估值达到约 5000 亿美元。今天,OpenAI 还宣布以 11 亿美元收购了产品分析创业公司 Statsig,并任命其 CEO Vijaye Raji 为 OpenAI 的产品 CTO—— 向应用 CEO Fidji Simo 报告。
......
#MetaFold
机器人衣物折叠新范式,NUS邵林团队用MetaFold解耦轨迹与动作
本文的共同第一作者为新加坡国立大学博士生陈浩楠,南京大学研究助理 / 本科生李骏骁和北京大学博士吴睿海。合作者为刘益伟、侯懿文、徐志轩、郭京翔、高崇凯、卫振宇、许申思、黄嘉祺。通讯作者为新加坡国立大学计算机学院助理教授邵林,研究方向为机器人和人工智能。
机器人对可形变物体的操作(Deformable Object Manipulation, DOM),是衡量通用机器人智能水平的关键指标之一。与刚体操作不同,衣物、绳索、食物等物体的形态不固定,其状态空间维度极高,且物理交互过程呈现出复杂的非线性动力学特性,为感知、规划和控制带来了巨大挑战。
传统的服装折叠方法往往依赖于预定义的关键点或演示数据 [1, 2],这严重限制了它们在不同服装类别间的泛化能力。现有研究大多采用基于规则的启发式方法或依赖人工演示的学习方式,这些方法在面对多样化的服装类型和用户指令时表现出明显的局限性。
近年来,随着基础模型在计算机视觉和自然语言处理领域的巨大成功,研究者们开始探索将这些先进技术应用于机器人操作任务 [3]。视觉和语言引导的机器人操作已成为当前研究的热点,它能够让机器人理解自然语言指令并执行相应的操作任务。然而,在可变形物体操作,特别是服装折叠任务中,如何有效结合视觉和语言指导与物理操作仍然是一个亟待解决的问题。
在此背景下,MetaFold 旨在填补现有研究的空白:创建一个既能理解人类语言的丰富内涵和场景的视觉信息,又能精准、泛化地操作多类别衣物的、具有良好解释性的机器人框架。
目前,该论文已被机器人领域顶级会议 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025) 接收。
论文标题:MetaFold: Language-Guided Multi-Category Garment Folding Framework via Trajectory Generation and Foundation Model
论文链接:https://arxiv.org/abs/2503.08372
项目主页:https://meta-fold.github.io/
MetaFold:基于轨迹生成和动作预测的分层架构
MetaFold 采用了一种创新的分层架构设计,将复杂的服装折叠任务分解为两个相对独立的子问题:任务规划(task planning)和动作预测(action prediction)。这种分离式设计受到人类神经系统结构的启发 —— 大脑负责高级任务理解和物体识别,而脊髓和外周神经系统管理手部运动和抓取动作。
该框架的核心思想是通过语言引导的点云轨迹生成来处理任务规划,同时使用低级基础模型来进行动作预测。这种模块化设计不仅简化了训练过程,还显著提高了模型在不同服装类别间的泛化能力。

Fig. 1 MetaFold 框架
数据集生成与标注
由于当前衣物折叠数据稀缺,研究团队首先构建了一个包含 1210 个服装和 3376 条轨迹的大规模数据集。该数据集基于 ClothesNet [4] 提供的服装模型,使用 DiffClothAI [5] 可微分仿真器生成高质量的点云轨迹数据。
对于不同种类的衣物,研究团队首先使用启发式的方法生成折叠轨迹,并记录每时刻的衣物网格。从连续帧的衣物网格中,可以提取出衣物的点云轨迹。研究团队对这些衣物的折叠轨迹进行筛选,将失败的折叠轨迹去除,构建了一个成功折叠的衣物折叠数据集。
数据集涵盖了四种主要的折叠类型:(1)无袖折叠(包括连衣裙、裙子和无袖上衣)(2)短袖折叠(3)长袖折叠(4)裤子折叠。每个轨迹都配有相应的自然语言描述,用于指导折叠过程。
数据集已经在 huggingface 上开源:
开源地址:https://huggingface.co/datasets/chenhn02/MetaFold
轨迹生成模型
轨迹生成模型的核心是一个基于注意力机制的跨模态融合模型。它首先通过独立的编码器分别提取点云的几何特征和语言指令的语义特征,然后利用交叉注意力机制来深度融合这两种模态的信息,从而理解指令在特定几何形态上的具体意图。
该模型的输出并非直接的机器人动作,而是衣物形态在未来的一系列几何快照。这种以点云轨迹作为中间表征的设计是 MetaFold 的关键创新之一,其优势在于:
- 解耦与抽象:它将「任务目标」的几何定义从「如何实现该目标」的物理动作中剥离出来,显著降低了学习的复杂性。
- 提升泛化性:无论是 T 恤还是连衣裙,「对折」这一动作在几何形态上的变化具有共性。学习这种视觉 / 语言 - 几何的映射,比学习视觉 / 语言 - 具体动作的映射更具泛化潜力。
- 可解释性:生成的可视化点云轨迹为人类提供了一个直观的窗口,以理解和验证机器人的「任务规划」是否符合预期。
轨迹生成模型基于条件变分自编码器(CVAE)构建,其编码器和解码器均采用 Transformer 编码器架构。该模型接收点云观察和语言描述,生成点云轨迹。模型使用 PointNet++ 提取点云空间信息,得到点云特征。同时,LLaMA 模型处理语言描述的语义信息,经过降维后得到语言特征。
,时长00:03
底层操作策略
ManiFoundation [6] 模型将操作任务形式化为接触合成问题。接收两个连续点云状态,模型将输出从上一个点云状态转移到下一个点云状态所需要的动作。这个动作将以接触合成的形式表示,即若干个接触点和对应的运动方向。
为减轻随机种子对预测结果的影响,系统采用模型集成方法,使用 160 个不同随机种子生成多个预测结果。当两个预测结果之间的距离小于阈值时,将它们归为同一组,最终选择排名最高的组内平均位置最近的点及其对应力作为输出。
系统实施闭环反馈控制策略,在机器人执行动作后重新获取服装状态,将当前点云输入轨迹生成模型产生后续轨迹。这种设计使框架能够适应环境扰动和变化,确保操作的鲁棒性和精确性。
实验结果与深度分析
数据集与评估指标
实验在 Isaac Sim 仿真环境中进行,相比传统的 PyFleX 仿真环境,该环境能够提供更准确的服装内力仿真和更低的网格穿透发生率。为了能同时衡量多种衣物的折叠效果,研究团队采用三个关键评估指标:
- 矩形度(Rectangularity):折叠后服装面积与其边界矩形的比值,评估折叠质量。
- 面积比(Area Ratio):折叠后与初始服装面积的比值,指示折叠紧密程度。
- 成功率(Success Rate):矩形度超过阈值且面积比低于阈值的样本比例。
性能对比分析
MetaFold 在多项指标上显著优于现有方法。
- 在矩形度上,MetaFold 保持 0.80-0.87 的高水平。
- 在面积比指标上,MetaFold 实现 0.24-0.45,优于基线方法。
- 在成功率指标上,MetaFold 达到 79%-97%,显著超过 UniGarmentManip [9] 的 42%-91% 和 GPT-Fabric [3] 的 3%-63%
在未见过的 CLOTH3D [7] 数据集上,MetaFold 仍然达到 79%-97% 的成功率,证明了其强大的跨数据集泛化能力。

在语言指导的实验中,MetaFold 与基线比较了已见指令与未见指令的泛化能力。结果表明,MetaFold 在处理不同类型语言指令方面表现出色。除此之外,系统能够处理复杂的用户指令,如指定折叠顺序(「先左后右」)等,即使这些顺序在训练数据中未出现过,模型仍能正确理解和执行。

真实环境验证
研究团队使用 uFactory xArm6 机器人配备 xArm Gripper 和俯视 RealSense D435 相机进行真实环境实验。通过 SAM2 [8] 分割 RGB 图像生成服装掩码,结合深度数据提取真实服装点云。相比于 RGB 图片,点云模态有更小的模拟与实际差距 (sim-to-real gap),使其能够直接迁移到真实环境,而无需另外训练。
真实环境实验证实了 MetaFold 从仿真到现实的有效迁移能力,成功完成了多种服装的折叠任务,验证了框架的实用性和鲁棒性。


,时长00:29
结论和展望
本研究成功地提出并验证了一个名为 MetaFold 的、用于机器人多类别衣物折叠的语言引导框架。其核心贡献在于:
- 提出了一种创新的解耦架构,将任务规划与动作生成分离,有效提升了系统的性能、泛化性和可解释性。
- 引入点云轨迹作为中间表征,为连接高级语义与底层控制提供了一种高效的桥梁。
- 构建并开源了大规模多类别服装折叠点云轨迹数据集,为后续研究提供了宝贵资源。
参考文献
[1] Canberk, Alper, et al. "Cloth Funnels: Canonicalized-Alignment for Multi-Purpose Garment Manipulation." 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023.
[2] Ganapathi, Aditya, et al. "Learning dense visual correspondences in simulation to smooth and fold real fabrics." 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021.
[3] Raval, Vedant, et al. "GPT-Fabric: Folding and Smoothing Fabric by Leveraging Pre-Trained Foundation Models." CoRR (2024).
[4] Zhou, Bingyang, et al. "Clothesnet: An information-rich 3d garment model repository with simulated clothes environment." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[5] Yu, Xinyuan, et al. "Diffclothai: Differentiable cloth simulation with intersection-free frictional contact and differentiable two-way coupling with articulated rigid bodies." 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023.
[6] Xu, Zhixuan, et al. "Manifoundation model for general-purpose robotic manipulation of contact synthesis with arbitrary objects and robots." 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024.
[7] Bertiche, Hugo, Meysam Madadi, and Sergio Escalera. "Cloth3d: clothed 3d humans." European Conference on Computer Vision. Cham: Springer International Publishing, 2020.
[8] Ravi, Nikhila, et al. "Sam 2: Segment anything in images and videos." arXiv preprint arXiv:2408.00714 (2024).
[9] Wu, Ruihai, et al. "Unigarmentmanip: A unified framework for category-level garment manipulation via dense visual correspondence." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
.....
#特斯拉下一代金色Optimus原型现身
一双「假手」成为最大槽点
一大早,特斯拉的人形机器人 Optimus 整了个「大活」。
Salesforce CEO Marc Benioff 发布了一个短视频,视频中他与一个周身涂抹为金色的 Optimus 进行了一些对话,并盛赞其开启了物理智能体革命,并成为生产力变革者。价格也异常高昂,达到了 20 万到 50 万美元。他还 @了一下马斯克。

马斯克也现身评论区并留言互动。

有眼尖的网友表示,马斯克本人就潜伏在背景里面。

不过,这不是「金色擎天柱」的首次现身,去年就有博主爆料特斯拉打造了一个金色 Optimus,并且还有手部细节。

我们先来看这段视频:
,时长00:52
人与机器人之间的对话内容是这样的:
Commander:嘿,Optimus,你在那儿做什么呢?
- Optimus:没什么,正待命呢,随时可以帮忙。
- Commander:嘿,Optimus,你知道我在哪里能买到可乐吗?
- Optimus:抱歉,我没有实时信息,但如果你想去厨房看看有没有可乐,我可以带你过去。
- Commander: 哦,好啊,那太棒了。是的,就这么办吧。我们走。
- Optimus:好的,我们去厨房吧。
- Commander:
- 好的,好的,走吧。
- 我觉得我们需要给它多一点空间。
- 它现在对空间有点过于敏感了。
- 这样我也能走得快很多。
该说不说,Optimus 走起路来虽然略显迟钝,但还是很稳的:

评论区很多人被 Optimus 如此高的价格震到了。根据此前的预测以及马斯克的说法,大规模量产之后,Optimus 的售价大概为 2 万到 3 万美元。

还有人惊叹 Optimus 的手看起来非常像真人,但是这个手看起来像金属一体的,似乎只是个摆设。

令人啼笑皆非的是,评论区有人表示这是为了防止手部设计被抄袭。

有人做了大胆猜测,「这很可能是 Optimus 2.5 或 V3,它比 Optimus 2 更轻盈。看起来去掉了一些多余的部件,并在设计上做了一些简化。显然,手部的设计目前还处于保密状态。」
特斯拉二代 Optimus 在 2023 年 12 月首次亮相,拥有灵活得像真人的双手以及可在一定幅度内转向的高自由度脖子。此后在灵活性、智能化、人机交互方面不断演进,展示过跳舞、唱歌、倒饮料、猜拳、比心、聊天等多样性动作,还可以识别障碍物、帮人拿物品,在自主导航、物体识别能力上也越来越强。

还有人吐槽 Optimus 看起来又吵又笨重还延迟。

当然也有熟悉的呼叫 grok 环节,不过 grok 否认了。

但有人认为这就是 Grok 语音集成,「使用的 Grok 声音过于做作,拖沓且延迟严重。走路声音很大,听起来就像一桶螺栓在晃动。」

另一边,Figure 也放出了机器人把碗整齐地装进洗碗机的视频。视频里,机器人在厨房精准地把碗、盘子、杯子一件件放进洗碗机,动作流畅精准。
,时长01:07
Figure 表示,他们致力于「把机器人带进千家万户」,并且强调,无论是之前的叠衣服、整理包裹,还是现在将碗碟装入洗碗机,背后都是同一个 Helix 模型(Figure 的 VLA 模型)。其强大的泛化能力并非源于新算法或特殊改造,而仅仅是新数据训练的结果。

有人吐槽称,「杯子和碗放的有些随意,尤其是碗没有叠放起来。」
两家明星机器人同时放出视频,相比之下,Figure 展示了一个此前从未有机器人完成的动作,但没有演示遵循人类指令或沟通互动的能力;而特斯拉 Optimus 更像是走廊中一次偶遇拍摄,表现不尽如人意。

也有人表示,Figure 展示的是 Optimus 早就做过的类似的动作。

「一边是精心准备的 demo,一边是临时遇到的场景。」两段演示显然无法说明一切,但是否意味着特斯拉 Optimus 遇到了一些麻烦呢?
.....
#From reactive to cognitive
让xx智能体拥有「空间感」!清华、北航联合提出类脑空间认知框架,导航、推理、做早餐样样精通
想象一下这样的早晨:
你还在被窝里,你的机器人管家已经在厨房里忙碌了起来:它熟练地导航到燕麦罐、可可球、牛奶,逐一抓取并添加到碗中,最后,它将一碗搭配好的营养早餐送到你的面前,整个过程行云流水,无需任何人工干预。



BSC-Nav 在真实环境中执行「制作早餐」的移动操作任务
这并非科幻片中的桥段,而是来自清华大学与北京航空航天大学团队的最新成果——BSC-Nav 的真实演示。通过模仿生物大脑构建、维护空间记忆的原理,研究团队让智能体拥有了前所未有的「空间感」。
论文标题:From reactive to cognitive: brain-inspired spatial intelligence for embodied agents
arxiv 地址:https://arxiv.org/abs/2508.17198
项目地址:https://github.com/Heathcliff-saku/BSC-Nav
这项工作发布后,立刻引起了业界的关注。有同行评价道:「BSC-Nav 证明了它学习和适应不同环境的强大能力,这可能引领我们迈向更智能的导航机器人时代。」

BSC-Nav(Brain-inspired Spatial Cognition for Navigation)是首个受生物大脑空间认知机制启发的统一框架。它不仅赋予了智能体卓越的通用导航能力,还使其能够完成主动xx问答、复杂移动操作等更高阶的空间感知与交互任务。
当前,以多模态大模型(MLLMs)为代表的基座模型几乎无所不能,我们距离通用人工智能(AGI)还有多远?一个公认的瓶颈在于:如何让 AI 走出虚拟世界,在复杂的物理环境中理解、记忆并与世界高效交互——即实现真正的xx智能。
然而,目前大多数由大模型驱动的xx智能体,更像一条「记忆只有七秒的鱼」。它们主要依赖即时观察做出反应,缺乏对环境长期、结构化的记忆。这导致它们在真实、动态的环境中泛化能力差。
为了攻克这一核心难题,BSC-Nav 团队从认知神经科学中汲取灵感,为xx智能体量身打造了一个结构化的空间记忆系统,并与最前沿的基座模型深度融合,让 AI 从此告别「路痴」,拥有了强大的空间认知能力。
xx智能体的记忆碎片化挑战
现有的xx智能导航方法为何难以形成有效的空间记忆?主要存在两类困境:
- 端到端策略的「记忆固化」:基于强化学习或模仿学习训练的导航策略,其模型参数在训练完成后便固定不变。这使得它们高度依赖训练数据的分布,一旦进入未见的真实环境,便如同刻舟求剑,难以泛化到复杂和动态的环境,更无法在新的探索中积累和更新空间记忆。
- 模块化策略的「记忆短视」:另一类主流的导航方法采用层次化策略,通常由多模态大模型进行上层规划(如规划导航子目标),再由启发式算法执行动作规划。然而,这些方法的空间记忆要么是「即时性」的(仅依赖当前观测),要么是「浅表性」的(如静态的语义地图或抽象拓扑图),不仅表征能力有限,更缺乏有效的更新机制,无法应对真实世界的复杂场景和动态变化。
究其根本,这些挑战都指向同一个核心问题:如何为智能体植入一个能够持续构建、动态更新的强大空间记忆系统。这正是 BSC-Nav 驱动多模态大模型在xx环境中,完成从「被动反应」到「主动认知」这一关键跃迁的基石。
解锁 BSC-Nav 的技术核心:三大「记忆组件」复刻人类空间认知
我们之所以能在复杂的环境中穿梭自如,依靠的并非是超强的「大脑算力」,而在于我们与生俱来的一套高效且灵活的空间认知系统。神经科学研究早已表明,生物大脑主要依赖三种相互关联的空间知识形成稳健的空间认知:
- 地标知识(Landmarks):记住环境中显著的物体,比如「街角的花店」、「桌面上的星巴克咖啡杯」。
- 路线知识(Route knowledge):记住连接地标的移动轨迹,比如「从花店直走,到红绿灯右转」。
- 勘测知识(Survey knowledge):在大脑中形成一张类似地图的全局认知,使我们能够规划捷径或绕行。
BSC-Nav 框架巧妙地将这一生物学原理进行了计算化实现,其核心是三个协同工作的模块:

图:BSC-Nav 从生物空间认知汲取灵感(a),构建结构化空间记忆和检索机制(b),并与多模态大模型结合进行导航规划)
- 地标记忆模块(Landmark Memory Module):该模块采用开放词汇检测器(YOLO-World)识别环境中的显著物体(如沙发、桌子),并记录物体的类别标签、置信度、投影后的空间位置,形成稀疏而高效的「地标」记忆。同时,在每次记录后都会进行坐标重合检测与地标合并,确保每个记录的物体对应环境中的唯一实例。
- 认知地图模块(Cognitive Map Module):这个模块更进一步,通过 DINO-V2 实时编码观测图像的 patch 特征,并投影至统一的体素化网格空间中,每个网格都具有特征缓存池以容纳来自不同视角、不同时期观测的视觉特征。它将智能体的路径观测(路线知识)转化为全局一致的「认知地图」(勘测知识)。该模块采取了「意外驱动」(surprise-driven)的策略。这意味着只有当观察到的新信息与现有记忆产生足够大的「意外」或偏差时,系统才会更新认知地图。这种机制极大地提升了记忆效率,避免了对重复信息的冗余存储。
- 工作记忆模块(Working Memory Module):这一模块实现了人脑视觉-空间工作记忆的功能,用于检索、重构与具体任务相关的空间记忆。当接到任务时(比如「去冰箱拿瓶牛奶」),工作记忆模块会根据指令的复杂程度,决定是从「地标记忆」中快速检索,还是在「认知地图」上进行更复杂的规划。模块中设计了「联想增强」(association-enhanced)的检索策略。对于模糊指令,比如「去那个放着蓝色古典茶壶的桌子」,即使从未精确记录过「蓝色古典茶壶」,系统也能通过多模态大模型丰富指令细节,并依赖图像生成「脑补」出目标的视觉特征,再将其与认知地图中的视觉信息进行匹配,从而实现精准定位。这赋予了智能体前所未有的推理和与泛化能力。

图:工作记忆对不同模态、不同复杂度的目标进行空间位置进行精确定位
碾压式性能提升:多项导航任务刷新纪录
为了全面验证 BSC-Nav 的能力,研究团队在 Habitat 物理仿真环境中,针对四大主流导航任务(目标导航、开放词汇导航、文本实例导航、图像实例导航)进行了覆盖 62 个场景、多达 8195 个导航片段的大规模实验。
结果显示,BSC-Nav 的性能实现了「碾压式」的超越,在各项任务中均超越了以往方法。

图:BSC-Nav 在物体导航、开放词汇导航、文本实例导航和图像实例导航四大基准均实现新的 SOTA
如上图所示,无论是在导航成功率(SR)还是路径效率(SPL)上,BSC-Nav 均显著优于当前领域的顶尖方法。它不仅「找得到」,还「走得快」。例如,在物体导航(OGN)任务中,BSC-Nav 在 HM3D 数据集上的成功率高达 78.5%,比此前的 SOTA 方法 UniGoal 高出整整 24.0%。在更具挑战性的文本实例导航(TIN)任务中,BSC-Nav 更是将成功率提升了近一倍,展现了其强大的多模态理解与定位能力。
更进一步:轻松拿捏复杂导航指令与烧脑提问
强大的空间记忆与多模态大模型的深度融合,赋予了智能体一个能够推理并执行复杂任务的「超级大脑」。它不再只是被动执行单点指令,而是能够理解并拆解长序列任务,甚至能主动探索环境,回答具有空间逻辑的「烧脑」难题。
面对「穿过玻璃门,从沙发和咖啡桌中间走过去,走到冰箱那,然后右转停在楼梯口」这样的长指令,多模态大模型能够智能地将其分解为一系列清晰的子目标(路标点),随后 BSC-Nav 便能像执行多站点任务一样,精准地依次抵达。在权威的长指令导航基准 VLN-CE R2R 中,BSC-Nav 的零样本(zero-shot)表现已非常接近需要大量监督数据训练的顶尖模型,且导航效率(SPL 53.1%)远超所有对手!

图:BSC-Nav 针对复杂指令下的视觉语言导航任务表现出色
更令人印象深刻的是,当被问及「楼上那四幅画下面是什么?」这类需要主动探索和空间推理的问题时,BSC-Nav 能够准确解析问题中的关键实体「四幅画」,主动导航至二楼相应位置,通过仔细观察找到答案,并给出「四幅画下面是一个散热器」的精准回答。在主动xx问答(A-EQA)基准上,BSC-Nav 的表现显著超越了所有基线方法。

图:BSC-Nav 在主动视觉问答基准上的表现超越现有基线方法
从理解长指令到主动回答空间问题,BSC-Nav 展现了从「感知」到「认知」的质的飞跃。它不仅知道「去哪里」,更理解「为什么去」以及「去了之后做什么」,这正是通往通用人工智能所需要的、真正的认知智能。
走向现实:真机实测,导航、移动操作信手拈来!
仿真中的优异表现,能否迁移到充满不确定性的真实世界?这是所有xx智能研究者最为关心的问题,BSC-Nav 给出了肯定的答案!
为了研究在真实环境下的性能,研究团队和松灵机器人团队专门打造了一台集感知、导航和操作于一体的移动机器人平台,并在一个面积约 200 平方米的双层真实室内环境中,对 BSC-Nav 进行了严苛的实地测试。

实验结果再次证明了 BSC-Nav 的强大泛化性。无论是根据简单的物体名称、复杂的文本描述,还是模糊的参考图片进行导航,机器人都能精准、高效地到达目的地。在 15 个不同目标的 75 次随机起点测试中,BSC-Nav 实现了高达 80% 以上的导航成功率(任务成功定义为最终停止位置距离目标小于 1 米)。
此外,得益于其强大的空间认知能力,BSC-Nav 能够无缝衔接复杂的移动操作任务。在演示中,机器人不仅能完成清理桌面、搬运饼干盒等任务,还能执行开篇提到的、包含三次导航和三次操作的「制作早餐」任务。
One More Thing
这项研究最大的启示是什么?
xx智能的进化,或许并不完全依赖于算力和参数的无限堆砌。
生物亿万年的演化已经向我们展示了足够强大和高效的智能范式。正如团队在论文中所写道的:
「从被动响应到主动认知,BSC-Nav 证明了一件事:让机器理解空间,记忆是关键(From reactive behavior to cognitive spatial intelligence, memory is the key)。」
下一步?团队计划将这套类脑记忆框架扩展到更动态的环境和更复杂的认知任务中。
也许在不久的将来,当机器人管家为你做早餐时,它不仅能找到食材,还能记住你昨天说过的「明天我想试试溏心蛋」。
毕竟,是记忆,让智能成为真正的智能。
团队介绍
该工作有两位共同一作,其中一位是来自于北京航空航天大学人工智能研究院的三年级直博生阮受炜,他同时是清华大学 TSAIL 课题组访问博士生,师从韦星星教授、苏航教授。研究方向为深度学习鲁棒性、多模态大模型与空间智能。此前在 IEEE TPAMI、ICCV、ECCV 发表论文 10 余篇,曾获国家奖学金、西电特等奖学金荣誉。
另一位是来自于清华大学心理与认知科学系的助理教授王立元,他先前是清华大学 TSAIL 课题组的博士生和博士后。研究兴趣包括持续学习、终身学习和类脑智能,研究成果以第一/通讯作者发表在 Nature Machine Intelligence、IEEE TPAMI、NeurIPS、ICLR、CVPR、ICCV 等期刊和会议,曾获 CAAI 清源学者、WAIC 云帆奖、WAIC 青年优秀论文奖等荣誉。
团队成员来自于北京航空航天大学和清华大学:阮受炜,王立元(指导老师),康彩新,朱淇惠,刘松铭,韦星星(指导老师,通讯作者),苏航(指导老师,通讯作者)。
.....
#Towards User-level QoE
重新定义个性化视频体验,快手与清华联合提出灵犀系统
近日,快手与清华大学孙立峰团队联合发表论文《Towards User-level QoE: Large-scale Practice in Personalized Optimization of Adaptive Video Streaming》,被计算机网络领域的国际顶尖学术会议 ACM SIGCOMM 2025 录用。该论文提出了一种创新的视频流优化系统 —— 灵犀系统,这是业界首个成功部署在大规模生产环境中、面向用户个性化体验的自适应视频流优化系统。
- 论文:《Towards User-level QoE: Large-scale Practice in Personalized Optimization of Adaptive Video Streaming》
- 论文地址:https://dl.acm.org/doi/10.1145/3718958.3750526
ACM SIGCOMM 是全球计算机网络领域历史最悠久、声望最高的旗舰学术会议之一。该会议对论文的质量和创新性有着极为严苛的标准,每年录用率极低。入选 SIGCOMM 的论文通常代表了网络研究的最新突破和未来方向,不仅要求研究工作具有坚实的理论基础和系统性的实践验证,更强调其对学术界和工业界的深远影响。历史上,从奠定互联网基石的 TCP/IP 协议到引领网络变革的软件定义网络(SDN)等诸多里程碑式的技术,都曾在 SIGCOMM 上首次亮相,深刻推动了全球网络技术的发展与演进。
视频流体验的个性化优化在学术界与工业界已进行诸多探索。然而,现有的方法在真实的大规模生产环境部署中,常常面临着一些根本性制约,如显式用户评分干扰用户体验、控制带宽进行播放干预导致体验受损、优化不连续以及难以规模化等。灵犀(LingXi)系统的设计初衷便是为了系统性地攻克这些难题,实现一个真正可部署、可持续、无打扰的个性化 QoE 优化框架。如下表 1 清晰地展示了灵犀系统与既往方法的核心区别:

表 1:灵犀系统与既有工作的核心区别
一、背景:从传统 QoS 到个性化 QoE 的转变
1. 系统级 QoS 优化的性能瓶颈
为了验证传统 QoS 优化方法的局限性,我们进行了一项为期数天的大规模线上 A/B 测试。实验组采用两种不同的 QoS 优化倾向:Alg2(基线)、Alg3(优先保障视频质量)、Alg1(优先降低卡顿)。如图 1 所示,尽管各算法在具体 QoS 指标(图 1-a;1-b)和线性 QoE 模型(图 1-c)上表现出差异,但在最核心的真实用户体验指标 —— 总观看时长(图 1-d)上,没有任何算法表现出持续且具有统计显著性的优势。这一结果证明,在现代视频流系统中,仅提升系统级的 QoS 指标已难以直接转化为真实用户体验的改善,传统的优化路径已趋于饱和。

(a) 目标 3 实现了最高的视频质量

(b) 目标 1 实现了最低的卡顿时间

(c) 目标 1 实现了最高的线性 QoE 分数

(d) 没有算法可以取得明显的观看时长提升
图 1:A/B 测试中具有不同优化目标的算法获得的 QoS 和 QoE。
2. 识别关键 QoE 影响因子:聚焦 “卡顿”
为了寻找新的优化突破口,我们必须理解不同 QoS 指标对用户行为的真实影响。我们以 “用户退出率” 作为衡量 QoE 的细粒度指标,分析了上百万条真实播放轨迹。

(a) 视频质量

(b) 视频流畅性

(c) 整体卡顿时间

(d) 复合效应下的卡顿时间
图 2:QoS 指标对退出率的影响。
如图 2 所示,我们发现不同 QoS 指标对退出率的影响存在显著的量级差异:
- 视频质量 (图 2-a):影响量级在 10⁻³。
- 视频平滑度 (图 2-b)(码率切换):影响量级在 10⁻²。
- 卡顿时长 (图 2-c):影响量级在 10⁻¹,是前两者的 10 倍乃至 100 倍。
结论 1:在所有 QoS 指标中,卡顿事件是影响用户体验的最主要负向因素。由于其影响的权重远超其他因素,且用户行为本身存在大量与 QoS 无关的噪声,因此,对影响较小的指标进行个性化建模极易被噪声淹没。一个有效的个性化 QoE 优化系统,必须将建模的重心放在用户对卡顿的响应上。
3. 验证个性化优化空间:用户感知的 “千人千面”
在确定卡顿为核心优化目标后,我们进一步探究了用户对卡顿的感知是否存在个体差异。

(a) 平均可容忍卡顿时间的累积分布

(b) 用户在遇到不同卡顿时间时的案例
图 3:卡顿的个性化感知。
如图 3 (a) 所示,用户平均可容忍卡顿时长的累积分布函数表明,用户间的卡顿容忍度差异巨大,并且具有一定稳定性。同时,图 3 (b) 展示了不同用户的真实反应曲线,清晰地呈现出三种模式:敏感型(卡顿轻微增加,退出率即飙升)、阈值敏感型和不敏感型。
结论 2:用户对卡顿的感知和容忍度存在显著的、稳定的个体差异性与时间动态性。这为实现用户级的个性化 QoE 优化提供了坚实的理论基础和巨大的优化空间。
二、算法设计:灵犀系统的三大核心组件
基于以上洞察,我们设计了灵犀系统。它并非一个全新的 ABR 算法,而是一个可以与任何现有 ABR 算法兼容的动态优化目标调整模块。灵犀系统的模块化架构使其能够便捷地集成到现有传输系统中,不对播放过程进行干预保证了生产环境安全,基于用户自然观看行为无需显式反馈避免打扰用户体验,同时通过实时追踪用户偏好变化实现持续的个性化优化。灵犀系统的结构设计如图 4 所示。

图 4:灵犀系统概览
其核心架构由三个协同工作的组件构成:
1. 在线贝叶斯优化 (Online Bayesian Optimization, OBO):参数的动态探索者
由于用户 QoE 与 ABR 参数之间的函数关系是未知的 “黑盒”,并且用户偏好会随时间动态变化。基于这一背景,我们需要一个样本效率高、能处理黑盒问题并适应动态环境的算法,即在线贝叶斯优化 (Online Bayesian Optimization, OBO)。灵犀系统会为每个用户独立运行 OBO 过程,利用历史 “参数 - 体验反馈” 数据点,构建高斯过程代理模型来拟合未知的目标函数。通过最大化采集函数(Acquisition Function),OBO 能够智能地在 “探索”(尝试不确定性高的参数)和 “利用”(选择当前最优的参数)之间进行权衡,为每个用户持续迭代寻找当前最优的 ABR 参数(如卡顿惩罚因子)。
2. 蒙特卡洛采样 (Monte Carlo Sampling):决策的未来模拟器
当 OBO 给出一个候选参数后,灵犀系统会启动蒙特卡洛模拟。它基于用户历史网络状况建立带宽模型,并从当前播放器状态开始,进行多次独立的虚拟播放。在每次模拟中,系统都使用该候选参数驱动 ABR 进行决策,并利用退出率预测器计算每个 segment 的退出概率。最终,通过汇总所有模拟轨迹的平均退出率,来评估该候选参数的长期影响,从而实现对短期和长期 QoE 的对齐。
3. 混合退出率预测器 (Hybrid Exit Rate Predictor):体验的精准量化器

图 5:混合退出率预测器神经网络架构
卡顿是影响 QoE 的主导因素,且其与其他 QoS 指标(如画质、观看时长)的交互效应复杂且非线性。因此,我们设计了一个混合模型来捕捉这种复杂性,既保证对核心痛点(卡顿)进行个性化精准建模,还有效避免了在低影响因素上的个性化建模所可能引入的噪声,从而实现了模型性能与鲁棒性的平衡。
- 个性化神经网络:专门用于预测发生卡顿时用户的退出率。该网络(如图 5 所示)输入包括短期播放状态(码率、吞吐量、卡顿时长序列)和长期用户状态(历史卡顿间隔、历史卡顿 - 退出间隔),能够捕捉复杂的非线性关系和用户个体特征。
- 整体统计模型:对于未发生卡顿的场景,由视频质量、平滑度等影响较小的因素主导,我们使用从全体用户日志中得到的统计模型进行预测。
三、实验效果:大规模 A/B 测试的有力证明
我们在快手平台上进行了为期 10 天的大规模 A/B 测试,将灵犀系统与生产环境中经过高度优化的基线 ABR 算法进行对比。
1. 整体 QoE 与 QoS 双重提升

(a) 总观看时长

(b) 码率

(c) 卡顿时间
图 6:灵犀系统的 A/B 实验。
实验结果显示,灵犀系统在总观看时长(QoE)、平均视频码率(QoS)、总卡顿时长(QoS)方向上均取得了全面且显著的性能提升。这证明灵犀系统在优化用户主观体验的同时,也协同改善了客观服务质量指标。
2. 低带宽长尾用户的显著收益
灵犀系统更大的价值体现在对播放体验更敏感的低带宽用户上。

(a) 在线参数

(b) 卡顿时间
图 7:不同带宽下的灵犀系统性能
如图 7 所示:
- 参数自适应:在低带宽(<2000 kbps)区域,卡顿风险高,灵犀自动为用户分配了更保守的 ABR 参数;在高带宽区域,则采用更激进的参数以追求更高画质。
- 卡顿优化效果:在带宽低于 2000 kbps 的场景下,灵犀系统使卡顿时长减少了约 15%,极大地改善了弱网用户的观看体验。
3. 个性化优化的直接验证
为了验证灵犀系统在 “因人而异” 优化方面的效果,我们分析了用户的卡顿敏感度与其对应参数之间的关系。






图 8:多日卡顿退出率与ABR参数关系分析。
如图 8 所示,用户的卡顿退出率(衡量其对卡顿的敏感度)与系统为其分配的 ABR 参数之间存在明显的负相关关系。即对卡顿越敏感(退出率越高)的用户,系统分配的参数越保守,反之亦然。
四、总结
灵犀(LingXi)系统的成功实践,标志着自适应视频流优化范式的一次关键演进,即从以往追求单一、静态的系统级优化目标,转向了为成千上万个动态、独立的个性化用户目标提供量身定制的策略,实现了真正的 “千人千面”。
该系统通过混合预测器、蒙特卡洛模拟与在线贝叶斯优化架构,精准量化并持续适应每个用户的独特体验偏好。在覆盖数千万用户的生产环境验证中,这一用户级优化范式不仅带来了整体 QoE 与 QoS 的双重提升,更关键的是,它为长期困扰行业的弱网用户带来了高达 15% 的卡顿减少,并直观地展现了为不同敏感度用户匹配差异化策略的能力。综上,灵犀系统为大规模、用户级的个性化 QoE 优化提供了突破当前行业瓶颈的关键路径。
.....
#人工智能专业排名全球前10的MBZUAI启动本硕博项目招生
在阿联酋 2031 国家人工智能战略的驱动下,穆罕默德・本・扎耶德人工智能大学(MBZUAI) 正以 AI 专业学术全球排名前十的硬实力,重塑 AI 教育格局。这所由阿联酋总统创立的学术引擎,不仅承载着中东向科技转型的雄心,更以丰厚奖学金覆盖所有学位项目,为全球优秀人才铺就一条通往未来的黄金大道。
迎向未来:国家战略背书的 AI 学术高地
2017 年,阿联酋总统穆罕默德在石油经济腹地播下一颗 AI 种子 —— 启动了《阿联酋人工智能战略 2031》(UAE National Strategy for Artificial Intelligence 2031),目标是在 2031 年使阿联酋成为全球人工智能领域领导者。
- 在能源、物流、旅游、医疗、教育、网络安全等九大优先行业部署人工智能,通过概念验证资金和政府 — 企业联合试点,提升国家核心竞争力。
- 引入全球顶尖科研力量,共建 MBZUAI(全球第一所专注于研究人工智能的大学)、国家虚拟研究院、“思想家计划” 等,形成区域人才高地。
- 通过设立加速器、20 亿迪拉姆创新基金、外资激励计划,培育本土初创企业,吸引外国直接投资。
- 打造 “UAI” 国家品牌与四级认证体系(公共 / 私营 / 机构 / 产品),推动阿联酋成为全球人工智能首选目的地。
- 建立全球首个 “人工智能政府专门委员会”(IPCC for AI),制定伦理、法律、网络安全三位一体的国家治理体系,并向全球输出阿联酋标准。
- 预计到 2031 年,人工智能产业将为阿联酋带来 3350 亿迪拉姆的额外经济产出,相当于非石油 GDP 的 20%。
《阿联酋人工智能战略 2031》全文:https://ai.gov.ae/wp-content/uploads/2021/07/UAE-National-Strategy-for-Artificial-Intelligence-2031.pdf
在国家战略支持下,MBZUAI 作为全球第一所人工智能大学,自 2019 年 10 月筹备以来,吸引了世界各地的顶尖学者、研究人员和天才学生加入。今天,MBZUAI 在其专业领域排名已跻身全球前十之列(#10 by CS Rankings 2015-2025 in Artificial intelligence, Computer vision, Machine learning, Natural language processing, Comp. bio & bioinformatics, and Robotics),超越众多欧美传统名校。

塑造未来:MBZUAI 快速崛起的硬核实力
1、 顶配资源:从教授天团到硬件王牌
在阿联酋国家战略层面的高度重视和雄厚的资本支持下,MBZUAI 成立短短几年就吸引了来自 CMU、伯克利、MIT、佐治亚理工、哈佛、剑桥、慕尼黑工业大学等全球 AI 名校的逾百名顶尖学者前来任教。
由机器学习与生物健康领域的国际知名学者 Eric Xing 邢波校长领衔的教授天团包括:图灵奖获得者 Raj Reddy、美国三院院士 Michael Jordan 教授、曾任 MIT AI 实验室副主任的 Sir Michael Brady 教授、慕尼黑工业大学机器人与系统智能系主任 Sami Haddadin 教授、前 Google 用户体验总监 Elizabeth Churchill、东京大学知名教授 Yoshihiko Nakamura、自然语言处理专家 Timothy Baldwin 教授等。

根据来自南京外国语学校的张佳栋同学介绍:“今年 MBZUAI 的教职人数达到 120 人,师生比非常高,教授们能更直接地帮助每个同学。我一入学就与教授建立了每周一对一的讨论时间,来探讨关于 Optimization 的相关学习。可以说,不管你想学什么,都可以找到对应方向的顶尖大牛帮助你。”
同时,MBZUAI 也跟业界知名企业和实验室保持着密切交流,特聘讲师团汇聚了来自英伟达、谷歌、微软、亚马逊、Meta 等公司的行业专家,为学生和研究人员带来行业前沿的研究动态、应用经验和实践思考。
硬件上,阿联酋已经跻身世界 AI 算力强国之列,MBZUAI 配备了足以支撑世界级人工智能研究所需的计算能力基础设施,硬件实力不亚于谷歌等世界顶尖机构。MBZUAI 还通过其基础模型研究所(IFM)进行全球布局,在美国硅谷、法国巴黎以及阿布扎比都建立了实验室设施。这种 “多站点计划” 使其能够连接全球顶尖 AI 生态,并有助于整合利用不同地区的计算资源和人才资源,为学校在 AI 领域的可持续发展提供了坚实的硬件和软件基础。

2、 产研结合:技术 + 商业的密切链接
从创立之初,MBZUAI 注重理论与实践的结合。学校里很多教授不仅是老师,同时也是企业家、创业者或者大公司的高管。他们的研究方向并非纯粹的学术探索,而是更注重解决实际产业问题。
计算生物学方向的生命大模型研究、机器人方向的人脑控制机器人研究、计算机视觉专业生成虚拟现实的世界模型研究等 AI 前沿研究项目,让 MBZUAI 这个成立仅 5 年多的人工智能新秀持续成为全世界关注的焦点。截止发稿日,MBZUAI 在顶级期刊和会议上发表的总论文数已超过 2,000 篇。
本科项目的负责人 Hao Li 教授,既是计算机视觉领域的专家学者,也是好莱坞著名视觉特效公司 Pinscreen 的创始人兼 CEO,其设计的 “3+1” 学制,让来自全世界的天才少年们,在前三年接受到系统的人工智能学科教育,第四年则通过为期一年的实习或科研,形成链接真实世界的产业视角。
据在读学生介绍,不仅阿联酋当地的企业和 MBZUAI 有深度合作,在学校周边还有许多国际知名企业,实习机会非常多。学校的孵化器每周都有讲座,邀请各界商业领袖分享前沿的看法。

3、 光明前景:职业发展的黄金通道
得益于从始至终贯彻的产研结合,MBZUAI 的毕业生们前景一片光明。他们中既有人继续留在 MBZUAI 或是前往牛津大学、苏黎世理工等名校继续深造的学者,也有人选择入职大公司或自主创业,其中有近 90% 的毕业生留在阿联酋,硕士毕业生平均年薪 36 万迪拉姆(约 10 万美金)。考虑到阿布扎比的物价水平和发展机会,这个薪资水平的实际购买力含金量相当不俗。
值得一提的是,MBZUAI 招收的阿联酋本地学生中,不乏王室成员中的精英代表,学校还设有专门的团队为有创业意向的学生提供创业孵化指导和融资渠道支持,目前已经有多支学生团队拿到创业资金。从学术到产业,MBZUAI 致力于为人工智能人才铺设职业发展的黄金通道。

4、 未来之城:安全、多元与机遇的交汇点
MBZUAI 位于阿联酋首都阿布扎比。这座地处欧洲、亚洲和非洲交汇点的历史文化名城,拥有得天独厚的区位优势,连续多年被评为全球最安全的城市之一,犯罪率接近于零,社会环境稳定,对外国人友好且包容,近年来已经成为备受青睐的国际化都市和最具活力的世界商业中心之一。
作为阿布扎比发展版图上的闪耀明星, MBZUAI 汇聚了来自 47 个国家地区的天才学生。据在校学生分享,阿布扎比的安全、干净和现代化程度是可以跟国内一线城市媲美的,硬件设施好,宿舍宽敞舒适、网速很快、生活便利。在阿联酋本地人不多见,一般打交道的都是外国人,大家地位平等互相尊重即可,都说英语,也不用担心语言问题。值得一提的是,MBZUAI 学校的食堂品质很好,不仅供应当地菜系还有沙拉、披萨、汉堡等选择。如果吃不惯,阿布扎比也有温超,还有中餐厅可以配送盒饭,总能找到适合自己胃口的中国菜。
在读期间,学校会给每位学生办理签证,毕业后可由雇主办理十年黄金签证,且工资免税。安全、多元、充满机遇的国际化都市,也为选择 MBZUAI 的提供了未来发展的更多可能。
神仙打架:录取率 5% 的 AI 梦校
8 月,MBZUAI 迎来了 403 位新生,他们从 8,000 多名申请者中脱颖而出,阿联酋政府为 2025 年的所有学生提供了全额奖学金,覆盖学费、住宿费、医疗保险和签证费用。其中,本科生项目今年共收到超过 2,000 份申请,最终仅录取来自 25 个国家的 115 名学生,录取率不到 5%,难度不亚于英美名校。
这其中,不乏有全球数学、信息学、人工智能等领域的奥赛奖牌得主,比如来自希腊的 Kyriakos Tsourekas 同学,曾先后于 2024 和 2025 年获得 IMO 金牌和银牌,同时也是多次游泳和象棋比赛奖牌得主;来自俄罗斯的 Arthur Leontiev 同学,是 LeanTech AI Lab 的创始人,拒绝了美国 2 所牛校的全奖,选择了 MBZUAI;来自印尼的 Faiz Ramadhan 同学和来自印度的 Rayan Banerjee 同学,是 2025 国际人工智能奥赛银牌得主;来自北京十一中学的国家一级运动员 Alda Wang 同学,放弃了多个来自美国名校的 Offer,选择来 MBZUAI 攻读人工智能专业。
Alda 的妈妈曾在剑桥大学取得硕士学位,对于国际教育有着深刻清醒的认识,她在采访中表示,孩子入学后的体验 “超乎预期”。首先是学术方面,MBZUAI 的师资力量和师生配比在全球是顶尖的,很多课程采用分层小班教学,孩子在大一就能选到闫令琪教授这种级别学者的课,而且还有机会参与到课题组研究中,感觉很兴奋。相比之下,美国名校 STEM 相关课程大多数都还是上百人的大班教学,而提供小班教学的文理学院又没有计算机相关课程,对于有志于深耕人工智能领域的学生来说,MBZUAI 是一个很好的选择。其次在生活方面,学校提供的宿舍和食堂也让大家很满意。寝室硬件条件无可挑剔,入学时校方更是贴心地连床单、被子、枕头等床品都准备好了。家乐福超市步行可达,购物很便利。学校食堂自助餐只要约 50 元人民币,附近还有非常棒的亚洲餐厅。更惊喜的是,除了原本承诺的覆盖学费、住宿费、医疗保险和签证的奖学金之外,学校还额外提供了每月 3500 迪拉姆(约 7000 人民币)的津贴,以及往返机票的费用,让孩子们更有动力专注学习和研究。
来自中国的 NOI 信息奥赛银牌得主王学逸同学分享:“我高中阶段就对 CS 和 AI 的一些研究方向有初步了解,有较强的科研兴趣,希望本科阶段能探索科研方向、确认自己是否适合科研。MBZUAI 作为一所上升潜力巨大的研究型高校,科研资源丰富,特别是人均资源很充足,非常契合我的规划。相比传统高校,MBZUAI 对学生培养更加自由,鼓励课堂外探索(科研、实习、创业),允许学生免修已掌握课程,从而有更多时间学习高级知识或进行课外探索。”
全面开启:2026 年本硕博招生通道
2025 年 9 月,MBZUAI 开启了 2026 年秋季入学的本硕博招生通道,无需任何申请费用,并将继续为优秀人才提供丰厚的奖学金。
本科申请面向全球高中毕业生,在 MBZUAI 官网提交简历、成绩单、学校在读证明和个人陈述即可进行申请,还可提交奖项证书、推荐信等材料作为补充。在录取过程中,MBZUAI 不限地域、年龄、民族,主要寻求学业成绩优异兼具数学技能、沟通能力、领导力和创业精神的候选人,并将优先考虑有强大编程能力,在数理竞赛或商业竞赛获奖,或是在体育、艺术领域有杰出特长的候选人。
据 MBZUAI 教务长兼自然语言处理教授 Timothy Baldwin 介绍,本科课程分为两个方向 —— 工程和商科,前者侧重于人工智能模型的开发和部署,后者专注业务整合和创业。“工程专业更侧重于核心技术技能,例如自然语言处理等人工智能技能。商科专业则更侧重于创业能力、金融能力和沟通能力,但所有这些能力都与人工智能密切相关。MBZUAI 的目标是让学生从这些课程中培养创业思维,成为引领人工智能转型的人才。”
学士课程的学制是 4 年,第四年以行业实践为主,学生需要在企业、初创公司或研究所体验真实的行业、学术环境,本科生的最低学位要求为 120 个学分。
来自中国的 2025 级本科生杨永函同学介绍:“MBZUAI 的课程设置非常新颖,这里没有过多的传统课业,而是以人工智能为核心不断提供让我们接触前沿科研和跨学科应用的机会,还有大四一年的 Co-Op 实践我们的学识。虽然本科目前只有人工智能方向,但学校基于对本科生创业的愿景将人工智能大方向的课程分成了有很多交集的工程路径和商业路径。得益于较小的本科生人数,我跟这学期的教授都有频繁联络,我非常享受在教授 Office Hours 畅谈。教授们都非常厉害,让我同时了解了不同类型的天才,我也很想感谢他们分享、甚至带我参与他们感兴趣的学术问题中。”
研究生项目目前有计算机视觉、机器学习、自然语言处理、机器人、计算机科学、统计与数据科学六个专业,另外预计近期开设计算生物学和人机交互专业这两个新专业,要求申请人具有计算机 / 工程 / 数学 / 物理等人工智能相关理工类专业学历(GPA 3.2+),博士需提交研究计划,直博生需要提供论文或 GRE 成绩。据在读研究生分享,除了学费、医疗保险和签证费用全部由奖学金覆盖,研究生还额外享有每年 5 到 14 万美元津贴。强大的导师团队、雄厚的硬件实力再加上丰厚的资金支持,使得 MBZUAI 备受 AI 领域顶尖人才的青睐,往届研究生主要来自清华、北大、CMU、MIT、斯坦福等顶尖名校,竞争也相当激烈。
- 本科申请时间:
ED 和 RD 申请开放日期:2025 年 9 月 1 日
ED 申请截止日期:2025 年 11 月 15 日
ED 录取最晚公布日期:2025 年 12 月 31 日
RD 申请截止日期:2026 年 4 月 30 日
RD 录取最晚公布日期:2026 年 6 月 15 日
提前决定(ED)申请是具有约束力的承诺。若被接受,申请人将承担法律和道德上的义务,必须加入 MBZUAI 并撤回所有其他申请。所有 ED 和 RD 申请都是滚动审核的,因此鼓励尽早提交。
大部分 ED Offer 将提供全额奖学金,RD 轮中的优秀申请者也将有机会获得全额奖学金。
- 研究生申请时间:
- 优先申请期限: 2025 年 11 月 15 日
- 最终截止日期: 2025 年 12 月 15 日
- 录取截至日期: 2026 年 3 月 15 日
- 官网申请:点击直达 (https://mbzuai.ac.ae)
特别通道:拿到本科 Offer 的候选人很有可能被邀请携家长到 MBZUAI 访校(中国往返阿布扎比机票 2 张及访校期间酒店费用均由校方提供)。
正如 Eric Xing 邢波校长所言:“我们正在重新定义人工智能教育的意义 —— 不只是培养工程师,更要培养企业家、设计师、影响力人物、高级管理者和远见卓识的创新者,让他们在各行各业推动人工智能发展。”
.....
#InfinityHuman
长视频AI数字人来了!字节×浙大推出商用级音频驱动数字人模型
随着内容创作智能化需求的爆发,长时长、高质量数字人视频生成始终是行业痛点。近日,字节跳动商业化 GenAI 团队联合浙江大学推出商用级长时序音频驱动人物视频生成模型 ——InfinityHuman,打破传统音频驱动技术在长视频场景中的局限性,开启 AI 数字人实用化新征程。
从静态图像到动态视频:
音频驱动的 "数字复活术"
只需提供一张人物图像与对应音频素材,InfinityHuman 就能自动生成连贯自然的高分辨率长视频:无论是 30 秒的产品快推、还是 3 分钟的演讲致辞,均能实现专业级呈现。技术团队演示中,仅凭一段音频即可让电影中的人物复活 " 为动态数字人,视频效果生动自然,肢体动作与语音节奏高度同步。
,时长01:00
该图由 AI 生成
核心突破:攻克长视频两大技术难关
InfinityHuman 的关键优势在于创造性解决了长期动画中的两大核心难题:
- 身份漂移难题:通过 "姿态引导优化" 技术,以稳定的骨骼姿态序列为锚点,结合初始图像的视觉特征,确保数字人在长时间视频中保持面部特征、光影风格的一致性,避免传统技术中常见的 "越生成越不像" 问题。
- 细节失真难题:精准捕捉并还原手部交互、面部微表情、情感起伏等细节,让数字人的手势动作自然流畅,情绪表达细腻真实,突破同类技术中 "手部僵硬"" 表情呆板 " 的瓶颈。
商用场景全面落地,推动数字人技术实用化
从项目主页展示的案例来看,InfinityHuman 已实现多场景商用级应用:
- 电商带货中,虚拟主播可手持商品进行沉浸式讲解;
- 企业培训中,虚拟讲师能完成长时间课程录制;
- 自媒体创作中,数字人主播可实现每日内容量产。
尤其值得关注的是,该模型对中文语音的支持效果尤为出色,在分钟级长视频中仍能保持身份稳定与手部动作自然,充分满足中文内容创作需求。
,时长00:30
,时长00:28
,时长00:20
技术细节与更多展示
如需了解更多技术细节和效果演示,可访问:
- 论文项目主页:https://infinityhuman.github.io/
- 技术报告:https://arxiv.org/pdf/2508.20210
方法概述
如图所示,InfinityHuman 是一个统一框架,旨在通过单张参考图像、音频和可选文本提示生成长时间、全身的高分辨率说话视频,确保视觉一致性、精准唇同步和自然手部动作。该框架采用 “由粗到细” 策略:先通过低分辨率音视频生成模块得到含粗略动作的低分辨率视频,再由姿态引导细化模块结合低分辨率视频和参考图像生成高分辨率视频,同时引入手部校正策略提升手部动作的真实感与结构完整性。
低分辨率音视频生成模块基于 Flow Matching 和 DIT,融合参考图像、文本、音频等多模态信息,通过多模态条件注意力机制增强音频与视觉的对齐;姿态引导细化模块利用参考图像作为身份先验,结合低分辨率视频及其姿态序列,通过前缀潜变量参考策略和姿态引导确保长时生成中的时序连贯性与外观一致性;手部特定奖励反馈学习则针对手部易出现的畸变问题,利用预训练奖励模型进行偏好微调,提升手部结构的合理性与真实感。

实验结果
实验结果表明,InfinityHuman 在音频驱动全身说话视频生成任务中表现优异。在 EMTD 和 HDTF 数据集上的评估显示,该方法在视觉真实感(FID)和时序连贯性(FVD)指标上均优于 FantasyTalking、Hallo3 等主流基线方法,生成视频的整体质量显著提升。身份一致性方面,通过姿态引导细化模块有效维持了与参考图像的相似度,解决了长时生成中的外观漂移问题。针对手部生成这一难点,手部特定奖励反馈学习显著提升了手部关键点的准确性,减少了手指畸变、关节异常等常见问题,尤其在复杂手势场景中表现稳定。
消融实验进一步验证了核心模块的有效性:移除姿态引导细化模块会导致视觉质量下降、身份一致性减弱,视觉细节模糊且时序连贯性降低;取消手部奖励机制则使手部关键点精度下降,手部失真现象明显增多。
综合定量指标和定性分析,InfinityHuman 在高分辨率、长时长视频生成任务中实现了真实感、一致性与动作自然度的全面提升。

字节跳动 VIVID Avatar 团队:深耕音视频数字人技术,推动AI生成走向实用化
作为字节跳动旗下专注于音视频数字人生成的研发力量,商业化 GenAI 的 VIVID(Voice Integrated Video Immersive Digital)Avatar 团队始终站在技术前沿,致力于突破音频与视觉融合的技术边界。团队以 “让数字人更鲜活、更实用” 为目标,在语音合成与视频生成两大方向持续深耕,形成了从基础研究到商业化落地的完整技术链路。
语音合成方向,团队推出 MegaTTS3、Make-An-Audio 2 等模型,视频生成领域,从长视频模型 HumanDiT、NeurIPS 2024 收录的 MimicTalk 个性化 3D 建模,到 ICLR 2024 Spotlight 成果 Real3D-Portrait 单样本 3D 合成,再到 DiTalker 等音频驱动方案,构建了覆盖长视频、3D 肖像、实时驱动的完整技术矩阵。目前,团队已通过 GitHub 开源平台(https://github.com/VIVID-Avatar/)分享多项核心技术,并将最新研发的长时序音频驱动视频生成模型 InfinityHuman 部署至商业化即创平台,让前沿技术从实验室快速走向产业应用,为内容创作、教育培训、电商直播等领域提供低成本、高质量的数字人解决方案。
.....

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐


 23
23 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)