【深入理解 Linux 网络】数据发包原理与内核实现
本系列文章
- 【深入理解 Linux 网络】关键术语
- 【深入理解 Linux 网络】内核初始化流程
- 【深入理解 Linux 网络】收包原理与内核实现(上) 从网卡到协议层
- 【深入理解 Linux 网络】收包原理与内核实现(中)TCP 传输层处理
- 【深入理解 Linux 网络】收包原理与内核实现(下)应用层读取与 epoll 实现
- 【深入理解 Linux 网络】数据发送处理流程与内核实现
- 【深入理解 Linux 网络】配置调优与性能优化
数据的接收和处理流程分析完了,本篇我们来看下数据的发送流程。
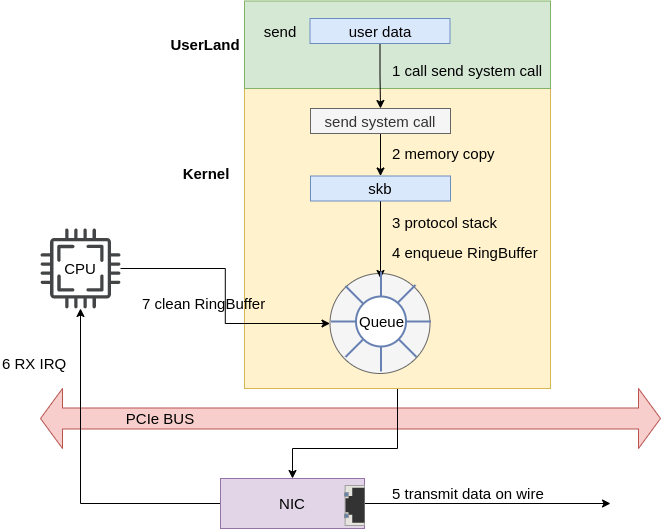
从系统的视角俯瞰,一个数据包从用户程序发出并到达网卡的流程如下:
- 用户程序:执行 send 系统调用,发送数据。
- socket 协议族处理:socket 根据传递的协议族信息找到相应的协议族处理函数。
- 协议族处理:即传输层处理,我们这里以 TCP 为例进分析,这一步会将数据 data 封装为 packet。
- IP 层处理
- 邻居子系统处理
- 网络设备子系统处理
- 网卡驱动处理
- 网卡发包
下面我们来看下每一步是怎样实现的。
系统初始化
在 【深入理解 Linux 网络】内核初始化流程 中我们提到过内核协议栈的初始化,当时只分析了 inet_init 方法中为收包执行 inet_add_protocol 注册协议栈将 ip_rcv、tcp_rcv 等收包函数注册到内核的流程。
除此之外该函数还执行了具体协议和 socket 相关初始化,代码如下:
https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/af_inet.c#L1942
static int __init inet_init(void)
{
...
rc = proto_register(&tcp_prot, 1);
if (rc)
goto out;
rc = proto_register(&udp_prot, 1);
if (rc)
goto out_unregister_tcp_proto;
rc = proto_register(&raw_prot, 1);
if (rc)
goto out_unregister_udp_proto;
rc = proto_register(&ping_prot, 1);
if (rc)
goto out_unregister_raw_proto;
/*
* Tell SOCKET that we are alive...
*/
(void)sock_register(&inet_family_ops);
/*
* Add all the base protocols.
*/
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
...
内核在这里完成两项关键任务:
- 传输层协议栈的注册
- Socket 协议族操作的注册
注册 TCP 传输层协议
内核调用 proto_register(struct proto *prot, int alloc_slab) 注册传输层的相关协议。这里注册了四种传输层协议:
- TCP
- UDP
- PING 协议:基于 ICMP 协议的 ping 命令的优化实现
- RAW 协议:原始套接字,绕过传输层直接与 IP 层通信
以 TCP 协议为例,其默认定义好的结构体为 tcp_prot,这是 TCP 协议在 Linux 内核中的完整定义,包含了TCP协议的所有操作函数和配置参数。
struct proto tcp_prot = {
.name = "TCP", // 协议名称
.owner = THIS_MODULE, // 所属模块
.close = tcp_close, // 关闭socket(优雅关闭)
.pre_connect = tcp_v4_pre_connect, // // 连接前的预处理
.connect = tcp_v4_connect, // 建立TCP连接(客户端)
.disconnect = tcp_disconnect, // 断开连接
.accept = inet_csk_accept, // 接受新连接(服务端)
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock, // socket初始化函数
.destroy = tcp_v4_destroy_sock, // socket销毁函数
.shutdown = tcp_shutdown, // 关闭读写方向
.setsockopt = tcp_setsockopt, // 设置socket选项
.getsockopt = tcp_getsockopt, // 获取socket选项
.bpf_bypass_getsockopt = tcp_bpf_bypass_getsockopt,
.keepalive = tcp_set_keepalive, // 设置keepalive参数
.recvmsg = tcp_recvmsg, // 接收数据函数
.sendmsg = tcp_sendmsg, // 发送数据函数
.sendpage = tcp_sendpage,// 零拷贝发送page
.backlog_rcv = tcp_v4_do_rcv, // 处理积压数据的接口,内核接受数据时 TCP 层的主要处理函数
.release_cb = tcp_release_cb,
.hash = inet_hash, // 将socket加入哈希表
.unhash = inet_unhash, // 从哈希表移除socket
.get_port = inet_csk_get_port, // 获取可用端口
#ifdef CONFIG_BPF_SYSCALL
.psock_update_sk_prot = tcp_bpf_update_proto,
#endif
.enter_memory_pressure = tcp_enter_memory_pressure, // 进入内存压力状态
.leave_memory_pressure = tcp_leave_memory_pressure, // 退出内存压力状态
.stream_memory_free = tcp_stream_memory_free, // 流内存释放
.sockets_allocated = &tcp_sockets_allocated, // 当前TCP socket数量
.orphan_count = &tcp_orphan_count, // 孤儿socket数量
.memory_allocated = &tcp_memory_allocated, // // TCP使用的总内存
.memory_pressure = &tcp_memory_pressure,
.sysctl_mem = sysctl_tcp_mem, // 内存限制配置
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_tcp_wmem), // 写缓冲区配置偏移
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_tcp_rmem), // 读缓冲区配置偏移
.max_header = MAX_TCP_HEADER, // 最大TCP头部大小
.obj_size = sizeof(struct tcp_sock), // TCP socket对象大小
.slab_flags = SLAB_TYPESAFE_BY_RCU, // SLAB缓存标志
.twsk_prot = &tcp_timewait_sock_ops, // TIME_WAIT状态socket操作
.rsk_prot = &tcp_request_sock_ops, // SYN_RECV状态socket操作
.h.hashinfo = &tcp_hashinfo, // TCP哈希表信息
.no_autobind = true, // 禁用自动端口绑定
.diag_destroy = tcp_abort,
};
注册协议族 Socket 操作
注册完传输层协议后会执行 (void)sock_register(&inet_family_ops); 将 IPv4 协议族的 socket 操作注册到内核中。协议族结构体如下:
// https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/af_inet.c#L1117
static const struct net_proto_family inet_family_ops = {
.family = PF_INET, // 即 AF_INET
.create = inet_create, // socket 创建方法
.owner = THIS_MODULE,
};
这里的关键是 inet_create 函数,这是创建 Socket 的入口函数。
注册 socket 接口映射
inet_create 只是一个入口,在具体创建时还需要根据不同的协议类型去执行具体的任务,因此 inet_create 会根据 socket 的类型和协议查找合适的处理函数,这些处理函数也是在协议栈注册时初始化好的。在注册完 socket 以及调用 inet_add_protocol 注册完协议栈后,会执行如下两行代码进行注册:
static int __init inet_init(void) {
...
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
...
}
这里会初始化一个链表,将 inetsw_array 中的所有元素插入到 inetsw 的链表中。inetsw_array 是预定义好的协议操作数组,代码如下:
/* Upon startup we insert all the elements in inetsw_array[] into
* the linked list inetsw.
*/
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
},
{
.type = SOCK_RAW,
.protocol = IPPROTO_IP, /* wild card */
.prot = &raw_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
}
};
可以看到这里定义了 TCP、UDP、ICMP 和 RAW 四种协议的 socket 操作。以 TCP 为例,相关操作定义在 inet_stream_ops,代码如下,可以看到我们熟悉的 bind、connect、listen、accept 以及用于数据接收和发送的 recvmsg、sendmsg 等函数。
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept,
.getname = inet_getname,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
#ifdef CONFIG_MMU
.mmap = tcp_mmap,
#endif
.sendpage = inet_sendpage,
.splice_read = tcp_splice_read,
.read_sock = tcp_read_sock,
.sendmsg_locked = tcp_sendmsg_locked,
.sendpage_locked = tcp_sendpage_locked,
.peek_len = tcp_peek_len,
#ifdef CONFIG_COMPAT
.compat_ioctl = inet_compat_ioctl,
#endif
.set_rcvlowat = tcp_set_rcvlowat,
};
Socket 创建
了解完 Socket 相关的初始化流程,我们可以看下数据发送的流程了。下面是一个示例程序:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
int main() {
int sock;
struct sockaddr_in server_addr;
char *msg = "Hello, Server!\n";
// 1. 创建 socket
sock = socket(AF_INET, SOCK_STREAM, 0);
if (sock < 0) {
perror("socket");
exit(1);
}
// 2. 设置服务器地址
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(8080); // 目标端口
server_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); // 目标 IP
// 3. 连接服务器
if (connect(sock, (struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) {
perror("connect");
close(sock);
exit(1);
}
printf("Connected to server!\n");
// 4. 发送数据
if (send(sock, msg, strlen(msg), 0) < 0) {
perror("send");
close(sock);
exit(1);
}
printf("Message sent: %s", msg);
// 5. 关闭 socket
close(sock);
return 0;
}
Socket 初始化
当我们执行代码 sock = socket(AF_INET, SOCK_STREAM, 0); 时,这是用的 glibc 提供的系统调用,会通过 Linux 系统调用层 根据我们提供的 AF_INET 协议族和 SOCK_STREAM 类型找到相应协议族实现。对于 IPv4 协议族和 TCP 协议,就是执行到注册的 inet_create 函数和 inetcp_v4_init_sock 函数,核心逻辑如下:
- 基于 socket 的参数确定协议。
- 查找注册的 socket 映射表,将协议操作绑定到 socket。
- 分配 socket 内核对象并初始化。
- 如果需要,加入哈希表。
- 如果需要,执行协议初始化,如 tcp_v4_init_sock。
- 如果需要,执行 BPF 相关操作。
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
sock->state = SS_UNCONNECTED;
// 查找协议
lookup_protocol:
err = -ESOCKTNOSUPPORT;
rcu_read_lock();
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
if (answer->protocol == protocol) {
/* Found a matching protocol. */
err = 0;
break;
}
}
// 将协议操作绑定到 socket
sock->ops = answer->ops;
answer_prot = answer->prot;
answer_flags = answer->flags;
rcu_read_unlock();
...
// 分配 socket 内核对象
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
...
// 初始化socket数据结构
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv; // 如 TCP:tcp_v4_do_rcv
if (inet->inet_num)
// 如果需要,加入哈希表
err = sk->sk_prot->hash(sk);
// 如果需要,执行协议初始化,如 tcp_v4_init_sock
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk);
}
// BPF 相关操作
if (!kern) {
err = BPF_CGROUP_RUN_PROG_INET_SOCK(sk);
}
}
Socket 队列初始化
网络数据的收发会有接收队列和发送队列,熟悉 TCP 协议的同学一定对 net.ipv4.tcp_rmem 和 net.ipv4.tcp_wmem 这两个参数不陌生,它们分别用于设置 TCP 套接字的接收和发送缓冲区队列大小的。
Socket 创建时会初始化相关的队列,调用链是 sk_init_data() -> sock_init_data_uid() -> sk_init_common(sk); -> sk_common_init(),核心代码如下:
// https://elixir.bootlin.com/linux/v5.15.139/source/net/core/sock.c#L2008
static void sk_init_common(struct sock *sk)
{
// 初始化接收队列
skb_queue_head_init(&sk->sk_receive_queue);
// 初始化发送队列
skb_queue_head_init(&sk->sk_write_queue);
// 初始化错误队列
skb_queue_head_init(&sk->sk_error_queue);
...
}
TCP Socket 初始化
Socket 创建好后,对于 TCP 协议,这里还会执行 tcp_v4_init_sock 函数继续执行 TCP 相关的初始化工作,我们来看下具体实现。
void tcp_init_sock(struct sock *sk)
{
// 获取 inet_connection_sock 结构体指针,
struct inet_connection_sock *icsk = inet_csk(sk); //
// 获取 tcp_sock 结构体指针
struct tcp_sock *tp = tcp_sk(sk);
// 初始化乱序队列
tp->out_of_order_queue = RB_ROOT;
// 初始化重传队列
sk->tcp_rtx_queue = RB_ROOT;
// 初始化定时器,包括重传定时器、延迟ACK定时等
tcp_init_xmit_timers(sk);
// 初始化 TSQ(TCP Small Queues)节点的链表头
// TSQ 用于限制小数据包的发送,减少网络拥塞
INIT_LIST_HEAD(&tp->tsq_node);
// 初始化按时间戳排序的发送队列链表头
// 用于跟踪已发送但未确认的数据包,便于 RTT 计算和丢包检测
INIT_LIST_HEAD(&tp->tsorted_sent_queue);
// 设置初始重传时间,默认为 1s
icsk->icsk_rto = TCP_TIMEOUT_INIT;
// 设置最小重传时间,默认是 200ms
icsk->icsk_rto_min = TCP_RTO_MIN;
// 设置延迟 ACK 的最大延迟时间,默认是 200ms
icsk->icsk_delack_max = TCP_DELACK_MAX;
// 将初始 RTO 转换为微秒并设置为平均偏差的初始值
// 用于 RTO 算法中的方差计算
tp->mdev_us = jiffies_to_usecs(TCP_TIMEOUT_INIT);
// 重置最小 RTT 跟踪器,初始值设为最大值
minmax_reset(&tp->rtt_min, tcp_jiffies32, ~0U);
// 设置初始拥塞窗口大小(通常为 10 个段)
tcp_snd_cwnd_set(tp, TCP_INIT_CWND);
/* There's a bubble in the pipe until at least the first ACK. */
tp->app_limited = ~0U;
// 标记当前速率受应用层限制
// 用于 BBR 等现代拥塞控制算法的速率控制
tp->rate_app_limited = 1;
// 设置慢启动阈值为无限大
// 初始时不限制拥塞窗口的增长,直到检测到拥塞
tp->snd_ssthresh = TCP_INFINITE_SSTHRESH;
// 设置拥塞窗口的上限为最大值
// 在正常情况下不会达到这个限制
tp->snd_cwnd_clamp = ~0;
// 设置默认的最大段大小(通常为 536 字节)
// 这是保守的默认值,后续会通过路径 MTU 发现进行调整
tp->mss_cache = TCP_MSS_DEFAULT;
// 从网络命名空间的系统配置中读取重排序参数
// 用于检测数据包重排序,影响快速重传的触发
tp->reordering = READ_ONCE(sock_net(sk)->ipv4.sysctl_tcp_reordering);
// 为此连接分配拥塞控制算法(如 Cubic, BBR 等)
// 不同的算法有不同的拥塞控制策略
tcp_assign_congestion_control(sk);
// 初始化时间戳偏移为 0
// TCP 时间戳选项用于 RTT 测量和 PAWS(防止旧段)
tp->tsoffset = 0;
// 设置 RACK 算法的重排序窗口步长为 1
// RACK(Recent ACKnowledgment)用于更精确的丢包检测
tp->rack.reo_wnd_steps = 1;
// 设置使用写队列的标志
// TCP 需要维护发送队列来实现可靠传输
sk->sk_write_space = sk_stream_write_space;
sock_set_flag(sk, SOCK_USE_WRITE_QUEUE);
// 设置 MSS 同步函数
// 用于在连接过程中协商和更新 MSS 值
icsk->icsk_sync_mss = tcp_sync_mss;
// 从系统配置中读取并设置发送缓冲区大小(索引1是默认值)
WRITE_ONCE(sk->sk_sndbuf, READ_ONCE(sock_net(sk)->ipv4.sysctl_tcp_wmem[1]));
// 从系统配置中读取并设置接收缓冲区大小(索引1是默认值)
WRITE_ONCE(sk->sk_rcvbuf, READ_ONCE(sock_net(sk)->ipv4.sysctl_tcp_rmem[1]));
// 增加系统中已分配的 socket 计数
sk_sockets_allocated_inc(sk);
// 强制启用 GSO(Generic Segmentation Offload)功能
// GSO 允许网卡硬件进行数据包分段,提高性能
sk->sk_route_forced_caps = NETIF_F_GSO;
}
如果做过类似 【动手实验】TCP数据的发送和接收 的抓包实验和源码分析,对上述相关字段一定不会感到陌生。
内核 Socket 类型比较
到这里 TCP 相关的 socket 对象就已经创建完成了,我们看到了 socket、sock、tcp_sock、inet_connection_sock 等不同类型的 socket 结构体。这里我们对其做简要的对比:
| 结构体名称 | 说明 | 功能 |
|---|---|---|
| struct socket | 用户态 socket 对象,glibc 封装的接口 | 用户空间的 socket 对象 |
| struct sock | 内核态通用 socket 对象,所有协议族通用 | 内核协议栈核心结果,管理发送/接收队列、锁等 |
| struct inet_sock | IPv4 协议族 socket 对象,继承自 struct sock | Internet 协议族(AF_INET/AF_INET6)的基础结构,包含 IP 等相关信息 |
| struct inet_connection_sock | 连接型协议(如 TCP) socket 对象,继承自 struct inet_sock | 为面向连接的协议(主要是TCP)提供通用的连接管理功能,处理连接建立、维护和移除的共同逻辑,管理定时器、重传、拥塞控制等机制 |
| struct tcp_sock | TCP 协议特有的 socket 对象,继承自 struct inet_connection_sock | 包含 TCP 状态机、序列号等 |
系统调用 connect: 建立连接
笔者这里用的是客户端程序,因此先执行的是 connect 系统调用,而不是 listen、bind、accept。这一步会执行 TCP 三次握手建立连接。TCP 连接的建立和终止的相关内容可以参考笔者的两篇 blog,这里就不做深入的探讨了。
系统调用 send:发送数据
连接建立后程序开始发送数据 send(sock, msg, strlen(msg), 0),send 系统调用根据协议信息找到初始化时设置的 ops 操作合集,然后执行对应的操作。针对 send 其对应的操作函数为 inet_sendmsg。
const struct proto_ops inet_stream_ops = {
.connect = inet_stream_connect,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
}
inet_sendmsg
该函数的操作非常简单,会根据注册的信息找到传输层协议的处理函数。
// https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/af_inet.c#L818
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
if (unlikely(inet_send_prepare(sk)))
return -EAGAIN;
return INDIRECT_CALL_2(sk->sk_prot->sendmsg, tcp_sendmsg, udp_sendmsg,
sk, msg, size);
}
可以看到对于 tcp 其调用的是 tcp_sendmsg,从这里开始数据交给 TCP 协议进行处理。这
TCP 协议层处理
tcp_sendmsg
这里的完整调用链是 send -> inet_sendmsg > tcp_sendmsg -> tcp_sendmsg_locked,核心发送流程在 tcp_sendmsg_locked 中实现,整体代码比较长,我们来分步看下。
初始化状态检查
这一步会做一些特性和状态的检查,比如是否开启零拷贝、Fast Open 等特性,Socket 是否达到发送状态等。
// https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/tcp.c#L1206
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);
struct ubuf_info *uarg = NULL;
struct sk_buff *skb;
struct sockcm_cookie sockc;
int flags, err, copied = 0;
int mss_now = 0, size_goal, copied_syn = 0;
int process_backlog = 0;
bool zc = false;
long timeo;
flags = msg->msg_flags;
// 零拷贝检查
if (flags & MSG_ZEROCOPY && size && sock_flag(sk, SOCK_ZEROCOPY)) {
}
// Fast Open 检查
if (unlikely(flags & MSG_FASTOPEN || inet_sk(sk)->defer_connect) &&
...
}
开启发送循环
如果状态满足,就可以开始发送数据了,这里会有两步工作:
- 计算 MSS
- 开启发送循环
while (msg_data_left(msg)),这个循环是TCP发送机制的核心,会不断读取应用层需要发送的数据,将其封装到 skb 中,实现用户数据到网络数据包的完整转换。
https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/tcp.c#L1292
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
restart:
mss_now = tcp_send_mss(sk, &size_goal, flags);
err = -EPIPE;
if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN))
goto do_error;
// 开启循环
while (msg_data_left(msg)) {
int copy = 0;
...
}
}
数据封装
开启循环后,循环内部会执行 sk_write_queue 尝试从发送队列中获取尾部的 skb:
- 如果 skb 还有空间,就复用它
- 如果没有 skb 或 skb 空间不足,就新建一个 skb
skb 确定后,会准备将用户发送来的数据拷贝到 skb 中准备发送。
// https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/tcp.c#L1285
restart:
mss_now = tcp_send_mss(sk, &size_goal, flags);
err = -EPIPE;
if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN))
goto do_error;
while (msg_data_left(msg)) {
int copy = 0;
// 获取尾部 skb
skb = tcp_write_queue_tail(sk);
if (skb)
copy = size_goal - skb->len;
// 如果没有 skb 或 skb 空间不足,就新建一个 skb
if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) {
bool first_skb;
new_segment:
if (!sk_stream_memory_free(sk))
goto wait_for_space;
if (unlikely(process_backlog >= 16)) {
process_backlog = 0;
if (sk_flush_backlog(sk))
goto restart;
}
first_skb = tcp_rtx_and_write_queues_empty(sk);
skb = sk_stream_alloc_skb(sk, 0, sk->sk_allocation,
first_skb);
if (!skb)
goto wait_for_space;
process_backlog++;
skb->ip_summed = CHECKSUM_PARTIAL;
tcp_skb_entail(sk, skb);
copy = size_goal;
/* All packets are restored as if they have
* already been sent. skb_mstamp_ns isn't set to
* avoid wrong rtt estimation.
*/
if (tp->repair)
TCP_SKB_CB(skb)->sacked |= TCPCB_REPAIRED;
}
/* Try to append data to the end of skb. */
if (copy > msg_data_left(msg))
copy = msg_data_left(msg);
if (!zc) {
bool merge = true;
int i = skb_shinfo(skb)->nr_frags;
struct page_frag *pfrag = sk_page_frag(sk);
if (!sk_page_frag_refill(sk, pfrag))
goto wait_for_space;
if (!skb_can_coalesce(skb, i, pfrag->page,
pfrag->offset)) {
if (i >= READ_ONCE(sysctl_max_skb_frags)) {
tcp_mark_push(tp, skb);
goto new_segment;
}
merge = false;
}
copy = min_t(int, copy, pfrag->size - pfrag->offset);
if (!sk_wmem_schedule(sk, copy))
goto wait_for_space;
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
pfrag->page,
pfrag->offset,
copy);
if (err)
goto do_error;
/* Update the skb. */
if (merge) {
skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy);
} else {
skb_fill_page_desc(skb, i, pfrag->page,
pfrag->offset, copy);
page_ref_inc(pfrag->page);
}
pfrag->offset += copy;
} else {
if (!sk_wmem_schedule(sk, copy))
goto wait_for_space;
err = skb_zerocopy_iter_stream(sk, skb, msg, copy, uarg);
if (err == -EMSGSIZE || err == -EEXIST) {
tcp_mark_push(tp, skb);
goto new_segment;
}
if (err < 0)
goto do_error;
copy = err;
}
if (!copied)
TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH;
WRITE_ONCE(tp->write_seq, tp->write_seq + copy);
TCP_SKB_CB(skb)->end_seq += copy;
tcp_skb_pcount_set(skb, 0);
copied += copy;
if (!msg_data_left(msg)) {
if (unlikely(flags & MSG_EOR))
TCP_SKB_CB(skb)->eor = 1;
goto out;
}
if (skb->len < size_goal || (flags & MSG_OOB) || unlikely(tp->repair))
continue;
这里有几个性能优化点,我们来分别看下。
积压处理
这是首先会判断接受队列的积压情况,当到达阈值 16 时会调用 sk_flush_backlog 函数处理接受队列的积压数据。这么做的目的是在发送大量数据时避免对数据接收造成性能影响,同时也减轻内存压力。
if (unlikely(process_backlog >= 16)) {
process_backlog = 0;
if (sk_flush_backlog(sk))
goto restart;
}
流控处理
在发送数据前会调用 sk_stream_memory_free 函数检查当前 socket 的发送缓冲区是否有足够的空间来存放即将发送的数据。如果缓冲区空间不足,函数会返回 0,导致发送操作被阻塞,等待缓冲区有足够空间后再继续发送。
if (!sk_stream_memory_free(sk))
goto wait_for_space;
wait_for_space:
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
if (copied)
// 如果已经拷贝了一部分数据,就发送出去
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
// 这里会开启一个 while(1) 循环,阻塞等待缓冲区有空间
err = sk_stream_wait_memory(sk, &timeo);
if (err != 0)
goto do_error;
// 重新计算 MSS
mss_now = tcp_send_mss(sk, &size_goal, flags);
}
零拷贝优化
如果开启了零拷贝功能(MSG_ZEROCOPY 标志),数据会直接从用户空间拷贝到网络设备的缓冲区,避免了中间的内存拷贝,提高了性能。
if (flags & MSG_ZEROCOPY && size && sock_flag(sk, SOCK_ZEROCOPY)) {
zc = sk->sk_route_caps & NETIF_F_SG;
}
if (!zc) {// 常规数据拷贝
...
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
pfrag->page,
pfrag->offset,
copy);
} else {
if (!sk_wmem_schedule(sk, copy))
goto wait_for_space;
// 零拷贝
err = skb_zerocopy_iter_stream(sk, skb, msg, copy, uarg);
if (err == -EMSGSIZE || err == -EEXIST) {
tcp_mark_push(tp, skb);
goto new_segment;
}
if (err < 0)
goto do_error;
copy = err;
}
段合并优化
对于普通数据拷贝,如果当前 skb 还有空间,就会尝试将新的数据直接追加到现有的 skb 上,避免频繁创建新的 skb,从而减少内存分配和释放的开销,提高发送效率。
// 检查是否可以合并到现有片段
if (!skb_can_coalesce(skb, i, pfrag->page, pfrag->offset)) {
// 如果片段数量达到系统限制,标记推送并创建新段
if (i >= READ_ONCE(sysctl_max_skb_frags)) {
tcp_mark_push(tp, skb);
goto new_segment;
}
merge = false; // 不能合并
}
if (merge) {
// 如果可以合并,增加最后一个片段的大小
skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy);
} else {
// 创建新的页面描述符
skb_fill_page_desc(skb, i, pfrag->page,
pfrag->offset, copy);
page_ref_inc(pfrag->page); // 增加页面引用计数
}
pfrag->offset += copy;
最大段数限制
上面的段合并优化中,如果不能合并,会检查当前 skb 的片段数是否达到系统配置的最大值 sysctl_max_skb_frags,如果达到就会标记当前 skb 需要推送,并创建一个新的 skb 来存放后续数据。这是为了防止单个 skb 过大,影响网络传输效率。
if (i >= READ_ONCE(sysctl_max_skb_frags)) {skb_frags = 17
tcp_mark_push(tp, skb);
goto new_segment; < size_goal || (flags & MSG_OOB) || unlikely(tp->repair))
}
该数值受内核参数 net.core.max_skb_frags 的控制,通常是 17,在 在 RDMA、DPDK 或大流量场景,常常需要调大。可以通过以下命令查看:
$ sudo sysctl -a | grep skb
net.core.max_skb_frags = 17
数据发送判断
在执行完数据拷贝和 skb 构建后,就可以根据策略发送数据了。TCP 判断逻辑如下:
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
这里有两种情况,前者是批量发送,后者是单包发送,两者简要对比如下:
| 方面 | forced_push (批量发送) | tcp_push_one (单包发送) |
|---|---|---|
| 触发条件 | 缓冲区满、超时等紧急情况 | 正常数据发送流程 |
| 发送数量 | 队列中所有待发送包 | 仅当前一个包 |
| Nagle处理 | 绕过 Nagle 算法 | 遵循 Nagle 算法 |
| 性能特点 | 降低延迟,提高吞吐量 | 平衡延迟和效率 |
__tcp_push_pending_frames 和 tcp_push_one 最终都会调用到 tcp_write_xmit 函数执行具体的 TCP 发送任务,我们来看下其实现。
数据发送处理
到了 tcp_write_xmit 就是 TCP 的各种核心处理了,我们在 RFC 协议中看到的各种窗口控制都是在这里生效的。代码逻辑如下:
https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/tcp_output.c#L2614
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
// 最大段
u32 max_segs;
sent_pkts = 0;
// 刷新TCP时间戳,用于RTT计算
tcp_mstamp_refresh(tp);
max_segs = tcp_tso_segs(sk, mss_now);
// 遍历发送队列的每个 SKB
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
// 发送速率控制
tcp_pacing_check(sk);
// 基于当前 mss 计算 TCP Segmentation Offload 段数
tso_segs = tcp_init_tso_segs(skb, mss_now); // 计算当前skb的TSO段数
// 拥塞窗口控制
cwnd_quota = tcp_cwnd_test(tp, skb);
// 接收窗口控制
tcp_snd_wnd_test(tp, skb, mss_now);
if (tso_segs == 1) {
// 单个段, 走Nagle 算法
if (unlikely(!tcp_nagle_test(tp, skb, mss_now,
(tcp_skb_is_last(sk, skb) ?
nonagle : TCP_NAGLE_PUSH))))
break;
} else {
// TSO 优化路径
if (!push_one &&
tcp_tso_should_defer(sk, skb, &is_cwnd_limited,
&is_rwnd_limited, max_segs))
break;
}
...
// skb太大,分片处理
if (skb->len > limit &&
unlikely(tso_fragment(sk, skb, limit, mss_now, gfp)))
break;
if (tcp_small_queue_check(sk, skb, 0))
break;
// 发送 skb 到网络层
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
...
}
可以看到我们熟悉的拥塞控制、滑动窗口、Nagle 算法等机制都在这里得到了体现。
Nagle 算法与 TCP 软木塞(corking)机制
这里我们对 Nagle 算法的处理做简要的进一步分析。
Nagle 算法的目的是减少网络中的小数据包数量,从而提高网络效率。它通过将小数据包合并成更大的数据包来实现这一点。其核心思想是:在发送一个小数据包后,如果还有未确认的数据包存在,则不会立即发送新的小数据包,而是等待这些数据包被确认后再发送。
Linux 内核判断是否启用 Nagle 的代码如下:
// https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/tcp_output.c#L2075
static inline bool tcp_nagle_test(const struct tcp_sock *tp, const struct sk_buff *skb,
unsigned int cur_mss, int nonagle)
{
/* Nagle rule does not apply to frames, which sit in the middle of the
* write_queue (they have no chances to get new data).
*
* This is implemented in the callers, where they modify the 'nonagle'
* argument based upon the location of SKB in the send queue.
*/
if (nonagle & TCP_NAGLE_PUSH)
return true;
/* Don't use the nagle rule for urgent data (or for the final FIN). */
if (tcp_urg_mode(tp) || (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN))
return true;
if (!tcp_nagle_check(skb->len < cur_mss, tp, nonagle))
return true;
return false;
}
// https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/tcp_output.c#L1953
/* Return false, if packet can be sent now without violation Nagle's rules:
* 1. It is full sized. (provided by caller in %partial bool)
* 2. Or it contains FIN. (already checked by caller)
* 3. Or TCP_CORK is not set, and TCP_NODELAY is set.
* 4. Or TCP_CORK is not set, and all sent packets are ACKed.
* With Minshall's modification: all sent small packets are ACKed.
*/
static bool tcp_nagle_check(bool partial, const struct tcp_sock *tp,
int nonagle)
{
return partial &&
((nonagle & TCP_NAGLE_CORK) ||
(!nonagle && tp->packets_out && tcp_minshall_check(tp)));
}
这里受 tcp->noagle 标志控制,默认为 0,表示启用 Nagle 算法,可选值有三个
TCP_NAGLE_PUSH:禁用 Nagle 算法TCP_NAGLE_CORK:启用软木塞(corking)机制TCP_NAGLE_PUSH:强制推送数据,绕过 Nagle 算法
// https://elixir.bootlin.com/linux/v5.15.139/source/include/net/tcp.h#L228
/* Flags in tp->nonagle */
#define TCP_NAGLE_OFF 1 /* Nagle's algo is disabled */
#define TCP_NAGLE_CORK 2 /* Socket is corked */
#define TCP_NAGLE_PUSH 4 /* Cork is overridden for already queued data */
TCP_NAGLE_PUSH是由外层调用设置的,用户应用程序中有两种方式可以设置其他值:
- 通过
setsockopt系统调用设置TCP_NODELAY、TCP_CORK来禁用 Nagle 算法或启用软木塞机制。 - 通过
MSG_MORE标志在send系统调用中临时设置软木塞机制。
setsockopt(sock, IPPROTO_TCP, TCP_NODELAY, &one, sizeof(one)); // 禁用 Nagle 或设置 TCP_CORK
send(sock, buf, len, MSG_MORE); // 临时启用软木塞机制
了解了相关值的含义,我们再来看下上述的判断逻辑:
- 如果
nonagle的标志为TCP_NAGLE_PUSH,表示当前数据包需要立即发送,绕过 Nagle 算法的限制。 - 如果数据包包含紧急数据(URG)或是连接终止(FIN)标记,也会绕过 Nagle 算法,立即发送。
- 如果数据包的长度不小于当前的 MSS,即
skb->len < cur_mss不成立,表示这是一个完整的数据包,可以立即发送。
当数据包的长度小于 MSS 时,才会进一步检查 Nagle 算法的其他条件:
- 如果启用了 Corking 软木塞机制,则启用 Nagle 算法,这是一项优化技术,允许内核将多个小包积累为单个数据报发送出,从而减少网络上的小数据包数量,提高传输效率。
- 如果没有启用 Corking 机制,并且当前有未确认的数据包(
tp->packets_out非零),则启用 Nagle 算法,等待这些数据包被确认后再发送新的小数据包。 - 如果没有启用 Corking 机制,并且所有已发送的小数据包都已被确认(
tcp_minshall_check(tp)返回 true),则禁用 Nagle 算法,允许立即发送新的小数据包。
封装 TCP 头
经过 tcp_write_xmit 函数的处理后,skb 就准备交给网络层去处理了,这里是调用 tcp_transmit_skb -> __tcp_transmit_skb() 函数来执行的。该函数主要做了两件事:
- 复制 skb:TCP 是支持重传的,而 skb 在网卡发送完后机会释放掉,因此这里需要通过拷贝给 IP 层一份,而 TCP 只有等收到 ACK 后才能释放原有的 skb。
- 封装 TCP Header
完成后会调用 ip_queue_xmit 发送至网络层处理,TCP 传输层的发送流程到此结束。
// https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/tcp_output.c#L1235
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
、、、
if (clone_it) {
TCP_SKB_CB(skb)->tx.in_flight = TCP_SKB_CB(skb)->end_seq
- tp->snd_una;
// 保存原始 skb
oskb = skb;
// 拷贝 skb
tcp_skb_tsorted_save(oskb) {
if (unlikely(skb_cloned(oskb)))
skb = pskb_copy(oskb, gfp_mask);
else
skb = skb_clone(oskb, gfp_mask);
} tcp_skb_tsorted_restore(oskb);
...
}
inet = inet_sk(sk);
tcb = TCP_SKB_CB(skb);
memset(&opts, 0, sizeof(opts));
tcp_header_size = tcp_options_size + sizeof(struct tcphdr);
// 设置 TCP header
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(rcv_nxt);
*(((__be16 *)th) + 6) = htons(((tcp_header_size >> 2) << 12) |
tcb->tcp_flags);
th->check = 0;
th->urg_ptr = 0;
tcp_options_write((__be32 *)(th + 1), tp, &opts);
...
// 发给网络层
err = INDIRECT_CALL_INET(icsk->icsk_af_ops->queue_xmit,
inet6_csk_xmit, ip_queue_xmit,
sk, skb, &inet->cork.fl);
return err;
}
发送至 IP 层
在经过 TCP 头封装后,TCP 协议层的处理到此为止,最终通过 INDIRECT_CALL_INET(icsk->icsk_af_ops->queue_xmit, inet6_csk_xmit, ip_queue_xmit, sk, skb, &inet->cork.fl); 调用 ip_queue_xmit 函数,将 skb 发送给 IP 层进行处理。
IP 层处理
网络层的处理从 __ip_queue_xmit 开始,完整调用路径如图。
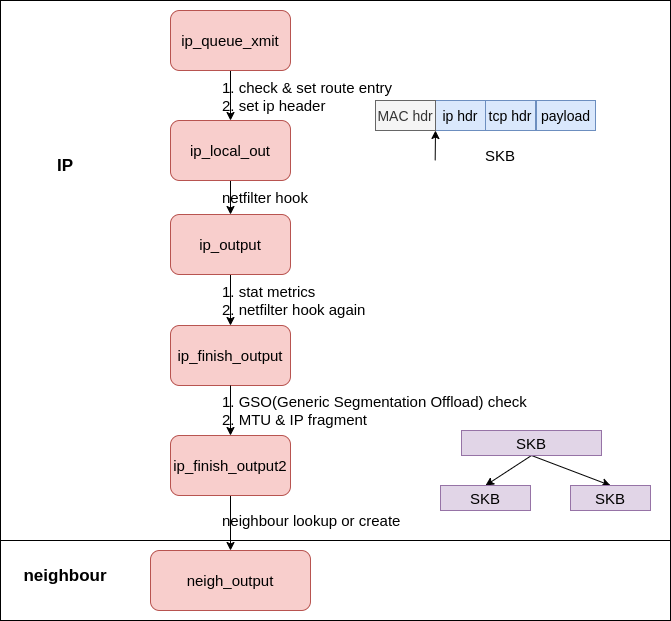
__ip_queue_xmit:路由查找与 IP Header 封装
作为 IP 层处理的第一站,这里会进行路由查找和 IP header 处理,以确定包的发送目的地,我们服务器的路由表就是在这里生效的。
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
/* Skip all of this if the packet is already routed,
* f.e. by something like SCTP.
*/
rcu_read_lock();
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
// 检查skb是否已有路由信息
rt = skb_rtable(skb);
/* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
// 执行路由查找
if (!rt) {
__be32 daddr;
daddr = inet->inet_daddr;
if (inet_opt && inet_opt->opt.srr)
daddr = inet_opt->opt.faddr;
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS_TOS(sk, tos),
sk->sk_bound_dev_if);
sk_setup_caps(sk, &rt->dst);
}
// 设置路由信息
skb_dst_set_noref(skb, &rt->dst);
// 路由确定后的处理
packet_routed:
if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway)
goto no_route;
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
// 获取 IP 头指针
iph = ip_hdr(skb);
// 设置头部字段
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff));
// 基于 PMTUD 设置分片字段
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
// 设置TTL
iph->ttl = ip_select_ttl(inet, &rt->dst);
// 设置协议信息
iph->protocol = sk->sk_protocol;
// 设置目标地址和源地址
ip_copy_addrs(iph, fl4);
...
// 执行发送
res = ip_local_out(net, sk, skb);
rcu_read_unlock();
return res;
}
netfilter 处理
在执行完路由和 IP header 后,进入 ip_local_out->__ip_local_out 函数主要执行了 netfilter 的处理:
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
...
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
可以看到这里的 HOOK 是 NF_INET_LOCAL_OUT,执行完相关操作后会调用 dst_output 函数进行数据包的发送,之后会执行到 ip_output 函数处理,这里也是主要执行了 netfilter 的处理,对应的 HOOK 是 NF_INET_POST_ROUTING。
static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
return INDIRECT_CALL_INET(skb_dst(skb)->output,
ip6_output, ip_output,
net, sk, skb);
}
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev, *indev = skb->dev;
// 执行统计
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUT, skb->len);
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, indev, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
在数据发送时会经过 NF_INET_LOCAL_OUT 和 NF_INET_POST_ROUTING 这两个 netfilter hook,如果我们在这两个 HOOK 上设置的规则过多,可能会导致性能问题。
ip_finish_out 分片处理
在 NF_INET_POST_ROUTING HOOK 处理完毕后,会执行 ip_finish_output->__ip_finish_output 函数进行数据包的发送。这里主要的任务就是 IP 包分片,如果数据包大小大于 MTU(最大传输单元),就需要进行分片处理,逻辑如下:
https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/ip_output.c#L288
static int __ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
unsigned int mtu;
...
mtu = ip_skb_dst_mtu(sk, skb);
if (skb_is_gso(skb))
return ip_finish_output_gso(net, sk, skb, mtu);
if (skb->len > mtu || IPCB(skb)->frag_max_size)
return ip_fragment(net, sk, skb, mtu, ip_finish_output2);
return ip_finish_output2(net, sk, skb);
}
- 如果启用了 GSO(Generic Segmentation Offload),则交给
ip_finish_output_gso函数处理。 - 如果数据包大小大于 MTU(最大传输单元)或开启强制分配,则执行
ip_fragment函数进行分片处理。 - 不需要分配,执行
ip_finish_output2函数进行数据包的发送。
Path MTU Discovery
Linux 提供了一个 路径 MTU 发现(Path MTU Discovery, PMTUD)的机制,用于内核自动确定路径的最大 MTU,从而动态调整数据包的大小以避免分片,提高传输效率。
当启用 PMTUD 时,内核会在发送数据包时设置 IP 头中的 DF(Don’t Fragment)标志,表示该数据包不允许被分片。如果路径中的某个路由器发现数据包的大小超过了其 MTU,就会丢弃该数据包并发送一个 ICMP “Fragmentation Needed” 消息回源主机,告知其路径 MTU 的限制。源主机收到该消息后,会调整其发送的数据包大小,以适应路径 MTU,从而避免分片。
在日常实践中,强烈推荐启用 PMTUD 功能,以确保网络传输的高效性和可靠性,当然其默认也是开启的。我们可以通过下面一些方式来启用 PMTUD。
系统配置
Linux 系统了 net.ipv4.ip_no_pmtu_disc 和 net.ipv4.ip_forward_use_pmtu 两个内核参数来日常发包和转发场景下的PMTUD 功能,默认值均为 0,表示启用 PMTUD 功能。有三个可选值:
- 0:启用PMTU发现
- 1:禁用PMTU发现
- 2:启用PMTU发现但忽略黑洞检测
$ sysctl net.ipv4.ip_no_pmtu_disc
net.ipv4.ip_no_pmtu_disc = 0
$ sysctl net.ipv4.ip_forward_use_pmtu
net.ipv4.ip_forward_use_pmtu = 0
Socket 设置
可以通过 setsockopt 系统调用设置 IP_MTU_DISCOVER 选项来启用或禁用 PMTUD 功能。该选项有四个可选值:
IP_PMTUDISC_DONT:禁用 PMTUD 功能IP_PMTUDISC_WANT:启用 PMTUD 功能,允许分片IP_PMTUDISC_DO:强制启用 PMTUD 功能,不允许分片IP_PMTUDISC_PROBE:启用 PMTUD 功能,允许通过发送探测包以确定路径 MTU。
可以通过在创建 socket 后调用 setsockopt 来设置该选项:
int val = IP_PMTUDISC_DO; // 强制启用 PMTUD 功能,不允许分片
setsockopt(sock, IPPROTO_IP, IP_MTU_DISCOVER, &val, sizeof(val));
具体到协议,TCP 协议在 Linux 上默认已经启用 PMTUD(相当于 DO),但 UDP、RAW socket 需要手动设置。
ip_finish_output2:邻居查找与数据包发送
无论是分片处理还是直接发送,最终都会调用到 ip_finish_output2 函数做后续的处理。
首先是处理各种数据统计,对于多播和广播包会进行相应的统计处理。然后会检查 skb 的头部空间是否足够,如果不够就会调用 skb_realloc_headroom 扩展头部空间,确保有足够的空间来容纳任何需要的链路层头部。
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev;
unsigned int hh_len = LL_RESERVED_SPACE(dev);
struct neighbour *neigh;
bool is_v6gw = false;
if (rt->rt_type == RTN_MULTICAST) {
// 多播,使用 IP_UPD_PO_STATS 宏来增加 OutMcastPkts 和 OutMcastOctets 计数
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST)
// 广播,使用 IP_UPD_PO_STATS 宏来增加 OutBcastPkts 和 OutBcastOctets 计数
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTBCAST, skb->len);
// 按需扩展头部空间
if (unlikely(skb_headroom(skb) < hh_len && dev->header_ops)) {
skb = skb_expand_head(skb, hh_len);
if (!skb)
return -ENOMEM;
}
...
}
完成后就会执行邻居查找,核心是下面几行代码:
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
// 查找邻居项
neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
if (!IS_ERR(neigh)) {
int res;
// 确认邻居项可达
sock_confirm_neigh(skb, neigh);
// 邻居项可达,交给邻居子系统发送数据包
res = neigh_output(neigh, skb, is_v6gw);
rcu_read_unlock_bh();
return res;
}
...
}
ip_neigh_for_gw -> ip_neigh_gw4 函数会针对 IPv4 数据包查找下一跳的邻居项,代码如下:
static inline struct neighbour *ip_neigh_gw4(struct net_device *dev,
__be32 daddr)
{
struct neighbour *neigh;
neigh = __ipv4_neigh_lookup_noref(dev, (__force u32)daddr);
if (unlikely(!neigh))
neigh = __neigh_create(&arp_tbl, &daddr, dev, false);
return neigh;
}
这里首先会调用 __ipv4_neigh_lookup_noref 根据传入的 IPv4 地址查找 ARP 缓存,如果没找到,则调会用 __neigh_create 函数创建一个新的邻居项。确认邻居项可达后,会执行 neigh_output 函数,内部会调用邻居子系统的 output 函数继续处理报文的发送,
// https://elixir.bootlin.com/linux/v5.15.139/source/include/net/neighbour.h#L496
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb,
bool skip_cache)
{
...
return n->output(n, skb);
}
邻居子系统操作的定义信息如下,这里实际调用的是 neigh_resolve_output 函数,
// https://elixir.bootlin.com/linux/v5.15.139/source/net/ipv4/arp.c#L130
static const struct neigh_ops arp_generic_ops = {
.family = AF_INET,
.solicit = arp_solicit,
.error_report = arp_error_report,
.output = neigh_resolve_output,
.connected_output = neigh_connected_output,
};
邻居子系统处理
在网络分层模型中,IP 网络层处理完成后就需要交给链路层来进行发送了,我们知道二层传输需要的是 MAC 地址,因此在发送数据包之前我们需要通过 ARP 协议等手段获取目标 MAC 地址,这个工作就是由邻居子系统来完成的。
邻居子系统主要负责管理和维护 IP 地址与 MAC 地址之间的映射关系,当一个主机需要发送数据包到另一个主机时,它会首先检查 ARP 缓存中是否存在目标主机的 MAC 地址。如果存在,则直接使用该地址进行数据包的发送;如果不存在,则需要通过 ARP 请求来获取目标主机的 MAC 地址。
Linux 的 IPv4 和 IPv6 都依赖邻居子系统来处理地址解析和邻居发现,IPv4 使用 ARP 协议,而 IPv6 使用 NDP(Neighbor Discovery Protocol)协议,最终由邻居子系统将数据包发送给网络设备子系统。
邻居子系统的处理从 neigh_resolve_output 函数开始,完整调用路径如图。
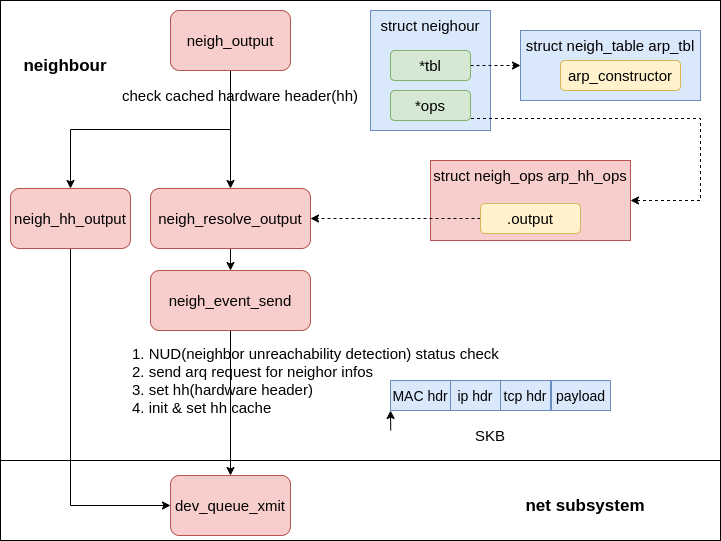
构建 MAC 头
在 neigh_resolve_output函数中,代首先会调用执行 neigh_event_send()->__neigh_event_send(neigh, skb); 函数执行邻居可达性检查,这里可能会发送 ARP 请求,如果邻居不可达则会返回 0,表示数据包无法发送。
如果可达则会调用 dev_hard_header 函数构建 MAC 头,将邻居的 MAC 地址设置到数据包的头部,然后调用 dev_queue_xmit 函数将数据包交给网络设备子系统进行发送。
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb)
{
int rc = 0;
// 邻居可达性检查,可能会发送 ARP 请求
if (!neigh_event_send(neigh, skb)) {
...
do {
__skb_pull(skb, skb_network_offset(skb));
seq = read_seqbegin(&neigh->ha_lock);
// 设置 MAC 头,ha 即为邻居的 MAC 地址
err = dev_hard_header(skb, dev, ntohs(skb->protocol),
neigh->ha, NULL, skb->len);
} while (read_seqretry(&neigh->ha_lock, seq));
if (err >= 0)
// 交给网络设备子系统发送数据包
rc = dev_queue_xmit(skb);
else
goto out_kfree_skb;
}
out:
return rc;
out_kfree_skb:
rc = -EINVAL;
kfree_skb(skb);
goto out;
}
网络设备子系统处理
从 dev_queue_xmit->__dev_queue_xmit 开始,数据包开始进入网络设备子系统处理,核心处理逻辑都是在 __dev_queue_xmit 函数中完成的,我们来一步步看下。
发布准备
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
int rc = -ENOMEM;
bool again = false;
skb_reset_mac_header(skb);
skb_assert_len(skb);
if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP))
__skb_tstamp_tx(skb, NULL, NULL, skb->sk, SCM_TSTAMP_SCHED);
/* Disable soft irqs for various locks below. Also
* stops preemption for RCU.
*/
rcu_read_lock_bh();
skb_update_prio(skb);
...
}
这里开始的准备工作主要有:
- 声明 nedt_device、netdev_queue、Qdisc 等变量,代表网络设备、发送队列和队列调度器。
- 调用
skb_reset_mac_header,重置 skb 内部的 MAC 头指针,指向当前数据位置,使得 skb 的 MAC 头可以被正确访问。 - 合法性长度检查
- 调用
rcu_read_lock_bh,禁用软中断,防止在临界区内被打断,确保数据一致性。 - 调用
skb_update_prio,如果启用了 Network priority cgroup,网络优先级 cgroup ,会更新 skb 的优先级信息,这对于流量控制和队列调度非常重要。但这只针对 cgroup1 有效,cgroup2 不支持该功能。在 cgroupv2 环境下可以使用 eBPF\ 程序来实现类似的功能。
完成一系列准备工作后,下一步会选择发送队列,将 skb 交给合适的发送队列进行处理。整体逻辑大致为:
- 调用
netdev_core_pick_tx函数选择一个发送队列。 - 调用
rcu_dereference_bh获取该队列对应的队列调度器(Qdisc)。 - 调用
trace_net_dev_queue进行跟踪,可以通过 ftrace 的等工具查看。 - 如果有队列规则,则调用
__dev_xmit_skb函数将 skb 交给队列调度器处理。 - 如果没有队列规则,通常是回环设备或者隧道设备,则调用
dev_hard_start_xmit函数发送数据包。
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
txq = netdev_core_pick_tx(dev, skb, sb_dev);
q = rcu_dereference_bh(txq->qdisc);
trace_net_dev_queue(skb);
if (q->enqueue) {
// 有队列规则,交给队列调度器处理
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
if (dev->flags & IFF_UP) {
...
// 没有队列规则,直接发送
skb = dev_hard_start_xmit(skb, dev, txq);
goto out;
}
}
我们来重点看下选择发送队列的逻辑。
选择发送队列
ndo_select_queue 回调函数
首先会调用 netdev_core_pick_tx 函数来选择一个合适的发送队列。
struct netdev_queue *netdev_core_pick_tx(struct net_device *dev,
struct sk_buff *skb,
struct net_device *sb_dev)
{
int queue_index = 0;
#ifdef CONFIG_XPS
u32 sender_cpu = skb->sender_cpu - 1;
if (sender_cpu >= (u32)NR_CPUS)
skb->sender_cpu = raw_smp_processor_id() + 1;
#endif
if (dev->real_num_tx_queues != 1) {
const struct net_device_ops *ops = dev->netdev_ops;
if (ops->ndo_select_queue)
queue_index = ops->ndo_select_queue(dev, skb, sb_dev);
else
queue_index = netdev_pick_tx(dev, skb, sb_dev);
queue_index = netdev_cap_txqueue(dev, queue_index);
}
skb_set_queue_mapping(skb, queue_index);
return netdev_get_tx_queue(dev, queue_index);
}
处理逻辑为:
- 如果网卡仅有一个发送队列,则直接选择该队列。
- 现代网卡大多支持多队列,这里会根据是否实现了
ndo_select_queue回调函数来选择发送队列。
ndo_select_queue 是 net_device_ops 结构体中的一个函数指针,网卡驱动可以通过实现该回调函数来自定义发送队列的选择逻辑。对于内核来说:
- 如果网卡驱动实现了
ndo_select_queue函数,则调用该函数来选择发送队列,对于 i40e 驱动,其对应函数为 i40e_lan_select_queue。 - 如果没有实现,则调用内核的默认选择逻辑
netdev_pick_tx
netdev_pick_tx 内核默认选择逻辑
我们首先看下内核默认是如何选择发送队列的,这里主要由 netdev_pick_tx 函数来完成。
// https://elixir.bootlin.com/linux/v5.15.139/source/net/core/dev.c#L4084
u16 netdev_pick_tx(struct net_device *dev, struct sk_buff *skb,
struct net_device *sb_dev)
{
struct sock *sk = skb->sk;
int queue_index = sk_tx_queue_get(sk);
sb_dev = sb_dev ? : dev;
if (queue_index < 0 || skb->ooo_okay ||
queue_index >= dev->real_num_tx_queues) {
int new_index = get_xps_queue(dev, sb_dev, skb);
if (new_index < 0)
new_index = skb_tx_hash(dev, sb_dev, skb);
if (queue_index != new_index && sk &&
sk_fullsock(sk) &&
rcu_access_pointer(sk->sk_dst_cache))
sk_tx_queue_set(sk, new_index);
queue_index = new_index;
}
return queue_index;
}
整体逻辑如下:
- 首先调用
sk_tx_queue_get尝试从 socket 缓存中获取发送队列索引,如果没有缓存,返回 -1,表示索引无效。 - if 语句做一系列检查,只要任一条件满足,就表示没有有效的队列索引,需要重新选择:
queue_index < 0:索引无效,没有可用的缓存。skb->ooo_okay:如果不为 0 说明内核允许发送数据包乱序发送,内核可能需要为此选择不同的发送队列。UDP 协议永远设置为 0。queue_index >= dev->real_num_tx_queues:索引超出队列数量,如果用户最近通过 ethool 或者ip link set命令修改了网卡的队列数量,可能会导致索引无效。
- 上述任一条件成立后,首先会调用
get_xps_queue函数尝试基于 XPS(Transmit Packet Steering,传输包调度)策略选择发送队列。 - 如果没有启用 XPS 或者没有匹配的队列,则调用
skb_tx_hash函数基于哈希算法选择一个发送队列。
Transmit Packet Steering (XPS)
Transmit Packet Steering (XPS, 数据包传输导向) 是一种网络优化技术,旨在通过将传输数据包分配到特定的 CPU 核心和网络队列上,提高多核处理器系统的网络性能。XPS 通过减少 CPU 核心之间的缓存失效和上下文切换,优化了数据包的处理效率。更详细的介绍可以参考 Linux 文档。
配置 XPS 主要通过设置每个网络队列允许使用的 CPU 核心来实现,这通常通过修改 /sys/class/net/<interface>/queues/tx-<n>/xps_cpus 文件来完成,其中 <interface> 是网络接口名称,<n> 是队列索引。文件内容是一个位掩码,表示允许使用的 CPU 核心。下面是笔者云服务器的默认配置:
$ cat /sys/class/net/eth0/queues/tx-0/xps_cpus
1
$ cat /sys/class/net/eth0/queues/tx-1/xps_cpus
2
队列发送:__dev_xmit_skb
现在内核已经准备好了网络设备、发送队列和排队规则 qdisc,接下来就会调用 __dev_xmit_skb 函数将 skb 交给 qdisc 进行处理。
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev) {
...
txq = netdev_core_pick_tx(dev, skb, sb_dev);
q = rcu_dereference_bh(txq->qdisc);
trace_net_dev_queue(skb);
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
...
}
Queuing Disciplines 排队规则
在 Linux 内核中,排队规则(Queuing Disciplines,简称 qdisc)或者说是队列调度器,负责管理和调度网络数据包的发送顺序和速率。简单来说就是发送包的时候要排队,qdisc 就是管理这么包如何排队,何时发出去的。
qdisc 通过维护一个或多个队列来存储待发送的数据包,并根据预定义的调度算法决定数据包的发送顺序,从而实现流量控制、带宽管理和服务质量(QoS)保障等功能。
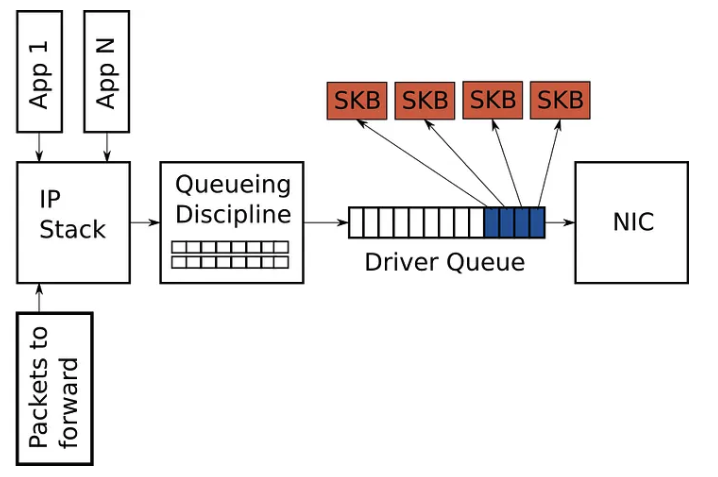
每个网络设备(如以太网卡)都可以关联一个或多个队列调度器,以适应不同的网络需求和应用场景。Linix 系统在默认情况下会为每个网络设备配置一个默认的队列调度器,具体取决于网卡的发送队列数量。
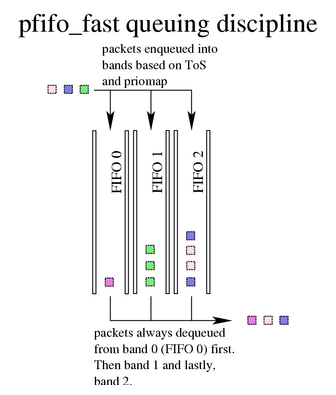
- 如果网卡只有一个发送队列,则会使用 pfifo_fast 作为默认的队列调度器。pfifo_fast 是最老的默认 qdisc,相当于一个简单的 FIFO 队列,有 3 个优先级 band,几乎就是“先进先出”。
- 如果网卡有多个发送队列,则会使用
mq作为默认的队列调度器。mq不是一个真正的排队算法,而是一个调度器容器,将每个队列关联一个 qdisc,目前 Linux 默认会为每个队列关联一个fq_codelqdisc。
$ sudo tc qdisc show dev eth0
qdisc mq 0: root
qdisc fq_codel 0: parent :2 limit 10240p flows 1024 quantum 8514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
qdisc fq_codel 0: parent :1 limit 10240p flows 1024 quantum 8514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
关于 qdisc 的更多介绍可以参考两篇经典的教程 Traffic Control HOWTO 和 Linux Advanced Routing & Traffic Control HOWTO。
__dev_xmit_skb
我们看下 __dev_xmit_skb 函数的实现,核心代码如下
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
{
...
qdisc_calculate_pkt_len(skb, q);
// 无锁队列
if (q->flags & TCQ_F_NOLOCK) {
if (q->flags & TCQ_F_CAN_BYPASS && nolock_qdisc_is_empty(q) &&
qdisc_run_begin(q)) {
/* Retest nolock_qdisc_is_empty() within the protection
* of q->seqlock to protect from racing with requeuing.
*/
if (unlikely(!nolock_qdisc_is_empty(q))) {
rc = dev_qdisc_enqueue(skb, q, &to_free, txq);
__qdisc_run(q);
qdisc_run_end(q);
goto no_lock_out;
}
qdisc_bstats_cpu_update(q, skb);
if (sch_direct_xmit(skb, q, dev, txq, NULL, true) &&
!nolock_qdisc_is_empty(q))
__qdisc_run(q);
qdisc_run_end(q);
return NET_XMIT_SUCCESS;
}
rc = dev_qdisc_enqueue(skb, q, &to_free, txq);
qdisc_run(q);
no_lock_out:
if (unlikely(to_free))
kfree_skb_list(to_free);
return rc;
}
/*
* Heuristic to force contended enqueues to serialize on a
* separate lock before trying to get qdisc main lock.
* This permits qdisc->running owner to get the lock more
* often and dequeue packets faster.
*/
contended = qdisc_is_running(q);
if (unlikely(contended))
spin_lock(&q->busylock);
spin_lock(root_lock);
if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) {
__qdisc_drop(skb, &to_free);
rc = NET_XMIT_DROP;
} else if ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) &&
qdisc_run_begin(q)) {
/*
* This is a work-conserving queue; there are no old skbs
* waiting to be sent out; and the qdisc is not running -
* xmit the skb directly.
*/
qdisc_bstats_update(q, skb);
if (sch_direct_xmit(skb, q, dev, txq, root_lock, true)) {
if (unlikely(contended)) {
spin_unlock(&q->busylock);
contended = false;
}
__qdisc_run(q);
}
qdisc_run_end(q);
rc = NET_XMIT_SUCCESS;
} else {
rc = dev_qdisc_enqueue(skb, q, &to_free, txq);
if (qdisc_run_begin(q)) {
if (unlikely(contended)) {
spin_unlock(&q->busylock);
contended = false;
}
__qdisc_run(q);
qdisc_run_end(q);
}
}
spin_unlock(root_lock);
if (unlikely(to_free))
kfree_skb_list(to_free);
if (unlikely(contended))
spin_unlock(&q->busylock);
return rc;
}
核心执行逻辑为:
- 计算数据包长度,更新 qdisc 的统计信息。
- 根据 qdisc 的标志位决定是否需要加锁。
- 如果 qdisc 支持直接发送且当前队列为空,则尝试直接发送
- 否则将数据包加入队列,并根据需要触发队列调度器运行,发送数据包。
- 释放锁和资源,返回发送结果。
整体判断条件比较多,包括是否是无锁队列,是否支持直接发送,队列是否为空,qdisc 是否正在运行等,我们这里暂不做深入分析。就整体调用流程来说,主要有两种情况:
- 如果可以直接发送,则走快速路径直接调用
sch_direct_xmit函数直接将数据包发送出去。 - 如果需要排队,则走慢速路径,首先调用
dev_qdisc_enqueue函数将数据包加入队列,然后调用__qdisc_run函数触发队列调度器运行,发送数据包。
即使是慢速路径最终也会调用 sch_direct_xmit 函数发送数据包,只不过是通过队列调度器来控制发送顺序和速率,后面我们还会分析这个函数。现在我们先看下队列发送是如何执行的。
__qdisc_run:执行 qdisc 的入口
__qdisc_run 函数是执行 qdisc 的入口,主要负责触发队列调度器运行,发送数据包,完整代码比较简单。
void __qdisc_run(struct Qdisc *q)
{
int quota = READ_ONCE(dev_tx_weight);
int packets;
// 不断循环从队列取出一个 skb 并发送,直到发送的数据包数达到配额或者队列为空
while (qdisc_restart(q, &packets)) {
quota -= packets;
if (quota <= 0) { // 如果发送的数据包数达到配额,则退出循环
if (q->flags & TCQ_F_NOLOCK) //
set_bit(__QDISC_STATE_MISSED, &q->state);
else
__netif_schedule(q);
break;
}
}
}
可以看到核心发送逻辑在 qdisc_restart 函数中完成。
qdisc_restart:从队列取包并发送
该函数主要逻辑有两步:
- 调用
dequeue_skb函数从队列中取出一个 skb。如果退列为空,则返回 false,表示没有更多数据包需要发送。外层的 while 循环会退出。 - 如果有 skb,则获取 qdisc 的锁(如果需要),然后获取相关的网络设备和发送队列,最后调用
sch_direct_xmit函数将 skb 和这些信息一起发送出去。
static inline bool qdisc_restart(struct Qdisc *q, int *packets)
{
spinlock_t *root_lock = NULL;
struct netdev_queue *txq;
struct net_device *dev;
struct sk_buff *skb;
bool validate;
// skb 出队
skb = dequeue_skb(q, &validate, packets);
if (unlikely(!skb))
return false;
if (!(q->flags & TCQ_F_NOLOCK))
root_lock = qdisc_lock(q);
// 获取网络设备和发送队列
dev = qdisc_dev(q);
txq = skb_get_tx_queue(dev, skb);
return sch_direct_xmit(skb, q, dev, txq, root_lock, validate);
}
dequeue_skb:出队操作
这是 qdisc 规则真正生效的地方,dequeue_skb 函数比较长,但核心逻辑很简单,就是 skb = q->dequeue(q); 这一行代码,这里调用的具体的排队算法的 dequeue 函数指针来完成出队操作。
struct Qdisc *qdisc_alloc(struct netdev_queue *dev_queue,
const struct Qdisc_ops *ops,
struct netlink_ext_ack *extack)
{
struct Qdisc *sch;
...
sch->ops = ops;
sch->dequeue = ops->dequeue;
}
Qdisc_ops 结构体定义了各种排队算法的操作函数接口,其中 dequeue 函数指针定义了出队操作,不同的排队算法根据接口自行实现自己的出队逻辑。下面是 pfifo_fast 和 fq_codel 的示例。
// https://elixir.bootlin.com/linux/v5.15.139/source/net/sched/sch_generic.c#L228
struct Qdisc_ops pfifo_fast_ops __read_mostly = {
.id = "pfifo_fast",
.priv_size = sizeof(struct pfifo_fast_priv),
.enqueue = pfifo_fast_enqueue,
.dequeue = pfifo_fast_dequeue,
.peek = pfifo_fast_peek,
.init = pfifo_fast_init,
.destroy = pfifo_fast_destroy,
.reset = pfifo_fast_reset,
.dump = pfifo_fast_dump,
.change_tx_queue_len = pfifo_fast_change_tx_queue_len,
.owner = THIS_MODULE,
.static_flags = TCQ_F_NOLOCK | TCQ_F_CPUSTATS,
};
https://elixir.bootlin.com/linux/v5.15.139/source/net/sched/sch_fq_codel.c#L705
static struct Qdisc_ops fq_codel_qdisc_ops __read_mostly = {
.cl_ops = &fq_codel_class_ops,
.id = "fq_codel",
.priv_size = sizeof(struct fq_codel_sched_data),
.enqueue = fq_codel_enqueue,
.dequeue = fq_codel_dequeue,
.peek = qdisc_peek_dequeued,
.init = fq_codel_init,
.reset = fq_codel_reset,
.destroy = fq_codel_destroy,
.change = fq_codel_change,
.dump = fq_codel_dump,
.dump_stats = fq_codel_dump_stats,
.owner = THIS_MODULE,
};
不同的排队算法有不同的出队逻辑,比如 pfifo_fast 是一个简单的 FIFO 队列,而 fq_codel 则实现了更复杂的公平队列和拥塞控制机制。我们这里不做深入分析,感兴趣的读者可以参考相关代码和文档。
sch_direct_xmit:发送数据包到网卡
现在我们到了发送包到网卡的最后一步:sch_direct_xmit。核心就是调用 dev_hard_start_xmit 函数,将 skb 发送到网卡驱动程序,这个我们后续会继续分析。
*/
bool sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock, bool validate)
{
skb = dev_hard_start_xmit(skb, dev, txq, &ret);
}
软中断调度
让我们回到 __qdisc_run 函数中,如果发送的数据包数达到了配额 dev_tx_weight,则会调用 __netif_schedule(q) ->__netif_reschedule(q),触发 NET_TX_SOFTIRQ 软中断。
void __netif_schedule(struct Qdisc *q)
{
if (!test_and_set_bit(__QDISC_STATE_SCHED, &q->state))
__netif_reschedule(q);
}
static void __netif_reschedule(struct Qdisc *q)
{
struct softnet_data *sd;
unsigned long flags;
local_irq_save(flags);
sd = this_cpu_ptr(&softnet_data);
q->next_sched = NULL;
*sd->output_queue_tailp = q;
sd->output_queue_tailp = &q->next_sched;
// 触发软中断
raise_softirq_irqoff(NET_TX_SOFTIRQ);
local_irq_restore(flags);
}}
我们知道处理软中断的函数是 net_tx_action 函数,这个函数主要负责处理发送队列和完成队列,核心代码如下:
static __latent_entropy void net_tx_action(struct softirq_action *h)
{
...
if (sd->output_queue) {
struct Qdisc *head;
...
while (head) {
struct Qdisc *q = head;
...
qdisc_run(q);
if (root_lock)
spin_unlock(root_lock);
}
}
}
整体代码比较长,这里最核心的处理就是对 sd->output_queue 发送队列进行遍历,然后调用 qdisc_run(q) 函数处理每个 qdisc,最终也是会走 __qdisc_run -> qdisc_restart -> sch_direct_xmit -> dev_hard_start_xmit 这条路径将数据包发送到网卡驱动。
网卡驱动发包
现在我们终于到了数据包发送的最后一步:网卡发包。大多数设备和驱动基本通过两个步骤来完成发包:
- 数据映射发送阶段:将数据包映射到网卡可以 DMA 访问到的内存区域,然后网卡通过 DMA 从该内存区域读取数据包并发送。
- 状态清理阶段:发送完成后,网卡设备发出中断,驱动程序会解决映射关系、释放内存等资源。
上面提到无论是软中断,还是用户进程内核态中的数据发送,都会调用到 dev_hard_start_xmit 函数,这个函数主要负责将数据包发送到网卡驱动程序,核心流程是 dev_hard_start_xmit -> xmit_one -> netdev_start_xmit -> __netdev_start_xmit。在 __netdev_start_xmit 函数会调用网卡驱动的 ndo_start_xmit 回调函数来实际发送数据包。
驱动回调注册
在介绍系统初始化时,我们提到网卡驱动注册时会设置 net_device_ops 结构体,其中包含了各种回调函数指针,结构体中定义了一个 ndo_start_xmit 函数,用于发送数据包,网卡驱动必须实现该函数,对于 i40e 驱动来说,ndo_start_xmit 回调函数是 i40e_lan_xmit_frame 函数。
static const struct net_device_ops i40e_netdev_ops = {
.ndo_open = i40e_open,
.ndo_stop = i40e_close,
.ndo_start_xmit = i40e_lan_xmit_frame,
}
ndo_start_xmit 发包
上层网络栈通过 net_device_ops.ndo_start_xmit 函数指针调用驱动的发包函数,完成数据包的发送。在 i40e 驱动中回调函数是 i40e_lan_xmit_frame 函数,我们从该函数开始看起。
netdev_tx_t i40e_lan_xmit_frame(struct sk_buff *skb, struct net_device *netdev)
{
...
return i40e_xmit_frame_ring(skb, tx_ring);
}
i40e_lan_xmit_frame 会调用i40e_xmit_frame_ring 函数,这是 i40e 驱动中发送数据包的核心函数,主要负责将 skb 中的数据打包成网卡可以识别的格式,并将其映射到网卡可访问的 DMA 内存区域,最后通知网卡发送数据包。我们来一步步看下该函数的实现。
函数首先会计算发送数据包所需的描述符数量,然后根据分片情况对描述符数量做相应的调整。
/* 计算发送这个数据包需要的描述符数量 */
count = i40e_xmit_descriptor_count(skb);
/* 检查是否需要线性化skb(将分散的数据片段合并) */
if (i40e_chk_linearize(skb, count)) {
/* 尝试线性化skb */
if (__skb_linearize(skb)) {
/* 线性化失败,释放skb并返回成功(避免重传) */
dev_kfree_skb_any(skb);
return NETDEV_TX_OK;
}
/* 重新计算线性化后的描述符数量 */
count = i40e_txd_use_count(skb->len);
/* 统计线性化次数 */
tx_ring->tx_stats.tx_linearize++;
}
然后驱动程序会检查发送队列是否有足够的描述符资源来处理这个数据包。如果资源不足,驱动会停止发送并返回 NETDEV_TX_BUSY,表示当前无法处理更多的数据包。这会导致 skb 被 qdisc 重新排队,等待下一次发送机会。
/* 需要的描述符总数计算:
* - 每页需要的描述符数 * PAGE_SIZE/I40E_MAX_DATA_PER_TXD
* - skb头部数据需要的描述符数
* - 4个描述符的间隙(避免缓存行冲突)
* - 1个上下文描述符
* 如果描述符不够,停止发送
*/
if (i40e_maybe_stop_tx(tx_ring, count + 4 + 1)) {
/* 统计因资源不足导致的繁忙次数 */
tx_ring->tx_stats.tx_busy++;
return NETDEV_TX_BUSY;
}
确定有足够资源后,驱动程序会准备传输描述符,首先会获取到队列中下一个可用的描述符索引,并将 skb 关联到该描述符上,记录数据包的字节数和 GSO 段数。
// 获取 TX 队列中的下一个可用描述符索引
/* record the location of the first descriptor for this packet */
first = &tx_ring->tx_bi[tx_ring->next_to_use];
// 将 skb 关联到描述符
first->skb = skb;
// 记录数据包字节数
first->bytecount = skb->len;
// 初始化 GSO 段数为 1
first->gso_segs = 1;
完成后会进行一系列的协议处理和标志设置,包括处理 VLAN 标签、设置 IPv4/IPv6 标志、处理 TSO(TCP Segmentation Offload)等。
/* 获取数据包的网络层协议类型(处理VLAN标签) */
protocol = vlan_get_protocol(skb);
/* 根据协议类型设置IPv4/IPv6标志 */
if (protocol == htons(ETH_P_IP))
tx_flags |= I40E_TX_FLAGS_IPV4; /* IPv4协 */
/* 处理TSO(TCP Segmentation Offload)大包分段 */
tso = i40e_tso(first, &hdr_len, &cd_type_cmd_tso_mss);
/* 启用校验和卸载(硬件计算校验和) */
tso = i40e_tx_enable_csum(skb, &tx_flags, &td_cmd, &td_offset,
tx_ring, &cd_tunneling);
完成一系列设置后,驱动程序会创建传输上下文描述符,并调用 i40e_tx_map 函数执行具体的映射,后续我们会详细分析该函数。在发送成功后,还会进行一些清理操作,主要包括时间戳相关的资源清理。
cleanup_tx_tstamp:
/* 清理时间戳相关资源 */
if (unlikely(tx_flags & I40E_TX_FLAGS_TSYN)) {
struct i40e_pf *pf = i40e_netdev_to_pf(tx_ring->netdev);
/* 释放PTP发送的skb */
dev_kfree_skb_any(pf->ptp_tx_skb);
pf->ptp_tx_skb = NULL;
/* 清除PTP发送进行中的状态位 */
clear_bit_unlock(__I40E_PTP_TX_IN_PROGRESS, pf->state);
}
i40e_tx_map: 映射数据到 DMA
i40e_tx_map 负责将 skb 中的数据映射到 DMA 内存区域,然后通知网卡发送数据包,我们简单看下该函数的实现。
首先是一系列的变量声明,为了方便理解我们还是加上注释将他们列出来。
static inline int i40e_tx_map(struct i40e_ring *tx_ring, struct sk_buff *skb,
struct i40e_tx_buffer *first, u32 tx_flags,
const u8 hdr_len, u32 td_cmd, u32 td_offset)
{
/* 获取skb分片数据的总长度(不包括线性数据部分) */
unsigned int data_len = skb->data_len;
/* 获取skb线性数据部分的长度 */
unsigned int size = skb_headlen(skb);
/* 指向当前处理的分片 */
skb_frag_t *frag;
/* 指向当前的传输缓冲区 */
struct i40e_tx_buffer *tx_bi;
/* 指向当前的传输描述符 */
struct i40e_tx_desc *tx_desc;
/* 发送环中的当前索引位置 */
u16 i = tx_ring->next_to_use;
/* DMA地址 */
dma_addr_t dma;
/* 使用的描述符计数 */
u16 desc_count = 1;
然后会开始数据的映射处理,代码比较冗长,我们总结下一些值得注意的步骤:
- 将 skb 的线性数据部分映射到 DMA 地址。
- 开启一个非常长的循环,遍历 skb 的所有数据片段(包括线性部分和分片)。
- 不断记录描述符的使用情况,并根据数据大小和对齐要求调整描述符的控制字段。
- 对于大于单个描述符最大容量的数据段,使用多个描述符进行分段处理。
- 不断更新描述符迭代器和传输缓冲区指针,直到所有数据片段都被处理完毕。
- 当处理完所有分片后,终止循环。
static inline int i40e_tx_map(struct i40e_ring *tx_ring, struct sk_buff *skb,
struct i40e_tx_buffer *first, u32 tx_flags,
const u8 hdr_len, u32 td_cmd, u32 td_offset)
{
...
/* 将skb的线性数据部分映射到DMA地址 */
dma = dma_map_single(tx_ring->dev, skb->data, size, DMA_TO_DEVICE);
/* 获取当前位置的传输描述符 */
tx_desc = I40E_TX_DESC(tx_ring, i);
/* 遍历所 skb 所有有数据片段(包括线性部分和分片) */
for (frag = &skb_shinfo(skb)->frags[0];; frag++) {
/* 每个描述符最大数据长度(按对齐要求) */
unsigned int max_data = I40E_MAX_DATA_PER_TXD_ALIGNED;
/* 检查DMA映射是否成功 */
if (dma_mapping_error(tx_ring->dev, dma))
goto dma_error;
/* 调整max_data以对齐到页边界,优化DMA传输效率 */
max_data += -dma & (I40E_MAX_READ_REQ_SIZE - 1);
/* 设置描述符的DMA缓冲区地址(转换为小端序) */
tx_desc->buffer_addr = cpu_to_le64(dma);
/* 处理大于单个描述符最大容量的数据段 */
while (unlikely(size > I40E_MAX_DATA_PER_TXD)) {
...
/* 构建并设置描述符的控制字段(命令、类型、偏移、大小) */
tx_desc->cmd_type_offset_bsz =
build_ctob(td_cmd, td_offset,
max_data, td_tag);
}
/* 如果没有更多分片数据,结束循环 */
if (likely(!data_len))
break;
...
/* 将分片数据映射到DMA地址 */
dma = skb_frag_dma_map(tx_ring->dev, frag, 0, size,
DMA_TO_DEVICE);
/* 获取下一个传输缓冲区 */
tx_bi = &tx_ring->tx_bi[i];
}
/* 设置最后一个描述符的完整控制字段 */
tx_desc->cmd_type_offset_bsz =
build_ctob(td_cmd, td_offset, size, td_tag);
}
当所有描述符准备好,skb 的所有数据都映射到 DMA 地址后,驱动程序会就会执行到最后一步,通知网卡发送数据包,核心代码如下:
/* 记录数据包发送时间戳(用于网络统计) */
skb_tx_timestamp(skb);
/* 内存屏障:确保所有描述符写入完成后再通知硬件
* 这是关键的同步点,防止硬件在描述符准备完成前开始处理
*/
wmb();
/* 设置监控点,指向最后一个描述符(用于完成检测) */
first->next_to_watch = tx_desc;
/* 通知硬件有新的数据包等待发送
* 只有在队列停止或没有更多数据包时才写寄存器(批处理优化)
*/
if (netif_xmit_stopped(txring_txq(tx_ring)) || !netdev_xmit_more()) {
writel(i, tx_ring->tail);
}
/* 成功返回 */
return 0;
-
skb_tx_timestamp:用来获取基于软件的发送时间戳,这个时间戳可以用于网络统计和调试,帮助分析数据包的发送时间,某些网卡还支持硬件打时间戳。通过这个时间戳我们可以分析数据包在网络栈的耗时。 -
调用
wmb设置内存屏障,确保所有描述符写入完成后再通知硬件,防止网卡从内存中读到不一致的数据。 -
设置
first->next_to_watch指向最后一个描述符,这个字段用于完成后使用。 -
调用
writel(i, tx_ring->tail);通知网卡有新的数据包等待发送。只有在队列停止或没有更多数据包时才写寄存器,这样可以批量处理多个数据包,减少对寄存器的写操作,提高性能。
这部分会涉及一些内存一致性和内存屏障相关的知识,可以参考 内核内存屏障文档、内存模型文章和这个教程。
最后就是一些错误处理逻辑,只有 DMA 映射失败才会走到这里,驱动会释放已经映射的资源,并返回错误码。
dma_error:
dev_info(tx_ring->dev, "TX DMA map failed\n");
/* clear dma mappings for failed tx_bi map */
for (;;) {
tx_bi = &tx_ring->tx_bi[i];
i40e_unmap_and_free_tx_resource(tx_ring, tx_bi);
if (tx_bi == first)
break;
if (i == 0)
i = tx_ring->count;
i--;
}
tx_ring->next_to_use = i;
return -1;
发送完成
当数据发送完成后,网卡会产生一个硬中断来表示发送完成。对于 i40e 驱动和设备来说,数据收包和发送完成其 IRQ 是相同的,因此会走同一套中断处理流程。这个我们在数据收包章节已经分析过,这里我们简单回顾一下:
- 收到数据包或者发包完成
- 网卡触发硬中断
- 驱动程序调用中断处理函数
i40e_msix_clean_rings - 触发软中断,这里触发的软中断是
NET_RX_SOFTIRQ - 软中断启用 NAPI 处理
- 执行
i40e_napi_poll函数,处理收包和发包 - 如果没有更多的包或者预算用完,结束 NAPI 处理
对于 i40e 驱动来说,其处理函数为 i40e_msix_clean_rings函数,最终会调用 ____napi_schedule 触发软中断。
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
struct task_struct *thread;
...
list_add_tail(&napi->poll_list, &sd->poll_list);
// 触发 NET_RX_SOFTIRQ 软中断
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
可以看到即使是发包,这里触发的也是 NET_RX_SOFTIRQ 软中断,这是软中断统计 RX 往往高于 TX 的原因,发包完成后也会触发 RX 软中断来处理发送完成的队列。
i40e_napi_poll: 处理收包和发包
我们在来到 i40e_napi_poll 函数时,其核心流程是先处理发包,然后处理收包,最后根据预算和工作量决定是否结束 NAPI 处理。
因为发包结束只会涉及一些清理工作,执行相对较快。因此会先执行发包结束处理并给予较大的预算 budget,然后调用 i40e_clean_tx_irq 函数来处理发送完成的队列,这是发送结束后的核心处理逻辑。
int i40e_napi_poll(struct napi_struct *napi, int budget)
{
struct i40e_q_vector *q_vector =
container_of(napi, struct i40e_q_vector, napi);
// 处理发包
i40e_for_each_ring(ring, q_vector->tx) {
bool wd = ring->xsk_pool ?
// XDP 模式处理
i40e_clean_xdp_tx_irq(vsi, ring) :
// 普通模式处理
i40e_clean_tx_irq(vsi, ring, budget);
}
// 处理收包
i40e_for_each_ring(ring, q_vector->rx) {
int cleaned = ring->xsk_pool ?
i40e_clean_rx_irq_zc(ring, budget_per_ring) :
i40e_clean_rx_irq(ring, budget_per_ring);
work_done += cleaned;
/* if we clean as many as budgeted, we must not be done */
if (cleaned >= budget_per_ring)
clean_complete = false;
}
/* 如果收发都处理完毕,结束 NAPI */
return min(work_done, budget - 1);
}
i40e_clean_tx_irq: 处理发送完成
我们来详细看下具体的发送完成处理函数 i40e_clean_tx_irq,代码比较长,我们分步骤来看下。
首先是一系列的变成声明和初始化。
/**
* i40e_clean_tx_irq - Reclaim resources after transmit completes
**/
static bool i40e_clean_tx_irq(struct i40e_vsi *vsi,
struct i40e_ring *tx_ring, int napi_budget)
{
static bool i40e_clean_tx_irq(struct i40e_vsi *vsi,
struct i40e_ring *tx_ring, int napi_budget)
{
// 初始化当前清理位置为下一个待清理的描述符索引
int i = tx_ring->next_to_clean;
// 声明TX缓冲区和描述符指针
struct i40e_tx_buffer *tx_buf;
struct i40e_tx_desc *tx_head;
struct i40e_tx_desc *tx_desc;
// 初始化统计变量
unsigned int total_bytes = 0, total_packets = 0;
// 设置清理预算,限制本次清理的最大描述符数量
unsigned int budget = vsi->work_limit;
// 获取当前待清理的TX缓冲区指针
tx_buf = &tx_ring->tx_bi[i];
// 获取当前待清理的TX描述符指针
tx_desc = I40E_TX_DESC(tx_ring, i);
// 调整索引,为环形缓冲区处理做准备
i -= tx_ring->count;
// 获取硬件当前的头指针位置(已完成传输的位置)
tx_head = I40E_TX_DESC(tx_ring, i40e_get_head(tx_ring));
...
}
这里比较重要的是清理预算 budget,它限制了本次清理的最大描述符数量,防止一次清理过多导致软中断处理时间过长,影响系统响应。其初始值为 vsi->work_limit,默认值为 256。
// https://elixir.bootlin.com/linux/v5.15.139/source/drivers/net/ethernet/intel/i40e/i40e_txrx.h#L10
/* Interrupt Throttling and Rate Limiting Goodies */
#define I40E_DEFAULT_IRQ_WORK 256
接下来,会开始一个循环,遍历待清理的描述符,直到达到预算或者没有更多描述符需要清理。
do {
struct i40e_tx_desc *eop_desc = tx_buf->next_to_watch;
/* if next_to_watch is not set then there is no work pending */
if (!eop_desc)
break;
/* prevent any other reads prior to eop_desc */
smp_rmb();
i40e_trace(clean_tx_irq, tx_ring, tx_desc, tx_buf);
/* we have caught up to head, no work left to do */
if (tx_head == tx_desc)
break;
/* clear next_to_watch to prevent false hangs */
tx_buf->next_to_watch = NULL;
/* update the statistics for this packet */
total_bytes += tx_buf->bytecount;
total_packets += tx_buf->gso_segs;
// 释放 skb 或 XDP 帧
if (ring_is_xdp(tx_ring))
xdp_return_frame(tx_buf->xdpf);
else
napi_consume_skb(tx_buf->skb, napi_budget);
// 释放 skb 相关的 DMA 映射
dma_unmap_single(tx_ring->dev,
dma_unmap_addr(tx_buf, dma),
dma_unmap_len(tx_buf, len),
DMA_TO_DEVICE);
// 清空tx_buffer中的skb指针和DMA长度
tx_buf->skb = NULL;
dma_unmap_len_set(tx_buf, len, 0);
// 处理多描述符包:解除剩余缓冲区的映射
while (tx_desc != eop_desc) {
// 接触剩余页面的 DMA 映射
if (dma_unmap_len(tx_buf, len)) {
dma_unmap_page(tx_ring->dev,
dma_unmap_addr(tx_buf, dma),
dma_unmap_len(tx_buf, len),
DMA_TO_DEVICE);
dma_unmap_len_set(tx_buf, len, 0);
}
}
...
// 减少预算
budget--;
} while (likely(budget));
1. 首先将 `eop_desc(end of packet)` 设置为当前 `tx_buf->next_to_watch`,这是该数据包的最后一个描述符。
2. 检查 `next_to_watch` 是否为空,如果为空说明没有更多工作需要处理,跳出循环。
3. 执行一系列设置和统计
4. 释放 skb
5. 解除 DMA 映射
6. 设置 `tx_buf->skb` 为 NULL,表示该缓冲区已被清理。
7. 如果数据包使用了多个描述符,继续解除剩余描述符的 DMA 映射。
循环结束后,会执行一系列的收尾动作,包括
```c
...
// 通知网络设备已完成的缓冲区数量
netdev_tx_completed_queue(txring_txq(tx_ring),
total_packets, total_bytes);
// 定义唤醒阈值(需要的描述符数量的2倍)
#define TX_WAKE_THRESHOLD ((s16)(DESC_NEEDED * 2))
// 检查是否需要唤醒发送队列
if (unlikely(total_packets && netif_carrier_ok(tx_ring->netdev) &&
(I40E_DESC_UNUSED(tx_ring) >= TX_WAKE_THRESHOLD))) {
// 内存屏障,确保其他CPU能看到新的next_to_clean值
smp_mb();
// 如果子队列被停止且VSI未关闭
if (__netif_subqueue_stopped(tx_ring->netdev,
tx_ring->queue_index) &&
!test_bit(__I40E_VSI_DOWN, vsi->state)) {
// 唤醒对应的发送子队列
netif_wake_subqueue(tx_ring->netdev,
tx_ring->queue_index);
// 增加队列重启统计计数
++tx_ring->tx_stats.restart_queue;
}
}
// 返回是否还有剩余预算(转换为布尔值)
return !!budget;
- 调用
netdev_tx_completed_queue通知网络设备已完成的缓冲区数量。如果清理出的空间足够多,这可能会重启队列。 - 更新网络统计信息。
- 检查队列是否被停止且有足够的描述符可用,如果是则唤醒队列。
- 最后返回是否还有剩余预算,转换为布尔值。如果还有剩余预算,返回 true,否则返回 false。
完成发送完成的清理工作后,NAPI 处理函数 i40e_napi_poll 会继续处理接收队列,直到预算用完或者没有更多数据包需要处理,最后决定是否结束 NAPI 处理。
至此我们对 Linux 网络的接收和发送流程都做了简要的分析,正如 Joe Damato 所说的:
Optimizing and monitoring the network stack is impossible unless you carefully read and understand how it works. You cannot monitor code you don’t understand at a deep level.
不深入阅读和理解网络栈,就不可能优化和监控它。 你监控不了你没有深入理解的代码。
只有在深刻理解了复杂的 Linux 网络栈之后,我们才能更好的去优化和监控它,从而提升系统的网络性能,下一篇我们来聊聊 Linux 网络和系统相关的监控与优化手段。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)